the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 12 Sep 2025
| 12 Sep 2025
CLEAR: a new discrete multiplicative random cascade model for disaggregating path-integrated rainfall estimates from commercial microwave links
Marc Schleiss
A novel disaggregation algorithm for commercial microwave links (CMLs), named CLEAR (CML Segments with Equal Amounts of Rain), is proposed. CLEAR utilizes a multiplicative random cascade generator to control the splitting of link segments, with the generator's standard deviation dependent on the rain rate and segment length. Spatial consistency during the splitting process is maintained using rain rate information from neighboring CMLs. CLEAR is evaluated on a network of 77 CMLs in Prague. The performance is assessed first using simulated rainfall fields and second through a case study with real attenuation data from the network to demonstrate its applicability in real-world scenarios. Results from the virtual rainfall fields indicate good overall performance, including the generation of realistic spatial patterns and effective estimation of maximal and minimal rain rates along CML paths. The stochastic nature of CLEAR allows it to represent uncertainty as an ensemble of rain rate distributions along CML paths. However, the generated ensembles significantly underestimate overall variability along the paths. Additionally, the case study on real data highlights challenges associated with uncertainties in CML quantitative precipitation estimates, which are common across all methods. In conclusion, CLEAR contributes to generating more representative rainfall distributions along CMLs, which is critical for spatial reconstruction of rainfall fields from path-integrated CML data. It also has the potential to reduce errors in CML quantitative precipitation estimates caused by assuming uniform rain rates along CML paths.
- Article
(8027 KB) - Full-text XML
- BibTeX
- EndNote




Commercial microwave links (CMLs) are point-to-point radio connections in cellular networks. They typically operate at frequencies in the order of 10–90 GHz (Chwala and Kunstmann, 2019; Fencl et al., 2020) where electromagnetic waves are known to be attenuated by raindrops. This attenuation can be measured and used to provide path-averaged rainfall estimates (Leijnse et al., 2007; Messer et al., 2006).
CMLs are an appealing source of opportunistic rainfall measurements. According to Ericsson (2019), there are about 5 million CMLs worldwide, including sparsely gauged regions and developing countries. The large coverage, high density in urban areas, and low costs of operation are clear advantages over traditional rain gauge and radar networks. However, the path-integrated nature of CML data also poses some challenges. For example, if one wishes to retrieve spatially representative rainfall estimates (e.g., 2D maps), the path-integrated data from the CMLs first need to be transformed to point data and interpolated to a regular two-dimensional Cartesian grid. The most straightforward way to obtain such a map is to reduce each CML observation into a single-point measurement located at the center of the CML path and subsequently interpolate these point data using kriging or inverse distance weighted (IDW) interpolation (Graf et al., 2020; Overeem et al., 2013). Unfortunately, previous research has shown that due to the large spatial and temporal variability of rain, such an approach can lead to large biases and unrealistic rainfall distributions, especially for longer CMLs of several kilometers in length and during heavy, localized rain showers.
Over time, several alternative solutions to the rainfall reconstruction problem from CML data have been proposed. Tomographic reconstruction methods (Cuccoli et al., 2013; Giuli et al., 1991; Zinevich et al., 2008) offer the advantage of directly handling path-averaged rainfall data. Another approach, random mixing, achieves this by conditioning random fields with a spatial dependence structure modelled by copulas (Haese et al., 2017). However, in both cases optimal performance requires a model of the underlying rainfall field, which is often unavailable. Following a different approach, Goldshtein et al. (2009) suggested an iterative reconstruction algorithm based on IDW interpolation where each CML is represented by a set of equally spaced points. The distribution of the rainfall rates along the control points is then iteratively estimated from observations of neighboring CMLs, until some kind of convergence is reached. Both tomographic and iterative IDW algorithms are computationally efficient, with decent performances for slowly varying rainfall fields and a more or less regular network of CMLs. However, their performance strongly depends on CML topology (e.g., link density, lengths, frequencies and orientations) and rainfall variability. So far, no convincing solution has been proposed to address the issue of rainfall intermittency (i.e., the fact that it may not rain over the entire CML), which is a big problem for longer CMLs and during heavy, localized rain showers. In those cases, both tomographic and IDW-based algorithms are likely to predict highly unrealistic spatial structures and distributions with large outliers and uncertainties.
This paper addresses this issue by proposing a novel disaggregation technique based on random cascades named CLEAR (CML segments with equal amounts of rain). CLEAR redistributes rainfall amounts along CML paths over smaller and smaller scales by means of a discrete, conservative multiplicative random cascade. The approach is inspired by the EVA (Equal-volume area) cascade by Schleiss (2020) for disaggregating spatially intermittent rainfall fields. During the CLEAR cascade, each CML segment is split into two new segments of different path-lengths but identical path-integrated rainfall. Random cascades have been extensively used to downscale time series and spatial fields of rain (Molnar and Burlando, 2005). However, to our knowledge, this is the first time that the formalism is applied to path-averaged data from CMLs. Because CLEAR inherits the main features of the EVA cascade model, it should be well suited to reproduce the highly variable rainfall distributions seen along CMLs, including its intermittency. Furthermore, the stochastic nature of the cascade makes it possible to quantify the uncertainty related to the spatial redistribution of rainfall rates along CMLs.
As with any random cascade model, the performance of CLEAR strongly depends on the characteristics of the underlying cascade generator model. Hence, different ways to model and estimate the generator model based on high-resolution virtual rainfall fields are proposed and discussed. In addition to the simulation experiments, we also report on the results obtained for a case study in Prague (CZ), which we use to highlight the strengths and weaknesses of CLEAR compared with other approaches. For simplicity, the scope is limited to the methodological development of CLEAR and its evaluation on selected studies while other important issues related to the spatial interpolation and final reconstruction of 2D rainfall fields from CML data are ignored. Broader validation using larger and more diverse rainfall and CML datasets as well as additional comparisons to other disaggregation algorithms is also beyond the scope of this paper.
The rest of this paper is structured as follows: The Sect. 2 describes the rainfall and CML data used in this study, Sect. 3 describes the algorithm and explains how its performance is evaluated. Section 4 compares the results obtained with CLEAR to the benchmark by Goldshtein et al. (2009) and discusses the strengths and weaknesses of the algorithm on selected cases studies. Finally, the results and limitations of the algorithm are critically reviewed and contextualized in the discussion and conclusion sections.
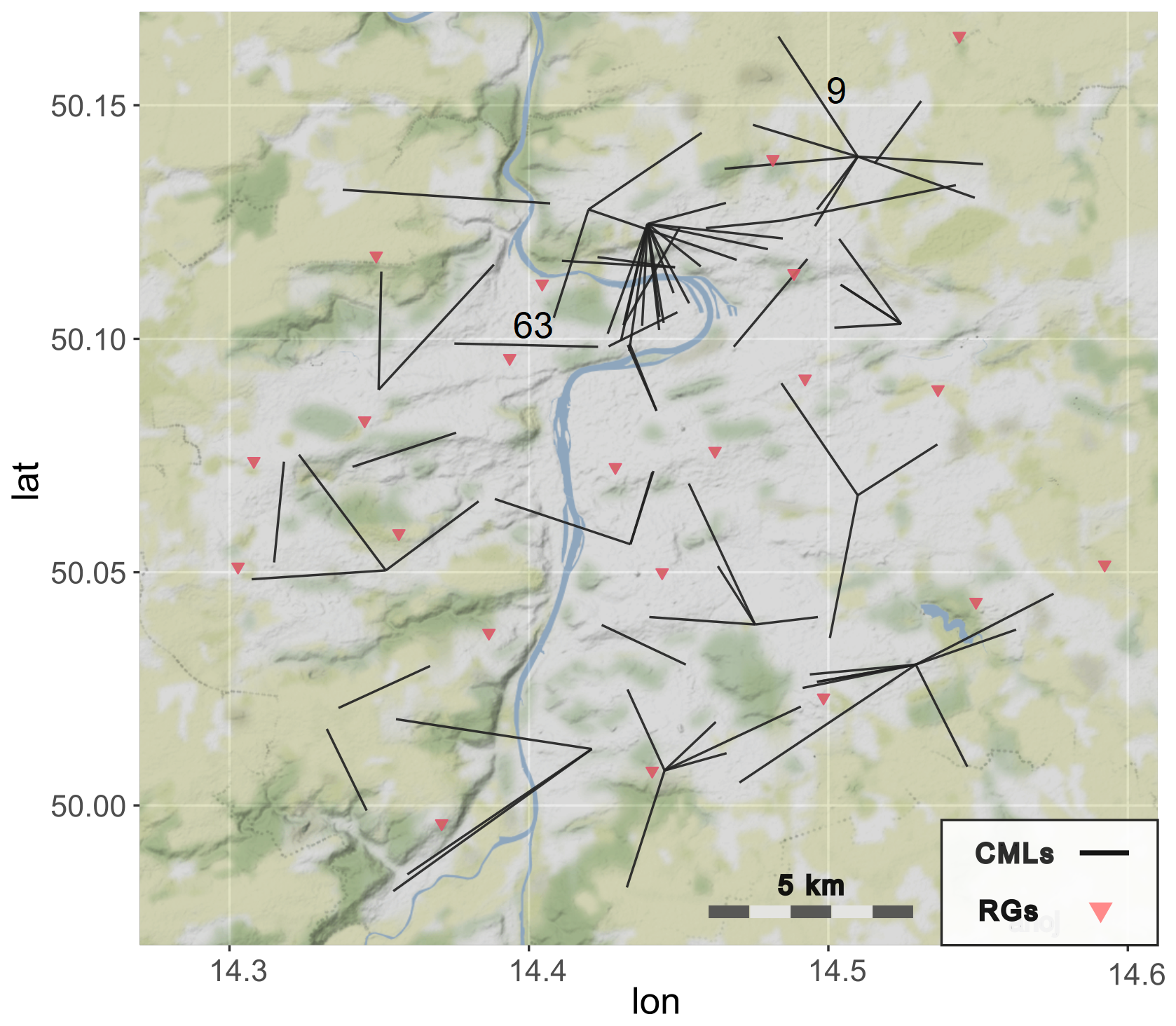
Figure 1Map of CMLs in Prague used for the analysis, together with the rain gauges used for bias-correcting weather radar rainfall estimates over the area. CML 9 and 63 are highlighted as examples discussed in the Result section. © OpenStreetMap contributors 2023. Distributed under the Open Data Commons Open Database License (ODbL) v1.0.
CLEAR is tested on a real-world topology of 77 CMLs forming a telecommunication backhaul operated by T-Mobile, CZ in Prague (Fig. 1). First, simulated rainfall fields are used to derive rain rates along a CML path. Second, real attenuation data from the same set of 77 CMLs are used as a case study to illustrate the strengths and weaknesses of the approach in real-world applications. All essential data and codes underlying this publication are openly available on 4TU Research data (Fencl and Schleiss, 2025).
