the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 17 Oct 2025
| 17 Oct 2025
Surveillance Camera-Based Deep Learning Framework for High-Resolution Near Surface Precipitation Type Observation
Xing Wang
Kun Zhao
Hao Huang
Ang Zhou
Haiqin Chen
Urban surveillance cameras offer a valuable resource for high spatiotemporal resolution observations of near surface precipitation type (SPT), with significant implications for sectors such as transportation, agriculture, and meteorology. However, distinguishing between common SPT – rain, snow, and graupel – present considerable challenges due to their visual similarities in surveillance videos. This study addresses these challenges by analyzing both daytime and nighttime videos, leveraging meteorological, optical, and imaging principles to identify distinguishing features for each SPT. Considering both computational accuracy and efficiency, a new deep learning framework is proposed. It leverages transfer learning with a pre-trained MobileNet V2 for spatial feature extraction and incorporates a Gated Recurrent Unit network to model temporal dependencies between video frames. Using the newly developed 94 h SPT Surveillance Video (SPTV) dataset, the proposed model is trained and evaluated alongside 24 comparative algorithms. Results show that our proposed method achieves an accuracy of 0.9677 on the SPTV dataset, outperforming all other relevant algorithms. Furthermore, in real-world experiments, the proposed model achieves an accuracy of 0.9301, as validated against manually corrected Two-Dimensional Video Disdrometer measurements. It remains robust against variations in camera parameters, maintaining consistent performance in both daytime and nighttime conditions, and demonstrates wind resistance with satisfactory results when wind speeds are below 5 m s−1. These findings highlight the model's suitability for large-scale, practical deployment in urban environments. Overall, this study demonstrates the feasibility of using low-cost surveillance cameras to build an efficient SPT monitoring network, potentially enhancing urban precipitation observation capabilities in a cost-effective manner.
- Article
(11912 KB) - Full-text XML
- BibTeX
- EndNote




Near surface precipitation type (SPT) refer to any atmospheric particle consisting of liquid or solid water, which are integral to precipitation processes and play a crucial role in the water cycle and cloud microphysics (Pruppacher and Klett, 1980). Despite SPT and ground conditions (i.e., snow or rain on ground) are related, note that they are different. The identification of SPT contributes to the improvement of quantitative precipitation estimation algorithms and promotes the understanding of precipitation microphysical processes, thus providing scientific support for the improvement of microphysics scheme of numerical weather prediction. Common examples of SPTs include rain, snow, graupel. They account for more than 90 % of the SPT and influence urban transportation, communication, electricity, and other industries (Casellas et al., 2021a; Zhou et al., 2020). Especially in winter, a weather process may contain multiple SPTs and often co-exist or convert to each other. Given the same amount of precipitation, the impacts of different SPTs may vary considerably (Leroux et al., 2023). For example, if 5 mm of precipitation falls in 24 h, it is only light rain for the liquid precipitation but heavy snow for the solid precipitation, severely influencing social production and life. In winter, when snow, rain, and graupel co-exist or alternate frequently, it is tough for forecasters to know the actual weather conditions, which seriously affects the quality of forecasts (Haberlie et al., 2015). Therefore, the accurate discrimination of the SPT, especially for the rain, snow, and graupel, has significant scientific and practical value.
Nowadays, many countries and regions no longer observe precipitation information manually (e.g., in January 2014, China cancelled ground-based manual observation). Ground-based Disdrometers (i.e., OTT Parsivel, Two-Dimensional Video Disdrometer), airborne optical and electromagnetic wave detection devices, and dual-polarization radars have become the primary tools (Jennings et al., 2023). However, (1) with the rapid development of urbanization, ground-based disdrometers in urban areas face outstanding problems such as high construction costs, difficulty in management and maintenance, and low deployment density, resulting in limited spatial representativeness of the SPT observations (Arienzo et al., 2021). (2) The data collected by airborne equipment is mainly used for validating and analysing scientific experiments, which is challenging to apply on a large scale and in real-time observation tasks (Schirmacher et al., 2024). (3) Dual polarization radar can alternatively or simultaneously transmit and receive polarized waves in both horizontal and vertical directions to obtain the echo information in different directions of the target scatterer and thus identify the SPT in the cloud (Casellas et al., 2021b). However, precipitation particles undergo a complex physical evolution from high altitude to the ground, especially in urban areas, where the temperature may have significant spatial differences, leading to large differences in the SPT between regions (Speirs et al., 2017). In summary, existing techniques have not effectively addressed SPT's high temporal and spatial resolution discrimination.
The development of the new observation method has received much attention. Some researchers have adopted the idea of “Citizen Science” by encouraging residents to report precipitation they see to provide the actual value of the SPT (Crimmins and Posthumus, 2022). Extensive investigations have demonstrated the effectiveness of the citizen science-based approach (Arienzo et al., 2021; Jennings et al., 2023), which provides important insights for our study. According to a survey by Comparitech (https://www.comparitech.com/, last access: 12 May 2024), there are approximately 770 million surveillance cameras worldwide. Surveillance video allows 24/7 observation of the precipitation process and provides clues for SPT discrimination (Wang et al., 2023a). If every surveillance camera is regarded as an observation site, such a vast number of surveillance cameras provide a high spatial resolution observation. At the same time, the surveillance video is transmitted through fiber optic, 4G, and 5G communication networks, enabling transmission back 15–25 surveillance images per second, which offer a high temporal resolution sensing of SPT. Moreover, the SPT observation mission can be deployed on existing surveillance resources, showcasing the advantage of low operation and maintenance costs. Compared to the other citizen science-based approach, the SPT observation network composed of surveillance cameras offered a more objective record of the precipitation process, which has the potential advantages of low cost, all-day, and high spatiotemporal resolution.
However, extensive analysis and comparison experiments have revealed that rain, snow, and graupel show greater similarity in surveillance videos (e.g., graupel and rain, as well as graupel and snow, are more similar in daytime surveillance videos under different precipitation intensities, whereas at nighttime, the distinguishing image features of the three are much closer, making the distinction much more difficult (For more details, see Sect. 3.1). This study focuses on the discrimination of three SPT, i.e., rain, snow, and graupel particles via surveillance video, and develops a deep learning-based SPT discrimination method. Considering that surveillance cameras capture visible and near-infrared video during daytime and nighttime, respectively, this study first analyzes the video imaging model of three different particles and compares their differences in surveillance video features. Taking the above findings as a priori knowledge, a deep learning-based SPT classification model is proposed. An efficient convolutional neural network (CNN) called MobileNet V2 is used to extract spatial features from surveillance images based on transfer learning. These features are stacked together and fed to a gated recurrent unit (GRU) network, which enables modeling the long-term dynamics of the SPT in a video sequence. Then, a SPT surveillance video (SPTV) dataset is constructed for the deep learning model training and testing. Finally, the effectiveness of the proposed method is evaluated on both the SPTV dataset and the real-world experiments. To the authors' knowledge, this is the first study on graupel observation from surveillance video data. The research findings can provide technical and data support for understanding the microphysical process of precipitation, improving the microphysical calculation model of precipitation and improving the accuracy of satellite/radar retrievals.
The rest of this paper is organized as follows. Following this introduction, we present the related works in Sect. 2; and explain the details of the proposed deep-learning model in Sect. 3; and finally, we discuss the experimental results in Sect. 4 and conclude in Sect. 5.
Visual perception is an effective way to distinguish SPT. Visual sensors, such as surveillance cameras, cell phones, digital cameras, and vehicle cameras, are considered potential weather phenomena observers in existing studies. Considering the research theme, visual is primarily defined as optical images obtained from the ground. This does not include data obtained from LiDAR, Radar, or similar technologies. The authors divided the existing visual-based SPT identification work into three categories: traffic surveillance cameras, in-vehicle cameras, and user-generated visual data. It should be noted that “weather” is a more generic and broad expression that includes rain, snow, fog, sunny or cloudy conditions, etc. Meanwhile, “hydrometeor” or “precipitation type” specifically refers here to rain, snow and graupel.
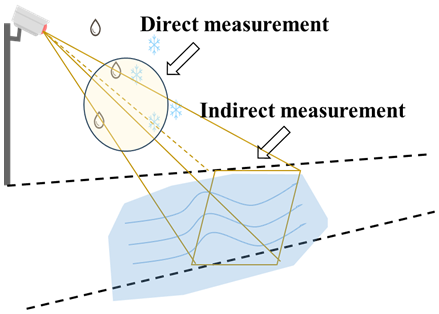
Figure 1Weather classification using traffic surveillance cameras. Direct measurement methods focus on the image/video features exhibited during the precipitation particle's falling process, while indirect measurements involve snow or water accumulation on the ground.
2.1 Traffic surveillance camera
During rainy and snowy weather, roads suffer from snow, ice, and ponding, affecting transportation efficiency. Timely weather information reports are significant for traffic warning, diversion, and management. However, with the limited number of weather stations and delays in radar/ satellite-based weather information release, some researchers exploited weather recognition from outdoor road surveillance cameras (Li et al., 2014; Lu et al., 2014). As shown in Fig. 1, these studies include two categories:
-
Indirect measurement mainly refers to detecting snow, pounding, and road surface wetness from video to deduce the weather. Therefore, these methods mainly focus on the information on the road surface rather than precipitation processes; specifically, they focus on whether there is snow on the ground rather than whether it is snowing. For example, Shibata et al. (2014) used the texture features of the surveillance images to quantify the pattern and texture of the road surface and detect road surface conditions (wet and snow) by surveillance cameras from day to night (or low-light scenarios). Morris and Yang (2021) constructed a road extract method by Mask R-CNN and then built a gradient-boosting ensemble classifier to predict pavement wetness. Ramanna et al. (2021) used deep CNNs to label the road surveillance images into five conditions and constructed a dataset for deep learning models training. Extensive experiments have shown that the EfficientNet-B4 network-based system achieved optimal performance. Landry and Akhloufi (2022) utilized the SVM and CNN to extract snow areas in the image. They built a model using surveillance cameras to estimate the percentage of the snow-covered road surfaces. To reduce the difficulty of model training and improve accuracy, Khan and Ahmed (2022) introduced a transfer learning method to apply several pre-trained CNN models for weather and road condition classification tasks. Lü et al. (2023) pre-processed the surveillance images through the road segmentation network to obtain the binary images to obtain the road image features. Subsequently, a convolutional neural network, composed of overall network branches and road network branches, was established and used to extract the overall image area features and focus on extracting the road weather features, respectively. Askbom (2023) first used CNN-based deep learning to determine the weather condition (mainly focusing on snow), then constructed a road condition classification deep learning network with the premise of road area has been extracted by the U-Net model. Additionally, in an innovative and impressive work, Carrillo and Crowley (2020) integrated roadside surveillance images and weather data from weather stations to improve the performance of road surface condition evaluation. The fusion of surveillance cameras and other observations provides novel insights for road weather identification.
However, there is still a period between the occurrence of rain or snow and the appearance of ponding or snow on the road surface. Thus, these indirect measurements are difficult to meet the needs of some applications with high real-time requirements. Moreover, the above methods will not work for those surveillance cameras with no road surface or other specific region as a reference in the observed area.
-
Direct measurement refers to identifying the SPT by the captured information of falling raindrops, snowflakes. For example, Zhao et al. (2011) classified weather conditions into steady, dynamic, and nonstationary and employed four direction templates to analyze the max directional length of motion blur caused by rain streaks or snowflakes. In this way, rain and snow can be distinguished from traffic cameras. After analysing the image features of different weather conditions, Li et al. (2014) adopted the decision tree to model the image features captured during different weather conditions and built an SVM classifier to predict the weather. Afterward, Lee (2017) proposed a more straightforward method, which used the histogram features of road images as metrics to discriminate fog and snow in road surveillance cameras. A serious CNN-based weather classification effort has been implemented with the development of a deep learning algorithm. Xia et al. (2020) took the residual network ResNet50 as the basis and proposed a simplified model for weather feature extraction and recognition on traffic roads. Sun et al. (2020) built a deeply supervised CNN to identify road weather conditions through the road surveillance system. Dahmane et al. (2021) constructed a deep CNN to differentiate between five weather conditions from traffic surveillance cameras, such as no precipitation, foggy, and rainy. Some advanced deep learning networks or methods like Attention and transformer were naturally introduced, such as Dahmane et al. (2018), who used CNN to identify rain, fog, and snow weather from road cameras and applied on large-scale from day to night through the learning transfer method. Wang et al. (2023b) built a Multi-Stream Attention-aware Convolutional Neural network to identify dust storm from city surveillance cameras. Chen et al. (2023) built a deep learning model that employs multiple convolutional layers to extract features from weather images and a Transformer encoder to calculate the probability of each weather condition based on these extracted features.
Compared to indirect measurements, direct measurements do not require road surface conditions as a reference and thus have a broader range of applications. That is, direct measure methods can also be deployed in non-traffic surveillance cameras, which are also adopted in this study.
2.2 In-vehicle cameras
Some researchers concentrated on recognizing weather conditions from images captured by in-vehicle cameras. For example, Kurihata et al. (2005) used image features from PCA to detect raindrops on a windshield and to judge rainy weather. Roser and Moosmann (2008) presented an approach that employed SVM to distinguish between multiple weather situations based on the classification of single monocular color images. Considering that lighting conditions have a significant impact on weather identification from vehicle-mounted imagery, Pavlic et al. (2013) used spectral features and a simple linear classifier to distinguish between clear and foggy weather situations in both day-time and night-time scenarios to improve the visual perception accuracy degradation of in-vehicle cameras in harsh weather and low light conditions. Additionally, CNN-based deep learning algorithms also have been employed (Dhananjaya et al., 2021; Triva et al., 2022). From the perspective of hardware, Zhang et al. (2022) mounted visible and infrared cameras in front of the car to collect day-time and night-time road images. After that, they proposed two single-stream CNN models (visible light and thermal streams) and one dual-stream CNN model developed to classify winter road surface conditions automatically. Samo et al. (2023) argued that a single image may include more than one type of weather. Then, they built a multilabel transport-related dataset of seven weather conditions and assessed different deep-learning models to address multilabel road weather detection tasks. In particular, sensing the transition between these extreme weather scenes (sunny to rainy, rainy to sunny, and others) is a significant concern for driving safety and is less of a concern. For this, Kondapally et al. (2023) proposed a way to interpolate the intermediate weather transition data using a variational autoencoder and extract its spatial features using VGG. Further, they modelled the temporal distribution of these spatial features using a gated recurrent unit to classify the corresponding transition state. In addition, Aloufi et al. (2024) treated weather classification and object detection as a single problem and proposed a new classification network, which integrated image quality assessment, Super-Resolution Generative Adversarial Network, and a modified version of the YOLO network. This work adds dust storm weather recognition, which has yet to be considered in previous research.

Figure 2Snow captured by different visual sensors: (a) snow captured by a traffic surveillance camera (Sun et al., 2020), (b) snow captured by an in-vehicle camera (Triva et al., 2022), (c) snow captured by a mobile phone camera (Xiao et al., 2021). Taking snow as an example, a comparison reveals the visual feature differences of precipitation events captured by these three different types of visual data.
However, weather visual data collected by In-vehicle cameras and that of surveillance cameras remain different. Take snow as an example, snow images captured by different visual sensors are presented in Fig. 2. Surveillance cameras are usually shot from an overhead view, while the in-vehicle cameras are mainly from a horizontal view. Different shooting angles result in images with different backgrounds. These efforts take a different perspective than surveillance cameras for weather recognition and provide substantial theoretical and methodological references and guidance for our study.
2.3 User-generated visual data
Here, the user-generated visual data means the pictures/videos taken by visual devices other than surveillance cameras (i.e., cell phones, digital cameras, and web cameras). Nowadays, with rapid dissemination on the Internet and social media platforms, visual data with spatial (geotags) and temporal (timestamps) information can collectively reveal weather information around the world. Based on this, researchers could collect user-generated visual data from the Internet or social media platforms for weather condition classification purposes. For example, Chu et al. (2017) used the random forest classifier to build a weather properties estimator; Zhao et al. (2018) propose to treat weather recognition as a multi-label classification task and present a CNN-RNN architecture to identify multi- weather-label from images; Wang et al. (2018) combine the real-time weather data with the image feature as the final feature vector to identify different weather; Guerra et al. (2018) explored using super-pixel masks as a data augmentation technique, considering different CNN architectures for the feature extraction process when classifying outdoor scenes in a multi-class setting using general-purpose images. Ibrahim et al. (2019) proposed a new framework named WeatherNet for visibility-related road condition recognition, including weather conditions. WeatherNet takes single-images as input and used multiple deep convolutional neural network (CNN) models to recognise weather conditions such as clear, fog, cloud, rain, and snow. Toğaçar et al. (2021) used GoogLeNet and VGG-16 models to extract image features and use them as input to construct a spiking neural network for weather classification; Xiao et al. (2021) proposed a novel deep CNN named MeteCNN for weather phenomena classification. Mittal and Sangwan (2023) extracted features using a pre-trained deep CNN model and used transfer learning techniques to build a weather classification framework to save the time and resources needed for the system to work and increase the reliability of the results.
