the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 27 May 2026
| 27 May 2026
A guide to optimised spatiotemporal data co-location by mutual information maximisation
Heather Guy
Michael Ray Gallagher
Ryan Reynolds Neely III
The matching of data described on different coordinate systems between multiple data sources – spatiotemporal co-location – is a necessary and crucial step in geospatial data synthesis and validation. The particular choice of co-location scheme, and the choice of parameters applied to it, decide what subsets of the original datasets are included in downstream analyses, affecting the quantitative outputs of comparison studies and multi-retrieval synthesised datasets. Previously, no generalised framework for deciding how best to co-locate data has existed. We outline a domain- and data-agnostic framework that generalises the process of selecting an optimised co-location parametrisation for a given co-location scheme, by maximising the mutual information encoded between the data included in the subsequent analyses. We demonstrate the framework by applying it to a comparison of vertical cloud fraction profiles retrieved from the polar-orbiting ICESat-2 satellite's ATL09 data product, and surface-based observations at four Cloudnet observatories. We evaluate per-site optimised co-location parametrisations and find that using the optimised co-location parametrisations quantitatively improves the comparison between the datasets over naive choices of co-location parameters. This work has implications across almost all remote sensing data products – especially for satellite validations – and will facilitate deep learning methodologies by producing paired datasets with the maximal information about the structure between datasets available to be learned.
- Article
(3830 KB) - Full-text XML
- BibTeX
- EndNote




Remote sensing data, obtained from Earth observation satellites and surface based observatories, provide invaluable data for furthering our understanding of Earth-system processes, for the validation and constraining of models, and for making observations in remote locations or locations with extreme conditions.
Particularly for satellite data, rigorous validation and a formal uncertainty characterisation are essential for subsequent use of the data. In order to validate satellite data, we need to compare it against reference measurements (Loew et al., 2017). Rarely are the reference measurements described on the same set of coordinates as the data to be validated. Inter-comparison of remote sensing retrievals and multi-sensor data synthesis are subject to similar challenges.
Ideally when comparing data from two different sources, the observations are made simultaneously, and are sensitive to the same spatial volume. However, observations from different platforms will have different viewing geometries, such that the sensitivities across the same observed spatial volume differ between the data sources. This induces a difference between the measurements often referred to as the smoothing error (e.g. Rodgers, 2008). Furthermore, the observations from different sources can measure distinct physical volumes that are spatiotemporally displaced from each other. This induces a bias commonly referred to as the co-location mismatch (e.g. Verhoelst et al., 2015; Virtanen et al., 2018). Verhoelst et al. (2015, Fig. 1) and Loew et al. (2017, Fig. 2) both provide good representations of the issues of co-locating measurements.
In order to compare data recorded on different sets of coordinates, we need to perform spatiotemporal co-location. We define spatiotemporal co-location as the process of matching data between two or more data sources, described on different sets of coordinates, such that discrete co-location events can be defined. For a given co-location event, the data associated with it from the different data sources is considered sufficiently close in time and space to be directly comparable once the data have been homogenised (Loew et al., 2017). Often, for a given implementation of spatiotemporal co-location – which we will refer to as a co-location scheme (defined in Sect. 2.1) – there will be parameters for the scheme that change the amount of data permitted by the subsetting operations of the co-location process. Once data have been co-located and co-location events have been identified, formal uncertainty characterisation can be performed, or other comparison metrics such as the bias, RMSE and correlation coefficients can be calculated (e.g. Verhoelst et al., 2026).
A good spatiotemporal co-location requires that there are sufficient co-location events for the subsequent analysis to be viable. Conversely, the co-location cannot permit so much data that the subsequent analysis is contaminated with data being compared between two physically independent sets of observations. Finding a parametrisation for a co-location scheme that balances the need for sufficient data, whilst minimising the co-location mismatch between the compared data within a co-location event is the crux of the problem, and is as yet unsolved (Langsdale et al., 2025).
As an example, when comparing data between a satellite and a surface based observatory, a simple and often used co-location scheme is to generate co-location events when the satellite measurement footprint falls within some along-ground distance R of the surface based observatory, and to subset the surface based data with a temporal window of duration τ, centred on the time of closest approach of the satellite to the observatory. By doing this, individual co-location events (often described as overpasses) are small segments of a single orbit from the satellite, and the data is often averaged along-track to obtain a single vertical profile or scalar value that can be compared against temporally averaged data from the surface-based observatory (e.g. Alexander and Protat, 2018; Baars et al., 2023; Liu et al., 2017; Lu et al., 2021; Mamouri et al., 2009; Martin et al., 2021; Mona et al., 2009; Pappalardo et al., 2010; Pauly et al., 2019; Proestakis et al., 2019; Protat et al., 2009; Robinson et al., 2025; Schuster et al., 2012). Each of the studies using the aforementioned co-location scheme to match data between a satellite and surface-based observatory need to make a choice for the values of R and τ, the parameters affecting the spatiotemporal volumes within which data must have been recorded in order to be permitted in subsequent analyses.
When deciding how data are co-located, care must be taken to ensure the co-location parametrisation is selected independently of the results of the subsequent analysis (von Clarmann, 2006). Some studies justify the choice of their co-location parametrisations qualitatively (e.g. Baars et al., 2023; Blanchard et al., 2014; Fuchs et al., 2022; Lu et al., 2021; McErlich et al., 2021; Proestakis et al., 2019; Robinson et al., 2025; Sayer et al., 2020). Some studies test the effects of changing the co-location parameters empirically (e.g. Alexander and Protat, 2018; Eibedingil et al., 2021; Pappalardo et al., 2010; Protat et al., 2009) however, these studies use the comparison metric being used in the subsequent analysis to justify or inform the choice of co-location parametrisation. The comparison metric is an unknown quantity (hence the need for the analysis in the first place), so by using the value of the comparison metric to inform the co-location parametrisation – which in turn affects the estimate of the comparison metric itself – a prior expectation is effectively applied to the comparison metric in the analysis.
For example, the linear correlation coefficient between retrieved values is often used as a comparison and validation metric. Often, the co-location parametrisation that maximises the correlation coefficient is selected (e.g. Eibedingil et al., 2021; Pappalardo et al., 2010; Schuster et al., 2012). The computation of the correlation coefficient is an estimate, with bias and variance depending on the data permitted by the co-location. By selecting a co-location parametrisation that maximises the correlation coefficient, we are preferentially selecting results with larger correlation coefficients, which could arise from the variance in the estimation, rather than an actually better comparison between the measurements. This is akin to over-fitting models to our data. The outcome: results will look better than they potentially are. For example, the uncertainty budgets for retrievals may be underestimated and inferred biases could be too small in magnitude.
As such, an independent metric for assessing the quality of data co-location is necessary. By treating measurements as samples drawn from probability distributions of underlying geophysical fields, and paired measurements within a co-location event as being drawn from a joint probability distribution, we propose the mutual information between data within co-location events as an appropriate metric to assess the quality of spatiotemporal co-locations. Mutual information balances the requirements for sufficiently sampling the available system states such that we can infer relationships between the data, whilst being sensitive to the inclusion of comparisons between physically independent samples.
From this, we outline a generalised framework for evaluating optimised co-location parametrisations by maximising the mutual information between data to be compared. For any co-location scheme that can be parametrised with a finite number of parameters (Sect. 2.1), the mutual information (Sect. 2.2) is estimated between the data permitted by the co-location (Sect. 2.3), and the optimised co-location parametrisation is selected as the parametrisation that maximises the mutual information (Sect. 2.4). We demonstrate the framework by applying it to a comparison between the ICESat-2 ATL09 cloud layer product and macrophysical cloud products derived from four Cloudnet observatories (Sect. 3).
2.1 Framework definitions
The outcome of this framework is the co-location of data where the information shared between the two retrievals is maximised. As described in Loew et al. (2017), before validation metrics between datasets can be calculated, three key steps must be performed: quality checks, to ensure the data being compared are realistic, self-consistent, and reasonably well characterised; spatiotemporal co-location, ensuring that the data being compared represent sufficiently similar measurements in time and space, and; homogenisation, whereby any further transformations to the data (unit conversions, temporal or spatial aggregations, etc.) are applied, allowing like-to-like comparisons to be made between the homogenised data. In this framing, both the quality checks and co-location processes act to subset the data, permitting observations that meet both the quality requirements and co-location criteria to be used in the homogenisation process. Throughout this work, we will refer to co-location schemes, criteria, parametrisations and events.
-
Co-location scheme. The method by which data from two or more data sources are matched with each other. Some example co-location schemes are outlined in Fig. 1.
-
Co-location criteria. The logical statements that implement a given co-location scheme. The co-location criteria often take the form of inequalities, with data satisfying the inequalities being included in the analysis.
-
Co-location parametrisation. A vector specifying the values of variable parameters used in the co-location criteria. These can be described by a general parametrisation vector, p = , where M is the number of values required to fully describe the co-location scheme.
-
Co-location event. A discrete unit of matched homogenised data between the co-located data sources that simultaneously satisfy all of the co-location criteria.
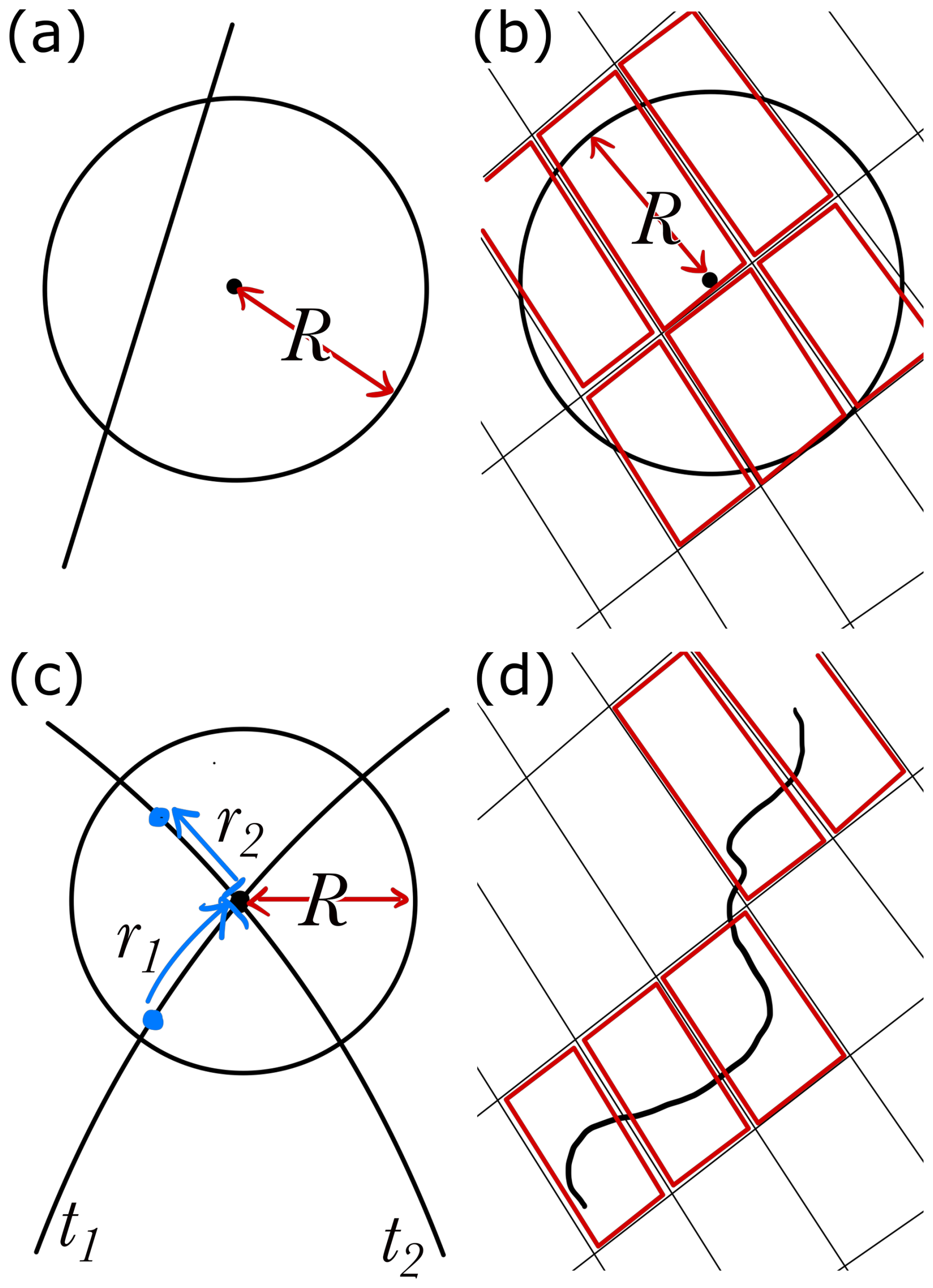
Figure 1Example realisations of spatial co-location schemes between data of different spatial dimensionalities. (a) A point-line co-location, where the data falling within a distance R of the point data source is utilised from the line source. (b) A point-area co-location, where pixels whose centres fall within a distance R of the point data source are used. (c) A line-line co-location where data falling within a distance R of the crossing point between the lines is used. (d) A line-area co-location, where a minimum path length, l, must be traced within each pixel in order for the pixel to be used in the analysis. In panels (b) and (d), the pixels highlighted in bold (red) are those selected to remain in the homogenisation process. Each spatial co-location scheme will also be paired with a temporal co-location scheme. References for each co-location scheme are provided in Sect. 2.1.
The framework requires that the co-location criteria for a given co-location scheme can be described by a finite number of parameters, which is applicable for all realistic co-location schemes. The co-location scheme can be arbitrary, but it should be physically motivated to achieve better results. Figure 1 shows four possible co-location schemes between data of different dimensionalities. Panel (a) shows a scheme for co-locating satellite swath data and point-like surface based observations, as was described in the introduction (e.g. Alexander and Protat, 2018; Baars et al., 2023; Blanchard et al., 2014; Liu et al., 2017, 2010; Lu et al., 2021; McErlich et al., 2021; Pappalardo et al., 2010; Proestakis et al., 2019; Protat et al., 2009; Robinson et al., 2025; Schuster et al., 2012). Panel (b) instead shows a possible scheme for matching data between a 2-dimensional source (e.g. a grid of pixels) and a point source of data (e.g. Compernolle et al., 2021; Deneke et al., 2009; Eibedingil et al., 2021; Fuchs et al., 2022; Papagiannopoulos et al., 2016; Protat et al., 2014b; Roebeling et al., 2008). Panel (c) shows a possible co-location scheme between two 1-dimensional data sources – possibly two satellite ground tracks (e.g. Protat et al., 2009; Wang et al., 2024). Data are subset based on it falling within a circle of radius R, common to both data sources, and centred on the location where the paths cross. There is a second criterion, that the time difference between the data sources being at the crossing point should be less than some upper bound τ, where ri are the distances of data from source i to the crossing point, and ti are the times associated with data from source i being at the crossing point. Thus, the co-location scheme leads to the co-location criteria of ri≤R and . The co-location criteria can be described by the parametrisation p = (R,τ). Co-location events consist of paired homogenised data between the two satellites where their orbital paths intersected within a time τ, and the data are spatially subset within the circle of radius R.
Although the above co-location schemes are basic and naive to the underlying physical processes that govern the spatiotemporal gradients of the measurands, our knowledge of the underlying processes can be encoded into the co-location scheme through the inclusion of additional co-location criteria and higher dimensional co-location parametrisations. For example, if co-locating atmospheric data between a satellite and ground-based station, the co-location scheme in Fig. 1a could be augmented to encode our expectations about how local advection may affect the spatiotemporal co-location of the data. For example, more complex schemes could allow us to encode our expectations of how local advection would affect the spatial distribution of (in)dependent samples between data sources, through the implementation of logical criteria on ancillary wind data.
2.2 Mutual information
In this framework, we treat the underlying physical state as being independent between co-location events. Thus, we treat the underlying physical state of the system being measured as a random variable drawn from the distribution of all plausible system states. Measurements are affected by this randomness, as well as other confounding variability due to co-location mismatch and detector noise (for example). As such, pairs of measurements within a co-location event should be related by a joint probability distribution that accounts for the distribution of system states and the additional variability. If the measurements being made are not independent, the joint probability distribution will have some non-independent structure that can be used to inform us about the relationship between the measurements. Mutual information is a concept derived from information theory (e.g. Shannon, 1948) that we use as a quantitative metric to assess the quality of the relationship between sets of retrievals when co-locating the data with different co-location parametrisations. Stone (2022) provides a good introduction to the concepts of information theory.
Nearing et al. (2017) describes the entropy of a variable X, H(X), as a measure of our ignorance about the variable X prior to observation, and as the average quantity of information we stand to learn by measuring X.
where p(X) is the probability of the variable having a given value, and 𝔼X is an expectation value taken over all possible values of X. Nearing et al. (2017) describes mutual information between two random variables X and Y as the expected reduction in our ignorance of the possible values of X, given our knowledge of the value of Y. Mutual information is expressed as
where p(X,Y) is the joint probability of the outcome of X and Y occurring simultaneously, p(X) and p(Y) are the marginal distributions of X and Y respectively, and 𝔼X,Y represents an expectation over all possible pairs of X and Y. Mutual information has units depending on the base b of the logarithm used in the information theoretic equations, with b = 2 giving units of bits, and b = e giving units of nats. Conversions between information theoretic units consists of linearly scaling the information theoretic values.
In our framework, X and Y are the retrievals or measurements of underlying physical quantities that we wish to compare or relate. In the limiting case that X and Y are independent, we obtain p(X,Y) = p(X)p(Y), and Eq. (2) yields a value of I = 0. Otherwise, the mutual information encoded between the measurements will be positive, with larger values indicating greater reductions in our ignorance of the pair of measured values given access to one of the values.
When co-locating data between data sources in order to compare the data, we want to include data that best characterises the relationship between the data sources. The best possible relationship between our data is a one-to-one mapping between values X and Y. In this case, knowledge of one variable fully determines the value of the other. This case is equivalent to minimising our ignorance of the joint value of the two retrievals, and is equivalent to maximising the mutual information between the retrievals.
This is shown in Fig. 2. Two variables, X and Y, each with a fixed marginal distribution (Fig. 2a–c), take on two distinct joint probability distributions (Fig. 2d–e). Figure 2d shows X and Y as being independent variables. The probability density is distributed throughout the space, and the probability of X given any value of Y simply follows the marginal distribution p(X). In this case, learning the value of Y yields no new information about the possible value of X, and the mutual information is estimated to be near zero. The value of = −0.002 nats can be negative as a result of it being empirically estimated (see Sect. 2.3). In Fig. 2e, X and Y have a strong non-linear dependency. If we know the value of Y, our ignorance about the possible values of X decreases substantially, as X almost certainly falls on the manifold mapping Y to X. There is obvious structure in the joint probability distribution that can be learned, and as a result, the mutual information estimate = 1.965 nats is higher when X and Y are dependent compared to being independent.