2.1 Simulated rainfall fields
Virtual rainfall fields for three events with varying intensities, durations and spatial variability were generated following the method proposed by Schleiss et al. (2012). In this method, fields of drop size distribution (DSD) are generated using a geostatistical method known as sequential Gaussian (or indicator) simulation. The DSD at each location is modelled using a Gamma distribution with stochastic parameters μ (shape) and Nt (drop concentration). The scale parameter Λ is derived from μ using a deterministic relationship. The simulation involves transforming the DSD parameters into Gaussian variables via anamorphosis, modelling their space-time structure with variograms, and generating fields using sequential indicator and Gaussian simulations. After simulation, the fields are back-transformed to their original scale and rainfall intensities are calculated based on the DSD. The simulation parameters were inferred from disdrometer time series and 2D radar rainfall data in the vicinity of Lausanne, Switzerland. The synthetic rainfall fields cover an area of 20×20 km2 with a spatial resolution of 100×100 m2. They are advected and evolved over time and are “realistic” in the sense that they reproduce the distribution and spatio-temporal autocovariance structure of observed rainfall fields, which makes them useful for testing rainfall estimation and retrieval algorithms.
Table 1Characteristics of the virtual rainfall events. The metrics are calculated for a whole domain for each time step.

2.2 Virtual CML data
To calibrate the cascade generator, 6000 randomly placed CMLs of various lengths between 0.5 and 6 km and orientations were simulated. The virtual rainfall fields from Sect. 2.1 were then used to calculate the theoretical path-averaged rain rates along each of the CMLs. Similarly, the virtual CML data can be used to study the spatial distribution of rainfall rates along different CML segments, which can be used to parameterize the cascade generator and compare the performances of the different disaggregation methods.
2.3 CML and radar data for the case study
The CML dataset used in the case study was acquired from Ericsson MINILINK CMLs during the month of September 2014 by an SNMP based application running at T-Mobile network operation centre. The data consist of CML transmit and received signal power levels with the quantization of 1/3 dB recorded at approximately 10 s intervals. The selected CMLs operate at frequencies between 23 and 38 GHz, and only those longer than 1.5 km were included in the analysis, resulting in a total of 77 CMLs. Note that six CMLs experienced outages during this day, which means that only 71 out of the 77 CMLs were used. The 1.5 km length threshold was chosen to align with the 1 km2 resolution of the weather radar reference used in the case study. Additionally, shorter CMLs can be affected by large errors related to wet antenna attenuation and quantization effects, making them less suitable for rainfall retrieval (Blettner et al., 2023).
In addition to the 77 CMLs, we also considered bias-adjusted C-band weather radar rainfall estimates provided by the Czech Meteorological Institute. The latter are used as a reference when validating the results for the case study. Specifically, we used the gridded product from the lowest elevation layer (Cappi2000) which has a spatial resolution of 1×1 km2 and a temporal resolution of 5 min. The rainfall estimates were adjusted using the mean field bias correction method in wradlib, an Open Source Library for Weather Radar Data Processing (Heistermann et al., 2013). Note that the mean field bias was estimated using 23 tipping bucket rain gauges of type MR3, METEOSERVIS v.o.s. (operated by the city of Prague), with a catch area of 500 cm2 and a tip resolution of 0.1 mm. The performance of the radar adjustment has been evaluated by cross-validation against the rain gauges during the summer season (April to October) of 2024. While the adjusted rain rates are on average only slightly underestimated (rel. error ), the root mean square error remains relatively high (RMSE =3.5 mm h−1). The Pearson's correlation coefficient between adjusted-radar and the rain-gauge rain rates is 0.65. The full radar dataset is used in a supporting analysis to investigate different formulations of the standard deviation model in the CLEAR cascade generator. For illustration purposes, the performance of CLEAR is evaluated on real CML data during single heavy-rainfall event that begun on 21 September 2014 at 19:00 UTC, and lasted approximately two hours. The average rainfall depth over the area was 18 mm and the light rainfall rates after 21:00 UTC (approx. 0.5 mm h−1) were not included in the evaluation because the rain rate was too low to be reliably detected by the CMLs.
3.1 Rainfall estimation from commercial microwave links
The basic quantity needed to estimate rainfall from CMLs is the total loss (Lt) in power between the transmitted and received signals. The total loss consists of various components, including free space loss, losses in the medium (e.g. gaseous attenuation and raindrop attenuation), losses at transmission and reception, and antenna gains. Before the rainfall rate can be estimated, different types of signal processing techniques need to be applied to identify and separate the rainfall-related specific attenuation k (dB km−1) from other sources of attenuation. We write:
where l (km) is the length of the CML path, B (dB) is the baseline attenuation (i.e., all losses that are not due to rain) and Aw (dB) the wet antenna attenuation due to water on the antenna radomes. For an overview of different baseline and wet antenna attenuation estimation techniques, the reader is referred to Chwala and Kunstmann (2019); Pastorek et al. (2022a). Once the specific rainfall-induced attenuation has been retrieved, a power-law model can be used to estimate the path-averaged rainfall rate R (mm h−1) along the link (Atlas and Ulbrich, 1977):
where α (mm h−1 dB−β kmβ) and β (–) are empirical parameters dependent on CML frequency, polarization, and raindrop size distribution (ITU-R, 2005).
For the case study, the original 10 s CML attenuation data were averaged over 5 min to match the temporal resolution of the weather radar data. The averaged CML attenuation data were then processed with a standard baseline and wet antenna identification methodology (see e.g. Chwala and Kunstmann, 2019). More specifically, the rainfall-induced attenuation along each CML was calculated by subtracting a constant baseline attenuation equal to the median of the total losses during September 2014. The wet antenna attenuation correction is a modified version of the Kharadly model (Kharadly and Ross, 2001) proposed by Pastorek et al. (2022b) with a single set of model parameters for all the CMLs. The parameters of the wet antenna model were optimized by minimizing the average squared difference between the path-averaged rain rates from the CMLs and the reference path-averaged rain rates obtained from gauge-adjusted weather radar. Rainfall-related path attenuation is converted to rain-rate using a standard power law model (2) with ITU parameters (ITU-R, 2005).
3.2 The CLEAR algorithm
The CLEAR algorithm redistributes the path-integrated rainfall amount along a CML over smaller and smaller scales by means of discrete multiplicative random cascade. At each cascade level the CML segments are split into two smaller segments of variable lengths, containing half of the original rainfall amount (mm h−1 km). The ratio between the parent length L0 (km) and resulting segment lengths L1 (km) and L2 (km) is determined by drawing random weights W from a cascade generator model with logit normal probability distribution:
where μ is the mean and σ the standard deviation of an underlying Gaussian random variable. The mean μ is forced to zero, to ensure W is centered around 0.5. The path-averaged rain rates R1 (mm h−1) and R2 (mm h−1) along the two split segments satisfy the following relations:
where R0 (mm h−1) is the path-averaged rain rate of the parent CML segment and W1 and are the random cascade weights.
The splitting can be controlled by changing the standard deviation of the generator (3). For small standard deviation values, the random weights tend to be closer to 0.5, which leads to a more homogeneous redistribution of the rainfall rates along the path of the link. For larger values of standard deviation, the weights cluster around 0 and 1, which translates into more uneven splits and more intermittency (Schleiss, 2020).
During the splitting process, a spatial coherence (SC) rule inspired by Schleiss (2020) is applied to determine which link segment receives the shortest length and, therefore, the highest rainfall intensity along its path. According to this rule, the smaller of the two weights (W1, W2) is always assigned to the link segment experiencing the highest rainfall rate in its vicinity, based on neighboring segments that have already been split. This approach works under the assumption that all CML segments are split only once at the first cascade level before progressing to the next level.
To estimate the rainfall rate in the vicinity, the SC rule involves an intermediate step: a partial spatial reconstruction of the rainfall field over a regular Cartesian grid. For further details on this process, readers are referred to Appendix A.
The splitting process concludes when the rainfall amount along a CML segment falls below a predefined threshold. CML segments with very small rainfall amounts are no longer split but continue to be considered when applying the SC rule to the remaining CML segments. In this analysis, the threshold is set to 1 mm h−1 km, which corresponds approximately to the attenuation of dB by the 23–38 GHz CMLs, i.e. the value matching the quantization of CMLs employed in the case study. The cascade terminates when all CML segments have stopped splitting or when a fixed number of cascade levels (nine in our case) has been reached. Since the cascade weights are drawn at random, the CLEAR algorithm produces a different output each time it is run. By comparing the different realizations to each other, one can quantify the uncertainty (in point rainfall estimates) due to the random redistribution of the rainfall rates along the CMLs. For more technical details of the CLEAR implementation, readers are referred to scripts published along with the dataset (Fencl and Schleiss, 2025).
3.3 Sample estimation of the cascade generator model
Similarly to the original EVA cascade in Schleiss (2020), the standard deviation (SD) of the cascade generator is assumed to depend on the length L0 (km) of the parent CML segment and rain rate R0 (mm h−1) according to the following power-law model:
where, a (km−b mm−c hc), b (–), and c (–) are empirical parameters that need to be estimated from the data or prescribed by the user.
There are two ways to estimate the cascade generator model: (1) using real data, and (2) using simulated rainfall fields. The first approach is purely data-driven. Given a set of CMLs with varying lengths, orientations, and path-integrated rainfall intensities, the key question is: how should a CML be split to ensure that the resulting segments have the same path-integrated rainfall attenuation (or, equivalently, the same total rainfall amount)? The answer depends on many factors such as the link's length, position, orientation, and the characteristics of the rainfall field. This is why multiple CMLs and rainfall fields are needed to estimate a robust, climatological cascade generator.
However, estimating empirical cascade weights using real CML networks and gridded weather radar data has drawbacks. Radar products often lack the spatial resolution needed to accurately capture rainfall variability along CMLs, particularly for shorter links. Additionally, results may be highly specific to the particular CML network or characteristics of rainfall field, such as spatial anisotropy, especially if not all the possible link lengths and orientations are equally represented in the network. Furthermore, measurement noise in both radar and CML data complicates the estimation process, making it challenging to obtain precise estimates of empirical cascade weights. The simulation approach addresses these issues. By using large synthetic CML networks with diverse lengths and orientations, along with high-resolution simulated rainfall fields that realistically represent the local climatology, one can more accurately estimate the empirical cascade generator model.
For an arbitrary CML of length l and rainfall field R(x), the empirical breakdown coefficients w can be calculated by splitting the CML such that:
Simulated rainfall fields have much higher spatial resolutions than radar. Nevertheless, there will always be some discretization level, which means that in practice, the integral in Eq. (6) has to be replaced by a cumulative sum. The exact position of the breakpoint W is thus determined by linear interpolation (Fig. 2). The breakdown coefficients W are then transformed using the left-hand side of Eq. (3) to follow Gaussian distribution and grouped according to the path lengths and path-averaged rain rates of the parent links that generated them. The sample SD is then calculated for each group which allows us to empirically relate SD with rain-rate and path-length (Fig. 3, left). In the final step, the SD model (5) is then optimized to fit empirically estimated SD values (Fig. 3, middle, right). The optimal parameters for our case are a=0.65, b=0.33, and 8. With these parameters, the SD values tend to be high for very low rain rates and/or long CML, leading to a high probability of unequal splits. Conversely, at higher rain rates and for shorter CMLs, the splits are more likely to be even. More details on how to calculate the sample SD and fit the SD model are given in Appendix B.
