the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Jul 2019
| 02 Jul 2019
Cloud identification and classification from high spectral resolution data in the far infrared and mid-infrared
William Cossich
Iacopo Sbrolli
A new cloud identification and classification algorithm named CIC is presented. CIC is a machine learning algorithm, based on principal component analysis, able to perform a cloud detection and scene classification using a univariate distribution of a similarity index that defines the level of closeness between the analysed spectra and the elements of each training dataset. CIC is tested on a widespread synthetic dataset of high spectral resolution radiances in the far- and mid-infrared part of the spectrum, simulating measurements from the Fast Track 9 mission FORUM (Far-Infrared Outgoing Radiation Understanding and Monitoring), competing for the ESA Earth Explorer programme, which is currently (2018 and 2019) undergoing industrial and scientific Phase A studies. Simulated spectra are representatives of many diverse climatic areas, ranging from the tropical to polar regions. Application of the algorithm to the synthetic dataset provides high scores for clear or cloud identification, especially when optimisation processes are performed. One of the main results consists of pointing out the high information content of spectral radiance in the far-infrared region of the electromagnetic spectrum to identify cloudy scenes, specifically thin cirrus clouds. In particular, it is shown that hit scores for clear and cloudy spectra increase from about 70 % to 90 % when far-infrared channels are accounted for in the classification of the synthetic dataset for tropical regions.
- Article
(5413 KB) - Full-text XML
- BibTeX
- EndNote





At the end of 2017, the European Space Agency selected the FORUM (Far-infrared Outgoing Radiation Understanding and Monitoring) mission as one of the two instrument concepts to compete for the Earth Explorer Fast Track 9 satellite programme. FORUM is based on a far-infrared spectrometer devoted to high spectral resolution (nominally 0.3 cm−1) measurements from 100 to 1600 cm−1, thus including the so-called far-infrared (FIR) region, spanning from 100 to 667 cm−1.
The FIR represents an important fraction of Earth's outgoing longwave radiation, which contributes considerably to the planetary energy balance. The atmospheric emission in the FIR is driven by the rotational absorption band of the water vapour molecules and is characterised by strong absorption lines interspersed by narrow regions (called “dirty micro-windows”), where absorption is less intense. The strong absorption features of water vapour roto-vibrational lines cause atmospheric weighting functions in the FIR to peak in the mid-troposphere and upper troposphere, thus making the on-line upward emission particularly sensitive to the atmospheric thermodynamic profile and water vapour content of the highest tropospheric levels. Micro-window radiance is highly sensitive to the water vapour mixing ratio (Maestri et al., 2014) and also affected by the water vapour continuum absorption, which is usually modelled through observations (Mlawer et al., 2012; Serio et al., 2008). Moreover, the condensed phases of water, in the form of liquid water and ice clouds, also affect Earth's radiation budget significantly (Sinha and Harries, 1995) and, in particular, the presence of ice clouds causes lower-emitting temperatures and, hence, a shift towards longer wavelengths (thus towards the FIR) of the peak of the black-body emission distribution function. For this reason, a detailed study of the Earth's radiation budget should account for global, accurate, all-sky condition measurements of the exiting radiance, including the FIR.
As many recent studies have shown, due to the large sensitivity of the upward radiance in the far-infrared part of the spectrum to water vapour and clouds, the FIR can be used to complement standard remote-sensing measurements performed in the mid-infrared (MIR) part of the spectrum in order to retrieve atmospheric water vapour profile, for cloud detection, classification and property derivation. In Merrelli (2012) it is demonstrated that the retrieval of cloud properties and water vapour mixing ratio in the middle and upper troposphere is more accurate if FIR spectral information (i.e. radiance) is considered. Moreover, in Palchetti et al. (2016) it is shown that by using the full infrared emission spectrum more information may be retrieved about cirrus cloud microphysical properties. In Maestri et al. (2019), it is shown that the Radiation Explorer in the “Far InfraRed: Prototype for Applications and Development” (REFIR-PAD) channels hold additional information for cloud detection and cloud-phase classification from ground-based measurements.
Along the lines of these recent research studies, in this work an innovative cloud identification and classification technique, with applications for infrared high spectral resolution synthetic data, including the far-infrared part of the spectrum, is presented. Many different cloud detection techniques exist and the majority of them exploit data spanning from infrared to shortwave, which limits their applicability to daytime hours only. An example of such a technique is the principal component analysis (PCA)-based detection algorithm presented by Ahmad (2012). Other techniques rely on outgoing longwave radiation only; one example is the algorithm presented in Serio et al. (2000), which is tailored to work on water surfaces. Among the techniques exploiting outgoing longwave radiation only and applied globally, the cumulative discriminant analysis by Amato et al. (2014), the European Centre for Medium-range Weather Forecasts (ECMWF) scheme by McNally and Watts (2003), the Met Office 1D-Var retrieval system (Pavelin et al., 2008), the NCEP minimum residual method (Eyre, 1989) and the Centre de Météorologie Spatiale (CMS) cloud mask (Lavanant and Lee, 2005) are mentioned. These methodologies are applied to space-borne spectrometers and radiometers such as the Atmospheric InfraRed Sounder (AIRS), the Infrared Atmospheric Sounding Interferometer (IASI) and the Advanced Very-High-Resolution Radiometer (AVHRR). The last three methodologies perform cloud detection and classification simultaneously. They also depend on ancillary information regarding the atmospheric state derived from numerical weather prediction models. McNally and Watts (2003), for example, analyse the difference between simulated clear-sky spectra and the measured spectra to detect the presence of clouds, using the global model of the ECMWF to make a short-term forecast of the atmospheric state.
Most cloud detection schemes rely on the definition of some statistical parameter, which serves as a classifier, and on a statistical technique used to assign a value to the classifier. Both the cumulative discriminant analysis and the Met Office 1D-Var retrieval system seek the minimisation of a cost function. This minimisation produces the classification label of the spectrum and an estimate of the cloud fraction, respectively.
Some of the detection algorithms used for cloud identification have been adapted for aerosol detection and some innovative methodologies have been recently developed. A comprehensive overview of the most widely used techniques for aerosol detection and classification, such as feature detection methods based on thresholds and brightness temperature differences, spectral fitting minimisation methods, approaches based on look-up-tables and minimisation of the Mahalanobis distance, and methods based on singular value decomposition and PCA, is provided in Clarisse et al. (2013).
Taking the cue from existing cloud detection algorithms, a cloud identification and classification (CIC) method is developed. CIC is a machine learning algorithm based on principal component analysis, which performs an identification and classification using a single threshold applied to a univariate distribution of a newly defined parameter called the similarity index (see Sect. 3.2), which determines relatedness with a specific class (training set). It is partially based on other works (see Malinowski, 2002; Turner et al., 2006, for reference) and, with respect to previously described methods, has the advantages of being easy to implement, user-friendly, fast and efficient.
In this paper, the CIC algorithm is used to perform cloud detection on a synthetic dataset consisting of infrared spectra with wave numbers ranging from 100 to 1600 cm−1 and a nominal resolution equal to 0.3 cm−1, created to simulate satellite measurements of the FORUM mission. Cloud detection is performed both using the MIR only or the full spectrum (FIR and MIR), so that the detection performances could allow an evaluation of far-infrared channels information content in realistic conditions. The algorithm is applied to simulated FORUM measurements from different climatic areas in order to observe the influence of atmospheric conditions on detection scores.
This paper is organised as follows. In Sect. 2 the synthetic dataset is illustrated. Sect. 3 is dedicated to the CIC algorithm description and functionalities. Section 4 deals with results obtained from CIC application to FORUM synthetic data. A brief summary is drawn in Sect. 5.
A widespread dataset of simulated radiances for multiple atmospheric conditions is computed in order to test the cloud identification and classification algorithms. The synthetic dataset is built using a chain of codes to perform accurate line-by-line multiple scattering computations as represented in Fig. 1. The computational methodology is similar to the one described by Bozzo et al. (2010) and the radiative transfer equation is solved through an adding–doubling algorithm for a plane-parallel geometry and simulating the FORUM satellite nadir view.
The line-by-line computations of layer spectral optical depths are performed using the Line-by-Line Radiative Transfer Model (LbLRTM) version 12.7 (Clough et al., 2005), whose inputs are atmospheric vertical profiles and spectroscopic gas properties. This model includes a recently updated water vapour continuum parameterisation, MT_CKD (Mlawer et al., 2012) version 3.0, and a consistent spectroscopic database, AER version 3.5, built from HITRAN2012 (Rothman et al., 2013). The atmospheric thermodynamic vertical profiles and gas mixing ratios (such as those of H2O, CO2, CH4, O3 and for a total of 22 molecules) are derived from different sources. The first one is the ERA-Interim reanalysis (Dee et al., 2011), with a horizontal resolution equal to 0.75∘ (approximately 80 km) and 60 vertical levels from the surface up to 0.1 hPa. This database, which provides four sets of data per day, is used to retrieve profiles of temperature, pressure, specific humidity, ozone mixing ratio and surface geopotential height from which the geometric surface and atmospheric level heights are computed. The daily January, April, July and October 2016 ERA-Interim reanalysis data are downloaded for the dataset generation in order to reproduce the seasonal and daily variations in the thermodynamic variables. Grid points from the tropics, mid-latitudes and polar regions (Arctic and Antarctic) are selected.
The second source of information is the initial guess climatological database IG2 (Remedios et al., 2007), which includes atmospheric profiles for six latitude bands, four seasons and two times of the day. This database spans from 2007 onwards, with a constant vertical resolution of 1 km from the surface up to 120 km, and provides time-averaged data concerning altitude, pressure, temperature and a wide range of gas-mixing ratio profiles.
ERA-Interim reanalysis data are thus used to characterise the daily variation in the main atmospheric parameters up to approximately 60 km in height, and the IG2 is used to add information in the highest atmospheric layers and to provide information concerning minor gases mixing ratios.
Surface emissivity properties are selected in accordance with geolocation by using the global database produced by Huang et al. (2016). The database includes 11 types of spectral emissivity in the infrared region of the spectrum representative of rainforest; temperate deciduous forest; conifer forest; grass; dry grass; desert; ocean; coarse, medium, and fine snow; and ice.
The cloud microphysical properties are generated by integrating the Ping Yang database, consisting of single-scattering properties of randomly oriented non-spherical ice crystals (Yang et al., 2013), over a large set of gamma type size distributions. Liquid water and mixed-phase spherical particles radiative properties are derived through the ScattNlay code (Peña and Pal, 2009) and subsequently used to get bulk properties of particle size distributions. The mixed-phase spheres consist of a core of ice surrounded by a coating of liquid water. This shell of liquid is modelled as a coating of 10 % or 20 % of the radius of the entire particle. In the simulations, many cloud properties are varied: cloud top height, geometrical thickness, optical thickness, particle size distribution, mean effective dimension, particle shape and phase (ice, liquid water and the two levels of mixed phase). The cloud property inputs to the radiative transfer code are modified over large ranges of values in order to account for the largest possible variability encountered in nature. Some datasets and recent studies are considered as baseline. The International Satellite Cloud Climatology Project (ISCCP) (Rossow and Schiffer, 1999; Hahn et al., 2001) is an example. Cirrus clouds properties in the tropics and at mid-latitudes are mostly based on what was found by Veglio and Maestri (2011), while Antarctic cloud properties are obtained from several sources (i.e. Adhikari et al., 2012; Bromwich et al., 2012; Lachlan-Cope, 2010). In Table 1 the range of variability of some key cloud properties is reported.
Table 1Range of variability of the main cloud properties used in the simulations. The habit type indicates the assumed pristine shapes of the ice crystals. The mixed-phase water coating indicates the percentage of liquid water coating with respect to the dimensions of the assumed spherical particle.


Figure 1Software architecture (schematic) of the simulation process used to build the synthetic dataset for FORUM-like observations. Blue boxes are codes and red boxes are auxiliary datasets. OD stands for gaseous optical depths computed using the Line-by-Line Radiative Transfer Model (LbLRTM) version 12.7 (Clough et al., 2005). The radiative transfer X (RTX) is described in Bozzo et al. (2010). The Fourier transform spectroscopy and the simulation of FORUM noise are included in the RTX box.
As illustrated in Fig. 1, for each selected atmospheric condition, high spectral resolution optical depths of atmospheric layers are computed using LbLRTM and the results are passed as inputs to the radiative transfer X (RTX) and, when in presence of clouds, the gas optical depths are merged with those derived from cloud properties (see Bozzo et al., 2010). RTX, which is based on the doubling and adding method (Evans and Stephens, 1991) and is thus capable of solving the full radiative transfer equation in multiple scattering conditions, is then run to obtain the high spectral resolution radiances that are finally convoluted with an ideal FORUM-like instrument line shape (ILS) that is assumed to be a sinc function.
Table 2Random noise used to simulate the Fourier transform spectrometer of the FORUM mission.
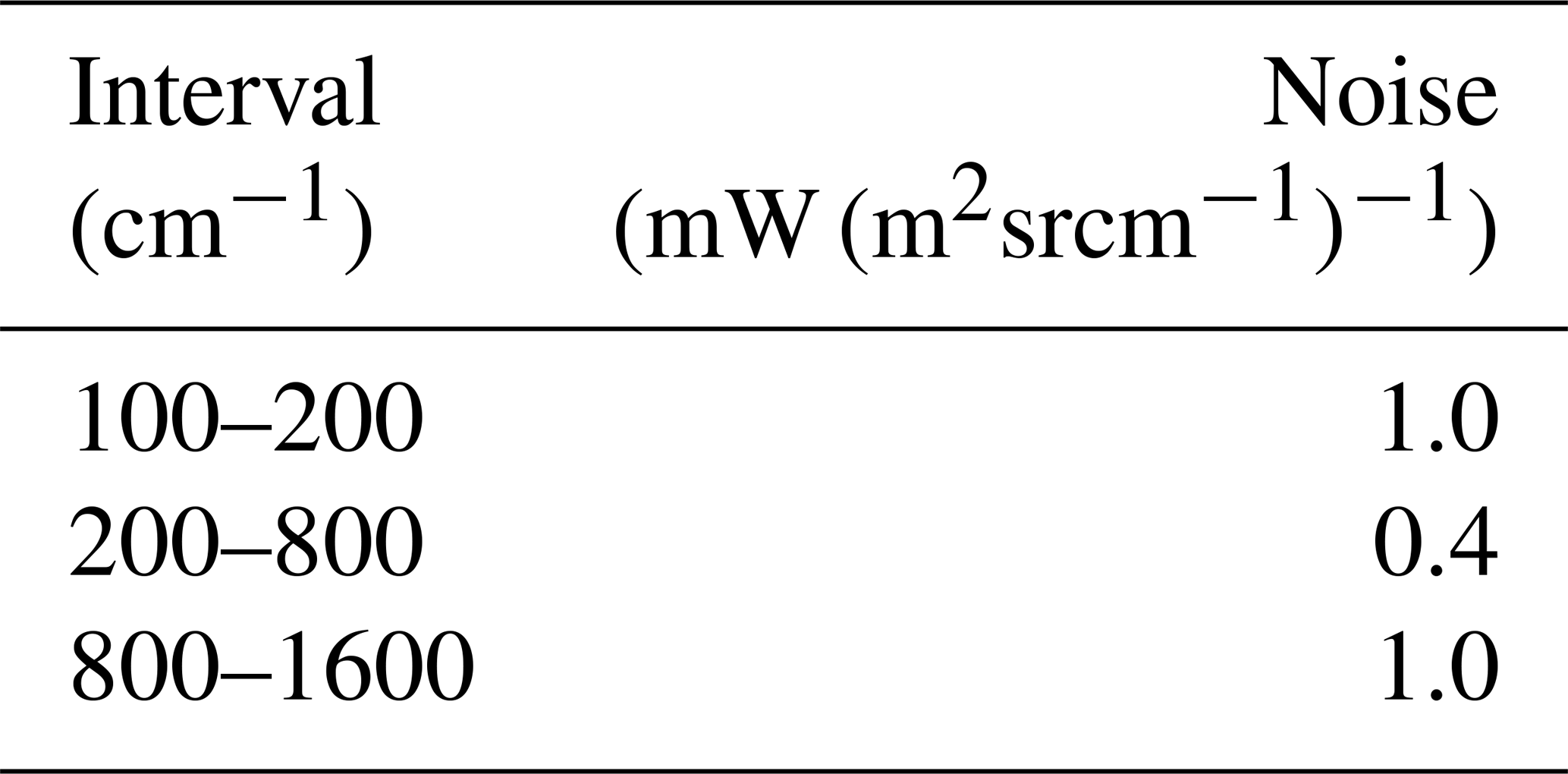
This operation produces unapodised spectra with 0.3 cm−1 spectral resolution over a spectral range spanning from 100 to 1600 cm−1, representative of FORUM mission noiseless observations. In a subsequent step, a nominal noise-equivalent spectral radiance (NESR), as reported in the FORUM proposal RCEE9/027 to the ESA, is added to the simulated radiances in order to produce a realistic FORUM observations dataset. The new dataset is computed by adding a Gaussian wave-number-dependent noise to the noiseless radiances. The spectral dependence and amplitude of the noise are derived from the technical specification of the Fourier transform spectrometer instrument described in the FORUM proposal to the ESA (available on request) and reported in Table 2. The NESR values reported in the table correspond to a typical percentage noise of about 1 % in the 200–800 cm−1 wave number interval. The exact value depends on the specific wave number and observational conditions accounted for. Below 200 cm−1 and above 1400 cm−1 the percentage noise can be higher than 15 % due to the low radiance values.
