the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 06 Aug 2019
| 06 Aug 2019
Evaluating and improving the reliability of gas-phase sensor system calibrations across new locations for ambient measurements and personal exposure monitoring
Sharad Vikram
Ashley Collier-Oxandale
Michael H. Ostertag
Massimiliano Menarini
Camron Chermak
Sanjoy Dasgupta
Tajana Rosing
Michael Hannigan
William G. Griswold
Advances in ambient environmental monitoring technologies are enabling concerned communities and citizens to collect data to better understand their local environment and potential exposures. These mobile, low-cost tools make it possible to collect data with increased temporal and spatial resolution, providing data on a large scale with unprecedented levels of detail. This type of data has the potential to empower people to make personal decisions about their exposure and support the development of local strategies for reducing pollution and improving health outcomes.
However, calibration of these low-cost instruments has been a challenge. Often, a sensor package is calibrated via field calibration. This involves colocating the sensor package with a high-quality reference instrument for an extended period and then applying machine learning or other model fitting technique such as multiple linear regression to develop a calibration model for converting raw sensor signals to pollutant concentrations. Although this method helps to correct for the effects of ambient conditions (e.g., temperature) and cross sensitivities with nontarget pollutants, there is a growing body of evidence that calibration models can overfit to a given location or set of environmental conditions on account of the incidental correlation between pollutant levels and environmental conditions, including diurnal cycles. As a result, a sensor package trained at a field site may provide less reliable data when moved, or transferred, to a different location. This is a potential concern for applications seeking to perform monitoring away from regulatory monitoring sites, such as personal mobile monitoring or high-resolution monitoring of a neighborhood.
We performed experiments confirming that transferability is indeed a problem and show that it can be improved by collecting data from multiple regulatory sites and building a calibration model that leverages data from a more diverse data set. We deployed three sensor packages to each of three sites with reference monitors (nine packages total) and then rotated the sensor packages through the sites over time. Two sites were in San Diego, CA, with a third outside of Bakersfield, CA, offering varying environmental conditions, general air quality composition, and pollutant concentrations.
When compared to prior single-site calibration, the multisite approach exhibits better model transferability for a range of modeling approaches. Our experiments also reveal that random forest is especially prone to overfitting and confirm prior results that transfer is a significant source of both bias and standard error. Linear regression, on the other hand, although it exhibits relatively high error, does not degrade much in transfer. Bias dominated in our experiments, suggesting that transferability might be easily increased by detecting and correcting for bias.
Also, given that many monitoring applications involve the deployment of many sensor packages based on the same sensing technology, there is an opportunity to leverage the availability of multiple sensors at multiple sites during calibration to lower the cost of training and better tolerate transfer. We contribute a new neural network architecture model termed split-NN that splits the model into two stages, in which the first stage corrects for sensor-to-sensor variation and the second stage uses the combined data of all the sensors to build a model for a single sensor package. The split-NN modeling approach outperforms multiple linear regression, traditional two- and four-layer neural networks, and random forest models. Depending on the training configuration, compared to random forest the split-NN method reduced error 0 %–11 % for NO2 and 6 %–13 % for O3.
- Article
(5047 KB) - Full-text XML
- BibTeX
- EndNote




As the use of low-cost sensor systems for citizen science and community-based research expands, improving the robustness of calibration for low-cost sensors will support these efforts by ensuring more reliable data and enabling a more effective use of the often-limited resources of these groups. These next-generation technologies have the potential to reduce the cost of air quality monitoring instruments by orders of magnitude, enabling the collection of data at higher spatial and temporal resolution, providing new options for both personal exposure monitoring and communities concerned about their air quality (Snyder et al., 2013). High-resolution data collection is important because air quality can vary on small temporal and spatial scales (Monn et al., 1997; Wheeler et al., 2008). This variability can make it difficult to estimate exposure or understand the impact of local sources using data from existing monitoring networks (Wilson et al., 2005), which provide information at a more regional scale. Furthermore, studies have highlighted instances where air quality guidelines have been exceeded on small spatial scales, in so-called “hot spots” (Wu et al., 2012). This may be of particular concern for environmental justice communities, where residents are unknowingly exposed to higher concentrations of pollutants due to a lack of proximity to local monitoring stations. One group using low-cost sensors to provide more detailed and locally specific air quality information is the Imperial County Community Air Monitoring Network (English et al., 2017). The goal of this network of particulate monitors is to help inform local action (e.g., keeping kids with asthma inside) or open the door to conversations with regulators (English et al., 2017). In another example, researchers are investigating the potential for wearable monitors to improve personal exposure estimates (Jerrett et al., 2017).
The increasing use of low-cost sensors is driving a growing concern regarding data quality (Clements et al., 2017). Low-cost sensors, particularly those designed to detect gas-phase pollutants, are often cross sensitive to changing environmental conditions (e.g., temperature, humidity, and barometric pressure) and other pollutant species. Much work has gone into exploring calibration methods, models, and techniques that incorporate corrections for these cross sensitivities to make accurate measurements in complex ambient environments (Spinelle et al., 2014, 2015b, 2017; Cross et al., 2017; Sadighi et al., 2018; Zimmerman et al., 2018). While the methods of building (or training) calibration models differ, these studies have all utilized colocations with high-quality reference instruments in the field – instruments such as Federal Reference Method or Federal Equivalent Method monitors (FRM/FEM) (Spinelle et al., 2014, 2015b, 2017; Cross et al., 2017; Sadighi et al., 2018; Zimmerman et al., 2018). These colocated data allow accurate calibration models to be built for the conditions that the sensors will experience in the field (e.g., diurnal environmental trends and background pollutants). A recurring observation has been that laboratory calibrations, while valuable for characterizing a sensor’s abilities, perform poorly compared to field calibrations, likely due to an inability to replicate complex conditions in a chamber (Piedrahita et al., 2014; Castell et al., 2017).
Recently, researchers have begun to explore calibrating sensors in one location and testing them in another, called transfer. Often, a decrease in performance is seen in new locations where conditions are likely to differ from the conditions of calibration. In one study, researchers testing a field calibration for electrochemical SO2 sensors from one location in Hawaii and at another location also in Hawaii found a small drop in correlation between the reference and converted sensor data (Hagan et al., 2018). This was attributed to the testing location being a generally less polluted environment (Hagan et al., 2018). In a study that involved calibration techniques for low-cost metal oxide O3 sensors and nondispersive infrared CO2 sensors in different environments (e.g., typical urban vs. a rural area impacted by oil and gas activity), researchers found that simpler calibration models (i.e., linear models), although generally lower in accuracy, performed more consistently (i.e., transferred better) when faced with significant extrapolations in time or typical pollutant levels and sources (Casey and Hannigan, 2018). In contrast, more complex models (i.e., artificial neural networks) only transferred well when there was little extrapolation in time or pollutant sources. A study utilizing electrochemical CO, NO, NO2, and O3 sensors found that performance varied spatially and temporally according to changing atmospheric composition and meteorological conditions (Castell et al., 2017). This team also found calibration model parameters differed based on where exactly a single sensor node was colocated (i.e., a site on a busy street versus a calm street), supporting the idea that these models are being specialized to the environment where training occurred (Castell et al., 2017). In a recent study targeting this particular issue with low-cost sensors, electrochemical NO and NO2 sensors were calibrated at a rural site using a multivariate linear regression model, support vector regression models, and a random forest regression model. The performance of these models was then examined at two urban sites (one background urban site and one near-traffic urban site). For both sensor types, random forests were found to be the best-performing models, resulting in mean average errors between 2 and 4 parts per billion (ppb) and relatively useful information in the new locations (Bigi et al., 2018). One important note from the authors is that both sensor signals were included in the models for NO and NO2 respectively, potentially helping to mitigate cross-interference effects (Bigi et al., 2018). In another recent study, researchers also compared several different calibration model types, as well as the use of individualized versus generalized models and how model performance is affected when sensors are deployed to a new location (Malings et al., 2019). An individualized model is a model for a sensor based on its own data, whereas a generalized model combines the data from all the sensors of the same type being calibrated. The researchers found that the best-performing and most robust model types varied by sensor type; for example, simpler regression models performed best for electrochemical CO sensors, whereas more complicated models, such as artificial neural networks and random forest models, resulted in the best performance for NO2. Despite the varied results, in terms of the best-performing model types, the researchers observed that across the different sensor types tested, generalized models resulted in more consistent performance at new sites than individualized models despite having slightly poorer performance during the initial calibration (Malings et al., 2019). If this observation holds across sensor types and the use in other locations, it could help solve the problem of scaling up sensor networks, allowing for much larger deployments.
The mixed results and varying experimental conditions of these studies highlight the need for a more comprehensive understanding of how and why calibration performance degrades when sensors are moved. A better understanding could inform potential strategies to mitigate these effects. As recent research has successfully applied advanced machine learning techniques to improve sensor calibration models (Zimmerman et al., 2018; De Vito et al., 2009; Casey et al., 2018), we believe these techniques could also be leveraged in innovative ways to improve the transferability of calibration models.
This paper contributes an extensive transferability study as well as new techniques for data collection and model construction to improve transferability. We hypothesize that transferability is an important issue for sensors that exhibit cross sensitivities. Based on the hypothesis that the increased errors under transfer are due to overfitting, we propose that training a calibration model on multiple sites will improve transfer. Finally, we propose that transfer can be further improved with a new modeling method, split-NN, that can use the data from multiple sensor packages trained at multiple sites to train a two-stage model with a global component that incorporates information from several different sensors and locations and a sensor-specific model that transforms an individual sensor's measurements to a form that can be input to the global model
As many previous studies studied colocation with reference measurements in one location and a validation at a second location, we designed a deployment that included triplicates of sensor packages colocated at three different reference monitoring stations and then rotated through the three sites – two near the city of San Diego, CA, and one in a rural area outside of Bakersfield, CA. This allows for further isolating the variable of a new deployment location. The analysis focuses on data from electrochemical O3 and NO2 sensors, although other sensor types were deployed and used in the calibration, analogous to Bigi et al. (2018). These pollutants are often of interest to individuals and communities given the dangers associated with ozone exposure (Brunekreef and Holgate, 2002) and nitrogen dioxide's role in ozone formation. In studying these pollutants, we are adding to the existing literature by examining the transferability issue in relation to electrochemical O3 and NO2 sensors, which are known to exhibit cross-sensitive effects (Spinelle et al., 2015a). We compare the transferability of multiple linear regression models, neural networks, and random forest models. Based on these results, we introduce a new training method that trains all the sensors using a split neural network that consists of a global model and sensor-specific models that account for the differing behaviors among the individual sensors. Sharing data holds the promise to lower training costs while at the same time lowering prediction error.

Figure 1Labeled MetaSense Air Quality Sensing Platform. (a) Modular, extensible platform in standard configuration with NO2, O3, and CO electrochemical sensors. (b) Additional modules that can be added to the board for additional measurement capabilities.
2.1 The MetaSense system
2.1.1 Hardware platform
A low-cost air quality sensing platform was developed to interface with commercially available sensors, initially described in Chan et al. (2017). The platform was designed to be mobile, modular, and extensible, enabling end users to configure the platform with sensors suited to their monitoring needs. It interfaces with the Particle Photon or Particle Electron platforms, which contain a 24 MHz ARM Cortex M3 microprocessor and a Wi-Fi or 3G cellular module, respectively. In addition, a Bluetooth Low Energy (BLE) module supports energy-efficient communication with smartphones and other hubs with BLE connectivity. The platform can interface with any sensor that communicates using standard communication protocols (i.e., analog, I2C, SPI, UART) and supports an input voltage of 3.3 or 5.0 V. The platform can communicate results to nearby devices using BLE or directly to the cloud using Wi-Fi or 2G/3G cellular, depending on requirements. USB is also provided for purposes of debugging, charging, and flashing the firmware. The firmware can also be flashed or configured remotely if a wireless connection is available. An SD card slot provides the option for storing measurements locally, allowing for completely disconnected and low-power operation.
Our configuration utilized electrochemical sensors for traditional air quality indicators (NO2, CO, O3), nondispersive infrared sensors for CO2, photoionization detectors for volatile organic compounds (VOCs), and a variety of environmental sensors (temperature, humidity, barometric pressure). The electrochemical sensors (NO2: Alphasense NO2-A43F, O3: Alphasense O3-A431, and CO: Alphasense CO-A4) are mounted to a companion analog front end (AFE) from Alphasense, which assists with voltage regulation and signal amplification. Each sensing element has two electrodes which give analog outputs for the working electrode (WE) and auxiliary electrode (AE). The difference in signals is approximately linear with respect to the ambient target gas concentration but has dependencies with temperature, humidity, barometric pressure, and cross sensitivities with other gases. The electrochemical sensors generate an analog output voltage, which is connected to a pair of analog-to-digital converters (ADCs), specifically the TI ADS1115, and converted into a digital representation of the measured voltage, which is later used as inputs for our machine learning models.
Modern low-cost electrochemical sensors offer a low-cost and low-power method to measure pollutants, but currently available sensors are more optimized for industrial applications than air pollution monitoring: the overall sensing range is too wide and the noise levels are too high. For example, the Alphasense A4 sensors for NO2, O3, and CO have a measurement range of 20, 20, and 500 ppm, respectively, which is significantly higher than the unhealthy range proposed by the United States Air Quality Index. Unhealthy levels for NO2 at 1 h exposure range from 0.36 to 0.65 ppm, O3 at 1 h exposure from 0.17 to 0.20 ppm, and CO at 8 h exposure from 12.5 to 15.4 ppm (Uniform Air Quality Index (AQI) and Daily Reporting, 2015). Along with the high range, the noise levels of the sensors make it difficult to distinguish whether air quality is good. Using the analog front end offered by Alphasense, the noise levels for NO2, O3, and CO have standard deviations of 7.5, 7.5, and 10 ppb, respectively. These standard deviations are large compared to observed signal levels for NO2 and O3 measurements, which ranged between 0–35 and 12–60 ppb, respectively, during the 6-month testing period.