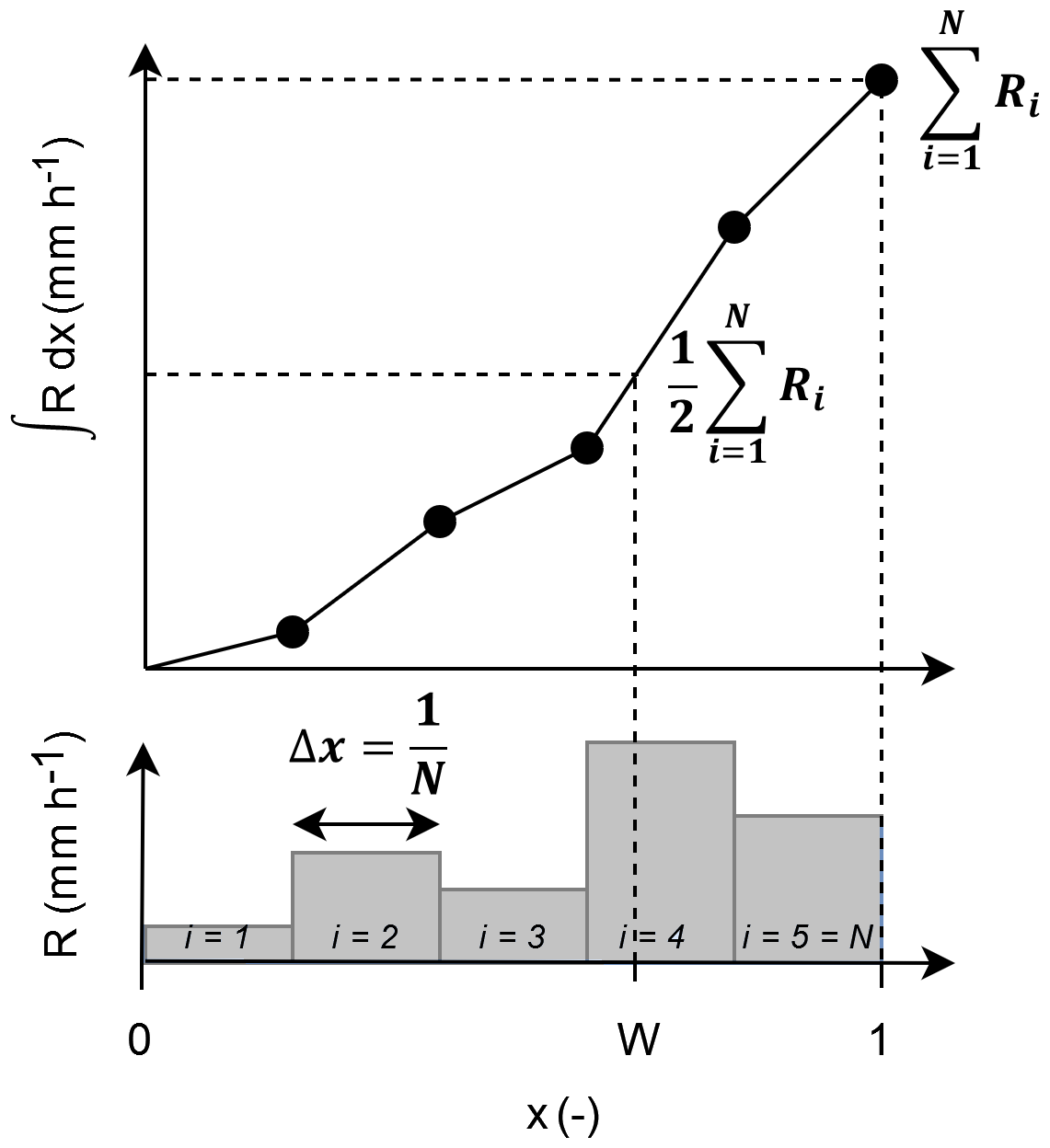
Figure 2Empirical breakdown coefficient determined by a cumulative sum of rain rates along a CML path using linear interpolation.
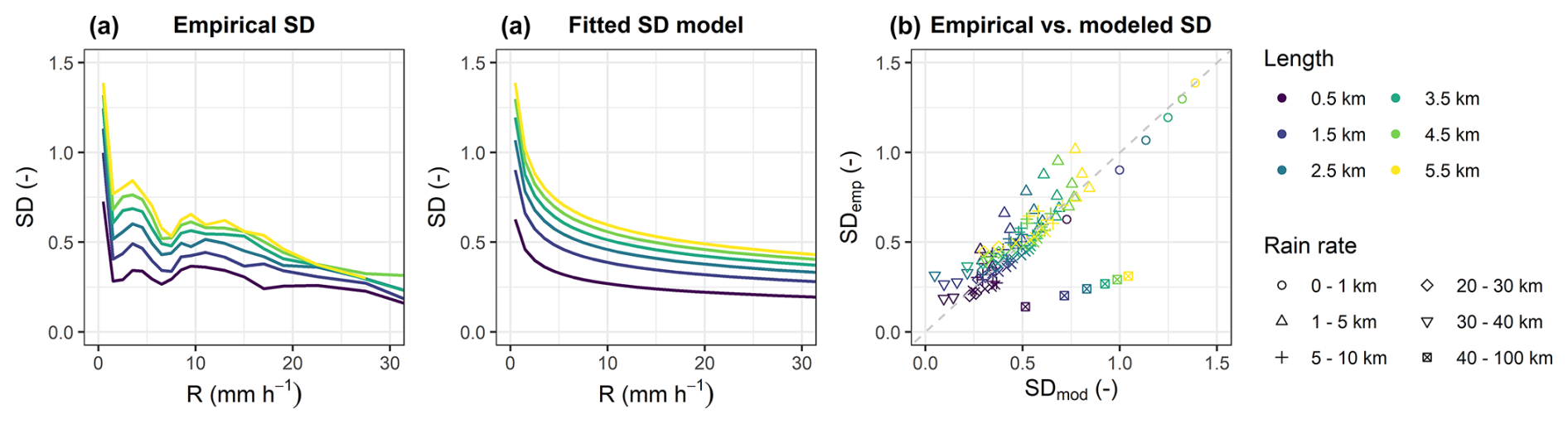
Figure 3(a) Standard deviation calculated for all samples larger than 50 members. (b) Fitted SD model. (c) Comparison of empirical and modeled standard deviations with rain rates indicated by point shapes. Path lengths of parent CMLs are distinguished by color.
3.4 Benchmarking and performance evaluation
Path-averaged rain rates without disaggregation are used as a zero benchmark algorithm. The disaggregation procedure implemented in the Goldshtein-Messer-Zinevich (GMZ) algorithm (Goldshtein et al., 2009) is used as a more complex benchmark: Each CML is divided into segments of equal length such that the length is close to some predefined threshold (100 m in our case) but does not exceed it. This threshold is the same for all the CMLs in the domain and determines the final resolution of the disaggregation. The resulting CML segments have lengths between 94 and 100 m. Initial path-averaged rain rates are iteratively redistributed along CML segments to match rain rates interpolated from neighboring CMLs with inverse-distance-weighted mean.
The performance of CLEAR is assessed in detail using synthetic experiments with virtual rainfall fields (described in Sect. 2.1). High-resolution rainfall fields placed over the network of CMLs enables us to extract reference distributed rain rates and path-averaged rain rates along the path of each CML. Path-averaged rain rates are in each time step disaggregated with CLEAR algorithm and compared to the reference rainfall. Furthermore, the disaggregation performance is benchmarked against the GMZ algorithm. To enable benchmarking, the reference and CLEAR-disaggregated rain rates are resampled using weighted average to match the segments defined by the GMZ algorithm. In the case study with real data, reference and CLEAR-disaggregated rain rates are resampled in the same manner, except that the maximal segment length in the GMZ algorithm is set to 1 km to match the resolution of the reference weather radar product.
Three different features of disaggregation algorithms are evaluated:
-
The ability to reproduce rainfall patterns and extremes along a CML path is evaluated by quantifying the standard deviation of rain rates, their maxima, and their minima along each CML path during each time step. In addition, we quantify the variance conditional to rain rate and CML length.
-
The distribution and location of disaggregated rain rates along the CMLs compared to the reference.
-
An ensemble of CLEAR rain rates (50 runs) is generated and evaluated in terms of its variance.
R-squared (R2), root mean square error (RMSE), and relative error (RE) are used as performance metrics in the first and second analysis. Containing ratio (CR) and average band width (ABW) are used as performance metrics in the third analysis. CR is defined as the ratio of observations lying within confidence bands defined by 5 % a 95 % quantile of the whole ensemble and ABW as an average difference between 5 % a 95 % quantile of the whole ensemble.
CR and ABW is evaluated for different classes of rain rate and CML length. The same classes are used when quantifying conditional variance in the first analysis. Five equidistant CML length classes are defined covering lengths between 1–6 km. Rain rate classes are defined by non-equidistant binning along the range of rain rates available in the dataset (0–52 mm h−1): Rain rates 0–10 mm h−1 are binned by 1 mm h−1, binning by 2 mm h−1 is applied up to rain rate of 20 mm h−1, binning by 5 up to 30 mm h−1, and final two classes are 30–40 and 40–52 mm h−1. The relatively large size of bins for high rain rates reflects their low number in the dataset.
The results in the following four subsections (Sect. 4.1–4.4) are obtained from the experiment with simulated rainfall fields. Section 4.5 presents results from the case study with real CML observations. The spatial resolution of disaggregated and reference rain rates is 100 m for the experiments with simulated rainfall fields and 1 km for the case study.
4.1 Features of CLEAR disaggregation
Figure 4 shows two examples of rainfall rates disaggregated with the CLEAR algorithm. In the first case (Fig. 4, left), CLEAR nicely reproduces the actual distribution of rain rates along the CML. The location of the min/max values are estimated correctly, the estimated ensemble mean is moderately correlated with the reference rain rates (r=0.55), and the variance over the ensemble members nicely captures the overall variability of the rainfall rate along the link (i.e., 89 % of the reference observations lie within the 90 % confidence bands). Moreover, the ensemble spread tends to increase with growing rain rates (r=0.51), reflecting higher uncertainty due to disaggregation during heavy rainfall. In the second case (Fig. 4, right), while the overall variability in rainfall rates along the link is accurately captured, the locations of the predicted minima and maxima are incorrect, and the 90 % confidence bands do not align with the actual observations. This highlights an important point: in CLEAR, the position of peak rainfall intensity along a CML is heavily influenced by the spatial distribution of rainfall in the surrounding area. When no nearby CMLs are available, the spatial consistency rule relies almost entirely on smooth spatial interpolation of the rainfall field at coarser levels (see Appendix A). As a result, for isolated CMLs, CLEAR tends to systematically assign peak rainfall intensity to the same side of the link.
The better performance observed for CML 63 can likely be attributed to the presence of nearby CMLs, which provide valuable information to the spatial consistency rule and significantly influence the splitting process and the location of the peak intensity. In contrast, CML 9 is near the border of the domain, with only one end point having independent CML observations in its vicinity, which limits the accuracy of the prediction.
