the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Aug 2022
| 02 Aug 2022
A kriging-based analysis of cloud liquid water content using CloudSat data
Jean-Marie Lalande
Guillaume Bourmaud
Pierre Minvielle
Jean-François Giovannelli
Spatiotemporal statistical learning has received increased attention in the past decade, due to spatially and temporally indexed data proliferation, especially data collected from satellite remote sensing. In the meantime, observational studies of clouds are recognized as an important step toward improving cloud representation in weather and climate models. Since 2006, the satellite CloudSat of NASA is carrying a 94 GHz cloud-profiling radar and is able to retrieve, from radar reflectivity, microphysical parameter distribution such as water or ice content. The collected data are piled up with the successive satellite orbits of nearly 2 h, leading to a large compressed database of 2 Tb (http://cloudsat.atmos.colostate.edu/, last access: 8 June 2022).
These observations offer the opportunity to extend the cloud microphysical properties beyond the actual measurement locations using an interpolation and prediction algorithm. To do so, we introduce a statistical estimator based on the spatiotemporal covariance and mean of the observations known as kriging. An adequate parametric model for the covariance and the mean is chosen from an exploratory data analysis. Beforehand, it is necessary to estimate the parameters of this spatiotemporal model; this is performed in a Bayesian setting. The approach is then applied to a subset of the CloudSat dataset.
- Article
(18781 KB) - Full-text XML
- BibTeX
- EndNote





Clouds have a strong influence on weather and climate. They are a key element of earth’s hydrological cycle, bringing water from the air to the ground and from one region of the globe to another. They also dominate the energy budget of the earth through their action on the exchange of solar and thermal radiation within the atmosphere and between the atmosphere, the hydrosphere, the land surface, the biosphere, and space. However, they still remain a major source of uncertainty in predicting the weather and climate change.
While the measurement of cloud occurrences and properties at useful spatial and temporal scales is notoriously difficult (Marshak and Davis, 2005; Stephens and Kummerow, 2007), the proliferation of satellite platforms in the past few decades (Stephens et al., 2002; Eriksson et al., 2008; Wu et al., 2009) is fostering a number of new approaches. One such satellite, CloudSat, whose payload is a cloud-profiling radar (CPR), has been dedicated to measuring the cloud vertical structure and microphysical properties. It is part of the A-train constellation, which was originally set to comprise seven satellites specifically designed to measure cloud and precipitation properties using different instruments. Since 2006 CloudSat has collected a large database of cloud properties, globally and over an extended period of time, despite some malfunctions.
In this study, we analyze statistically a part of this database in order to perform interpolation and prediction of cloud properties. This kind of spatiotemporal estimation can be of major importance for the assessment of satellite cloud attenuation (Lyras et al., 2016), including Global Positioning System (GPS) radio occultation (Yang and Zou, 2012). It is required for improving the representation of cloud systems in numerical weather prediction (Bodas-Salcedo et al., 2008; Chen et al., 2011), e.g., for data assimilation (Qu et al., 2018). It can be involved in the assessment of an aircraft icing detection system (Vivekanandan et al., 2001), the design of a satellite communication system (Khan et al., 2012), the systematic comparison with other cloud products from different instruments and/or satellites, etc.
As observations from different instruments are likely not collected at the same spatiotemporal positions, the procedure of interpolation–prediction usually involves regridding selected slots of data. A number of statistical methods dedicated to the analysis of spatial and spatiotemporal data have been developed over the years taking into account the spatial and/or temporal correlation of the observations (Ripley, 1981; Cressie, 1993). In this study, we propose to use an approach based on a kriging estimator for the interpolation–prediction problem. The kriging estimator was initially introduced by Krige (1951), from which it takes its name, to estimate the gold distribution at the Witwatersrand reef complex in South Africa based on samples from boreholes. It was then formalized mathematically by Matheron (1963) in the context of mining geology. Afterwards, the kriging estimator spread to many other areas of sciences (Wackernagel, 2013) (hydrogeology, geotechnics, agronomy, air quality, fishery, epidemiology, water and soil pollution, noise, etc.). The best-known kriging techniques are simple kriging, which assumes stationarity of the first order with a known mean, ordinary kriging, where the mean is unknown and to be estimated, and universal kriging, which assumes non-stationarity of the first-order. Since its initial development, kriging techniques have largely evolved, and a number of new kriging techniques have been developed (Chiles and Delfiner, 1999; Cressie, 1993; Cressie and Wikle, 2015). In the field of meteorology, the kriging estimator has primarily been used to estimate precipitation accumulation from rain gauges (Nour et al., 2006; Belo-Pereira et al., 2011) and in combination with satellite-derived precipitation (Jewell and Gaussiat, 2015; Verdin et al., 2016; Varouchakis et al., 2021) as well as aerosol concentration in the air from in situ observations (Park, 2016). It has also been used for the estimation of temperature from in situ measurements (Heuvelink et al., 2012; Didari and Zand-Parsa, 2018), from satellite observations (Florio et al., 2004), or a combination of them (Didari and Zand-Parsa, 2018) as well as for the estimation of surface properties from remote measurements (der Meer, 2012; Zakeri and Mariethoz, 2021).
Our approach is based on a second-order analysis of cloud liquid water content (LWC) obtained from the Level 2B product of the CloudSat ground segment data. We perform a detailed analysis of these properties and propose an adequate parametric model for their mean and covariance. The model parameters are obtained by maximizing the a posteriori probability density, which comprises a likelihood term expressing how the model fits the observation conditionally to the presence of clouds. Finally, we apply this model in the context of interpolation and prediction of CloudSat observations. To our knowledge, it is the first time the kriging estimator has been employed to infer cloud microphysical properties using CloudSat observations:
-
We provide a comprehensive mathematical description of the kriging estimator. It allows us to mention that the parameters of the mean and covariance functions are commonly treated differently in the kriging literature. In our approach, parameters can enter both linearly and non-linearly in the mean, which makes it more flexible in accommodating the trend of the observations. Thus, we propose a global treatment of all the parameters of the model since standard universal kriging is not compatible with non-linearity.
-
We propose a model for the mean and covariance functions and thoroughly justify each choice we make (e.g., stationarity assumption, homogeneity assumption)
-
We perform a detailed analysis of both the estimated model parameters and the resulting interpolated–predicted cloud LWC.
2.1 The CloudSat data and the CPR instrument
CloudSat has been flying in formation in the A-train with other satellites including Aqua, Aura and CALIPSO. CloudSat payload consists of a 94 GHz CPR that was specifically designed to sense cloud-sized particles (i.e., cloud ice, snow, cloud droplets and light rain).
It was declared operational on 2 June 2006 and had been flying in the A-train until 22 February 2018. It follows a sun-synchronous orbit with an approximately 13:30 LT equatorial crossing time. Since 2011 and a battery malfunction, it has provided observations only during daytime. The satellite visits the same position of the globe after a period of 16 d corresponding to 233 orbits. Each orbit is achieved in about 1 h and 58 min. The CloudSat radar samples profiles at 625 kHz and has an along-track velocity of approximately 7 km s−1, which corresponds to a profile measured every 0.16 s with an along-track displacement of approximately 1.1 km. Each profile has 125 vertical bins of 240 m thickness.
In this study, we use the Level 2B Cloud Water Content product (2B-CWC-RO) that contains retrieved estimates of cloud liquid and ice water content, effective radius, and related quantities for each radar backscattered reflectivity profile (Austin et al., 2009). We focus on a region centered over Europe and under-sampled at a rate of (cf. Fig. 1). In this region, we select data from 16 June 2006 to 14 June 2015 constituting a set of 239 087 profiles. The CPR observations are classified according to their cloud types in the Level 2B-CLDCLASS product (cf. Fig. 2). After analysis of the cloud type distribution inside the considered region, we decided to focus on the LWCs labeled as altostratus since they constitute a good balance between the number of available data and the computational feasibility. Moreover, altostratus are less fractionated than other cloud types, and thereby their physical properties are more continuous.

Figure 1CloudSat ground track representing 14 orbits (a), zoom in on the European zone under study (b).
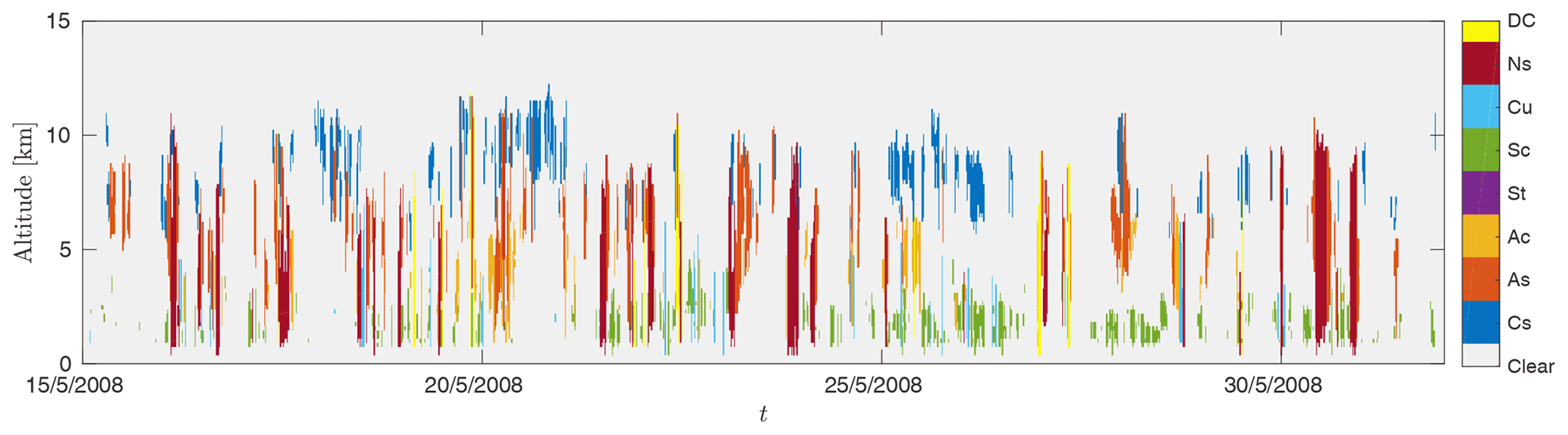
Figure 2Sample of CloudSat cloud classification over a period of 15 d. Clouds are classified according to clear (no clouds), Cs (cumulus), As (altostratus), Ac (altocumulus), St (stratus), Sc (stratocumulus), Cu (cirrus), Ns (nimbostratus), DC (deep convective).
2.2 Mathematical description of the data
2.2.1 Background
We consider the scalar function Φ of three spatial variables and a temporal variable t mapping elements from D into ℝ:
where s∈D is spatiotemporal localization, x, y represent, respectively, the longitude and latitude at the earth's surface and z is the altitude. The function Φ can be modeled as a deterministic or stochastic quantity. The stochastic nature of the function Φ can be introduced to model some inner variability of the physical phenomenon under study or an incomplete knowledge of the phenomenon itself. The complete description of a stochastic process requires the construction of the joint probability density function for the continuous variables in space and time (Chonavel and Ormrod, 2002; Gaetan and Guyon, 2008; Brockwell and Davis, 2009), which can be cumbersome in a high-dimensional space. To alleviate this burden, it is possible to resort to the description of the mean and covariance of the random function. This proves very efficient when the distribution associated with the random function is not too complex (for instance, when the random function is Gaussian, the mean and covariance are sufficient to completely describe the distribution).
In this study, we assume that the mean and covariance exist and represent sufficiently well the distribution of the random function Φ. The mean is a function of the spatiotemporal localization s:
where E[⋅] denotes the expectation of the random variable. The covariance is a function of 4 spatiotemporal variables and 4 spatiotemporal shift variables, noted . Thus we have
The covariance function describes the spatiotemporal dependency of the stochastic function Φ. Based on these definitions, it is useful to introduce certain stationary models to characterize the degree of homogeneity of the random function Φ.