In contrast, as shown in Fig. 2, user-generated visual data differs significantly from surveillance images/videos in terms of resolution, clarity, background content, etc., and the image characteristics of weather conditions may also differ. Therefore, there are considerable differences in the algorithm design ideas and result accuracy for determining the weather from web images and surveillance images.
Table 1 presents a comparison of surveillance camera-based weather classification/recognition algorithms. Since ordinary surveillance cameras differ in the images captured during daytime and nighttime, the working time is divided into daytime and nighttime (low-light scenarios are categorized as nighttime). Moreover, the weather types that can be recognized/classified are also listed. Combined with previous review and analysis, we can summarise:
-
In terms of working time: Existing studies mainly focus on weather condition in daytime, while that of nighttime is given little attention.
-
In terms of weather: It can be found from Table 1 that the existing works have not yet paid attention to the distinction of graupel, which is more challenging due to its similarity to rain and snow particles.
-
In terms of methodology: mainstream classification methods have shifted from traditional machine learning methods to deep learning methods. For data-driven deep learning methods, a wealthy and high-quality training dataset is the foundation for deep learning model construction. We are pleased to see some datasets for road weather being released (Karaa et al., 2024; Bharadwaj et al., 2016; Guerra et al., 2018). However, existing methods are primarily focused on single-image information. Compared to images, videos, which contain temporal dependencies between image frames, are seldom used, although this will help improve the accuracy of recognition results.
Table 1Comparison of surveillance camera-based weather classification/recognition studies.

Figure 3Comparison of rain, snow, and graupel in day and night surveillance images (Particles are labelled by red circles). Differences in image features such as brightness, color, and trajectory exhibited by rain, snow, and graupel in daytime visible light and nighttime near-infrared images, due to their varying optical properties, interactions with light, and terminal fall speeds.
Previous meteorological studies have explored the size, shape, brightness, and terminal velocity (mainly referring to the terminal velocity of particles during free fall near surface) of rain, snow, and graupel, providing an essential foundation for analyzing their visual characteristics. It is important to emphasize that in this study, graupel, also known as snow pellets, refers specifically to solid particles “consisting of crisp, white, opaque ice particles, round or conical in shape and about 2–5 mm in diameter” according to the World Meteorological Organization terminology (WMO, 2017). In this study, no mixed phase precipitation is considered. After analyzing a large number of surveillance videos, the distinctions between rain, snow, and graupel particles can be primarily summarized in terms of brightness and shape from the perspective of video observations. To enhance clarity, we present a comparison of these precipitation types in both visible and near-infrared video footage.
-
Brightness: Ordinary surveillance cameras take visible light video during the day and near-infrared video at night. Therefore, the brightness of the particles differs in the day and night-time images/videos. In the daytime, rain and graupel particles have strong forward reflections of visible light and appear brighter than the background. In contrast, snow appears in white; at night, the brightness of the three particles is similar, with little differentiation, as shown in Fig. 3.
-
Shape: Due to the long exposure time of surveillance cameras, rain, and graupel particles have a large deformation in surveillance images, usually appearing as lines. These lines describe the trajectories of rain and graupel particles. However, as shown in Fig. 3, meteorological studies have pointed out that, in general, the speed of graupel particles (Heymsfield and Wright, 2014; Kajikawa, 1975) is greater than that of rain (Montero-Martínez et al., 2009). In combination with the imaging principles of the camera, the trajectory of a graupel particle is longer than that of a raindrop particle of the same size in the same surveillance camera. Moreover, rain has a greater number concentration value (the number of particles per unit volume) (10–104 m−3) than graupel (1–10 m−3) (Zhang, 2016). That is to say, the number of raindrops in the surveillance images is denser compared to graupel. And snow particles have less shape change due to their slower falling speed (≤1 m s−1) (Vázquez-Martín et al., 2021). Overall, the length of rain is wider and shorter than that of graupel, while snow is the shortest.
The analysis shows that distinguishing snow is relatively straightforward, given the significant differences in brightness, shape, and terminal velocity when compared to that of rain and graupel. However, the primary challenge of this study lies in differentiating between rain and graupel. While there are notable differences in their number concentrations, rain and graupel share similar speeds, shapes, and brightness, which complicates accurate differentiation. Traditional hand-crafted features fall short in capturing the subtle distinctions between rain and graupel particles, making it necessary to employ deep learning features. Furthermore, accurate classification requires not only spatial features from images but also temporal features from video sequences.
In practical applications, the timeliness of precipitation data extracted from surveillance videos is essential to ensure the value of the data. With the widespread availability of high-definition, full high-definition, and ultra-high-definition surveillance cameras, video resolution is continuously improving, leading to rapid increases in surveillance data volume. In this context, where numerous cameras generate massive amounts of real-time data, it is vital to consider not only memory and computational resources but also the speed and efficiency of the SPT recognition algorithm, alongside accuracy, for effective processing.
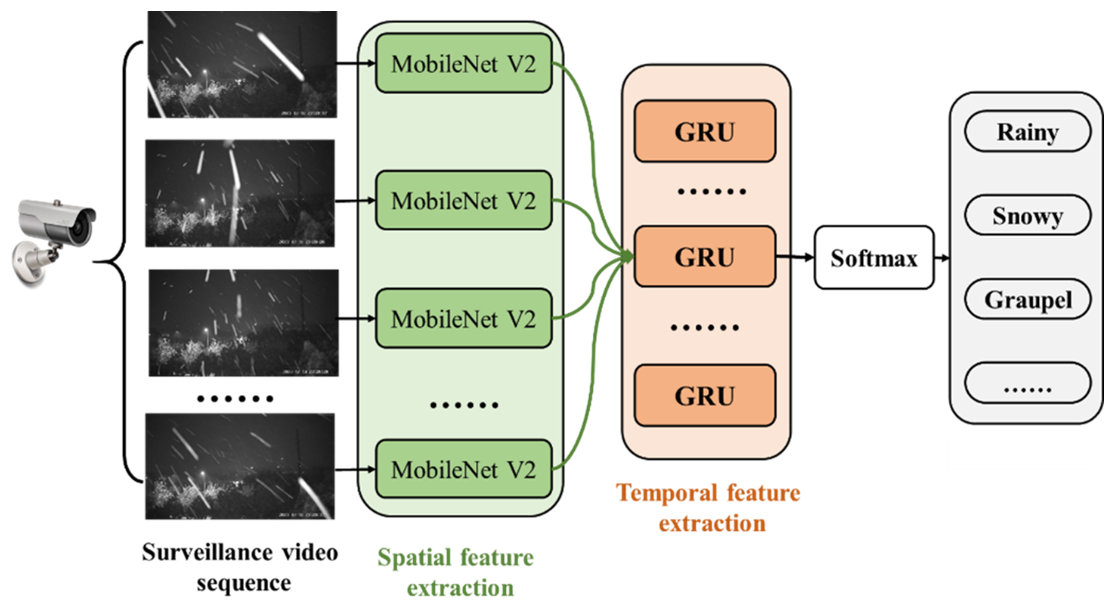
Figure 4The structure of the surveillance camera-based SPT identification system. Frames are selected from the surveillance video and fed into the spatial feature extraction module. The extracted spatial feature vectors are then aggregated and input into a temporal feature extraction module composed of GRUs, enabling the differentiation of SPT.
3.1 SPT classification model construction
In this section, surveillance video-based SPT identification is approached as a video classification task. To balance accuracy, computational speed, and computational load in designing the SPT classification algorithm, a deep learning model that integrates MobileNetV2 and GRU is proposed. First, a pre-trained MobileNetV2 model based on ImageNet is adapted for spatial feature extraction using a transfer learning strategy, enabling it to capture differences between surveillance images from various SPT events. These features are then fed into a GRU network to model the long-term dynamics of the surveillance video sequence. The structure of the surveillance camera-based SPT identification system is illustrated in Fig. 4. The surveillance video is divided into 5 s segments. Within each segment, sequences of 5, 10, and 15 frames are selected and fed into the spatial feature extraction module (the effect of sequence length on the classification results is discussed in Sect. 4.4). The extracted feature vectors are then input into the temporal model for precipitation type classification.
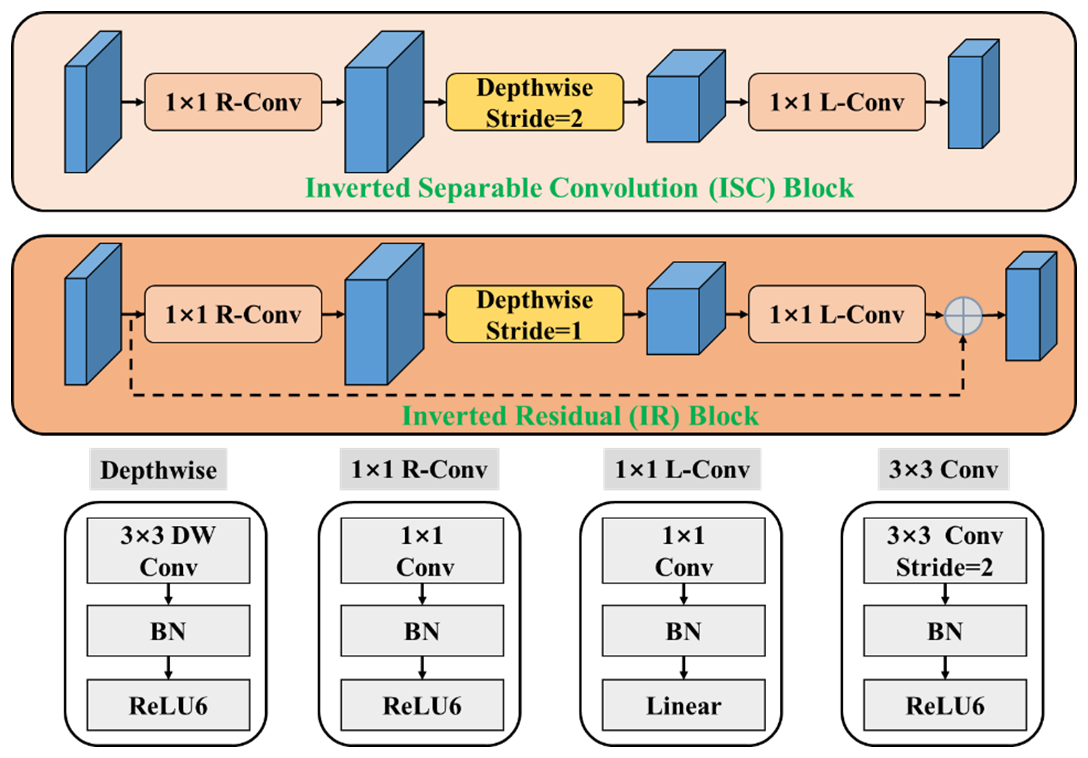
Figure 5The structure of the inverted separable convolution (ISC) block and inverted residual (IR) block.
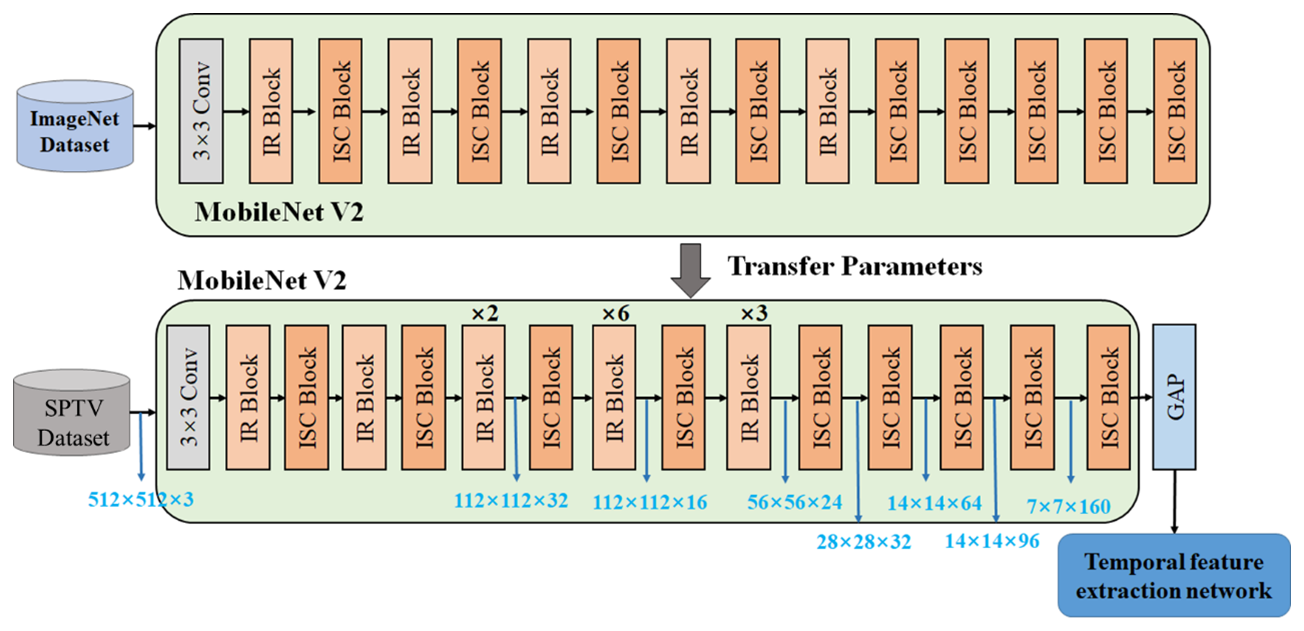
Figure 6The structure of MobileNet V2 backbone network. The spatial feature extraction module, based on MobileNet V2, is initially trained on the ImageNet dataset to leverage its large, diverse image data for general feature extraction. Subsequently, transfer learning is applied, and the model is fine-tuned on our constructed PPSV dataset, allowing it to adapt to the specific characteristics of precipitation-related images in our study.
3.1.1 Spatial feature extraction model
As analyzed previously, the primary distinctions between rain, snow, and graupel in surveillance images are reflected in their brightness, shape, and number concentration. The role of the spatial feature extractor is to identify and capture these differences from surveillance images captured during both daytime and nighttime conditions. MobileNetV2, a lightweight framework, is widely used for visual object classification, recognition, and tracking tasks, offering an effective trade-off between accuracy and model efficiency in terms of size and computational speed. These advantages align well with the requirements for spatial feature modelling of various SPT particles, making MobileNetV2 the chosen backbone for the spatial feature extraction model. MobileNetV2 builds upon MobileNetV1 and is based on two primary components: the inverted separable convolution (ISC) block and the inverted residual (IR) block.
-
ISC block: This block utilizes a 1×1 convolution with batch normalization and a ReLU6 activation function (1×1 R-Conv) to expand the number of channels in the input feature map. It then calculates the feature maps through depth-wise convolution (DW), after which the number of channels is reduced using a linear 1×1 convolution.
-
IR block: Built upon the ISC block, this block reduces the stride of the DW convolution to 1, maintaining the feature map size before and after processing. It also incorporates a shortcut connection between each residual block, similar to the residual network structure (He et al., 2016). This setup allows the feature maps following the 1×1 linear convolution (1×1 L-Conv) to be added to the input feature maps, completing the calculation of the residual feature maps. The structures of the ISC and IR blocks are shown below.
Figure 6 presents the architecture of the existing MobileNet V2 backbone model. Here, we set the input size of the MobileNet V2 to , and output seven groups of feature maps of different sizes, from to , to the temporal feature extraction model for feature fusion processing.
Transfer learning involves leveraging knowledge from one task to inform another, eliminating the need for feature extractors to be trained from scratch. This approach accelerates training, reduces the risk of overfitting, and enables the construction of accurate models more efficiently. Previous research has shown that pre-trained models, developed using extensive datasets like ImageNet, offer an excellent foundation for new tasks where dataset size is limited. Consequently, the final two layers of MobileNetV2 were removed and replaced with global average pooling (GAP), batch normalization (BN), and temporal feature extraction layers (detailed in Sect. 3), including GRU layers. Finally, the pre-trained MobileNetV2, fine-tuned on the ImageNet dataset, was adapted through transfer learning to extract spatial features of SPT from surveillance images.
3.1.2 Temporal feature extraction model
Another critical indicator for differentiating between rain, snow, and graupel particles is their varying falling velocities, as illustrated in Fig. 7 (Zhang, 2016). While such differences are challenging to detect in single images, they become much more pronounced in video sequences. Consequently, the temporal feature extractor builds upon the spatial feature extractor by capturing the temporal dependencies between adjacent frames, thereby enabling the modeling of falling velocities for rain, snow, and graupel particles. Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM), and Gated Recurrent Units (GRU) are widely recognized networks for learning temporal dependencies, effectively leveraging contextual information. This capability is particularly valuable in tasks such as natural language processing, video classification, and speech recognition. RNNs apply recurrent operations to each element in a sequence, where the current computation is influenced by both the current input and previous states. However, traditional RNNs are prone to the vanishing and exploding gradient problems, which limit their effectiveness in capturing long-term dependencies, confining them mostly to short-term dependencies. To address these limitations, variants such as LSTM and GRU were introduced. These networks are specifically designed to capture long-term dependencies. The GRU, a streamlined version of LSTM, features fewer parameters, making it more efficient in terms of memory usage and computational speed. A GRU consists of three primary components: the update gate, the reset gate, and the current memory gate.