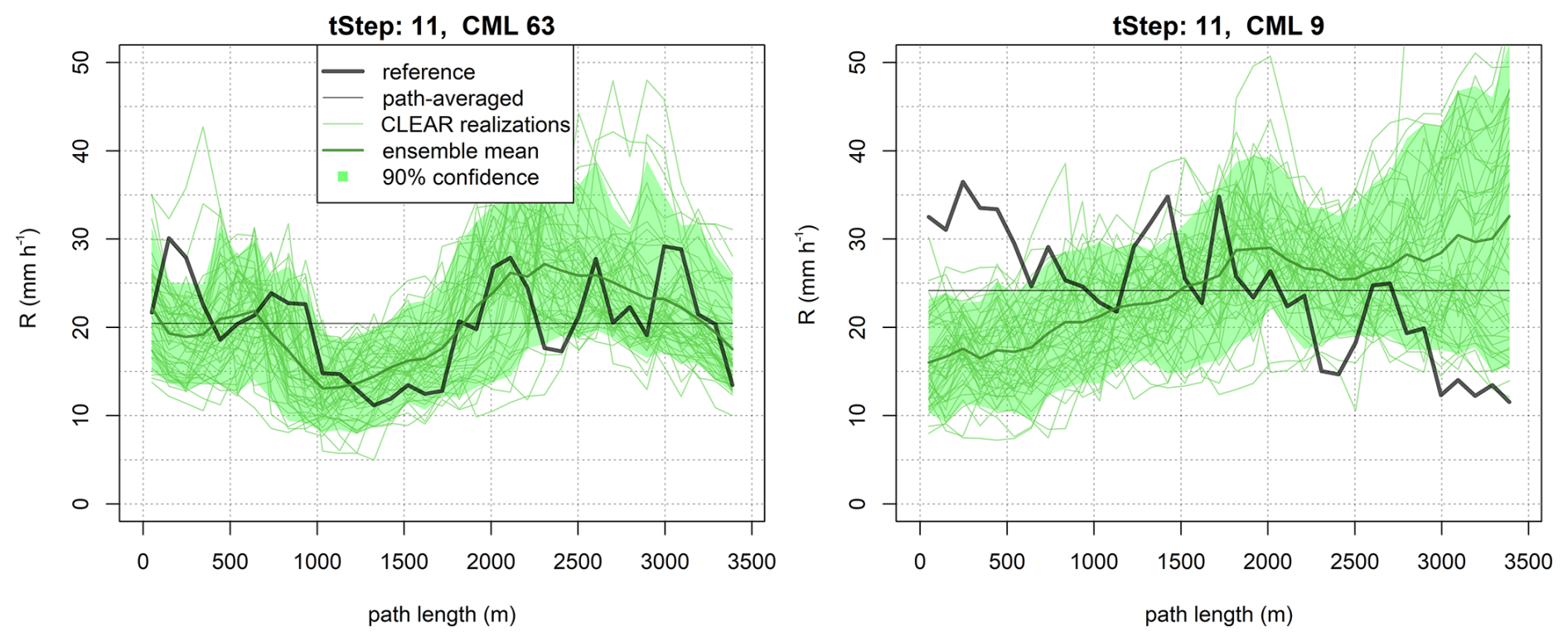
Figure 450 realizations of CLEAR rain-rate disaggregation along two links (CML 63 and CML 9) of similar path length (i.e., 3.5 km) during the time step 11 of event 1. Ninety-percent confidence bands are calculated as 5 % and 95 % quantiles of all realizations over each CML segment. Reference rain rates are from simulated rainfall fields.
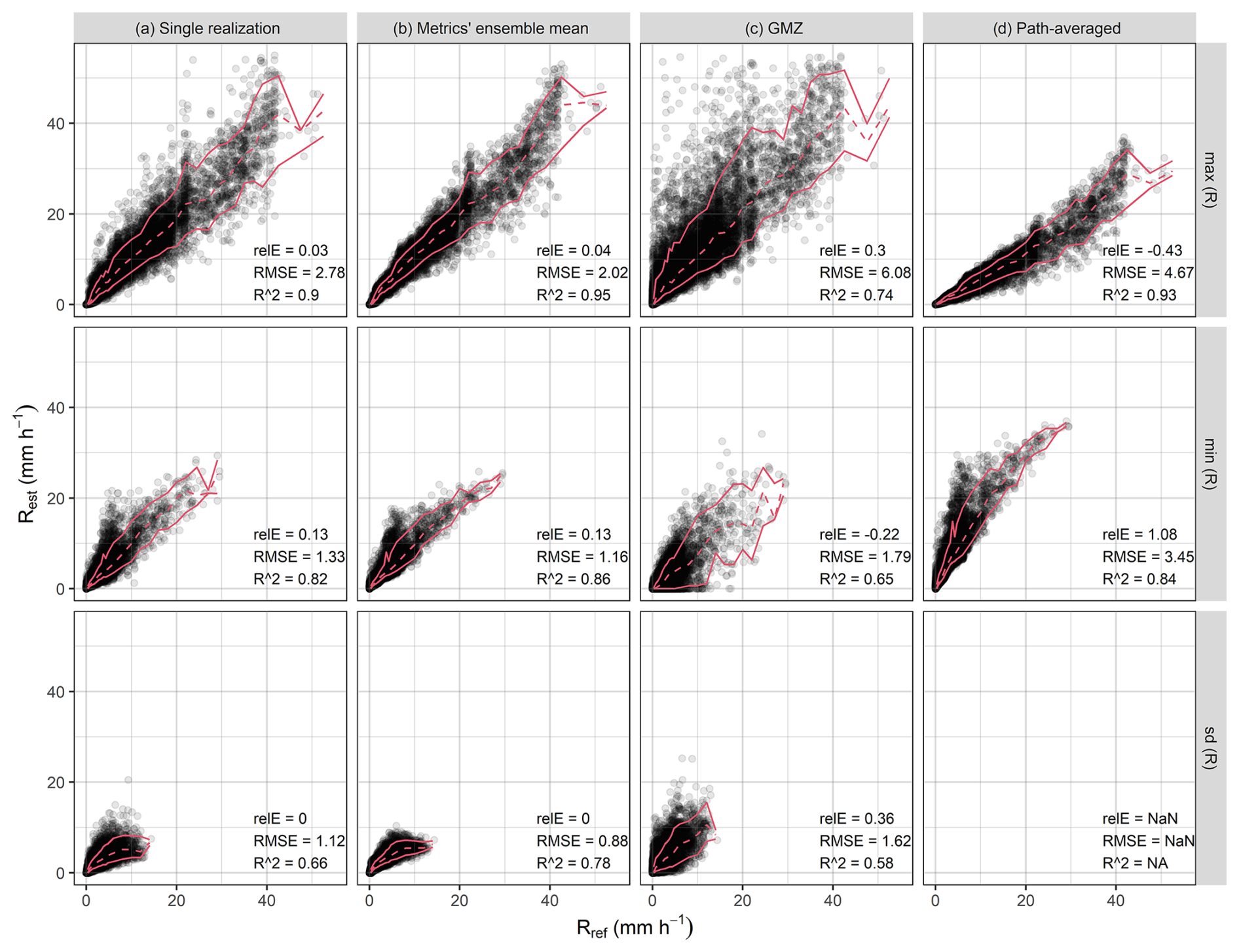
Figure 5Statistics of reference rain rate (Rref) along a CML path quantified for each time step compared to the statistics of estimated rain rates (Rest) when using CLEAR algorithm (a–b), benchmark GMZ algorithm (c), or path-averaged rain rates without disaggregation (d). Red lines depict median and 10 % and 90 % quantiles.
4.2 Evaluation of rainfall patterns along CMLs
The ability of disaggregation algorithms to realistically reproduce rainfall patterns is evaluated in each time step by quantifying rain-rate maximum, minimum, and standard deviation along a path of each CML. Figure 5 compares the statistics for the reference rain-rates with the ones obtained using CLEAR disaggregation and the two benchmarks. The ensemble of 50 CLEAR realizations is treated in two different ways: (a) the statistics are evaluated for a single realization and (b) the statistics are evaluated for each realization and afterwards averaged. The CLEAR algorithm clearly outperforms the benchmarks in all three statistics. It is better at reproducing the min/max values (overall, across all ensemble members as well as for individual realizations). The ensemble mean of the statistics leads to even more robust results. The relative error for the ensembles is similar to the one for single realization. However, the RMSE is markedly lower and R2 higher. Figure 5 also clearly shows how the naive approach of taking path-averaged rain rates (zero benchmark) systematically underestimates local maxima and overestimates minima.
CLEAR also reliably accounts for the effect of rain rate averaging along a CML path. Figure 6a shows how the variance of reference rain rates along a CML on average increases with increasing rain rate. In addition, for low and moderate rain rates, the variance tends to be higher for longer CMLs. CLEAR is able reproduce the dependence of variance on both rain rate and CML length very well up to rain rates about 15 mm h−1. For higher rain rates, the variance tends to be overestimated. This is probably due to systematic overestimation of the SD model (5) during higher rain rates (Fig. 3). The GMZ algorithm tends to overestimate variance and fails to accurately capture the relationship between variance and CML path length. Specifically, it does not reflect the fact that variance increases with longer CML path.
Compared with GMZ, CLEAR also has a more stable performance: Fig. 7 shows R-squared between reference and disaggregated rain rates along each CML evaluated over all time steps. R-squared values for the CLEAR ensemble mean range between 0.69 and 0.93 with a median value of 0.80, while for GMZ the values are between 0.3 and 0.94 with a median of 0.68. For comparison, the R-squared values for the zero benchmark (path-averaged rain rates) are between 0.63 and 0.94 with a median of 0.83. Using CLEAR, 18 CMLs (23 %) perform better than the zero benchmark, whereas by using GMZ, only 6 CMLs (8 %) perform better. It is interesting, that none of the CMLs performing better with GMZ match with those performing better under CLEAR disaggregation, which shows how CLEAR can help overcome the weaknesses of GMZ.