2.2.2 Stationarity
In order to infer the distribution of the random function Φ, the structure of the spatiotemporal process is of great importance. In this sense, stationary models make it possible to structure the spatiotemporal variability of the random function Φ. The process under study is said to be strictly stationary if the distributions and are identical for all δ, , and for all k∈ℕ. This is a very restrictive condition which is not usually satisfied in real-life applications. The weak stationarity stipulates that
-
the random function Φ is first-order stationary when its expected value does not depend on the localization s:
-
the random function Φ is second-order stationary when its covariance function depends only on the lag vector δ between two localizations s and :
2.2.3 Observations and uncertainties
We denote the successive spatiotemporal positions , and the targeted quantity Φ at these positions:
We model the actual observations of the targeted quantity Φ as corrupted by an additive noise related to the measurement uncertainty. The observation at position sn is then denoted Ψn and is written:
where Ψn, Φn and Bn are random variables. We denote the values associated with a realization of these random variables by ψn, φn and bn. Thus, a realization of the random variable Ψ at the position sn is written:
and additionally, we write:
where , and are the collections of the related N quantities.
2.2.4 Objectives
The objective of this work is to determine the value φ0 of the quantity of interest φ at a given location . This is an estimation problem that is tackled by designing an estimate of the quantity of interest φ0 from the data ψ described in the previous section. On the one hand, spatially, this is an interpolation problem since the point x0, y0, z0 is usually not on the grid of observations. On the other hand, temporally, this is a prediction problem since t0 is naturally positioned in the future. The considered approach is to statistically learn from the large number of available data both to interpolate and predict the targeted quantity and to quantize the uncertainty associated with the estimated value. In the next section, we introduce the kriging estimator, which is specifically designed to perform such a task.
The goal is to construct a statistical estimator
in order to estimate φ0 from the observations ψ. This section describes the strategy for the construction of the kriging estimator which has been widely used in geostatistics. This framework has been developed in a number of handbooks (Cressie, 1993; Chiles and Delfiner, 1999; Diggle et al., 2003) and later on by Montero et al. (2015), in the case of a known mean and covariance. Our development differs slightly from the standards of geostatistical literature in two ways.
-
The parameters of the mean function mΦ(s) usually act linearly and consequently their estimation can be performed inside the kriging estimator while the estimation of the covariance parameters is classically performed in a previous offline procedure. Instead, in order to design a model with a higher capacity, we consider both a non-linear mean and a non-linear covariance function and estimate their parameters in an offline procedure.
-
Our approach is fully parametric and consequently relies on a parametric covariance function instead of a variogram (Banerjee et al., 2014).
Thus, in the following development, we consider that the mean and covariance functions are known and defer the (offline) estimation of their parameters to the next section.
We consider a linear estimator of the form
where are the observations, are scalar coefficients and N is the number of available observations. This can be alternatively expressed in terms of realizations of the random variables as
Our goal is to determine the coefficients a and a0. The strategy is to minimize an error between the estimated quantity and the true value Φ0. We choose the mean square error (MSE):
The estimator , defined by Eqs. (3)–(4) with
and the corresponding estimator is the so-called minimum mean square error estimator (MMSE). The value minimizing Eq. (5) satisfies
giving
Then, plugin of Eq. (6) into Eq. (5) and expanding leads to
where we introduced the following notations:
where RΨ is the covariance matrix of the observations, is the covariance between the observations and the quantity of interest, and var[Φ0] is the variance of the quantity of interest. The vector aopt that minimizes Eq. (7) satisfies
and that leads to
Moreover, modeling noise B independent of the quantity of interest Φ, we have
so that
Finally, we deduce the estimated value of the quantity of interest φ at position s0 by inserting Eqs. (9) and (6) in Eq. (4):
Additionally, the MSE of the estimated value is given by
which, in this context, equals to the variance of the estimation error because the bias is equal to zero. This estimator is known as the kriging estimator in the geostatistical literature (Montero et al., 2015). In a slightly different form, this estimator is also the one of Kalman and Wiener in the field of filtering.
4.1 Time–altitude and spectral analysis
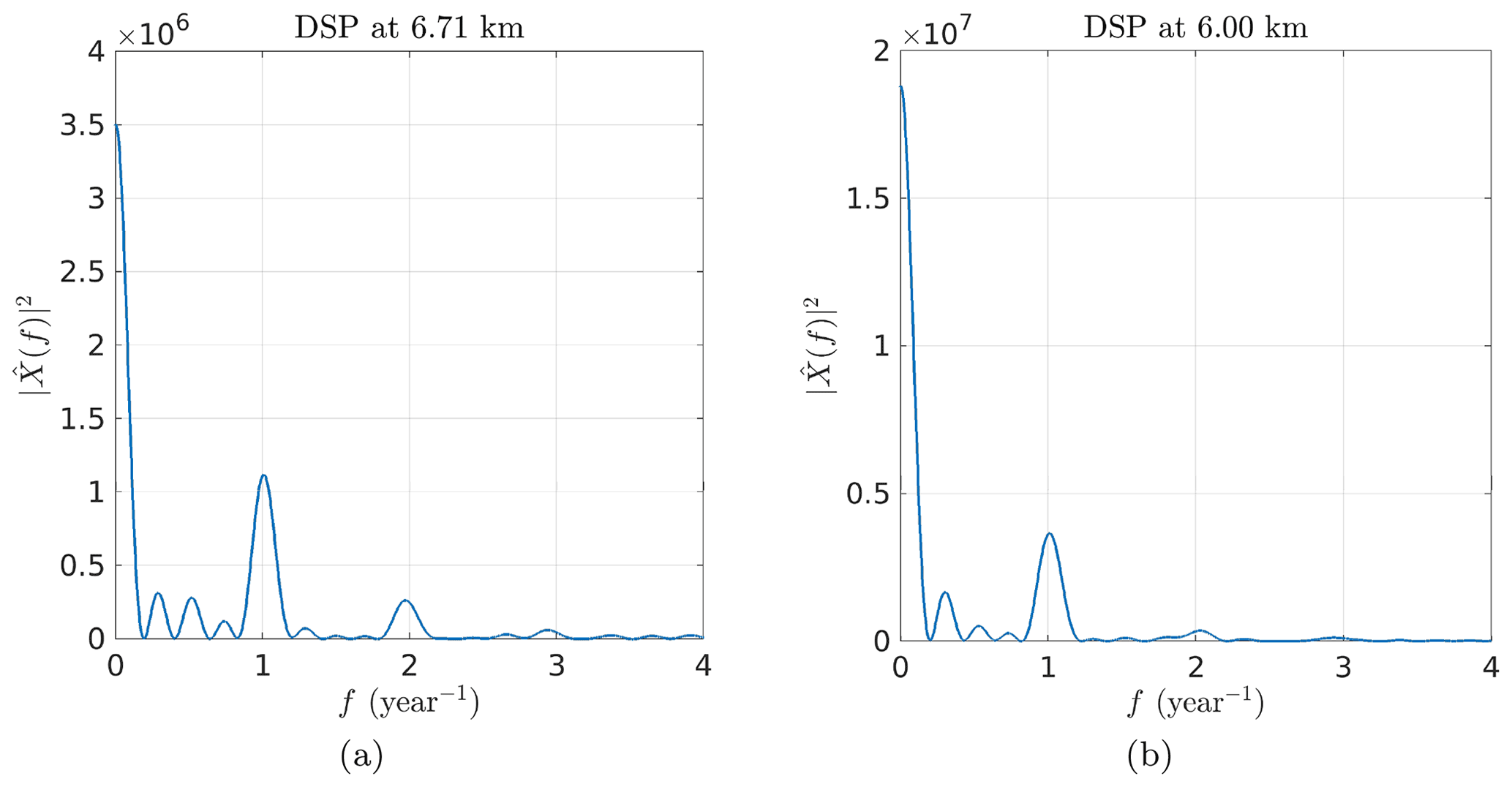
In order to construct an adequate model for the mean and the covariance, we start with an exploratory analysis to extract some raw characteristics from the time–altitude observations represented in Fig. 3. We compute the biased empirical covariance for the 2-dimensional case (δt,δz) and the 1- dimensional case at a fixed altitude of z=6.711 km (cf. Fig. 4). This shows 1-year periodicity of the LWC observations in the time component, while the altitude component decreases to 0 for δz=1 km. The blue spots located at km are due to zero-padding above and below the cloudy profile that introduces an artificial correlation. Another way of looking at the data ψ is to compute the empirical power spectral density , i.e., the squared modulus of the Fourier transform of the observations ψ (a.k.a. periodogram) (cf. Fig. 5). There is clearly a peak at 1 year−1. For some altitudes, there are lower peaks at 2 year−1 or even at 3 year−1, indicating that the signal cannot be modeled by a single sinusoidal component. At lower altitudes, the fundamental component becomes negligible as do the harmonics. Nevertheless, this suggests that CloudSat observations can be interpreted as the superposition of multiple periodic components.
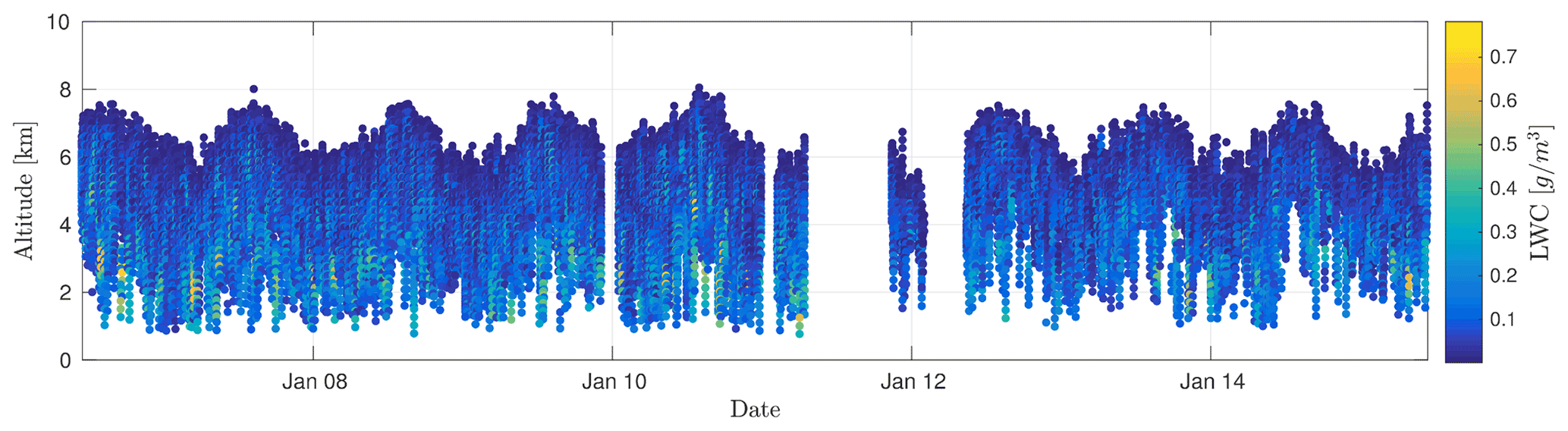
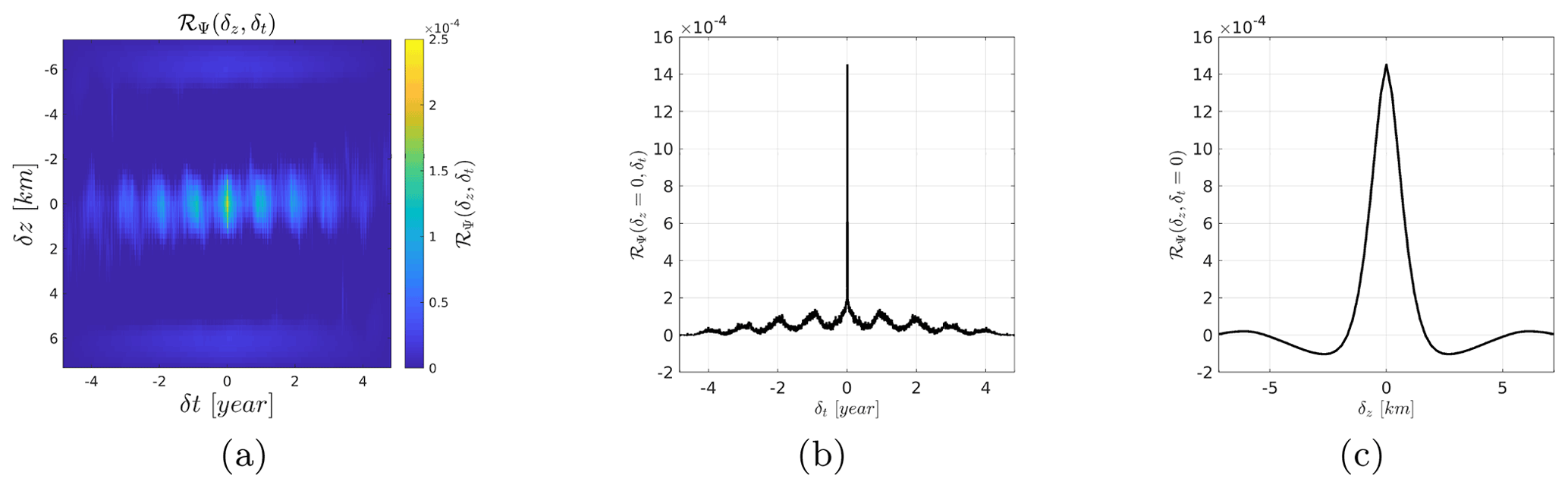
Figure 4Empirical covariance: (a) 2-dimensional covariance (δt,δz), (b) slice at δz=0 km and (c) slice at δt=0 year.