-
Update gate: Controls the extent to which previous information is retained and carried forward to future states (Eq. 1).
-
Reset gate: Determines the amount of past information that should be discarded (Eq. 2).
-
Current memory gate: Computes the current state by integrating the previous hidden state with the current input (Eq. 3). The final memory is determined as described in Eq. (4).
where, Wz, Wr, and W are learnable weight matrices, ht−1 is the previous hidden state, xt is the input vector, σ and tanh are the sigmoid and tanh activation function, ∗ represents the Hadamard product, and bz, br and b are biases.
After extracting spatial features, they are input into a GRU layer with 93 hidden units to capture temporal dependencies. The outputs from the GRU layer are concatenated and passed through a dense layer. Following the dense layer, a batch normalization layer is applied, which is subsequently connected to a fully connected output layer. This final layer uses a SoftMax activation function to classify the SPT event from the surveillance video sequence. The spatial feature map has an input shape of 1280×N, where N represents the length of the video sequence utilized for temporal dependency modeling. The impact of different values of N on the accuracy of SPT classification is analyzed in Sect. 4.4.
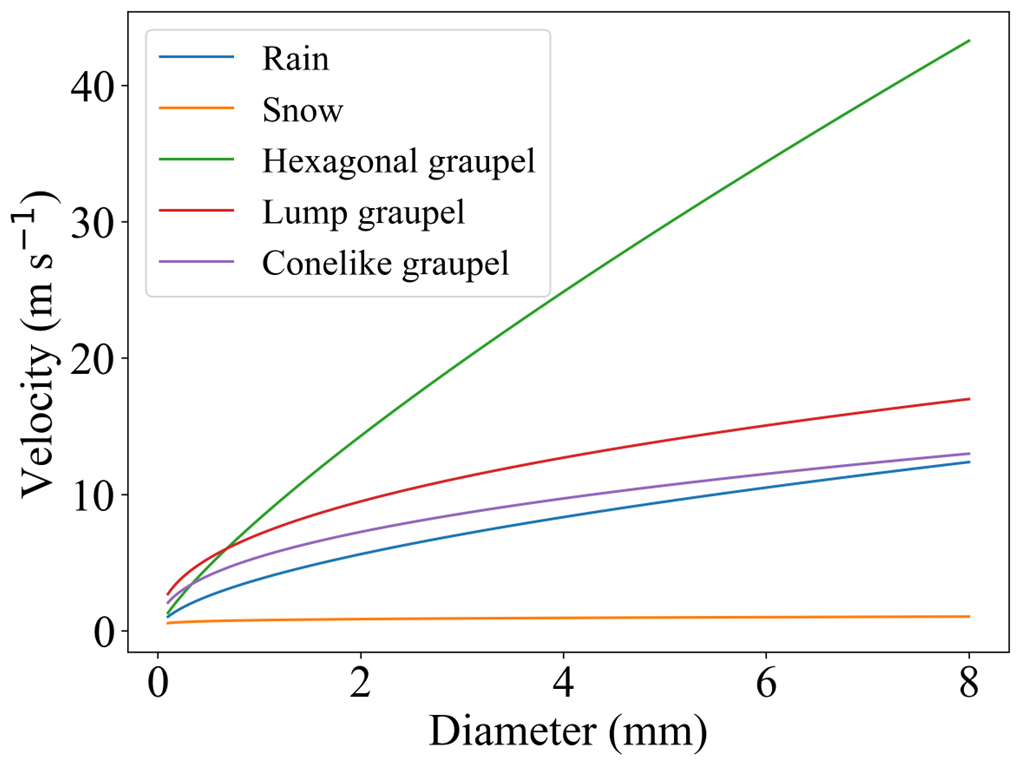
Figure 7Comparison of terminal velocities of different particles. The differences in fall velocities among different precipitation particles (rain (Atlas et al., 1973), snow (Brandes et al., 2007), graupel (Kajikawa, 1975; Magono and Lee, 1966)) serve as an important basis for constructing our temporal feature extraction module. It is important to note that this study primarily focuses on solid graupel particles.
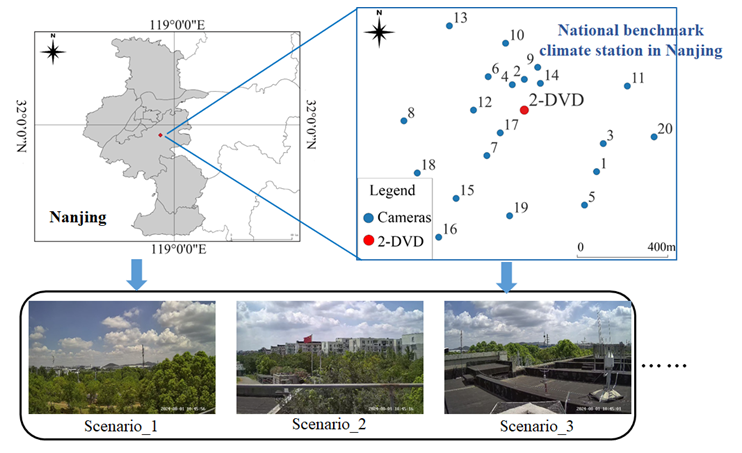
Figure 8Overview of the study area. Due to space limitations, we only present the scenes captured by three surveillance cameras. The use of a variety of 20 surveillance cameras deployed in different places ensures the dataset's diversity and generalizability, enhancing the model's applicability and reliability in real-world scenarios.
3.2 Dataset building
For training and testing the deep-learning model, a new SPTV dataset was constructed. As illustrated in Fig. 8, 20 surveillance cameras were deployed at the National Benchmark Climate Station in Nanjing, Jiangsu, China. Of these, videos from 17 cameras (IDs 4 to 20) were utilized to build the dataset, while the remaining 3 cameras (IDs 1 to 3) were reserved for real-world precipitation observation experiments, as discussed in Sect. 4.5.
Considering the broad range of potential applications, the deployed urban surveillance cameras exhibit substantial variation in parameters, including resolution (960×720, 1280×960, 1920×1080, 2592×1944), focal length (4, 6, 8, 12 mm), and frame rate (15, 20, 25 fps). This diversity ensures that the collected video data reflects real-world surveillance conditions, thereby minimizing the gap between the performance of the deep-learning model on the SPTV dataset and its applicability in real-world scenarios.
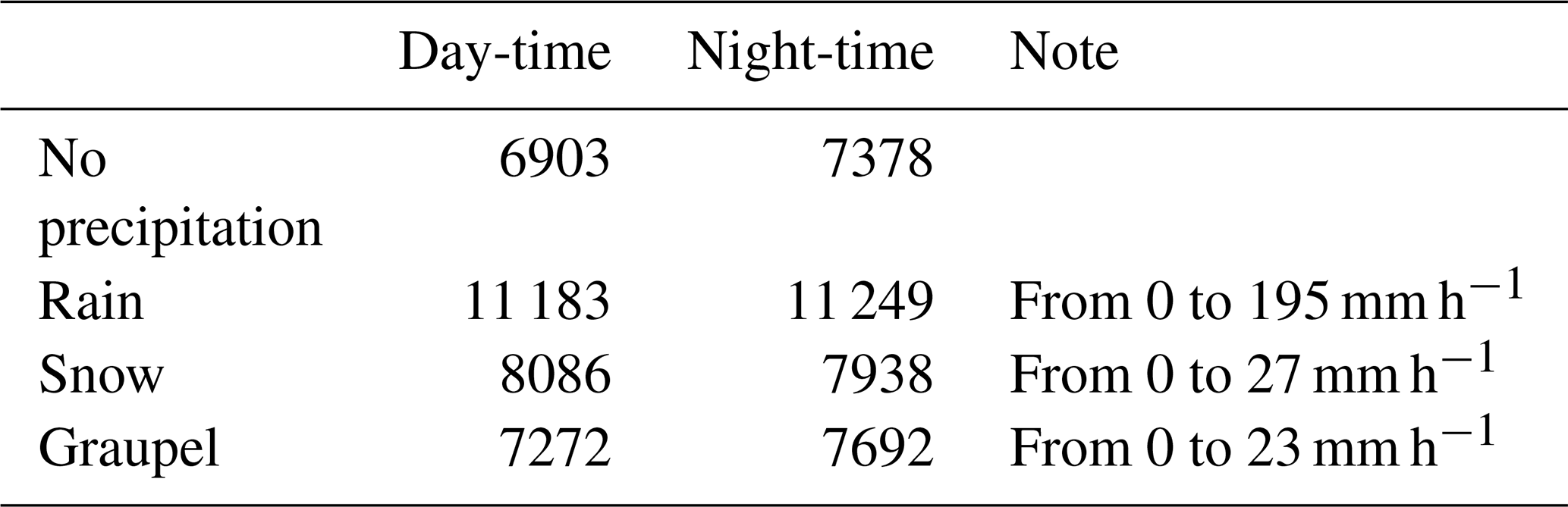
After a long period of observation (starting from March 2023 and ending in July 2024), we captured a huge amount of surveillance video data for different SPTs. During this period, we captured extreme precipitation surveillance videos such as snowstorms with intensities of 27 mm h−1 and heavy rainfalls of 195 mm h−1. These rare and precious precipitation scenarios play an important role in improving the generalization and diversity of our dataset. Finally, about 94 h of surveillance videos from day to night were selected and categorized into four categories: rainfall, snowfall, graupel, and no precipitation. The videos were divided into segments, each of which was 5 s in length, with a frame rate ranging from 15–25 fps, and were saved in .mp4 format. More details can be found in Table 2.
In addition, the Two-Dimensional Video Disdrometer (2-DVD), a professional precipitation measurement instrument, works in synchronization with the surveillance cameras to provide the true value/label of the SPT for the surveillance videos. Simultaneous observations by researchers are also conducted, and their observed data are used to refine the 2DVD measurements, ensuring the accuracy of the true value/label of SPT. The precipitation intensity values are calculated every minute. Therefore, the values in Table 2 refers to the precipitation intensity during a 1 min period, not an hourly intensity. The maximum distance between the 2DVD and the camera is 1 km, which ensures that the SPT observed by the two is the same.
Table 2Description of the SPTV dataset. Each video clip with length of 5 s.
4.1 Experimental environment
Our experiments were performed on a workstation with Ubuntu 11.2.0 (Linux 5.15.0-25-generic) for the operating system. More specifications are as follows:
-
4× Intel Xeon Silver 4216 CPU@2.10 GHz (32 cores);
-
8× NVIDIA GEFORCE GTX2080Ti graphics cards equipped with 11 GB GDDR6 memory;
-
188 GB RAM;
-
Python 3.9.16;
-
TensorFlow 2.4.1, Scikit-learn 1.2.1, and Keras 2.4.3 libraries;
-
CUDA 11.8 and CUDNN 8
4.2 Evaluation metrics
To evaluate the SPT classifiers, we selected 3 different established metrics: the balance accuracy, weighted precision, and weighted recall. The balance accuracy metric (Accuracy) is described as:
where TPi and Si stand for the number of True Positive and sample size of class i, respectively.
The weighted precision metric (Precision) can be calculated as follows:
where FPi is the number of False Positive of class i and ri is the ratio between the number of samples of class i and the total number of samples.
The weighted recall (Recall) is calculated as follows:
4.3 Model training details
The SPTV dataset was split into training, validation, and test datasets according to the ratio of . Training and validation sets were employed to construct the deep learning model. To analyze the performance of the proposed method, some classical CNN models with ImageNet pre-trained weights such as: DenseNet 121 (Huang et al., 2017), EfficientNet B0 (Tan and Le, 2019), Inception V3 (Szegedy et al., 2016), and ResNet 50 (He et al., 2016) are used to extract the spatial features of precipitation images, while some commonly used neural networks for temporal signal analysis like RNN, LSTM, 1D-CNN (Kiranyaz et al., 2021), and Bi-LSTM (Huang et al., 2015) are employed to extract the temporal features of precipitation surveillance videos, respectively. In terms of realization, transfer learning is exploited, and the last layer of each spatial extraction architecture (i.e., the fully connected (FC) and Softmax layers) was deleted and replaced with two layers: GAP and BN, to extract the deep spatial features based on transfer learning. Second, the spatial features were sent to temporal feature extraction networks listed above. The Softmax function was used as a classifier to identify SPT. Thus, a total of 25 deep-learning algorithms are constructed and compared. The hyper-parameters deep-learning models were set as listed in Table 3.
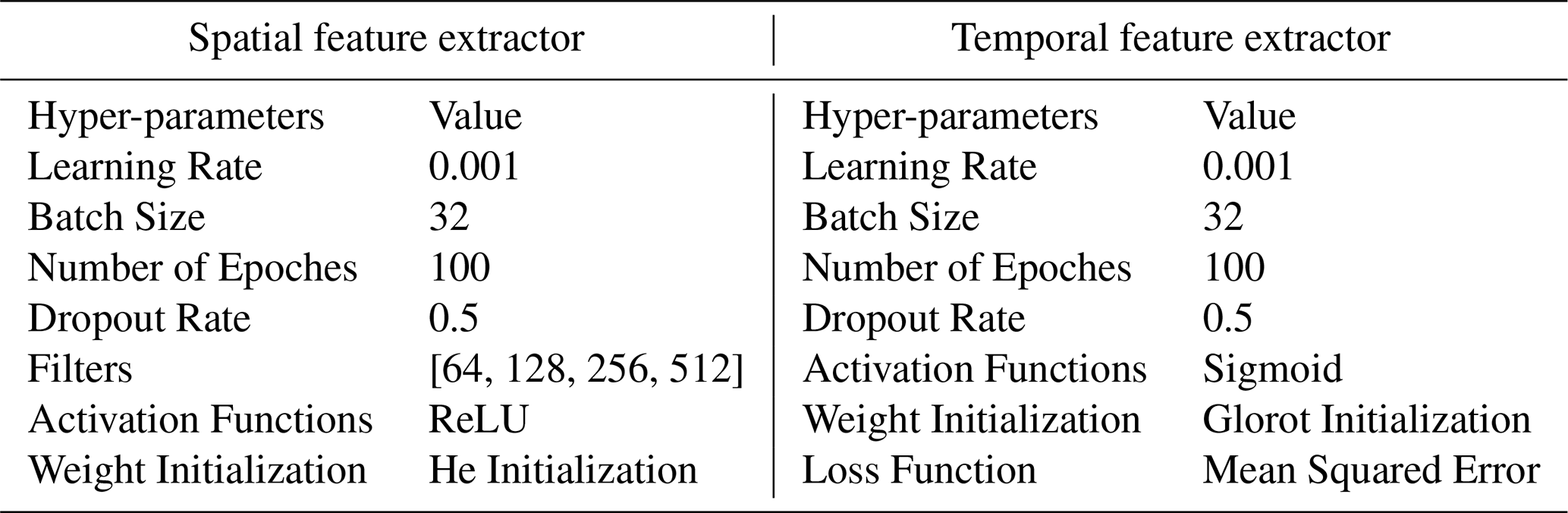
4.4 Experiments on the SPTV dataset
Given the length of the input frames on the temporal feature extraction, we evaluated the performance of different algorithms when screening 5, 10, and 15 frames per second from the video clips for comparison. The results of different numbers of frames per second (NFS) as input to temporal feature extraction are shown in Tables 4, 5, and 6, the bold black entries indicate relatively better performance.
Table 4Comparison of SPT recognition by different deep-learning algorithms (NFS =5). The bold entries indicate relatively better performance.