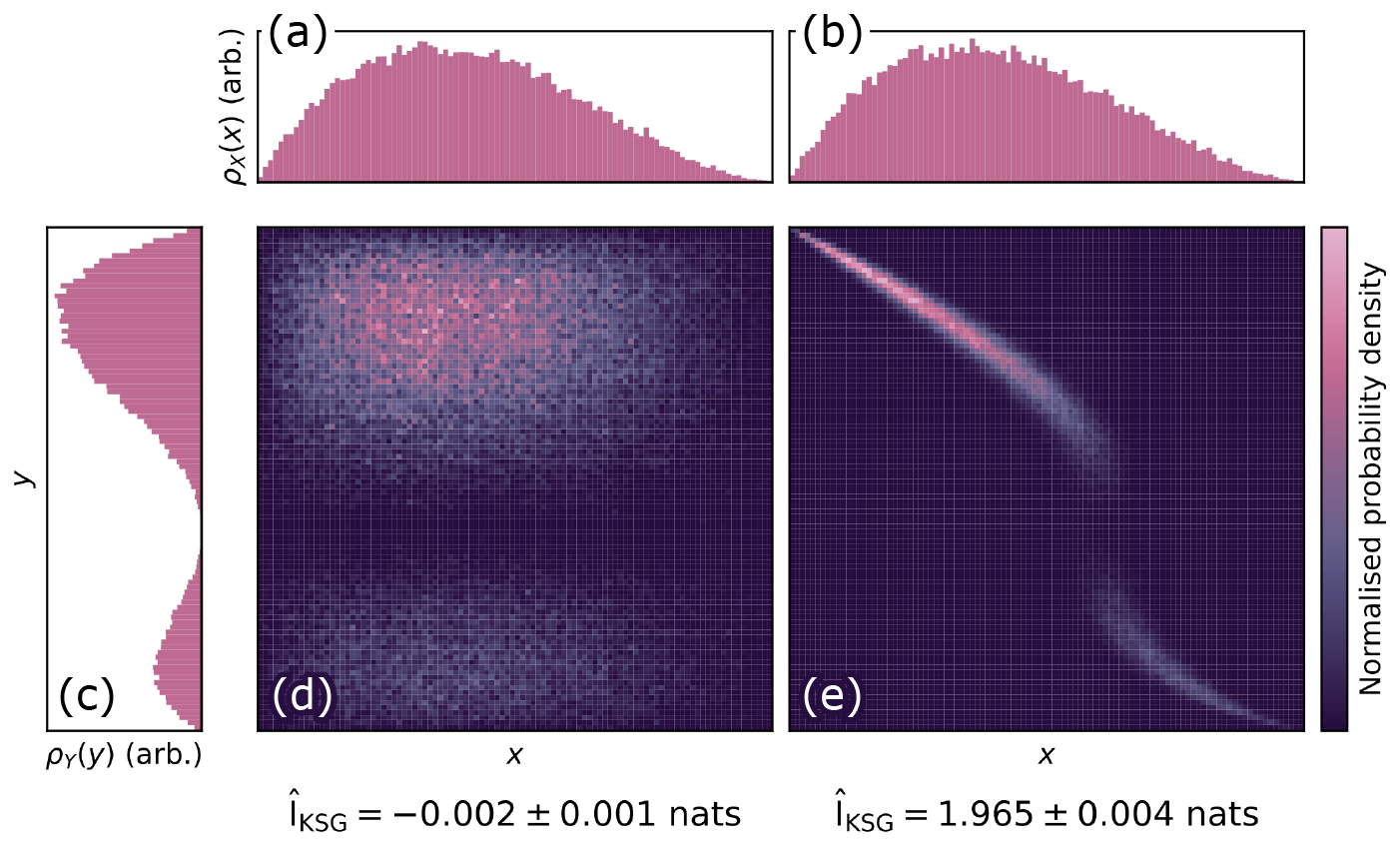
Figure 2Two synthetically generated variables X and Y with fixed marginal distributions (a, b, c) form two different joint probability distributions (d, e). X and Y are independent in panel (d), but have a strong non-linear dependence in panel (e). When there is dependence between the variables, the probability density is spread across fewer possible states. Mutual information, IKSG (given below d and e), captures this structure, increasing as the individual variables encode more information about the joint distribution.
It is of note that the mutual information between the data X and Y is invariant under reversible transformations X → X′ and Y → Y′. Conversely, it can be shown through the data processing inequality (e.g. Cover and Thomas, 2006; Polyanskiy and Wu, 2024) that if X′ is computed independently of Y, or Y′ is computed independently of X, that the post-processing steps can only act to decrease the mutual information between X′ and Y′. That is,
with equality holding only if the transformations X → X′ and Y → Y′ are both reversible. Thus, for computing mutual information between homogenised geophysical variables, the number of irreversible post-processing corrections to the data that would be applied to a typical analysis should be minimised. For example, range corrections to lidar backscatter data are reversible, as they consist of multiplication by a fixed factor for each data point. Thus, these type of range corrections can be applied, but have no impact on the mutual information. A noise reduction process like a rolling-window average however is irreversible, so would act to reduce the mutual information between the two data sources.
2.3 Mutual information estimation
The definition for mutual information given in Eq. (2) requires full knowledge of the joint probability distribution between the variables in question. We have incomplete knowledge of the marginal and joint probability distributions from which our measurements are sampled. Thus, we need to estimate mutual information, and the estimator must be able to handle a finite number of continuous valued samples as input. Problems in the Earth sciences may require comparison of multiple variables simultaneously, or of vector quantities. Thus, mutual information estimators that also handle higher dimensional samples from probability distributions are preferable.
One method to estimate the mutual information is to discretise the measurements and produce a histogram approximating the underlying probability distributions (e.g. Beirlant et al., 1997), as is demonstrated in Fig. 2. This method requires that a sufficient number of joint measurements are made in order to well characterise the joint probability distribution. As mutual information is a measure of the structure of the joint probability distribution, the choice of histogram bins into which the data are discretised is very important. The bins need not be uniform in size, and adapting the bins to the data can decrease the bias and variance of the estimator (Darbellay and Vajda, 1999).
Another commonly employed method is estimating the mutual information from nearest neighbour distances between samples in the sample space (e.g. Kraskov et al., 2004; Holmes and Nemenman, 2019). Regions of the sample space with high probability density will likely be sampled more frequently than regions with lower probability density, resulting in samples drawn with low separations between them, indicating structure in the distribution. Holmes and Nemenman (2019) describes a method that extends the mutual information estimators described in Kraskov et al. (2004), , from 1-dimensional to multidimensional samples from both X and Y, and a way to characterise the bias and variance of the estimator. The extension of a nearest neighbours method to multidimensional samples allows fast and (relatively) computationally efficient calculation of mutual information compared to discretisation methods.
2.4 Parametrising co-location criteria by maximising mutual information
A good comparison between data requires that comparisons are made between retrievals from co-location events that well sample the physically possible underlying system states. This amounts to obtaining enough co-location events such that the marginal distributions of all retrievals are well sampled.
The reliable estimation of the mutual information requires a certain number of co-location events to be permitted by a co-location parametrisation p. Some p will permit too little data for the mutual information estimators to learn structure in the joint probability distribution, resulting in an underestimation of the mutual information. At some point, parametrisations p will permit sufficient data for the mutual information estimator to accurately estimate I(X;Y) (assuming no contamination by independent data), when the individual measurement marginal distributions are well sampled. Thus, having parametrisations permit more data leads to increases in , until the estimated ≈ I, and additional co-location events provide no new information about the joint distribution of the retrievals being compared.
At some point, parametrisations will produce co-location events matching data within a sufficiently large spatiotemporal volume, such that the data contributing to the co-location event from different sources originate from physically independent observations. This will contaminate the joint probability distribution being assessed with independent samples. Appendix A demonstrates, using a toy model, that contaminating the comparison with independent data necessarily reduces the upper bound of the mutual information encoded between retrievals. Thus, for p permitting data co-location within large enough spatiotemporal volumes, increasing the spatiotemporal volume should act to decrease the mutual information.
Figure 3 implements the toy model described in Appendix A1 to demonstrate the effects of a co-location parametrisation permitting too little and too much data. Figure 3a shows a data limited regime, in which there are deficient samples for learning the structure of the relationship between the variables reliably. The mutual information between the variables can be improved by further sampling, as is shown in Fig. 3b. In this case, there is no contamination and the significantly denser sampling results in a value of = 1.984 ± 0.015 nats. Figure 3c–d show the effects of contamination with independent data, and how it rapidly reduces the estimated values to near zero when the signal to noise ratio is highest in panel (d).
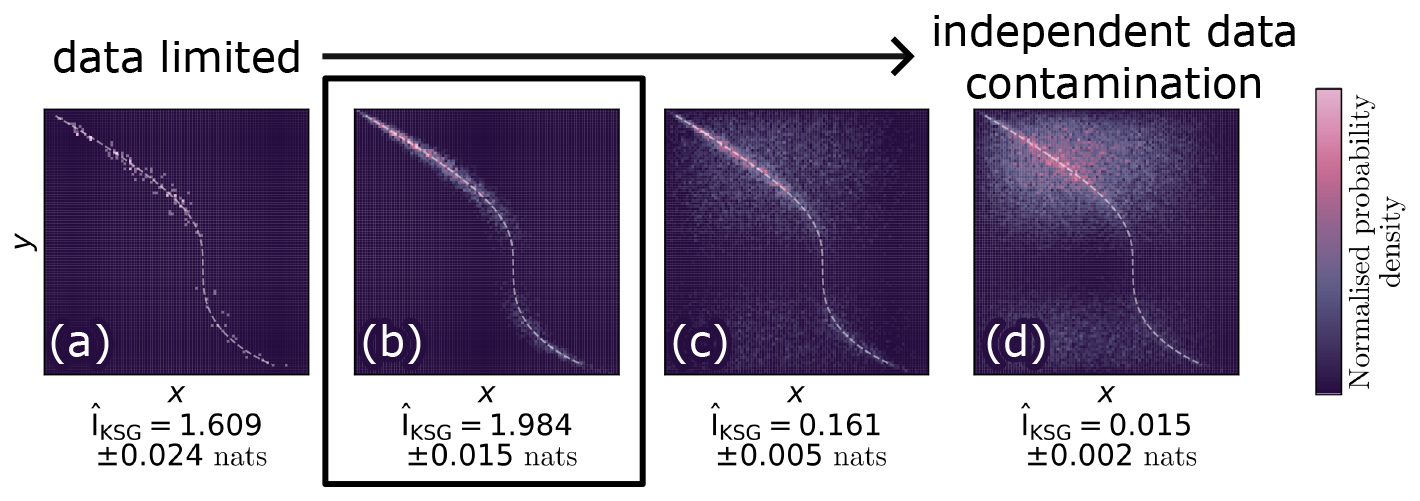
Figure 3A demonstration of how a data-limited (a) and independent data contaminated (c–d) regime reduces the estimated mutual information encoded between two variables X and Y, when compared to a case when X and Y are well sampled without contamination from independent data (b). Panel (b) represents the best scenario for a co-location. In all cases, X and Y are synthetic and generated from the same marginal distributions as in Fig. 2.
Thus, there are two main factors influencing : a data limited regime in which the inclusion of more data acts to increase and; a contaminated data regime in which the inclusion of more data increases the proportion of independent samples being compared, which acts to reduce . We postulate that a parametrisation exists for which the mutual information is maximised, where the competing effects of including more comparable samples and more independent samples are balanced. At , the relationship between the retrievals, encoded in their joint distribution, is best characterised, and this should be the co-location parametrisation used in any subsequent analysis.
Thus, in order to optimise the co-location parametrisation , the steps are:
-
Identify a set 𝒫={p}, describing a range of plausible parametrisations.
-
For every p∈𝒫, perform quality checks and spatiotemporal co-location subsetting according to p on the data to be compared.
-
Apply the chosen mutual information estimator to the co-located homogenised data, to obtain .
-
Identify the optimised co-location parametrisation as the parametrisation maximising . That is
In the following section, we will demonstrate the application and usefulness of this framework by co-locating satellite and surface based retrievals of vertical cloud fraction, and showing that the comparison is optimised by choosing the co-location parametrisation over other values.
3.1 ICESat-2 ATL09 cloud layer product
ICESat-2 is a polar orbiting satellite, launched by NASA in 2018, and is the only satellite currently in orbit with the capability to make vertically resolved observations polewards of 83° north and south (Markus et al., 2017). The satellite has a single instrument payload, the Advanced Topographic Laser Altimeter System (ATLAS) – a photon counting lidar predominantly designed for altimetry (Neumann et al., 2019). To aid analyses of the altimetry data, atmospheric backscatter products are produced to facilitate quality checks on the altimetry data products. The ATL04 normalised relative backscatter profiles product is a level 2 product derived from the photon point-cloud data provided by ATL02 (McGarry et al., 2021). ATL04 consists of photon returns that are vertically aggregated and summed over 400 consecutive laser pulses, to produce a data product with 30 m vertical resolution and 280 m along-track resolution. Photon counts are reported in a vertical range from 250 m below an on-board digital elevation model (DEM) to 13.75 km above the DEM. The ATLAS lidar transmits six laser beams, split into three pairs of a strong and weak beam, with the strong beams transmitting four times more power than the weak beams. The ATL04, and subsequently the ATL09 product, use the measurements from the three strong beams, producing three sets of vertically resolved observations.
The ATL09 calibrated backscatter and atmospheric layers data product (Palm et al., 2021, 2023) derives from the ATL04 data product, with the aim of characterising the state of the atmosphere through which ICESat-2 performs its altimetry measurements. Due to the challenges associated with absolute calibration of the backscatter profiles, the high noise rate, and the folding of signals into a 15 km window (Palm et al., 2021), a bespoke cloud detection algorithm was developed, the density dimension algorithm (DDA, Herzfeld et al., 2021).
Although ATL09 calibrated backscatter profiles have been compared against profiles from a cloud physics lidar, and CALIPSO (Palm et al., 2021), and the DDA has been demonstrated for cloud and blowing snow detection over Antarctica (Herzfeld et al., 2021), no validation of the produced cloud layer product has been made against surface based cloud observations. This study will demonstrate the framework outlined in Sect. 2 whilst providing an initial comparison of the ICESat-2 ATL09 cloud layer retrieval against surface based retrievals.
Quality checks for the ATL09 data are described in Appendix B1. The homogenisation process transforms the atmospheric layer boundaries reported – pairs of cloud top and cloud base heights – into a categorised feature mask distinguishing between clear sky, cloud, and attenuated regions where the presence of atmospheric scatterers cannot be determined. Vertical profiles of the feature mask are subset according to the co-location criteria (outlined in Sect. 3.3). The feature mask is then horizontally averaged across all the remaining profiles to produce vertical cloud fraction (VCF) profiles. The VCF profiles are then homogenised by being vertically interpolated onto a set of 50 height coordinates with a vertical spacing of 240 m.
3.2 Cloudnet
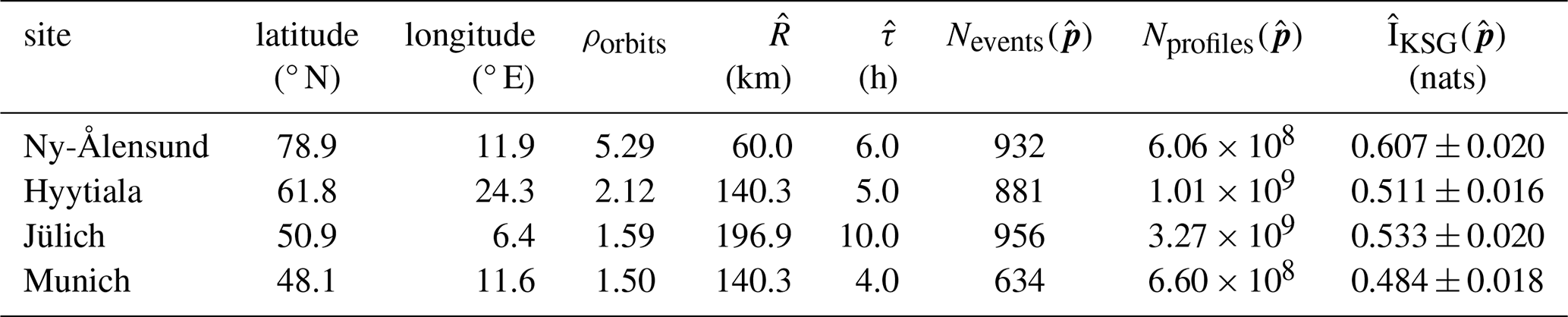
The Cloudnet retrieval (Illingworth et al., 2007) produces products that categorise the atmospheric profile above a given observatory by optimally combining available retrievals from multiple data sources. Cloudnet synthesises data from ground-based radar, lidar, microwave radiometer, and weather forecast models to produce fields of macrophysical and microphysical quantities such as temperature, cloud occurrence and ice water content. There are 28 main Cloudnet sites, with numerous campaigns and ARM sites also contributing data. For this study, we use data from four observatories: Ny-Ålesund, Hyytiala, Jülich and Munich (Ebell et al., 2025). The location of each site is outlined in Table 1.
Table 1The locations of the Cloudnet sites used in the analysis, and important results of the mutual information calculation between the ATL09 and Cloudnet VCF profiles at each site. ρorbits represents the normalised across-track density of ICESat-2 orbits at the latitude of the Cloudnet site. = represents the optimised parametrisation at which the maximum mutual information, , is found. Nevents(p) is the number of co-location events from which data is included with a parametrisation p. Nprofiles(p) is the number of pairwise profile comparisons made between ATL09 and Cloudnet VCF profiles across all co-location events for a given parametrisation p.
To produce the homogenised VCF profiles used in our analyses, we start with the Cloudnet categorize product, which holds the calibrated synthesised data (accessed through the Cloudnet FMI website, Ebell et al., 2025). Following the definition of cloud mask in the code presented in Tukiainen et al. (2020), we extract the cloud mask as the feature mask used in the analysis. The full quality check process is described in Appendix B2. The vertical profiles of the feature mask are then subset according to the temporal co-location criteria described in Sect. 3.3. Like the ATL09 homogenisation process, the Cloudnet-derived feature masks are horizontally averaged to produce profiles of vertical cloud fraction, and vertically interpolated onto a set of 50 height coordinates with a vertical spacing of 240 m.
3.3 Co-location scheme
Data from Cloudnet and ATL09 are co-located using the co-location scheme shown in Fig. 1a. Projected onto the Earth's surface, the spatial co-location scheme treats each Cloudnet site as a 0-dimensional point-like source. The ATL09 data then constitutes three distinct 1-dimensional line-like sources – one for each ATLAS strong beam. For each vertical profile in each of the three beams from the ATL09 data, here indexed with subscript j, the great-circle distance between the profile's footprint on the ground, and the location of the Cloudnet site, rj, is calculated. The criteria for accepting the ATL09 data is
such that all profiles falling within a distance R across the Earth's surface of the Cloudnet site are kept in the analysis.