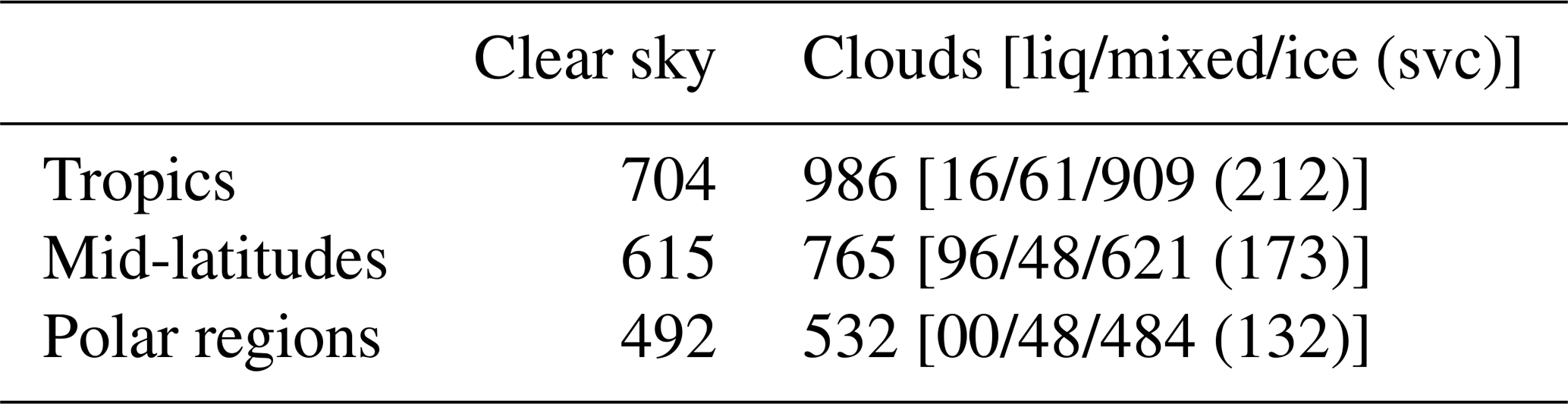
Table 3Number of clear and cloudy simulated spectra for each latitude belt. Indicated in brackets is the number of liquid water clouds (liq), mixed-phase clouds (mixed), and ice clouds (ice) and, among these, the number of sub-visible cirrus clouds (svc), consisting of high-altitude cirri with optical depths less than 0.03, are shown in parentheses.
A spectral random noise is computed for each spectrum. The central limit theorem is used so that the sum of random numbers (rtot) from a uniform distribution ranging from −0.5 to 0.5 (variance is 1∕12) is used to generate a Gaussian variable (rgauss) with a mean of 0 and a standard deviation, σν, assumed to be equal to the FORUM noise. The spectral random noise is thus obtained by using the following formula:
A schematic summary of the whole dataset, comprised of 4244 simulated spectra, is presented in Table 3 for each latitude belt and for the clear or cloudy class. Some examples of spectra are shown in Figs. 2, 3, 4 and 5.
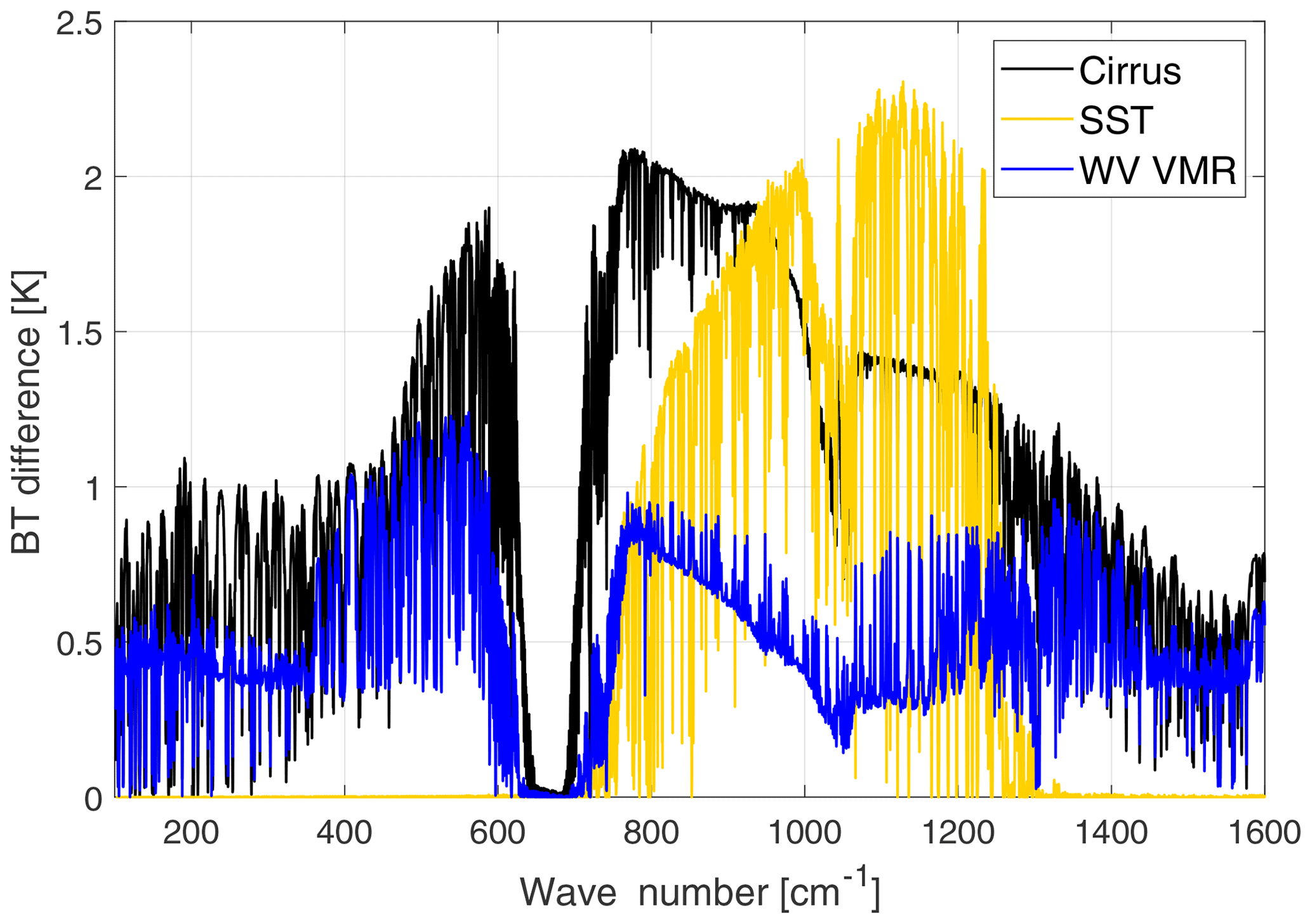
Figure 2Brightness temperature (BT) sensitivity to a sub-visible cirrus cloud (black line), a 3 K decrease in surface temperature (yellow line) and an increase of 10 % in water vapour mixing ratio at all levels (blue line). The BT differences are obtained in reference to a tropical clear-sky case over the ocean.
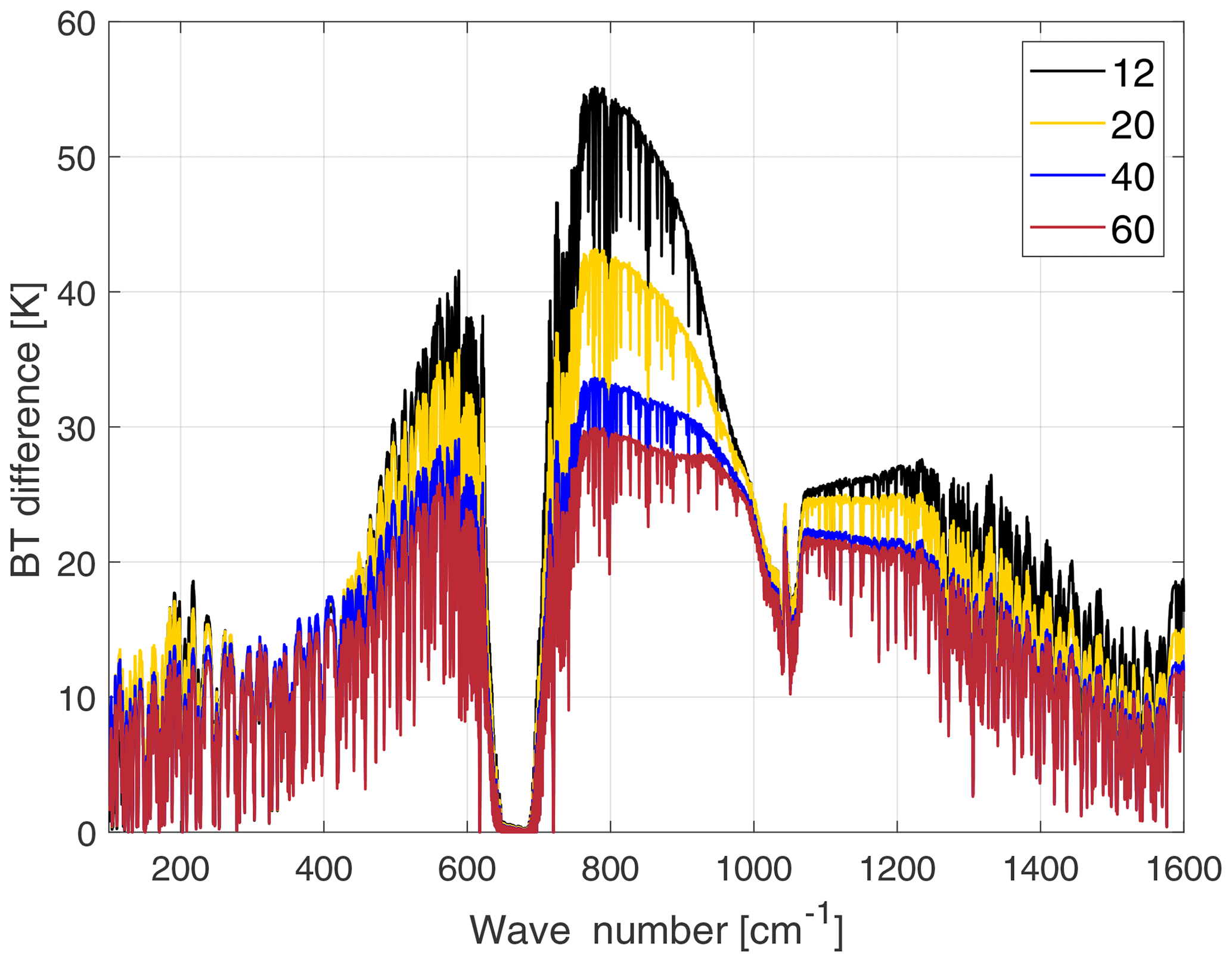
Figure 3Brightness temperature sensitivity to cirrus cloud particle-size-distribution effective dimensions. Dimensions values in the legend are in µm. The assumed shape is the plate type, optical depth is 1.5, the cloud thickness is 1 km and cloud top is at 14 km. The BT differences are obtained in reference to a tropical clear-sky case over the ocean.
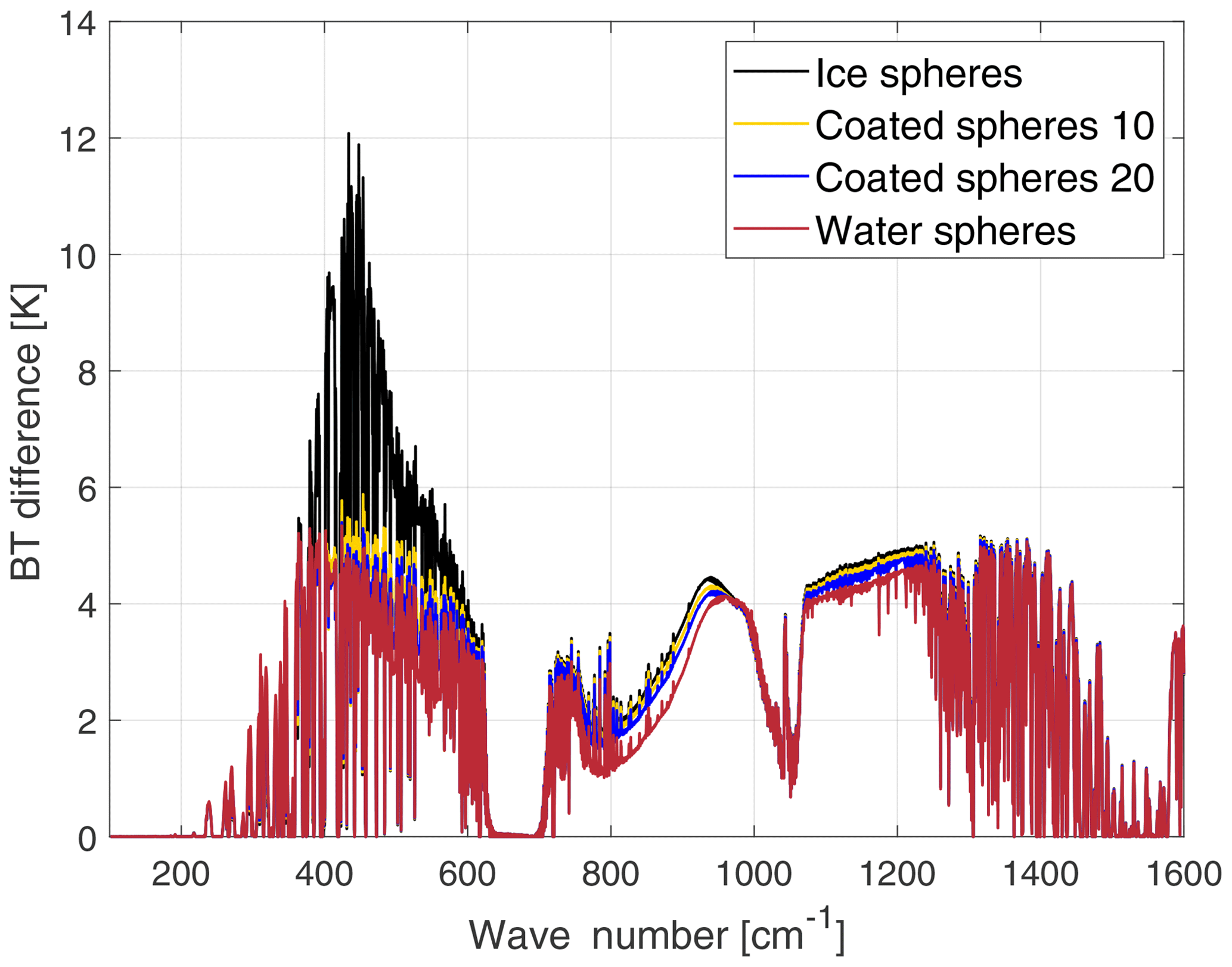
Figure 4Brightness temperature sensitivity to the particle phase. A polar cloud is assumed made of a particle size distribution of spheres of ice (black line), liquid water (red) and two mixed phases. The mixed phase are spheres with an ice core and liquid water coating. The coating is, respectively, 10 % (yellow line) and 20 % (blue line) of the total sphere radius. Cloud optical depth is 7, cloud thickness is 1.5 km and cloud altitude is 5 km. The BT differences are obtained in reference to an Antarctic clear-sky case over a snowed surface.