4.2 Proposition of an adequate model
The observations Ψ are modeled as the addition of a random process Φ and a random noise process B, such as
We dodge the complexity of handling 4 dimensions and choose to do an in-depth analysis of a time-altitude dependent model while omitting the latitude-longitude dimensions. This simplification can be justified when the spatial extension of the dataset is not too important. This is equivalent to assimilating the dataset to a single spatial location by averaging over the geographic components. All random processes are modeled as Gaussian (Rasmussen and Williams, 2005):
where RΦ, RB and RΨ are the covariance matrices associated with the quantity of interest Φ, the noise B and the observations Ψ. Assuming the noise B independent of the random function Φ, we can write , see Eq. (8).
In order to take into account the periodic temporal trend observed in the observations, we consider a non-first-order stationary model. Moreover, the mean is chosen not to be a function of the altitude in order to limit the number of parameters. Considering the time variations, we chose a periodic mean with one fundamental and two harmonics such that
where β0, β1, β2 and β3 are, respectively, the amplitude of the continuous component, the fundamental and the 2 harmonics, αi (with ) are the phase parameters of the fundamental and the harmonics and T is the period.
In order to further simplify we resort to the widely used separable model for the covariance (Genton, 2007) so that the spatiotemporal covariance factors into a purely spatial and a purely temporal component. This reduces the number of parameters allowing for computationally efficient estimation and inference, and it is then more tractable to run different tests on the dataset. Thus, the separable covariance model is written as
where rΦ is the variance of the quantity of interest. We chose an exponential covariance model for the time covariance
where lt is the correlation time. The choice of this covariance model is motivated by the shape of the empirical covariance described in the previous section (it decreases more rapidly than a Gaussian). The altitude covariance is set to be
where lz is the correlation length in altitude. We then use a white noise:
where rB is the variance of the noise. Finally, we have a model consisting of 12 parameters, including four parameters for covariance and eight parameters for the mean:
Using this notation we can denote the parametric model for the mean mΨ(δt;θ) and for the covariance . In the following section, we describe the strategy to estimate this set of parameters.
In this section, we present the strategy for the estimation of the model parameters θ. We choose the maximum a posteriori (hereafter abbreviated MAP) estimate for θ, which is the mode of the posterior probability density function (pdf) in Bayesian statistics. The analysis of the estimated parameters and corresponding model is deferred to Sect. 6 for the 1-dimensional case and Sect. 7 for the 2-dimensional case.
5.1 The MAP estimator
In the previous section, we proposed a parametric model for the mean mΨ(δt;θ) and for the covariance of the random variables Ψ, which decomposes into a model for the quantity of interest Φ and the noise B. The problem is to find an estimate of the true parameters θ⋆ from the observations ψ. We introduce the posterior pdf:
where f(ψ|θ) is the so-called likelihood function, which expresses the probability of the observations given the parameter θ, ρ(θ) is the prior distribution for the parameters θ and f(ψ) is the marginal pdf for the observations. Since we model the observations by a Gaussian pdf conditionally to the parameters θ (see Eq. 12), the likelihood function f(ψ|θ) is written as
where we have omitted the dependence in θ, δt and δz for RΨ and mΨ to weigh down the notations. Since the posterior pdf π(θ|ψ) is by definition positive, we consider the co-log posterior , which expands as follows:
where # stands for “equality up to an additive constant” (not function of θ). The minimum of Eq. (14) is the maximum of the posterior pdf. Thus, minimizing the CLP gives the MAP estimate. To complete, we consider a uniform prior ρ(θ) on a given domain Θ:
where Θ is a hyper-rectangle in ℝP describing a range of possible values for each component of θ. For our model P=12. Finally, we obtain
The function CLP is infinite when θ∉Θ because of the term −log 𝒰Θ(θ). The minimizer , given by
is the MAP estimate of the true parameter θ⋆.
5.2 Optimization procedure
An optimization procedure is required in order to determine the minimizer of the CLP. In this study, we use an iterative conditional mode strategy with a golden-section search (ICM-GS) for each component (Kiefer, 1953; Press et al., 1992). We then have an algorithm composed of an outer and an inner loop.
The inner loop optimizes with respect to one component at a time, say, θp, based on a golden-section search. It stops when the variation of θp is smaller than a given threshold, say, εp. The outer loop repeats the scan of the P components and stops when the variation of θ becomes smaller than a second given threshold denoted by η. The values εp and η have been fixed so as to reach stable results. The specific threshold values used in optimization procedure are reported in Table 1.
Table 1Threshold values ϵp used for each parameter and global threshold value η.
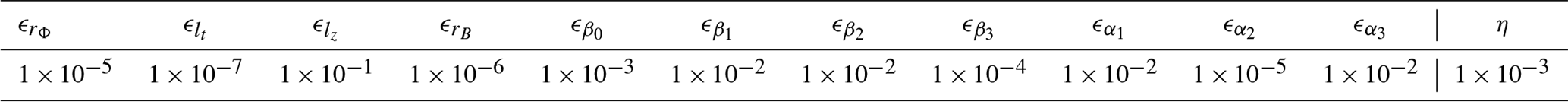
5.3 Kriging equation with and
The interpolation–prediction solution given the observations ψ is performed using the kriging estimator developed in Sect. 3. The kriging equations were initially developed assuming a known mean mΦ and covariance RΨ. In reality, we only have at hand the parametric mean and covariance that depend on the estimated parameter . Thus, the estimation of the quantity of interest Φ in t0 is written:
where is a vector of estimated mean at the positions of the observations. Finally, we can compute the minimum mean square error:
This last expression is equal to the variance of the estimation error, which we note . It gives an estimation of the forecast error associated with the kriging technique. However, it should be kept in mind that this variance does not account for the uncertainty in the model parameter estimate . Therefore, this expression tends to underestimate the true estimation variance. This feature has been well documented in Cressie (1993) and Montero et al. (2015). We leave the assessment of this impact for further development of this model. Note that the kriging stage is essentially a computational step that does not present any major difficulty except for the computational burden when dealing with large dimensions.
We start our analysis with the 1-dimensional case at a single altitude. We give a detailed analysis of the estimated parameters according to the MAP criterion and the ICM-GS algorithm, both described in the previous section. We concentrate on the estimation over the west of Europe and analyze the impact of reducing the considered geographic area. We then proceed to the kriging of observations in the interpolation and prediction case.
6.1 Estimation over a European area at a single altitude
In order to analyze the results of the previously described parameter estimation procedure, we first consider observations associated with altostratus clouds over a European area extending from 10∘ W to 10∘ E in longitude and 30 to 60∘ N in latitude (see Fig. 1) and use a subsampled database (at rate) at a single altitude of z≃6 km. This corresponds to a set of Nobs=3653 observations. The period parameter T has been readily set to 1 year so as to represent the seasonality observed in the data.
Figure 6 shows the evolution of CLP during the optimization process which, as expected, decreases with the iterations and stabilizes after ∼5 iterations. The current value of the parameters changes at each iteration and stabilizes as shown in Fig. 7.