The temporal co-location scheme first requires finding the time of closest approach between ICESat-2 and the Cloudnet site, t0. This is simply the time associated with an ATL09 profile j that minimises rj. That is,
To subset the Cloudnet data, for each Cloudnet profile with index l, the criteria applied is
where tl is the time associated with the given Cloudnet profile l. This subsets the Cloudnet data based on the profile being recorded within a temporal window of duration τ, centred on the time of closest approach. Thus, the co-location of the ATL09 and Cloudnet data can be parametrised as p = (R,τ).
Figure 4 shows a demonstration of the co-location of ATL09 and Cloudnet data at Ny-Ålesund. In the ATL09 granule, ICESat-2 ground tracks passed within 18 km of the Cloudnet observatory at Ny-Ålesund. Figure 4a shows the locations of the ATLAS strong-beam footprints in relation to the Cloudnet site as ICESat-2 travelled from north to south.
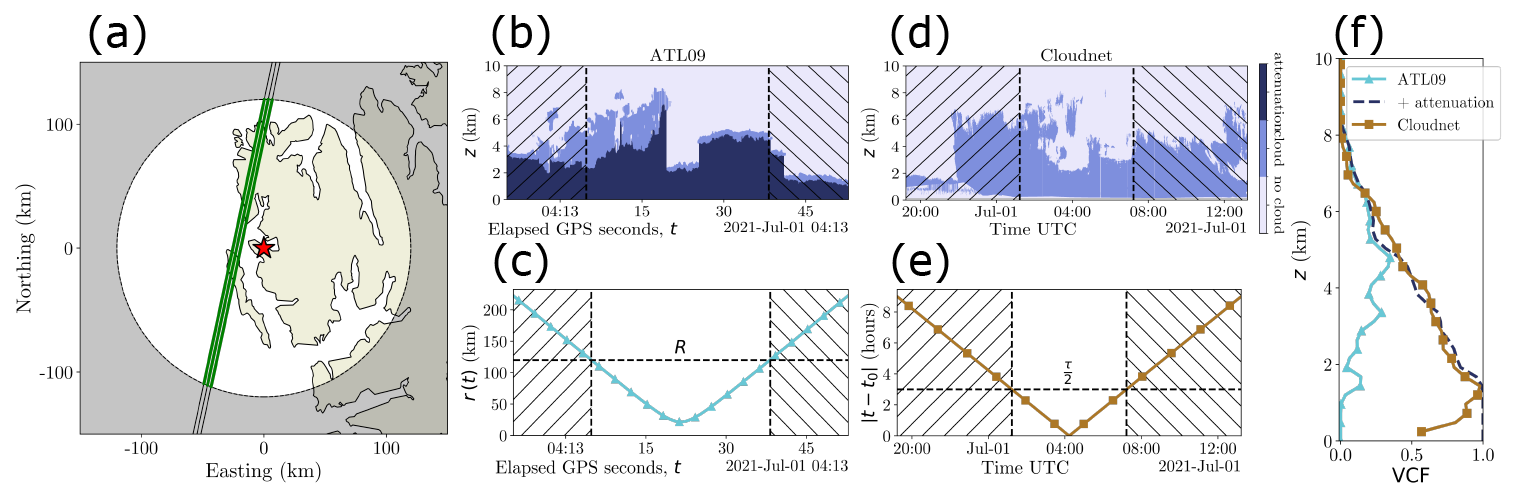
Figure 4The co-location of ATL09 and Cloudnet data at Ny-Ålesund, with ATL09 data from the granule with reference ground track 115 on cycle 12 (dated 1 July 2021), using the co-location parametrisation p = (125 km, 6 h). (a) The Cloudnet observatory (star), and the three ATLAS strong beams (lines). A circle of radius R = 125 km is drawn around the Cloudnet site. (b) The feature mask generated from the ATL09 data associated with strong beam 1, showing where ATL09 retrieves clouds and is attenuated. (c) The distance between the ATLAS ground track and Cloudnet observatory, showing the co-location criteria subsetting of the cloudmask. The unhatched region contains the vertical profiles contributing to the co-location. Panels (d) and (e) are the same as panels (b) and (c), but for the Cloudnet data contributing to the co-location event. (f) Vertical cloud fraction profiles for the ATL09 and Cloudnet feature masks, as well as the vertical cloud and attenuation profile for the ATL09 feature mask, subset by the co-location parametrisation.
Figure 4b shows the ATL09 cloudmask from the granule. The observed clouds are optically thick enough to attenuate the ATLAS lidar beam throughout the co-location event, so lower level cloud layers will be missed. Layers are detected across a range of heights, with cloud tops varying from 2 up to 8 km. Figure 4c plots the spatial co-location criteria from Eq. (5) as the satellite travels near Ny-Ålesund. The distance from the lidar beam to the ground forms a hyperbolic curve with a minimum separation of 18.4 km. This results in the volume of ATL09 data per overpass being asymptotically linear in R. The horizontal dashed line represents the spatial co-location parametrisation of R = 125 km, and the vertical dashed lines seen in Fig. 4b–c are the boundaries of the subset data based on the spatial co-location criteria, with hatching showing the data rejected by the co-location scheme.
Similarly, Fig. 4d–e show the feature mask and temporal co-location criteria applied to the Cloudnet data during the overpass. Early profiles in the mask show low cloud layers between 1 and 2 km, growing into a thicker cloud layer ranging from near the surface up to 8 km high, with the top height varying throughout the co-location event. The co-location criteria plotted forms a piecewise linear function, the result of this being that the volume of Cloudnet data used in the analysis is linear in τ.
Figure 4f shows the output of the homogenisation process on the ATL09 and Cloudnet data. The feature masks, subset by the co-location criteria, are horizontally averaged over all included vertical profiles, producing VCF profiles. A profile of the cloud and attenuation fraction is also given for the ATL09 data. Above 5 km in height, both VCF profiles visually correlate with each other, indicating that the co-location between the ATL09 and Cloudnet data may be viable. However, below 5 km, the ATL09 VCF values are significantly lower than the Cloudnet VCF values, due to attenuation of the ATLAS lidar beam in the higher cloud layers, resulting in lower cloud layers being unobserved by ICESat-2. The ATL09 vertical cloud and attenuation fraction profile correlates with the Cloudnet VCF down to an altitude of roughly 1.5 km.
3.4 Mutual information estimation
With the homogenised ATL09 and Cloudnet data both being VCF profiles described on 50 height levels each, the joint probability distribution for pairs of VCF profiles is 100 dimensional. As such, we require a mutual information estimator that accepts multi-dimensional inputs.
The KSG mutual information estimator (Kraskov et al., 2004) and its adaptations to multidimensional data (Holmes and Nemenman, 2019), , will be used in this work. As inputs, we provide the matched sets of ATL09 and Cloudnet VCF profiles. The KSG estimator provides mutual information estimates in units of nats. This is a result of the estimator being derived using natural logarithms instead of logarithms with base 2. The conversion from nats to the more widely used unit bits is a scaling factor of (ln 2)−1 bits nat−1.
We use the estimator parameter k = 10, as testing on our data showed that it balances the decrease in estimator variance as k increases against the increase in bias and computational cost as k increases. The variance of the KSG estimator, , can be estimated as following the form (Holmes and Nemenman, 2019, Appendix 1)
where N is the number of samples used in estimating , and B is a constant parameter to be evaluated. In the maximum likelihood estimation of B, we produce ni = 10 non-overlapping partitions of the original data to compute , and perform this nrepeats = 20 times to evaluate B.
As well as identifying the optimised parametrisation , we also identify regions of the parameter space where are consistent with the value of (the maximum estimated mutual information), giving a region with finite extent from which an optimised parametrisation could feasibly be selected. To do this, we perform an unequal variances (Welch's) t test for each p ≠ to test the null hypothesis that the mean estimated mutual information at p is equal to the mean estimated mutual information at – that is that = . Parametrisations p for which the null hypothesis cannot be rejected with a significance of 0.05 are considered candidate optimised parametrisations. Conversely, parametrisations for which the null hypothesis is rejected are not considered as candidates for the optimised parametrisation.
In our analysis, we will use the parametrisation that maximises the mutual information between the ATL09 and Cloudnet VCF profiles, but other strategies could be employed to select which candidate optimised co-location parametrisation will be used (e.g. maximising the data volume permitted by the co-location). If two parametrisations yield negligibly different mutual information values, it is up to the researcher to decide which parametrisation they should use, considering any trade-offs between the use of additional data and any increased computational costs the additional data may incur.
3.5 Validation metrics and methodology
Once we have evaluated the optimised co-location parametrisations for each Cloudnet observatory, we perform a basic comparison of the co-located ATL09 and Cloudnet VCF profiles to demonstrate the impact of using a co-location parametrisation with maximised mutual information instead of other choices of parametrisation.
We compute confusion matrices classifying VCF values into three categories: containing no cloud (nc), when VCF=0; being partially cloudy (pc), when 0 < VCF < 1; and being totally cloudy (tc), when VCF = 1. We make the distinction between nc, pc and tc cases, as VCF values are defined on the closed interval [0,1], but the probability distribution has degeneracies at 0 and 1, when scenes with no or total cloud cover happen with finite probability. This results in the probability distribution of VCF values having Dirac-delta like contributions at 0 and 1, but being otherwise continuous on the open interval (0,1).
Having computed confusion matrices, we then compute copula densities between pairs of VCF values across all co-location events and heights within VCF profiles. A copula is the multidimensional extension of the cumulative distribution function for multiple random variables. Random variables are transformed by the probability integral transform – that is, values x for a random variable X with cumulative distribution function FX(x) are transformed into the variable U with values u = FX(x), such that U is uniformly distributed on the interval [0,1]. In the bivariate case, with variables X and Y, transformed into the variables U and V respectively, the copula is computed as
which represents the probability that both uniformly distributed variables U and V are less than their respective coordinates at the same time. Because the marginal distributions of all variables contributing to a copula are uniform, the structure of the copula captures the dependency structure between the variables, independent of the marginal distributions of the original random variables.
In the same way that a probability density function can be obtained by differentiating a cumulative distribution function, so too can a copula density function be obtained by repeated differentiation of the copula. In the bivariate case,
For independent variables, the copula is given as Cindependent(u,v) = uv. From this, we derive the independent copula density as cindependent(u,v) = 1 uniformly. Thus, we can interpret copula densities greater than 1 as giving pairs (u,v) (and by extension (x,y)) that are sampled more frequently than if the variables U and V were independent. Conversely, copula densities less than 1 indicate regions of (u,v) that are sampled less frequently than if the variables were independent. Schölzel and Friederichs (2008) provide a good introduction to methods and interpretation concerning copulae.
Copula densities with values further from 1 indicate that the underlying distribution is dissimilar to the independent joint distribution, which is the desired quality of the co-location. We define the root mean squared difference (RMSD) as a metric of the difference between a copula density and the independent copula:
Larger RMSD values indicate that a given copula density differs more from the independent copula. If the ATL09 and Cloudnet VCF measurements are entirely independent, c = 1 uniformly and the RMSD is zero. If there is dependency between the VCF distributions, then certain pairs of (u,v) values will be sampled more frequently than if the VCF distributions were independent (c(u,v) > 1) and, to conserve probability, some pairs (u,v) will be sampled less frequently than if the distributions were independent (c(u,v) < 1). The more dependent the VCF distributions are, the larger the area of (u,v) pairs for which will be, and the larger the magnitudes of will be in these areas. Thus, stronger dependency between the distributions will result in larger RMSD values. The RMSD attains a maximum value of 1 when c(u,v) describes a one-to-one mapping (e.g. c(u,v) = δ(u−v)).
For this analysis, with a given parametrisation p, we identify all co-location events i, and compute VCFATL09,i(z) and VCFCloudnet,i(z). We keep pairs of VCF values for each height z, and each co-location event if both VCF values are categorised as pc. We do this so that a valid copula density function can be defined without the degeneracies induced by considering cases with no or total cloud cover.
3.5.1 Vertical bias distributions
We compute the vertical distribution of bias between the ATL09 and Cloudnet VCF profiles as a function of height, ρbias(ν,z), where ν = VCFATL09 − VCFCloudnet is the bias, bounded between −1 and 1. The expected bias and variance of the bias as a function of height are calculated as
3.6 Results
3.6.1 Case study: Jülich
We will start by demonstrating the results of the mutual information computation at a singular site, Jülich, before showing the results across all four example sites.
Figure 5a shows the number of co-location events used in the study as a function of the co-location parametrisation. The Cloudnet data at Jülich forms a near-complete record, meaning co-location events are solely dependent on the availability of sufficiently close ICESat-2 orbital tracks. Thus, we expect no gradient in Nevents as a function of τ, which we see.
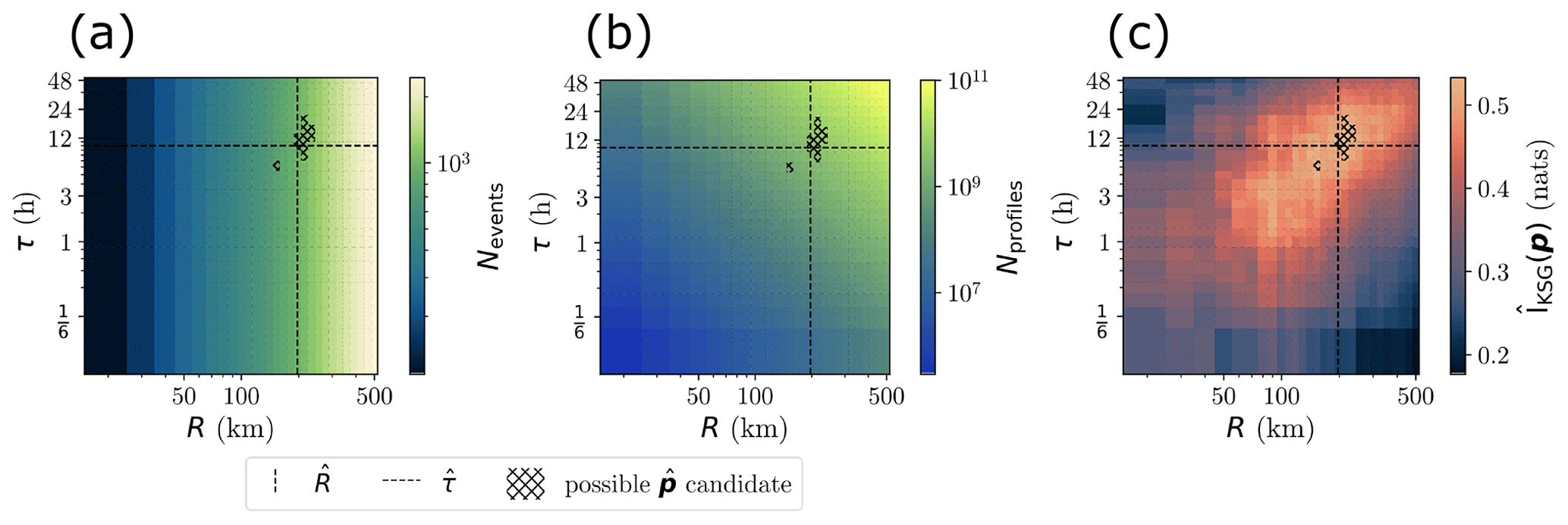
Figure 5The number of co-location events (a), pairwise vertical profile comparisons (b), and the mutual information (c) computed between ATL09 data and Cloudnet data from the observatory at Jülich, as a function of co-locations parametrisation p = (R,τ). The maximum mutual information (indicated by crossing dashed lines) occurs at = (196.9 km, 10 h). Hatching denotes regions of parameter space where is not significantly different from .
We should expect the number of co-location events to be approximately a linear function of R. At a given latitude, orbital ground tracks can be split into two sets, ascending and descending. Within each set, all orbital tracks are approximately parallel at a given latitude, so the number of events included in the analysis is the number of orbital tracks intersecting a line centred at Jülich, of length 2R, perpendicular to the orbital tracks. Given the rotational symmetry of repeating orbital tracks, the across-track density of orbits, ρorbits, can be approximated as constant at given latitude, and an equation approximating ρorbits is given in Appendix C. The outcome is that Nevents(R,τ) ∝ R. Given the logarithmic scaling of the colour map, and the plot coordinates, the smooth colour gradient seen in Fig. 5a indicates that Nevents is a polynomial function of R, consistent with the above arguments.
Figure 5b shows the number of pairwise vertical profile comparisons, Nprofiles, computed as
where i represents a co-location event, and ns,i is the number of vertical profiles from data source s, in co-location event i, included in the analysis after the application of the co-location criteria. This can be thought of as the volume of data being compared – if the homogenisation process was not to aggregate the data but instead compare individual observations in a pairwise fashion, this is the number of paired VCF profiles that would be available in the analysis.
As with Nevents, the smooth colour gradient in Fig. 5b indicates Nprofiles is approximately polynomial as a function of R and τ. We expect Nprofiles to be proportional to τ, as for each co-location event, the number of included vertical profiles linearly scales with the duration of the time window of length τ. We expect Nprofiles to be proportional to R2, one power coming from a proportionality to Nevents, and the other deriving from the fact that for each given co-location event, the number of included vertical profiles scales as a function of , which is approximately linear in R in the limit of R ≫ rmin. The results are consistent with Nprofiles(R,τ) ∝ R2τ.
Figure 5c shows the mutual information calculated according to Sect. 3.4 across all tested parametrisations. For each parametrisation p = (R,τ), a joint distribution of VCFs between the ATL09 and Cloudnet data could be plotted, akin to Fig. 3 (albeit in 100 dimensions), from which a value of the mutual information between the ATL09 and Cloudnet VCFs is computed. Mutual information values range from a minimum of 0.177 ± 0.010 nats at p = (500 km, 300 s), to a maximum of 0.533 ± 0.020 nats with = (196.9 km, 10 h). The mutual information surface has a ridge of higher values where the global maximum is found. As p moves away from , the mutual information appears to decrease roughly monotonically. In the region of lower R and τ values, this can be explained as the mutual information estimator being data limited. The KSG estimator acts on the pairs of VCF profiles as though they are drawn from a 100-dimensional joint probability distribution. In order to learn structure in this joint distribution and compute larger mutual information values, a sufficient number of co-location events must contribute to the analysis, so that the 100-dimensional distribution can be sampled densely enough to infer the structure.
For larger values of R and τ, we expect the rate of errors as a results of co-location mismatch to increase. This will contaminate the VCF comparisons with uncorrelated and independent profile comparisons. As is shown in Appendix A, the inclusion of independent data to the comparison necessarily decreases the possible upper bound of the mutual information. The surface seen in Fig. 5c is consistent with these expectations.