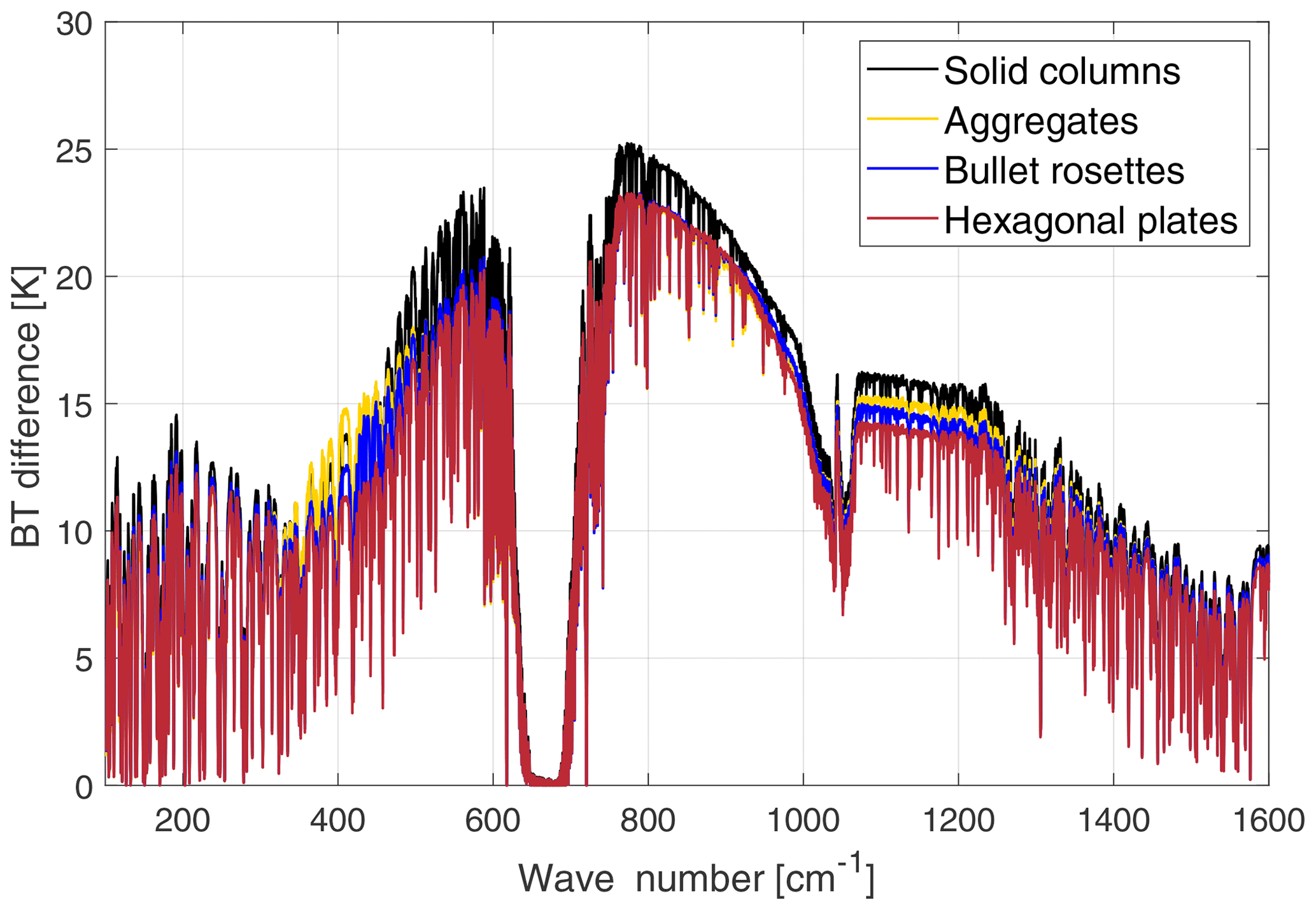
Figure 5Brightness temperature sensitivity to cirrus cloud crystal habit. The crystal's habits assumed are reported in the legend. The simulated tropical cirrus cloud is 2 km thick, with optical depth 1 and with an effective dimension equal to 32 µm. The BT differences are obtained in reference to a tropical clear-sky case over the ocean.
In Fig. 2, the brightness temperature sensitivity (with respect to a reference clear-sky case) is shown for three different cases in the tropical atmosphere: a sub-visible cirrus cloud (black line), the clear-sky case with a 3 K decrease in skin surface temperature (yellow line) and the clear-sky case with an increase of 10 % along the vertical profile of the water vapour mixing ratio (blue line). The cirrus is assumed to be composed of plates with an effective dimension of 20 µm, optical depth OD=0.03 and geometrical thickness 1 km. Results show distinctive spectral features due to the presence of the cirrus cloud in the satellite view. For the tropical region in particular, the radiance signal in the FIR exiting from the surface is masked by the strong absorption by the water vapour rotational band (which is almost saturated for wave numbers below 300 cm−1).
In Fig. 3 the large brightness temperature (BT) sensitivity to cloud particle-size-distribution effective dimensions is highlighted for channels in the MIR window and for wave numbers between 400 and 600 cm−1. Cloud properties are as follows: OD is 1.5, geometrical thickness is 1 km and cloud top is at 14 km.
Sensitivity to cloud particle phase is shown in Fig. 4. In the computations a polar cloud (OD is 7, geometrical thickness is 1.5 km and cloud top is at 5 km) made of spheres of pure ice, liquid water or of two diverse mixed phases (see figure caption for the details) is assumed. The results show that the highest BT sensitivity to phase is found at FIR wave numbers. Note also how the mixed-phase spheres resemble the pure ice phase in the MIR window channel and the pure liquid water in the FIR channels.
Finally, in Fig. 5 the sensitivity to crystal habit is shown. Four different habits (aggregates, plates, bullet rosettes and solid columns) are assumed in the simulation of four different tropical cirrus clouds with the same features (OD is 1, geometrical thickness is 2 km, cloud top is at 15 km and the effective dimension is 32 µm). Habit sensitivity is much larger in the FIR (about 5 K spread among the curves for different shapes) than in the MIR windows (about 2 K). This is mostly due to a minimum in the imaginary part of the ice refractive index at around 410 cm−1 that implies a minimum in absorption at FIR wavelengths and a relatively large importance of scattering processes that are related to crystal shape. This FIR largest sensitivity is noted to increase with the dryness of the atmosphere and thus amplified when moving towards higher latitudes (not shown here).
3.1 Algorithm description
CIC is an innovative classification algorithm based on principal component analysis. The methodology relies on a machine learning algorithm that requires the definition of a certain number of training sets equal to the number of classes used for the classification. A descriptive example of the identification process of clear and cloudy cases (cloud detection) is first provided in order to facilitate the comprehension of the rigorous mathematical treatment that follows this brief introduction. In Fig. 6 a flowchart of the algorithm is depicted.
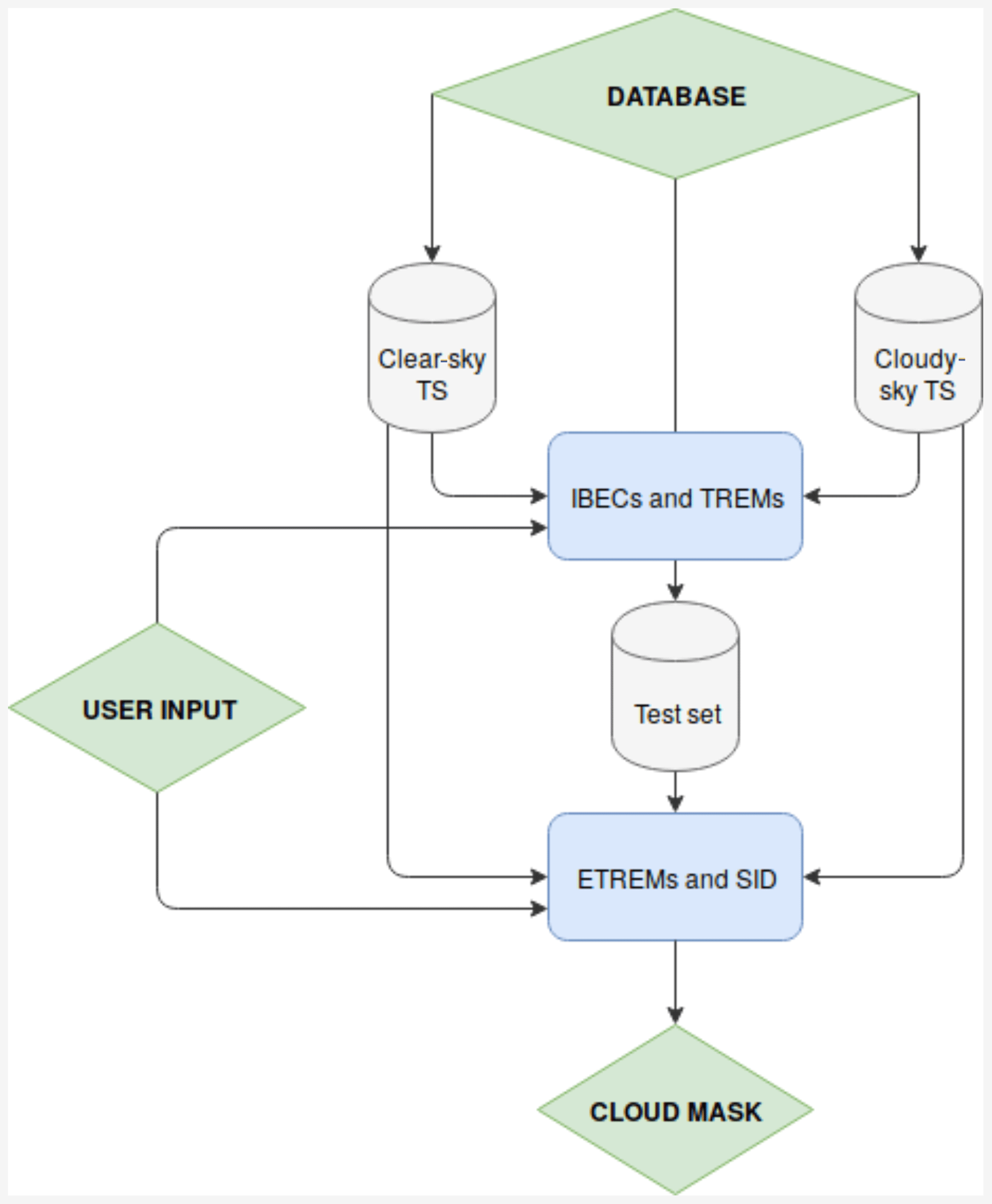
The first step requires the definition of a clear-sky training set (TRcle), consisting of a number Tcle of clear-sky spectra, and a cloudy-sky training set (TRclo), consisting of Tclo cloudy-sky spectra. For each training set the principal components (PCs) are computed and stored in a matrix. Each spectrum of the test set (one at a time) is then added to the TRcle, and thus an extended clear-sky training set (ETRcle) is defined. ETRcle is a group of Tcle+1 spectra. The principal components of the ETRcle are computed. Supposing that the test set spectrum under consideration is a clear-sky spectrum, it is expected that the PCs computed for ETRcle are very similar to the ones computed for TRcle, which is to say that the test set element has the same basic features as the elements belonging to the training set (clear in the running example). In this case, it is also expected that the PCs computed for the cloudy-sky training set TRclo differ from the PCs obtained from the extended cloudy-sky training set (ETRclo) that is obtained by adding the spectrum in consideration (that is clear) to the cloudy-sky training set.
CIC evaluates the variation in the principal components of the training sets due to the addition of a new spectrum (from the test set). The association of a spectrum to a specific class is obtained by evaluating the similarity of PCs of the extended training sets to those of the original training sets: small changes in PCs are interpreted as that the spectrum belongs to the class while large changes suggest that the spectrum belongs to a different class. The variations in the PCs obtained for the extended training sets with respect to the original ones are evaluated by means of a new parameter called similarity index.
The notation for similarity indices is as follows:
where i is the class label, j is the test set spectrum label and J is the number of spectra in the test set to be classified. As an example (that is used in the whole text), it is assumed that the class label is 1 for clear-sky spectra and 2 for cloudy-sky spectra.
The computation of the similarity indices are now described mathematically. The first step is the definition of the training set matrices.
where t is the spectrum index, Ti is the number of spectra in each training set i, ν is the wave number index that spans from 1 to νmax, which is the highest wave number index.
The second step consists of the computation of the PCs of each training set matrix by evaluating the eigenvectors (eig) of their covariance (cov) matrix:
where TREMi is the training eigenvector matrix, p indicates the pth principal component and is the total number of principal components.
Each row of this matrix contains normalised eigenvectors:
Given J spectra in the test set, a number of J new matrices are defined for each class. These matrices are simply the concatenation of the training set matrices with each single spectrum (j) from the test set and are called extended training set matrices. The following matrix contains all of the spectra from the test set.
The extended training set matrices are defined as follows:
where the notation ∥ indicates matrix concatenation. Note that rowj(TS(ν,j)) is a single test set spectrum in a one-dimensional array.
CIC evaluates the principal components of the extended training set ETREMi,j as follows:
The training and extended training eigenvector matrices are used to compute the similarity indices (SIs) for each test set spectrum (j) and for each class (i):
where νtot is the number of features (channels) used for PCA analysis and Po is the number of principal components that are associated to the physical signal (real variability) characterising the spectrum. Using the same weight (1∕2Po) for each term of the sum makes the SI very sensitive to any spectral signature present in the spectrum.
The set of optimal principal components (Po) characterising the signal constitutes the information-bearing principal components (IBECs). The Po elements are extracted by minimising the factor indicator function (IND) defined by Malinowski (2002) and Turner et al. (2006) as follows:
where RE(p) is defined, in Turner et al. (2006), as the real error
where λi is the ith eigenvalue of the covariance of some of the data matrices and Ti is the number of spectra in the training set i.
The natural number P0, obtained through this minimisation process, is the number of eigenvectors associated with the physical signal corresponding to the number of IBECs. In CIC, Po is computed separately for both training set matrices ().
Once Po is determined, the similarity index can be calculated using Eq. (7). For consistency, the same value of Po is used when the SI computation is applied to the two training sets; the minimum value for Po is utilised.