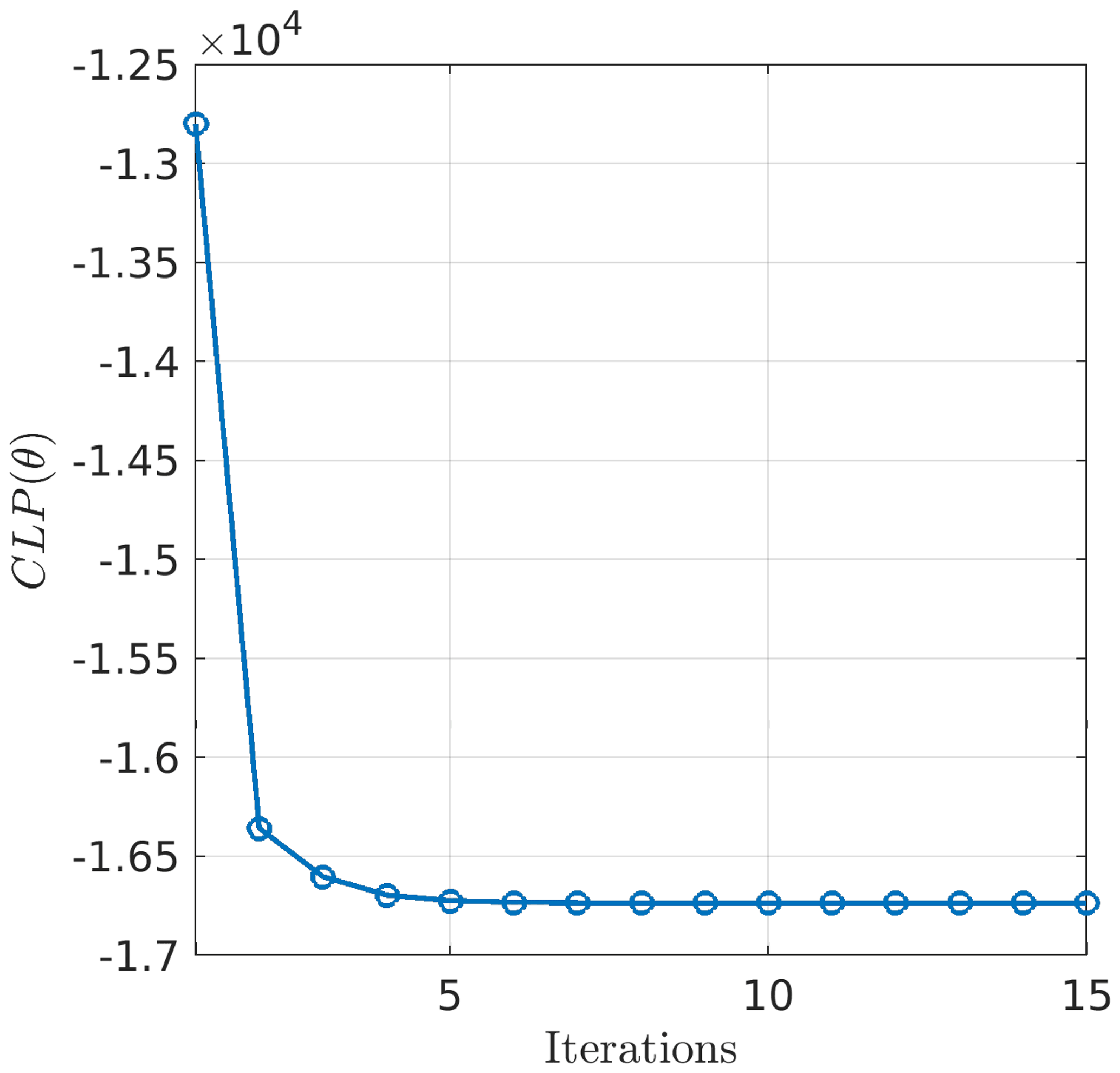
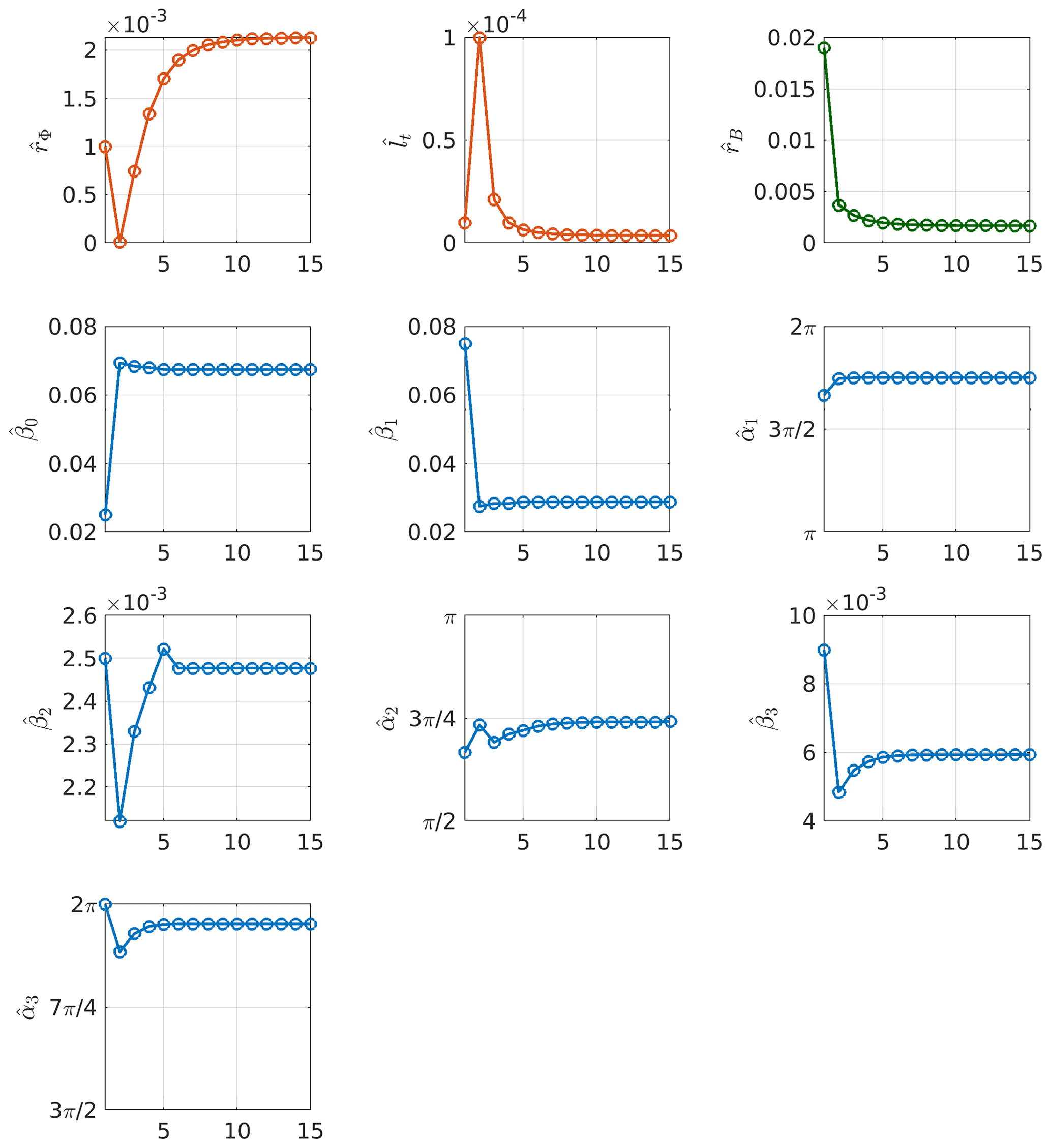
Figure 7Evolution of each parameter along the optimization process. The x axes represent the iteration index while the y axes represent the current value for each parameter. Parameters associated with the covariance of the quantity of interest are represented with red circles, parameters associated with the mean of the quantity of interest are represented with blue circles and the noise variance is represented with green circles.

Figure 8(a) Contour plot of CLP as a function of rΦ and lt. There is a global minimum characterized by , and a corresponding CLP and a local minimum characterized by , and CLP. (b) CLP as a function of rΦ while fixing all the other parameters to their initial values. This shows why the first two iterations of the optimization algorithm are moving away from the global minimum shown in the contour plot because the CLP is strictly monotonic inside the considered region.
Even though the decrease in CLP along the iterative optimization process indicates convergence toward a minimum, there is no guarantee that it is a global minimum. This is highlighted in Fig. 8a which represents the isocontour plot of CLP as a function of (rΦ,lt) while the other parameters are fixed to their estimated values. Additionally, we plot the current values of rΦ and lt at each iteration of the ICM-GS algorithm in Fig. 8a. In Fig. 8b we plot the CLP as a function of rΦ while fixing all the other parameters to their initial values to highlight the fact that the first two iterations of the optimization algorithm are moving away from the global minimum shown in the contour plot. The contour plot has been represented by varying values of rΦ and lt while setting the other parameters to their estimated value at the end of the optimization procedure so that it is not representative of the CLP at the initial states. It clearly shows a global and a local minimum. The global minimum is reached for . The estimated value corresponds to ∼2 min. This correlation time is very small compared to the 9-year period used to train the parameters. It indicates that there is essentially no correlation for observations later than 6 min apart. Indeed, the exponential covariance model reaches a 5 % correlation at about 3lt (Banerjee et al., 2014). This feature can be either explained by the model, the observations or the phenomenon itself. However, it is then evident that such a model will not be very efficient from the perspective of long-term forecasts.
As stated in Rasmussen and Williams (2005), each local minimum corresponds to a particular interpretation of the data, and a careful analysis may be required to choose one model instead of the other. In the next section, we will further discuss the presence of two minima of the CLP in relation to two competing models. An exhaustive search for all local minima requires computing the criterion CLP(θ) for all possible combinations of parameters in the domain Θ, which is impossible. Instead, we performed a set of 10 optimizations with random initialization to track down additional local minima and converged toward the same minimizer. Hence we conclude there is no other local minima than the one previously pointed out (cf. Fig. 8a).
6.2 Discussion on the reduction of the geographic area
In order to assess the influence of the considered geographic area, the optimization procedure is run by reducing the geographic extent of the dataset. We consider nine areas that are represented in Fig. 9, and the estimated parameters are summarized in Fig. 10.

Figure 9The nine geographic areas used for the parameter estimation analysis.
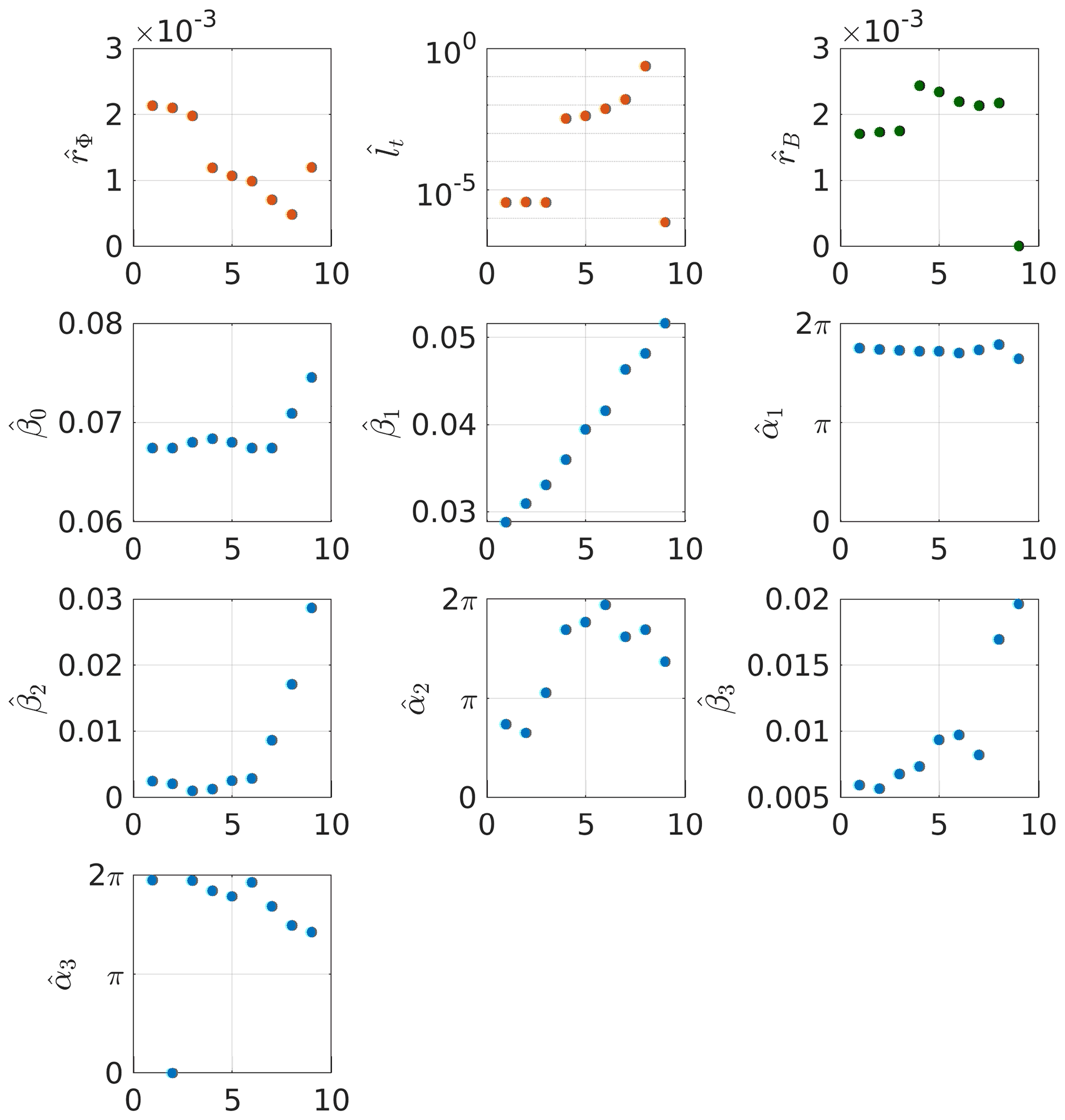
Figure 10Comparison of the estimated parameters for nine geographic areas. Parameters associated with the covariance of the quantity of interest are represented with red dots, parameters associated with the mean of the quantity of interest are represented with blue dots and the noise variance is represented with green dots.