There is a region of p near for which are not significantly different from with a significance of 0.05, indicated by the hatching on Fig. 5c. This region represents other possible choices of an optimal parametrisation that provides similarly informative comparisons between the ATL09 and Cloudnet VCF retrievals at Jülich. The region predominantly exists for values of R ≥ , extending as far as ∼ 240 km. The possible values of τ range from ∼ 8 h (less than ) to ∼ 18 h (greater than ). As seen in Fig. 5a–b, the hatched regions represent similar or larger input data volumes when compared to , indicating that the KSG estimator could be not data-limited prior to incorporating sufficient independent data to contaminate the results, such that has attained its upper bound given the data distributions. There is also a smaller region of possibly optimised parametrisations found near p = (150 km, 6 h), with lower associated data volumes.
3.6.2 Mutual information at four Cloudnet observatories
We will start by considering the surfaces for Munich, Jülich and Hyytiala, as seen in Fig. 6a–c. Qualitatively, all three sites show a similar structure of a surface with a ridge of higher mutual information values that contains a single global maximum. These similarities in structure can be explained using the same arguments as in Sect. 3.6.1, with regions in the parameter space where the KSG estimator is data limited, and regions where the input data to the estimator is contaminated with independent samples. Despite structural similarities, the optimised parametrisations, , at each site differ, as do the magnitudes of . Values for , , and other quantities at each Cloudnet observatory are given in Table 1.
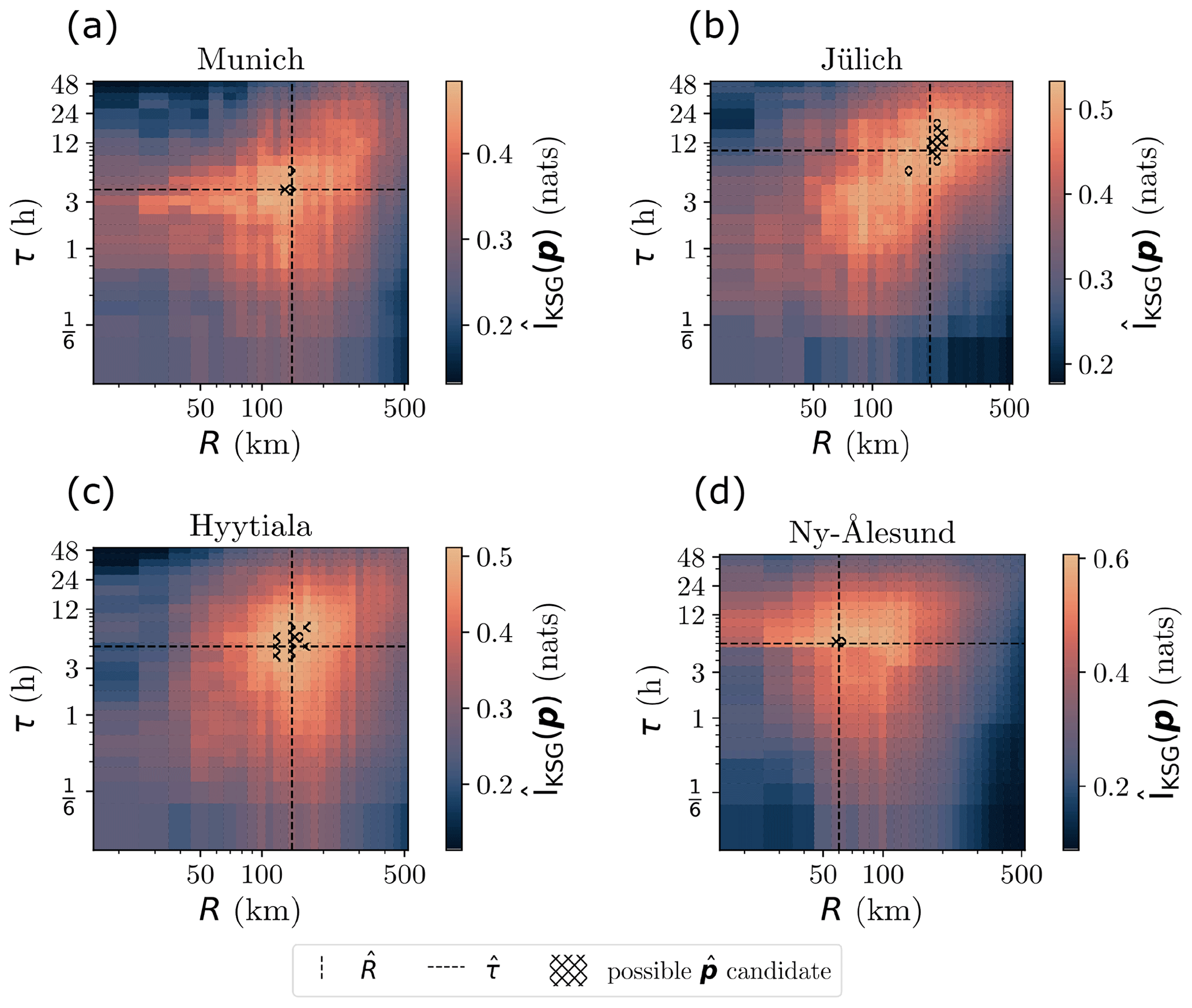
Figure 6The mutual information computed between ATL09 and Cloudnet VCF profiles as a function of co-location parametrisation p = (R,τ) for the Cloudnet observatories at Munich (a), Jülich (b), Hyytiala (c) and Ny-Ålesund (d). The location of the maximum mutual information value, , is indicated by the crossing dashed lines, and hatching indicates regions in parameter space where does not differ significantly from . Panel (b) is the same as Fig. 5c.
Table 1 shows that the optimised radius can vary on a per-site basis. For example, is larger than both and . One possible explanation for this is the relatively flat orography around the Jülich Cloudnet observatory, when compared (for example) to the proximity of the Munich observatory to the Alps. The mountainous orography of the Alps could result in smaller spatial scales over which local cloud formation is correlated, giving rise to smaller spatial informativity scales than at other locations like Jülich. The values of at Munich, Jülich and Hyytiala are similar orders of magnitude, ranging from 4 to 10 h. These values are consistent with the temporal scale of cloud evolution found in other studies (Shupe et al., 2011; Silber et al., 2018).
At Ny-Ålesund, the surface (see Fig. 6d) shares some qualities with the mutual information surfaces seen at the other Cloudnet observatories – the surface has a single ridge of larger values, with decreasing as p moves away from , and has a value of = 6 h, which is in the same order of magnitude as the values of at the other Cloudnet sites. The mutual information values increase sharply as R increases above R ∼ 50 km and as τ increases above τ ∼ 5 h. This sharp increase in the mutual information values results in the maximum = 0.607 ± 0.020 nats occurring at = (60 km, 6 h). The value of is lower than those found at the other three Cloudnet sites. This could partially be explained by the orography around Ny-Ålesund. The island of Spitsbergen, on which Ny-Ålesund is sat, is mountainous with peaks as high as 1700 m. The proximity of the Cloudnet observatory at Ny-Ålesund to the mountainous orography could lead to a reduced spatial autocorrelation scale between the clouds observed at the Cloudnet site and those to the East, that may be observed by ICESat-2. Thus, physically uncorrelated VCF comparisons would contaminate the mutual information calculation at smaller values of R than at other sites, reducing the value of .
Another more subtle effect impacts the value of at each site. For a given parametrisation p, the KSG mutual information estimator accepts Nevents(p) pairs of VCF profiles in order to estimate . is of a similar order of magnitude at Ny-Ålesund when compared to Hyytiala and Jülich, even with a substantially smaller value of . This is due to the local across-track density of orbits being an increasing function of latitude. As well as being linearly proportional to R, Nevents has a functional dependency on latitude, which is derived in Appendix C. The normalised across-track orbital density, ρorbits, is given for each site in Table 1. The higher local density of orbits at Ny-Ålesund compared to the other sites allows for more data to be used in the estimation of at Ny-Ålesund than at Cloudnet observatories at lower latitudes. This could result in denser sampling of the 100-dimensional joint probability distribution at lower values of R for more poleward locations. Thus, the mutual information estimator, being able to infer structure in the joint probability distribution at smaller values of R, switches from a data limited regime to being sensitive to the inclusion of independent VCF samples. This could result in the estimated value being reduced from the maximum attainable value at lower values of R at Ny-Ålesund than at other sites, as the structure has already been inferred by the KSG estimator, and the effect of contamination by independent data outweighs the inclusion of more VCF comparisons that may be related.
The hatched regions in Fig. 6 are unique across all four Cloudnet observatories, but can be split into two sets: Jülich and Hyytiala, being generally surrounded by flatter orography and having larger plausible extents in parameter space from which optimised co-location parametrisations can be selected, and; Munich and Ny-Ålesund, having much closer proximity to mountainous orography, and having substantially smaller regions of parameter space from which a plausibly optimised parametrisation can be selected – in the case of Ny-Ålesund, only a single tested parametrisation, specifically , can significantly be considered optimised. This split between the two sets suggests not only are the optimised parametrisations different between locations, but that the co-locations at each site are uniquely sensitive to the choice of p, with the sites located closest to mountainous orography being the most sensitive to the choice of co-location parametrisation.
By quantifying the mutual information encoded between our data, we learn where and when we should be selecting data around each Cloudnet observatory, and find that the spatial and temporal scales for data subsetting are different at each location. In identifying , we are able to analyse the maximum volume of data while minimising the contamination of the results through the inclusion of independent data. We have demonstrated that the value of is influenced by local factors, such as mountainous orography near the surface-based observatories, and non-local factors such as the satellite sampling strategy (Schutgens et al., 2017). The non-trivial shape of the surfaces computed for each Cloudnet observatory show that optimising the parametrisation requires a full exploration of the parametrisation space, and that optimising each individual parameter independently will not adequately identify the true maximum in the estimated mutual information. Moreover, we have shown that a one-size-fits-all approach to selecting the co-location parametrisation is unsuitable. Using at the other Cloudnet observatories would reduce the number of permitted co-location events, reducing the data volume available for the subsequent analyses. Instead, if we chose for all Cloudnet observatories, the co-location at Ny-Ålesund would be degraded by the inclusion of independent samples, but the co-location at Jülich would conversely be degraded by a reduction in the available co-location events.
3.6.3 Dependency between ATL09 and Cloudnet VCFs for different co-location parametrisations
To demonstrate the importance of the choice of co-location parametrisation p on the validation of satellite data, we compute confusion matrices and copulae between all pairs of VCF values in the ATL09-Cloudnet VCF profile pairs for the parametrisations given in Table 2. Two canonical choices of co-location parametrisation exist. Firstly, one could choose to only accept co-locations that minimise the spatiotemporal displacement between the data sources, at the expense of reducing the available data volume for subsequent analysis. This is represented by p00 = (50 km, 30 min). The second canonical choice is to use all of the available data, in the hopes of having enough good data comparisons that the inclusion of independent data is not impactful. This is represented by p11 = (500 km, 2 d).
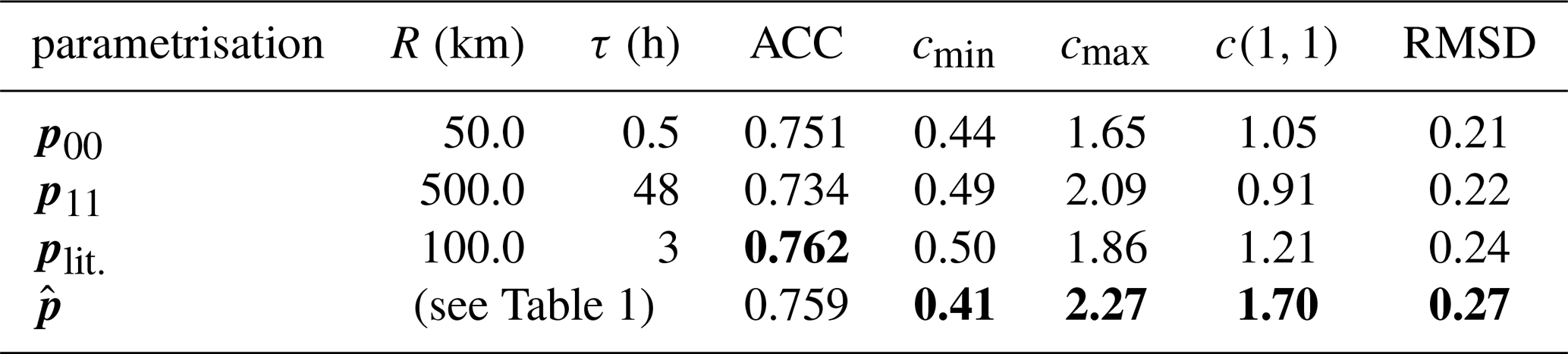
Table 2Results from the computation of copulae comparing VCF values between ATL09 and Cloudnet data for all the tested parametrisations. The accuracy of the agreement between the VCF retrievals for the categories nc, pc and tc (see Fig. 7) is given as ACC. cmin is the minimum copula density for the given parametrisation, cmax is the maximum achieved copula density, and c(1,1) is the discretised tail dependence of the copula. RMSD is the root mean squared difference of the copula density from the independence copula density. Values in bold indicate the best parametrisation for the given metric (the notion of best being defined in the text).
Many previous bodies of work use the same co-location scheme as outlined in Sect. 3.3. Many of these studies use values of R that are low integer multiples of 50 km, and similarly values of τ that are low integer multiples of 30 min (e.g. Robinson et al., 2025; Lin et al., 2022; Protat et al., 2009, 2014a; Schuster et al., 2012; Baars et al., 2023; Wang et al., 2024; Pappalardo et al., 2010; Mona et al., 2009; Proestakis et al., 2019; Papagiannopoulos et al., 2016; Liu et al., 2017; Lu et al., 2021; Pauly et al., 2019; Mamouri et al., 2009). As such, we use plit. = (100 km, 3 h) to represent a typical choice of co-location parametrisation from the literature.
The parametrisation represents the collection of all the co-location events across the four Cloudnet observatories, using each site-specific optimised co-location parametrisation (see Table 1).
Confusion matrices for the retrieval of no cloud (nc), partial cloud (pc) and total cloud (tc) VCF values between the ATL09 and Cloudnet data are given in Fig. 7a–d. In all tested parametrisations, the cells corresponding to (nc, nc) and (pc, pc) are the two most probable states. The accuracy, being the sum of the confusion matrix diagonal elements where both retrievals agree, is given as ACC in Table 2. Across the tested parametrisations, the accuracy ranges between 0.73 and 0.76, with plit. having the highest accuracy of 0.762. The contaminated-data regime given by p11 has the lowest proportion of data falling in the (tc, tc) classification, and the highest proportion of data falling into the (pc, pc) classification. This is a result of the large integration scales for the larger R and τ values, decreasing the probability that all or none of the vertical profiles contain any cloud at a given height. plit. and produce similar confusion matrices, although , typically having larger R and τ values than plit., has less degeneracy in the VCF values and as a result has a higher proportion of (pc, pc) samples than plit..
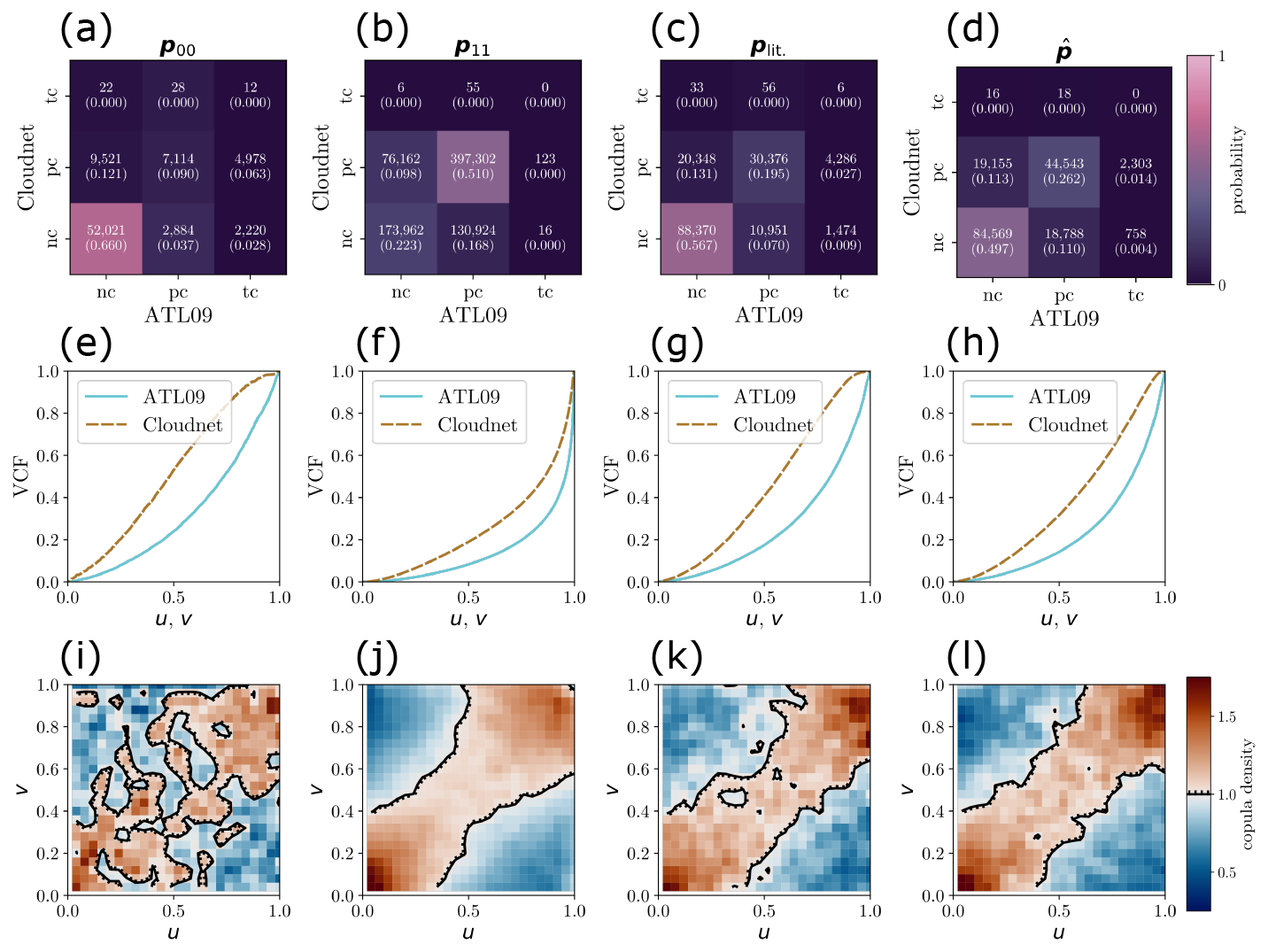
Figure 7Confusion matrices for the detection of no cloud (nc), partial cloud (pc) and total cloud (tc) across all VCF values at all sites for the co-locations representing: a data limited co-location, p00 (a); an independent data contaminated co-location, p11 (b); a co-location typical of those in the literature, plit. (c) and; the per-site optimised co-location, (d). The values of the co-locatio parametrisation vectors are given in Table 2. (e–h) Cumulative distribution functions for ATL09 and Cloudnet VCF values across all sites for associated co-location parametrisations, conditional that the VCF values are strictly between 0 and 1 to remove degeneracies in the copula densities. (i–l) Copula density plots for the associated co-location parametrisations. The contour indicates copula densities of 1, with higher densities indicating regions in (u,v) space that are sampled more frequently than if the variables U and V are independent.