The ambient environmental sensors accurately measure temperature, humidity, and pressure and are important for correcting the environmentally related offset in electrochemical sensor readings. The TE Connectivity MS5540C is a barometric pressure sensor capable of measuring across a 10 to 1100 mbar range with 0.1 mbar resolution. Across 0 to 50 ∘C, the sensor is accurate to within 1 mbar and has a typical drift of ±1 mbar per year. The Sensirion SHT11 is a relative humidity sensor capable of measuring across the full range of relative humidity (0 % to 100 % RH) with ±3 % RH accuracy. Both sensors come equipped with temperature sensors with ±0.8 and ±0.4 ∘C accuracy, respectively. The sensors stabilize to environmental changes in under 30 s, which is sufficiently fast to accurately capture changes in the local environment.
In order to improve the robustness of the boards to ambient conditions, the electronics were conformally coated with silicone and placed into an enclosure as shown in Fig. 2. The housing prevents direct contact with the sensors by providing ports over the electrochemical sensors and a vent near the ambient environmental sensors. The system relies on passive diffusion of pollutants into the sensors due to the high power cost of active ventilation. However, as described in Sect. 2.3, for this study the housed sensor packages were placed in an actively ventilated container.

Figure 2An enclosure was 3-D printed for the MetaSense Air Quality Sensing Platform with top-side ports above the electrochemical sensors and a side port next to the ambient environmental sensors. The sensor is sized to be portable and has velcro straps that can be used to mount it to backpacks, bicycles, etc.
2.1.2 Software infrastructure
We developed two applications for Android smartphones that leverage the BLE connection of the MetaSense platform. The first application, the MetaSense Configurator app, enables users to configure the hardware for particular deployment scenarios, adjusting aspects such as sensing frequency, power gating of specific sensors connected, and the communication networks utilized. The second application, simply called the MetaSense app, collects data from the sensor via BLE and uploads all readings to a remote database. Each sensor reading is stamped with time and location information, supporting data analysis for mobile use cases. Moreover, users can read the current air quality information on their device, giving them immediate and personalized insight into their exposure to pollutants.
The remote measurements database is supported by the MetaSense cloud application and built on Amazon's AWS cloud. Not only can the MetaSense app connect to this cloud, but the MetaSense boards can be configured to connect directly to it using Wi-Fi or 3G. The measurement data can be processed by machine learning algorithms in virtual machines in AWS, or the data can be downloaded to be analyzed offline. The aforementioned over-the-air firmware updates are handled through Particle's cloud, which also allows remotely monitoring, configuring, and resetting boards. These direct-to-cloud features are key to supporting a long-term, wide-scale deployment like the one presented in this paper.
2.2 Sampling sites
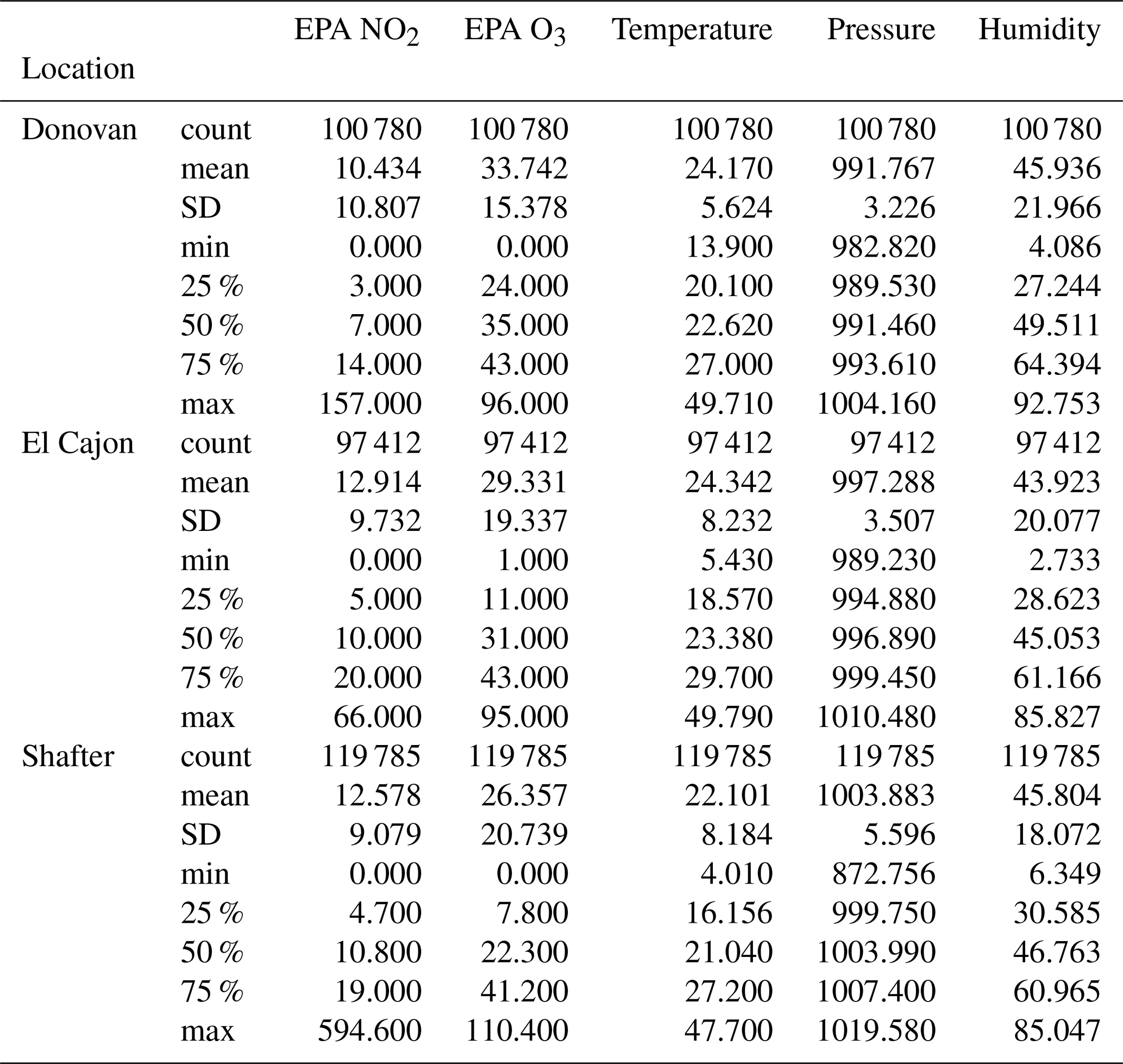
For this deployment, our team coordinated with two regulatory agencies (the San Diego Air Pollution Control District, SDAPCD; and the San Joaquin Valley Air Pollution Control District, SJVAPCD) in order to access three regulatory monitoring sites. Sensor packages were then rotated through each site over the course of approximately 6 months. Each monitoring site included reference instruments for NO2 and O3, among others. The first site was in El Cajon, CA, located at an elementary school east of San Diego, CA (El Cajon site). This site is classified by the SDAPCD as being in the middle of a major population center, primarily surrounded by residences (Shina and Canter, 2016); expected influences at this site include transported emissions from the heavily populated coastal region to the west as a well as emissions from a major transportation corridor (Shina and Canter, 2016). The second site was approximately 15 mi (24.1 km) to the southeast of San Diego, located at the entrance to a correctional facility (Donovan site). This site is not located in a high-density residential or industrial area and does not have many influences very near to the site; it is expected to provide air quality information for the southeast area of the county (Shina and Canter, 2016). Additionally, this site is approximately 2 mi (3.2 km) from a border crossing utilized by heavy-duty commercial vehicles – the Otay Mesa Port of Entry. The third site was located on the roof of a DMV (Department of Motor Vehicles) in the rural community of Shafter, CA, 250 mi (402 km) to the north near Bakersfield (Shafter site). The SJVAPCD lists the following potential sources of air pollution for this community: rural sources (agricultural and oil and gas production), mobile (including highways and railroads), and local sources (commercial cooking, gas stations, and consumer products) (SJVAPCD Website, 2019). Given the differences in location, land use, and nearby sources we expect to see differences in both the environmental (i.e., temperature, humidity, and barometric pressure) and pollutant profiles at each sites. For example, the Shafter site is considerably more inland, where weather would be more dominated by the desert ecosystem rather than the ocean ecosystem as compared to the two San Diego sites. In addition to being further inland, the Shafter site is rural and has a unique nearby source (i.e., oil and gas production), which might also result in a unique pollutant profile and differing composition of background pollutants when compared to the San Diego sites. Similarly, given the differences in land use and expected influences at the two San Diego sites, we may expect to see different trends in ozone chemistry. For example, given that the El Cajon site is a highly residential area, while the Donovan site is near the Otay Mesa border crossing, there may be more local heavy-duty vehicle emissions at the second site. Comparing the historical data from these sites provides some support for this idea. In the 2016 Network Plan by the SDAPCD we see that the El Cajon site had a slightly higher maximum 8 h ozone average than the Donovan site, at 0.077 and 0.075 ppm respectively, while the Donovan site had a higher maximum 1 h nitrogen dioxide average than the El Cajon site, at 0.067 and 0.057 ppm respectively. It is possible that this difference in peak levels at each site may be driven by the sources influencing each site, in particular the nitrogen dioxide levels, which may be tied to heavy-duty vehicle traffic. In terms of the differences between regions, the San Joaquin Valley has consistently had more days where the 8 h ozone standard has been exceeded than San Diego County from 2000 to 2015 (Shina and Canter, 2016; San Joaquin Valley Air Pollution Control District, 2016). In this instance the higher frequency of ozone elevations in the San Joaquin Valley may be evidence for different climate, meteorology, and sources driving different ozone trends. This variety of environmental and emissions profiles would allow us to meaningfully test for transferability, in particular to assess to what degree a calibration model trained on one site would overfit for the other sites.
2.3 Data collection
In ordinary use cases, the air quality sensors would be mounted to a backpack, bike, or other easily transportable item as shown in Fig. 2. A calibration algorithm located either on the sensor or a Bluetooth-compatible smartphone would convert the raw voltage readings from the sensors and ambient environmental conditions to a prediction of the current pollutant levels in real time. In order to develop these calibration models, we gathered data from air quality sensors and colocated regulatory monitoring sites over a 6-month deployment period.
To support a long-term deployment in potentially harsh conditions where no human operator would be able to monitor the sensors on a regular basis, the sensors were placed into environmentally robust containers, shown in Fig. 3b. The container was a dry box, measuring , that was machined to have two sets of two vents on opposing walls. Louvers were installed with two 5 V, 50 mm square axial fans expelling ambient air from one wall and two louvers allowing air to enter the opposite side. The configuration allowed the robust container to equilibrate with the local environment for accurate measurement of ambient pollutants. Each container could hold up to three MetaSense boards with cases and complementary hardware. Due to the long timeframe of the deployment, a USB charging hub was installed into the container to power the fans, the air quality sensors, and either a BLU Android phone or Wi-Fi cellular hotspot. The phones and hotspots were used to connect the sensors to the cloud; therefore, we could remotely monitor the sensors’ status in real time and perform preliminary data analysis and storage. Each board also had an SD card to record all measurements locally, increasing the reliability of data storage. It is important to note that end users of the air quality sensors would not need to perform this lengthy calibration procedure. End users will either receive precalibrated devices or can perform calibration by colocating their sensor with existing, calibrated sensors.
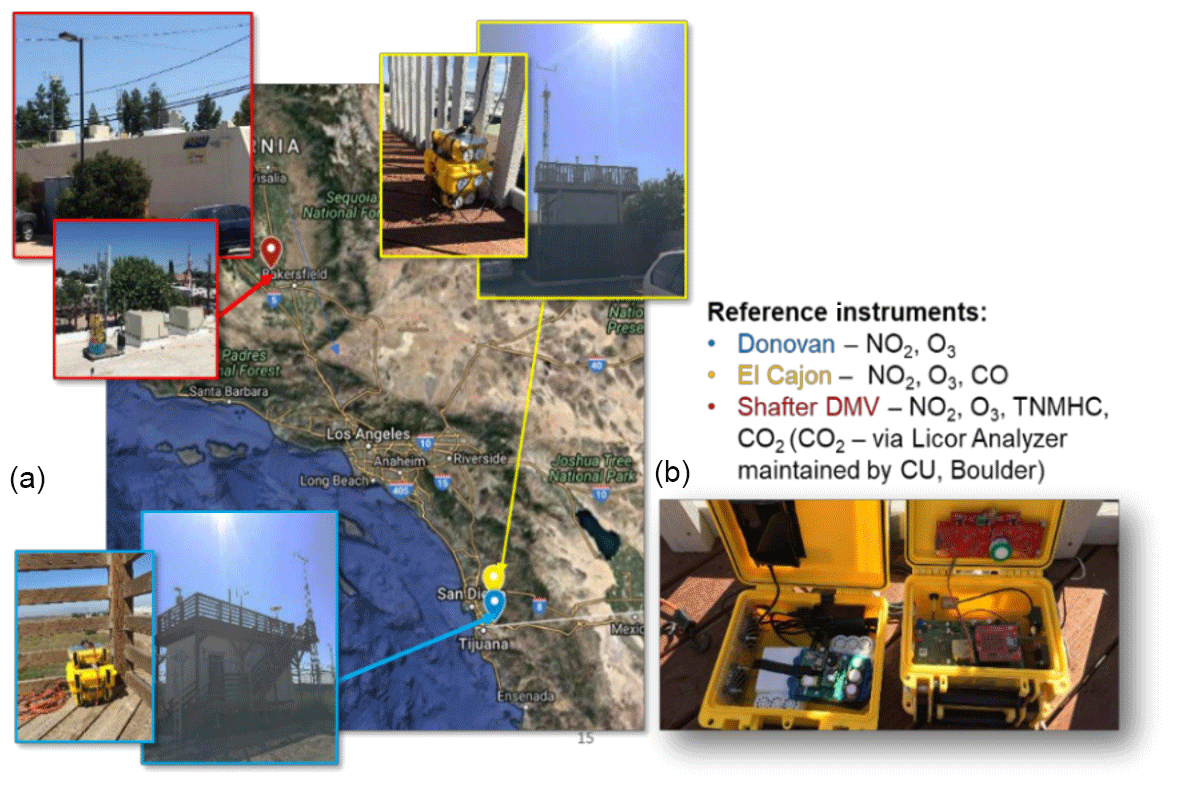
Figure 3(a) Map and images of deployment locations. The Shafter DMV (red) was located 250 mi (402 km) away from Donovan (blue) and El Cajon (yellow), which were located in San Diego, CA. (b) Deployment containers' configuration for the extended deployment. Each container has active ventilation to keep the internal conditions equivalent to the ambient environment.