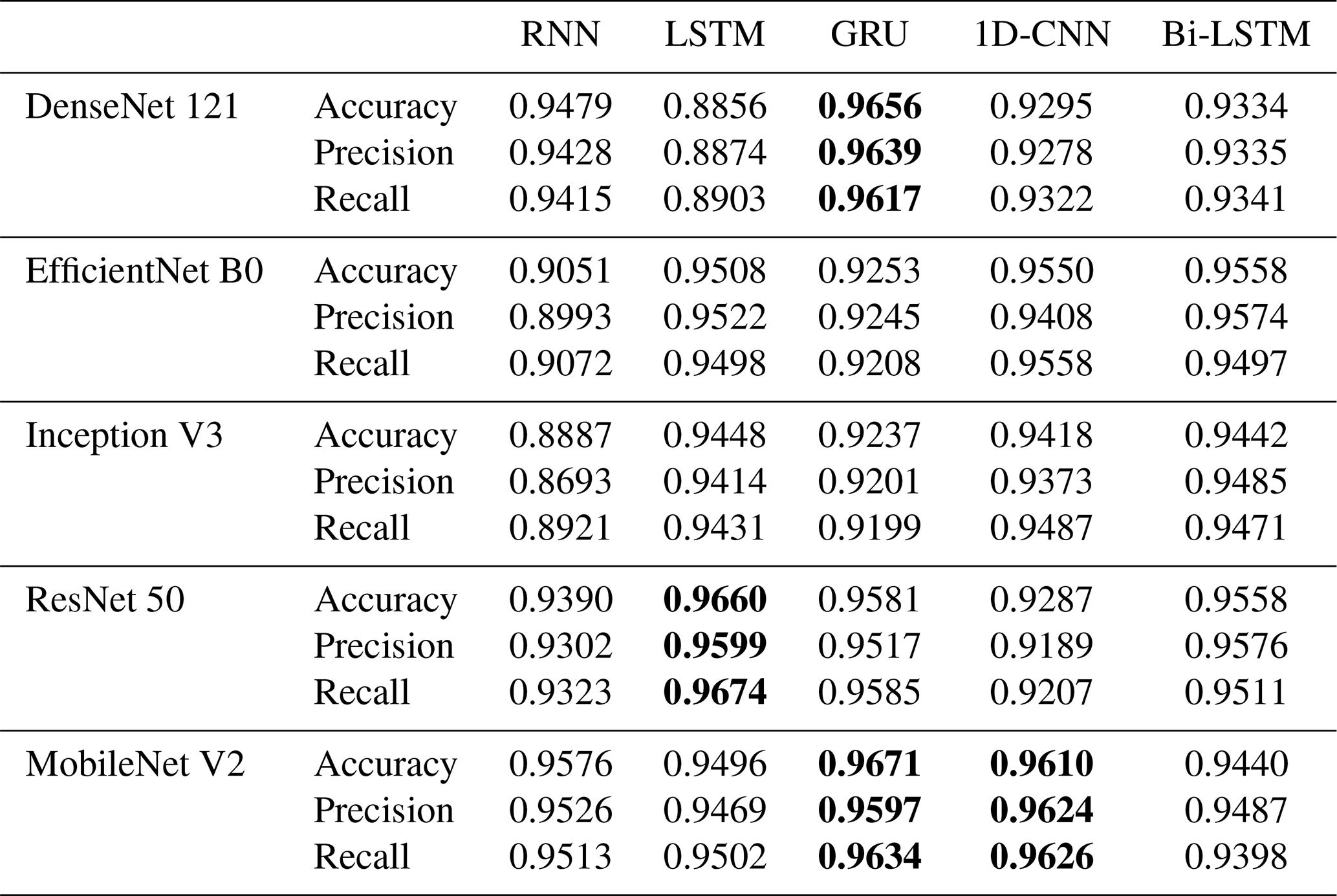
Table 5Comparison of SPT recognition by different deep-learning algorithms (NFS =10). The bold entries indicate relatively better performance.
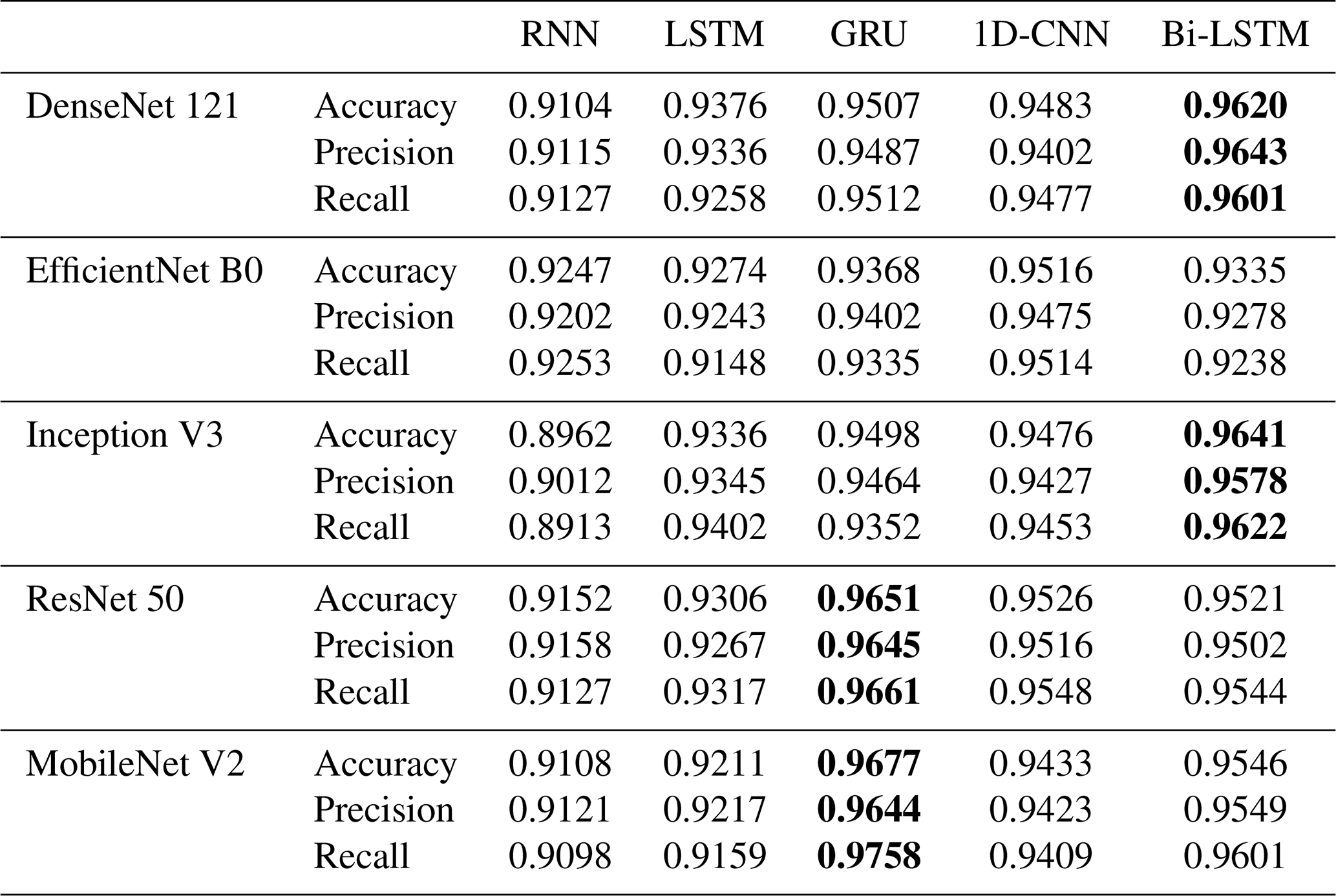
Table 6Comparison of SPT recognition by different deep-learning algorithms (NFS =15). The bold entries indicate relatively better performance.
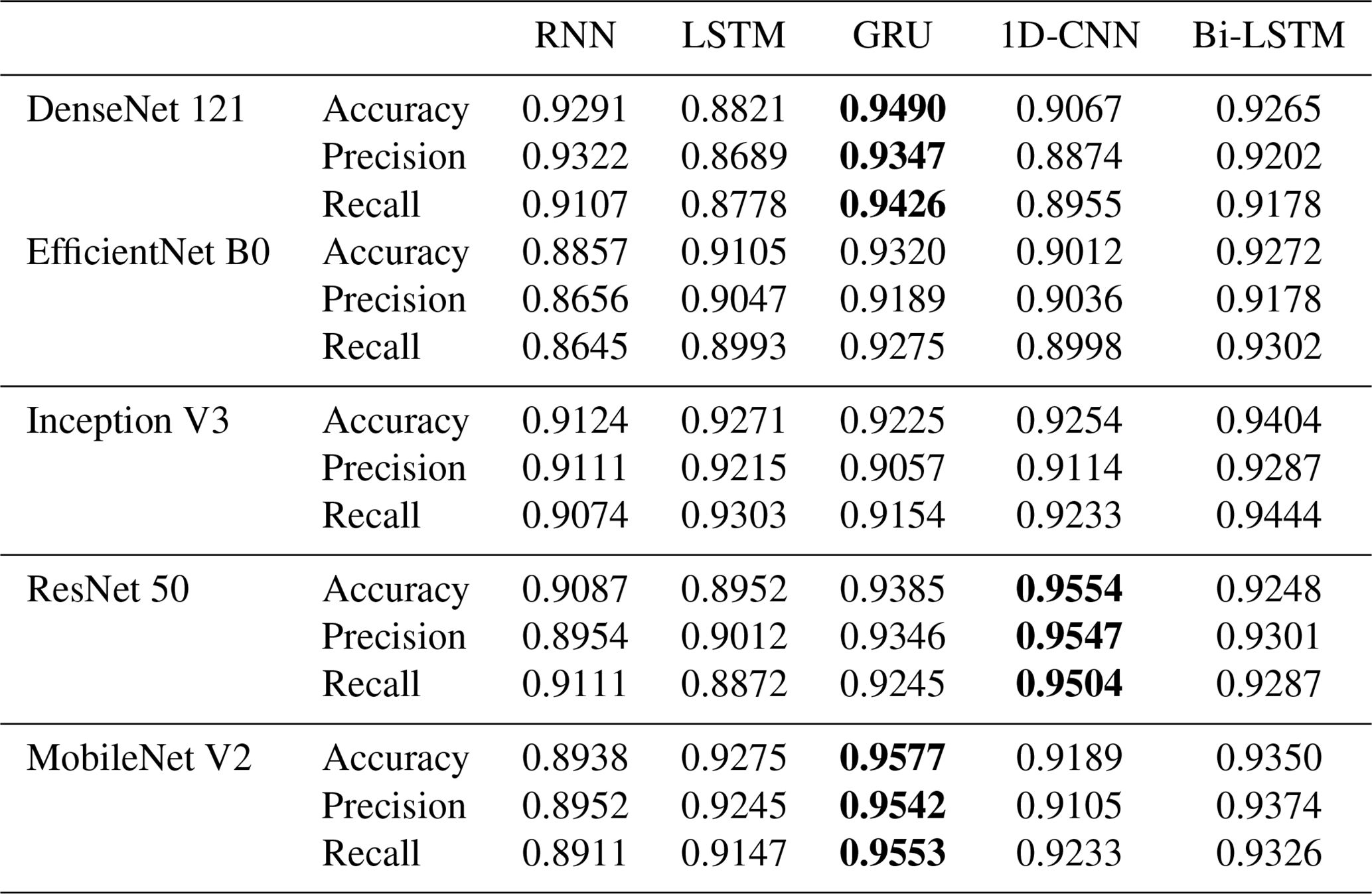
The results indicate that when the number of frames (NFS) is set to 5, the accuracy of our proposed method closely aligns with those of the DenseNet 121+GRU, ResNet 50+LSTM, and MobileNet V2+1D-CNN models. When the NFS is increased to 10, the performance of our proposed method, DenseNet 121+Bi-LSTM, Inception V3+Bi-LSTM, and ResNet 50+GRU converges, showing minimal differences in classification accuracy, which ranges from 0.960 to 0.967. However, with NFS at 15, the accuracy of our proposed method surpasses that of DenseNet 121+GRU and ResNet 50+1D-CNN models, though it slightly declines to approximately 0.949 to 0.957.
The observed improvement in deep learning model performance when increasing NFS from 5 to 10 frames can be attributed to the enriched temporal features provided by the additional frames. These features enhance the models' ability to differentiate between various SPTs. Nonetheless, when the NFS reaches 15 (equivalent to 75 frames per video clip), the lengthier temporal sequences challenge the RNN and 1D-CNN architectures, resulting in reduced classification accuracy. In contrast, the GRU architecture, with its more compact structure and computational efficiency, facilitates faster aggregation during training on the SPTV dataset, allowing it to sustain high accuracy even with longer NFS. Our proposed algorithm demonstrates classification accuracies of 0.9671, 0.9677, and 0.9577 across the three experimental settings, thereby exhibiting consistently superior stability compared to other methods.
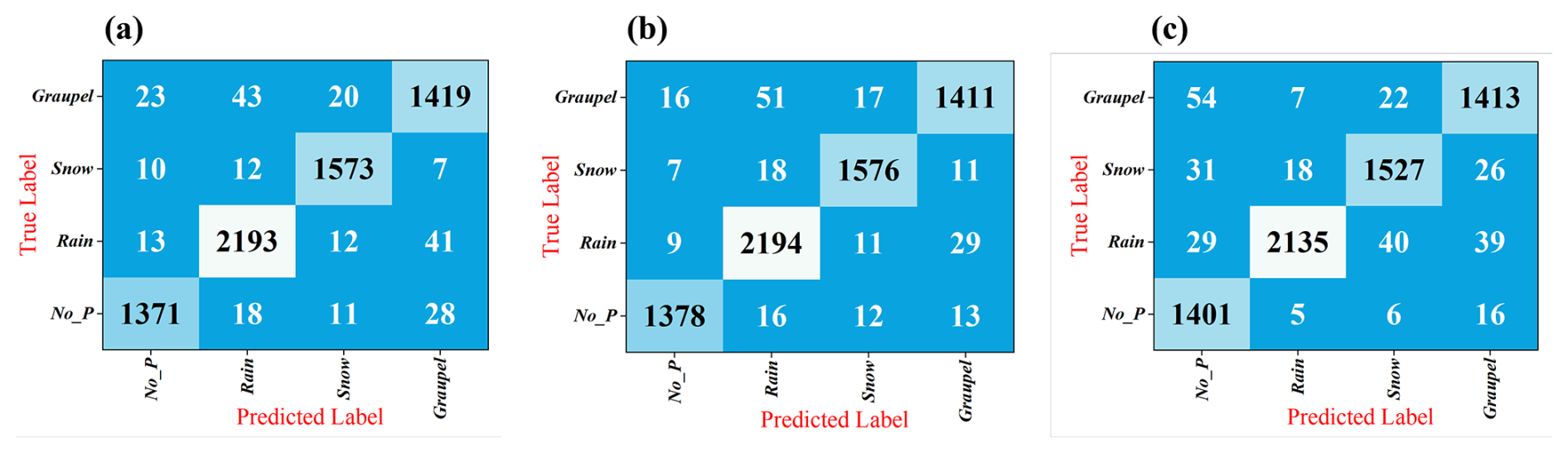
Figure 9Confusion matrix of proposed algorithm: (a) NFS =5, (b) NFS =10, (c) NFS =15. No_P means No precipitation. The three subplots share the same legend on the far right.
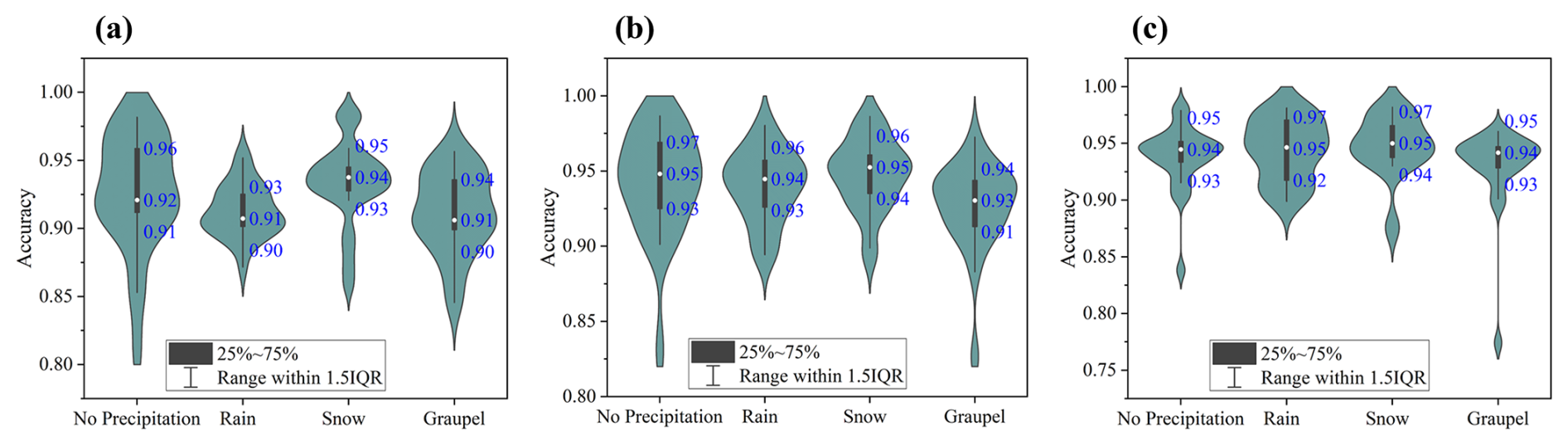
Figure 10Violin plots quantify the deep-learning algorithms' performance for SPT classification: (a) NFS =5, (b) NFS =10, (c) NFS =15.
To further assess model performance, confusion matrices are utilized as visual tools, elucidating the relationship between actual and predicted classifications. Figure 9 presents the confusion matrices for our proposed deep learning models on the SPTV dataset, detailing SPT discrimination capabilities (confusion matrices for comparison models are provided in Appendix A). In these matrices, columns denote true labels, while rows represent predicted classifications by different algorithms. Additionally, violin plots in Fig. 10 quantify the SPT classification performance across models, providing further insight into the comparative strengths of each approach.