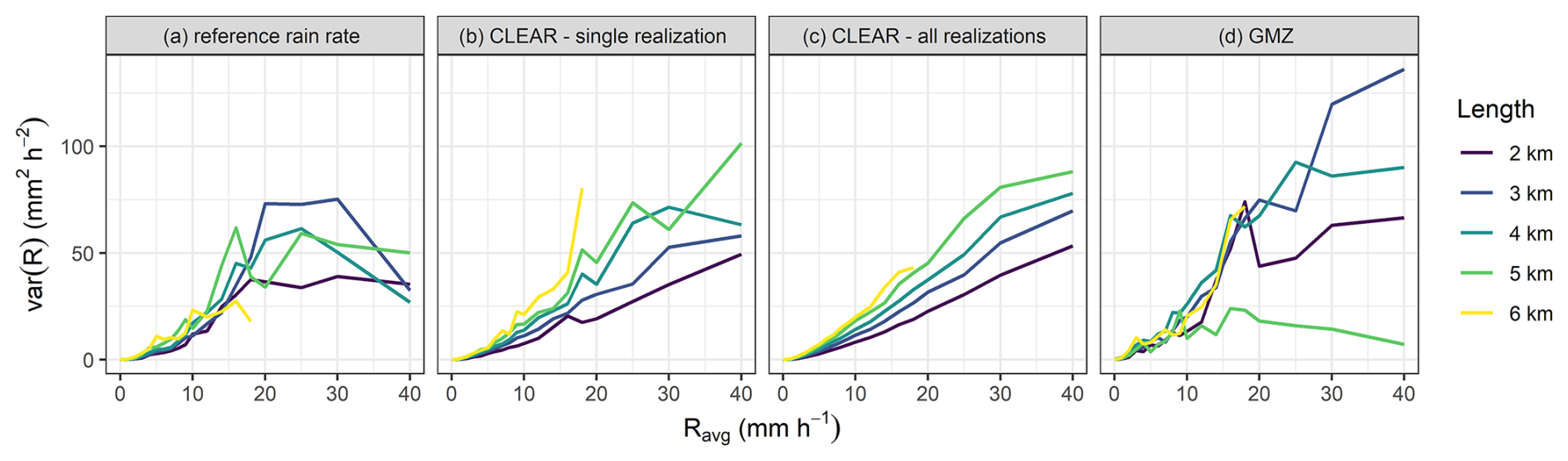
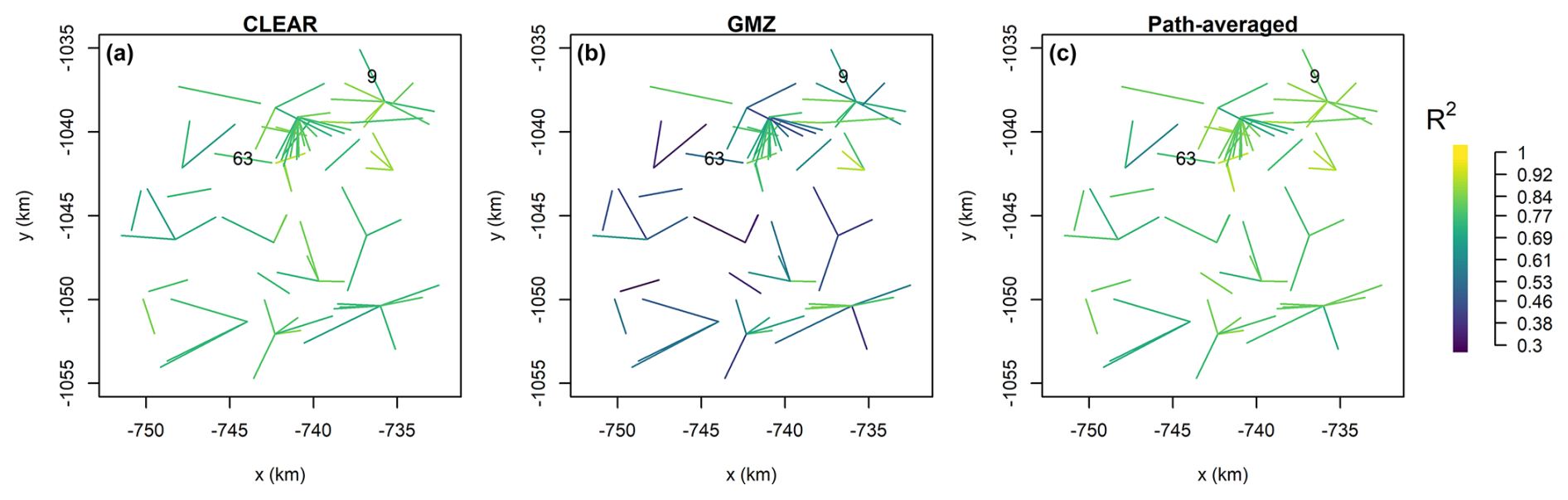
Figure 7R-squared between reference and disaggregated rain rates evaluated over all time steps separately for each CML. (a) CLEAR ensemble mean. (b) GMZ. (c) Path-averaged rain rates.
4.3 Segment-by-segment evaluation
The experiments performed on the simulated rainfall fields show that CLEAR produces roughly unbiased estimates on average. However, a more detailed segment-by-segment comparison between the ensemble mean of CLEAR (Fig. 8, left) and the actual rainfall values shows a clear conditional bias as a function of rainfall intensity.
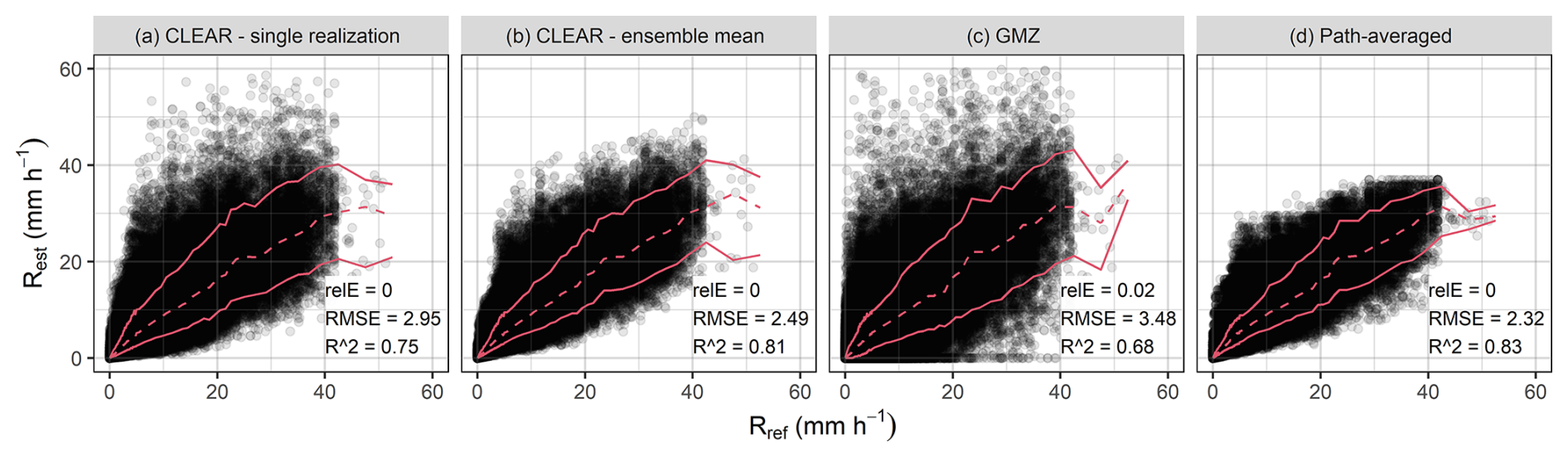
Figure 8Segment-by-segment comparison of disaggregated (a, b, c) and path-averaged (d) rain rates to the reference with lines depicting median and 10 % and 90 % quantiles.
Figure 8 shows that CLEAR systematically overestimates low rainfall rates and underestimates higher ones. This conditional bias can be attributed to errors in location with respect to the min/max rainfall rates along the link segments, as demonstrated in the right panel of Fig. 4, as well as the way the link segments are split during the cascade. However, it should be noted that the GMZ benchmark suffers from the same conditional bias. Moreover, GMZ also produces more outliers, even during relatively low rainfall rates. CLEAR does not have this issue because the disaggregation is controlled by a rain-rate dependent generator model, which means that link segments with higher intensities are split more homogeneously on average. Interestingly, Fig. 8 also shows that the simple strategy of distributing the rainfall rates homogeneously along the path of the links results in slightly better performance than the ensemble average of CLEAR. Nevertheless, they also systematically overestimate light rainfalls and underestimate heavy ones. This behavior is caused by averaging of extremes as indicated in Fig. 5.
4.4 CLEAR ensemble variance
The stochastic nature of CLEAR means that it can be used to generate ensembles of cascade realizations to assess the effect of model uncertainty on disaggregated rain rates. Figure 9 shows the containing ratio (CR) and average band width (ABW) conditional to the rain rate and CML length. Both metrics were evaluated over all 210 time steps. ABW increases with rain rate and CML length. This reflects what we expect, i.e., that the uncertainty of the disaggregation increases with increasing rain rates and CML path length. However, the CR values below 90 % indicate that the ensemble variance and hence the uncertainty represented by the band width are underestimated. The underestimation is the largest for light rainfall with rain rates below 1 mm h−1 (CR =0.18–0.47). The best performance, although not optimal, is achieved for rain rates between 2–10 mm h−1 (CR =0.60–0.80). On average, shorter CMLs tend to have lower CR than longer CMLs. Higher CR for longer CMLs is probably related to wider bands (higher ABW) of longer CMLs caused by the systematic overestimation of modelled SD (5) when compared to empirical SD (Fig. 3).
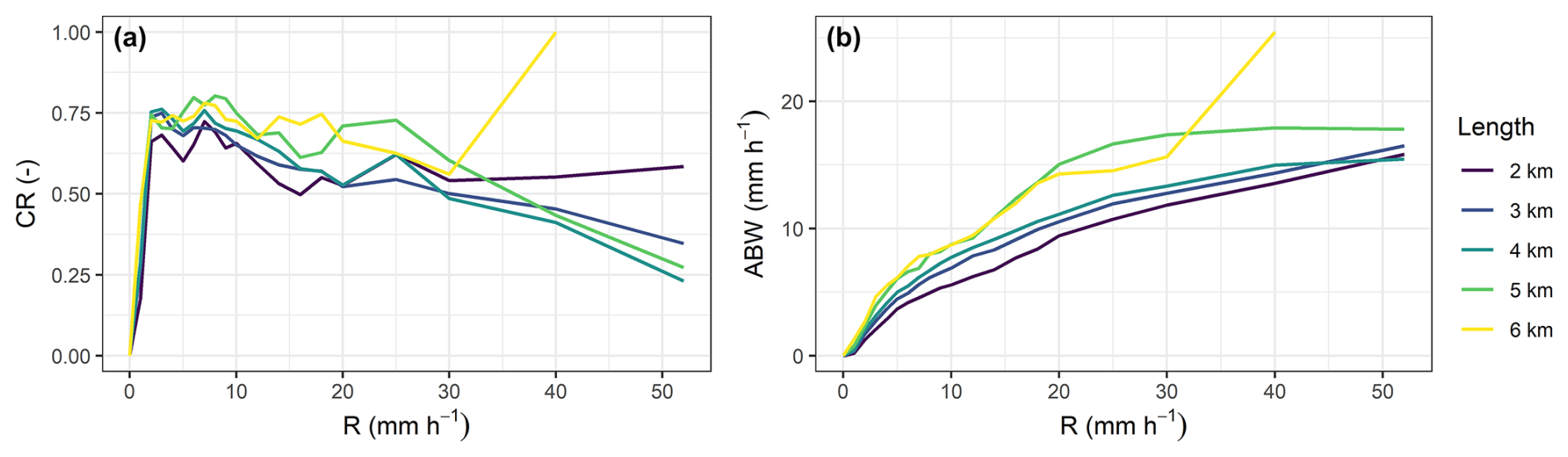
Figure 9Containing ratio (a) and average bandwidth (b) conditional to rain rate and CML length.
4.5 CLEAR performance for the case study
In this section, the strengths and weaknesses of CLEAR are demonstrated on real CML data during single heavy-rainfall event on 21 September 2014. The performance of CLEAR is first demonstrated on the same set of CMLs as in Sect. 4.1. Figure 10 shows disaggregated rain rates obtained using CLEAR at 19:45 UTC, which is the time when maximum rain rate occurred on CML 63. It shows that the CML path-averaged rain rates are systematically underestimated compared to the reference. Consequently, CLEAR also shows a systematic underestimation of the rain rates. However, this is not a shortcoming of the method but more an issue of the CML data themselves. For CML 63, CLEAR accurately reproduces the distribution of higher rain rates at the end nodes and lower ones in the middle. In contrast, for CML 9, it does not adequately capture the peak located in the middle section of the path. Overall, CLEAR reproduces the min/max more reliably than GMZ (Fig. 11). However, the results are significantly affected by the uncertainties in CML rain rate estimates. Also, and although they are bias-corrected, the radar rainfall estimates are likely to be affected by local biases as well. The minima, maxima, and standard deviations are similar to the values obtained on the simulated data and most reliably estimated by averaging the statistics over the ensemble. CLEAR has a slightly better performance than GMZ when evaluating segment-by-segment matches between reference and disaggregated CML rain rates: The RMSE values are 3.00 and 3.43 mm h−1 for CLEAR and GMZ respectively and the R2 is 0.38 and 0.30 respectively.