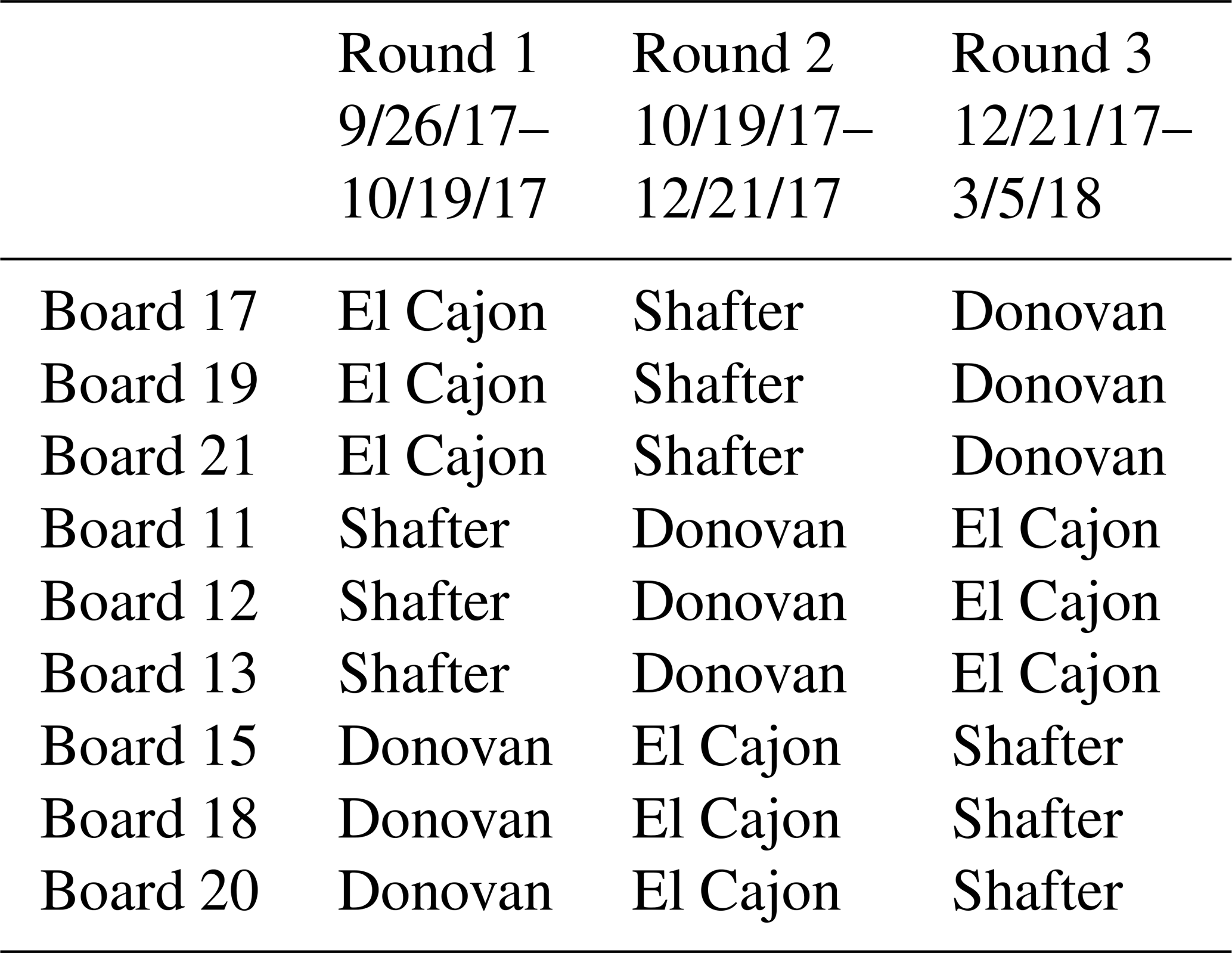
A container holding three MetaSense Air Quality Sensors was placed at each regulatory site, such that each site had one container of sensors for simultaneous measurement of conditions at all three regulatory sites. After a period of time, the containers were rotated to a new site. After three rotations, each sensor had taken measurements at each site. Table 1 lists the dates for each rotation as well as where each sensor system was located for each rotation. The dates are approximate due to the logistics of gaining access to regulatory field sites and the distances traveled to deploy sensors. Also of note is that the deployments were not of equal length. This does not affect the results reported below because we ran all combinations of training and testing sites, and training set sizes were normalized to remove the influence of training set size.
The data from the reference monitors was provided by the cooperating air quality districts in the form of minute-averaged O3 and NO2 concentrations for the time period that our sensor packages were deployed. We removed reference data collected during calibration periods as well as any data flagged during initial quality assurance/control by the regulatory agency who supplied the data. The reference data are not final ratified data as the timing of our study did not allow us to wait that long.
2.4 Preprocessing
Prior to using the data set for training the calibration models, we performed a preprocessing step. First, we programmatically filtered out data samples that contained anomalous values that might have occurred due to a temporary sensor board malfunction (e.g., due to condensation). Specifically, we searched for temperature and voltage spikes that were outside the realm of reasonable values (i.e., temperature values above 60 ∘C or ADC readings above 5 V) and removed the corresponding measurements. Each removed group of samples was visually inspected to ensure data were not being erroneously removed. A total of 422 551 samples were removed from the 17 948 537 collected samples, 2.4 % of the total. For the remaining data, a simple average was computed over each 1 min window so as to match the time resolution of the data from the reference monitors. If an entire minute of data is missing due to a crashed sensor or preprocessing, no minute-averaged value is generated. Although we gathered sensor voltage measurements from both the auxiliary and working electrodes of the electrochemical sensors, we used the difference between the two (AE–WE) as the representative voltage for each sensor since the auxiliary voltage is meant to serve as a reference voltage for the working electrode. This treatment is consistent with the methodology of Zimmerman et al. (2018), and we validated that the performance of the calibration models did not differ between tests with both electrodes and test with the difference as input features. As a final step, the resulting minute-averaged readings were time-matched with the reference data, removing readings that had no corresponding reference reading. The resulting data set over the three rounds at the three sites contains 1 100 000 minute-averaged measurements.
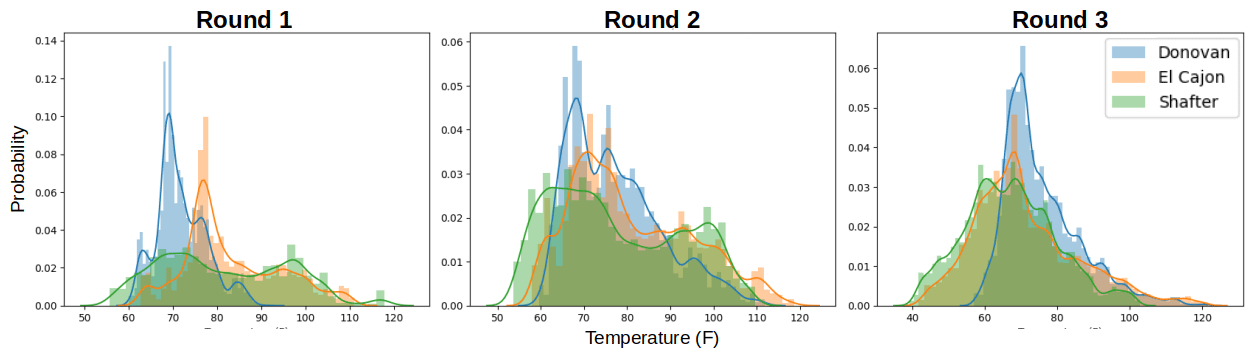
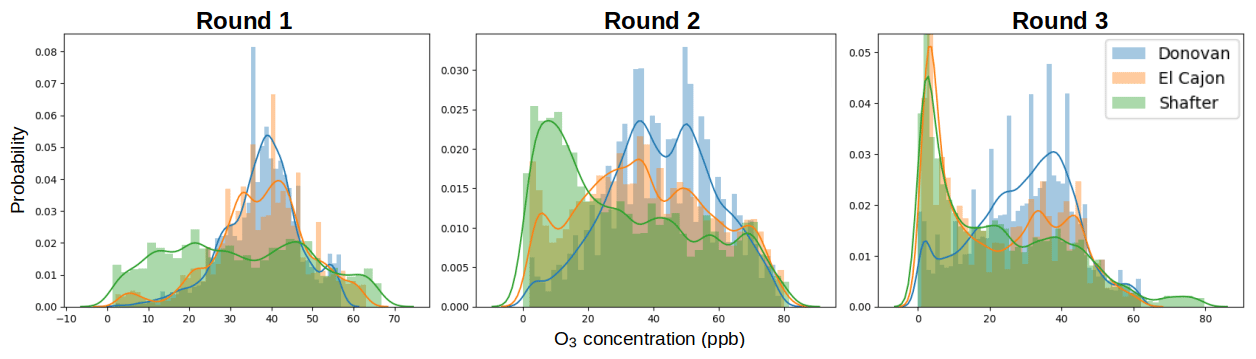
Furthermore, after receiving and examining the reference data we were able to verify our hypothesis in Sect. 2.2 that we would observe varied environmental and pollutant conditions among the sites. Again, this hypothesis was based on site characteristics and data/statistics from reports available from the respective regulatory agencies. Generally higher ozone values were reported at Shafter, whereas generally higher NO2 values were reported at Donovan. Higher humidity values were reported at the Donovan and El Cajon sites, as compared to Shafter. Some of the lowest temperature values were reported at Shafter. For more information see the distribution plots in Appendix A.
2.5 Baseline calibration methods
Sensor calibration is the process of developing and training models to convert a sensor voltage into a pollutant concentration. We formulate sensor calibration as a regression problem with input features x and e representing signals from the electrochemical sensors (O3 voltage, NO2 voltage, CO voltage) and environmental factors (temperature, pressure, humidity), respectively, for a total of six features. These features are input to a calibration function hθ(x,e) that estimates target values y representing pollutant concentrations (O3 ppb and NO2 ppb).
In our regression problem, we seek a function such that , which we formulate as an optimization where we minimize a measure of error over a training data set according to a loss function ; i.e.,
For most of the modeling techniques we minimize the mean squared error (MSE), except for random forest where we minimize the variance, which behaves similar to MSE. Models trained in this way assume that, at inference time, predictions are made on data sampled from the training distribution. While this assumption holds true when the air quality sensors are trained and tested at the same site, the distribution of pollutants and environmental conditions changes when the sensors are moved to a new location.
We investigated the performance of three calibration models: multiple linear regression, neural networks (sometimes called deep learning), and random forest. These methods vary in their ability to accurately model complex behaviors, otherwise known as capacity, with linear regression having relatively low capacity and neural nets and random forests having substantial capacity. The price of high capacity is the potential to overfit the training distribution, which is a failure to generalize beyond the training data. Models that overfit will incur significant error when predicting on out-of-distribution examples. Overfitting can be mitigated with regularization and by reducing the model capacity, but this can only go so far if the testing distribution is substantially different from the train distribution. All of these methods have been previously applied to ambient pollutant estimation by various research groups (Piedrahita et al., 2014; Spinelle et al., 2015b, 2017; Sadighi et al., 2018; Zimmerman et al., 2018; Casey and Hannigan, 2018) and are generally common predictive modeling methods. For neural nets, we investigated three variants: two layers, four layers, and four layers with a split architecture, which we motivate and describe in the next subsection.
Our baseline models were trained using the scikit-learn Python package, and the model parameters for each baseline model can be seen below.
-
Linear regression. We assume the functional form h(x)≜wTx+b and fit the parameters in closed form. We use no regularization or polynomial features.
-
Two-layer neural network. We fit a two-hidden-layer (200 wide) multilayer perceptron with rectified-linear-unit activation functions and a final linear layer. We train this neural network using the Adam optimizer () and a learning rate of 10−3.
-
Four-layer neural network. Same as the two-layer neural network, but with four hidden layers of width 200 instead of two.
-
Random forest. We divide our data into five folds and train a random forest of size 100 on each fold, resulting in 500 trees. We aim to reproduce the strategy of Zimmerman et al. (2018) as closely as possible.