The estimated values of the covariance parameters (i.e., , and ) vary in a complementary fashion, with approximately similar values for zones 1–3, a leap of several orders of magnitude for zones 4–8, followed by a drop for zone 9. These variations can be traced back to the presence of a local minimum in the domain Θ as shown in Fig. 11 where the variation of CLP−μCLP with respect to lt has been represented for each geographic area. All CLPs show the presence of local and global minima on the considered interval (except for the ninth area). The variations of CLP with respect to the correlation time lt have similar behavior for areas 1–3 with locations of the local and global minimum roughly identical. The same is valid for areas 4 and 5. Concerning areas 6–8 (cf. Fig. 11c), they have a more complex shape with a well-defined global minimum but less pronounced local minima at less correlation time.
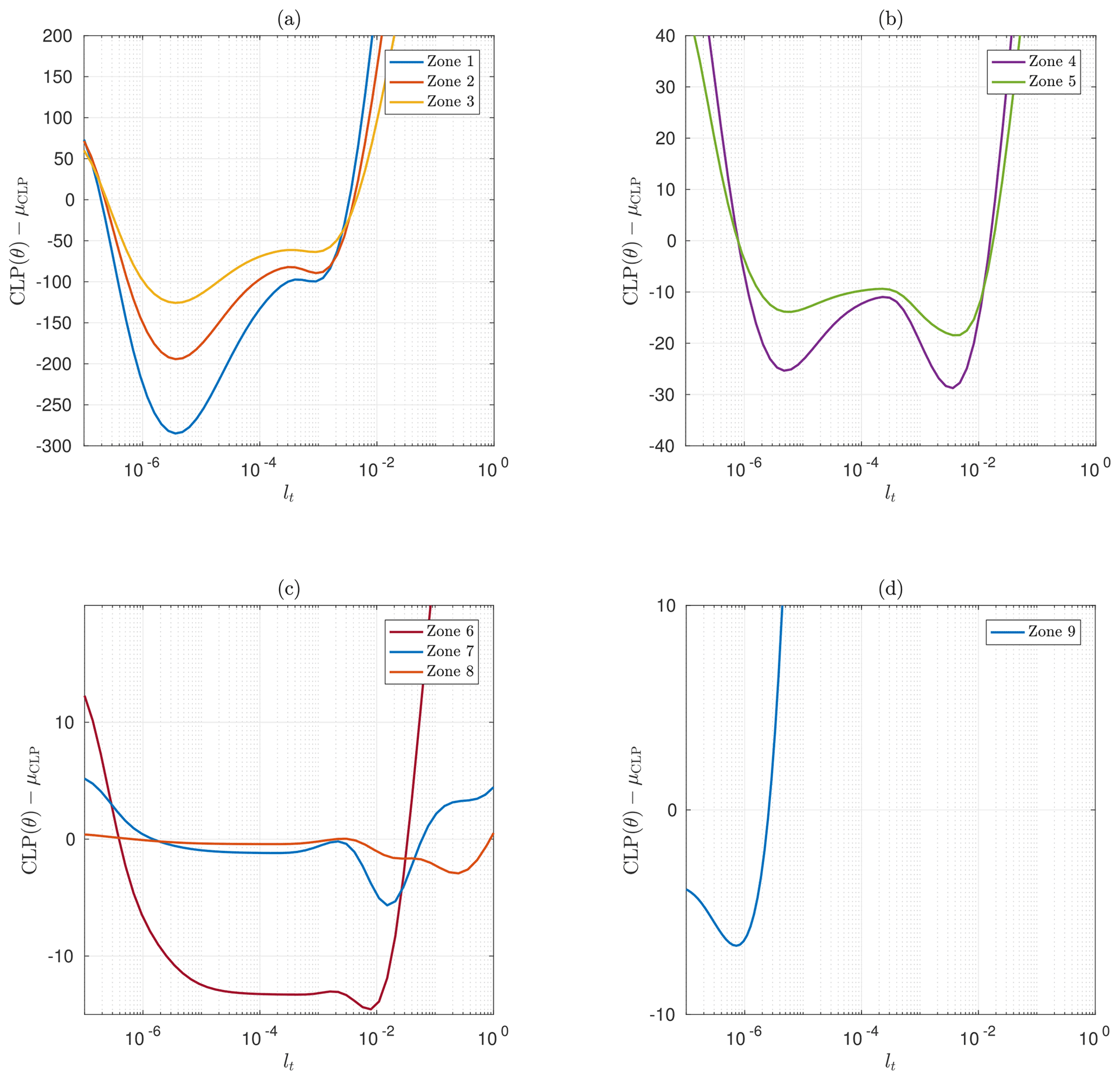
Figure 11(CLP−μCLP) as a function of the correlation time lt around for the geographic zones 1–3 (a), 4 and 5 (b), 6–8 (c) and 9 (d). The results for the nine geographic areas have been grouped into four sketches according to their similarities.
It is also worth highlighting the sliding of the global minimum to the local minimum when switching from zones 1, 2 and 3 to zones 4 and 5 (cf. Fig. 11a and b). The global minimum of zones 1, 2 and 3 is reached for a smaller correlation time year, which means that the aggregation of spatially distant observations is interpreted as a less correlated process than for smaller geographic area (i.e., zones 4 and 5). In this case, the retrieved model tends toward a white Gaussian noise as the covariance function is close to a Dirac function. However, the presence of a local minimum of CLP with a higher correlation time indicates that the observations could also be explained by a second model, providing some additional constraint on the correlation time (e.g., a different prior distribution for lt). In particular, we note that the order of magnitude of the lt values associated with this local minimum is similar to the lt values obtained for zones 4–7. When we reduce the geographic area, the set of observations tends to be more homogeneous, which is in favor of models with higher correlation times.
The result obtained for zone 9 has a different interpretation. The estimated correlation time is , which is several orders of magnitude smaller than every other geographic areas. This is in conjunction with a particularly low estimated noise variance (cf. Fig. 10c). For this geographic area, the estimated sticks to the minimum bound of the prior density so the optimization procedure is stuck for this parameter. Thus, the MAP estimator compensates for the remaining signal variance by increasing and decreasing the associated , so that ℛΦ tends toward a Dirac function, i.e., a covariance associated with white noise. In other words, the estimator is no longer able to separate the quantity of interest Φ from the noise with this dataset. To account for computational burden and stability of the estimated model, we will pursue our analysis with the dataset corresponding to the sixth geographic area.
6.3 Discussion on the 1-dimensional model
To conclude, it seems more interesting to carry on with geographic areas associated with higher correlation time, especially those obtained for zones 4–7 which corresponds to lt∼ 1–6 d, compared to lt∼2 min for zones 1–3. Considering the exponential covariance model reaches 5 % of its total variance at δt∼3lt (Banerjee et al., 2014), the latter tends toward its mean mΦ after ∼6 min. Note that the models corresponding to zones 4–7 are associated with variances rΦ lower than those obtained for zones 1–3 and a greater noise variance rB. However, the correlation time corresponding to zones 1–3 is very small that the corresponding covariance tends toward a diagonal matrix (i.e., a Dirac function).
6.4 Results in interpolation
We start with the interpolation of the LWC over the 9-year period. Note that, despite the regular sampling rate of the CPR, actual observations of altostratus in the European area are sparsely distributed. The temporal positions t0 at which kriging is applied are defined by , with N0=4001. The result of this kriging interpolation is represented in Fig. 12. The variability of the estimated is smaller than the actual variability of the observations, which is consistent with the estimated model parameters. Indeed, the estimated noise variance g2 cm−6 is greater than the estimated variance of the quantity of interest g2 cm−6. The periodic nature of the estimate is strong, especially when there are no observations (e.g., during the fifth year of operation of the satellite). In this case, the result of the kriging interpolation consists in the estimated mean . In the vicinity of observations, the kriging estimates take a more complex form because of the additional information brought by the neighboring data. The behavior observed over this period of 9 years is not surprising in itself because of the relative weakness of the observed correlation time, which is only d. We perform another kriging interpolation over a period of ∼36 d centered on the beginning of the satellite's third year of operation (cf. Fig. 13a). In this figure, we see that some observations are very close temporally and have significantly different values of LWC, which can explain the high estimated variance of the noise with respect to the variance of the quantity of interest. In this case, the kriging gives an average value of the observations. These observations generally correspond to successive profiles in the database, which are separated by 8 s. It should be noted that between two successive observations, the satellite moves ∼54 km, which can certainly explain a loss of spatial correlation not taken into account in our model. It is therefore likely that the model will explain this loss of spatial correlation by noise. On the other hand, we notice the presence of peaks in the structure of that can be explained by the structure of the chosen temporal covariance, which is in fact characterized by an exponential decay corresponding to the decay observed on the curve of when moving away from an observation (cf. Fig. 13a).
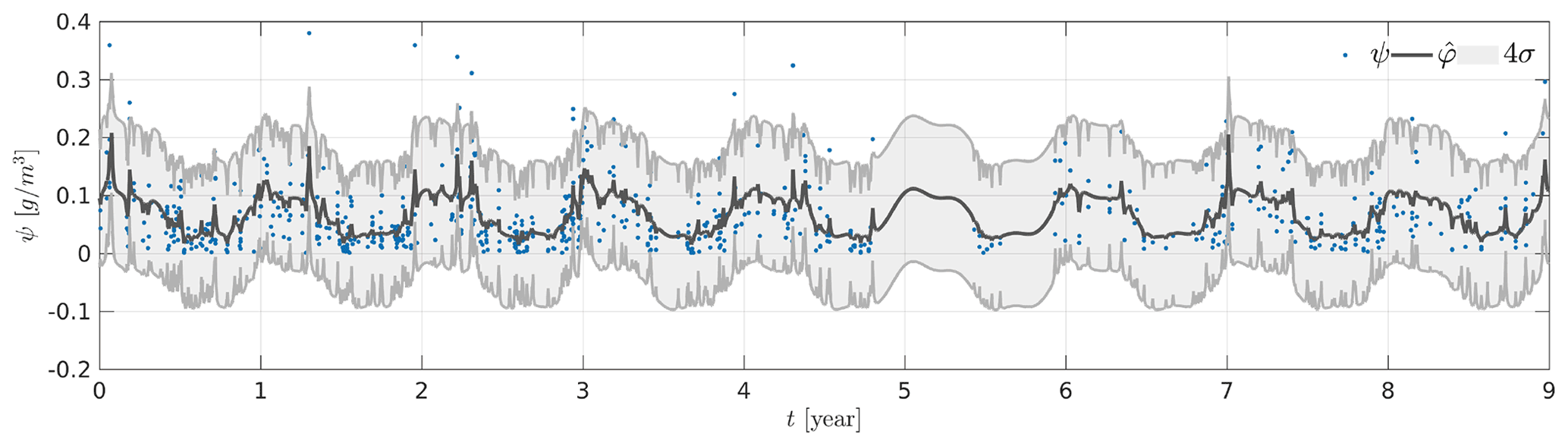
Figure 12Kriging-based interpolation over a 9-year period. The training set observations are represented as blue dots, the kriging estimate as a solid black line, and variance of the estimation error as shaded gray area.