The results of the case study are strongly affected by a large discrepancy between the CML path-averaged rain rates and the reference. First, a rainfall amount along CML path which is being disaggregated is determined by the estimated rain rate. Second, the under- or overestimation of initial rain rate affects the cascade generator model and estimated breakdown coefficients. Despite large uncertainties, CLEAR is still able to reproduce variability and extremes along a CML path more reliably than GMZ benchmark.
The discrepancy between reference and estimated rain rates is partly caused by inaccurate path-averaged CML rainfall estimates, nevertheless, it is also related to the limited reliability of the radar rainfall product used at the 5 min temporal resolution. In general, a radar adjustment at high resolution is highly challenging e.g. due to the scale discrepancy of a radar pixel and a rain gauge catch area, possible displacement of rainfall field due to rainfall advection, etc. (see e.g. Ochoa-Rodriguez et al., 2019; Schleiss et al., 2020).
The case study is limited to illustrating CLEAR performance during a single event. A more comprehensive evaluation using a substantially larger dataset with more CMLs and wider variety of rainfall types is needed to properly assess CLEAR performance on real data. The evaluation should focus on data aggregated over longer time intervals (e.g. 30 min or hourly data) for which adjusted radar quantitative precipitation estimates are more accurate. As rain rate aggregation over longer intervals leads to the smoothing of local extremes, the effect of any disaggregation will be less pronounced. Next case study evaluating CLEAR on aggregated data should thus focus on a network outside of a city which is commonly characterized by longer CMLs.
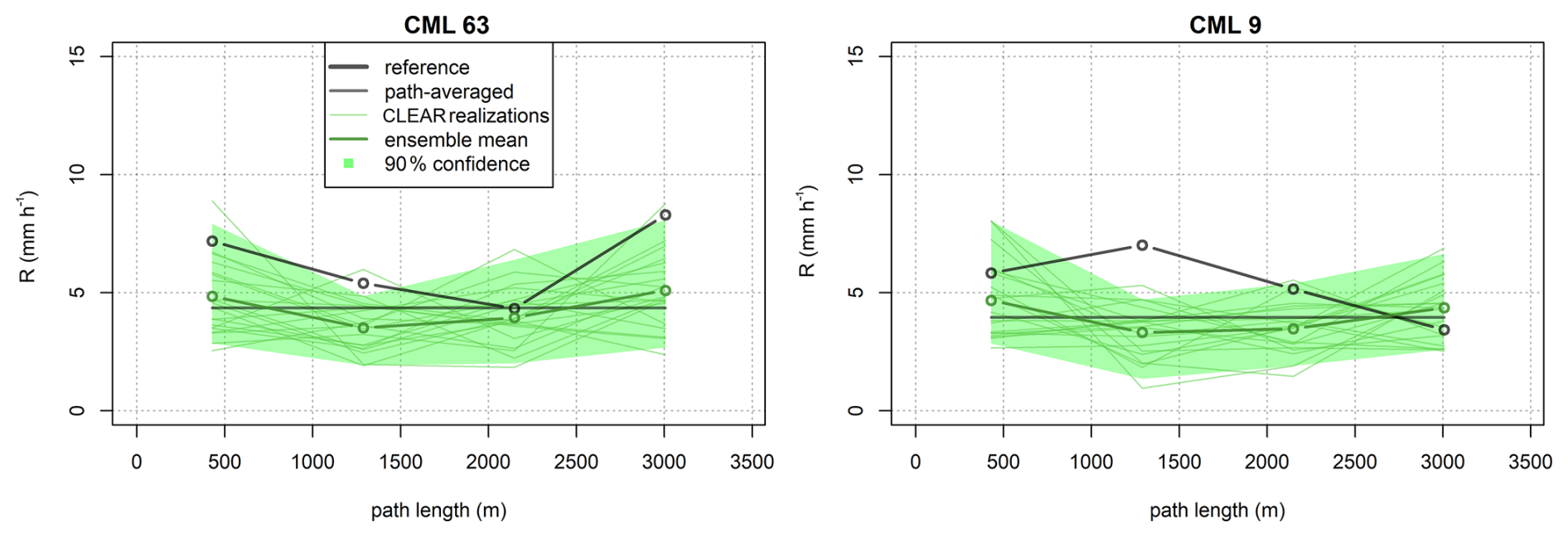
Figure 10CLEAR disaggregation of rain rates during one time step at 19:45 UTC demonstrated on real data from two CMLs of similar path length.
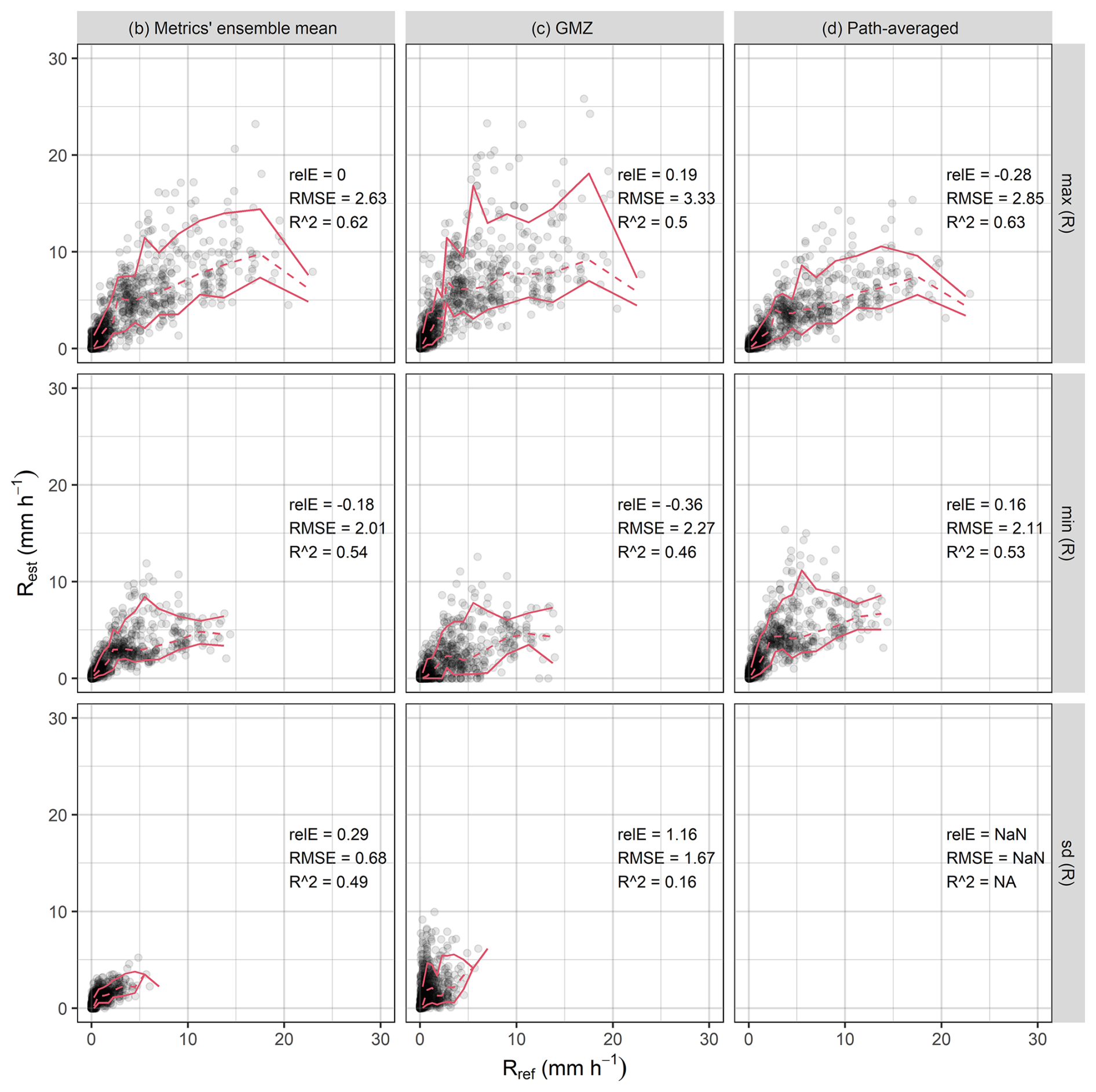
Figure 11Statistics of reference (radar) rain rate along a CML path for each time step and CML compared to the statistics when disaggregating real CML observations with: (a) CLEAR algorithm and calculating ensemble mean of each metric, (b) benchmark GMZ algorithm, or (c) using path-averaged rain rates without any disaggregation. Red lines depict median and 10 % and 90 % quantiles.
In this section we discuss results obtained from the experiments with simulated rainfall fields and identify factors influencing the performance of CLEAR. We also highlight advantages and limitations of CLEAR compared to the benchmark algorithm and explore potential research directions to address some of these limitations.
5.1 Modeling the cascade generator
The logit-normal cascade generator model behind the CLEAR algorithm assumes a simple power-law relation between the standard deviation (SD) of the cascade weights, the path-averaged rainfall intensity and link length (Eq. 5). Using the simulated rainfall fields, we can study the actual standard deviation of the empirical breakdown coefficients for a large number of CMLs links and compare them to the modeled ones to see how well the generator fits the data. Figure 12 shows the empirical breakdown coefficients when evaluated for each of the three simulated rain events, together with the global, fitted power-law model for the standard deviation (SD). It shows that the global SD model obtained by combining all the events together and imposing a power-law model significantly differs from the actual SD values for a given event. For starters, there are clear differences in the magnitude of the SD (for a given rainfall intensity and link length) from one event to another. Also, the patterns can be quite different. For example in event 1, the SD tends to increase for rainfall intensities between 1–5 mm, which is very different from the gradual decrease with intensity predicted by the model. The same ups and downs can be observed for event 2 and may be the consequence of the non-stationarity of the generator model in space and time. The fact that our simple cascade generator model cannot accommodate such patterns could explain the conditional bias with rain rates as well as the inability to adequately capture the location of min/max rainfall intensities along the link (Figs. 4 and 10).
To investigate this issue in more depth, we analyzed the empirical breakdown coefficients of the CML network in Prague using full dataset of bias-adjusted radar rainfall covering many different rain events. We found that the magnitude of the SD also seems to be related the maximum rainfall rate in the domain, however, the incorporation of this behavior through an additional parameter created more problems than it solved and often led to overfitting. We also tested how the SD model calibrated on the radar data performs. Although the model parameters substantially differed (a=0.36, b=0.52, and ), the performance of the CLEAR algorithm, when applied to the virtual CML observations, remained virtually unchanged. This highlights strong robustness of CLEAR to the choice of SD model. This property was also noted by Schleiss (2020) for the EVA cascade model. The explanation lies in the nature of the cascade process and functional form for the cascade generator model: although long CML segments may split quite differently at the initial levels, where SD values are higher, these differences quickly reduce in the later stages of the cascade. As the SD values decrease rapidly with each iteration, the resulting subdivisions become increasingly uniform, making the final disaggregation less sensitive to the specific SD model used.
Finally, the logit-normal cascade model itself may not work for all types of rainfall fields. In particular, the assumption of logit normal variability may not be valid for strongly skewed rainfall such as those associated with extreme convective events. In such cases, other more flexible models, e.g. the beta distribution, might perform better. Moreover, the spatial non-stationarity of rainfall features over the domain and the superposition of different generator models inside the domain was not explored, and further research is needed to understand how it could be detected and taken into account.