2.6 Split neural network method
Overfitting is a problem for high-capacity models with a limited distribution in training data, resulting in poor performance when a model is transferred to new locations and environments. One method to improve model transferability would be to collect more training data that includes the test distribution. However, colocating a sensor at multiple different regulatory field sites in order to capture a sufficiently wide distribution is prohibitive in terms of cost and time. An alternative solution is to deploy a set of sensors based on the same technology across multiple sites and then pool their data. However, there can be substantial sensor-to-sensor variance in performance that would amplify prediction errors.
Recent work in sensor calibration has produced architectures that split model training into global and sensor-specific training phases, primarily for metal oxide (MOX) gas sensors produced in an industrial setting. The process involves training a global or master model on a small subset of devices over a wide range of environmental conditions. The master model translates raw sensor readings (i.e., voltage or current measurements) to a target pollutant. MOX sensors, similar to electrochemical sensors, are sensitive to ambient conditions, so a wide range of conditions and combinations are explored in the master calibration phase. While it can produce very accurate calibration models, the time and expense of gathering calibration data over a wide range of conditions are prohibitive in the industrial manufacturing process for low-cost sensors. To overcome this, a limited number of master models are created, and then an affine transformation is generated between individual sensors and the master sensors. The affine transformation effectively transforms the sensors readings of individual sensors to match that of the master, after which the master calibration model can be used. A variety of methods have been developed to this end. Zhang et al. (2011) propose a method to calibrate a MOX sensor for detecting volatile organic compounds using a neural network to capture the complexity of the master model and an affine transform and a Kennard–Stone sample selection algorithm to develop a linear model between individual sensors and the master sensor. Other research has utilized windowed piecewise direct standardization to transform the sensor readings from a slave sensor to a calibrated master for single gas concentrations (Yan and Zhang, 2015) and direct standardization for a range of gases and concentrations over a longer timeframe (Fonollosa et al., 2016). While previous efforts utilized single master sensors, Solórzano et al. (2018) showed that including multiple master sensors in a calibration model can improve the robustness of the overall model. Similar findings were reached by Smith et al. (2017) when investigating sensor drift whereby an ensemble model was generated by training models for multiple sensors and the prediction was reported as the cluster median. These two-stage calibrations have primarily been performed in controlled laboratory settings but not in real-world conditions where ambient conditions and cross sensitivities may impact results. In addition, these studies train models in a piecewise fashion, training master and sensor-specific models separately.
We propose end-to-end training of a global and sensor-specific models. In particular, we propose a training architecture that consists of two sets of models: a global calibration model that leverages the data from a set of similar sensors spread across different training environments and sensor-specific calibration models that detect and correct the differences between sensors. In the previous subsection, we associated each board i with a calibration function and fit this calibration function with its colocated data. Taking into consideration a collection of many air quality sensors, we propose an alternate architecture based on transfer learning (Goodfellow et al., 2016, p. 535). We propose using a calibration function split into two distinct steps: first, pollutant sensor voltages and input into a sensor-specific model, which outputs a fixed dimensional latent vector u; and, second, u and environmental data e are input into a global calibration model, which outputs the concentration of the target pollutants. The sensor-specific model is unique for each individual sensor and parameterized by θi, where i denotes the individual sensor number. The global calibration model cϕ([u|e]) is universal for all sensors and parameterized by ϕ. For a single air quality sensor, our final calibration function is . Figure 4 depicts the use of such a model. Such a model is called a split neural network model (split-NN) since neural networks are generally used for both the sensor-specific models and the global calibration models. In our experiments, the sensor-specific model is either a linear regressor or neural network; cϕ is a two-layer, 100-neuron-wide neural network.
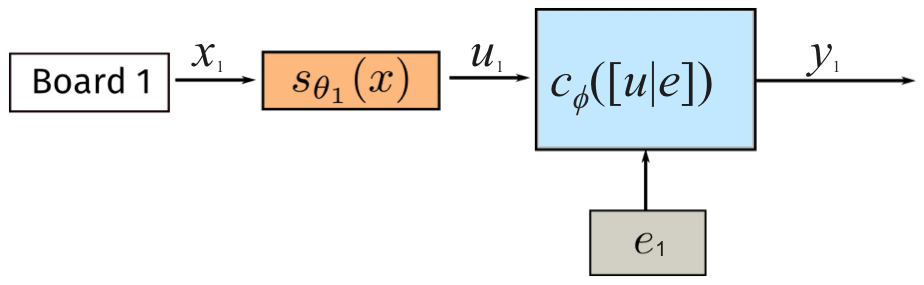
Figure 4Architecture of the split-NN model in deployment (testing). Each air quality sensor has a board-specific model that normalizes a given sensor's output (x) to an intermediate representation from all sensors (u). The intermediate representation is combined with environmental data (e) and input to the global model cϕ.
The purpose of the split-NN model is that corrects for differences in air quality sensor i's performance relative to the other sensors, thus normalizing the values and making the behavior of all the sensors compatible with the global model cϕ. The performance of the estimates from cϕ should be superior to that from an individual sensor model because it has been trained on the (normalized) data of all the boards as opposed to just a single board.
The split model can be trained efficiently with stochastic gradient descent. Specifically, we first collect N data sets for each board . We ensure each of these data sets is the same size by sampling each with replacement to artificially match the largest data set. We then pool the data sets together into one data set from which we sample minibatches. While each sensor-specific model is trained only on data collected by its sensor, the regression with the other sensor-specific models is designed to detect and correct its bias, outputting an intermediate representations u that is normalized with the others. The global calibration model is trained on the normalized data from all air quality sensors.
Although training this neural network will take longer than training one for a single board, it has several key advantages over conventional calibration techniques. The first is its ability to share information across multiple boards. Suppose Board A is trained on Location 1 and Board B is trained on Location 2. Pooling the data sets and using a shared model enables the global calibration model to predict well in both locations, and the calibration models for both boards will have information about the other locations in them, in theory improving transferability. The second is more efficient utilization of data. By pooling data and training jointly, we effectively multiply our data size by the number of boards. Alternatively, field deployments can be shortened.
Calibrating a new board without a full training. Field calibration is traditionally performed by colocating a sensor package with reference monitors and then training to match pollutant concentrations. But, suppose we already had a fleet of low-cost sensor packages already deployed. A simpler method not requiring coordination with regulatory agencies would be to colocate it with a calibrated sensor package and train a model to match its predicted pollutant levels. This risks compounding errors across models, however. The split-NN model enables calibrating a new sensor package by colocating to match representation instead of predictions, as learned representations can often improve generalization in transfer learning problems (Goodfellow et al., 2016, p. 536).
We propose calibrating sensor package N+1 to match the intermediate representation output of a colocated, previously calibrated sensor package. Specifically, we train model N+1 to minimize , or the loss between the two packages' intermediary outputs. These intermediate representations are designed to be robust to changes in location; therefore, it is expected that training to match these representations will result in more robust calibration models. We analyze this potential calibration technique by holding out a board from our data sets and training a split model. We then simulate calibrating the held out board by training a sensor model to match the representations produced by another board it was colocated with. We then use this new sensor model with the global calibration function to produce pollutant values.
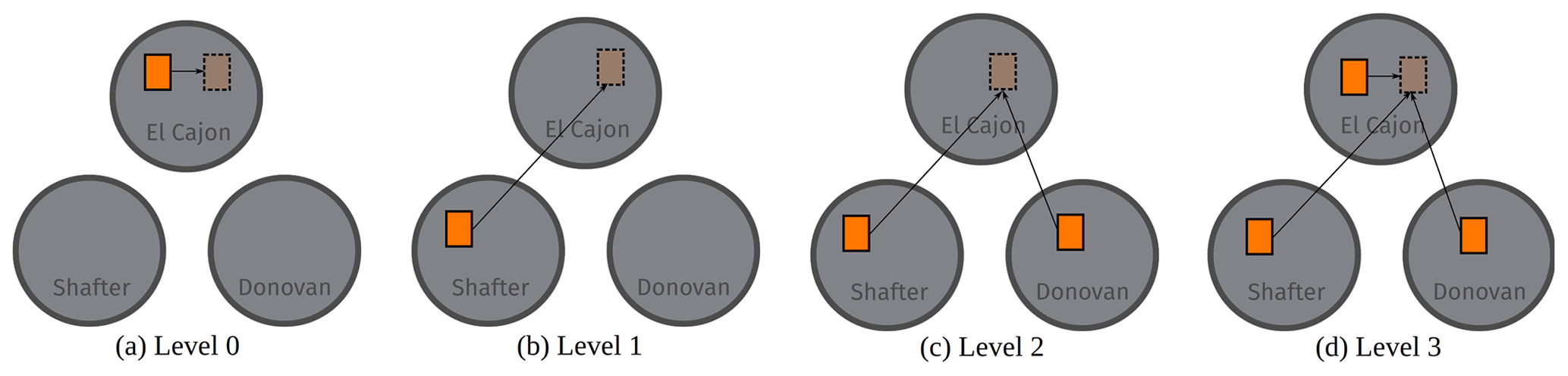
Figure 5Graphical depiction of training versus testing for the Level 0 through Level 3 benchmarks. The Level 0 and 3 benchmarks test on a training site using held out data. The Level 1 and 2 benchmarks train and test on different sites, also using held out data for consistency.
3.1 Robustness of different calibration techniques across new locations
We evaluated a set of four baseline models described in Sect. 2.5: multiple linear regression, two-layer neural network (NN-2), four-layer neural network (NN-4), and random forest (RF). With each of these four models, we performed a suite of identical calibration benchmarks that measure the robustness of models to out-of-distribution data. We split all data sets uniformly at random into training and testing subsets, reserving 20 % of each board's data for testing. In each benchmark, we progressively widened the training distribution by combining training data from more locations (using subsampling to maintain the training set size), while keeping the testing set data set from one location. We have four levels of such benchmarks.
-
Level 0. Train a model on one location and test on the same location. Several studies, discussed in Sect. 1, have previously assessed this configuration (Zimmerman et al., 2018; Spinelle et al., 2015b, 2017; Cross et al., 2017).
-
Level 1. Train a model on one location and test on another location. Some recent studies, also discussed in Sect. 1, have previously studied this configuration (Hagan et al., 2018; Casey and Hannigan, 2018; Bigi et al., 2018; Malings et al., 2019).
-
Level 2. Train a model on two locations and test on a third location.
-
Level 3. Train a model on three locations and test on one of the three locations.
In the Level 0 and Level 3 benchmarks, the training and testing data distributions have explicit overlap, whereas, in Level 1 and 2, there is no explicit overlap. We expect performance on Level 0 to be the best, as the training and testing distributions are identical. We expect performance on Level 3 to be similar, due to the overlap in training and testing distributions. We expect performance on Level 1 to be the worst, as the training distribution is the narrowest and with no explicit overlap, whereas we expect performance on Level 2 to be between Level 1 and Level 3, for although there is no explicit overlap, the overall training distribution will be wider, forcing the models to be more general and possibly affording more implicit overlap. Furthermore, we expect higher-capacity models to overfit more to the training data set and, as a result, have the largest gap between Level 0 and Level 1. Thus, we expect linear regression to have more consistent performance across the benchmarks, albeit at relatively high error, followed by the two-layer neural network, four-layer neural network, and finally the random forest.
We ran each benchmark across all possible permutations of location and sensor package, measuring six metrics in order to facilitate comparisons in the literature: mean squared error (MSE), root mean squared error (RMSE, also known as the standard error), centered root mean squared error (cRMSE), mean absolute error (MAE), the coefficient of variation of mean absolute error (CvMAE), mean bias error (MBE), and coefficient of determination (R2). Predictions were made in parts per billion (ppb); thus MSE is reported in ppb2, and the other errors are reported in ppb. CvMAE and R2 are dimensionless. The results for MAE of the baseline models are plotted in Fig. 6. Details can be explored further in Appendix C.
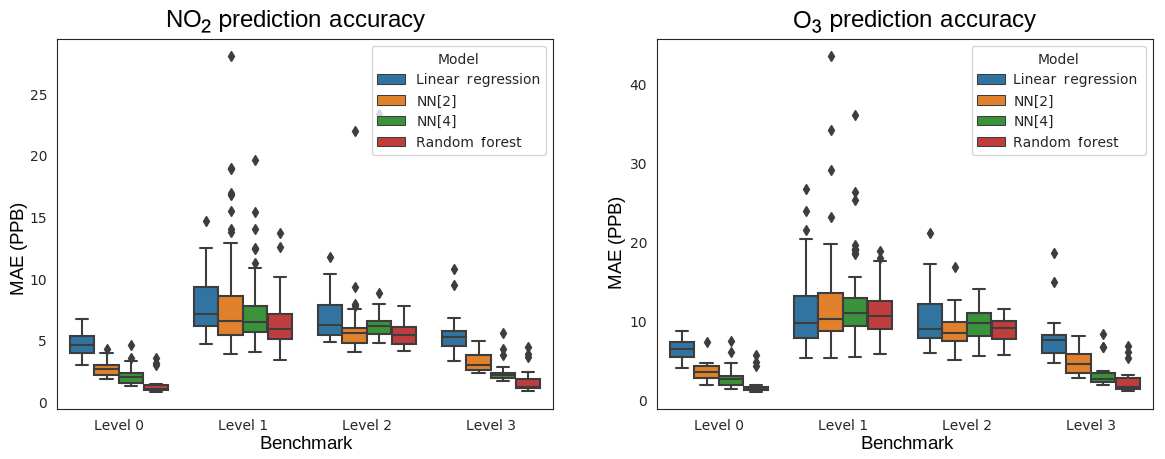
Figure 6Mean absolute error (MAE) boxplots for NO2 and O3, for the Level 0 through Level 3 benchmarks.