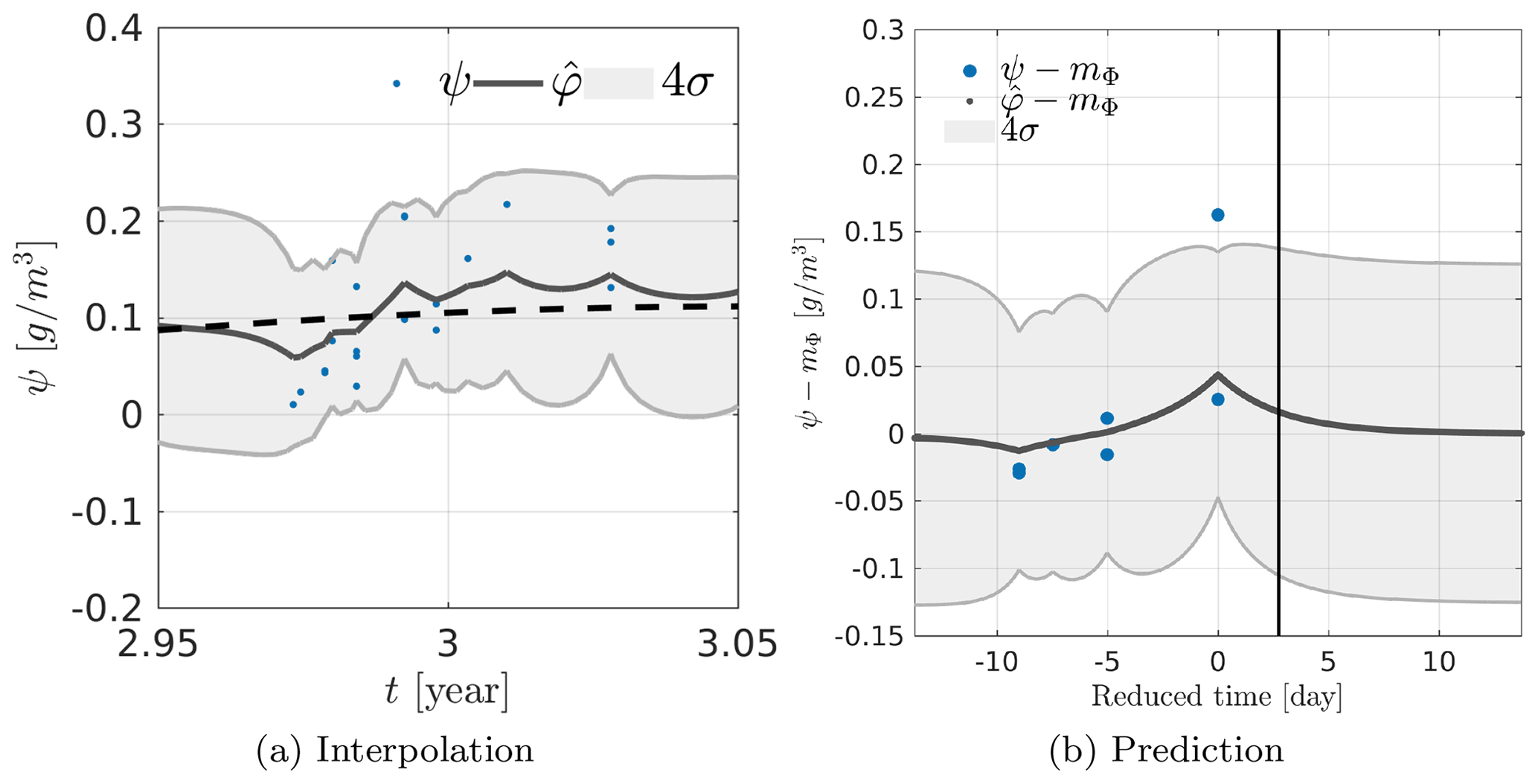
Figure 13(a) Kriging-based interpolation over a period of 36 d centered at the beginning of third year in the dataset. The mean is represented as a dashed black line. (b) Kriging-based prediction over a period of ∼36 d centered at the beginning of 3rd in the dataset. The vertical black line represents the correlation time lt after the last observation. In panels (a) and (b), the training set observations are represented as blue dots, the kriging estimate as a solid black line, and the variance of the estimation error as shaded gray area.
On all kriging results, we represent the 4σ area, where is the variance of the estimation error of Eq. (18). This variance is decomposed into two terms, the variance and a quadratic term in , which represents the covariance between the object of interest and the observations. At the observation location (i.e., Φ0 is chosen collocated with an observation), reaches its maximum value and so does the quadratic term . Consequently, at the observation location the minimum mean square error given in Eq. (18) is minimal.
6.5 Results in prediction
In order to study the results of kriging prediction, we selected a period that includes observations until a certain date and analyzed the behavior of the prediction beyond the last available observation (cf. Fig. 13b). In order to facilitate the interpretation, we subtracted the estimated mean from the observations ψ and the estimates and we centered the x axis on the last observation available. This clearly shows a decrease in the kriging result after the last observation toward 0, which indicates that the result tends toward the estimated mean. We plot the value of the correlation time lt as an indication. In the case of the exponential covariance, we get 5 % of the variance rΦ for a time ∼3lt, which corresponds to the time from which the kriging estimation tends toward the estimated mean. It is therefore a result consistent with the chosen covariance model and the estimated correlation time. This means that the prediction will be different from the average when an observation is available in a period of approximately 8.2 d (because lt≃2.7 d) before or after the position where the estimation is performed.
6.6 Error analysis
In this section, we interpret in more detail the kriging results through the analysis of the variance of the estimation error and the estimated noise. This is accomplished with a kriging estimation at temporal positions t0 collocated to the positions of the observed data (cf. Fig. 14a). Figure 14b represents the corresponding histograms for quantities and . Although the model used to describe the observed data is Gaussian, the histogram of the zero-mean quantity, , is not exactly Gaussian. It is actually skewed toward zero. However, its range of variation is smaller than the corresponding histogram for the observations, , which is an expected result as some of the observed variability is attributed to the presence of noise.
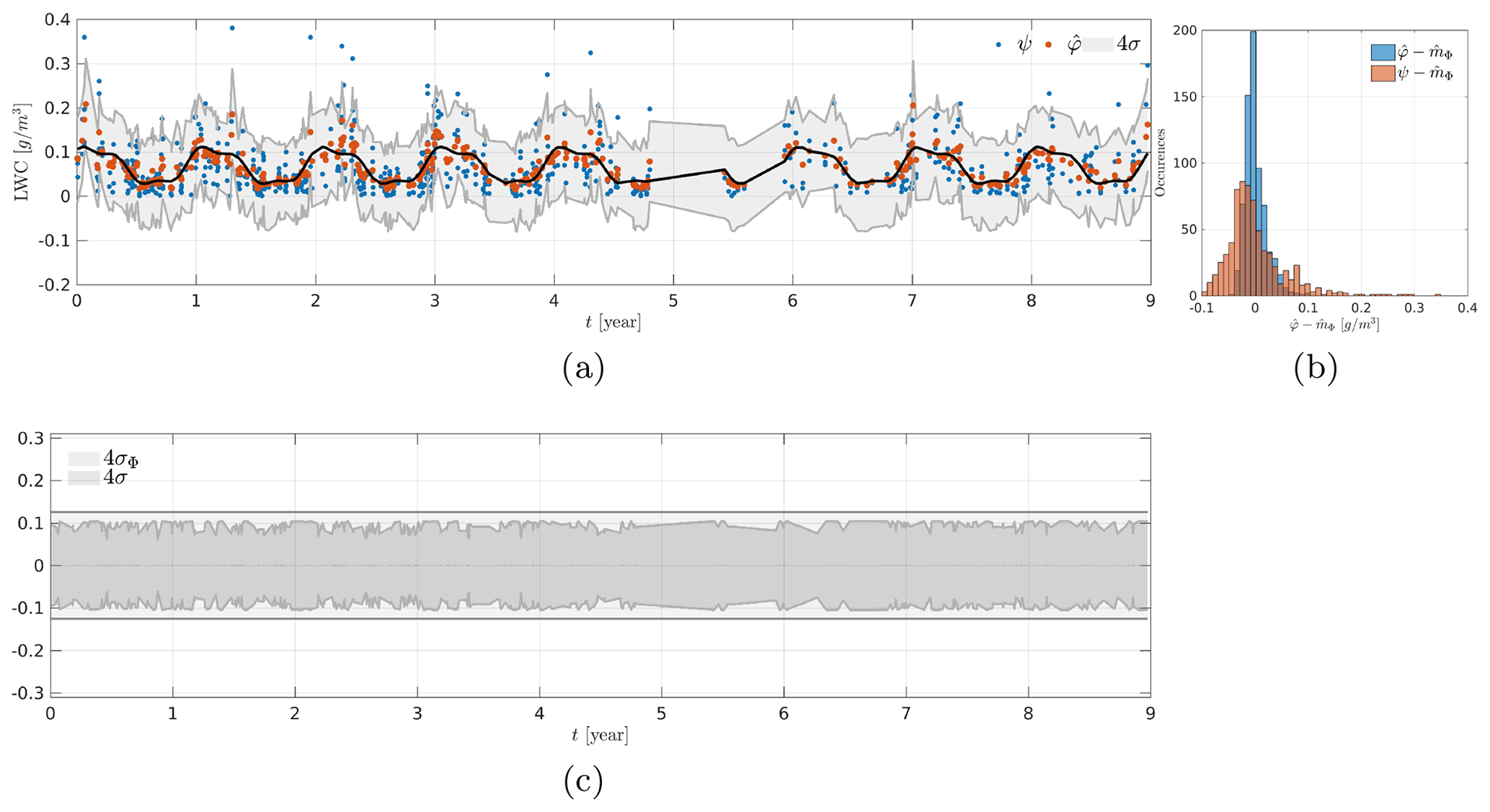
Figure 14Kriging results collocated to the observations. (a) Observations ψ (blue dots), estimate (red dots), estimated mean (solid black line) and variance of the estimation error (shaded gray). (b) Histograms of and . (c) Shaded gray area represents the variance of the estimation error and the variance of the quantity of interest Φ.
The variance of the estimation error gives an approximation of the variability around the estimated value . Note that it is impossible to compute exactly the difference , but we have estimated the variance of the noise knowing the observations, and it is then possible to compute the variance (cf. Sect. 3). This last variance term can be used to compute posterior realizations of the quantity of interest Φ. Figure 14c represents the variance var[Φ0] and the variance of the estimation error . The latter has a lower magnitude than var[Φ]0, which is consistent with Eq. (11) as the term is positive.
Finally, we computed the difference (cf. Fig. 15a). According to Eq. (2), this distribution must correspond to the noise distribution. We represented the normalized histogram of in Fig. 15b as well as the pdf of the noise . We observe that the two distributions have slightly different shapes but similar ranges of variation. The differences observed are mainly due to the fact that the parameters of a Gaussian model are estimated from observations that do not have a strictly Gaussian distribution. Indeed, we notice that the observations have an asymmetric distribution which extends toward higher values of LWC than the Gaussian distribution.

Figure 15(a) Differences (blue dots) superimposed on 4σB in shaded gray area, and (b) normalized histograms of and the pdf of .
In a similar fashion as in Sect. 6, we examine the 2-dimensional time–altitude case starting from the parameter estimation followed by the kriging results.
7.1 Parameter estimation
Here we consider the estimation of model parameters including the altitude dimension. Following the conclusions of the previous section, we use the observations of the sixth geographic area. However, for computational reasons, the training dataset is restricted to the first 3 years of observations, which consists of Nobs=4167 observations (cf. Fig. 17).
Figure 16 represents the evolution of each parameter during the optimization process. We observe that all parameters have stabilized toward an estimated value. Moreover, none of the parameters have converged toward the bound defined by the prior.