Figure 7e–h show the cumulative distribution functions transforming VCF values to their uniformly distributed copula coordinates. These are defined only for the data falling in the (pc, pc) classification so as to avoid degeneracies at 0 and 1. The shapes of the curves indicate that in all cases, the density of ATL09 VCF samples decreases as a function of the ATL09 VCF value, concentrating the majority of samples at lower values. For p00 and plit., the Cloudnet distribution functions are slightly inflected, as a result of having more VCF samples close in value to 1 than the parametrisations p11 and . This is likely due to the smaller τ values for p00 and plit. making the Cloudnet VCF values behave more like a binary variable than at larger τ values.
Figure 7i–l show the copula densities for the tested parametrisations. p00, being data-limited, produces a noisy copula density surface indicating that the relationship between the ATL09 and Cloudnet VCF distributions is not close to being one-to-one. The other parametrisations all have comparably smooth surfaces, with a well defined ridge of higher densities around the line u = v. This shows that for p11, plit. and , ATL09 and Cloudnet VCF values typically trend together – albeit in a non-linear fashion due to the non-equal cumulative distribution functions shown in Fig. 7e–h.
The copula density associated with p11 is the smoothest, due to being generated from the highest number of contributing samples. Despite this, the upper-right corner shows that c(1,1) = 0.91. The value of c(1,1) being less than 1 indicates that the two retrievals of VCF values disagree on when the most extreme VCF values occur, sampling this case less frequently than if the Cloudnet and ATL09 retrievals were independent. This only happens for p11. This is an undesirable characteristic in the comparison of the retrievals, and hints at the contamination of the comparison by VCF profiles that are independent due to the large spatio-temporal domain within which the co-locations happen. Considering the value of c(1,1) for different p, produces the copula with the highest density in the upper-right tail.
We can also show that the copula density associated with yields the smallest minimum copula density value, cmin = 0.41, and the highest maximum copula density value, cmax = 2.27, across the tested parametrisations. The RMSD values indicate that the plit. and co-location parametrisations are better than utilising all available data, or limiting the co-locations in order to naively reduce the rate of co-location mismatch. We see that yields the copula with the highest RMSD value of the tested parametrisations, with RMSD = 0.27. This indicates that the dependency structure of the relationship between the VCF distributions from Cloudnet and ATL09 data is stronger with than with plit., and the other tested parametrisations.
3.7 Vertical bias profiles
Figure 8a–d shows the bias distributions between the ATL09 and Cloudnet VCF profiles as a function of height. One common feature across all parametrisations is that the expected bias is negative for heights < 8 km, and is positive for higher altitudes (z > 10 km). This indicates that the ATLAS lidar is observing more cloud presence than Cloudnet at higher altitudes (and visa-versa at lower altitudes). This could be explained by the viewing geometries (i.e. ICESat-2 viewing clouds from above and Cloudnet viewing clouds from below) and the effects of signal attenuation on the retrievals, and is consistent with comparisons of other vertically resolved satellite retrievals of cloud presence against surface observations (e.g. McErlich et al., 2021).
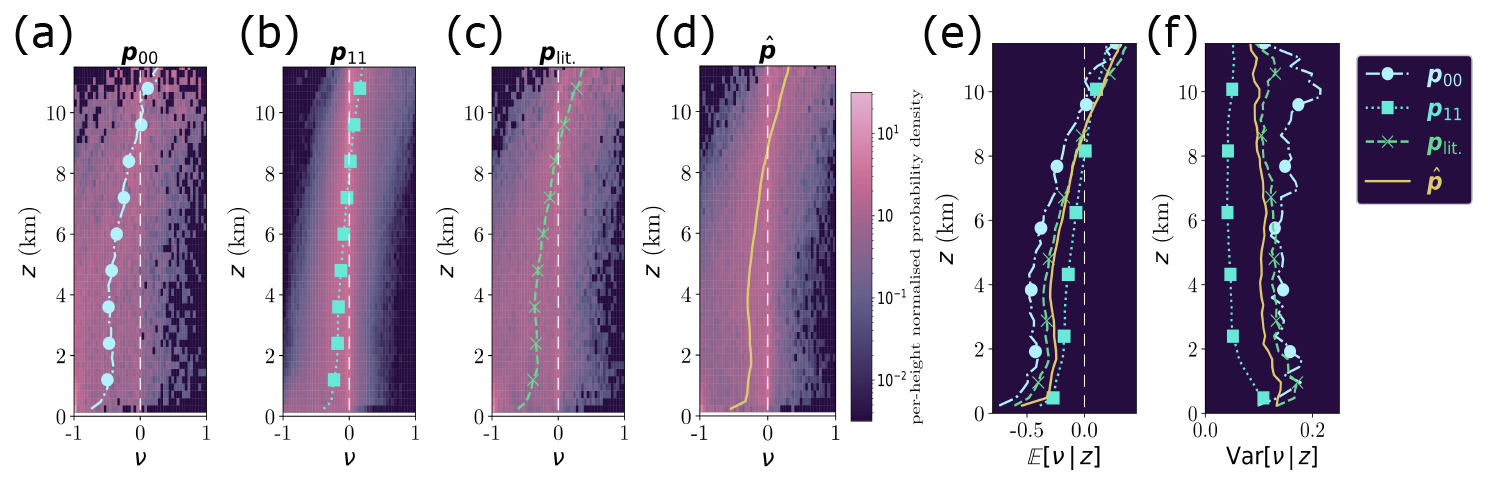
Figure 8Bias distributions between ATL09 and Cloudnet VCF profiles as a function of height for the parametrisations p00 (a), p11 (b), plit. (c) and (d). Expected bias profiles are given as coloured dashed lines. (e) The expected bias profiles for the different parametrisations plotted together, using the same line styles and markers as in their individual panels. (f) The variance in the bias distributions as a function of height.
Figure 8e shows the expected bias profiles for the shown parametrisations as a function of height. In all cases, the bias is negative for z < 8 km indicating that ICESat-2 is less sensitive to clouds at these altitudes than Cloudnet is. Similarly in all cases, for z > 10 km, the biases are positive showing that ATL09 is reporting more cloud at higher altitudes than Cloudnet is. This is consistent with results from other comparisons of vertically resolved satellite retrievals of cloud presence against surface based observations (McErlich et al., 2021). Although the expected profiles are all qualitatively similar, the height at which the bias changes sign is different between the parametrisations. p11 has the lowest change from negative to positive bias at a height of 7.9 km. Above this, both plit. and have bias transition heights around 8.5 km (their transitions occur within one histogram height bin of each other). p00 has the highest bias transition height of 9.4 km.
Figure 8f shows the variance of the bias distributions for the different parametrisations as a function of height. has a consistently lower variance across all heights when compared to p00 and plit.. p11 around z = 0 has a similar variance to the other parametrisations, but above this height, the variance reduces to a nearly constant value around 0.2 for heights above 2 km.
Simply from observing the expected bias profiles and the variance profiles, one may deduce that the selection of p11 gives the best comparison between the data, as the magnitude of the expected bias and variance are the lowest across all parametrisations. However, in using the expected bias and the variance to determine the choice of p, we have necessarily biased our results to be closer to ideal values. As was shown in Sect. 3.6.3, choosing p11 over other parametrisations includes more comparisons of independent data in the analysis when compared to the choice of . If we were to use p11, corrective factors for the bias could be too small in magnitude, and the uncertainty budget of the VCF profiles might be underestimated. Thus, we conclude that the metrics computed between the data to be compared should not be used to assess the quality of the co-location, and that the parametrisation should instead be evaluated by maximising the mutual information between the data to be compared.
By incorrectly choosing p, we subscribe to two possible outcomes: a degradation in the quality of the results of our comparisons between the data, obtaining quantitatively different results due to the difference in the input data, or; quantitatively similar results to those found when using , that may arise as a result of competing erroneous effects due to the inclusion of independent data, or the rejection of dependent data.
This paper presents a unified framework for determining an optimised parametrisation that should be used when spatiotemporally co-locating geospatial data, before comparative analyses or data synthesis can be performed. We utilise mutual information as a domain- and data-agnostic metric quantifying the quality of a data co-location, independent of the metrics typically used in subsequent analyses. Selecting the co-location parametrisation by optimising the comparison metrics of the analysis risks biasing the validation results to the highest attainable values given the data. As such, the comparison metric cannot be used to assess the quality of the co-location of the data used to compute the comparison metric. By definition, we do not know the value of the comparison metric, and by parametrising data co-location to maximise or optimise the comparison metric, we can be thought of as applying a prior distribution to the validation metric of what value we would like the result to have. Our framework allows you to assess your data independently from the co-location, reducing the effects of sample bias induced by a bad co-location.
We have demonstrated for a novel data comparison how the framework can be utilised, defining a co-location scheme to apply to ICESat-2 ATL09 derived VCFs and Cloudnet derived VCFs. Using a grid search, we were able to identify optimised co-location parametrisations per Cloudnet observatory, and with a basic comparison between the VCF values, show that this parametrisation produces better comparisons of the data than a typically used parametrisation, as well as naive choices that maximise or minimise the used data volume. Still, there are some important parts of this framework that need addressing.
4.1 The choice of mutual information estimator
In this study, we utilised the adaptation of the KSG estimator (Kraskov et al., 2004) proposed by Holmes and Nemenman (2019). We chose this implementation of a mutual information estimator as it allows for the mutual information to be computed between distributions of arbitrary dimension, and the development of variance estimation for the mutual information estimator allows us to determine regions in parameter space within which may lie, as opposed to identifying a single value for .
By accepting data of arbitrary dimension, the KSG estimator is widely applicable within the Earth sciences community. Care is needed to properly implement and interpret the outputs of the estimator, but this is the case for all mutual information estimators.
We believe the KSG estimator is at present a suitable choice of estimator for many problems, but other estimators may be developed, or be shown to be more robust for certain data. In these cases, it is up to the researcher's judgement to decide which estimator is most appropriate for their analysis.
4.2 Physical interpretation of
Ascribing physical meaning to the values of the parameters in may be tempting, as they define a spatio-temporal region where data falling within the region maximises the mutual information between the Cloudnet and ATL09 VCF retrievals. The values of and will be intimately linked to the spatial and temporal scales of cloud evolution at each given Cloudnet site. However, due to the high degree of non-linearity in the mutual information estimation, relating and to well-defined concepts such as autocorrelation scales is theoretically challenging. This work does not concern itself with elucidating the physical meaning of the values associated with , but further work could allow empirical relationships between the components of and other well-defined quantities to be identified, opening up new methods for the evaluation of these different quantities.
As was shown in Sect. 3.6.2, the extent of the regions from which optimised co-location parametrisations can be selected is site dependent, and depends on local factors such as orography, as well as factors relating to the sampling strategy at each site. As well as inferring physical meaning from the parameters in , work could be done to model how the plausible region of optimised co-location parametrisations depends on the local environment, which would allow for planning of sampling strategies in advance of satellite missions to capitalise on maximising mutual information at different locations where reference data is recorded.
4.3 Choice of co-location scheme
We demonstrated the use of a simple co-location scheme, only considering (spatially) the separation between the ATL09 data and the Cloudnet observatory. Even with this simplified treatment of the spatial distribution of clouds, we were able to show an improvement of the comparison metrics calculated between the ATL09 and Cloudnet data, simply by choosing to use the co-location parametrisation over other co-location parametrisations.
However, being simplified, the co-location scheme described in Sect. 3.3 still allows comparisons between independent VCF profiles. The scheme could be augmented with additional co-location criteria and parameters, in order to encode more a priori knowledge that constrains the data comparisons being permitted. As an example, Lu et al. (2021) compare CALIPSO cloud layer boundaries against those identified by a ceilometer at the Eastern North Atlantic (ENA) ARM observatory, located on the Azores. As well as subsetting data according to the co-location scheme described in Sect. 3.3, using p = (150 km, 1 h), co-location events are further subset based on the prevailing wind direction at the time of closest approach, in order to reduce the contamination of the analysis by comparing orographically disturbed cloud layers. The approach introduces two angular windows, one used if CALIPSO passes to the east of the ENA observatory, and one used if CALIPSO passes to the west. Each angular window is defined by two extreme angles, within which if the wind is blowing from within the angles subtended by the window, the co-location event is excluded from the analysis. In Lu et al. (2021), the angles are chosen as cardinal directions, and the windows as a result subtend 90° each. In this framework, the angles defining the edges of these windows could each become a free parameter, resulting in the 6-dimensional parameter space given by p = . The more complicated parametrisation space and co-location criteria may allow for higher mutual information between the datasets to be achieved if there was a systematic shortcoming with the simpler co-location scheme that allows independent samples to be permitted in the analysis regardless of the choice of parametrisation.
In our demonstration, the 2-dimensional parameter space was explored by a grid search method to compute mutual information values across a range of parametrisations. Higher dimensional parameter spaces come at the cost of increasing computational overhead, and grid search methods scale exponentially with the number of dimensions. Thus, identifying optimised parametrisations in higher dimensional parameter spaces may require the use of methods such as stochastic gradient descent (in this case, minimising negative mutual information) to efficiently explore the possible parametrisations and identify suitable choices of .
4.4 Applicability of the framework
This framework is widely applicable to problems where the use of multiple data products on non-homogenised coordinates is required. In this study, the framework is demonstrated on the use of a comparison of cloud presence data products. Mutual information can (with the Holmes estimator) be computed between data of arbitrary dimension. Thus, validations of scalar quantity retrievals (e.g. aerosol optical depth) and vector quantity retrievals (e.g. VCFs) are both possible.
Vector quantity retrievals are equivalent to the joint retrieval of two geophysical fields between distinct data sources. For example, the joint retrieval of temperature and pressure could be considered a vector quantity and can thus be compared between data sources.
By adapting the co-location scheme, data can be matched between (for example) two different satellite platforms (see Fig. 1c). This is important for facilitating analyses that characterise the differences between the retrievals of the same quantities by different satellites, better characterising uncertainties induced in long-term records of geophysical quantities.
The focus of the study need not be comparisons of satellite retrievals. The data could compare data from other mobile platforms, such as planes and ships. Outputs from generalised circulation models could be compared against surface-based or satellite observations, with the co-location schemes matching data from the model grid to the real data.
The framework of maximising mutual information would be useful in the synthesis of multi-sensor retrievals over large spatial extents. With given time and length scales over which mutual information between data is high, data from multiple sources could be optimally combined to increase spatial or temporal coverage of satellite data, or to better characterise the uncertainties of satellite data via comparison with sufficiently nearby surface-based observations.
The co-location of data can also be extended to include more than two sources of data. Triple co-location (e.g. McColl et al., 2014) is a method that already utilises three unique data sources to characterise the uncertainty and bias of retrievals with respect to the unknown true value. As long as a co-location scheme and homogenisation process can be defined that incorporates criteria combining more than two data sources, the framework can be utilised to identify the optimised choice of parametrisation for maximising the mutual information contained between the used data.
Maximising the mutual information between data is also essential for producing high quality labelled pairs of samples that can be used as the supervised training data for deep learning models. In order to produce accurate mappings from one data product to another, a deep machine learning approach not only requires high quality data, but a sufficient volume of samples to be trained on in order to learn the mapping. Generating paired data by maximising the mutual information produces data of high quality with limited contamination from independent data, whilst also ensuring that enough data is present for the structure in the joint distribution to be identified. The joint distribution structure is the probabilistic mapping from one data source to the other that is to be learned.
To summarise this work, we have proposed a data- and domain-agnostic framework that allows for the parameters determining the co-location of arbitrary data to be objectively optimised using the mutual information between the co-located data as an independent metric to assess the quality of the co-location. This is in opposition to using the validation or comparison metrics of subsequent analyses on the co-located data to assess the quality of the co-location, as is often done.
Correctly identifying the co-location parametrisation is crucial, as it determines the data available for all subsequent analysis and comparisons between the data. Parametrisations are multi-dimensional, and the effects of changing the parametrisation along individual dimensions are often non-separable. Thus sub-optimally selecting individual components of the parametrisation will degrade the subsequent analyses: either through the comparison of independent data or; by reducing the number of permitted dependent samples. Random or naive choices of the co-location parametrisation will almost certainly be sub-optimal, and the estimated mutual information surfaces are non-trivially dependent on the choice of parametrisation. We have shown that a one-size-fits-all approach to choosing the co-location parametrisation will likely be inappropriate when comparing data from different locations due to myriad local effects impacting the spatiotemporal variability of the geophysical fields being measured, and that using the optimised co-location parametrisations we define yields better relationships between data to be compared than naive choices of co-location parametrisations.
We demonstrate the application of this framework by comparing ICESat-2 ATL09 vertically resolved cloud retrievals against Cloudnet retrievals from four observatories. We computed mutual information surfaces as a function of the co-location parametrisation p, and were able to identify site-specific optimised parametrisations at each observatory. A basic comparison of ATL09 and Cloudnet VCF profiles for different parametrisations showed that, using our definition of optimised data co-location, comparisons between the data were improved over naive choices of co-location parametrisations, as well as a parametrisation typical of those used in the literature.
All that the framework requires in order to be implemented is: a co-location scheme with well defined criteria implementing the scheme, described by variable parametrisations p; a mutual information estimator that is appropriate for the data being compared and; a method for sampling different choices of p in a way that the parametrisation that maximises the mutual information, , will be identified (grid-search or an implementation of gradient ascent). The framework is adaptable and widely applicable, with applications in satellite validations, satellite inter-comparisons, model validation, multi-sensor data synthesis and the production of labelled training data for deep learning methods.
One of the concepts underpinning the framework described in Sect. 2 is that the relationship between two retrievals depends on the spatial and temporal displacement between where the retrievals are made, and that a region within which an optimum comparison can be made exists. Geophysical fields are spatially inhomogeneous, so we can assume that the joint probability distribution relating two retrievals of geophysical fields is also spatially inhomogeneous.
Let us assume that for all displacements between the retrievals of two variables X and Y, r, that the joint probability distribution relating X and Y can be described as . This distribution will have some mutual information associated with it.