From Fig. 6 we observe that, on average, as model capacity increases, Level 0 error decreases. This is consistent across both NO2 and O3 prediction and reflects the ability of the model to fit the training distribution. Concerning model transferability, we find that, consistently, all models exhibit relatively high error when tested on different locations. The Level 1 and 2 benchmarks test the ability of a model to generalize to a distribution it has not seen before, and we see in these benchmarks that errors are much higher and the gaps between models are much smaller. Furthermore, the Level 2 error is slightly lower on average than Level 1 error. By adding data from another site, effectively widening the training distribution, the models are slightly more robust to the unseen testing distribution. Level 3 performance aligns closely with Level 0 performance, which is to be expected, since in both cases the training distribution contains the testing distribution.
Across baselines, we observe that, on average, linear regression has the highest error on all the benchmarks. However, its errors across the Level 0 through Level 3 benchmarks are more consistent than the other models, suggesting that low-capacity linear regression is more robust to transfer. On the other hand, random forests have on average the lowest error but have the most inconsistent results across the levels. The results indicate a tradeoff between model capacity and robustness to transfer, consistent with our intuitions about model overfitting and generalization. Neural networks lie in between linear regression and random forests and offer a tradeoff between low error and consistent error.
To better understand how model performance degrades, we produced target plots, which visualize the tradeoff between centered error (cRMSE) and bias error (MBE) (Fig. 7). The target plots indicate that while error approximately doubles when there is no explicit overlap in the distribution, the increase in model bias is many times more. When considering the two types of error examined, the cRMSE may be of greater concern when considering sensor performance in new locations as compared to error due to bias. Sensor data exhibiting errors due to bias may still provide useful information regarding the diurnal trends of pollutants or relatively large enhancements. Despite the higher-capacity models showing better error and bias in a Level 0 benchmark, the models have similar error–bias tradeoffs in a Level 1 benchmark, indicating that a high-capacity model cannot avoid this performance degradation. Finally, in comparing the Level 1 and Level 2 plots, we observe that adding an additional (no-overlapping) site primarily reduces bias. The Level 3 plots are very similar to the Level 0 plots and are excluded from Fig. 7 for brevity.
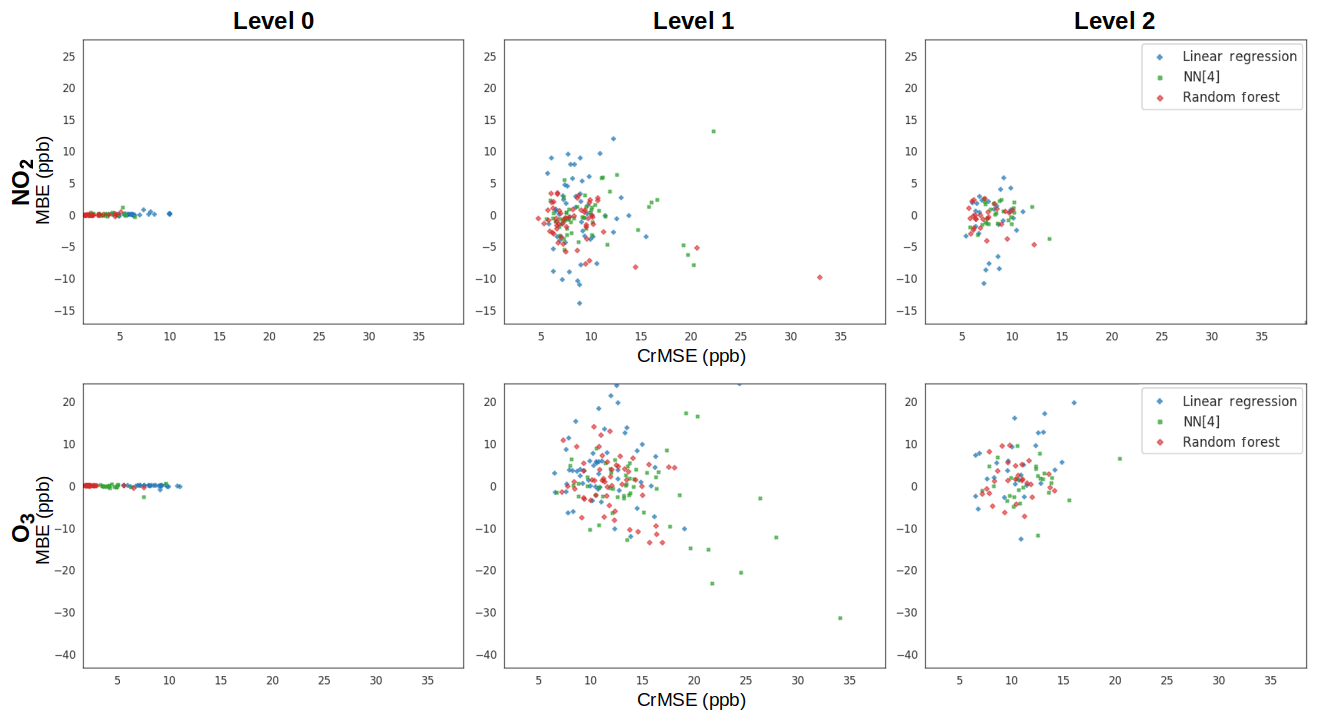
Figure 7Target plots for Level 0 through Level 2 for both NO2 and O3. In each panel, the centered error is plotted on the x axis, while the bias error (MBE) is plotted on the y axis. The differing colors then illustrate the performance of each calibration model at each level and for these metrics. Each point in the plot corresponds to a different individual benchmark (i.e., a unique round, location, and board).
In general, however, we observe that model performance degrades nontrivially when moved to different locations. This decrease in performance could result in overconfidence in a sensor's readings, potentially affecting downstream decisions. We briefly analyze the properties of our data that could result in overfitting by first investigating how data distributions across sites and times differ. Over each location and round, pollutant values can be highly variable. This is reflected, for example, in Fig. A3 where Shafter has higher values of NO2 in Round 1 and 2 but lower in Round 3. Furthermore, in Fig. A4, the distribution of O3 changes remarkably across round and location. Similarly, temperature and humidity change significantly across location and round, which can be seen in Figs. A1 and A2.
A question that remains is to what degree overfitting or unique (nonoverlapping) distributions of environmental data at the sites is contributing to the failure of the high-capacity models to transfer well. In an effort to better understand what may be driving the drop in performance of the high-capacity models when boards are moved, we examined error density plots for temperature and humidity for the Level 1 benchmarks. In these types of plots, one of the predictors, such as temperature or humidity, is plotted against the error for all three sites in a single plot. Figure 8 displays the error density plots in MAE for absolute humidity against the error for the O3 estimation, for both the linear regression and random forest models. These plots illustrate how the magnitude of error varies with respect to higher or lower predictor values as well as how different pairs of training and testing sites compare. There are a couple of things we can derive from this collection of plots. First, we observe that the pollutant concentrations at the Shafter site are difficult to predict, except for random forest when trained at Shafter itself (Fig. 8f). The Shafter site was spatially far from the other sites and likely had a unique composition of background pollutants and ambient environmental conditions. Second, we observe that when training a random forest model at one site and testing it at a different site (Fig. 8, bottom row), the error density plots look similar to the results from the linear regression models (Fig. 8, top row) despite the higher capacity of random forest models. Furthermore, comparing panels a and d, the errors at Shafter seem comparable to those at El Cajon for the random forest model, whereas for the linear regression model the errors seem greater at Shafter versus the second San Diego site. This difference potentially indicates that linear regression models are better at transferring between more similar environments, which has been observed by other researchers as well (Casey and Hannigan, 2018). We also observe that the greater errors at the Shafter site are occurring at humidity values that were seen in the training data set (more centrally in the plot), as is evident by their representation in the Donovan data. This implies that these errors did not occur at humidity values that have been extrapolated beyond the original training data set, but rather from overfitting at values in the distribution. This leads us to conclude that overfitting is the reason random forest's net performance in transfer is not much better than linear regression.
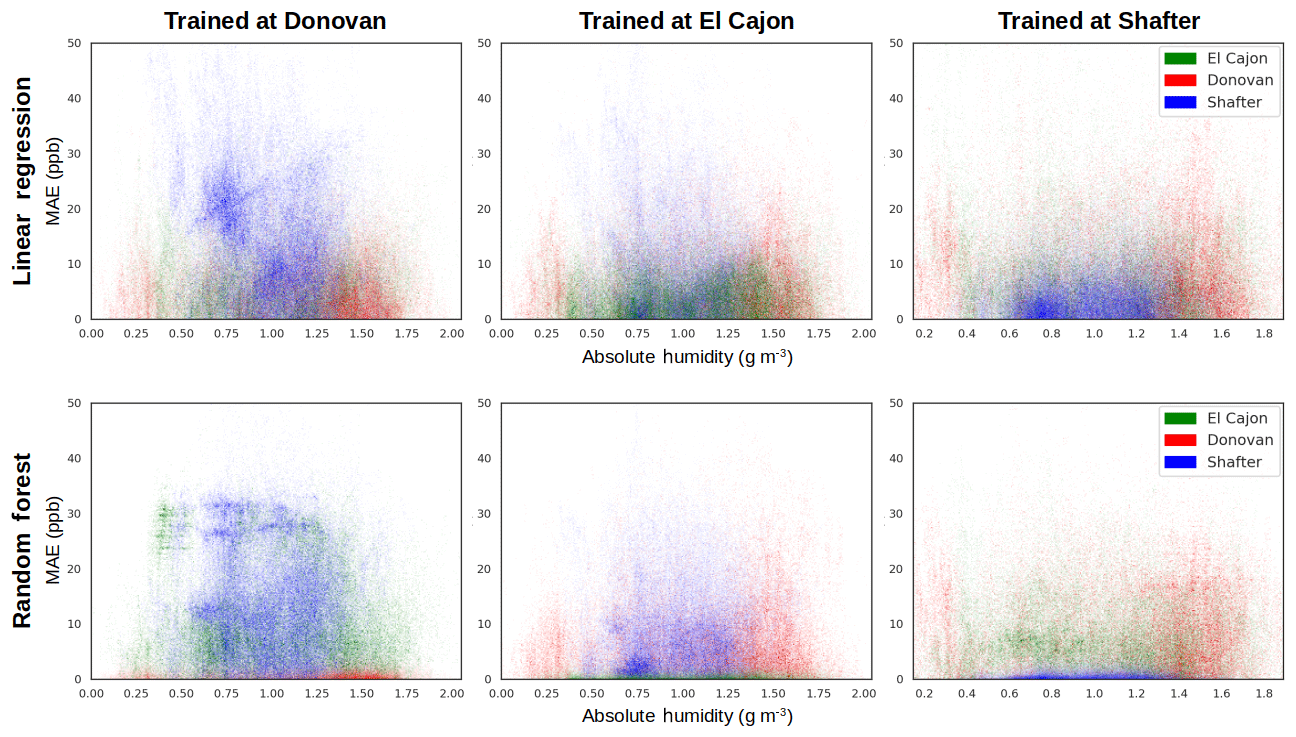
Figure 8Error density plots for O3 versus normalized absolute humidity for both linear regression (LR) and random forest (RF) in a Level 1 benchmark.
3.2 Benefits of sharing data across sensor packages
In this section, we evaluate the split-NN model architecture's utility for improving the transferability of a calibration model. The novelty of the split-NN model for calibrating a board's model is its ability include (normalized) data from other boards. Given that the resources for calibration are limited, the research questions for split-NN revolve around how boards could be best distributed to available field sites. For a standard modeling technique like random forest, a board has to be placed at three sites for three rounds to experience the wide training distribution that achieves the exceptional transferability observed in the Level 3 benchmarks. However, with the split-NN model, multiple boards can be deployed for just one round, divided equally across the sites. Then the data from their boards can be normalized and shared to produce models that we hypothesize to be of similar quality to a Level 3 benchmark, but in one-third of the time, in a single round.
To help reveal the value of calibrating multiple boards at once, we performed three one-round benchmarks: one board at each of the three sites, two boards at each of the three sites, and three boards at each of the three sites. In each of these conditions, a board is trained from a single round of data and tested on the other locations, not its own. In this vein, these are all Level 1 benchmarks; thus we compare the resulting models against our Level 1 baselines. We expect the split-NN to outperform Level 1 random forest, as the inclusion of more data helps reduce bias. In the situation that there are more boards to calibrate than there are training sites, there is an opportunity to also incorporate additional data boards at the same site. We expect that a greater multiplicity of boards at each site will produce slightly better models, but with diminishing returns. We evaluated this effect by including training split-NNs with increasing numbers of boards at each site, indicated by the variants split-NN (3), split-NN (6), and split-NN (9), corresponding to having one board at each site, two boards at each site, and three boards at each site. Figure 6 depicts how the voltages collected from one board in the split-NN (9) condition are translated into predictions, both plotted against the corresponding reference data points. We perform a similar assessment with two-round (Level 2) benchmarks, still testing only on sites that a board has not been trained on. As previously, we control for the total amount of data, simulating an abbreviated deployment for the Level 2 benchmarks.
Figure 10a–b shows that the split-NN model on average has slightly lower MAE in the Level 1 benchmarks when compared to the random forest model. We see in and Fig. 10c–d that the gap widens with the Level 2 benchmark, indicating that the split-NN model is able to better capitalize on the additional data. The results also support our hypothesis that we receive diminishing returns with additional data. Detailed results are provided in Appendix D.