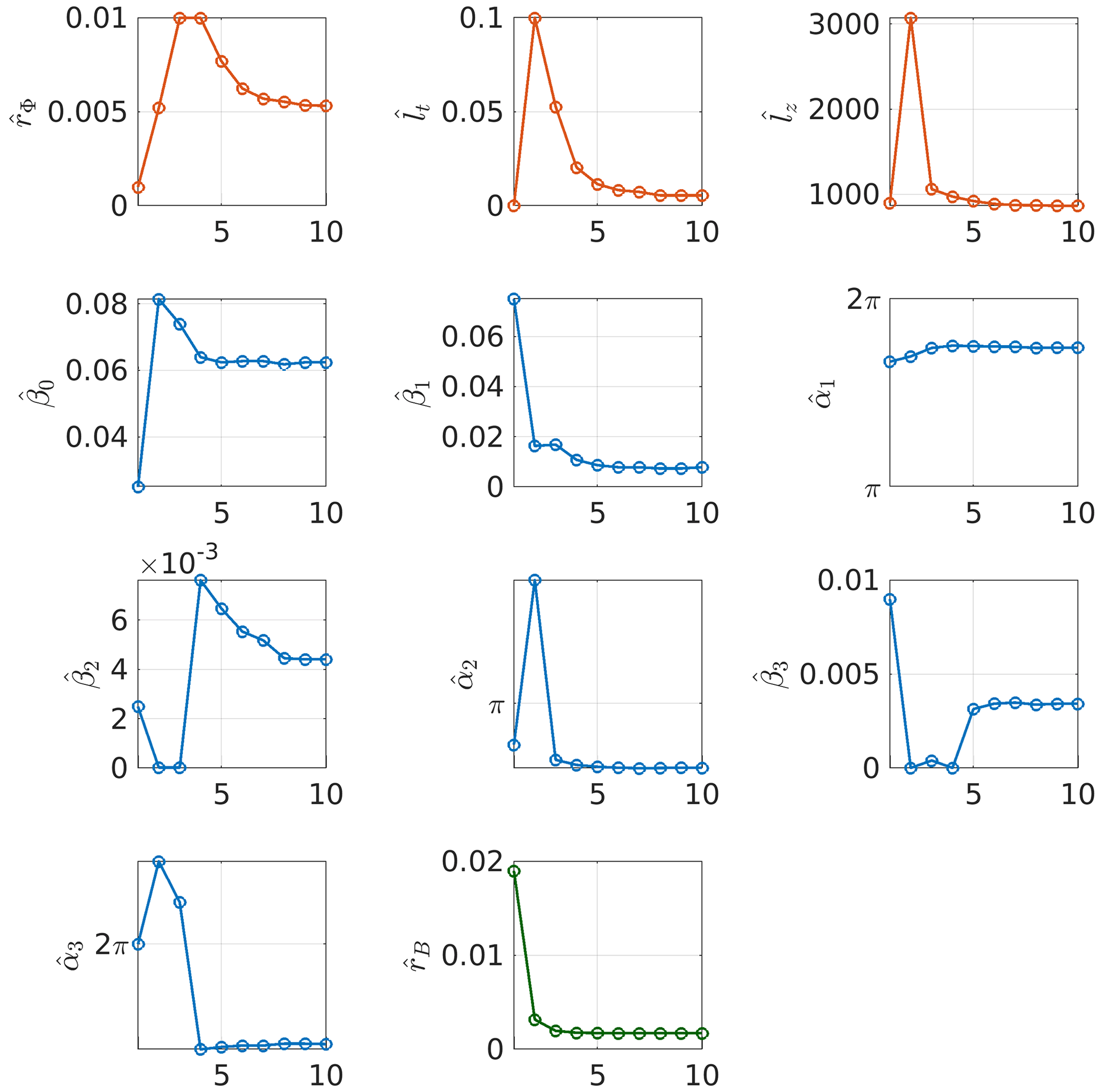
Figure 16Evolution of each parameter during the optimization process in 2-dimensional case (time–altitude). Parameters associated with the covariance of the quantity of interest are represented with red circles, parameters associated with the mean of the quantity of interest are represented with blue circles and the noise variance is represented with green circles.
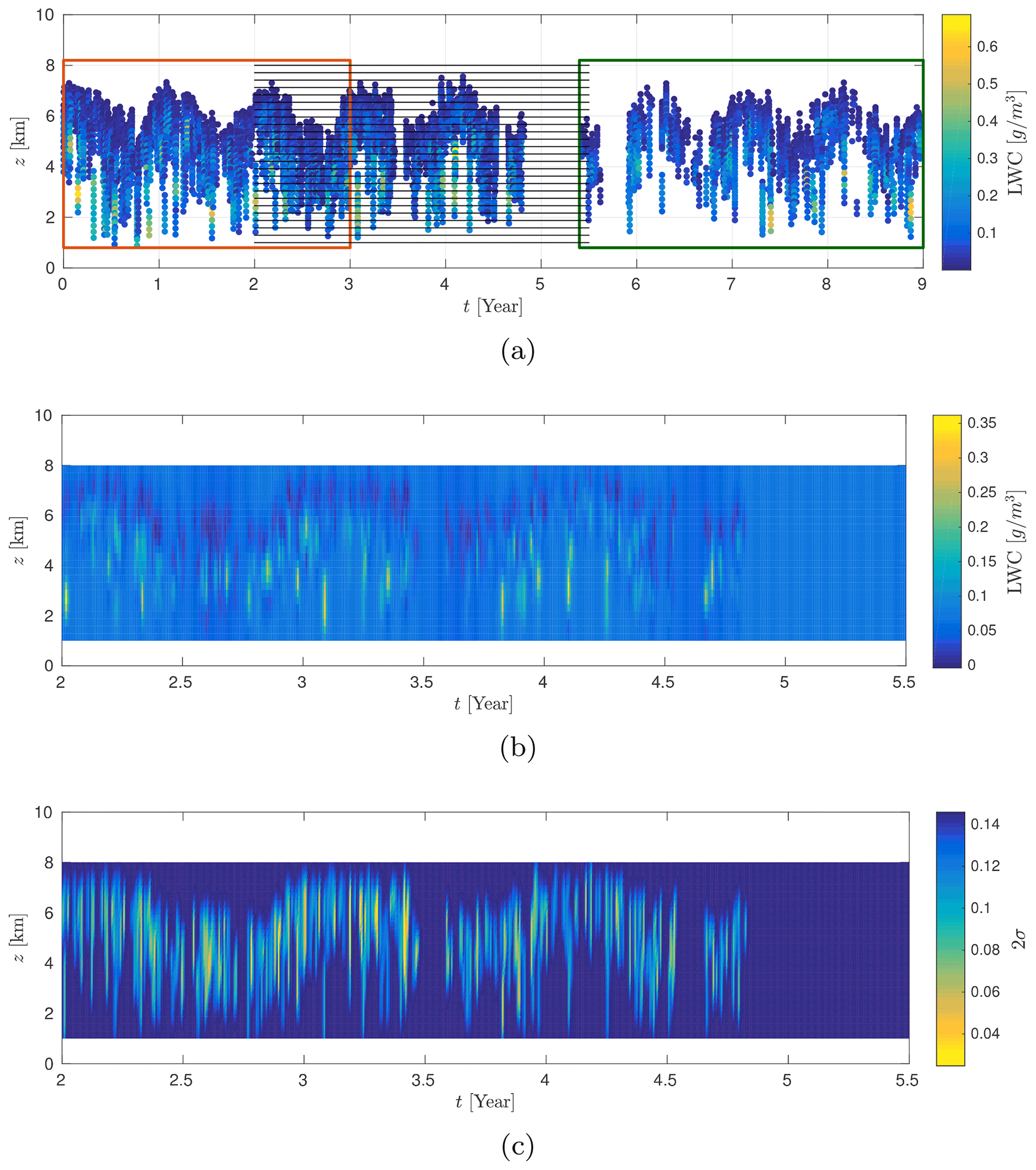
Figure 17CloudSat observations on geographic area 6. The red rectangle indicates the training dataset, the green rectangle indicates observations not used in the kriging estimate and the solid black lines represent the spatiotemporal positions where the kriging estimates are computed (a). Result of the 2-dimensional kriging on zone 6 (b) and its associated 2-dimensional variance of the estimation error (c).
The estimated values in the 1-dimensional (temporal) and 2-dimensional (time–altitude) cases are consistent from one model to the other (cf. Table 2). Overall, the order of magnitude for most quantities is close. However, we point out some noticeable differences:
-
There is a factor 10 between the estimated variance of the time model and the time–altitude model.
-
For the 1-dimensional case, whereas in the 2-dimensional case we have , which means that adding a dimension to the model helps to find some structure in the data that was missing otherwise.
-
The amplitudes and phases of the first and second harmonics (, , and ) differ substantially.
This last point explains the distinct mean behavior for the two models. The mean of the altitude–time model has a lower amplitude, which can be explained by the fact that the model must accommodate for a greater variability of observations due to an underlying altitude dependence of the dataset. It is an indication that future development should include this altitude dependence.
Table 2Comparison between estimated parameters for the 1-D and the 2-D model. Note that we have fixed T=1 in the optimization procedure.

7.2 Kriging results
In this section, we present the kriging results obtained for the time–altitude model. The parameters corresponding to this model have been estimated in Sect. 7.1. The kriging estimator is applied on a regular grid of 20×500 positions in time and altitude, this corresponds to a total of 10 000 positions. We take km and years. In addition, we excluded observations made after the fifth year. Therefore, we used a set of Nobs=6112 observations. Figure 17a outlines the situation we have just defined. The obtained kriging surface represented in Fig. 17b visually fits the observations from Fig. 17. Figure 17c represents the 2-dimensional map of the variance of the estimation error. We note that the variance of the estimation error is minimal when there are observations in the neighborhood, whereas it increases as we move away from the observations. This is an expected result that is consistent with what has been observed in the case of time kriging. Since the interpretation of kriging surfaces is complex, we represent these results at constant altitude (cf. Fig. 18). On constant height sections, the estimation structure seems more complex than in the 1-dimensional case; it can be explained by the interaction with observations at altitudes above and below the considered altitude. Moreover, we note that the model tends to the mean of the model when we move away from observations. This is especially true in the case of long-term predictions around the fifth year.

Figure 18Kriging results at constant altitudes, z≃2.17 km (a), z≃3.62 km (b), z≃5.08 km (c), z≃5.96 km (d). We represent the observations ψ (blue dots), the estimations (red dots), the mean (solid black line) as well as 2σ around the estimation .
The interpolation, in space, and prediction, in time, of the cloud microphysics in the medium and long term are of major importance in weather and climate analysis. Since a perfect estimation is obviously unattainable, it becomes an issue of uncertainty quantification. In this original work, we develop a statistical spatiotemporal kriging-based approach that is able to interpolate and predict from the dataset and provide uncertainties. Beforehand, it requires in particular estimating the covariance model parameters; it is performed in a Bayesian setting, which allows for estimation and uncertainty quantification. The approach is then applied to a subset of the CloudSat dataset, which shows promising results, especially in the 2-dimensional case where detailed structure appears in the quantity of interest. A natural extension to this approach would be to consider the latitude and longitude variables in order to interpolate horizontally the quantity of interest. Other extensions should consider the joint estimation of ice water content and LWC, the estimation of cloud types (cumulus, stratus, etc.) or some nonlinear functions of our actual quantity of interest (i.e., some parametric model that depends directly on LWC or ice water content such as optical properties). The treatment of these problems would require resorting to suitable kriging estimators (co-kriging, disjunctive kriging, etc.), or, more likely, some adapted versions of them. Finally, the impact of the parameter uncertainty in the kriging results could be rigorously handled by developing a complete Bayesian hierarchical model.
The level 2B-CWC-RO CloudSat data used in this study have been downloaded from the CloudSat Data Processing Center (http://www.cloudsat.cira.colostate.edu/, CloudSat Data Processing Center, 2022).