Interpreting the eigenvectors as directions in the multi-dimensional space, SI is an estimate of how much the principal components of the training set rotate after a new spectrum is added to the set. For this reason, similarity indices do not depend on eigenvalues but on eigenvectors: all the principal components describing the physical signal are accounted for with the same weight in Eq. (7), since all of them might be important for classification.
Similarity indices defined in this way are normalised. In fact, since the absolute value of the difference between the square loadings of two eigenvectors is at most equal to 2, the sum of Po differences can reach the maximum value of 2Po. And being an absolute value, the following is true:
therefore,
With reference to Eq. (7), the largest value of the similarity index (1) is obtained for identical TREM and ETREM matrices, meaning that the analysed test set spectrum is not adding any diverse physical information to the training set spectra. An SI close to zero means that the two matrices are described by very different PCA and the test set element is bringing additional information to the original training set.
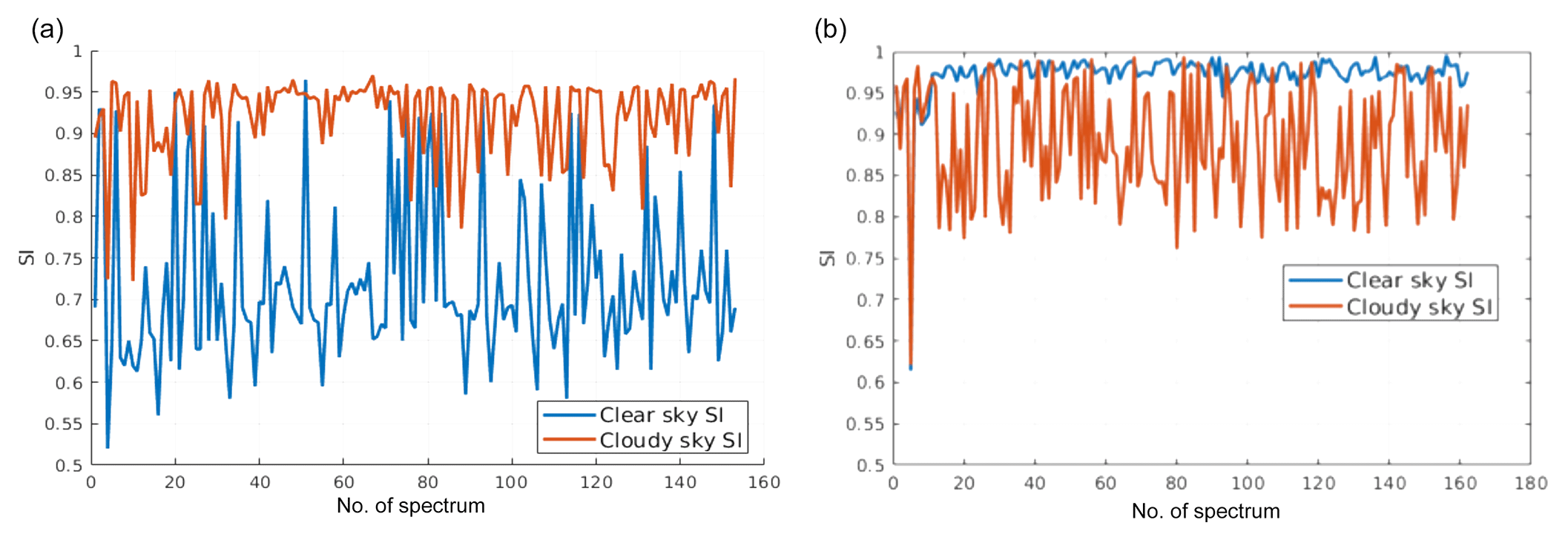
Figure 7Similarity indices computed using tropical cloudy spectra only (a) or clear-sky spectra only (b). In orange the SI is computed using the cloudy-sky training set and in blue using the clear-sky training set. The tropical case is accounted for. The full spectrum is used in the SI computations. Details on the training sets are provided below in the text.
A graphical example of the similarity index is provided in Fig. 7. The plot shows the SI computed for cloudy elements of the tropical test set only in Fig. 7a and for clear-sky elements only in Fig. 7b. For cloudy-sky test set cases, when the SI is computed using the cloudy training set (orange line), the SI is very close to one, while the SI values are mostly lower when the clear-sky training set is used. Thus, the inequality holds for most cloudy-sky spectra j. The situation is reversed when clear-sky elements of the test set are used (Fig. 7a) showing that highest SI values are generally obtained when using the clear-sky training set (blue line). CIC exploits results from both of the comparisons: SI computed using the clear-sky and the cloudy-sky training sets.
3.2 Classification
3.2.1 Elementary approach
CIC classification requires that each test set element is used for the computation of both similarity indices (one for each training set of the two classes). Once the SIs for the extended training sets (the one containing cloudy spectra and the one for clear ones) are computed, a comparison is performed. Continuing with the running example, when
then spectrum j is expected to be clear sky (cle). And, of course, for
the spectrum j is expected to be cloudy (clo).
These two conditions may be unified in a compact index that is defined as the similarity index difference (SID):
and thus
Spectra classification based only on the SID sign is defined as the elementary approach: SID acts as a binary classification parameter. Each spectrum is analysed sequentially and independently from the other elements of the test set under consideration. This elementary approach has the main advantage of being very simple and straightforward and the disadvantage of being sensitive to the composition of the training sets. In fact, results might be affected (and biased) if one of the training sets is not well populated by spectra that are representative of the variability within the class. An example of the elementary classification is given in Fig. 8 where the SID distribution for clear and cloudy-sky spectra is shown. In the example, the cloudy-sky and clear-sky training sets are not well characterised (some unbalance is observed) since even if all the cloudy spectra show positive SIDs (as expected), a large number of clear-sky spectra also has positive SIDs, and thus those spectra are potentially misclassified. It is therefore shown that the elementary approach requires an accurate definition of the training sets to work properly.
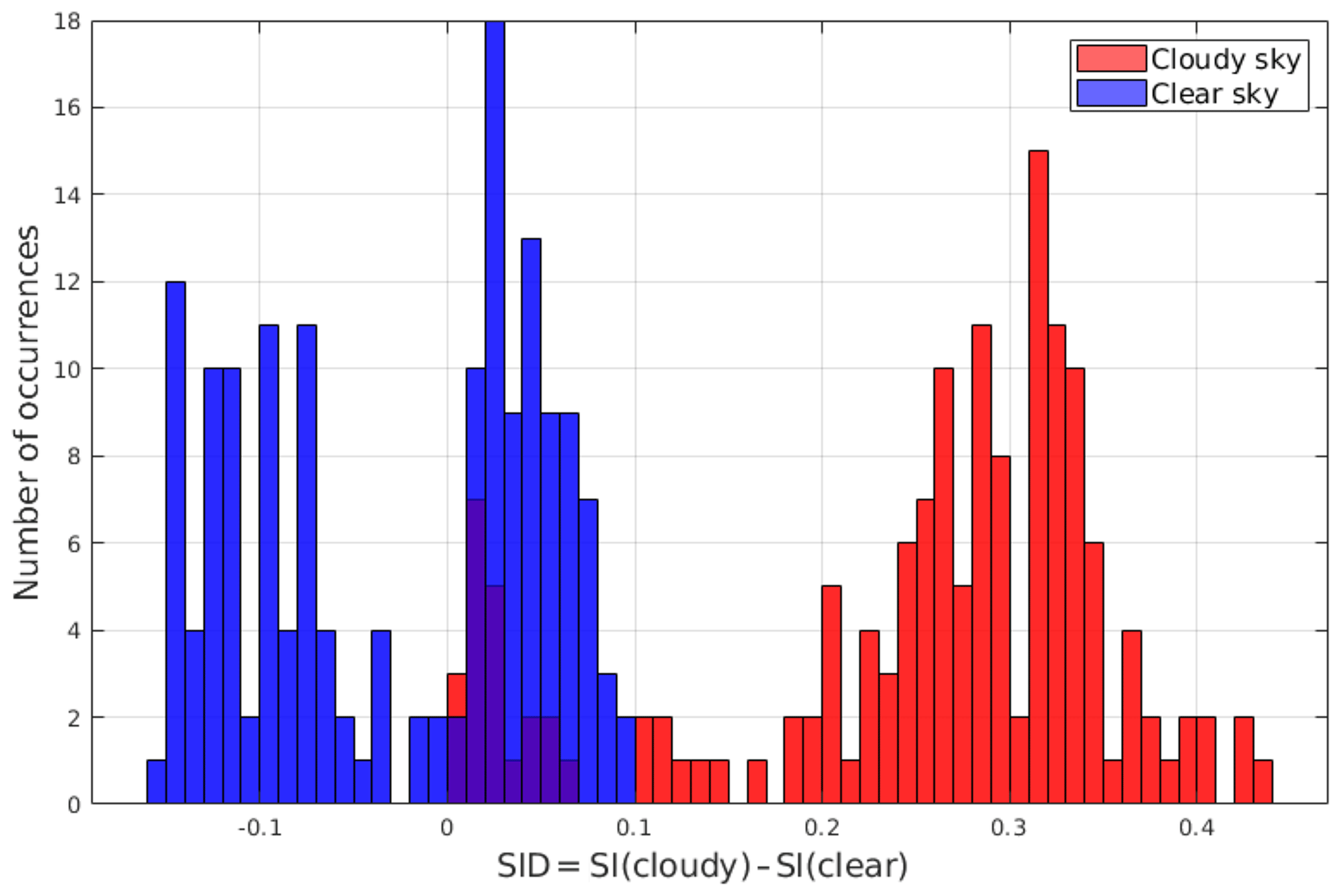
Figure 8SID occurrence distribution for a subset of tropical spectra. The SIDs are computed based on specific (not optimised) training sets. Test set clear-sky spectra are in blue, while cloudy-sky spectra are in red. Cirrus clouds show very small, positive values of the SID, comparable with values obtained for some clear-sky spectra. Class membership of test set spectra is known a priori since the dataset is synthetic.
3.2.2 Distributional approach
A distributional approach can be adopted for the classification in which the distribution of the SIDs of the training set is analysed before performing the classification.
A perfect classifier would ideally generate a bimodal SID distribution. Thus, the transition from one mode to the other could be associated to a binary classification parameter that changes sign in the transition point. In order to accomplish this task a new index is defined called the corrected similarity index difference (CSID).
The elements of the training set (both the clear and cloudy spectra) are used to mathematically define CSID, which is simply a shifted SID:
where shiftopt is the optimal value of the parameter “shift” that maximises a function that can potentially forecast the performance of the algorithm (a performance forecasting function, PFF). This function is called consistency index (CoI) and is defined below:
where the clear and cloudy false positives (FP) are counted as follows:
In the above formula, the card operator denotes the number of elements of the set, while Tcle and Tclo are the number of clear and cloudy training set elements, respectively. The consistency index measures the representativeness of the training sets and in particular it computes how many training set elements would be classified correctly if they were part of the test set. The consistency index is large (close to 1) only if both clear and cloudy false positives (FP in the equations above) are rare, i.e. when the training sets are composed of elements that accurately represent the variability within the specific class.
The new CSID parameter operates as the SID parameter: if it is positive, the spectrum is considered cloudy, and if it is negative, the spectrum is considered clear. The following formulae are used for this purpose:
The use of the distributional approach significantly improves the performance of the algorithm, as will be shown later in the text.
3.3 Unclassified spectra
Each element of the test set is classified in accordance with the sign of the classifier (SID or CSID). For practical purposes, it can be useful to define some thresholds or limits that determine a set of “unclassified” elements characterised by values of the classifier belonging to a limited interval around 0 (that is the ideal point separating the two modes of the distribution). The simplest way to set this interval is to let the user define two parameters, Θ1 (positive) and Θ2 (negative), representing the inner limits of a confidence interval. Any spectrum wherein the classifier falls within the interval [Θ2,Θ1] is considered “unclassified”. The Θ2 and Θ1 parameters should be defined in accordance with the experimental conditions and sensor performances and their quantification is beyond the scope of this work. For this reason, and since we rely on a synthetic test set, all the classifications performed will be binary, i.e. each element is classified either clear or cloudy.
3.4 Scores
There is no unique metric to define the performances of a cloud classification algorithm since their assessment is linked to the goal of the study. For this reason, the set of parameters (i.e. scores) used to evaluate the algorithm performance in this section are somewhat arbitrary. As a general rule, any metric should measure a better performance if more spectra are classified correctly.
In this regard, an element of the test set that undergoes a classification process falls into one of the following categories.
-
True Positive, TP. The element is a class i member and is correctly classified.
-
False Positive, FP. The element is not a class i member, but it is classified as belonging to class i.
-
False Negative, FN. The element is a class i member but is not correctly classified as such.
-
True Negative, TN. The element is not a class i member, and it is not classified as belonging to class i.
It is possible to define the classification performance using two or more of these sets.
A possible definition of performance is provided by the a priori classification score, here referred to as PRISCO:
where TP(i) is the number of class i true positives and FP(i) is the number of class i false positives. The PRISCO is known as hit rate in the literature (see Wilks, 2006). This score ranges between 0 and 1. It is maximised for FP(i)=0, occurring when all the spectra classified by the algorithm as class i actually belong to class i.
This score can be viewed as an a priori probability, i.e. the likelihood that a spectrum labelled as a member of class i actually belongs to class i:
where is the fraction of spectra labelled as class i, and is the fraction of spectra belonging to class i. The variable CTE represents the number of elements of the test set.
The a posteriori probability, i.e. the likelihood that a spectrum belonging to class i is correctly classified by the algorithm, is defined by the classification score here called POSCO:
where FN(i) is the number of class i false negatives. This score is useful to estimate the percentage of correctly classified spectra per each class: in fact, the sum of class i true positives and false negatives (TP(i)+FN(i)) is equal to the total number of class i spectra.
The two scores are complementary and are related by the following equation:
In this paper, detection performance (DP) is defined as the minimum value of the two PRISCO scores relative to the classes under examination:
where
The PRISCO is preferred to POSCO since no a priori assumption can be made about class membership when classification is performed on real data. In the definition of the detection performance the minimum PRISCO value is chosen because the classification performance is considered high only if hit rates for both classes are high.
In this section the performance of the CIC cloud detection algorithm is evaluated for multiple atmospheric conditions. The additional information content of the FIR part of the spectrum is also studied. Classifications are performed both by using the mid-infrared (MIR) channels only or by using channels spanning over the full FORUM spectrum (FIR + MIR).