Overall, the classification accuracy of above listed algorithms is slightly higher for “no precipitation” and “snow” conditions compared to “rain” and “graupel.” The confusion matrices indicate that the primary source of misclassification among the algorithms lies in differentiating between “rain” and “graupel” events. This issue arises due to the distinct shape, color, and falling velocity of snow particles, which starkly contrasts with rain and graupel, thereby making snowy conditions easier to classify. As discussed in Sect. 3, both “rain” and “graupel” share similar visual and temporal characteristics in both daytime visible and nighttime near-infrared videos, posing significant challenges for the classification algorithms.
Furthermore, Fig. 9 illustrates occasional misclassification between “no precipitation” and other SPTs. Upon analysing the SPTV dataset, it was observed that these errors typically occurred during low-intensity precipitation events, where only a minimal number of rain, snow, or graupel particles were present. While the 2-DVD device – known for its high sensitivity – can detect such subtle precipitation events, capturing these minute particles in surveillance videos remains challenging, particularly when affected by lighting conditions and external environmental factors within the camera's field of view.
Our proposed method effectively balances temporal and spatial features in precipitation surveillance videos, achieving classification accuracies for “no precipitation,” “rain,” “snow,” and “graupel” of 0.9454, 0.9652, 0.9657, and 0.9439, respectively, at NFS =5. The accuracies improve to 0.9713, 0.9795, 0.9775, and 0.9438 at NFS =10, and 0.9811, 0.9519, 0.9532, and 0.9445 at NFS =15. These results demonstrate our algorithm's consistently high and balanced accuracy across all SPTs, with NFS =10 being the optimal setting. This configuration has been adopted for real-world precipitation observation experiments, as detailed in Sect. 4.5.
4.5 Real-world experiments
Next, we evaluate the performance of the proposed method in real precipitation scenarios. The 2-DVD measurements, calibrated through simultaneous observations by researchers, are used as the true value to validate the effectiveness of the verification method. Here, six precipitation events are selected, including three types of precipitation scenarios: rain, snow, and shrapnel from day-time to night-time, and the duration of each precipitation event is 2 h. More details about each precipitation event are presented in Table 7. Considering the impact of wind on the trajectory and falling speed of precipitation particles, we have taken further measures to enhance the robustness and accuracy of the model. Specifically, we installed an anemometer next to the surveillance camera to capture real-time changes in wind speed and direction. This measure provides the model with relevant wind field data to better account for wind interference when predicting SPT. Since the orientation of the surveillance camera is generally fixed, the wind direction data collected by the anemometer can be combined with the camera's viewpoint to calculate the relative orientation of the wind to the camera lens.
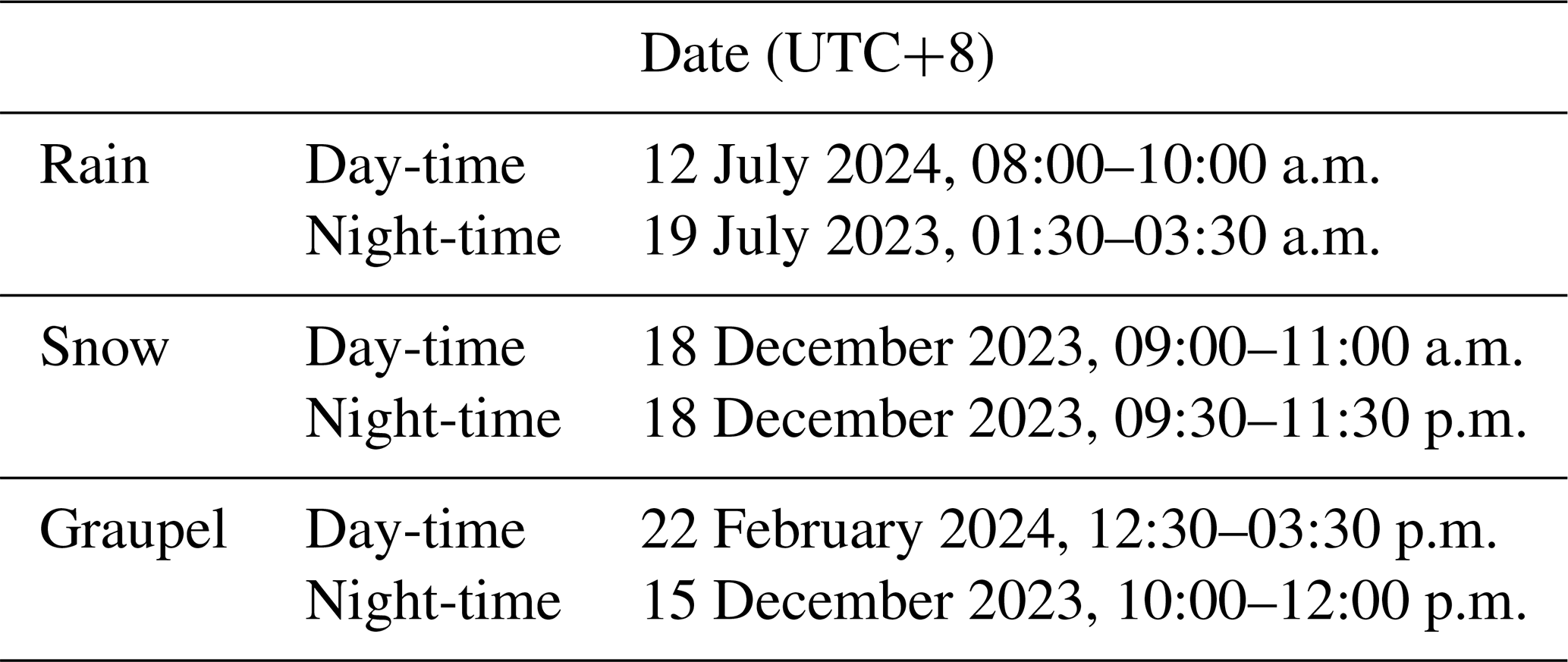

Three surveillance cameras (ID: 1, 2, and 3, as shown in Fig. 8) are used for real-world precipitation observation experiments. The key parameters of these three EZVIZ C5 series cameras are as following:
-
image resolution: 2592×1944, 1920×1080, 1280×960;
-
focal lengths: 4, 6, and 8 mm;
-
frame rate: 15, 20, 25 fps;
The three selected surveillance cameras simultaneously recorded the same precipitation event, although each camera captured a different scene. This arrangement supports the stability analysis of the deep learning algorithm. The field of view of the three cameras is shown in Fig. 11.
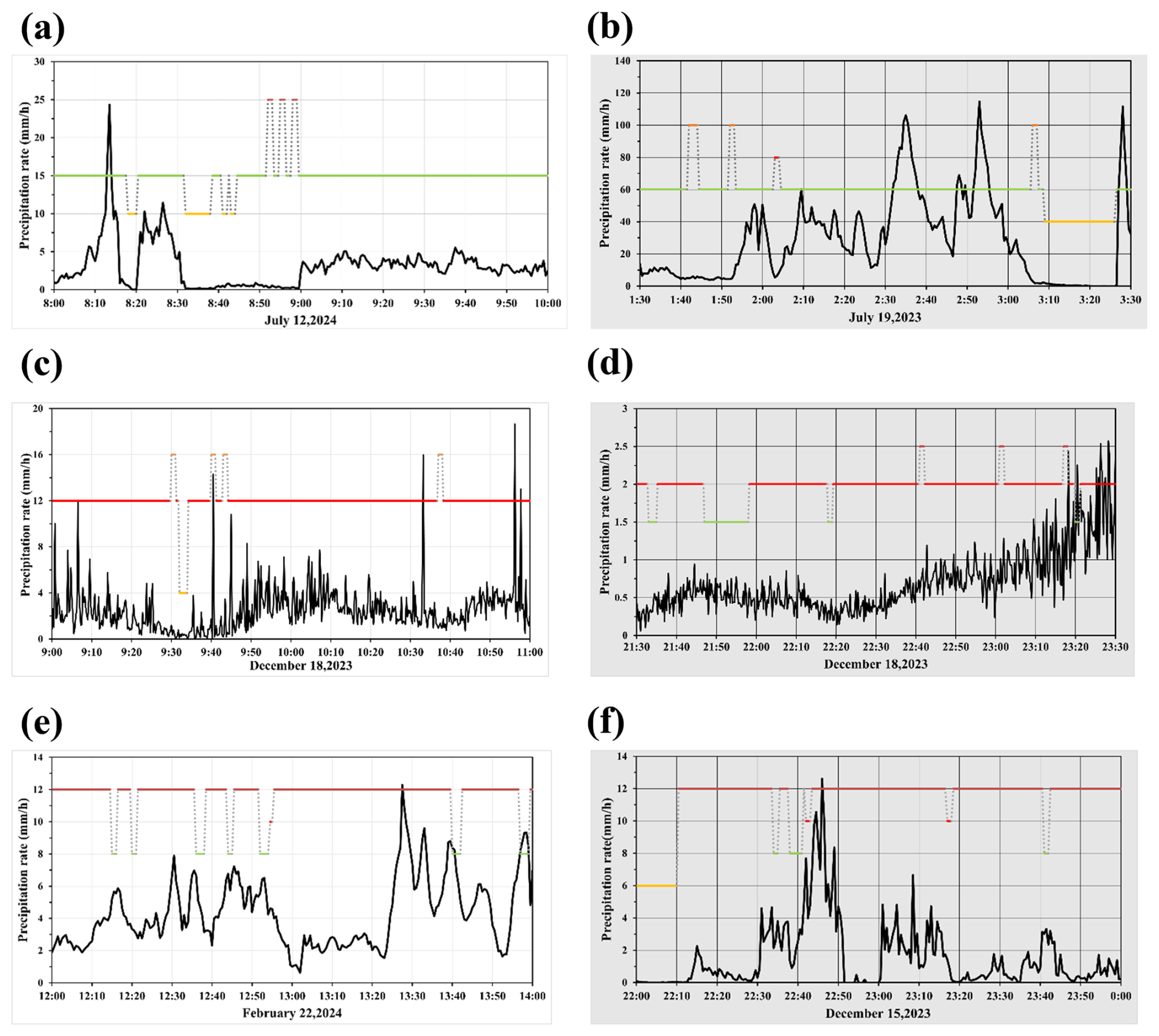
Figure 12Real-world SPT classification in camera_1: (a) Day-time rain, (b) Night-time rain, (c) Day-time snow, (d) Night-time snow, (e) Day-time graupel, (f) Night-time graupel. The black curve represents the precipitation intensity readings from the 2-DVD. The meanings of the lines represented by different colors are as follows: green: rain; red: snow; brown: graupel; yellow: no precipitation.
In line with the findings presented in Sect. 4.4, surveillance videos were processed by the model with a 5 s interval between frames, capturing 10 frames per second (NFS =10) for temporal feature extraction. The classification performance for various SPTs from Camera_1 is illustrated in Fig. 12, while the results from Camera_2 and Camera_3 are provided in Appendix B. In practical applications, the occurrence of false alarms significantly reduces the effectiveness of SPT recognition system. Therefore, the “no precipitation” label was also included in the evaluation. More detailed experimental results can be found in Table 8.
Table 8Identification accuracy of the proposed method for real-world SPT.
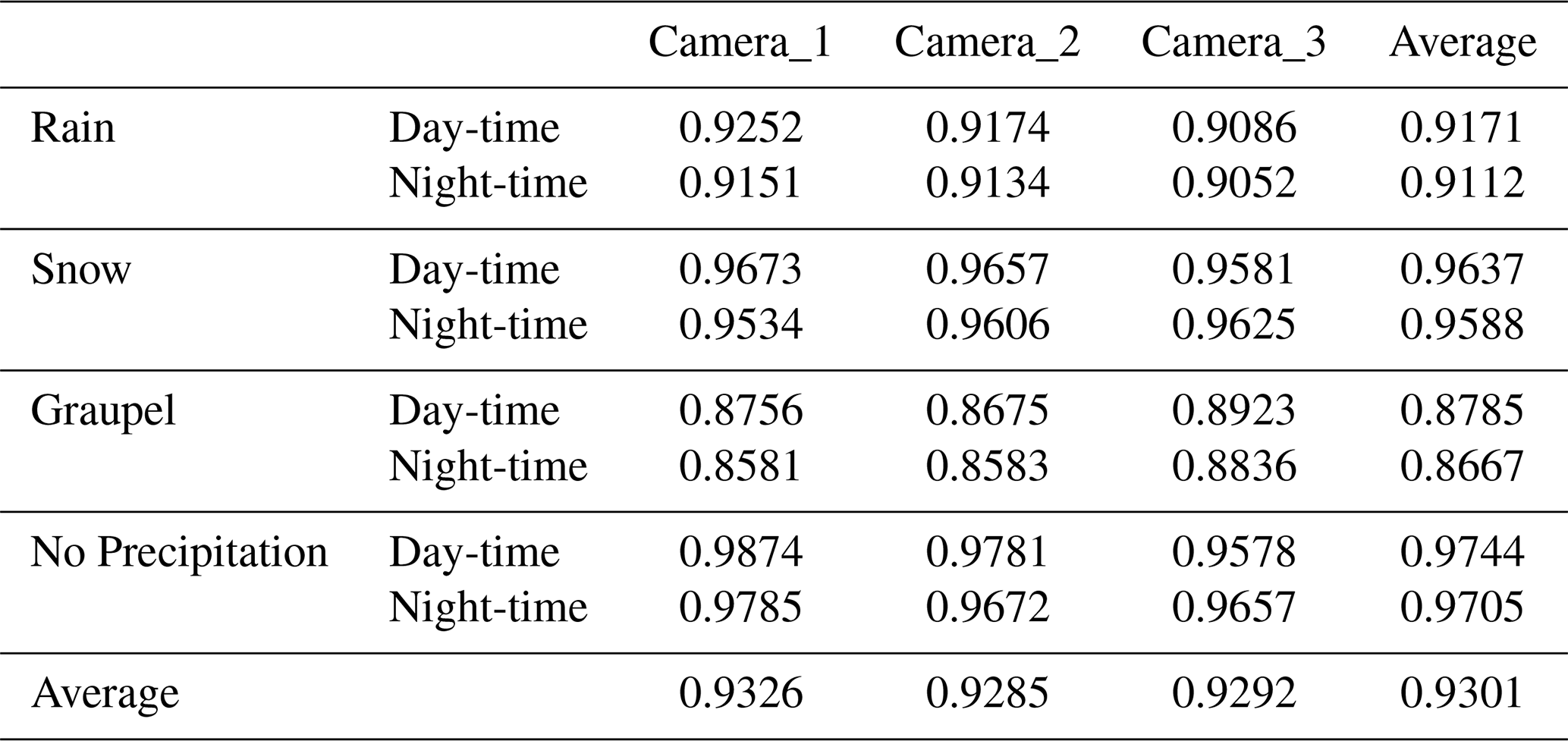
In real-world precipitation observation experiments, the proposed method achieves an average classification accuracy of 0.9301. Specifically, under daytime conditions, the method achieves classification accuracies of 0.9171, 0.9670, 0.8785, and 0.9744 for “no precipitation”, “rain”, “snow”, and “graupel”, respectively. Under nighttime conditions, the corresponding classification accuracies are 0.9112, 0.9225, 0.8667, and 0.9705. Overall, the classification accuracies for “rain” and “graupel” are comparatively lower, which aligns with the results observed in the SPTV dataset. Upon further analysis, many misclassifications occur when precipitation intensity is low, often being misidentified as “no precipitation”. This is likely due to the fact that under low precipitation intensity, the number concentration of the precipitation particles is small, making them difficult to detect in both daytime and nighttime videos. This issue is also supported by the data shown in Fig. 12 and Appendix B, where low-intensity precipitation events are hard to identify. As analysed in Sect. 4.4, the validation data used in this study mainly comes from the 2-DVD, which captures falling precipitation particles using a linear array scanning method, offering a high sensitivity to precipitation particles (Kruger and Krajewski, 2002). This allows the 2-DVD to detect precipitation events even at low particle concentrations, while such events may be missed in the surveillance video due to frame rate limitations or lighting conditions. This discrepancy leads to misclassification of some precipitation events as “no precipitation”. Moreover, as our method employs frame skipping when feeding video frames into the deep learning network (NFS =10), the probability of missing precipitation particles is further increased. Using more video frames as inputs to the deep learning model is a feasible approach. This would increase the temporal capture of precipitation particles, thereby reducing the likelihood of misclassification. However, this approach would also lead to an increase in model complexity and computational delay. Therefore, while optimizing the input data strategy, a balance needs to be found between model accuracy and computational efficiency to ensure real-time performance and stability in practical applications.
As analysed in Sect. 3, it is evident that the visual characteristics of rain, snow, and graupel differ between daytime and nighttime surveillance videos. Especially, during nighttime, present additional challenges due to varying light sources such as streetlights, vehicle headlights, and other ambient lighting interferences, which can significantly impact image features of SPT. Despite these variations, the results indicate that the proposed algorithm performs consistently well under both day and night conditions. This robustness underscores the algorithm's ability to effectively capture and distinguish the spatiotemporal features of various SPTs across complex illumination scenarios, making it highly suitable for SPT recognition tasks throughout the entire day. Furthermore, these findings suggest that exploring the distinctions between different SPTs from both spatial and temporal dimensions provides a reliable benchmark for future model enhancements. This also lays a solid foundation for refining deep learning models to improve their generalization ability across diverse real-world surveillance conditions.