PM and JFG designed the preliminary study, with continuous discussions from all co-authors along the project. JML developed the model code and performed the simulations. JML prepared the manuscript with contributions from all co-authors.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors would like to thank Audrey Giremus for her contribution to the preliminary step of the work and the two anonymous reviewers for their suggestions and comments.
This paper was edited by S. Joseph Munchak and reviewed by two anonymous referees.
Austin, R. T., Heymsfield, A. J., and Stephens, G. L.: Retrieval of ice cloud microphysical parameters using the CloudSat millimeter-wave radar and temperature, J. Geophys. Res., 114, D00A23, https://doi.org/10.1029/2008JD010049, 2009. a
Banerjee, S., Carlin, B., and Gelfand, A.: Hierarchical Modeling and Analysis for Spatial Data, Second Edition, Chapman & Hall/CRC Monographs on Statistics & Applied Probability, Taylor & Francis, https://doi.org/10.1201/b17115, 2014. a, b, c
Belo-Pereira, M., Dutra, E., and Viterbo, P.: Evaluation of global precipitation data sets over the Iberian Peninsula, J. Geophys. Res., 116, D20101, https://doi.org/10.1029/2010JD015481, 2011. a
Bodas-Salcedo, A., Webb, M., Brooks, M., Ringer, M., Williams, K., Milton, S., and Wilson, D.: Evaluating cloud systems in the Met Office global forecast model using simulated CloudSat radar reflectivities, J. Geophys. Res., 113, D00A13, https://doi.org/10.1029/2007JD009620, 2008. a
Brockwell, P. J. and Davis, R. A.: Time Series: Theory and Methods, Springer Series in Statistics, Springer New York, https://doi.org/10.1007/978-1-4419-0320-4, 2009. a
Chen, W.-T., Woods, C. P., Li, J.-L. F., Waliser, D. E., Chern, J.-D., Tao, W.-K., Jiang, J. H., and Tompkins, A. M.: Partitioning CloudSat ice water content for comparison with upper tropospheric ice in global atmospheric models, J. Geophys. Res., 116, D19206, https://doi.org/10.1029/2010JD015179, 2011. a
Chiles, J.-P. and Delfiner, P.: Geostatistics: modeling spatial uncertainty, Wiley, New York, ISBN: 978-0-470-18315-1, 1999. a, b
Chonavel, T. and Ormrod, J.: Statistical Signal Processing: Modelling and Estimation, Advanced Textbooks in Control and Signal Processing, Springer London, https://doi.org/10.1007/978-1-4471-0139-0, 2002. a
CloudSat Data Processing Center: level 2B-CWC-RO CloudSat data, CloudSat [data set], http://www.cloudsat.cira.colostate.edu/, last access: 8 June 2022. a
Cressie, N.: Statistics for spatial data, Wiley series in probability and mathematical statistics: Applied probability and statistics, J. Wiley, https://doi.org/10.1002/9781119115151, 1993. a, b, c, d
Cressie, N. and Wikle, C.: Statistics for Spatio-Temporal Data, Wiley, ISBN: 978-0-471-69274-4, 2015. a
der Meer, F. V.: Remote-sensing image analysis and geostatistics, Int. J. Remote Sens., 33, 5644–5676, https://doi.org/10.1080/01431161.2012.666363, 2012. a
Didari, S. and Zand-Parsa, S.: Enhancing estimation accuracy of daily maximum, minimum, and mean air temperature using spatio-temporal ground-based and remote-sensing data in southern Iran, Int. J. Remote Sens., 39, 6316–6339, https://doi.org/10.1080/01431161.2018.1460500, 2018. a, b
Diggle, P. J., Ribeiro, P. J., and Christensen, O. F.: An Introduction to Model-Based Geostatistics, Springer New York, New York, NY, https://doi.org/10.1007/978-0-387-21811-3_2, 2003. a
Eriksson, P., Ekström, M., Rydberg, B., Wu, D. L., Austin, R. T., and Murtagh, D. P.: Comparison between early Odin-SMR, Aura MLS and CloudSat retrievals of cloud ice mass in the upper tropical troposphere, Atmos. Chem. Phys., 8, 1937–1948, https://doi.org/10.5194/acp-8-1937-2008, 2008. a
Florio, E. N., Lele, S. R., Chang, Y. C., Sterner, R., and Glass, G. E.: Integrating AVHRR satellite data and NOAA ground observations to predict surface air temperature: a statistical approach, Int. J. Remote Sens., 25, 2979–2994, https://doi.org/10.1080/01431160310001624593, 2004. a
Gaetan, C. and Guyon, X.: Modélisation et statistique spatiales, Mathématiques et Applications, Springer Berlin Heidelberg, ISBN: 978-0-471-69274-4, 2008. a
Genton, M. G.: Separable approximations of space-time covariance matrices, Environmetrics, 18, 681–695, https://doi.org/10.1002/env.854, 2007. a
Heuvelink, G., Griffith, D., Hengl, T., and Melles, S.: Sampling Design Optimization for Space-Time Kriging, in: Spatio-Temporal Design: Advances in Efficient Data Acquisition, edited by: Mateu, J. and Müller, W. G., John Wiley & Sons, Ltd, 207–230, https://doi.org/10.1002/9781118441862.ch9, 2012. a
Jewell, S. and Gaussiat, N.: An Assessment of Kriging Based Rain-Gauge-Radar Merging Techniques, Q. J. Roy. Meteor. Soc., 141, 2300–2313, https://doi.org/10.1002/qj.2522, 2015. a
Khan, M. S., Grabner, M., Muhammad, S. S., Awan, M. S., Leitgeb, E., Kvicera, V., and Nebuloni, R.: Empirical Relations for Optical Attenuation Prediction from Liquid Water Content of Fog, Radioengineering, 21, 911–916, 2012. a
Kiefer, J.: Sequential minimax search for a maximum, P. Am. Math. Soc., 4, 502–506, 1953. a
Krige, D.: A statistical approach to some basic mine valuation problems on the Witwatersrand, J. S. Afr. I. Min. Metall., 52, 119–139, https://doi.org/10.10520/AJA0038223X_4792, 1951. a
Lyras, N. K., Kourogiorgas, C. I., and Panagopoulos, A. D.: Cloud attenuation statistics prediction from Ka-band to optical frequencies: Integrated liquid water content field synthesizer, IEEE T. Antenn. Propag., 65, 319–328, 2016. a
Marshak, A. and Davis, A.: 3D Radiative Transfer in Cloudy Atmospheres, Physics of Earth and Space Environments, Springer Berlin Heidelberg, https://doi.org/10.1007/3-540-28519-9, 2005. a
Matheron, G.: Principles of geostatistics, Econ. Geol., 58, 1246–1266, https://doi.org/10.2113/gsecongeo.58.8.1246, 1963. a
Montero, J.-M., Fernández-Avilés, G., and Mateu, J.: Spatial and Spatio-Temporal Geostatistical Modeling and Kriging, Wiley Series in Probability and Statistics, Wiley, ISBN: 978-1-118-41318-0, 2015. a, b, c
Nour, M., Smit, D., and Gamal El-Din, M.: Geostatistical mapping of precipitation: implications for rain gauge network design, Water Sci. Technol., 53, 101–110, https://doi.org/10.2166/wst.2006.303, 2006. a
Park, N.-W.: Time-Series Mapping of PM10 Concentration Using Multi-Gaussian Space-Time Kriging: A Case Study in the Seoul Metropolitan Area, Korea, Adv. Meteorol., 2016, 1–10, 2016. a
Press, W. H., Teukolsky, S. A., Vetterling, W. T., and Flannery, B. P.: Numerical Recipes in C, 2nd edn., The Art of Scientific Computing, Cambridge University Press, New York, NY, USA, ISBN: 978-0521431088, 1992. a
Qu, Z., Barker, H. W., Korolev, A. V., Milbrandt, J. A., Heckman, I., Bélair, S., Leroyer, S., Vaillancourt, P. A., Wolde, M., Schwarzenböck, A., Leroy, D., Strapp, J. W., Cole, J. N. S., Nguyen, L., and Heidinger, A.: Evaluation of a high-resolution numerical weather prediction model's simulated clouds using observations from CloudSat, GOES-13 and in situ aircraft, Q. J. Roy. Meteorol. Soc., 144, 1681–1694, 2018. a
Rasmussen, C. E. and Williams, C. K. I.: Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning), The MIT Press, ISBN: 978-0262182539, 2005. a, b
Ripley, B. D.: Spatial statistics, Wiley New York, https://doi.org/10.1002/0471725218, 1981. a
Stephens, G. L. and Kummerow, C. D.: The Remote Sensing of Clouds and Precipitation from Space: A Review, J. Atmos. Sci., 64, 3742–3765, 2007. a
Stephens, G. L., Vane, D. G., Boain, R. J., Mace, G. G., Sassen, K., Wang, Z., Illingworth, A. J., O'Connor, E. J., Rossow, W. B., Durden, S. L., Miller, S. D., Austin, R. T., Benedetti, A., Mitrescu, C., and the CloudSat Science Team: The CloudSat mission and the A-Train: A new dimension of space-based observations of clouds and precipitation, B. Am. Meteorol. Soc., 83, 1771–1790, https://doi.org/10.1175/BAMS-83-12-1771, 2002. a
Varouchakis, E. A., Kamińska-Chuchmala, A., Kowalik, G., Spanoudaki, K., and Graña, M.: Combining Geostatistics and Remote Sensing Data to Improve Spatiotemporal Analysis of Precipitation, Sensors, 21, 3132, https://doi.org/10.3390/s21093132, 2021. a
Verdin, A., Funk, C., Rajagopalan, B., and Kleiber, W.: Kriging and Local Polynomial Methods for Blending Satellite-Derived and Gauge Precipitation Estimates to Support Hydrologic Early Warning Systems, IEEE T. Geosci. Remote, 54, 2552–2562, https://doi.org/10.1109/TGRS.2015.2502956, 2016. a
Vivekanandan, J., Zhang, G., and Politovich, M.: An assessment of droplet size and liquid water content derived from dual-wavelength radar measurements to the application of aircraft icing detection, J. Atmos. Ocean. Tech., 18, 1787–1798, 2001. a
Wackernagel, H.: Multivariate Geostatistics: An Introduction with Applications, Springer Berlin Heidelberg, ISBN: 978-3662052945, 2013. a
Wu, D. L., Austin, R. T., Deng, M., Durden, S. L., Heymsfield, A. J., Jiang, J. H., Lambert, A., Li, J.-L., Livesey, N. J., McFarquhar, G. M., Pittman, J. V., Stephens, G. L., Tanelli, S., Vane, D. G., and Waliser, D. E.: Comparisons of global cloud ice from MLS, CloudSat, and correlative data sets, J. Geophys. Res., 114, D00A24, https://doi.org/10.1029/2008JD009946, 2009. a
Yang, S. and Zou, X.: Assessments of cloud liquid water contributions to GPS radio occultation refractivity using measurements from COSMIC and CloudSat, J. Geophys. Res., 117, D06219, https://doi.org/10.1029/2011JD016452, 2012. a
Zakeri, F. and Mariethoz, G.: A review of geostatistical simulation models applied to satellite remote sensing: Methods and applications, Remote Sens. Environ., 259, 112381, https://doi.org/10.1016/j.rse.2021.112381, 2021. a
- Abstract
- Introduction
- Data and mathematical description
- The kriging estimator
- Construction of a model for the mean and the covariance
- Model parameter estimation, optimization and final kriging equations
- The 1-dimensional time case
- The 2-dimensional time–altitude case
- Conclusion and perspectives
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References
- Abstract
- Introduction
- Data and mathematical description
- The kriging estimator
- Construction of a model for the mean and the covariance
- Model parameter estimation, optimization and final kriging equations
- The 1-dimensional time case
- The 2-dimensional time–altitude case
- Conclusion and perspectives
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References