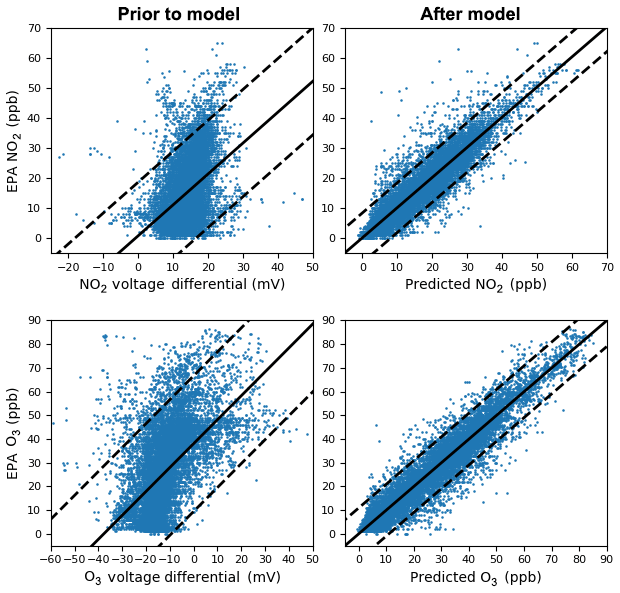
Figure 9A single board comparison (Board 12) of the relationship between the raw sensor values and target pollutant concentrations (left) and the predicted and target pollutant concentrations after the model was run (right) for the Level 1 split-NN (9) condition. The solid black line is a linear trend line and the dashed lines represent the 95th percentile.
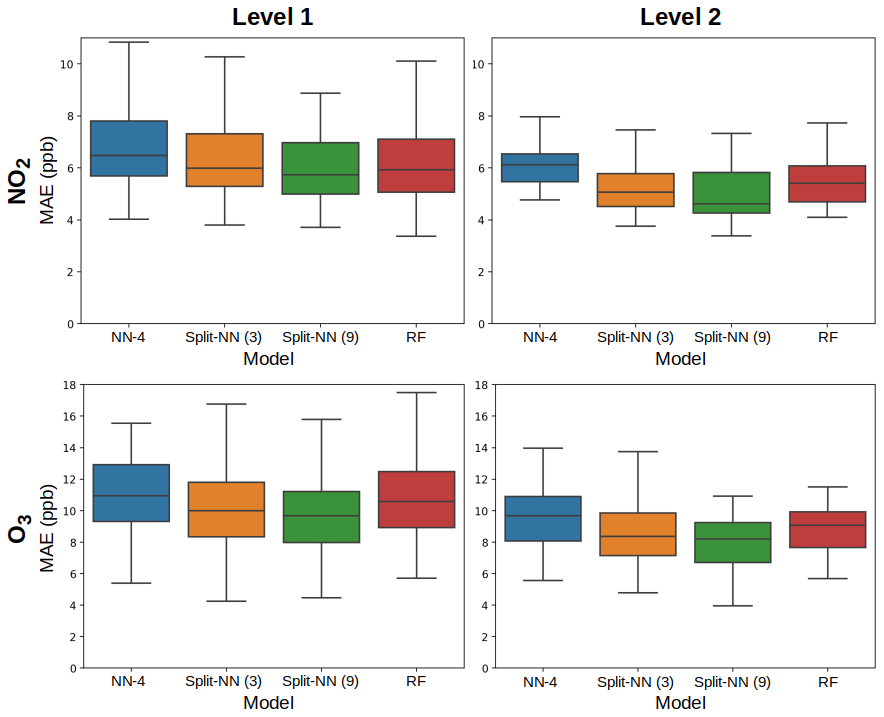
Figure 10Results of evaluating the split-NN model with a linear regression first stage, compared against the RF model in both Level 1 and Level 2 comparisons. The split-NN model has a lower mean and median error in all conditions. Boxplots are pictured without outliers for clarity.
The marginal improvement seen in the Level 1 benchmarks has two possible causes. One possibility is that the difference in behavior between sensors is nonlinear. To test this, we implemented a full neural network as the first stage. The results were comparable with a linear regression first stage with only slight improvement, suggesting that the relationship between the sensors is well represented by a linear model. The other possibility is that the pollution distributions have insufficient overlap across sites, compromising the first-stage linear regression to correct bias. The fact that using two rounds of data (Level 2) does much better suggests that this lack of overlap is a likely culprit.
3.3 Discussion
As low-cost sensor studies move from understanding sensor signal performance to how this performance is affected by moving sensors to new sampling locations or utilizing them in new applications, it is important that the results are translated into best practices to support the collection of usable high-quality data. This is particularly important given the interest in sensors by community-based organizations and citizen scientists. Although the present study examined only electrochemical O3 and NO2 sensors and the sampling sites were limited to three in California, it adds to a body of evidence that location matters in the calibration of low-cost sensors because the background environmental conditions matter. With this in mind, we make the following observations and recommendations.
We observed how prediction performance degrades when a sensor is moved to a new location, especially for high-capacity modeling techniques. In particular, training a complex random forest calibration model will likely result in relatively low error at a colocated site but can incur relatively high error at a different site. Although their predictions at a new site will have lower error than linear regression, the error they exhibit at the training site will likely not be representative of their error in practice. A linear model, on the other hand, despite not predicting as well at the training site, will not have substantially greater error at testing time. Thus, if it is important to know the likely error of your calibration model under transfer, it would be best to use a low-capacity method like linear regression.
When we drilled down to investigate the contributors to error when changing location, we found that bias error was a significant contributor in many cases. This is interesting because bias error indicates a loss of accuracy (a nonrandom additive error) rather than a loss of precision (random noise). This suggests that when moving a sensor to a new location, if the bias can somehow be detected, then it may be possible to make a bias correction to improve model performance. This result also motivates the use of the split neural network architecture, which has a model-specific correction stage that is designed to learn unbiased representations of sensor measurements.
We had expected that training at multiple sites would provide much better transferability, but the improvements were not substantial, suggesting that the high-capacity models were mostly improving due to implicit overlap in distributions and not actual generalization. This suggests that calibration should be directed at capturing the widest conditions possible, for example using many field sites with varying conditions, so as to create an overlap between the distributions of training and use. This recommendation is further supported by the observation that the Level 3 benchmarks performed nearly as well as the Level 0 benchmarks, in spite of carrying the load of a much wider distribution in the models.
The split-NN approach provides a potentially economical approach to creating overlap in distributions since sensors can share their data for calibration. That is, when calibrating multiple sensors, rather than colocating multiple sensors at a field site and rotating those sensors over time, it makes sense to distribute the sensors to as many field sites as possible to capture the widest distribution of conditions. The split-NN method has the additional benefit of being able to train a calibration model for a sensor that has never been colocated with a reference instrument. By simply colocating an uncalibrated sensor with a calibrated sensor and training the sensor-specific model to match the intermediate output of the calibrated sensor, the uncalibrated sensor can leverage the same global calibration model. More study will be required to see how well the split-NN approach scales as the training data distribution increases and to determine the bounds on calibration without reference colocation.
As low-cost gas-phase sensors are increasingly being adopted for citizen science efforts and community-based studies, there is a need to better understand what contributes to accurate sensing. A key question is how a change in background environmental or pollutant conditions, often unique to a location, affects accuracy. A rotating deployment strategy enabled benchmarking the transferability of models and investigating how to improve accuracy.
For our setting and conditions, we found the following.
-
Model error increased under transfer for all the modeling techniques investigated, demonstrating that overfitting is a concern. The effects are most dramatic when transferring high-capacity models like random forest that are trained with data that will not be representative of the conditions of use. The lower-capacity linear regression method deteriorated much less. This suggests that the predicted model error for linear regression will be more accurate under transfer, making it attractive when knowing the predicted error is important for the intended application.
-
Tantalizingly, much of the error introduced by transfer was bias. Given the simple structure of bias error, this suggests that transferability might be increased by detecting and correcting for bias.
-
When multiple sensors based on the same technology are being trained at the same time, we found that a split neural network architecture modestly decreases prediction error under transfer by giving a sensor's model access to normalized data from other sensors at other locations, hence widening the distribution without requiring additional data collection. Depending on the training configuration, compared to random forest the split-NN method reduced error 0 %–11 % for NO2 and 6 %–13 % for O3. This method also enables calibrating new sensors against existing calibrated sensors at increased cost.
-
For all the modeling techniques investigated, widening the data distribution proved a good strategy to reduce prediction error under transfer, even for the lower-capacity linear regression method. Notably, markedly better results were achieved when the training distribution contained the distribution encountered in use. In other words, for the setting and conditions investigated, training with representative data trumped algorithms.
In the future work we will be extending this work to answer open questions that we believe are relevant to the future of low-cost sensor calibration. One, the split neural network method underperformed our expectations, so we believe techniques of this sort warrant additional investigation. Two, there are questions about the effect of temporal resolution on accuracy. Currently, our MetaSense sensors are sampled every 5 s, but the ground-truth data provided from reference monitors is minute-averaged. By averaging our own sensor measurements every minute, we discard data that could be relevant for calibration. Recent advances in recurrent neural networks for sequence prediction might help leverage the high-resolution data for more robust prediction. On the other hand, noise will be more of a factor at this resolution, and the sensor can take up to 30 s to stabilize in new environmental conditions (See Sect. 2.1.1). Three, a potential application of low-cost sensing is truly mobile sensing with person- or vehicle-mounted sensors. Deployments such as these will raise questions about the effects of mobility on sensing accuracy, such as rapidly changing conditions, with few studies to date (Arfire et al., 2016). Finally, we will be examining the possible use of infrastructure data (e.g., knowledge of pollution sources) to infer the likelihood of specific pollutants, providing the potential to control for cross sensitivity.
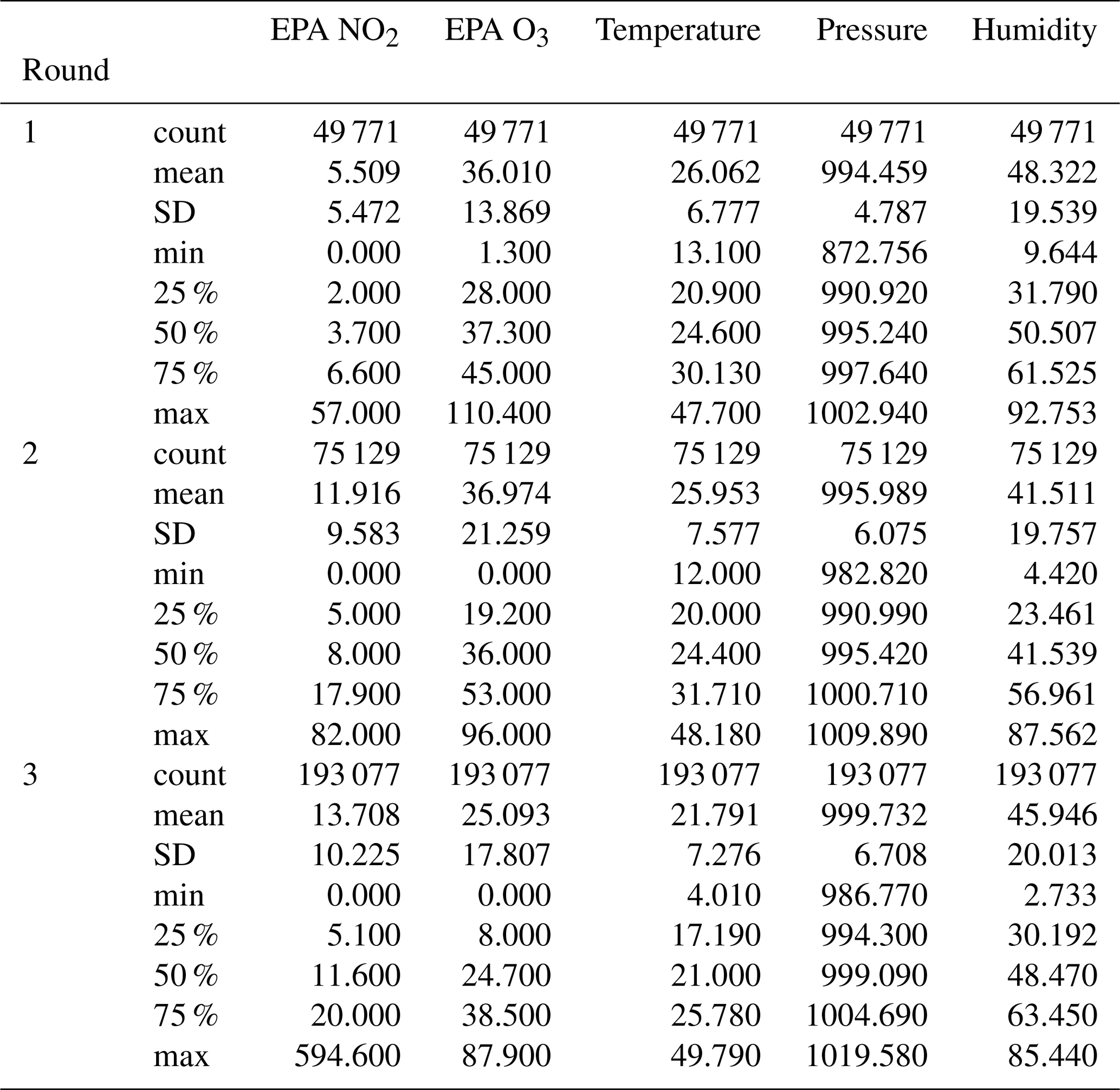
The following graphs summarize the distributions of pollutants and environment variables provided from the reference sensors at the three sites during the three rounds of the study. Each bar represents the total proportion of measurements at the given temperature or humidity (a histogram plot). The lines are a visualization of the kernel density estimation of the raw measurements.