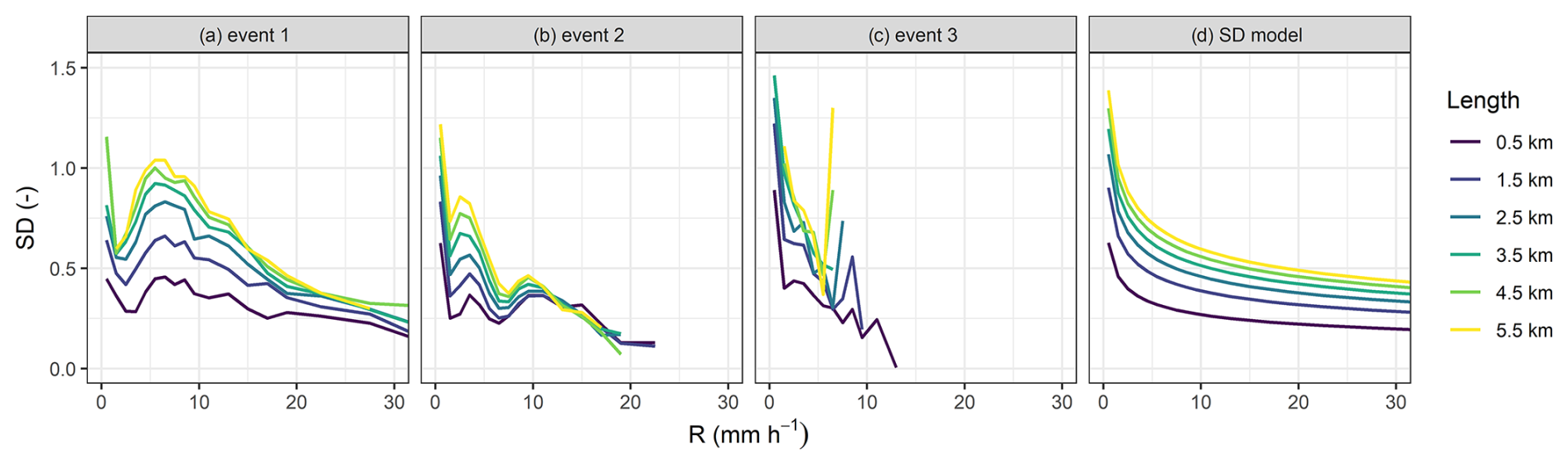
Figure 12Empirical (a–c) and modeled SD (d). SD of empirical breakdown coefficients is shown separately for three events evaluated in this study.
5.2 Sensitivity of CLEAR disaggregation to the spatial coherence rule
CLEAR is efficient in estimating rainfall extremes and variability along CML path (Figs. 5 and 6) and, in this respect, clearly outperforms the GMZ algorithm and path-averaged rain rates. However, it also struggles to reliably predict the position of the smallest/largest rainfall rates along the link, as clearly demonstrated by the results of the segment-by-segment evaluation (Sect. 4.3). To better understand where the errors in CLEAR originate from, we took a closer look at the performance of the SC rule itself. Specifically, we performed two additional analyses with the high-resolution simulated reference rainfall fields. In this simulation setting we could study how well the empirical splits based on interpolated rainfall rates from coarser scales actually are.
In the first analysis, we evaluated the precision of the empirical SC rule, i.e. the ratio of splits where a link segment correctly received the shortest length and, therefore, the highest rainfall intensity along its path. On average, about of the splits performed using the empirical rule were wrong leading to displacement of rainfall peaks and minima. In the second analysis, we applied CLEAR using an optimal SC rule based on the true rain rate along a CML path. We found that using an optimal SC rule significantly improves the performance of CLEAR on a segment-by-segment basis: For example, the RMSE decreased from 2.95 to 2.15 mm h−1 and R2 increased from 0.75 to 0.86. However, the optimal SC rule had almost no effect on the average performance statistics for the min/max and standard deviation of rain rates along a CML. The shortcomings of the empirical SC rule are thus not critical for applications where statistical distribution of rain rates is more important than their exact positioning. For example, for improving rainfall estimation from CMLs at lower (X, Ku band) or higher frequencies (E-band, W-band), where attenuation-rainfall relations can be significantly nonlinear and thus a commonly used assumption of uniform rain rate along a CML path potentially leads to higher errors.
5.3 Ensemble variance
Ensemble variance arises from a stochastic nature of the cascade generator (Eq. 3), however, the relation between the two is not straightforward. For example, the ensemble variance in CLEAR may be strongly affected by the SC rule used to split the segments. Our analyses show that different realizations of CLEAR disaggregation preserve similar rainfall pattern along a CML path, R-squared between the realizations is 0.84–0.86. In general, the uncertainty estimates derived from the CLEAR ensembles tend to be underestimated; the mismatch is highest during light rainfall (0–1 mm h−1) and heavy rainfall (R>30 mm h−1) (Fig. 9). Additional analyses (not shown) suggest that for light rainfalls, the underestimation may be due to the difficulty in reproducing rainfall intermittency and reparameterization of SD model discussed in Sect. 5.1 could help in this regard. For heavy rainfall, the estimated variability and position of rainfall peaks along the CMLs tend to be incorrectly estimated (Fig. 4, right). To improve, it might be necessary to design better, more elaborate and spatially variable coherence rules (e.g., as a function of CML density) to account for the uncertainty related to spatial coherence. Alternatively, some randomness could be introduced in the splitting rule. For example, by randomly re-assigning the peak rainfall rate to the other side of the CML with a frequency of about or less (especially at the first cascade levels). More realistic ensemble spread might also be achieved by improving the cascade generator model. For example, by locally adapting the spread of the cascade weights to account for the spatial correlation structure of the rain and other non-stationarities (e.g., proximity to dry areas).
A new disaggregation algorithm for CMLs named CLEAR (CML segments with equal amounts of rain) has been proposed. Within CLEAR, the splitting of link segments is controlled by a multiplicative random cascade generator, whose standard deviation depends on the rain rate along the CML segment and the length of the segment. Rain rate information from neighbouring CMLs is used to estimate the areas of largest/smallest rainfall intensities and thus preserve spatial consistency during the splitting. The stochastic character of CLEAR makes it possible to represent uncertainty as an ensemble of rain rate distributions along a CML.
Evaluation of the CLEAR algorithm on virtual rainfall fields shows good overall performance and realistic spatial patterns. CLEAR outperformed the GMZ benchmark both in the simulations and on real data. The case study, however, revealed challenges related to uncertainties in CML quantitative precipitation estimates, which are common to all methods. Despite the encouraging results, lots of potential for improvement remains. For example, the ensembles generated by CLEAR still significantly underestimates overall variability along a CML path. The segment-by-segment evaluation also shows that performance is negatively affected by errors in positioning of rainfall extremes along the CML. A better SC rule, accounting for rainfall advection and the introduction of more randomness into the splitting rule could help in this regard.
In conclusion, CLEAR can help in generating more representative rainfall distributions along CMLs, which is important for the spatial reconstruction of rainfall fields from path-integrated CML data. However, further research is needed to improve the SC rule and cascade generator model. Moreover, future evaluation studies using larger and more diverse datasets both in terms of rainfall and network topology may provide deeper insights into limitations and advantages of CLEAR compared to the other state-of-the-art disaggregation algorithms. CLEAR might also help to model rainfall intermittency along a CML path, albeit, this feature needs to be investigated in more detail first. Future work could also investigate how to deal with non-stationarity of the rainfall field and the cascade generator model, and how to incorporate data from previous time steps. It might also be interesting to investigate the performance of CLEAR when applied to CMLs at lower (X, Ku band) or higher frequencies (E-band, W-band), where attenuation-rainfall relations can be significantly nonlinear and thus an assumption of uniform rain rate along a CML path potentially leads to higher errors.
The SC rule is evaluated using gridded rainfall fields, which are reconstructed from CML data at each cascade level: initially from the original path-averaged rain rates and at further cascade levels from disaggregated rain rates along disaggregated CML segments. The initial resolution is 4×4 km2 and this resolution is refined after each cascade level such that the new grid size resolution is the original size divided by 2i, where i is the order of the cascade level. The initial and refined resolution approximately correspond to the length scales of the longest CMLs resp. their segments evolving as the result of the disaggregation.
Rainfall fields are constructed as follows: First CML segments are assigned to the grid cells by evaluating the overlap between the cells and the midpoints of the segments. Then, the cell rain rate is estimated as the average rain rate of the CML segments belonging to the cell. The cells that do not containing any segment are marked as cells with not available rain rate and are omitted from the evaluation of the SC rule.
Rain rates for evaluating the spatial consistency rule are sampled from the CML-derived rainfall field, with resolution matching the current cascade level. Sampling is performed using a 4×6 matrix of 24 regularly spaced points positioned near each end node of a CML segment. The spacing between these positions is set to one-third of the grid size of the rainfall field, meaning it is progressively refined alongside the field resolution at each cascade level. The splitting example is shown in Fig. A1. Figure A1a illustrates the placement of the SC rule sampling matrix for CML 33.
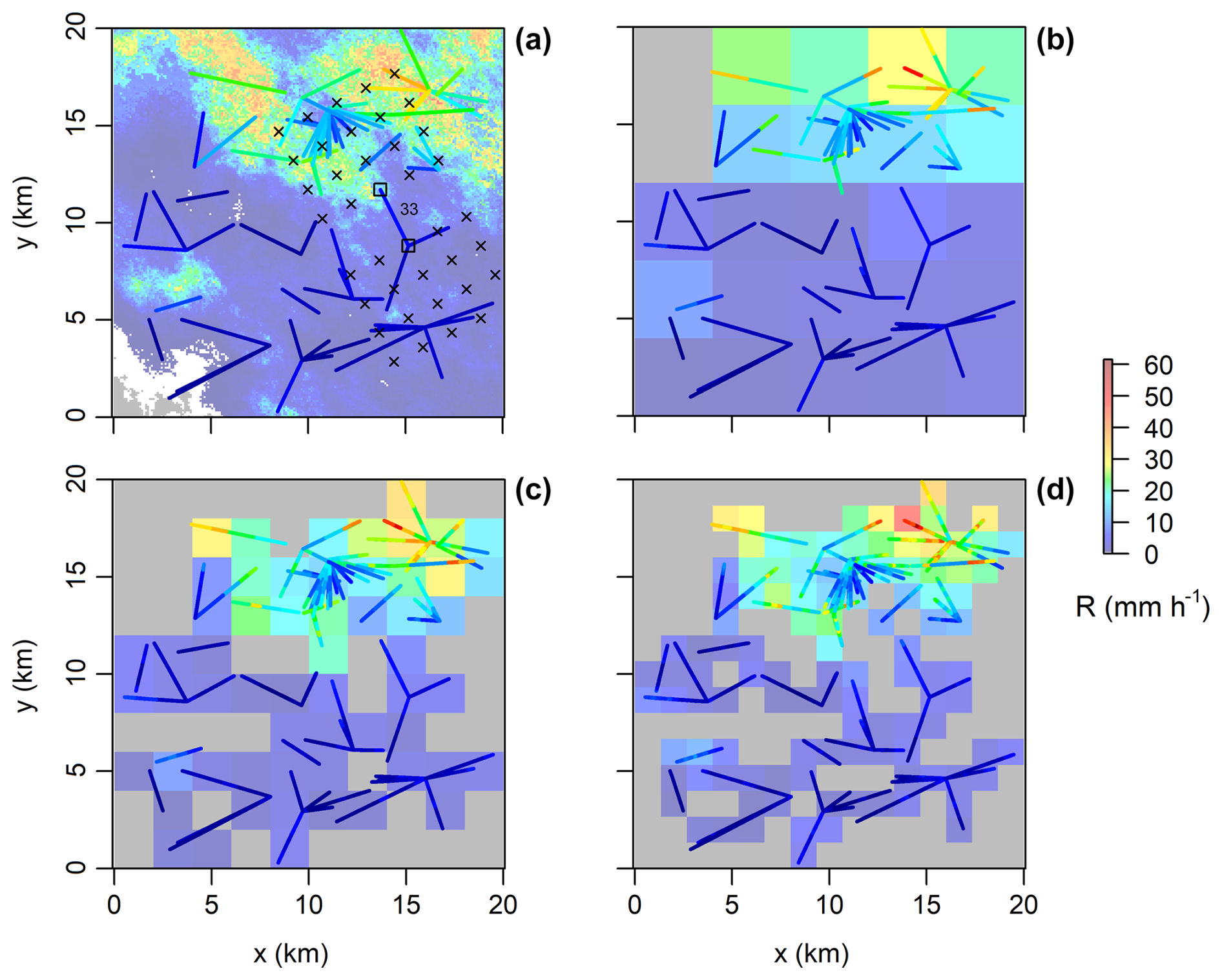
Figure A1(a) Reference rainfall field and CMLs with color-coded path-averaged rain rates. The positioning of the points used to sample rain rates for SC rule is illustrated for CML 33 and marked with crosses. (b–d) Gridded rainfall used to evaluate spatial coherence rule when splitting CML segments at successive levels (1st, 2nd, 3rd) of the cascade. Grey color is used to indicate cells with not available rain rate values.