Based on the previous introduction to camera parameters, the three surveillance cameras used in this study have different fields of view, image resolutions, and frame rates. In particular, differences in frame rates often imply variations in exposure time, leading to discrepancies in the captured images of the same precipitation particle, such as rainstreak length and width. This increases the challenge of distinguishing GPH. Despite the significant differences in camera parameters, our algorithm demonstrates consistent performance across all devices, exhibiting remarkable stability. This robustness can be attributed to two key factors. First, the self-constructed SPTV dataset is derived from a large number of real-world urban surveillance scenarios captured by cameras with varying parameters. Second, the results indicate strong generalization capability, thereby enhancing stability in cross-camera observations. Our method effectively integrates the temporal and spatial (image) characteristics of different SPTs, combining spatiotemporal-based features in a unified framework. This resilience to variations in camera parameters makes our approach particularly suitable for large-scale practical applications, as urban surveillance cameras typically exhibit substantial configuration differences. The demonstrated robustness ensures reliable performance across diverse surveillance environments, enhancing the applicability of our proposed algorithm in real-world scenarios.
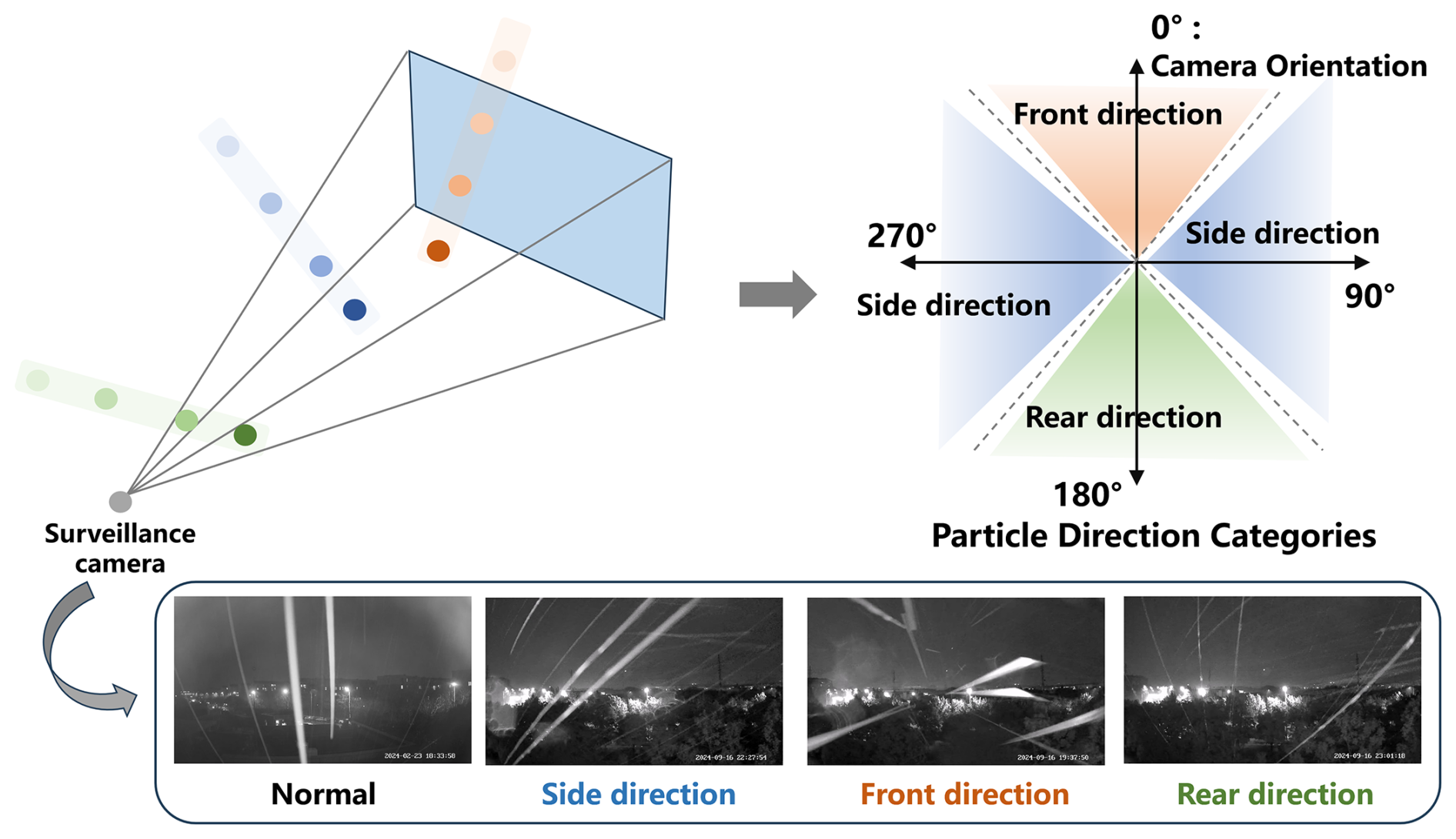
The influence of wind on precipitation particles mainly lies in altering their movement direction and falling speed, which, in turn, affects their representation in the camera's field of view. To investigate this, we examined the impact of wind speed and direction on the performance of the SPT recognition method. As shown in Fig. 12, surveillance cameras capture 2D images to represent a 3D space, meaning that wind causes particles to enter the camera's field of view from the front, rear, left, or right. The left and right directions are symmetrical, so particles entering from these two directions exhibit similar characteristics in the image or video. This is because wind from the left or right does not significantly affect the projected shape of the particles. Furthermore, since the directions are symmetrical, the paths, speeds, and variations of particles entering from these directions present similar features in the image. In contrast, particles entering from the front and rear exhibit different visual effects when projected onto the image plane. This difference is due to variations in the camera's focal length, field depth, and distance. Particles entering from the front appear to grow larger in the video, whereas those from the rear appear smaller. This phenomenon arises from the pinhole imaging principle followed by the monitoring camera, where objects closer to the camera appear larger in the field of view, and those farther away appear smaller. Thus, particles from the front and rear present distinct characteristics in the image, following the “near large, far small” imaging rule. As shown in Fig. 13, we categorized particle's relative direction to surveillance cameras (orientation of the surveillance camera as 0°) into four classes:
-
Normal: Particles fall vertically and enter the camera's field of view, showing typical image/video features.
-
Side direction: Particles enter from the left or right, presenting similar characteristics due to symmetry.
-
Front direction: Particles enter from the front, with their size changing according to the distance from the camera.
-
Rear direction: Particles enter from the rear, with their size decreasing as they move farther away.
Since the orientations of the three surveillance cameras are known, the relative wind direction of camera can be calculated by:
where, θw represents the wind direction provided by the anemometer, θc represents the orientation of the surveillance camera.
As shown in Fig. 13, the particle's relative direction to the camera can be determined based on the value of Δθ, as follows: Side direction: ; Front direction: ; Rear direction: . Next, we have statistically analyzed the recognition accuracy of SPTs under different wind speeds and directions. The data in the figure represent the average values from the three surveillance cameras. Considering that wind speeds ranging from 0 to 1 m s−1 cause minimal tilting of the precipitation particles, these cases are classified as “Normal” and are not separately reported.
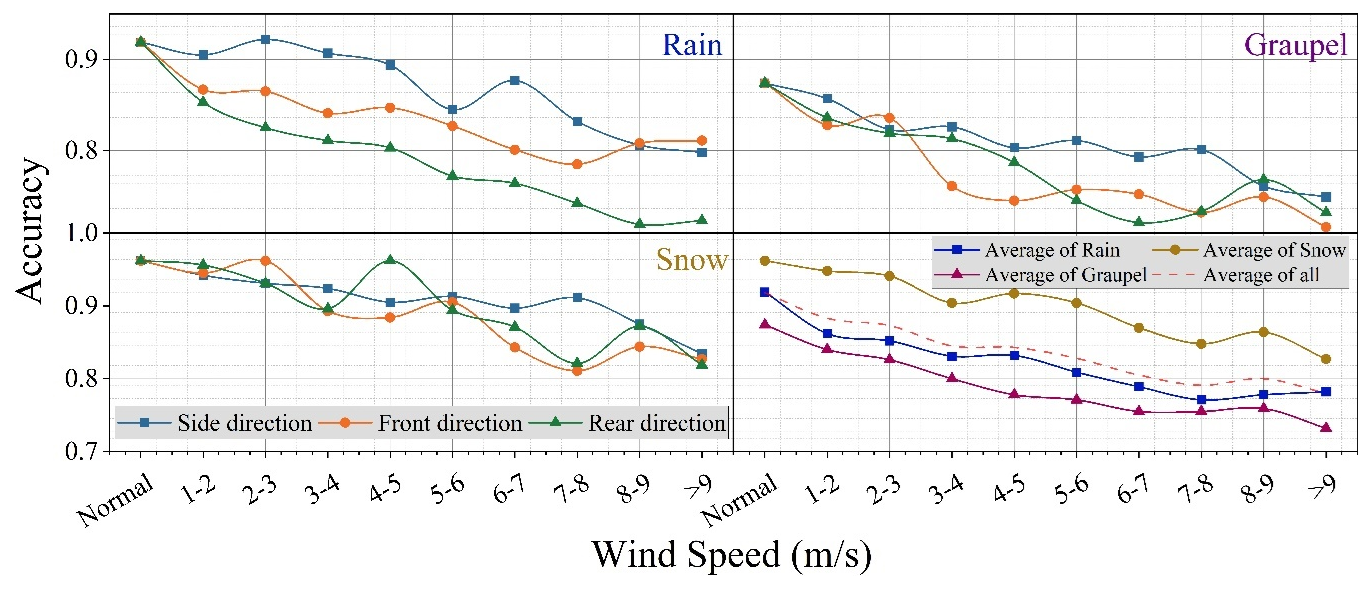
Overall, wind negatively impacts the classification accuracy of SPT, with its influence becoming more pronounced as wind speed increases. In particular, distinguishing between rain and graupel presents greater challenges under windy conditions, as the model's classification accuracy deteriorates significantly with increasing wind speed. Nevertheless, when wind speed is below 5 m s−1, the proposed method still achieves an accuracy of approximately 0.8 for rain-graupel classification, indicating that the method remains effective within this wind speed range. In comparison, when wind speed is below 6 m s−1, the proposed model maintains a classification accuracy above 0.9 for snow under different wind directions, demonstrating high reliability. Furthermore, the influence of particle direction (i.e., wind direction) is also significant and follows certain patterns. For instance, the classification accuracy for particles arriving from the side direction is higher than for those coming from that of front or rear directions. This may be because side-entering particles produce clearer projections in the images, providing the model with more distinguishable features and thereby improving classification accuracy. In contrast, particles arriving from the front or rear exhibit greater variability in their image representation due to differences in viewing angles and distances (as shown in Fig. 13), leading to a reduction in classification accuracy. In summary, the proposed method demonstrates a certain degree of robustness against wind, particularly when wind speed is below 5 m s−1, where it continues to perform reliably and effectively mitigates the impact of wind on precipitation particle classification.
In addition to the discussion on algorithm accuracy, computational complexity is also a critical factor in practical applications. Specifically, when scaling from a single camera to a large-scale surveillance network, the overall computational complexity may increase exponentially, significantly impacting system efficiency and resource consumption. Therefore, evaluating and optimizing the algorithm's computational cost while maintaining identification accuracy is essential for ensuring feasibility in real-world deployments. Here, two crucial metrics for evaluating the complexity and practicality of deep learning models for SPT identification are Floating Point Operations (FLOPs) and Parameters (Rump et al., 2008; Carr and Kennedy, 1994). FLOPs denote the total number of floating-point operations required to execute a network model once, reflecting the computational demand during a single forward propagation. This metric is widely used to assess a model's computational efficiency and processing speed. Meanwhile, Parameters encompass the total number of parameters within a model, as well as those that require training, which indicates the GPU memory resources needed for model training. A detailed comparison of FLOPs and Parameters across various deep-learning models is presented below, models with relatively lower Parameters and FLOPs are highlighted in bold black and underlined.
Table 9The Parameters of deep-learning models. The bold entries indicate relatively better performance.
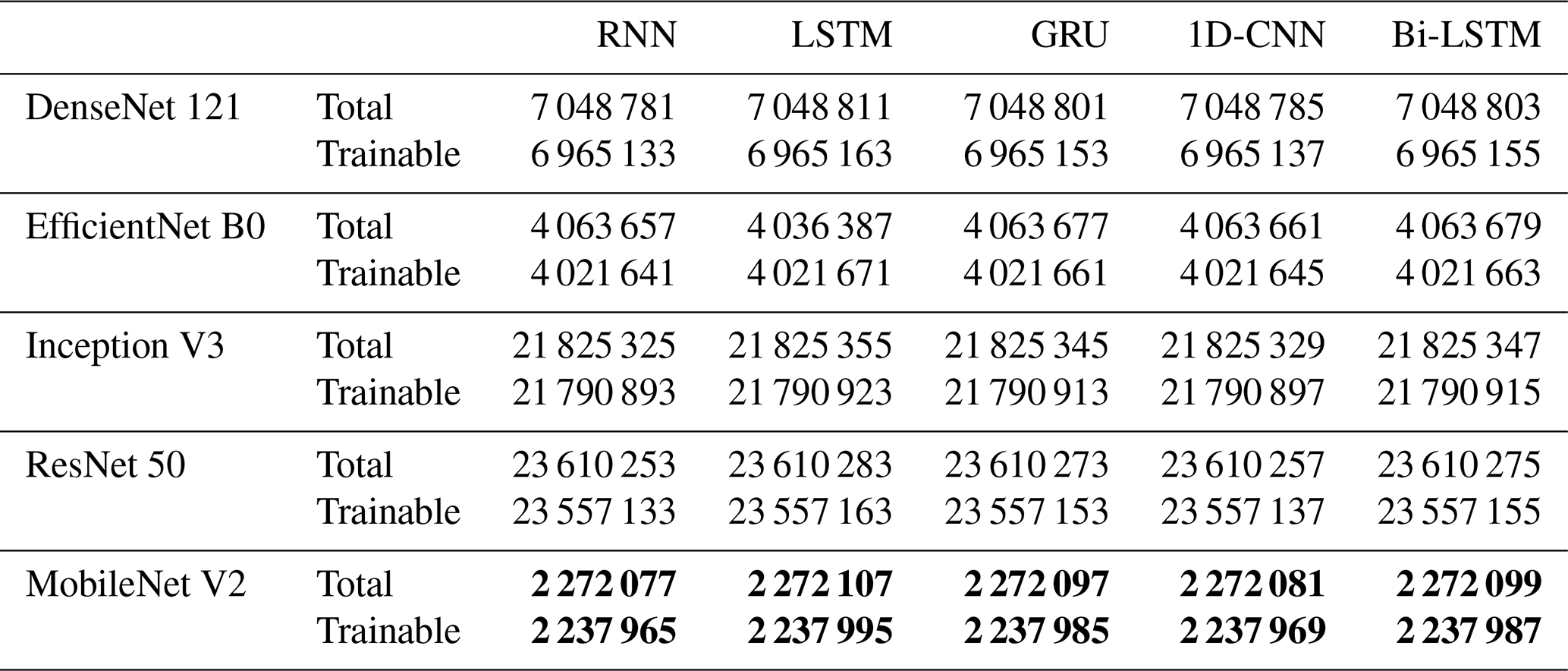
Table 10The FLOPs of deep-learning models. The bold entries indicate relatively better performance.