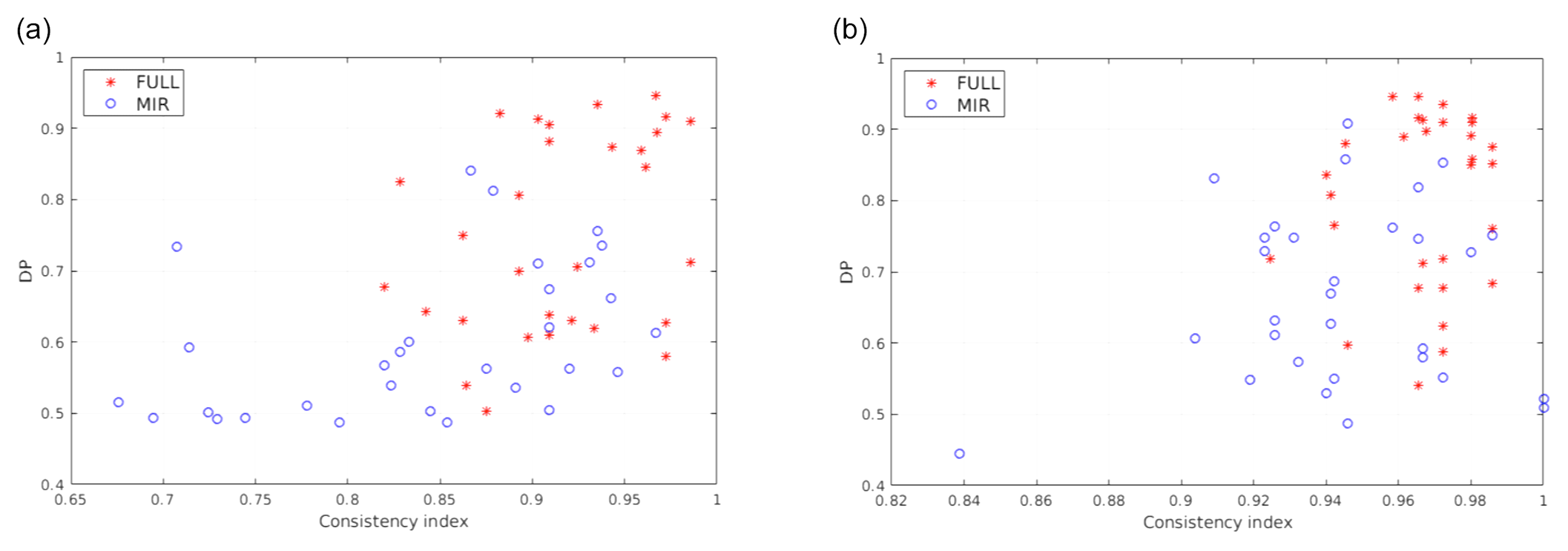
Figure 9Scatterplots relating the consistency index (CoI) and detection performance (DP) for multiple tropical training set pairs (clear and cloudy). CIC results are shown for both the elementary (a) and the distributional approach (b). Blue circles represent classification results obtained using features in the MIR only, while red stars represent classification results exploiting the full spectrum.
A first result is anticipated in Fig. 9; the details of the computations will be described in the next paragraph. Multiple couples of training sets (clear and cloudy), made up of 100 elements in total for each couple, are used to perform a classification applied to the simulations for the tropical case. For each training set (60 in the example), CIC is applied and the consistency index and the detection performance are computed and plotted as scatterplots. This allows the relation of the final classification scores (evaluated by DP) with the composition of the training set (whose characterisation is associated to the CoI). The CIC algorithm is run using both the MIR only or the full spectrum: 129 channels in the FIR and 129 in the MIR. The selected channels range in the [371.1–1300] cm−1 interval and are selected with a fixed sampling except for a small interval at around the 667 cm−1 ν2 vibrational CO2 band that is not used. Results show that the scores (indicated by DP) are generally larger when the full spectrum is exploited. In fact, it is computed that the average values of the DP move from 0,60 to 0.79 (for the elementary approach, Fig. 9a) and from 0.67 to 0.86 (for the distributional approach, Fig. 9b) when using features from the full FORUM spectra instead that those from the MIR only.
These preliminary computations suggest the following conclusions.
-
Better results are obtained for the distributional approach (Fig. 9b) with respect to the elementary one (Fig. 9a).
-
A correlation between the CoI and the DP exists.
The points above are taken into account in order to maximise the performances of the CIC algorithm when applied to a test set. In particular, it is suggested that the distributional approach is preferred over the elementary one and that an optimal training set can be arranged before the classification is actually performed since CoI is computed for training set elements.
Thus, a strategy for the application of CIC to the synthetic dataset is defined and the evaluation of the information content in the FIR is planned.
-
A reference training set (called RETS and consisting of a clear and a cloudy training set) is defined using an optimisation methodology based on the CoI values. The RETS is used as a reference to perform a test set classification with a variable number of features.
-
The performance of the algorithm is studied when using features from the MIR only or when exploiting also an increasing number of FIR channels up to cover the full FORUM spectrum.
4.1 Reference training set (RETS)
In this paragraph, a strategy for the definition of an optimised reference training set, RETS (intended as a set of clear and a set of cloudy spectra), is outlined. The optimisation applies when the training set elements are randomly chosen from a large subset of the whole dataset. Results could be different if training set elements are manually selected in order to cover the natural variability of the cloudy- and clear-sky spectra encountered for each latitudinal belt and season.
The strategy is based on the correlation between CoI and the CIC performances (measured by the DP parameter). As stated above, the CoI measures how well the training set elements would be classified if they were part of the test set.
For simplicity, only the CIC applications to the tropical dataset are reported in this section but the same process is also applied to mid-latitudes and polar cases (not shown). The tropical dataset includes 352 clear-sky and 817 cloudy-sky spectra, for a total of 1169 spectra. Out of these, 315 are used as a test set. The other spectra are exploited to define multiple training sets: 100 elements at a time for each training set pair (clear and cloudy). This strategy is followed in order to have multiple training sets with different combinations of spectra. Of course the optimisation process is particularly important when there are many spectra that need to be classified. The operation is also important in reducing computational cost (see Sect. 4.4). In fact, the TREM matrices and the SID distribution of the optimised training set can be saved in a file, reducing the running time of both the elementary and the distributional approach.
The training set elements (100 per each training set pair) are randomly chosen from a set of 854 simulations in clear and cloudy sky but with a constraint on the number of clear and cloudy components. Three different training set number configurations (TraNCs) are used:
A total of 20 different training sets are constructed for each TraNC. Both an elementary and a distributional-approach-based classification are provided for each training set.
CIC is run on the test set elements and a binary classification (each element is classified clear or cloudy) is performed by exploiting the full spectrum. The scores (and DP) are computed. The results are presented in Fig. 10 where the DP is plotted as a function of the CoI.
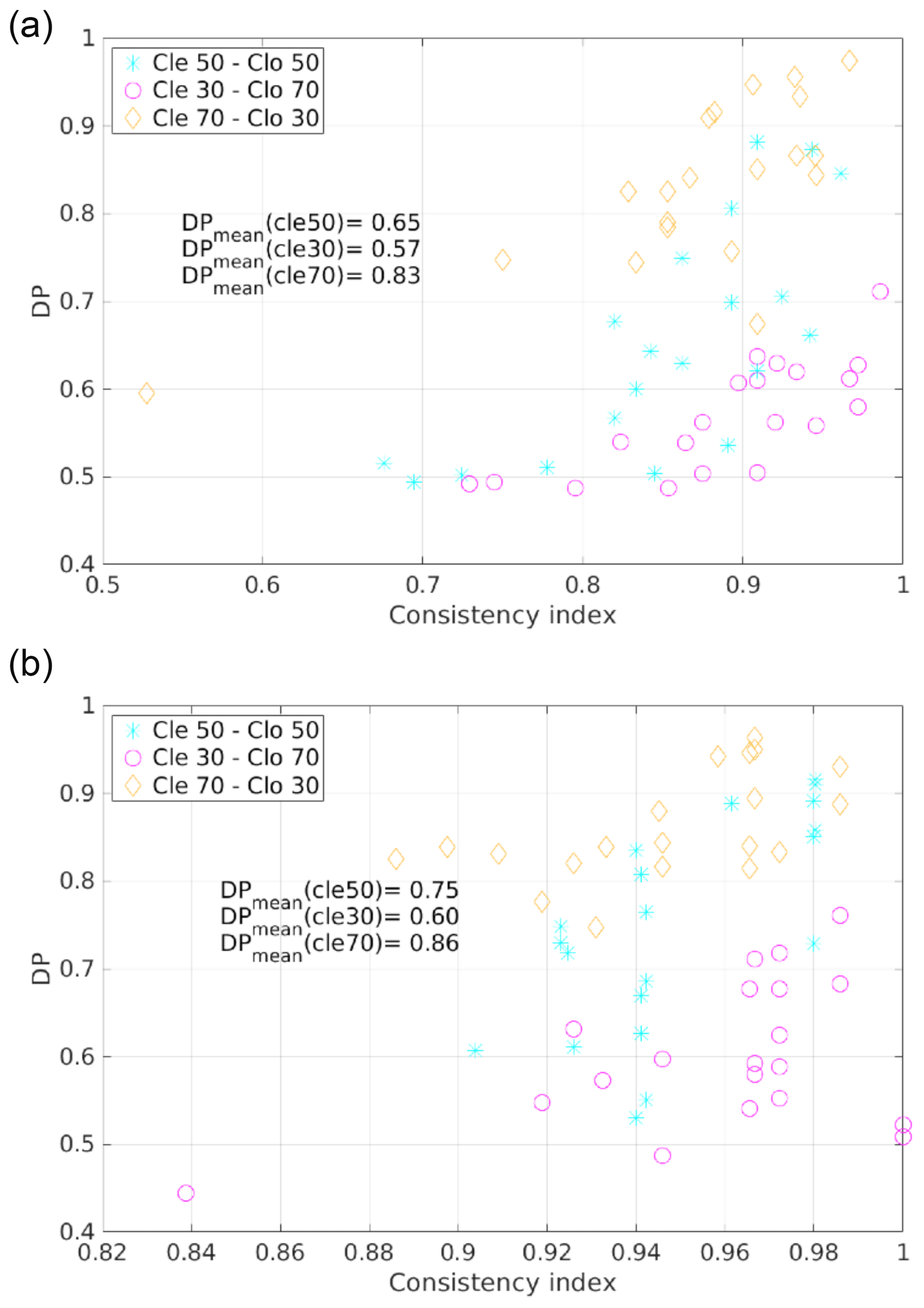
Figure 10Scatterplot of DP and CoI for multiple training sets (grouped into the three TraNC reported in the legend). Results are shown when using both the elementary approach (a) and the distributional approach (b). For each group an average value of the DP is computed and reported in the plot.
On average, the most accurate performances are obtained for TraNCs in which Tcle is larger than Tclo. The worst results are obtained for Tclo greater than Tcle. The average DP values for the three groups of TraNCs are reported in the plots of the figure.
Figure 10 shows that a correlation exists between the DP and CoI in the sense that, on average, large values of DP are obtained for large values of CoI. It is also shown that, on average, the DP computed using the distributional approach is larger than for results obtained using an elementary approach.
This correlation is significant because it is observed even when CIC computes these two parameters totally independently, i.e. when the elementary approach is followed. For this reason the CoI can be used as a performance forecasting parameter, i.e. a parameter estimating the quality of the classification. Nevertheless, a quantification of the performances cannot be provided a priori from the application of the algorithm since it also depends on the spectra of the test set to be analysed.
If a positive correlation between the DP and the CoI is assumed to exist, then the best performances are expected for training sets with the highest CoIs. For this reason, the RETS is defined as the training set with the highest CoI among those considered. In our case, the best performing training set is composed of 70 clear-sky and 30 cloudy-sky spectra.
The above configuration is selected as the tropical RETS to be used in the analysis shown in the next paragraphs. Similarly, RETS for mid-latitudes and polar latitudes are constructed. The RETS for clear sky consists of a set of spectra able to catch the seasonal (and thermal) variability reported in the synthetic dataset which is created to reproduce global conditions for all four of the seasons.
Table 4Number of cloudy spectra, as a function of cloud OD interval, for elements belonging to the cloudy set of the RETS and to the test set for the tropical case. In the second column, in parentheses, the percentage value with respect to the total number of elements in the test set for the same OD interval is reported.
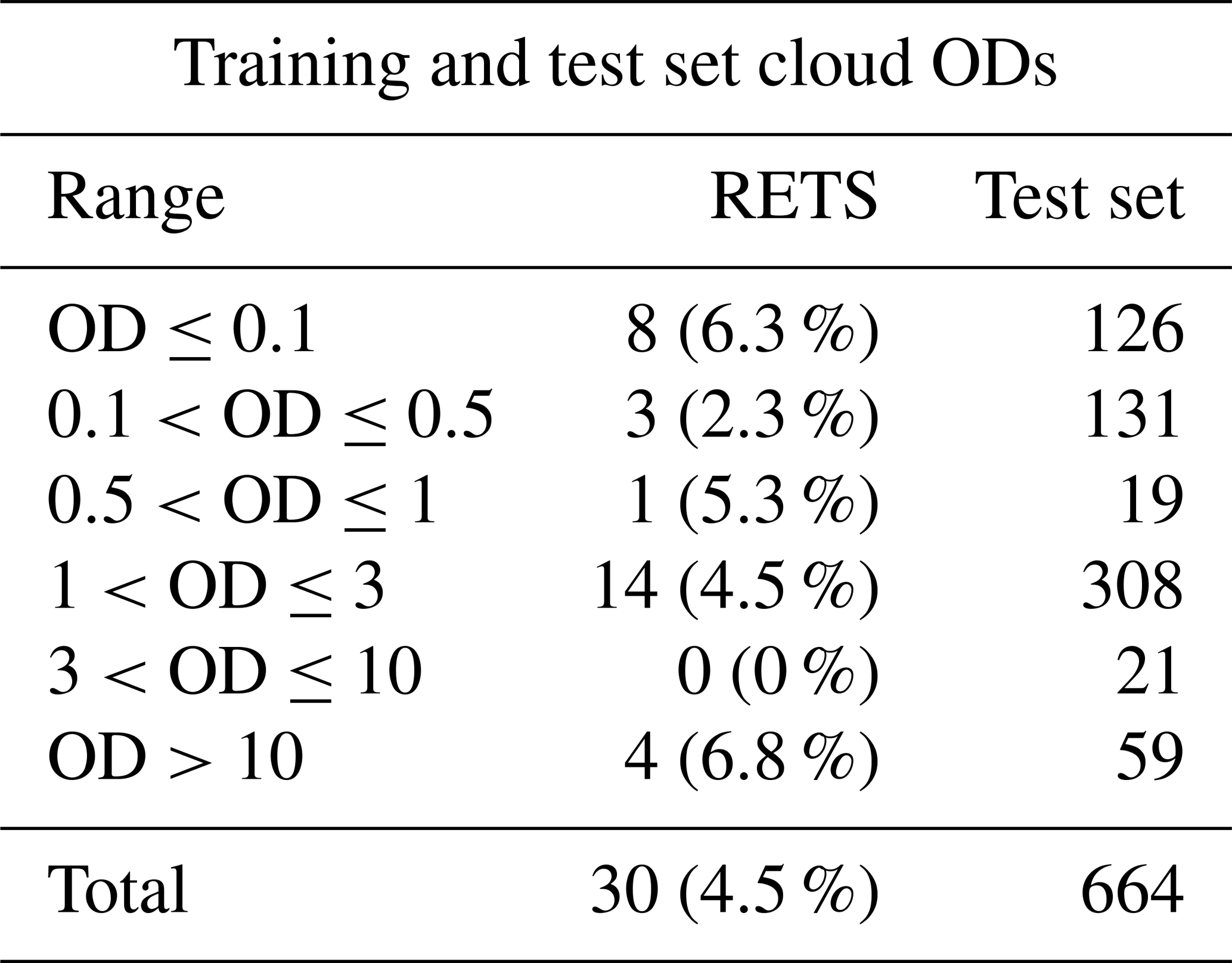
The cloud ODs accounted for in the cloudy RETS for the tropics range from 0.05 to 21.8, while the test set ranges from 0.02 to 23; the RETS's ice cloud top heights range from 9 to 16 km, and in the test set they span from 4 to 16 km. A summary of the clouds OD used in the RETS for the tropical case is reported in Table 4. It is shown that a large number of elements consists of optically thin clouds. This choice was performed in order to challenge the CIC capability of detecting clouds in very difficult conditions.
4.2 Evaluation of FIR contribution to cloud identification
Multiple classifications using a variable number of features (FORUM channels) and accounting both for the full spectrum and the MIR only are performed. The classifications account for a fixed number of MIR channels, while the number of FIR channels changes to assess if the FIR part of the spectrum is capable of bringing additional information content that significantly improves the algorithm's performance.
In order to speed up calculation and to avoid channels with a low signal-to-noise ratio, the chosen MIR wave numbers only range from 667 to 1300 cm−1, while the FIR ranges from 100 to 640 cm−1. Thus, the full spectrum spans over the 100–1300 cm−1 spectral range with the exception of a limited wave number interval in the ν2 CO2 band centred at around 667 cm−1.