We will use the notation I(X;Y) to refer to the mutual information encoded between X and Y, and I[ p(X,Y) ] to refer to the mutual information encoded by the probability distribution p(X,Y). Thus, assuming that the joint probability is fixed, we can write
If we co-locate X and Y by sampling with a density λ(r) across a domain 𝒮, the joint probability distribution relating X and Y will be
which represents a sample density weighted volume average of the probability distributions associated with all locations within the co-location domain 𝒮.
Letting the integral of λ(r) over 𝒮 be , the mutual information associated with the co-location within the domain 𝒮 can be expressed as
Mutual information can be expressed as the Kullback–Leibler (KL) divergence between a joint probability distribution and the product of its marginal distributions. It can also be shown that the KL divergence is convex in pairs of both of its arguments (e.g. Soch et al., 2025, proof 148). By extension, mutual information is convex in its arguments. This can be expressed through Jensen's inequality (Jensen, 1906):
where κ is a constant between 0 and 1 describing a mixture between probability distributions p and q. The mutual information for the linear combination of probability distributions is less than or equal to the same linear combination of the mutual informations of the individual distributions. The inequality can be extended to a normalised weighted sum of multiple distributions. Thus, using Eq. (A4), we can express an inequality for I as
Thus, if the mutual information between X and Y can be described by a function i(r) for samples recorded with a given displacement r, the total mutual information when co-locating data within a domain 𝒮 is bounded by the volume- and sample-density- weighted sum of all contributions.
For geophysical fields, we expect that their spatiotemporal autocorrelation (and by some extension, the mutual information) to be a decreasing function of the spatiotemporal displacements being considered. Thus, we can model i(r) as a decreasing function of . As such, it can be shown that the upper bound on the mutual information when considering all samples taken within a n-spherical domain 𝒮(R) of radius R around a fixed location is also a decreasing function of R. As stated in Sect. 2.4, this is the effect of data contamination by independent samples acting to decrease the mutual information encoded between the measurements X and Y. The above analysis assumes that the computation of the mutual information is perfectly informed and not in fact data limited. As such, this is still consistent with our expectation that the maximum mutual information that will be evaluated for data co-located within a finite number of co-location events will not be found for R = 0, as the mutual information estimation will be data limited and thus the increase in R will initially drive the value of upwards towards the limiting value, until sufficient samples are available and the effects of contamination take over.
A1 A radially isotropic two-population example
Imagine a plane, with an observatory located at the origin, measuring variable X with marginal distribution p(X). There is also a mobile platform making point-like measurements of variable Y, with marginal distribution p(Y). The measurements of variable Y are made at distances r from the origin, such that the sampling density is spatially uniform. This is represented as λ(r) = 1 uniformly, and as such λ will be ignored in the following derivation.
Y is a spatially inhomogeneous variable, but isotropic (with respect to the origin), such that X and Y are related by a spatially varying joint probability distribution. For r < R*, X and Y are dependent and have
being related by the non-zero mutual information I*. Considering samples radially further away than R*, X and Y are independent, such that
The data co-location scheme for matching samples between X and Y is to consider all matches for which r < R. That is, the domain 𝒮 is a disk of radius R centred on the origin. As such, the joint probability distribution relating X and Y as a function of R is
We can rewrite Eq. (A13) in terms of a mixing fraction κ,
Considering the convexity of the mutual information of mixture distributions, we can derive the bound on :
Thus, for sufficiently large R > R*, we necessarily expect a reduction in the mutual information between the co-located X and Y as the probability distribution becomes a mixture distribution, being contaminated with independent samples. Although this toy model is very simplified, it demonstrates explicitly how the inclusion of independent data reduces the upper bound on the mutual information encoded between X and Y, and thought experiments can easily develop the model by including additional radial intervals within which the encoded mutual information within the interval is constant but between I* and 0.
To demonstrate the mutual information bounds, we implemented the previously described sampling and co-location scheme. X and Y are two Gaussian distributed variables with unit variance. For r < R*, X and Y have a bivariate Gaussian joint probability distribution, with correlation ρ = , chosen such that I* = 1 nat. For r > R*, samples of X and Y are independently drawn from univariate Gaussian distributions to ensure an independent joint probability distribution between X and Y.
Figure A1 shows the estimated as a function of , where N is the number of samples of X and Y available to the KSG estimator. As → 0, the estimate → I should approach the real mutual information value. Figure A1 shows that for N > 104, the mutual information estimates for both the dependent and independent data have converged to the correct values of 1 and 0 nats respectively.
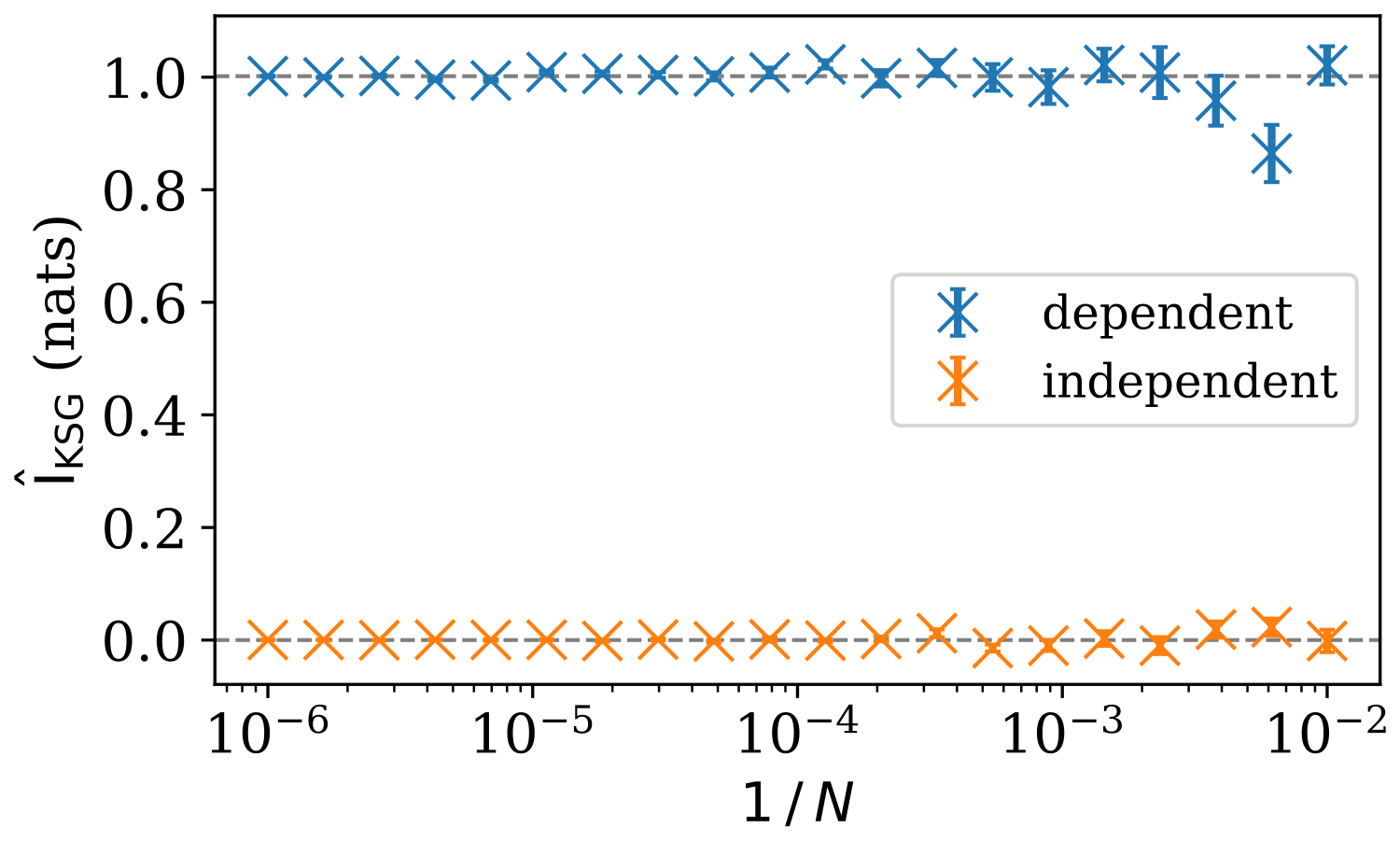
Figure A1Mutual information estimates between two Gaussian distributed variables as a function of the number of samples provided to the KSG estimator.
Figure A2 demonstrates a mixture distribution between the dependent and independent Gaussian joint distributions, as outlined in Eqs. (A14)–(A16). X and Y consist of N = 105 joint samples, with κN samples being drawn from the dependent joint probability distribution, and (1−κ)N samples being drawn independently. At the extremes where κ = 0 or 1, we recover the results seen in Fig. A1, that the mutual information estimates agree with the actual mutual information values. However, for 0 < κ < 1, the mutual information estimate is consistently lower than the theoretical upper bound provided by Eq. (A20).
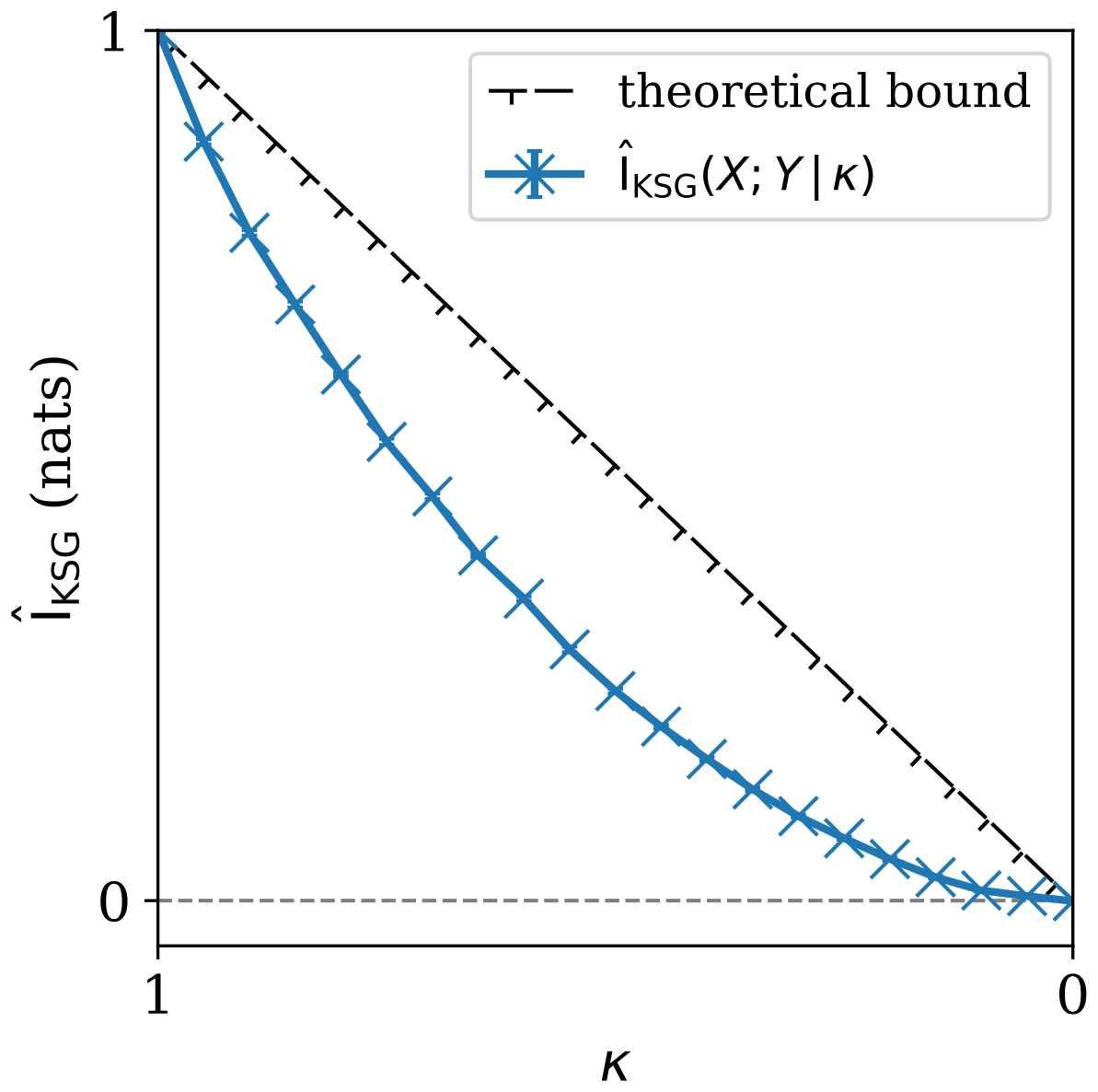
Figure A2The mutual information between two variables X and Y, which are sampled from a mixture distribution between a dependent and independent Gaussian distribution, as a function of mixing ratio κ. The theoretical upper bound given in Eq. (A20) is also plotted.
Figure A3 extends the implementation used to create Fig. A2, by extending the definition of N to depends on R, such that N = πR2λ. It also uses the full definition for κ(R) given in Eq. (A15). The estimated profiles of are plotted for multiple sampling densities, λ, defined by values N* such that
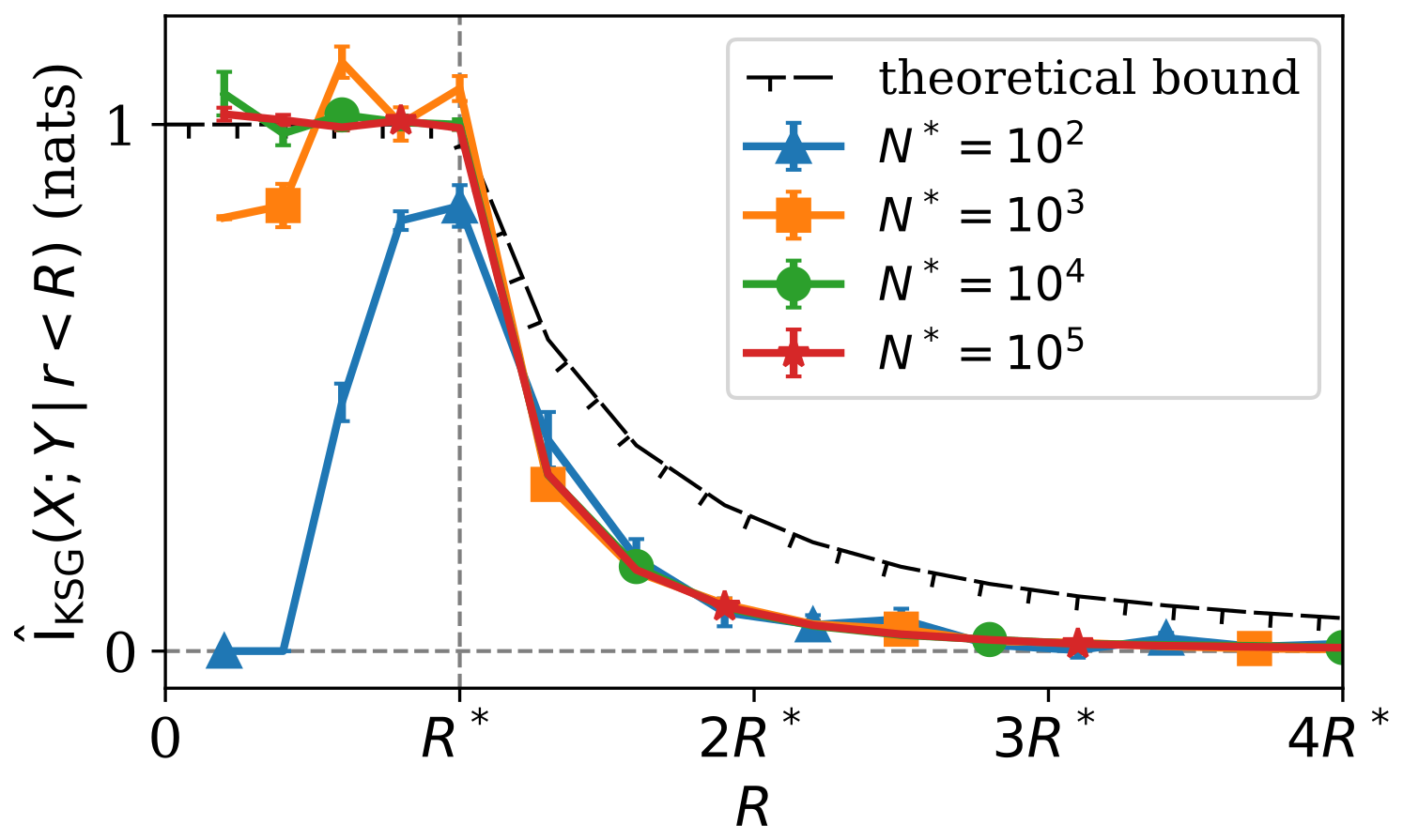
Figure A3Mutual information estimates plotted as functions of R for different sampling densities λ, associated with different values N*. The theoretical upper bound of the true mutual information between X and Y is also plotted, according to Eq. (A21).
The mutual information profiles all follow a generic pattern. For r < R*, increasing r results in an increase in the number of dependent samples N available for the KSG estimator to infer the relationship between X and Y. This results in rising from 0 nats when r = 0 towards a value of I*. For r > R*, the only additional samples provided to the KSG estimator are entirely independent, driving the estimates towards 0 nats. This is consistent with our expectations (see Sect. 2.4).
We also see, as in Fig. A2, that the mutual information estimates are almost always lower than the theoretical upper bound. The estimates for r < R* with N* = 102 and N* = 103 do vary above I* by more than 1σKSG, but this can likely be attributed to the variance of the estimator with a low number of samples.
B1 ATL09
The ICESat-2 ATL09 data (Palm et al., 2023) are downloaded through the NASA Harmony API (https://harmony.earthdata.nasa.gov/, last access: 22 May 2026), and are subset spatially based on circular polygons of radius 510 km centred on each Cloudnet observatory. Code to facilitate the downloads through the NASA Harmony API is given in Martin (2025a).
Each individual ATL09 file can be associated with a unique co-location event. A given ATL09 file is opened and the high_rate group is loaded for each profile (one per ATLAS strong beam). The high_rate groups are each described by a temporal coordinate, with height and layer index coordinates associated with specific variables within the group.
For each temporal coordinate within a group, we create an empty boolean vector with the size of the vertical dimension. Elements of the vector are populated with true for elements corresponding to heights at which the ATL09 product reports cloud, as given in the layer_bot and layer_top variables. This forms a vertical cloud presence profile. The inclusion of a layer is rejected if the corresponding layer_attr value is not 1 (cloud). If a layer within the vertical profile has an associated value layer_conf_dens < 0.4, then the entire vertical profile is rejected from the analysis.
All of the successfully generated vertical cloud presence profiles are concatenated. The profiles' latitude and longitude profiles are then used to compute the separation between the ATLAS footprint and the Cloudnet observatory, r. The co-location criteria outlined in Sect. 3.3 is applied.