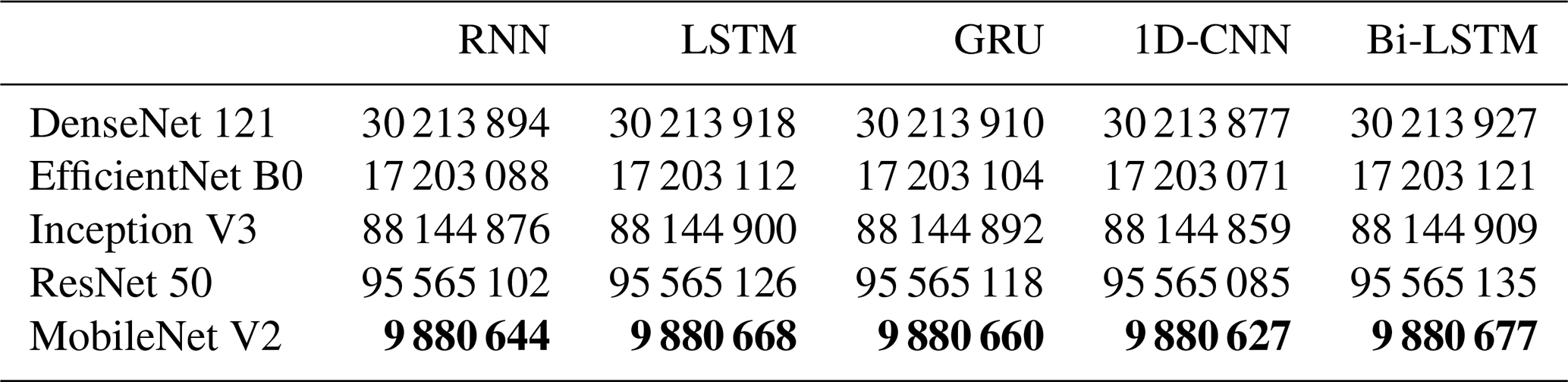
As shown in Tables 9 and 10, our proposed method exhibits significantly lower Parameters and FLOPs values compared to deep learning models based on alternative spatial feature extraction frameworks. While the GRU, which is used as our temporal feature extraction framework, presents a slightly higher complexity than RNN, LSTM, and 1D-CNN, it offers a clear advantage in terms of accuracy. This increased complexity is offset by the improved performance, demonstrating the ability of GRU to better capture the temporal dependencies inherent in SPT observation tasks. In summary, the proposed method represents an optimal choice for large-scale deployment and SPT observation applications. It not only achieves superior accuracy but also ensures efficiency in both the SPTV dataset and real-world experiments, outperforming other algorithms in terms of both computational resource usage and recognition performance. This makes it highly suitable for practical, large-scale applications where both accuracy and efficiency are paramount.

Figure 15Different types of surveillance image quality degradation: (a) Drop attachment on lens at night, (b) daytime drop attachment on lens, (c) wind caused image blurred, (d) mist caused lens blurred, (e) lightning-induced exposure anomalies, (f) dust caused image blurred. These special cases can be regarded as scenarios where our proposed method fails to work.
4.6 Discussion
In our years of video data collection and real-world experiments, we have found that under certain conditions, our method may fail. For example,
-
when raindrops adhere to the camera lens, the image becomes blurred, which affects the image quality and leads to inaccurate SPT identification. Since surveillance cameras are typically exposed to the external environment, this issue occurs not only during the day but also at night, as shown in Fig. 15a and b. In particular, under windy conditions, raindrops are more likely to attach to the lens, increasing the blurriness and unclear nature of the image. This not only affects the resolution of precipitation particles but also makes it difficult to accurately classify SPTs.
-
Strong winds may also cause camera shake, blurring precipitation images in the surveillance field of view. Under strong wind conditions, the movement trajectories of precipitation particles become unstable, and rain droplets, snowflakes, and other particles may be scattered by the wind, as shown in Fig. 15c. This not only alters their fall paths but may also cause the precipitation patterns to become unclear, increasing the complexity of algorithmic interpretation.
-
High air humidity during precipitation events is also a contributing factor. When humidity increases, particularly during continuous rainfall or wet weather, water droplets or mist tend to condense on the camera lens, leading to blurred images, as shown in Fig. 15d. This phenomenon is commonly observed during early mornings or at night when humidity levels are higher, and it may also occur during sudden precipitation events. The accumulation of moisture prevents the lens from clearly presenting the shape and movement trajectories of precipitation particles, further complicating the identification process.
-
Lightning can also affect the performance of surveillance cameras. As shown in Fig. 15e, the intense light from lightning and the rapidly changing environmental conditions can interfere with the camera's automatic exposure system, leading to overexposure or underexposure, or even uneven exposure in the image. This strong light and the rapid changes in the scene can disturb the normal functioning of the algorithm, resulting in misjudgment or loss of precipitation images, especially in thunderstorms with frequent lightning.
-
Additionally, dust on the lens can also affect image quality, though this impact is smaller compared to raindrops or humidity. When dust accumulates on the lens, the image may become slightly blurry, but it won't cause significant distortion like raindrops or fog, as shown in Fig. 15f. However, in cases of severe dust accumulation, it may affect the separation of SPT from the background, thus impacting the accurate recognition of SPT.
In practical applications, manually cleaning each camera lens is resource-intensive and difficult to implement on a large scale, particularly in large-scale surveillance networks. Currently, advanced image denoising and deblurring techniques have been developed in the field of computer vision, which can improve image quality to some extent by removing blur and enhancing the clarity of surveillance footage (Wang et al., 2020; Li et al., 2021). However, these techniques are primarily designed for conventional monitoring tasks, especially for object detection, such as monitoring people, vehicles, and other targets. In these applications, precipitation particle images are often considered “noise”, causing details and shapes of the precipitation particles to become blurred or even completely lost. This loss of information is critical for particle type classification, which negatively impacts SPT recognition tasks. To address this issue, two feasible solutions are proposed:
Develop a dedicated video/image quality recognition model: This model could evaluate image clarity and identify abnormal images caused by raindrop attachment, lens blur, high humidity, and other factors leading to degraded image quality. When the system detects that the image quality is insufficient, it can discard low-quality images. The main function of this model would be to preprocess the input videos or images, determining whether their quality is clear enough to meet the requirements of SPT identification tasks.
Incorporate low-quality images as a new class in the training dataset: By adding low-quality images as a new category, the model can learn how to recognize quality issues in precipitation images and make corresponding judgments. Specifically, this new class could be labelled as “low-quality image” or a similar label, representing images that are affected by raindrops, mist, lens stains, or other factors that degrade their quality. In this way, the model can not only recognize normal SPTs but also effectively differentiate which images cannot be accurately classified due to quality issues, thereby improving the accuracy and reliability of the results.
Mixed-phase precipitation holds significant importance in meteorology, particularly prominent during the winter season (Jennings et al., 2023). Surveillance videos capture precipitation particle groups, and under mixed precipitation conditions, variations in the proportions of solid and liquid particles lead to significant differences in image and video features. Firstly, the image features of mixed precipitation are not merely a simple superposition of single-particle images; optical effects such as refraction and reflection between particles further alter the visual characteristics (Mishchenko et al., 2002), increasing the complexity of visual feature modeling. Additionally, in mixed precipitation, the considerable fluctuations in the overall fall velocity of the precipitation particle group captured in the videos pose challenges to the temporal feature modeling based on existing single-phase particle fall theoretical formulas (e.g., Fig. 7). While this study establishes a basis for mixed-phase precipitation recognition, the present algorithm, which is largely constructed around the microphysical characteristics of single-phase precipitation (e.g., color, particle size, fall velocity), still exhibits notable uncertainty in accurately identifying mixed-phase events. In future work, we plan to introduce a “mixed precipitation” category or further subdivide it into multiple types such as “rain-snow mixture” and “snow-graupel mixture” to more accurately reflect the complexity of SPTs. Meanwhile, considering the scarcity of mixed precipitation surveillance video samples, we plan to expand the dataset and optimize the algorithm to improve the model's accuracy and stability in recognizing various precipitation types in practical applications, thereby enhancing its practical value and potential for broader deployment.
In this study, we focus on identifying three SPTs – rain, snow, and graupel – using surveillance cameras. We analyse their distinguishing characteristics in both daytime and nighttime videos to inform our classification approach. To balance precision, latency, and efficiency requirements in real-world applications, we employ a MobileNet V2 network with transfer learning to extract image and spatial features, followed by a GRU network to capture temporal information, enabling high-accuracy SPT discrimination. For training and testing, we constructed the SPTV dataset, a SPT video dataset totalling approximately 94 h. To evaluate the performance of our proposed deep learning model, we compared it against 24 alternative deep-learning models. Experiments on the SPTV dataset show that the proposed algorithm achieves an optimal accuracy of 0.9677 when NFS =10. Although some comparative algorithms demonstrate slightly lower accuracy, our method exhibits significantly reduced computational and time complexity, making it highly suitable for practical deployment. Furthermore, six real-world experiments yielded an average accuracy of 0.9301, with comparable performance during both daytime and nighttime, demonstrating the algorithm's stability even when faced with varying camera parameters. Moreover, our method demonstrates a certain degree of wind resistance, achieving satisfactory performance when wind speed is below 5 m s−1. This robustness makes our method a viable solution for large-scale, all-day, high-accuracy SPT observation tasks.
Currently, the method faces limitations in distinguishing between rain and graupel, with the recognition accuracy for graupel reaching only 0.8726 in real-world applications. Enhancing graupel discrimination accuracy is a key area for future improvement. Additionally, addressing challenges such as reducing misclassifications in “no precipitation” conditions and improving the system's ability to detect failure cases in special scenarios will be essential for increasing reliability and applicability in diverse real-world environments. To further improve the recognition of various SPTs, the SPTV dataset will be expanded to include hail and mixed precipitation surveillance videos, thereby enhancing the model's accuracy and robustness in practical applications.
The Confusion matrixs of different deep learning algorithms are presented as follows:
Table A1Confusion matrix of different deep learning algorithms (NFS =15).

Note: First row: DenseNet 121; Second row: EfficientNet B0; Third row: Inception V3; Forth row: ResNet 50; Fifth Row: MobileNet V2.
Table A2Confusion matrix of different deep learning algorithms (NFS =10).

Note: First row: DenseNet 121; Second row: EfficientNet B0; Third row: Inception V3; Forth row: ResNet 50; Fifth Row: MobileNet V2.
Table A3Confusion matrix of different deep learning algorithms (NFS =5).

Note: First row: DenseNet 121; Second row: EfficientNet B0; Third row: Inception V3; Forth row: ResNet 50; Fifth Row: MobileNet V2.
Real-world SPT identification by surveillance camera_2 and camera_3 is shown as below.
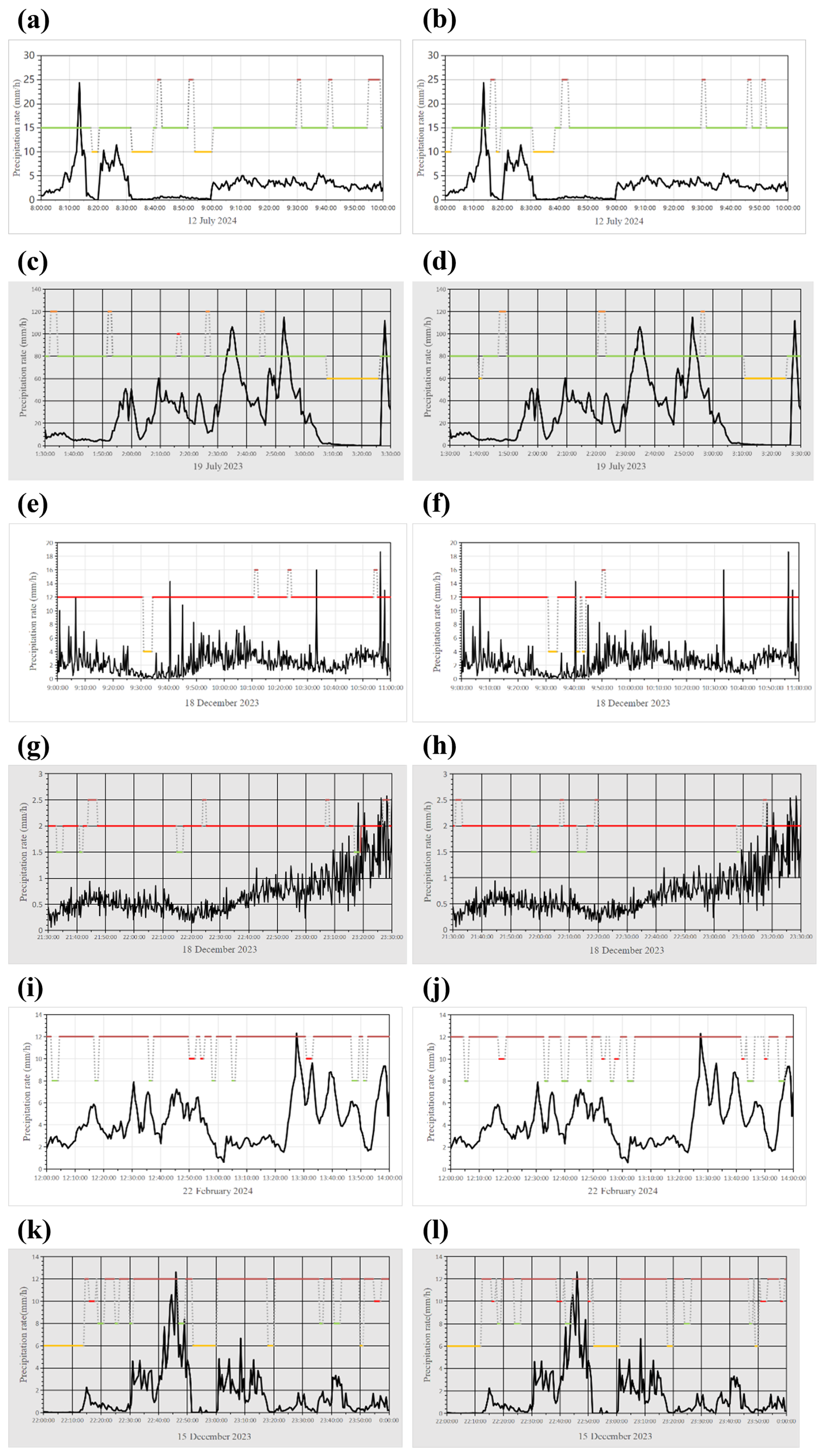
Figure B1Real-world SPT identification by surveillance camera_2 and camera_3: (a) Day-time Rain of camera_2, (b) Day-time Rain of camera_3, (c) Night-time Rain of camera_2, (d) Night-time Rain of camera_3, (e) Day-time snow of camera_2, (f) Day-time snow of camera_3, (g) Night-time snow of camera_2, (h) Night-time snow of camera_3, (i) Day-time graupel of camera_2, (j) Day-time graupel of camera_3, (k) Night-time graupel of camera_2, (l) Night-time graupel of camera_3. (green: rain; red: snow; brow: graupel; yellow: no precipitation; The black curve represents the precipitation intensity readings from the 2-DVD).
Given the sensitivity of urban surveillance data, we release partially anonymized experimental videos (with people and vehicles masked) and example visible- and near-infrared clips of rain, snow, and graupel, available at https://doi.org/10.5446/71534 (Wang, 2024).
Example visible- and near-infrared clips of rain, snow, and graupel, available at https://doi.org/10.5446/71534 (Wang, 2024).
XW, KZ and AZ conceptualized Surveillance Camera-based Near Surface Precipitation Type Observation. XW, HH and HC developed the deep learning network. XW, AZ, and HC designed the experiments and XW carried them out. XW, KZ, AZ, HH, and HC interpreted the results. XW prepared the manuscript with contributions from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors. Also, please note that this paper has not received English language copy-editing. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
This research was funded by the National Natural Science Foundation of China (NSFC) (nos. 42025501 and 42405140), the China Postdoctoral Foundation (nos. 2024M761383 and 2025T180080), the Fundamental Research Funds for the Central Universities – emac “GeoX” Interdisciplinary Program (no. 020714380210), the Open Grants of China Meteorological Administration Radar Meteorology Key Laboratory (nos. 2024LRM-A01 and 2024LRM-A02), and the Talent Startup project of NJIT (YKJ.202315).
This research has been supported by the National Natural Science Foundation of China (NSFC) (nos. 42025501 and 42405140), the China Postdoctoral Foundation (nos. 2024M761383 and 2025T180080), the Fundamental Research Funds for the Central Universities – emac “GeoX” Interdisciplinary Program (no. 020714380210), the Open Grants of China Meteorological Administration Radar Meteorology Key Laboratory (nos. 2024LRMA01 and 2024LRM-A02), and the Talent Startup project of NJIT (YKJ.202315).
This paper was edited by Luca Lelli and reviewed by three anonymous referees.
Aloufi, N., Alnori, A., and Basuhail, A. J. E.: Enhancing Autonomous Vehicle Perception in Adverse Weather: A Multi Objectives Model for Integrated Weather Classification and Object Detection, Electronics, 13, 3063, https://doi.org/10.3390/electronics13153063, 2024.
Arienzo, M. M., Collins, M., and Jennings, K. S.: Enhancing engagement of citizen scientists to monitor precipitation phase, Frontiers in Earth Science, 9, 617594, https://doi.org/10.3389/feart.2021.617594, 2021.
Askbom, L.: Road condition classification from CCTV images using machine learning, MS thesis, https://odr.chalmers.se/server/api/core/bitstreams/39745dde-45d6-4c9a-9621-fd1c611d8ef7/content (last access: 7 October 2025), 2023.
Atlas, D., Srivastava, R., and Sekhon, R. S.: Doppler radar characteristics of precipitation at vertical incidence, Reviews of Geophysics, 11, 1–35, https://doi.org/10.1029/rg011i001p00001, 1973.
Bharadwaj, H. S., Biswas, S., and Ramakrishnan, K.: A large scale dataset for classification of vehicles in urban traffic scenes, Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing, 2016, 1–8, https://doi.org/10.1145/3009977.3010040, 2016.