Channels are selected by using a constant sampling with no optimisation criteria applied. The number of selected channels in the FIR is defined by the following formula:
In this way, Nfeat spans over 2 orders of magnitude.
Table 5The lowest wave number as a function of the number of FIR channels. The sampling rate is constant and set equal to 2.1 cm−1. The highest FIR wave number is equal to 639.9 cm−1.
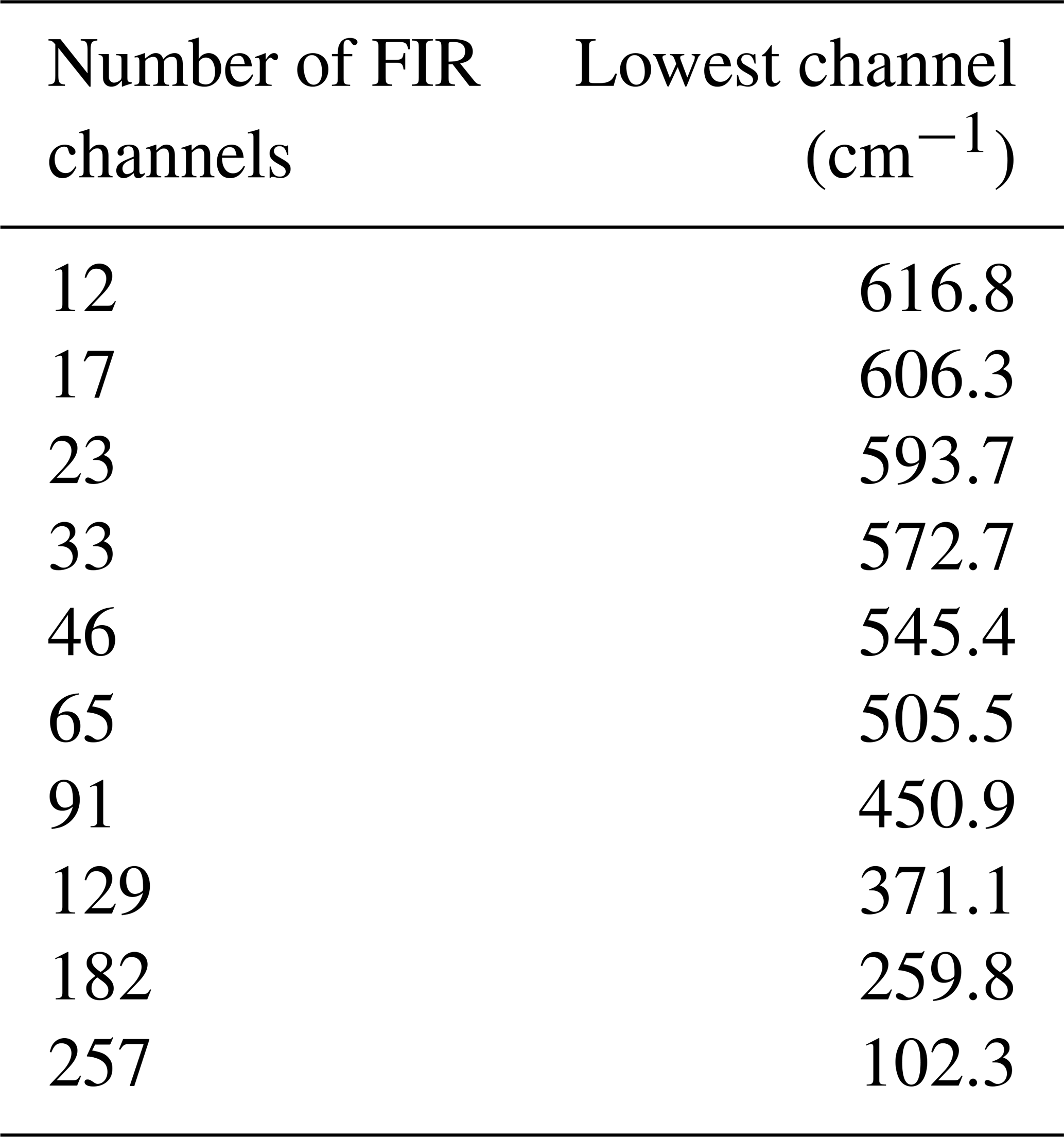
In Table 5 the number of features used in the FIR is reported. The upper (starting) channel in the FIR is at 639.9 cm−1 and the other FIR channels are sampled toward smaller wave numbers every 2.1 cm−1. Thus, the data reported in the table should be interpreted as follows: 12 channels means that 12 channels between 639.9 and 616.8 cm−1 are accounted for and the same is true with the other larger numbers of channel until they cover the full FIR part of the spectrum.
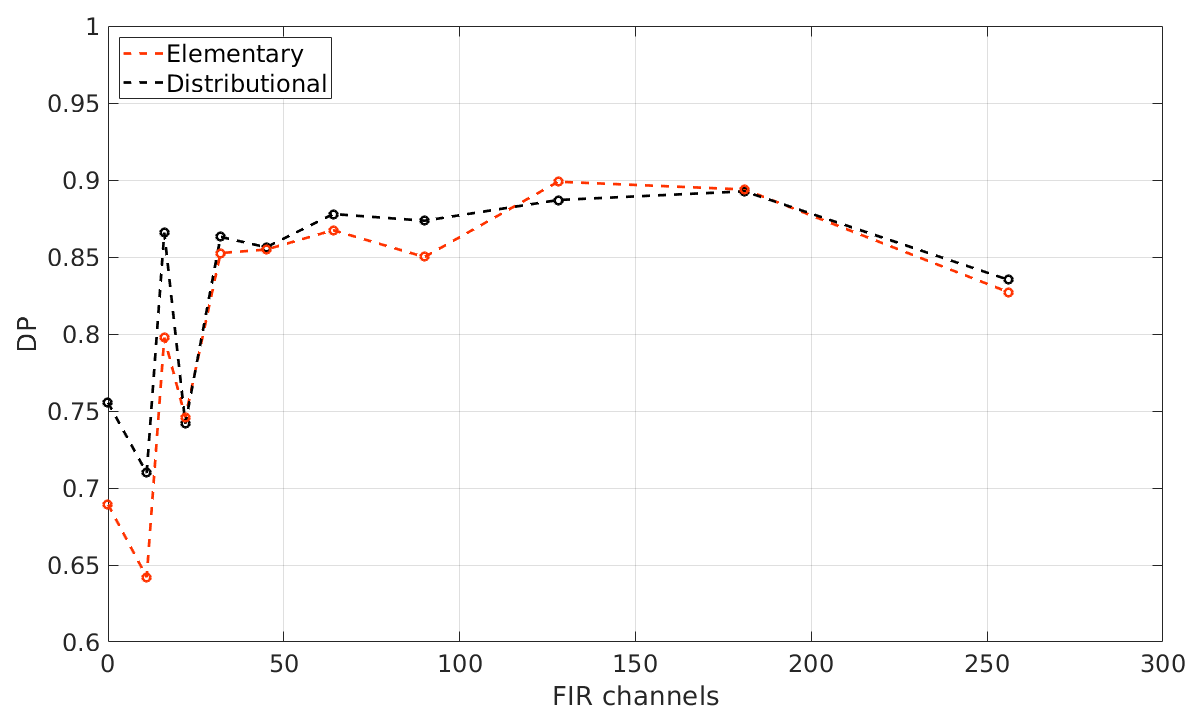
Figure 11CIC cloud detection performance as a function of the number of FIR features (channels) for the tropical case. A total of 256 MIR channels are used. The black and red dots indicate the distributional and elementary approach, respectively.
In Fig. 11, the results obtained for 11 different classifications are shown in terms of detection performance. DP is plotted as a function of the number of FIR features used in the classification applied to the tropical case. At the value 0 on the x axis of the figure, only the MIR part of the spectrum is accounted for (256 channels in this case), while in the other 10 cases the FIR part of the spectrum is also exploited with an increasing number of channels, indicated by the x axis values.
Results show that performance gradually improves for increasing numbers of FIR channels. In particular, there is a slight decrease in performance after adding the 12 channels closest to the CO2 ν2 band centre that are mostly insensitive to cloud parameters due to strong absorption of the carbon dioxide. The decrease is gradually offset by improvements obtained when channels in the [238.8–545.4] cm−1 wave number range are added. The DP slightly decreases if channels in the [102.3–238.8] cm−1 range are included probably due to a reduced radiance sensitivity to surface and cloud features at those wave numbers.
In the classifications, both the distributional approach (black line in the figure) and the elementary approach (red line) are followed. For the tropical case, the elementary and distributional approach provide DPs as high as 0.9. Note that both methodologies take advantage of the optimised selection of the RETS and that the information content critical for DP improvements derives from channels spanning the [238.8–545.4] cm−1 range.
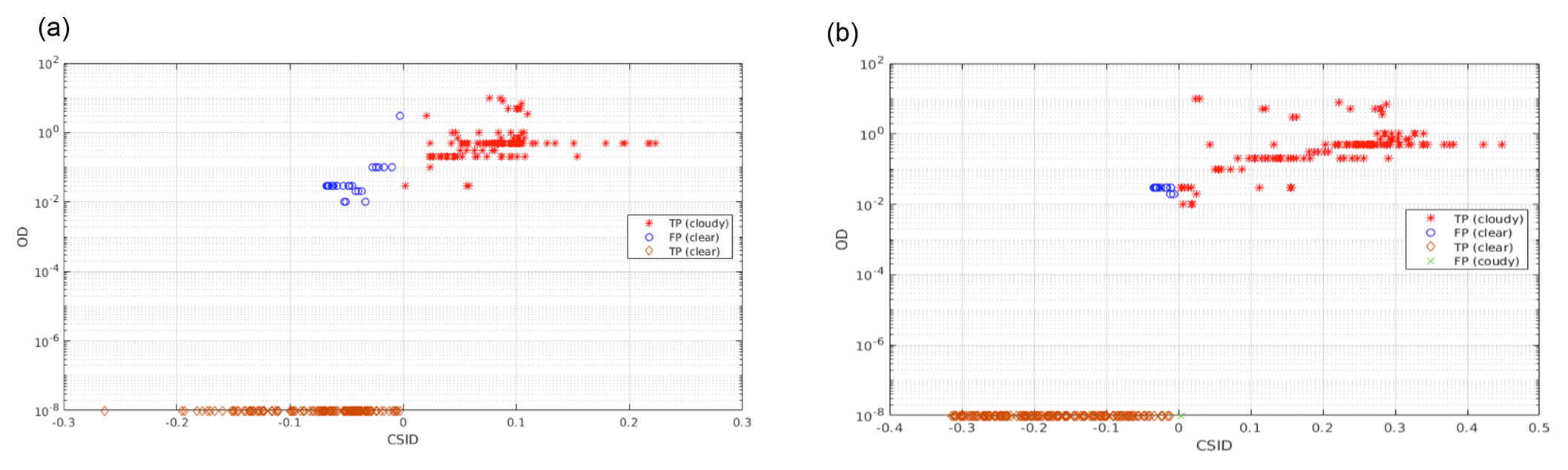
Figure 12Classification of the tropical test set as a function of the optical depth of the elements (a value of 10−8 is used to plot the clear-sky cases). Data are plotted as a function of the corrected similarity index difference (CSID) and cloud optical depth (OD). (a) CIC run using 128 MIR channels. (b) CIC run using the 128 MIR and 129 FIR channels. For both cases the distributional approach is assumed. Colour codes are reported in the legend.
In Fig. 12, the cloud detection of the tropical test set is plotted to the function of the CSID value and cloud optical depth. Two classifications are performed: one using the MIR (Fig. 12a) and another using the full spectrum (Fig. 12b). The number of MIR channels used in the process is kept the same (128) for both configurations. The considered FIR channels, when using the full spectrum, are 129 and span from 371.1 to 639.9 cm−1. For visual purposes the plotted clear-sky test set elements are associated to , while all the other OD values are for cloudy sky. Results shown in Fig. 12 are obtained using the RETS.
True positives (correct classification) for clear and cloudy spectra are, respectively, orange circles and red asterisks. False positives are blue circles for clear spectra and green asterisks for cloudy spectra. Figure 12a shows that the number of misclassified cloudy spectra grows for decreasing optical depth when using the MIR only. Clear-sky cases are all well classified in this configuration. If CIC is run exploiting the full spectrum (Fig. 12b) the overall detection performance is enhanced even if a clear-sky case is misclassified (green cross). Nevertheless, most cirrus clouds are now correctly classified, with the exception of only few cases with an optical depth of less than 0.5. Note that the DP value is the minimum between the hit rate computed for cloudy-sky cases and clear-sky cases (see Eq. 24) and thus is indicative of the CIC ability to correctly classify either clear and cloudy spectra.
4.3 Mid-latitudes and polar regions
The CIC code is applied to the mid-latitudes and polar datasets to test the algorithm performances in different atmospheric conditions. The results obtained using the MIR only and using the full spectrum are again compared. Since detection performances are dependent on the analysed datasets (test sets) the results cannot be interpreted in an absolute sense but only in reference to the configuration parameters.
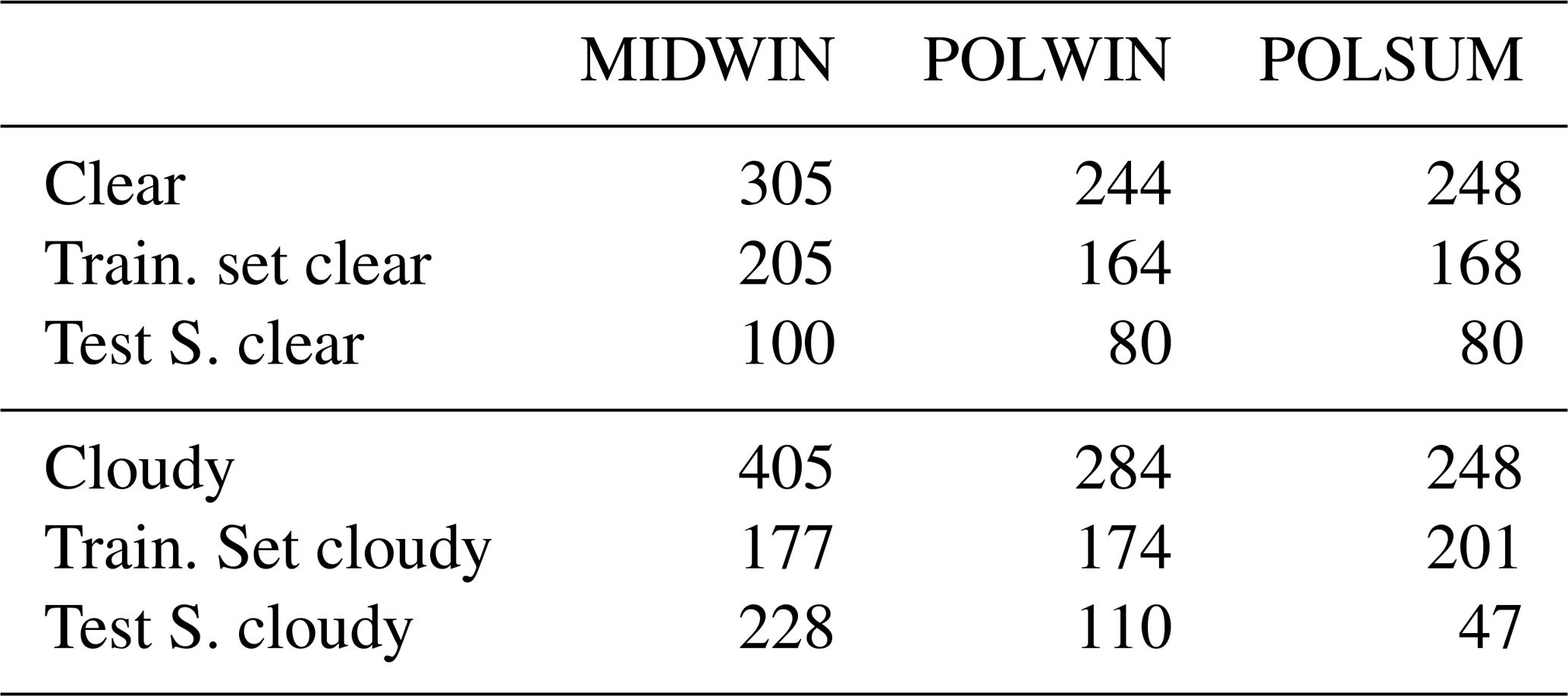
Mid-latitude winter (MIDWIN), polar winter (POLWIN) and polar summer (POLSUM) cases are presented. The TraNCs used are generated with the same methodology outlined for the tropical case; thus, they are composed of 70 clear-sky spectra and 30 cloudy-sky spectra randomly chosen from a large subset of the full dataset. Spectra used to define the training sets are not inserted in the test set. In Table 6 a summary of the total number of clear and cloudy spectra for each case study is provided. In the table the number of clear and cloudy simulations used for defining the training sets and for the test sets is also reported.