If fewer than 17 vertical cloud presence profiles remain after the co-location subsetting (17 × 240 m = 4.08 km along-track distance), the co-location event is rejected for containing insufficient valid data. Otherwise, the VCF profile for the co-location event is computed as the average vertical cloud presence profile at each height, considering all of the profiles permitted after the quality checks and co-location subsetting.
B2 Cloudnet
The Cloudnet categorize data product is downloaded from the Cloudnet FMI website (https://cloudnet.fmi.fi, last access: 22 May 2026), subset temporally between 1 October 2018 and 1 January 2025 to match the availability of ICESat-2 data (Ebell et al., 2025). Because the Cloudnet data is near-continuous compared to the ATL09 data at a given Cloudnet observatory, the ATL09 data is first processed to identify viable co-location events.
For a given successfully co-located ATL09 file, the time of closest approach is identified as the time t0 for which the computed separation between the ATLAS footprints and the Cloudnet observatory, r, is minimised:
where the subscript j indexes the ATL09 vertical profiles loaded when co-locating the ATL09 data.
The interval
is defined, and all Cloudnet files with data falling within the temporal interval 𝒯 are loaded and concatenated. The loaded data is then subset based on the interval 𝒯. Co-location and quality subsetting can be considered as set intersection operations, which are commutative, so the data can be temporally subset prior to other operations being performed. This saves computational effort.
The category_bits variable is unpacked, and the cloudmask from the Cloudnet data is identified (according to the code from Tukiainen et al., 2020, defined in cloudnetpy.products.classification._find_cloud_mask) as
where droplet, falling and freezing are three of the unpacked boolean fields. The cloud variable is thus a boolean field with the time and height dimensions associated with the Cloudnet dataset. VCF profiles are computed as the temporal average of the cloud field across all profiles permitted by the temporal co-location.
In this appendix, we will derive a formula to determine the across-track density of satellite orbits, with the following approximations:
-
The Earth is a sphere.
-
Subsequent orbits of the same satellite on the tangent plane at a given location on the Earth's surface are parallel.
-
Orbits form great circle paths over the surface of the Earth.
These approximations are incorrect, but in most circumstances will lead to reasonable results. Firstly, the Earth is in fact not a sphere, but instead is better approximated as an oblate spheroid. However, the semi-major and semi-minor axes for the Earth differ by less than 0.4 %, making the spherical assumption reasonable for back-of-the-envelope calculations.
Secondly, assuming subsequent orbits of a satellite on the tangent plane are parallel is a broken assumption. All of the orbits at a given latitude will have the same inclination relative to the vector locally pointing north. On the tangent plane, it is assumed that the direction pointing north is equal throughout the plane, however it will in reality have a longitudinal dependence. Sufficiently far from the poles, this assumption will be accurate to first order for displacements along the tangent plane, distances which increase closer to the equator.
Finally, treating orbits as great circles is approximate, as the Earth rotates under the satellite as it orbits. This acts to make orbital tracks along the ground have a stronger westwards component than they otherwise would, effectively tilting the orbital track relative to a co-rotating great circle of the same inclination. For polar orbiting satellites with orbital inclinations greater than 90°, this acts to make the orbital track locally appear to have a shallower angle relative to the equator compared to the great circle with the same inclination.
We can define three points on the surface of the Earth: let A0 be the ascending node of the orbit, found on the equator; let A1 be the location on the Earth's surface at which we want to compute the local across-track orbital density and; let A2 be the point where the highest latitude is reached. If we let ϕ represent latitude (positive northwards), and λ be longitude, the locations can be expressed as
where ϕ1 and ϕ2 are known constants which satisfy the inequalities ϕ1 ≤ ϕ2 and ϕ2 > 0. Specifically, ϕ2 is equal to the reference angle of the orbital inclination of the satellite (the angle as it would be if limited to being between 0 and ).
We will describe the bearing along which the great circle from point a to point b lies when measured from point a as αab. The angle αab can generally be expressed as
where λab = λb − λa is the difference in longitude between point a and point b.
At A2, the orbit has reached its highest latitude, ϕ2. As such, the bearing of the orbit must necessarily be as the satellite transitions from heading northwards to southwards. Thus, . Knowing that , we know that the denominator in Eq. (C5) must tend towards zero. For the case of α20:
This shows the longitudinal separation between A0 and A2 must be , which is consistent with what we would expect given the symmetries of two great-circles drawn over a sphere, the equator and the orbital track, and the separation between these great-circles having two crossing points and two maxima, all evenly spaced along the great-circles.
The same logic can be applied for α21, deriving an equation for cos λ21:
The cosine function is symmetric in its argument, meaning the Eq. (C12) also provides an expression for cos λ12 = cos λ21 because λ12 = −λ21. Applying Eqs. (C5) and (C12) to finding α12, we get
which is importantly expressed purely as a function of the known latitudes ϕ1 and ϕ2.
In order to convert this bearing into an across-track density of orbits, we need to evaluate the perpendicular separation between adjacent orbital tracks. For a satellite that revisits the same along-ground orbital track every N orbits, the longitudinal displacement between adjacent tracks, δx, is given as
This can be related to the across-track separation between the adjacent orbits, δs, as
The across-track density of orbits, ρorbits is inversely proportional to δs, such that
Thus, the across-track density of orbits can be approximated given the reference angle of the satellite's orbital inclination, ϕ2, and the latitude of the location at which the density is to be calculated, ϕ1. Multiplying Eq. (C22) by a factor of sin ϕ2 normalises ρorbits such that ρorbits = 1 when ϕ1 = 0.
Figure C1 shows the across-track density of orbits calculated for the ISS, EarthCARE, the A-Train constellation of satellites and ICESat-2.
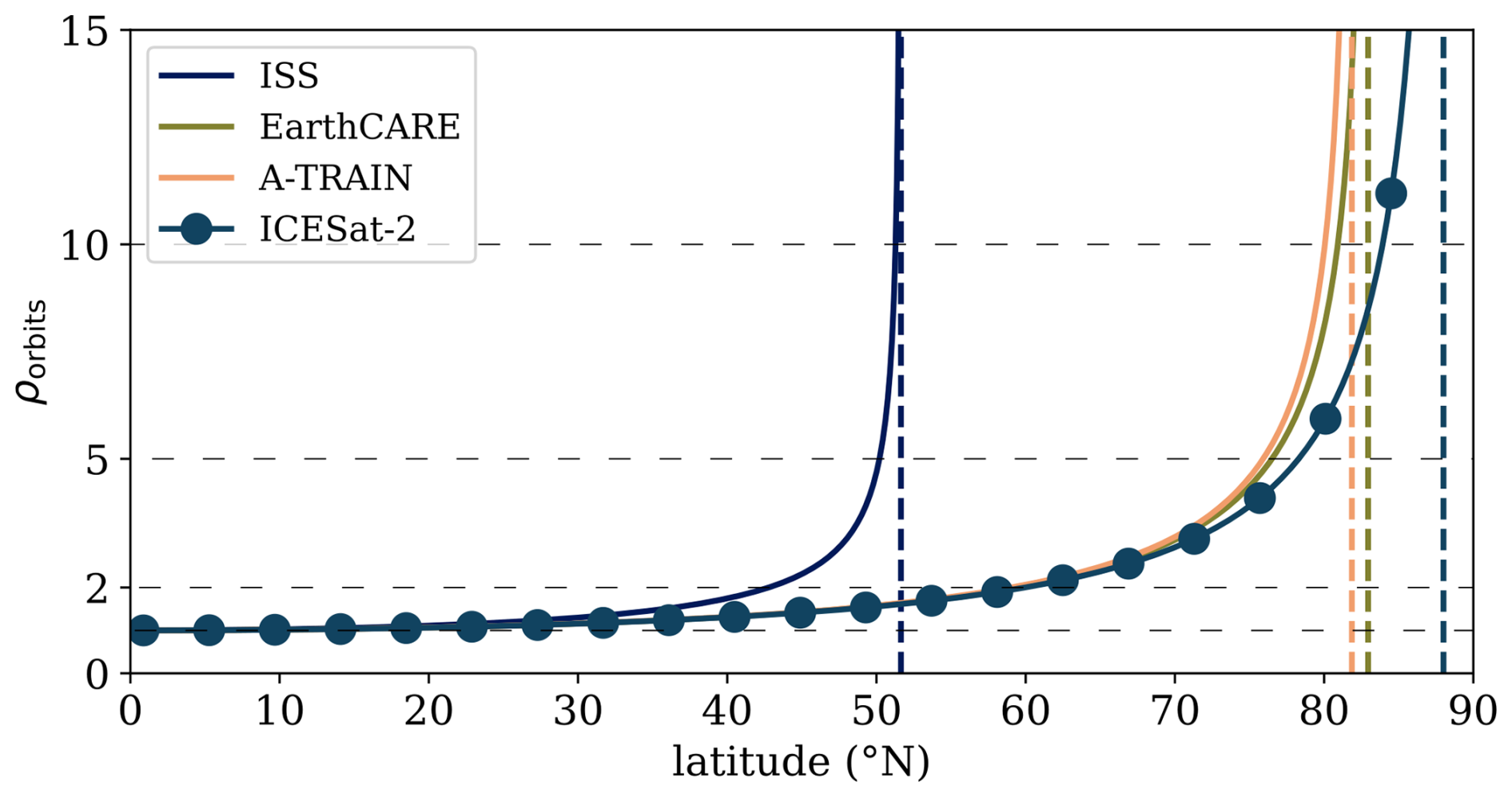
Figure C1Normalised across-track density of orbits, ρorbits, for the ISS, EarthCARE, A-Train satellite constellation, and ICESat-2. Horizontal dashed lines have fixed densities of 1, 2, 5 and 10. Vertical dashed lines correspond to the highest latitudes achieved by each satellite, and represent where Eq. (C22) diverges.
Software implementing the framework and producing results is given by Martin (2025a, https://doi.org/10.5281/zenodo.17830442). The Cloudnet data used in this study are generated by the Aerosol, Clouds and Trace Gases Research Infrastructure (ACTRIS) and are available from the ACTRIS Data Centre using the following link: https://doi.org/10.60656/726097978e364d06. The specific dataset is given in Ebell et al. (2025, https://doi.org/10.60656/726097978e364d06). ICESat-2 ATL09 data are downloaded from the NASA Harmony API (https://harmony.earthdata.nasa.gov/, last access: 22 May 2026) and utilise the ATL09 v6 data (Palm et al., 2023, https://doi.org/10.5067/ATLAS/ATL09.006). Generated results can be accessed directly through Martin (2025b, https://doi.org/10.5281/zenodo.17817304).
ASM conceptualised the study; ASM designed the framework; ASM, HG, MG designed the analysis methodology; ASM wrote the analysis software; ASM performed the analysis; All co-authors analysed and reviewed the results; ASM prepared the manuscript with feedback and contributions from all co-authors; HG, RN provided supervision.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
This work was supported by the Natural Environment Research Council (NERC) Centre for Satellite Data in Environmental Science (SENSE) Centre for Doctoral Training (grant no. NE/T00939X/1). We acknowledge ACTRIS and Finnish Meteorological Institute for providing the Cloudnet data set which is available for download from https://cloudnet.fmi.fi (last access: 22 May 2026). The cloud radar data for Ny-Ålesund was provided by the University of Cologne, the ceilometer and microwave radiometer data by the Alfred Wegener Institute, Helmholtz Centre for Polar and Marine Research. We thank the staff of AWIPEV research base in Ny-Ålesund for technical support of the measurements. We gratefully acknowledge the funding by the Deutsche Forschungsgemeinschaft DFG (German Research Foundation) – project number 268020496 – TRR 172, within the “Transregional Collaborative Research Center 'ArctiC Amplification: Climate Relevant Atmospheric and SurfaCe Processes, and Feedback Mechanisms (AC)3”'. We acknowledge ECMWF for providing IFS model data, DWD for providing ICON model data, and NCEP (National Centers for Environmental Prediction) for providing access to GDAS1 data. The authors would like to thank the many teams contributing to maintaining ICESat-2 for their ongoing efforts in creating the atmospheric data products. This work used JASMIN, the UK's collaborative data analysis environment (https://www.jasmin.ac.uk, last access: 22 May 2026; Lawrence et al., 2013). The Scientific colour maps acton, hawaii, imola, lipari, navia, roma and vik (Crameri, 2023) are used in this study to prevent visual distortion of the data and exclusion of readers with colour-vision deficiencies (Crameri et al., 2020). ASM would like to thank Von P. Walden for contributions to the statistical methodology, and for his shared guidance and wisdom. ASM would like to acknowledge the rest of the ICECAPS team and their support over the past 2 years. ASM would like to thank WO, SH, ISSW and TM for making the long 2 weeks enjoyable, and KC for always being there when the going gets tough. The authors would like to thank the two reviewers of the manuscript and the handling editor, for their in depth reading and understanding of the manuscript, and for their insightful comments and suggestions which have improved the work.
This research has been supported by the Natural Environment Research Council (grant no. NE/T00939X/1).
This paper was edited by Luca Lelli and reviewed by two anonymous referees.
Alexander, S. P. and Protat, A.: Cloud Properties Observed From the Surface and by Satellite at the Northern Edge of the Southern Ocean, J. Geophys. Res.-Atmos., 123, 443–456, https://doi.org/10.1002/2017JD026552, 2018. a, b, c
Baars, H., Walchester, J., Basharova, E., Gebauer, H., Radenz, M., Bühl, J., Barja, B., Wandinger, U., and Seifert, P.: Long-term validation of Aeolus L2B wind products at Punta Arenas, Chile, and Leipzig, Germany, Atmos. Meas. Tech., 16, 3809–3834, https://doi.org/10.5194/amt-16-3809-2023, 2023. a, b, c, d
Beirlant, J., Dudewicz, E., Gyor, L., and Meulen, E.: Nonparametric entropy estimation: An overview, International Journal of Mathematical and Statistical Sciences, 6, 17–39, 1997. a
Blanchard, Y., Pelon, J., Eloranta, E. W., Moran, K. P., Delanoë, J., and Sèze, G.: A Synergistic Analysis of Cloud Cover and Vertical Distribution from A-Train and Ground-Based Sensors over the High Arctic Station Eureka from 2006 to 2010, J. Appl. Meteorol. Clim., 53, 2553–2570, https://doi.org/10.1175/JAMC-D-14-0021.1, 2014. a, b
Compernolle, S., Argyrouli, A., Lutz, R., Sneep, M., Lambert, J.-C., Fjæraa, A. M., Hubert, D., Keppens, A., Loyola, D., O'Connor, E., Romahn, F., Stammes, P., Verhoelst, T., and Wang, P.: Validation of the Sentinel-5 Precursor TROPOMI cloud data with Cloudnet, Aura OMI O2–O2, MODIS, and Suomi-NPP VIIRS, Atmos. Meas. Tech., 14, 2451–2476, https://doi.org/10.5194/amt-14-2451-2021, 2021. a
Cover, T. M. and Thomas, J. A.: Elements of information theory, Wiley-Interscience, Hoboken, N.J, 2nd edn., https://doi.org/10.1002/047174882X, ISBN 978-1-118-58577-1, ISBN 978-0-471-74881-6, ISBN 978-0-471-74882-3, ISBN 978-0-471-24195-9, 2006. a
Crameri, F.: Scientific colour maps, Zenodo [code], https://doi.org/10.5281/zenodo.1243862, 2023. a
Crameri, F., Shephard, G. E., and Heron, P. J.: The misuse of colour in science communication, Nat. Commun., 11, 5444, https://doi.org/10.1038/s41467-020-19160-7, 2020. a
Darbellay, G. and Vajda, I.: Estimation of the information by an adaptive partitioning of the observation space, IEEE T. Inform. Theory, 45, 1315–1321, https://doi.org/10.1109/18.761290, 1999. a
Deneke, H. M., Knap, W. H., and Simmer, C.: Multiresolution analysis of the temporal variance and correlation of transmittance and reflectance of an atmospheric column, J. Geophys. Res.-Atmos., 114, https://doi.org/10.1029/2008JD011680, 2009. a
Ebell, K., Geiß, A., Kneifel, S., Marke, T., Maturilli, M., Moisseev, D., O'Connor, E., Patra, S., Pfitzenmaier, L., Pospichal, B., Ritter, C., Schween, J., and Zinner, T.: Custom collection of categorize data from Hyytiälä, Jülich, Munich, and Ny-Ålesund between 1 Oct 2018 and 1 Jan 2025, ACTRIS Cloud remote sensing data centre unit (CLU) [data set], https://doi.org/10.60656/726097978E364D06, 2025. a, b, c, d
Eibedingil, I. G., Gill, T. E., Van Pelt, R. S., and Tong, D. Q.: Comparison of Aerosol Optical Depth from MODIS Product Collection 6.1 and AERONET in the Western United States, Remote Sensing, 13, 2316, https://doi.org/10.3390/rs13122316, 2021. a, b, c
Fuchs, J., Andersen, H., Cermak, J., Pauli, E., and Roebeling, R.: High-resolution satellite-based cloud detection for the analysis of land surface effects on boundary layer clouds, Atmos. Meas. Tech., 15, 4257–4270, https://doi.org/10.5194/amt-15-4257-2022, 2022. a, b
Herzfeld, U., Hayes, A., Palm, S., Hancock, D., Vaughan, M., and Barbieri, K.: Detection and Height Measurement of Tenuous Clouds and Blowing Snow in ICESat-2 ATLAS Data, Geophys. Res. Lett., 48, e2021GL093473, https://doi.org/10.1029/2021GL093473, 2021. a, b
Holmes, C. M. and Nemenman, I.: Estimation of mutual information for real-valued data with error bars and controlled bias, Phys. Rev. E, 100, 022404, https://doi.org/10.1103/PhysRevE.100.022404, 2019. a, b, c, d, e
Illingworth, A. J., Hogan, R. J., O'Connor, E. J., Bouniol, D., Brooks, M. E., Delanoé, J., Donovan, D. P., Eastment, J. D., Gaussiat, N., Goddard, J. W. F., Haeffelin, M., Baltink, H. K., Krasnov, O. A., Pelon, J., Piriou, J.-M., Protat, A., Russchenberg, H. W. J., Seifert, A., Tompkins, A. M., van Zadelhoff, G.-J., Vinit, F., Willén, U., Wilson, D. R., and Wrench, C. L.: Cloudnet: Continuous Evaluation of Cloud Profiles in Seven Operational Models Using Ground-Based Observations, B. Am. Meteorol. Soc., 88, 883–898, https://doi.org/10.1175/BAMS-88-6-883, 2007. a
Jensen, J. L. W. V.: Sur les fonctions convexes et les inégualités entre les valeurs Moyennes, Acta Math.-Djursholm, 30, 175–193, https://doi.org/10.1007/BF02418571, https://doi.org/10.1007/bf02418571, 1906. a