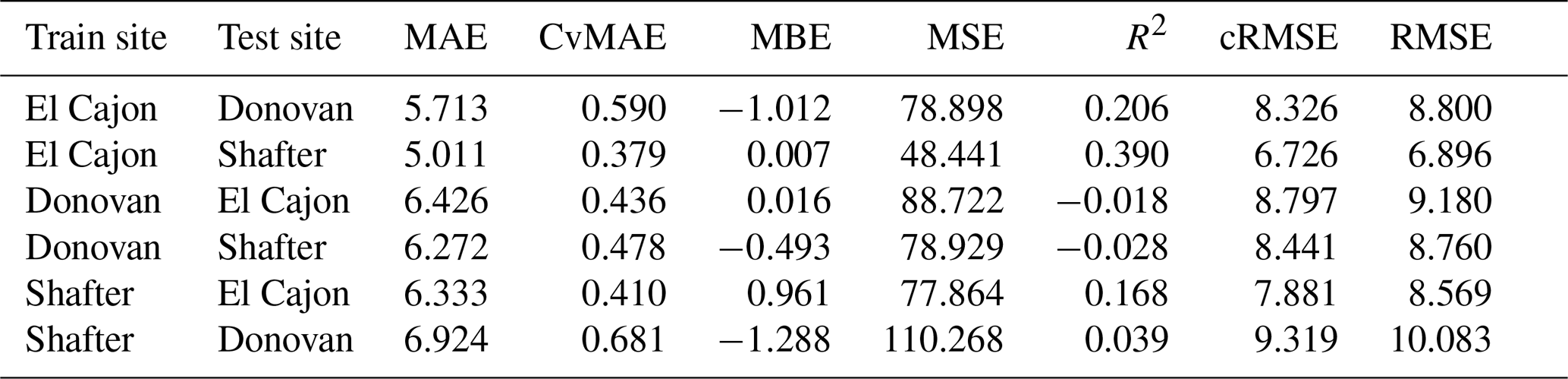
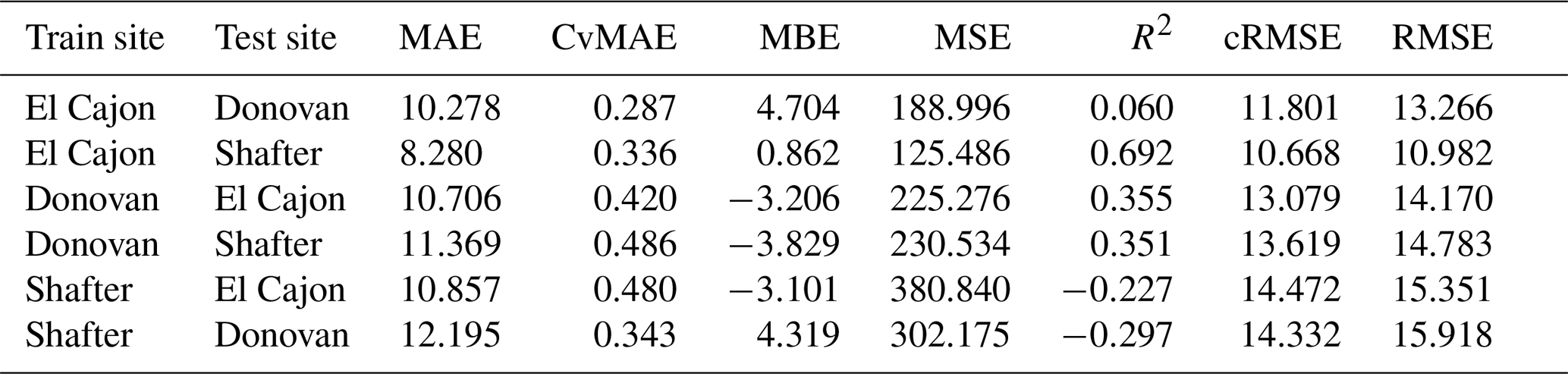
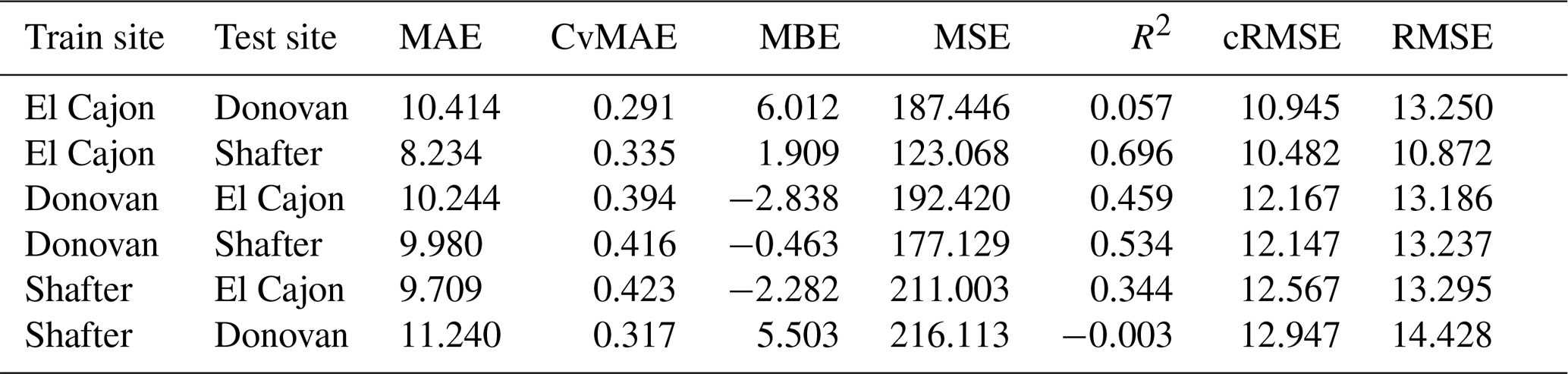
The following tables are the complete error results for the baseline models across the various conditions. In these tables, the modeling methods are labeled as MLR for multiple linear regression, NN-2 for the two-layer neural network, NN-4 for the four-layer neural network, and RF for random forest, as described in Sect. 2.5. Likewise, the error measures are labeled as MAE for mean absolute error, CvMAE for coefficient of variation of the mean absolute error, MBE for mean bias error, MSE for mean standard error, R2 for the coefficient of determination, cRMSE for centered root mean square error, and RMSE for root mean squared error. MSE is reported in parts per billion squared. All other errors are reported in parts per billion. CvMAE and R2 are dimensionless. The results are disaggregated by train and test sites and averaged across the sensor packages.
Table C1Level 0 train results for NO2 (train and test on the same data set).
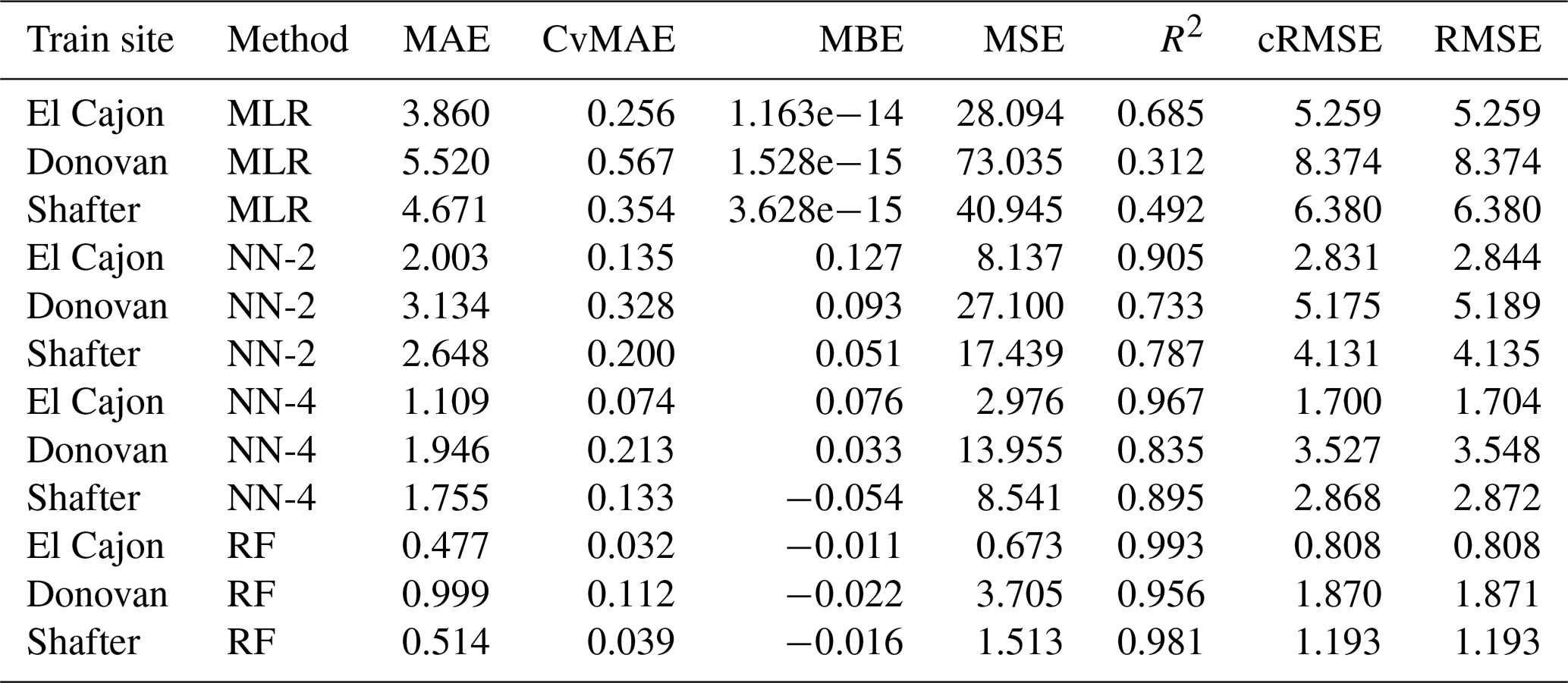
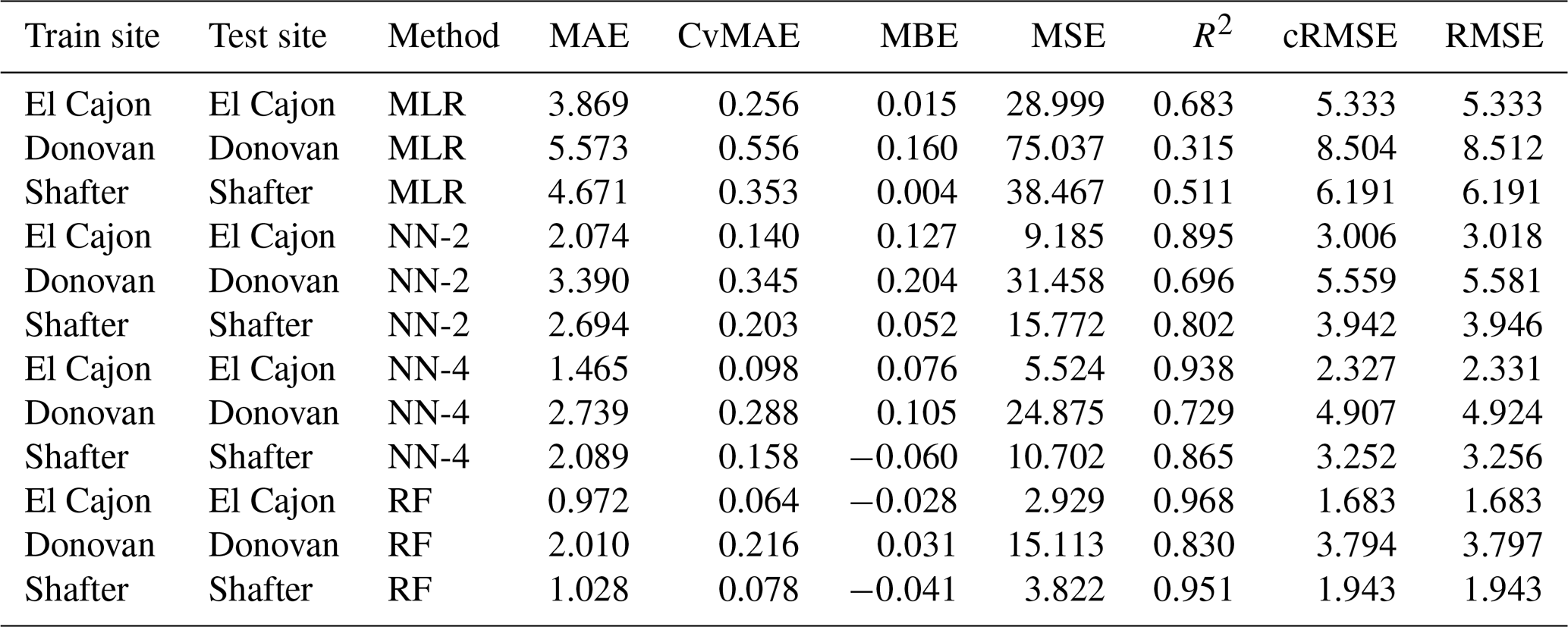
Table C3Level 0 train results for O3 (train and test on the same data set).