Table 6MIDWIN, POLWIN, and POLSUM datasets. For clear and cloudy conditions the table columns report the total number of simulations (spectra), the number of spectra used to define the training sets and the number of cases used as test sets.
The capability of extracting information content from the FIR is evaluated by applying the same procedure as before (see Sect. 4.1 and 4.2).
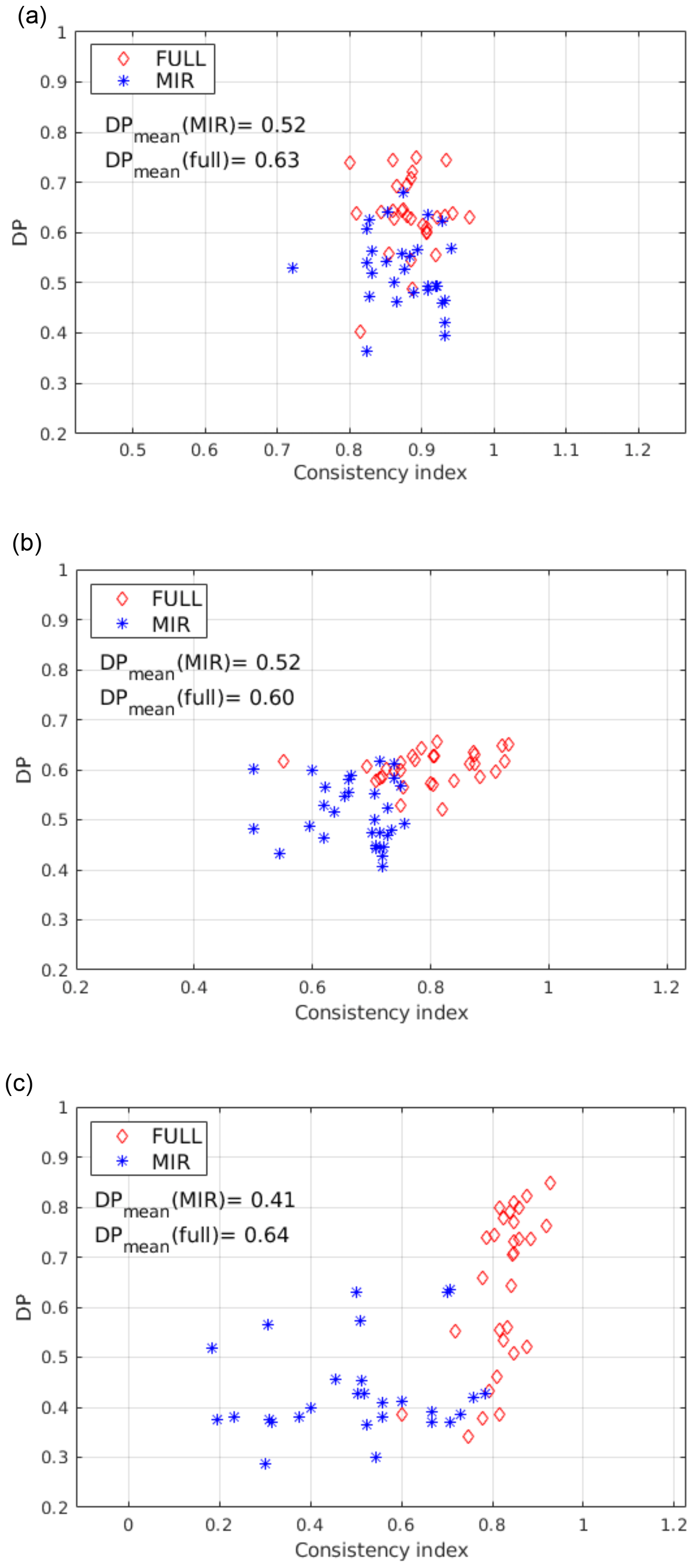
Figure 13Clear and cloudy classification DP using the distributional approach for the MIDWIN case (a), the POLWIN case (b) and POLSUM (c). Data are plotted as function of CoI, and 60 TraNC are used for each case.
Classification results obtained using 60 different training sets are shown in Fig. 13 for the three considered cases (MIDWIN, POLWIN and POLSUM, respectively, from Fig. 13a, b and c). Only results using the distributional approach are presented since CIC, on average, produces higher scores when run in this configuration.
It is shown that the classification scores increase by adding FIR channels to the MIR ones; average DP values are reported in the plots. However, the correlation between CoI and DP is less significant for the present cases with respect to what was found for the simulations in the tropics. The DPs obtained for the MIDWIN, POLWIN, and POLSUM cases are also lower than the ones obtained for the tropical case. This result might be caused by the mean larger temperature differences between high tropical cirrus clouds and the surface with respect to what found for mid-latitude and polar cases. It should be also considered that the polar regions (especially in winter season) present surface features (ice and snow on the ground) that have radiative properties similar to ice clouds, thus making the clear or cloudy identification extremely challenging, in particular when analysing a test set containing a large number of thin cirrus clouds.
The POLSUM case (Fig. 13c) show an evident correlation between the DP and CoI when the full spectrum is accounted for. Moreover, in this case, DP values are on average larger than 0.7 when CoI are larger than 0.85. Therefore, a RETS is chosen for this case to be used in testing the ability of CIC to correctly classify clouds with different optical depths. In Fig. 14 all the cloudy cases present in the POLSUM test set are classified using features in the MIR only or from the full FORUM spectrum. Results of the classification are plotted as a function of the CSID and of the cloud optical depth. It is noted that the majority of the cloudy cases (also for optically thick clouds) are missed by CIC when relying on MIR channels only (Fig. 14a). The scores improve significantly when the full spectrum is accounted for (Fig. 14b). Nevertheless, optically thin clouds (mostly sub-visible cirrus clouds with OD<0.03) are still misclassified. The misclassified cases do not show any relation with the type of polar surfaces accounted for in the simulations (fine snow, medium snow, coarse snow or ice).
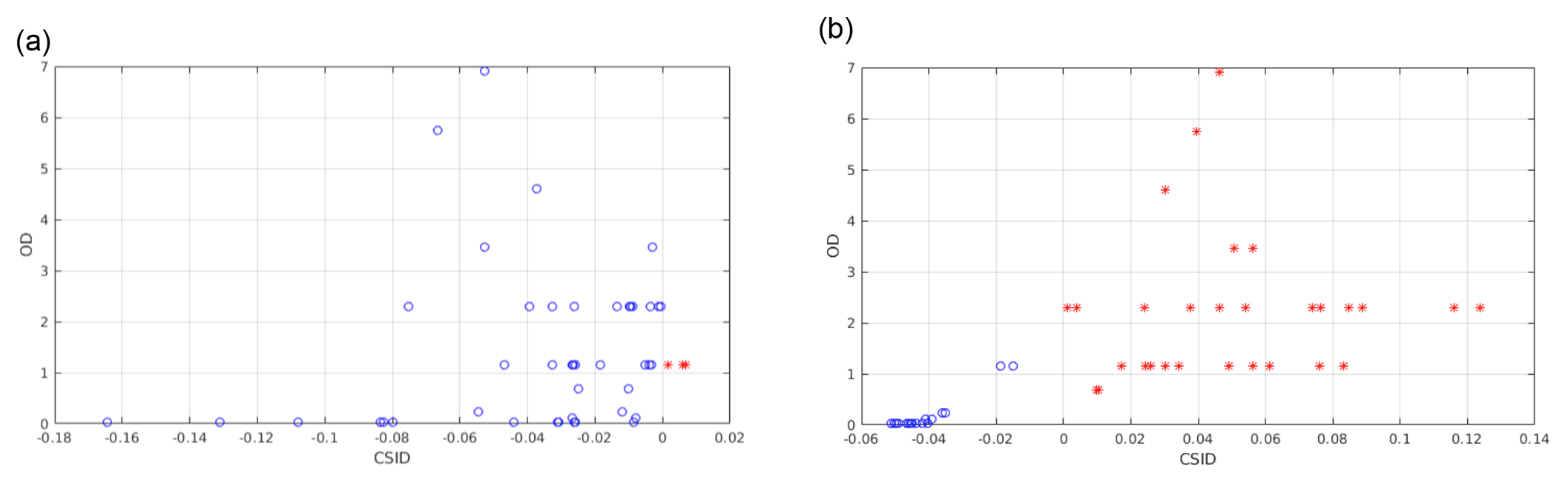
Figure 14Correctly classified (red asterisks) and misclassified (blue circles) cloudy-sky spectra from the polar summer (POLSUM) test set. Data are plotted as a function of the corrected similarity index difference (CSID) and cloud optical depth (OD), and the distributional approach is considered. In panel (a) only the MIR features are accounted for while in panel (b) the full spectrum is exploited in the classification.
4.4 Computational time
In this section, a study of the computational time required to calculate the CoI is performed. The CoI computational time is a good indicator of the speed of the core algorithm, since its computation requires the SI computation of all training set elements and the additional optimisation needed for the distributional approach. Moreover, the CIC classification subroutine is the only core routine with a duration that depends on the number of features used for the classification. The current version of CIC algorithm is implemented in the MATLAB programming language (https://www.mathworks.com/products/matlab.html, last access: 21 June 2019).
When the elementary approach is selected, the CoI computation is not necessary. For this reason, the sensitivity study made in this section can also be interpreted as a study of the distributional-approach computational cost and results represent an upper limit of the computational time for a classification process in any configuration.

Figure 15CoI computational time (a) and SI computational time (b) as functions of training set size (Ttot) and of the number of features used (Nfeat). A non-linear relationship between the variables is observed.
In Fig. 15a results concerning the computational time of CoI as a function of the number of features (Nfeat) and of the number of training set elements (here indicated with ) are reported. Times are referred to computations performed on a machine with a Intel i5 processor (four cores) and 4 GB RAM. It is shown that the computational time increases non-linearly with Nfeat.
The algorithms for solving linear algebra problems cannot have a linear time complexity (computational complexity describing the time to run the algorithm). Raz (2003) shows than a lower bound for time complexity of matrix multiplication is 𝒪(n2log (n)) and Demmel et al. (2007)) demonstrated that the same time complexity bound applies to most other linear algebra problems, including eigenvector computation, as performed by CIC.
CoI computation consists of three main subroutines: factor indicator function computation and its minimisation (see Eq. 8), the SI computation (see Eq. 7), and shiftopt determination (Eq. 17). Among the three, the computational cost of the SI is the highest, since the other two only perform a limited and fixed number of cycles involving simple arithmetic operations. This subroutine computes the similarity indices for all Ttot training set elements. SI computation requires the costly calculation of the TREM matrices (see Eq. 3). TREM matrices need covariance computation, whose time complexity is , and eigenvector computation, whose time complexity is . Therefore, SI computation has an approximate time complexity of . The results of the computation of the SI parameter as a function of Ttot and for different numbers of Nfeat are reported in Fig. 15b.
The running time of the remaining two routines (the one that computes the indicator function minimisation and the one that finds the shiftopt parameter) is very limited and less than 0.3 s for any of the configurations accounted for Nfeat and Ttot.
Note that the Fourier transform spectrometer of the FORUM mission will perform one measurement about every 12 s (as stated in the FORUM proposal for Earth Explorer Mission EE-9 “Fast Track” Earth Observation Envelope Programme June 2017), and thus the CIC algorithm could be run operatively on mission data.
A new methodology for cloud spectra detection and classification (named cloud identification and classification, CIC) is presented. CIC is a very fast machine learning algorithm based on principle component analysis that depends on a limited number of user-defined free parameters.
The algorithm exploits a training set composed of two groups of spectra (each group is a class). The training set elements should represent the observed variability within the classes and thus should include a sufficient number of spectra capable of characterising the radiative features encountered in the area of study. At the same time, they should be “sensitive” to the addition of new elements with spectral characteristics that are not present in the training set groups. Typically a total number of 100 spectra is sufficient to well characterise the clear-sky and cloudy-sky training set groups for each latitudinal belt (tropics, mid-latitudes, poles) and season. Mathematically the algorithm evaluates the similarity of each test set spectrum with each class and thus provides a classification. CIC, firstly, computes the eigenvectors of the covariance matrix of each training set class. Secondly, a test set element is analysed by adding it to each training group (the clear and cloudy sky). The new eigenvectors of the extended covariance matrix (formed by the training set elements of one class plus the test set element) are computed. An index of similarity is derived for the test set spectrum with respect to the two groups of the training set. It is assumed that a clear-sky spectrum, added to the set of spectra defining the clear-sky training set, does not significantly modify the group's principal components while some significant modifications will be detected if the clear-sky spectrum is added to the cloudy-sky training set. The opposite is true for a cloudy-sky spectrum of the test set. Similarity indexes are thus defined to quantify the modification of the principal components of the training set when a new element (of the test set) is added. Based on these indexes, the element is associated to one of the two considered classes.
CIC can be run by adopting two approaches: the elementary or the distributional approach. The first one is more intuitive and straightforward: the classification for each test set spectrum is done by comparing the similarity indexes computed with the two classes of the training set. The second one requires an additional a priori optimisation process, at very low computational extra cost (Sect. 4.4). The optimisation is based on the definition of the consistency index (CoI) that is related to the detection performance of the algorithm applied to the training set itself. Therefore, if the training set represents natural variability sufficiently well, the CoI serves as a performance forecaster. When optimisation is applied, higher scores are obtained, as measured by the increased detection performance (DP; see Sect. 4) parameter that can reach values as high as 0.95.
The CIC is tested against a large synthetic dataset computed to simulate high spectral resolution radiance from satellite, specifically as possibly observed by the Earth Explorer Fast Track 9 candidate mission FORUM (Far-Infrared Outgoing Radiation Understanding and Monitoring). The measured FORUM radiance covers the 100–1600 cm−1 spectral bands (thus including the under-explored far-infrared part of the spectrum) with a nominal spectral resolution of 0.3 cm−1 and a goal noise of 0.4 in the 200–800 cm−1 interval and 1 on the outside. The simulations are performed by using multiple surface properties, atmospheric profiles and different cloud features for liquid, mixed-phase, and ice clouds (including multiple ice habits). Simulations show that the far-infrared part of the spectrum is particularly sensitive to many atmospheric parameters, such as upper tropospheric temperature and water vapour and to cloud geometrical and microphysical properties.