The SD model is fitted to sample SD estimates of empirical breakdown coefficients W0 obtained from synthetic CML networks (Sect. 2.2). To ensure zero mean, the original breakdown coefficient W0 and the difference 1–W0 are merged to one population: . The breakdown coefficients W are then transformed to a Gaussian distribution using the left-hand side of Eq. (3) and grouped according to path lengths and path-averaged rain rates of the parent links that generated them. The length classes are equidistantly spaced with a bin size of 500 m between 500 and 6500 m. The rain rate bin sizes are 1 mm h−1 between 0–10 mm h−1, 2 mm h−1 between 10–20 mm h−1, and 5 mm h−1 between 20–55 mm h−1. The decreasing size of the bins with growing rain rates reflect naturally lower representation of higher rain rates in the population of CML rain rates. Sample SD values are calculated for each group having at least 50 samples in them.
SD model (5) is optimized using the simplex method for function minimization (Nelder and Mead, 1965) implemented in the optim function available within the statistical computing language R (R Core Team, 2023). A following objective function is minimized:
where SDsample is sample SD and SDmodel is modelled SD. The optimization is performed for sample SD obtained for breakdown coefficients of all synthetic CMLs during all three virtual rainfall events.
The essential data and codes underlying this work are publicly available at 4TU Research Data repository https://doi.org/10.4121/5C4AD375-4E88-402B-AC46-D27BB47250C3.V1 (Fencl and Schleiss, 2025). CML attenuation data for the case study are subjected to non-disclosure agreement (NDA) and can be shared on request to the corresponding author under conditions defined by the NDA. Similarly weather radar data and rain-gauge can be shared on request to the corresponding author under conditions defined by the a license agreement.
MF performed the analysis, prepared all the figures and wrote the first draft. MS provided advice, gave critical feedback on previous draft versions and helped improve the quality of the writing. MF and MS together prepared, annotated, and published the dataset including the code used for CLEAR disaggregation.
The contact author has declared that neither of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors. Also, please note that this paper has not received English language copy-editing.
We would like to thank T-Mobile Czech Republic a.s. for providing the CML data. Special thanks are extended to Pražská vodohospodářská společnost a.s. for providing rainfall data from their rain-gauge network and Pražské vodovody a kanalizace, a.s., who carefully maintains the rain gauges. Finally, we would like to thank 4TU Research Data for facilitating the publication process of our codes and data under the FAIR principles.
This research has been supported by the Grantová Agentura České Republiky (grant no. 24-13677L, proejct MERGOSAT).
This paper was edited by Maximilian Maahn and reviewed by two anonymous referees.
Atlas, D. and Ulbrich, C. W.: Path- and Area-Integrated Rainfall Measurement by Microwave Attenuation in the 1–3 cm Band, J. Appl. Meteorol., 16, 1322–1331, https://doi.org/10.1175/1520-0450(1977)016<1322:PAAIRM>2.0.CO;2, 1977.
Blettner, N., Fencl, M., Bareš, V., Kunstmann, H., and Chwala, C.: Transboundary Rainfall Estimation Using Commercial Microwave Links, Earth and Space Science, 10, e2023EA002869, https://doi.org/10.1029/2023EA002869, 2023.
Chwala, C. and Kunstmann, H.: Commercial microwave link networks for rainfall observation: Assessment of the current status and future challenges, Wiley Interdisciplinary Reviews: Water, 6, e1337, https://doi.org/10.1002/wat2.1337, 2019.
Cuccoli, F., Baldini, L., Facheris, L., Gori, S., and Gorgucci, E.: Tomography applied to radiobase network for real time estimation of the rainfall rate fields, Atmos. Res., 119, 62–69, https://doi.org/10.1016/j.atmosres.2011.06.024, 2013.
Ericsson: Ericsson Microwave Outlook Report 2019, https://www.ericsson.com/en/reports-and-papers/microwave-outlook/reports/2019 (last access: 10 December 2019), 2019.
Fencl, M. and Schleiss, M.: Data and codes underlying the publication: “CLEAR: a new discrete multiplicative random cascade model for disaggregating path-integrated rainfall estimates from commercial microwave links”, 4TU Research Data [code] and [data set], https://doi.org/10.4121/5C4AD375-4E88-402B-AC46-D27BB47250C3.V1, 2025.
Fencl, M., Dohnal, M., Valtr, P., Grabner, M., and Bareš, V.: Atmospheric observations with E-band microwave links – challenges and opportunities, Atmos. Meas. Tech., 13, 6559–6578, https://doi.org/10.5194/amt-13-6559-2020, 2020.
Giuli, D., Toccafondi, A., Gentili, G. B., and Freni, A.: Tomographic Reconstruction of Rainfall Fields through Microwave Attenuation Measurements, J. Appl. Meteorol., 30, 1323–1340, https://doi.org/10.1175/1520-0450(1991)030<1323:TRORFT>2.0.CO;2, 1991.
Goldshtein, O., Messer, H., and Zinevich, A.: Rain Rate Estimation Using Measurements From Commercial Telecommunications Links, IEEE T. Signal Proces., 57, 1616–1625, https://doi.org/10.1109/TSP.2009.2012554, 2009.
Graf, M., Chwala, C., Polz, J., and Kunstmann, H.: Rainfall estimation from a German-wide commercial microwave link network: optimized processing and validation for 1 year of data, Hydrol. Earth Syst. Sci., 24, 2931–2950, https://doi.org/10.5194/hess-24-2931-2020, 2020.
Haese, B., Hörning, S., Chwala, C., Bárdossy, A., Schalge, B., and Kunstmann, H.: Stochastic Reconstruction and Interpolation of Precipitation Fields Using Combined Information of Commercial Microwave Links and Rain Gauges, Water Resour. Res., 53, 10740–10756, https://doi.org/10.1002/2017WR021015, 2017.
Heistermann, M., Jacobi, S., and Pfaff, T.: Technical Note: An open source library for processing weather radar data (wradlib), Hydrol. Earth Syst. Sci., 17, 863–871, https://doi.org/10.5194/hess-17-863-2013, 2013.
ITU-R: RECOMMENDATION ITU-R P.838-3, Specific attenuation model for rain for use in prediction methods, http://www.itu.int/dms_pubrec/itu-r/rec/p/R-REC-P.838-3-200503-I!!PDF-E.pdf (last access: 7 March 2025), 2005.
Kharadly, M. M. Z. and Ross, R.: Effect of wet antenna attenuation on propagation data statistics, IEEE T. Antenn. Propag., 49, 1183–1191, https://doi.org/10.1109/8.943313, 2001.
Leijnse, H., Uijlenhoet, R., and Stricker, J. N. M.: Rainfall measurement using radio links from cellular communication networks, Water Resour. Res., 43, W03201, https://doi.org/10.1029/2006WR005631, 2007.
Messer, H., Zinevich, A., and Alpert, P.: Environmental Monitoring by Wireless Communication Networks, Science, 312, 713–713, https://doi.org/10.1126/science.1120034, 2006.
Molnar, P. and Burlando, P.: Preservation of rainfall properties in stochastic disaggregation by a simple random cascade model, Atmos. Res., 77, 137–151, https://doi.org/10.1016/j.atmosres.2004.10.024, 2005.
Nelder, J. A. and Mead, R.: A Simplex Method for Function Minimization, Comput. J., 7, 308–313, https://doi.org/10.1093/comjnl/7.4.308, 1965.
Ochoa-Rodriguez, S., Wang, L.-P., Willems, P., and Onof, C.: A Review of Radar-Rain Gauge Data Merging Methods and Their Potential for Urban Hydrological Applications, Water Resour. Res., 55, 6356–6391, https://doi.org/10.1029/2018WR023332, 2019.
Overeem, A., Leijnse, H., and Uijlenhoet, R.: Country-wide rainfall maps from cellular communication networks, P. Natl. Acad. Sci. USA, 110, 2741–2745, https://doi.org/10.1073/pnas.1217961110, 2013.
Pastorek, J., Fencl, M., Rieckermann, J., and Bareš, V.: Precipitation Estimates From Commercial Microwave Links: Practical Approaches to Wet-Antenna Correction, IEEE T. Geosci. Remote, 60, 1–9, https://doi.org/10.1109/TGRS.2021.3110004, 2022a.
Pastorek, J., Fencl, M., Rieckermann, J., and Bareš, V.: Precipitation Estimates From Commercial Microwave Links: Practical Approaches to Wet-Antenna Correction, IEEE T. Geosci. Remote, 60, 1–9, https://doi.org/10.1109/TGRS.2021.3110004, 2022b.
R Core Team: R: A language and environment for statistical computing, R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/ (last access: 13 May 2023), 2023.
Schleiss, M.: A new discrete multiplicative random cascade model for downscaling intermittent rainfall fields, Hydrol. Earth Syst. Sci., 24, 3699–3723, https://doi.org/10.5194/hess-24-3699-2020, 2020.
Schleiss, M., Jaffrain, J., and Berne, A.: Stochastic Simulation of Intermittent DSD Fields in Time, J. Hydrometeorol., 13, 621–637, https://doi.org/10.1175/JHM-D-11-018.1, 2012.
Schleiss, M., Olsson, J., Berg, P., Niemi, T., Kokkonen, T., Thorndahl, S., Nielsen, R., Ellerbæk Nielsen, J., Bozhinova, D., and Pulkkinen, S.: The accuracy of weather radar in heavy rain: a comparative study for Denmark, the Netherlands, Finland and Sweden, Hydrol. Earth Syst. Sci., 24, 3157–3188, https://doi.org/10.5194/hess-24-3157-2020, 2020.
Zinevich, A., Alpert, P., and Messer, H.: Estimation of rainfall fields using commercial microwave communication networks of variable density, Adv. Water Resour., 31, 1470–1480, https://doi.org/10.1016/j.advwatres.2008.03.003, 2008.