Brandes, E. A., Ikeda, K., Zhang, G., Schönhuber, M., and Rasmussen, R. M.: A statistical and physical description of hydrometeor distributions in Colorado snowstorms using a video disdrometer, Journal of Applied Meteorology and Climatology, 46, 634–650, https://doi.org/10.1175/JAM2489.1, 2007.
Carr, S. and Kennedy, K.: Improving the ratio of memory operations to floating-point operations in loops, ACM Transactions on Programming Languages and Systems (TOPLAS), 16, 1768–1810, https://doi.org/10.1145/197320.197366, 1994.
Carrillo, J. and Crowley, M.: Integration of roadside camera images and weather data for monitoring winter road surface conditions, arXiv [preprint], https://doi.org/10.48550/arXiv.2009.12165, 2020.
Casellas, E., Bech, J., Veciana, R., Pineda, N., Rigo, T., Miró, J. R., and Sairouni, A.: Surface precipitation phase discrimination in complex terrain, Journal of Hydrology, 592, 125780, https://doi.org/10.1016/j.jhydrol.2020.125780, 2021a.
Casellas, E., Bech, J., Veciana, R., Pineda, N., Miró, J. R., Moré, J., Rigo, T., and Sairouni, A.: Nowcasting the precipitation phase combining weather radar data, surface observations, and NWP model forecasts, Quarterly Journal of the Royal Meteorological Society, 147, 3135–3153, https://doi.org/10.1002/qj.4121, 2021b.
Chen, S., Shu, T., Zhao, H., and Tang, Y. Y.: MASK-CNN-Transformer for real-time multi-label weather recognition, Knowledge-Based Systems, 278, 110881, https://doi.org/10.2139/ssrn.4431880, 2023.
Chu, W.-T., Zheng, X.-Y., and Ding, D.-S.: Camera as weather sensor: Estimating weather information from single images, Journal of Visual Communication and Image Representation, 46, 233–249, https://doi.org/10.1016/j.jvcir.2017.04.002, 2017.
Crimmins, T. and Posthumus, E.: Do Carefully Timed Email Messages Increase Accuracy and Precision in Citizen Scientists' Reports of Events?, Citizen Science: Theory and Practice, 7, https://doi.org/10.5334/cstp.464, 2022.
Dahmane, K., Duthon, P., Bernardin, F., Colomb, M., Blanc, C., and Chausse, F.: Weather classification with traffic surveillance cameras, Proceedings of the 25th ITS World Congress, https://www.cerema.fr/system/files/documents/2018/09/Dahmane_ITS2018.pdf (last access: 30 September 2025), 2018.
Dahmane, K., Duthon, P., Bernardin, F., Colomb, M., Chausse, F., and Blanc, C.: Weathereye-proposal of an algorithm able to classify weather conditions from traffic camera images, Atmosphere, 12, 717, https://doi.org/10.3390/atmos12060717, 2021.
Dhananjaya, M. M., Kumar, V. R., and Yogamani, S.: Weather and light level classification for autonomous driving: Dataset, baseline and active learning, 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), 2816–2821, https://doi.org/10.1109/ITSC48978.2021.9564689, 2021.
Guerra, J. C. V., Khanam, Z., Ehsan, S., Stolkin, R., and McDonald-Maier, K.: Weather Classification: A new multi-class dataset, data augmentation approach and comprehensive evaluations of Convolutional Neural Networks, 2018 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), 305–310, https://doi.org/10.1109/ahs.2018.8541482, 2018.
Haberlie, A. M., Ashley, W. S., and Pingel, T. J.: The effect of urbanisation on the climatology of thunderstorm initiation, Quarterly Journal of the Royal Meteorological Society, 141, 663–675, https://doi.org/10.1002/qj.2499, 2015.
He, K., Zhang, X., Ren, S., and Sun, J.: Deep residual learning for image recognition, Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, 770–778, https://doi.org/10.1109/CVPR.2016.90, 2016.
Heymsfield, A. and Wright, R.: Graupel and hail terminal velocities: Does a “supercritical” Reynolds number apply?, Journal of the Atmospheric Sciences, 71, 3392–3403, https://doi.org/10.1175/jas-d-14-0034.1, 2014.
Huang, G., Liu, Z., Van Der Maaten, L., and Weinberger, K. Q.: Densely connected convolutional networks, Proceedings of the IEEE conference on computer vision and pattern recognition, 4700–4708, https://doi.org/10.1109/CVPR.2017.243, 2017.
Huang, Z., Xu, W., and Yu, K.: Bidirectional LSTM-CRF models for sequence tagging, arXiv [preprint], https://doi.org/10.48550/arXiv.1508.01991, 2015.
Ibrahim, M. R., Haworth, J., and Cheng, T.: WeatherNet: Recognising weather and visual conditions from street-level images using deep residual learning, ISPRS International Journal of Geo-Information, 8, 549, https://doi.org/10.3390/ijgi8120549, 2019.
Jennings, K. S., Arienzo, M. M., Collins, M., Hatchett, B. J., Nolin, A. W., and Aggett, G.: Crowdsourced Data Highlight Precipitation Phase Partitioning Variability in Rain-Snow Transition Zone, Earth and Space Science, 10, e2022EA002714, https://doi.org/10.1029/2022ea002714, 2023.
Kajikawa, M.: Measurement of falling velocity of individual graupel particles, Journal of the Meteorological Society of Japan. Ser. II, 53, 476–481, https://doi.org/10.2151/jmsj1965.53.6_476, 1975.
Karaa, M., Ghazzai, H., and Sboui, L.: A dataset annotation system for snowy weather road surface classification, IEEE Open Journal of Systems Engineering, https://doi.org/10.1109/ojse.2024.3391326, 2024.
Khan, M. N. and Ahmed, M. M.: Weather and surface condition detection based on road-side webcams: Application of pre-trained convolutional neural network, International Journal of Transportation Science Technology, 11, 468–483, https://doi.org/10.1016/j.ijtst.2021.06.003, 2022.
Kiranyaz, S., Avci, O., Abdeljaber, O., Ince, T., Gabbouj, M., and Inman, D. J.: 1D convolutional neural networks and applications: A survey, Mechanical Systems and Signal Processing, 151, 107398, https://doi.org/10.1109/access.2024.3433513, 2021.
Kondapally, M., Kumar, K. N., Vishnu, C., and Mohan, C. K.: Towards a transitional weather scene recognition approach for autonomous vehicles, IEEE Transactions on Intelligent Transportation Systems, 25, 5201–5210, https://doi.org/10.1109/TITS.2023.3331882, 2023.
Kruger, A. and Krajewski, W. F.: Two-dimensional video disdrometer: A description, Journal of Atmospheric and Oceanic Technology, 19, 602–617, https://doi.org/10.1175/1520-0426(2002)019<0602:TDVDAD>2.0.CO;2, 2002.
Kurihata, H., Takahashi, T., Ide, I., Mekada, Y., Murase, H., Tamatsu, Y., and Miyahara, T.: Rainy weather recognition from in-vehicle camera images for driver assistance, IEEE Proceedings Intelligent Vehicles Symposium, 2005, 205–210, https://doi.org/10.1109/IVS.2005.1505103, 2005.
Landry, F.-G. and Akhloufi, M. A.: Deep learning and computer vision techniques for estimating snow coverage on roads using surveillance cameras, 2022 18th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), 1–8, https://doi.org/10.1109/avss56176.2022.9959452, 2022.
Lee, I. J.: Big data processing framework of learning weather information and road traffic collision using distributed CEP from CCTV video: Cognitive image processing, 2017 IEEE 16th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), 400–406, https://doi.org/10.1109/ICCI-CC.2017.8109780, 2017.
Leroux, N. R., Vionnet, V., and Thériault, J. M.: Performance of precipitation phase partitioning methods and their impact on snowpack evolution in a humid continental climate, Hydrological Processes, 37, e15028, https://doi.org/10.1002/hyp.15028, 2023.
Li, Q., Kong, Y., and Xia, S.-M.: A method of weather recognition based on outdoor images, 2014 International Conference on Computer Vision Theory and Applications, 510–516, https://doi.org/10.5220/0004724005100516, 2014.
Li, S., Ren, W., Wang, F., Araujo, I. B., Tokuda, E. K., Junior, R. H., Cesar Jr., R. M., Wang, Z., and Cao, X.: A comprehensive benchmark analysis of single image deraining: Current challenges and future perspectives, International Journal of Computer Vision, 129, 1301–1322, https://doi.org/10.1007/s11263-020-01416-w, 2021.
Lu, C., Lin, D., Jia, J., and Tang, C.-K.: Two-class weather classification, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3718–3725, https://doi.org/10.1109/cvpr.2014.475, 2014.
Lü, M.-c., Liu, D., and Zhang, X.-j.: Study on Road Weather Recognition Method Based on Road Segmentation, Journal of Highway and Transportation Research and Development, 17, 26–35, https://doi.org/10.1061/jhtrcq.0000871, 2023.
Magono, C. and Lee, C. W.: Meteorological classification of natural snow crystals, Journal of the Faculty of Science, Hokkaido University, Series 7, Geophysics, 2, 321–335, https://doi.org/10.4159/harvard.9780674182769.c12, 1966.
Mishchenko, M. I., Travis, L. D., and Lacis, A. A.: Scattering, absorption, and emission of light by small particles, Cambridge University Press, https://doi.org/10.1016/0960-1686(93)90104-7, 2002.
Mittal, S. and Sangwan, O. P.: Classifying weather images using deep neural networks for large scale datasets, International Journal of Advanced Computer Science and Applications, 14, https://doi.org/10.14569/ijacsa.2023.0140136, 2023.
Montero-Martínez, G., Kostinski, A. B., Shaw, R. A., and García-García, F.: Do all raindrops fall at terminal speed?, Geophysical Research Letters, 36, https://doi.org/10.1029/2008gl037111 2009.
Morris, C. and Yang, J. J.: A machine learning model pipeline for detecting wet pavement condition from live scenes of traffic cameras, Machine Learning with Applications, 5, 100070, https://doi.org/10.1016/j.mlwa.2021.100070, 2021.
Pavlic, M., Rigoll, G., and Ilic, S.: Classification of images in fog and fog-free scenes for use in vehicles, 2013 IEEE Intelligent Vehicles Symposium (IV), 481–486, https://doi.org/10.1109/ivs.2013.6629514, 2013.
Pruppacher, H. R. and Klett, J. D.: Microphysics of Clouds and Precipitation, Nature, 284, 88–88, https://doi.org/10.1038/284088b0, 1980.
Ramanna, S., Sengoz, C., Kehler, S., and Pham, D.: Near real-time map building with multi-class image set labeling and classification of road conditions using convolutional neural networks, Applied Artificial Intelligence, 35, 803–833, https://doi.org/10.1080/08839514.2021.1935590, 2021.
Roser, M. and Moosmann, F.: Classification of weather situations on single color images, 2008 IEEE Intelligent Vehicles Symposium, 798–803, https://doi.org/10.1109/ivs.2008.4621205, 2008.
Rump, S. M., Ogita, T., and Oishi, S. i.: Accurate floating-point summation part I: Faithful rounding, SIAM Journal on Scientific Computing, 31, 189–224, https://doi.org/10.1137/050645671, 2008.
Samo, M., Mafeni Mase, J. M., and Figueredo, G.: Deep Learning with Attention Mechanisms for Road Weather Detection, Sensors, 23, 798, https://doi.org/10.3390/s23020798, 2023.
Schirmacher, I., Schnitt, S., Klingebiel, M., Maherndl, N., Kirbus, B., and Crewell, S.: Clouds and precipitation in the initial phase of marine cold air outbreaks as observed by airborne remote sensing, EGU General Assembly 2024, Vienna, Austria, 14–19 Apr 2024, EGU24-5220, https://doi.org/10.5194/egusphere-egu24-5220, 2024.
Shibata, K., Takeuch, K., Kawai, S., and Horita, Y.: Detection of road surface conditions in winter using road surveillance cameras at daytime, night-time and twilight, International Journal of Computer Science and Network Security (IJCSNS), 14, 21, 2014.
Speirs, P., Gabella, M., and Berne, A.: A comparison between the GPM dual-frequency precipitation radar and ground-based radar precipitation rate estimates in the Swiss Alps and Plateau, Journal of Hydrometeorology, 18, 1247–1269, https://doi.org/10.1175/jhm-d-16-0085.1, 2017.
Sun, Z., Wang, P., Jin, Y., Wang, J., and Wang, L.: A practical weather detection method built in the surveillance system currently used to monitor the large-scale freeway in China, IEEE Access, 8, 112357–112367, https://doi.org/10.1109/access.2020.3002959, 2020.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z.: Rethinking the inception architecture for computer vision, Proceedings of the IEEE Conference on Computer Sision and Pattern Recognition, 2818–2826, 2016.
Tan, M. and Le, Q.: Efficientnet: Rethinking model scaling for convolutional neural networks, International Conference on Machine Learning, 6105–6114, https://doi.org/10.48550/arXiv.1905.11946, 2019.
Toğaçar, M., Ergen, B., and Cömert, Z.: Detection of weather images by using spiking neural networks of deep learning models, Neural Computing and Applications, 33, 6147–6159, https://doi.org/10.1007/s00521-020-05388-3, 2021.
Triva, J., Grbić, R., Vranješ, M., and Teslić, N.: Weather Condition Classification in Vehicle Environment Based on Front-View Camera Images, 2022 21st International Symposium INFOTEH-JAHORINA (INFOTEH), 1–4, https://doi.org/10.1109/infoteh53737.2022.9751279, 2022.
Vázquez-Martín, S., Kuhn, T., and Eliasson, S.: Shape dependence of snow crystal fall speed, Atmos. Chem. Phys., 21, 7545–7565, https://doi.org/10.5194/acp-21-7545-2021, 2021.
Wang, H., Xie, Q., Wu, Y., Zhao, Q., and Meng, D.: Single image rain streaks removal: a review and an exploration, International Journal of Machine Learning and Cybernetics, 11, 853–872, https://doi.org/10.1007/s13042-020-01061-2, 2020.
Wang, S., Li, Y., and Liu, W.: Multi-class weather classification fusing weather dataset and image features, Big Data: 6th CCF Conference, Big Data 2018, Xi'an, China, 11–13 October 2018, Proceedings 6, 149–159, https://doi.org/10.1007/978-981-13-2922-7_10, 2018.
Wang, X.: Surveillance Camera-Based Deep Learning Framework for High-Resolution Near Surface Precipitation Type Observation, TIB AV-Portal [video], https://doi.org/10.5446/71534, 2024.
Wang, X., Shi, S., Zhu, L., Nie, Y., and Lai, G.: Traditional and Novel Methods of Rainfall Observation and Measurement: A Review, Journal of Hydrometeorology, 24, 2153–2176, https://doi.org/10.1175/jhm-d-22-0122.1, 2023a.
Wang, X., Yang, Z., Feng, H., Zhao, J., Shi, S., and Cheng, L.: A Multi-Stream Attention-Aware Convolutional Neural Network: Monitoring of Sand and Dust Storms from Ordinary Urban Surveillance Cameras, Remote Sensing, 15, 5227, https://doi.org/10.3390/rs15215227, 2023b.
World Meteorological Organization (WMO): Manual on the Observation of Clouds and Other Meteors-International Cloud Atlas (WMO-No. 407), https://cloudatlas.wmo.int/en/home.html (last access: 12 August 2025), 2017.
Xia, J., Xuan, D., Tan, L., and Xing, L.: ResNet15: weather recognition on traffic road with deep convolutional neural network, Advances in Meteorology, 2020, 6972826, https://doi.org/10.1155/2020/6972826, 2020.
Xiao, H., Zhang, F., Shen, Z., Wu, K., and Zhang, J.: Classification of weather phenomenon from images by using deep convolutional neural network, Earth and Space Science, 8, e2020EA001604, https://doi.org/10.1029/2020ea001604, 2021.
Zhang, C., Nateghinia, E., Miranda-Moreno, L. F., and Sun, L.: Winter road surface condition classification using convolutional neural network (CNN): visible light and thermal image fusion, Canadian Journal of Civil Engineering, 49, 569–578, https://doi.org/10.1139/cjce-2020-0613, 2022.
Zhang, G.: Weather radar polarimetry, Crc Press, ISBN 9781315374666, 2016.
Zhao, B., Li, X., Lu, X., and Wang, Z.: A CNN–RNN architecture for multi-label weather recognition, Neurocomputing, 322, 47–57, https://doi.org/10.1016/j.neucom.2018.09.048, 2018.
Zhao, X., Liu, P., Liu, J., and Tang, X.: Feature extraction for classification of different weather conditions, Frontiers of Electrical and Electronic Engineering in China, 6, 339–346, https://doi.org/10.1007/s11460-011-0151-1, 2011.
Zhou, A., Zhao, K., Lee, W.-C., Huang, H., Hu, D., and Fu, P.: VDRAS and Polarimetric Radar Investigation of a Bow Echo Formation After a Squall Line Merged With a Preline Convective Cell, Journal of Geophysical Research: Atmospheres, 125, e2019JD031719, https://doi.org/10.1029/2019JD031719, 2020.