The dataset is divided in subsets in accordance with the latitudinal belt (and season for the mid-latitudes) and the CIC is applied by accounting for different configurations. Results show that the CoI can be used to optimise the training set and that, statistically, the distributional approach performs better than the elementary one. The code is also used to assess the additional information content derived from the analysis of the far-infrared part of the spectrum with respect to the mid-infrared only. In this regard, it is shown that the overall detection performances increase when the radiance spectra in the far infrared are accounted for. In particular, the radiance exiting at 238–545 cm−1 improves the cirrus detection performances in almost all the atmospheric conditions (latitudinal belt and season). Very thin cirrus clouds (i.e. sub-visible cirrus) are better detected when exploiting the full FORUM spectrum than the mid-infrared part of the spectrum only. The hit scores for cirrus clouds with an optical depth less than 0.06 moves from about 25 % when using the mid-infrared only to about 60 % when exploiting also the FIR part of the spectrum. It is shown that, in tropical regions, the overall detection performances exploiting the full spectrum can be very high (higher than 0.9 for the present dataset, which is very challenging for the large presence of sub-visible cirri) when the appropriate training set is selected. It is finally noted that clear and cloudy spectra identification performances decrease when moving from the tropics to the poles, mostly due to the decreased sensitivity of cloudy spectra because of the colder atmospheric and surface temperatures and the increased similarities in the surface and cloud radiative properties.
In the present work, CIC functionalities are illustrated for cloud detection application in presence of high spectral resolution far- and mid-infrared radiance observations. Nevertheless, the same algorithm can, in principle, be implemented to work with different kinds of data (i.e. low spectral resolution data) and also to perform sub-classifications, such as cloud-phase identification. The CIC algorithm is easily adaptable to different viewing geometries and diverse high spectral resolution sensors. Currently, it is being tested against interferometric data in the far- and mid-infrared parts of the spectrum collected by the airborne Tropospheric Airborne Fourier Transform Spectrometer (TAFTS, Canas et al., 1997) and the Airborne Research Interferometer Evaluation System (ARIES, Wilson et al., 1999) during the 2015 CIRCCREX (Cirrus Coupled Cloud-Radiation Experiment) campaign (Pickering et al., 2015) and ground-based data collected by the REFIR-PAD interferometer since 2012 from the Dome C (Concordia) station on the Antarctic Plateau (http://refir.fi.ino.it/refir-pad-domeC, last access: 21 June 2019).
The CIC source code version used in the present paper is available by request from Iacopo Sbrolli, who is the software developer of the algorithm. Advanced versions of the code are available on request to the corresponding author.
| BT | Brightness temperature |
| CoI | Consistency index |
| CIC | Cloud identification and classification |
| CSID | Corrected similarity index difference |
| DP | Detection performance |
| ETR | Extended training set |
| ETREM | Extended training set eigenvector matrix |
| FIR | Far infrared |
| FN | False negative |
| FP | False positive |
| FORUM | Far-infrared Outgoing Radiation Understanding and Monitoring |
| IBEC | Information-bearing principal component |
| IG2 | Initial guess database no. 2 |
| ILS | Instrumental line shape |
| IND | Indicator function |
| LbLRTM | Line-by-line Radiative Transfer Model |
| MIDWIN | Mid-latitude winter |
| MIR | Mid-infrared |
| MT_CKD | Mlawer, Tobin, Clough, Kneizys and Davies water vapour continuum model |
| NESR | Noise-equivalent spectral radiance |
| OD | Optical depth |
| PCA | Principal component analysis |
| POLSUM | Polar summer |
| POLWIN | Polar winter |
| POSCO | A posteriori classification score |
| PRISCO | A priori classification score |
| RE | Real error |
| REFIR-PAD | Radiation Explorer in the Far InfraRed: Prototype for Applications and Development |
| RETS | Reference training set |
| RFTS | REFIR Fourier transform spectrometer |
| RTX | Radiative transfer X |
| TN | True negative |
| TP | True positive |
| TR | Training set |
| TraNC | Training set number configuration |
| TREM | Training set eigenvector matrix |
| TROSUM | Tropical summer |
| TROWIN | Tropical winter |
| SI | Similarity index |
| SID | Similarity index difference |
The structure of the work was implemented by all of the authors. TM and IS defined the methodology. IS implemented the algorithm in MATLAB and performed the classification tests. WC took care of the sensitivity studies. TM took responsibility for writing the paper.
The authors declare that they have no conflict of interest.
The present work is in preparation for the FORUM mission. FORUM-related studies are supported by projects of the Italian Space Agency (ASI) and of the European Space Agency (ESA).
This work has been financed by the ESA contract for the “End to End (E2E) Simulator for FORUM – Earth Explorer 9 Fast Track Candidate Mission”. Reference for State of Work: EOP-8MP/2017-12-2053, issue 1, revision 0, dated 10 January 2018.
This paper was edited by Lars Hoffmann and reviewed by two anonymous referees.
Adhikari, L., Whang, Z., and Deng, M.: Seasonal variations of Antarctic clouds observed by CloudSat and CALIPSO satellites, J. Geophys. Res.-Atmos., 117, D04202, https://doi.org/10.1029/2011JD016719, 2012. a
Ahmad, A.: Cloud Masking for Remotely Sensed Data Using Spectral and Principal Components Analysis, Engineering, Technology and Applied Science Research, 2, 221–225, 2012. a
Amato, U., Lavanant, L., Liuzzi, G., Masiello, G., Serio, C., Stuhlmann, R., and Tjemkes, S. A.: Cloud mask via cumulative discriminant analysis applied to satellite infrared observations: scientific basis and initial evaluation, Atmos. Meas. Tech., 7, 3355–3372, https://doi.org/10.5194/amt-7-3355-2014, 2014. a
Bozzo, A., Maestri, T., and Rizzi, R.: Combining visible and infrared radiometry and lidar data to test simulations in clear and ice cloud conditions, Atmos. Chem. Phys., 10, 7369–7387, https://doi.org/10.5194/acp-10-7369-2010, 2010. a, b, c
Bromwich, D., Nicolas, J., M Hines, K., Kay, J., L Key, E., Lazzara, M., Lubin, D., Mcfarquhar, G., Gorodetskaya, I., Grosvenor, D., Lachlan-Cope, T., and Lipzig, N.: Tropospheric clouds in Antarctica, Rev. Geophys., 50, 2011RG000363, https://doi.org/10.1029/2011RG000363, 2012. a
Canas, T. A., Murray, J. E., and Harries, J. E.: Tropospheric airborne Fourier transform spectrometer (TAFTS), Proc. SPIE 3220, Satellite Remote Sensing of Clouds and the Atmosphere II, https://doi.org/10.1117/12.301139, 1997. a
Clarisse, L., Coheur, P.-F., Prata, F., Hadji-Lazaro, J., Hurtmans, D., and Clerbaux, C.: A unified approach to infrared aerosol remote sensing and type specification, Atmos. Chem. Phys., 13, 2195–2221, https://doi.org/10.5194/acp-13-2195-2013, 2013. a
Clough, S. A., Shpehard, M. W., Mlawer, E., Delamere, J. S., Iacono, M. J., Cady-Pereira, K., Boukabara, S., and Brown, P. D.: Atmospheric radiative transfer modeling: a summary of the AER codes, J. Quant. Spectrosc. Ra., 91, 233–244, 2005. a, b
Dee, D., Uppala, S., Simmons, A., Berrisford, P., Poli, P., Kobayashi, S., Andrae, U., Alonso-Balmaseda, M., Balsamo, G., Bauer, P., Bechtold, P., Beljaars, A., van de Berg, L., Bidlot, J.-R., Bormann, N., Delsol, C., Dragani, R., Fuentes, M., Geer, A. J., Haimberger, L., Healy, S., Hersbach, H., Hólm, E. V., Isaksen, L., Kållberg, P., Köhler, M., Matricardi, M., McNally, A., Monge-Sanz, B., Morcrette, J.-J., Peubey, C., de Rosnay, P., Tavolato, C., Thépaut, J.-N., and Vitart, F.: The ERA-Interim reanalysis: Configuration and performance of the data assimilation system, Q. J. Roy. Meteor. Soc., 137, 553–597, https://doi.org/10.1002/qj.828, 2011. a
Demmel, J., Dumitriu, I., and Holtz, O.: Fast linear algebra is stable, Numer. Math., 108, 59–91, 2007. a
Evans, K. F. and Stephens, G. L.: A new polarized atmospheric radiative transfer model, J. Quant. Spectrosc. Ra., 46, 413–423, 1991. a
Eyre, J. R.: Inversion of cloudy satellite sounding radiances by nonlinear optimal estimation. I: Theory and simulation for TOVS, Q. J. Roy. Meteor. Soc., 115, 1001–1026, 1989. a
Hahn, C. J., Rossow, W. B., and Warren, S. G.: ISCCP cloud properties associated with standard cloud types identified in individual surface observations, J. Climate, 14, 11–27, 2001. a
Huang, X., Chen, X., Zhou, D. K., and Liu, X.: An observationally based global band-by-band surface emissivity dataset for climate and weather simulations, J. Atmos. Sci., 73, 3541–3555, 2016. a
Lachlan-Cope, T.: Antarctic clouds, Polar. Res., 29, 150–158, 2010. a
Lavanant, L. and Lee, A. C. L.: A global cloud detection scheme for high spectral resolution instruments, Proceeding of the fourteenth International TOVS Study Conference, Beijing, China, 2005. a
Maestri, T., Rizzi, R., Tosi, E., Veglio, P., Palchetti, L., Bianchini, G., Di Girolamo, P., Masiello, G., Serio, C., and Summa, D.: Analysis of cirrus cloud spectral signatures in the far infrared, J. Quant. Spectrosc. Ra., 141, 49–64, 2014. a
Maestri, T., Arosio, C., Rizzi, R., Palchetti, L., Bianchini, G., and Del Guasta, M.: Antarctic ice cloud identification and properties using downwelling spectral radiance from 100 to 1400 cm−1, J. Geophys. Res., 124, 4761–4781, 2019. a
Malinowski, E. R.: Factor Analysis in Chemistry, J. Chemometrics, 16, 635–635, https://doi.org/10.1002/cem.757, 2002. a, b
McNally, A. P. and Watts, P. D.: A cloud detection algorithm for high-spectral-resolution infrared sounders, Q. J. Roy. Meteor. Soc., 129, 3411–3423, 2003. a, b
Merrelli, A.: The Atmospheric Information Content of Earth's Far Infrared Spectrum, PhD thesis, University of Winsconsin-Madison, Madison, Winsconsin, 2012. a
Mlawer, E. J., Payne, V. H., Moncet, J. L., Delamere, J. S., Alvarado, M. J., and Tobin, D. C.: Development and recent evaluation of the MT_CKD model of continuum absorption, Philos. T. Roy. Soc. A, 370, 2520–2556, 2012. a, b
Palchetti, L., Di Natale, G., and Bianchini, G.: Remote sensing of cirrus cloud microphysical properties using spectral measurements over the full range of their thermal emission, J. Geophys. Res.-Atmos., 121, 10804–10819, 2016. a
Pavelin, E. G., English, S. J., and Eyre, J. R.: The assimilation of cloud affected infrared satellite radiances for numerical weather prediction, Q. J. Roy. Meteor. Soc., 134, 737–749, 2008. a
Peña, O. and Pal, U.: Scattering of electromagnetic radiation by a multilayered sphere, Comput. Phys. Commun., 180, 2348–2354, 2009. a
Pickering, J. C., Fox, C., Murray, J. E., and Last, A.: The Cirrus Coupled Cloud-Radiation Experiment: CIRCCREX, in: Fourier Transform Spectroscopy and Hyperspectral Imaging and Sounding of the Environment, p. JM3A.14, Optical Society of America, Lake Arrowhead, California, USA, paper JM3A.14, https://doi.org/10.1364/FTS.2015.JM3A.14, 2015. a
Raz, R.: On the Complexity of Matrix Product, Siam. J. Comput., 32, 1356–1369, 2003. a
Remedios, J. J., Leigh, R. J., Waterfall, A. M., Moore, D. P., Sembhi, H., Parkes, I., Greenhough, J., Chipperfield, M. P., and Hauglustaine, D.: MIPAS reference atmospheres and comparisons to V4.61/V4.62 MIPAS level 2 geophysical data sets, Atmos. Chem. Phys. Discuss., 7, 9973–10017, https://doi.org/10.5194/acpd-7-9973-2007, 2007. a
Rossow, W. B. and Schiffer, R. A.: Advances in Understanding Clouds from ISCCP, B. Am. Meteorol. Soc., 80, 2261–2287, 1999. a
Rothman, L., Gordon, I., Babikov, Y., Barbe, A., Benner, D. C., Bernath, P., Birk, M., Bizzocchi, L., Boudon, V., Brown, L., Campargue, A., Chance, K., Cohen, E., Coudert, L., Devi, V., Drouin, B., Fayt, A., Flaud, J.-M., Gamache, R., Harrison, J., Hartmann, J.-M., Hill, C., Hodges, J., Jacquemart, D., Jolly, A., Lamouroux, J., Roy, R. L., Li, G., Long, D., Lyulin, O., Mackie, C., Massie, S., Mikhailenko, S., Müller, H., Naumenko, O., Nikitin, A., Orphal, J., Perevalov, V., Perrin, A., Polovtseva, E., Richard, C., Smith, M., Starikova, E., Sung, K., Tashkun, S., Tennyson, J., Toon, G., Tyuterev, V., and Wagner, G.: The HITRAN2012 molecular spectroscopic database, J. Quant. Spectrosc. Ra., 130, 4–50, https://doi.org/10.1016/j.jqsrt.2013.07.002, 2013. a
Serio, C., Lubrano, A. M., Romano, F., and Shimoda, H.: Cloud detection over sea surface by use of autocorrelation functions of upwelling infrared spectra in the 800–900 cm−1 window region, Appl. Optics, 39, 3565–3572, https://doi.org/10.1364/AO.39.003565, 2000. a
Serio, C., Masiello, G., Esposito, F., Girolamo, P. D., Iorio, T. D., Palchetti, L., Bianchini, G., Muscari, G., Pavese, G., Rizzi, R., Carli, B., and Cuomo, V.: Retrieval of foreign-broadened water vapor continuum coefficients from emitted spectral radiance in the H2O rotational band from 240 to 590 cm−1, Opt. Express, 16, 15816–15833, https://doi.org/10.1364/OE.16.015816, 2008. a
Sinha, A. and Harries, J.: Water vapour and greenhouse trapping: The role of far infra-red absorption, Geophys. Res. Lett., 22, 2147–2150, 1995. a
Turner, D. D., Knuteson, R. O., and Revercomb, H. E.: Noise Reduction of Atmospheric Emitted Radiance Interferometer (AERI) Observations Using Principal Component Analysis, J. Atmos. Ocean. Tech., 23, 1223–1238, 2006. a, b, c
Veglio, P. and Maestri, T.: Statistics of vertical backscatter profiles of cirrus clouds, Atmos. Chem. Phys., 11, 12925–12943, https://doi.org/10.5194/acp-11-12925-2011, 2011. a
Wilks, D. S.: Statistical Methods in the Atmospheric Sciences, Elsevier Science Publishing, ISBN 9780123850225, 2006. a
Wilson, H. S., Atkinson, N., and Smith, J.: The Development of an Airborne Infrared Interferometer for Meteorological Sounding Studies, J. Atmos. Ocean. Tech., 16, 1912–1927, https://doi.org/10.1175/1520-0426(1999)016<1912:TDOAAI>2.0.CO;2, 1999. a
Yang, P., Bi, L., Baum, B. A., Liou, K.-N., Kattawar, G. W., Mishchenko, M. I., and Cole, B.: Spectrally Consistent Scattering, Absorption, and Polarization Properties of Atmospheric Ice Crystals at Wavelengths from 0.2 to 100 µm, J. Atmos. Sci., 70, 330–347, 2013. a