Kraskov, A., Stögbauer, H., and Grassberger, P.: Estimating mutual information, Phys. Rev. E, 69, 066138, https://doi.org/10.1103/PhysRevE.69.066138, 2004. a, b, c, d
Langsdale, M., Verhoelst, T., Povey, A., Schutgens, N., Dowling, T., Lambert, J.-C., Compernolle, S., and Kern, S.: The Challenges and Limitations of Validating Satellite-Derived Datasets Using Independent Measurements: Lessons Learned from Essential Climate Variables, Surv. Geophys., https://doi.org/10.1007/s10712-025-09898-4, 2025. a
Lawrence, B. N., Bennett, V. L., Churchill, J., Juckes, M., Kershaw, P., Pascoe, S., Pepler, S., Pritchard, M., and Stephens, A.: Storing and manipulating environmental big data with JASMIN, in: 201 IEEE International Conference on Big Data, IEEE, Silicon Valley, CA, USA, 68–75, https://doi.org/10.1109/BigData.2013.6691556, ISBN 978-1-4799-1293-3, 2013. a
Lin, Y., Tian, P., Tang, C., Pang, S., and Zhang, L.: Combining CALIPSO and AERONET Data to Classify Aerosols Globally, IEEE T. Geoscience Remote, 60, 1–12, https://doi.org/10.1109/TGRS.2021.3138085, 2022. a
Liu, Y., Shupe, M. D., Wang, Z., and Mace, G.: Cloud vertical distribution from combined surface and space radar–lidar observations at two Arctic atmospheric observatories, Atmos. Chem. Phys., 17, 5973–5989, https://doi.org/10.5194/acp-17-5973-2017, 2017. a, b, c
Liu, Z., Marchand, R., and Ackerman, T.: A comparison of observations in the tropical western Pacific from ground-based and satellite millimeter-wavelength cloud radars, J. Geophys. Res.-Atmos., 115, https://doi.org/10.1029/2009JD013575, 2010. a
Loew, A., Bell, W., Brocca, L., Bulgin, C. E., Burdanowitz, J., Calbet, X., Donner, R. V., Ghent, D., Gruber, A., Kaminski, T., Kinzel, J., Klepp, C., Lambert, J.-C., Schaepman-Strub, G., Schröder, M., and Verhoelst, T.: Validation practices for satellite-based Earth observation data across communities, Rev. Geophys., 55, 779–817, https://doi.org/10.1002/2017RG000562, 2017. a, b, c, d
Lu, X., Mao, F., Rosenfeld, D., Zhu, Y., Pan, Z., and Gong, W.: Satellite retrieval of cloud base height and geometric thickness of low-level cloud based on CALIPSO, Atmos. Chem. Phys., 21, 11979–12003, https://doi.org/10.5194/acp-21-11979-2021, 2021. a, b, c, d, e, f
Mamouri, R. E., Amiridis, V., Papayannis, A., Giannakaki, E., Tsaknakis, G., and Balis, D. S.: Validation of CALIPSO space-borne-derived attenuated backscatter coefficient profiles using a ground-based lidar in Athens, Greece, Atmos. Meas. Tech., 2, 513–522, https://doi.org/10.5194/amt-2-513-2009, 2009. a, b
Markus, T., Neumann, T., Martino, A., Abdalati, W., Brunt, K., Csatho, B., Farrell, S., Fricker, H., Gardner, A., Harding, D., Jasinski, M., Kwok, R., Magruder, L., Lubin, D., Luthcke, S., Morison, J., Nelson, R., Neuenschwander, A., Palm, S., Popescu, S., Shum, C., Schutz, B. E., Smith, B., Yang, Y., and Zwally, J.: The Ice, Cloud, and land Elevation Satellite-2 (ICESat-2): Science requirements, concept, and implementation, Remote Sens. Environ., 190, 260–273, https://doi.org/10.1016/j.rse.2016.12.029, 2017. a
Martin, A., Weissmann, M., Reitebuch, O., Rennie, M., Geiß, A., and Cress, A.: Validation of Aeolus winds using radiosonde observations and numerical weather prediction model equivalents, Atmos. Meas. Tech., 14, 2167–2183, https://doi.org/10.5194/amt-14-2167-2021, 2021. a
Martin, A. S.: DAndrewA/a-guide-to-optimised-spatiotemporal-data-co-location-by-mutual-information-maximisation: v1.0.1, Version v1.0.1, Zenodo [code], https://doi.org/10.5281/zenodo.17830442, 2025a. a, b
Martin, A. S.: Mutual information maximisation for spatiotemporal co-location: ICESat-2 ATL09 and Cloudnet categorize, Version v1, Zenodo [data set], https://doi.org/10.5281/zenodo.17817304, 2025b. a
McColl, K. A., Vogelzang, J., Konings, A. G., Entekhabi, D., Piles, M., and Stoffelen, A.: Extended triple collocation: Estimating errors and correlation coefficients with respect to an unknown target, Geophys. Res. Lett., 41, 6229–6236, https://doi.org/10.1002/2014GL061322, 2014. a
McErlich, C., McDonald, A., Schuddeboom, A., and Silber, I.: Comparing Satellite- and Ground-Based Observations of Cloud Occurrence Over High Southern Latitudes, J. Geophys. Res.-Atmos., 126, e2020JD033607, https://doi.org/10.1029/2020JD033607, 2021. a, b, c, d
McGarry, J. F., Carabajal, C. C., Saba, J. L., Reese, A. R., Holland, S. T., Palm, S. P., Swinski, J.-P. A., Golder, J. E., and Liiva, P. M.: ICESat-2/ATLAS Onboard Flight Science Receiver Algorithms: Purpose, Process, and Performance, Earth and Space Science, 8, e2020EA001235, https://doi.org/10.1029/2020EA001235, 2021. a
Mona, L., Pappalardo, G., Amodeo, A., D'Amico, G., Madonna, F., Boselli, A., Giunta, A., Russo, F., and Cuomo, V.: One year of CNR-IMAA multi-wavelength Raman lidar measurements in coincidence with CALIPSO overpasses: Level 1 products comparison, Atmos. Chem. Phys., 9, 7213–7228, https://doi.org/10.5194/acp-9-7213-2009, 2009. a, b
Nearing, G. S., Yatheendradas, S., Crow, W. T., Bosch, D. D., Cosh, M. H., Goodrich, D. C., Seyfried, M. S., and Starks, P. J.: Nonparametric triple collocation, Water Resour. Res., 53, 5516–5530, https://doi.org/10.1002/2017WR020359, 2017. a, b
Neumann, T. A., Martino, A. J., Markus, T., Bae, S., Bock, M. R., Brenner, A. C., Brunt, K. M., Cavanaugh, J., Fernandes, S. T., Hancock, D. W., Harbeck, K., Lee, J., Kurtz, N. T., Luers, P. J., Luthcke, S. B., Magruder, L., Pennington, T. A., Ramos-Izquierdo, L., Rebold, T., Skoog, J., and Thomas, T. C.: The Ice, Cloud, and Land Elevation Satellite – 2 mission: A global geolocated photon product derived from the Advanced Topographic Laser Altimeter System, Remote Sens. Environ., 233, 111325, https://doi.org/10.1016/j.rse.2019.111325, 2019. a
Palm, S., Yang, Y., Herzfeld, U., Hancock, D., Barbieri, K., Wimert, J., and the ICESat-2 Science Team: ATLAS/icesat-2 L3A calibrated backscatter profiles and atmospheric layer characteristics, Version 6, NASA National Snow and Ice Data Center Distributed Active Archive Center (NSIDC) [data set], Boulder, Colorado USA, https://doi.org/10.5067/ATLAS/ATL09.006, 2023. a, b, c
Palm, S. P., Yang, Y., Herzfeld, U., Hancock, D., Hayes, A., Selmer, P., Hart, W., and Hlavka, D.: ICESat-2 Atmospheric Channel Description, Data Processing and First Results, Earth and Space Science, 8, e2020EA001470, https://doi.org/10.1029/2020EA001470, 2021. a, b, c
Papagiannopoulos, N., Mona, L., Alados-Arboledas, L., Amiridis, V., Baars, H., Binietoglou, I., Bortoli, D., D'Amico, G., Giunta, A., Guerrero-Rascado, J. L., Schwarz, A., Pereira, S., Spinelli, N., Wandinger, U., Wang, X., and Pappalardo, G.: CALIPSO climatological products: evaluation and suggestions from EARLINET, Atmos. Chem. Phys., 16, 2341–2357, https://doi.org/10.5194/acp-16-2341-2016, 2016. a, b
Pappalardo, G., Wandinger, U., Mona, L., Hiebsch, A., Mattis, I., Amodeo, A., Ansmann, A., Seifert, P., Linné, H., Apituley, A., Alados Arboledas, L., Balis, D., Chaikovsky, A., D'Amico, G., De Tomasi, F., Freudenthaler, V., Giannakaki, E., Giunta, A., Grigorov, I., Iarlori, M., Madonna, F., Mamouri, R.-E., Nasti, L., Papayannis, A., Pietruczuk, A., Pujadas, M., Rizi, V., Rocadenbosch, F., Russo, F., Schnell, F., Spinelli, N., Wang, X., and Wiegner, M.: EARLINET correlative measurements for CALIPSO: First intercomparison results, J. Geophys. Res.-Atmos., 115, https://doi.org/10.1029/2009JD012147, 2010. a, b, c, d, e
Pauly, R. M., Yorks, J. E., Hlavka, D. L., McGill, M. J., Amiridis, V., Palm, S. P., Rodier, S. D., Vaughan, M. A., Selmer, P. A., Kupchock, A. W., Baars, H., and Gialitaki, A.: Cloud-Aerosol Transport System (CATS) 1064 nm calibration and validation, Atmos. Meas. Tech., 12, 6241–6258, https://doi.org/10.5194/amt-12-6241-2019, 2019. a, b
Polyanskiy, Y. and Wu, Y.: Information Theory: From Coding to Learning, Cambridge University Press, 1st edn., https://doi.org/10.1017/9781108966351, ISBN 978-1-108-96635-1, ISBN 978-1-108-83290-8, 2024. a
Proestakis, E., Amiridis, V., Marinou, E., Binietoglou, I., Ansmann, A., Wandinger, U., Hofer, J., Yorks, J., Nowottnick, E., Makhmudov, A., Papayannis, A., Pietruczuk, A., Gialitaki, A., Apituley, A., Szkop, A., Muñoz Porcar, C., Bortoli, D., Dionisi, D., Althausen, D., Mamali, D., Balis, D., Nicolae, D., Tetoni, E., Liberti, G. L., Baars, H., Mattis, I., Stachlewska, I. S., Voudouri, K. A., Mona, L., Mylonaki, M., Perrone, M. R., Costa, M. J., Sicard, M., Papagiannopoulos, N., Siomos, N., Burlizzi, P., Pauly, R., Engelmann, R., Abdullaev, S., and Pappalardo, G.: EARLINET evaluation of the CATS Level 2 aerosol backscatter coefficient product, Atmos. Chem. Phys., 19, 11743–11764, https://doi.org/10.5194/acp-19-11743-2019, 2019. a, b, c, d
Protat, A., Bouniol, D., Delanoë, J., O'Connor, E., May, P. T., Plana-Fattori, A., Hasson, A., Görsdorf, U., and Heymsfield, A. J.: Assessment of Cloudsat Reflectivity Measurements and Ice Cloud Properties Using Ground-Based and Airborne Cloud Radar Observations. J. Atmos. Ocean. Tech., 26, 1717–1741, https://doi.org/10.1175/2009JTECHA1246.1, 2009. a, b, c, d, e
Protat, A., Young, S. A., McFarlane, S. A., L'Ecuyer, T., Mace, G. G., Comstock, J. M., Long, C. N., Berry, E., and Delanoë, J.: Reconciling Ground-Based and Space-Based Estimates of the Frequency of Occurrence and Radiative Effect of Clouds around Darwin, Australia, J. Appl. Meteorol. Clim., 53, 456–478, https://doi.org/10.1175/JAMC-D-13-072.1, 2014a. a
Protat, A., Young, S. A., Rikus, L., and Whimpey, M.: Evaluation of hydrometeor frequency of occurrence in a limited-area numerical weather prediction system using near real-time CloudSat–CALIPSO observations, Q. J. Roy. Meteor. Soc., 140, 2430–2443, https://doi.org/10.1002/qj.2308, 2014b. a
Robinson, J., Jaeglé, L., Palm, S. P., Shupe, M. D., Liston, G. E., and Frey, M. M.: ICESat-2 Observations of Blowing Snow Over Arctic Sea Ice During the 2019–2020 MOSAiC Expedition, J. Geophys. Res.-Atmos., 130, e2025JD043919, https://doi.org/10.1029/2025JD043919, 2025. a, b, c, d
Rodgers, C. D.: Inverse methods for atmospheric sounding: theory and practice, in: Series on atmospheric, oceanic and planetary physics – Vol. 2, World Scientific, Singapore, reprinted edition, ISBN 978-981-02-2740-1, 2008. a
Roebeling, R. A., Deneke, H. M., and Feijt, A. J.: Validation of Cloud Liquid Water Path Retrievals from SEVIRI Using One Year of CloudNET Observations, J. Appl. Meteorol. Clim., 47, 206–222, https://doi.org/10.1175/2007JAMC1661.1, 2008. a
Sayer, A. M., Govaerts, Y., Kolmonen, P., Lipponen, A., Luffarelli, M., Mielonen, T., Patadia, F., Popp, T., Povey, A. C., Stebel, K., and Witek, M. L.: A review and framework for the evaluation of pixel-level uncertainty estimates in satellite aerosol remote sensing, Atmos. Meas. Tech., 13, 373–404, https://doi.org/10.5194/amt-13-373-2020, 2020. a
Schuster, G. L., Vaughan, M., MacDonnell, D., Su, W., Winker, D., Dubovik, O., Lapyonok, T., and Trepte, C.: Comparison of CALIPSO aerosol optical depth retrievals to AERONET measurements, and a climatology for the lidar ratio of dust, Atmos. Chem. Phys., 12, 7431–7452, https://doi.org/10.5194/acp-12-7431-2012, 2012. a, b, c, d
Schutgens, N., Tsyro, S., Gryspeerdt, E., Goto, D., Weigum, N., Schulz, M., and Stier, P.: On the spatio-temporal representativeness of observations, Atmos. Chem. Phys., 17, 9761–9780, https://doi.org/10.5194/acp-17-9761-2017, 2017. a
Schölzel, C. and Friederichs, P.: Multivariate non-normally distributed random variables in climate research – introduction to the copula approach, Nonlin. Processes Geophys., 15, 761–772, https://doi.org/10.5194/npg-15-761-2008, 2008. a
Shannon, C. E.: A mathematical theory of communication, Bell Syst. Tech. J., 27, 379–423, https://doi.org/10.1002/j.1538-7305.1948.tb01338.x, 1948. a
Shupe, M. D., Walden, V. P., Eloranta, E., Uttal, T., Campbell, J. R., Starkweather, S. M., and Shiobara, M.: Clouds at Arctic Atmospheric Observatories. Part I: Occurrence and Macrophysical Properties, J. Appl. Meteorol. Clim., 50, 626–644, https://doi.org/10.1175/2010JAMC2467.1, 2011. a
Silber, I., Verlinde, J., Eloranta, E. W., and Cadeddu, M.: Antarctic Cloud Macrophysical, Thermodynamic Phase, and Atmospheric Inversion Coupling Properties at McMurdo Station: I. Principal Data Processing and Climatology, J. Geophys. Res.-Atmos., 123, 6099–6121, https://doi.org/10.1029/2018JD028279, 2018. a
Soch, J., The Book of Statistical Proofs, Sarıtaş, K., Maja, Monticone, P., Faulkenberry, T. J., Martin, O. A., Kipnis, A., Balkus, S., lfkdlfdlk, Allefeld, C., Atze, H., Knapp, A., McInerney, C. D., Lo4ding00, Ohan, V., amvosk, and maxgrozo: StatProofBook/StatProofBook.github.io: StatProofBook 2024, Zenodo [code], https://doi.org/10.5281/zenodo.4305949, 2025. a
Stone, J. V.: Information theory: a tutorial introduction, Sebtel Press, Sheffield, United Kingdom, 2nd edn., ISBN 978-1-7396727-0-6, 2022. a
Tukiainen, S., O'Connor, E., and Korpinen, A.: CloudnetPy: A Python package for processing cloud remote sensing data, Journal of Open Source Software, 5, 2123, https://doi.org/10.21105/joss.02123, 2020. a, b
Verhoelst, T., Granville, J., Hendrick, F., Köhler, U., Lerot, C., Pommereau, J.-P., Redondas, A., Van Roozendael, M., and Lambert, J.-C.: Metrology of ground-based satellite validation: co-location mismatch and smoothing issues of total ozone comparisons, Atmos. Meas. Tech., 8, 5039–5062, https://doi.org/10.5194/amt-8-5039-2015, 2015. a, b
Verhoelst, T., Povey, A. C., Gruber, A., Bulgin, C. E., Keppens, A., Compernolle, S., and Lambert, J.-C.: Confidently Uncertain: Validating Satellite ECV Measurement Uncertainty Estimates, Surv. Geophys., https://doi.org/10.1007/s10712-026-09939-6, 2026. a
Virtanen, T. H., Kolmonen, P., Sogacheva, L., Rodríguez, E., Saponaro, G., and de Leeuw, G.: Collocation mismatch uncertainties in satellite aerosol retrieval validation, Atmos. Meas. Tech., 11, 925–938, https://doi.org/10.5194/amt-11-925-2018, 2018. a
von Clarmann, T.: Validation of remotely sensed profiles of atmospheric state variables: strategies and terminology, Atmos. Chem. Phys., 6, 4311–4320, https://doi.org/10.5194/acp-6-4311-2006, 2006. a
Wang, P., Donovan, D. P., van Zadelhoff, G.-J., de Kloe, J., Huber, D., and Reissig, K.: Evaluation of Aeolus feature mask and particle extinction coefficient profile products using CALIPSO data, Atmos. Meas. Tech., 17, 5935–5955, https://doi.org/10.5194/amt-17-5935-2024, 2024. a, b
- Abstract
- Introduction
- Framework
- Application example: validating the ICESat-2 ATL09 cloud layer product using Cloudnet observations
- Discussion
- Summary
- Appendix A: Mutual information bounds for spatially inhomogeneous joint distributions
- Appendix B: Quality checks and homogenisation
- Appendix C: Across-track orbital density
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Framework
- Application example: validating the ICESat-2 ATL09 cloud layer product using Cloudnet observations
- Discussion
- Summary
- Appendix A: Mutual information bounds for spatially inhomogeneous joint distributions
- Appendix B: Quality checks and homogenisation
- Appendix C: Across-track orbital density
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References