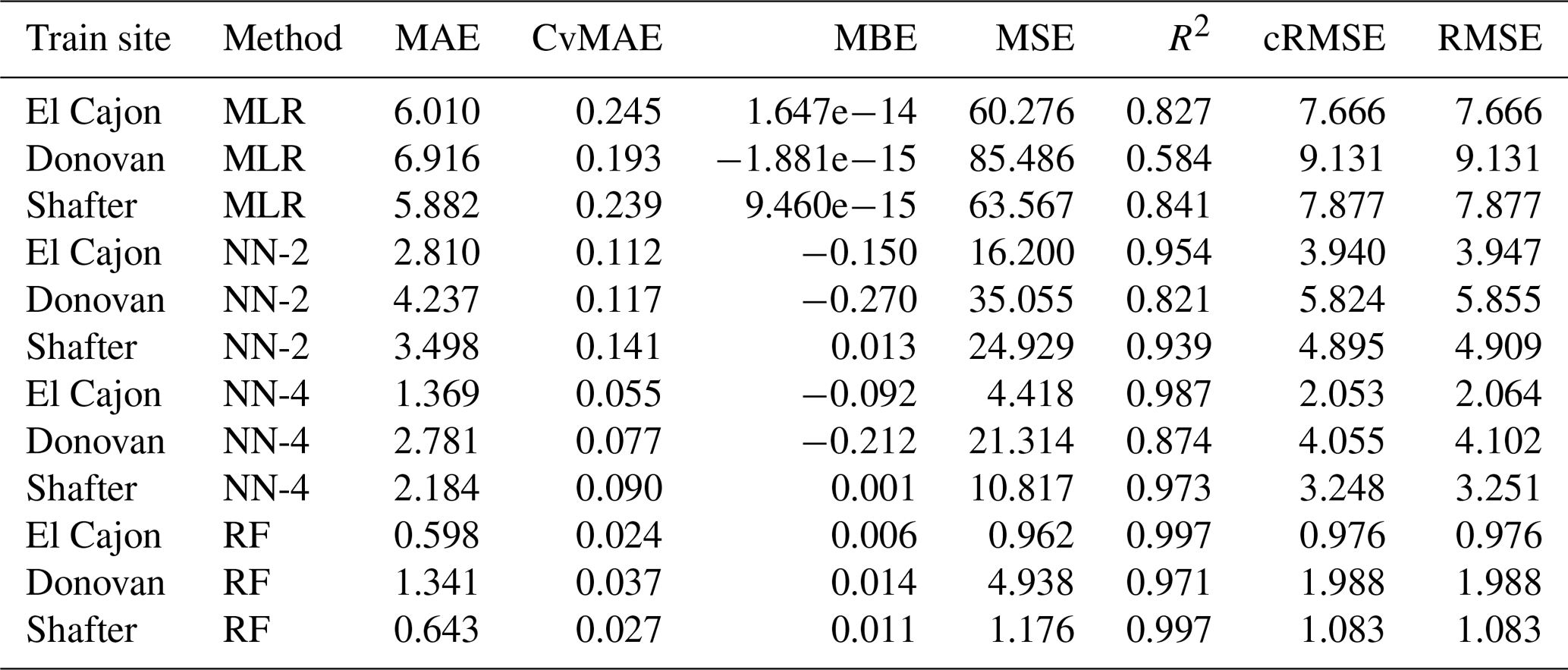
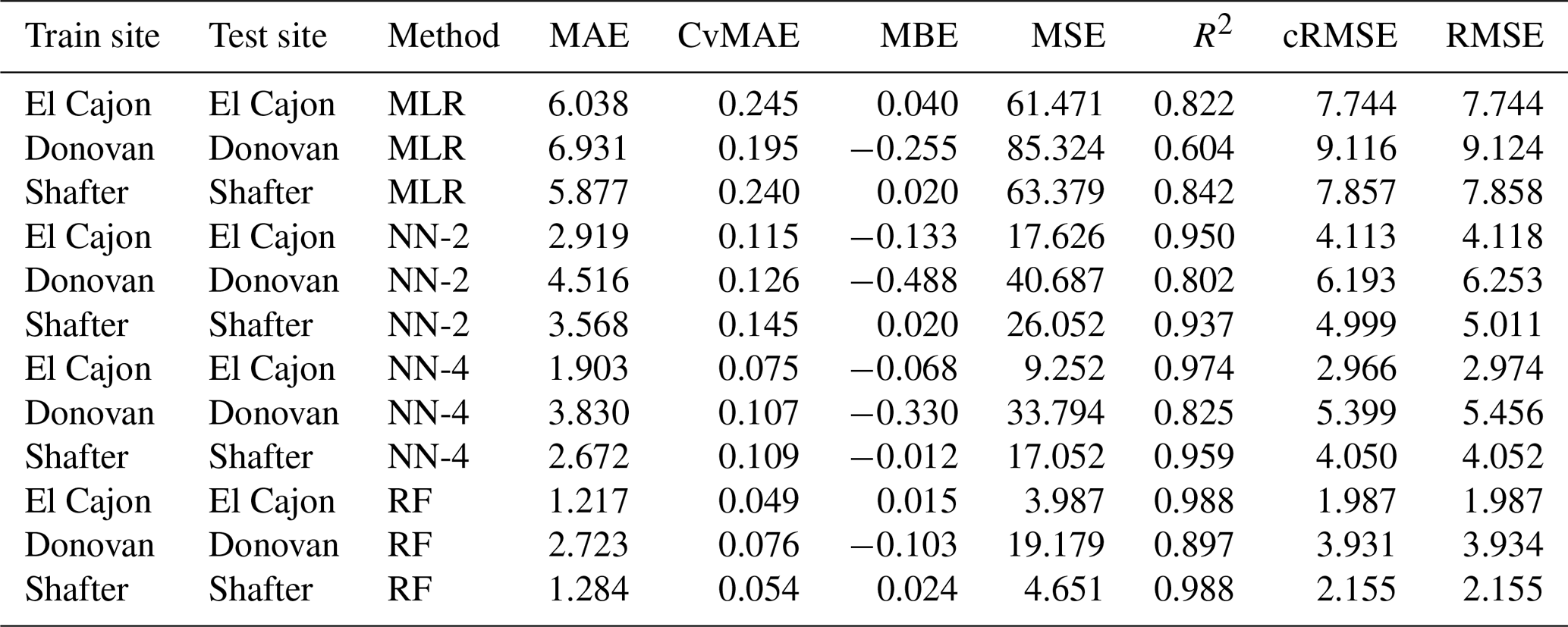
Table C5Level 1 train results for NO2 (train and test on the same data set).
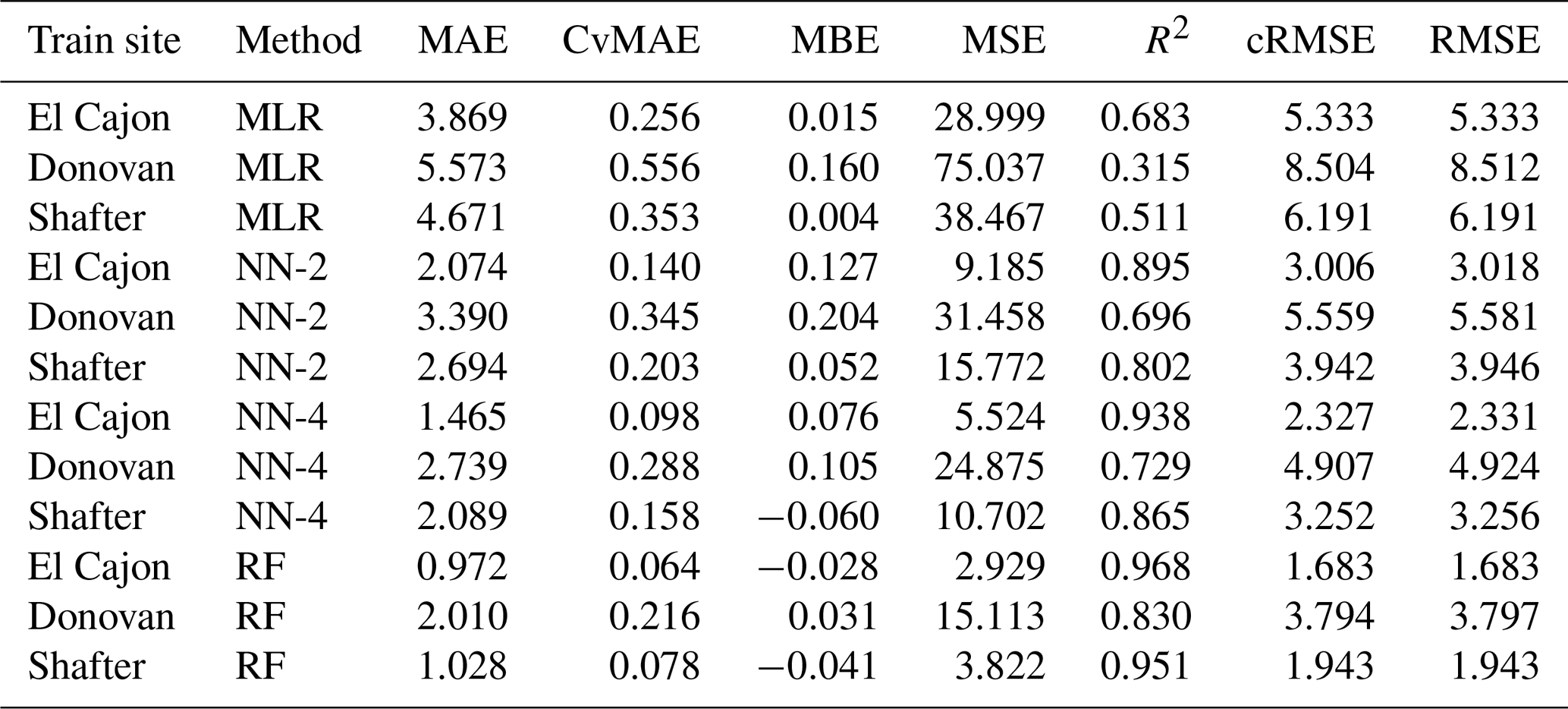
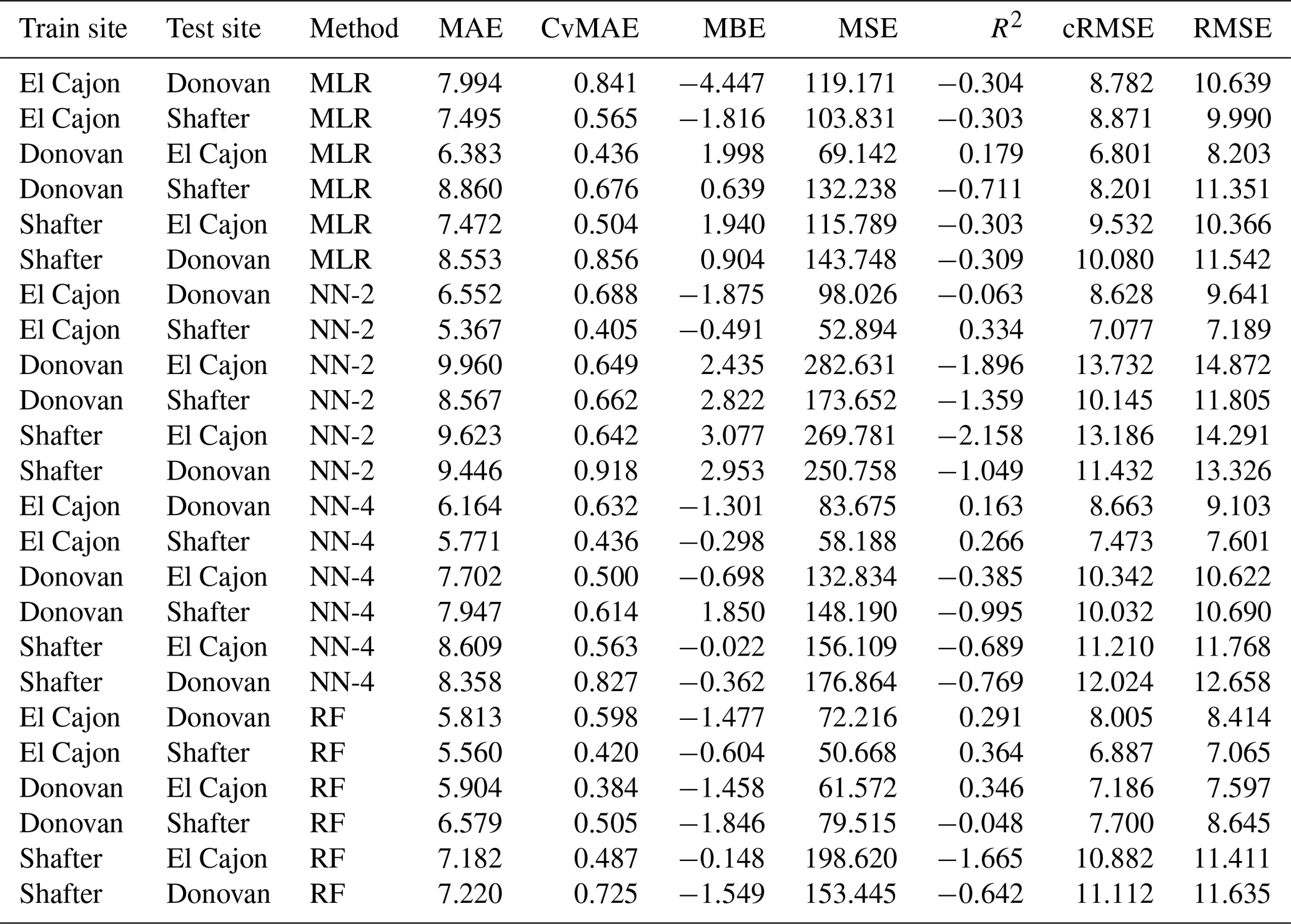
Table C7Level 1 train results for O3 (train and test on the same data set).
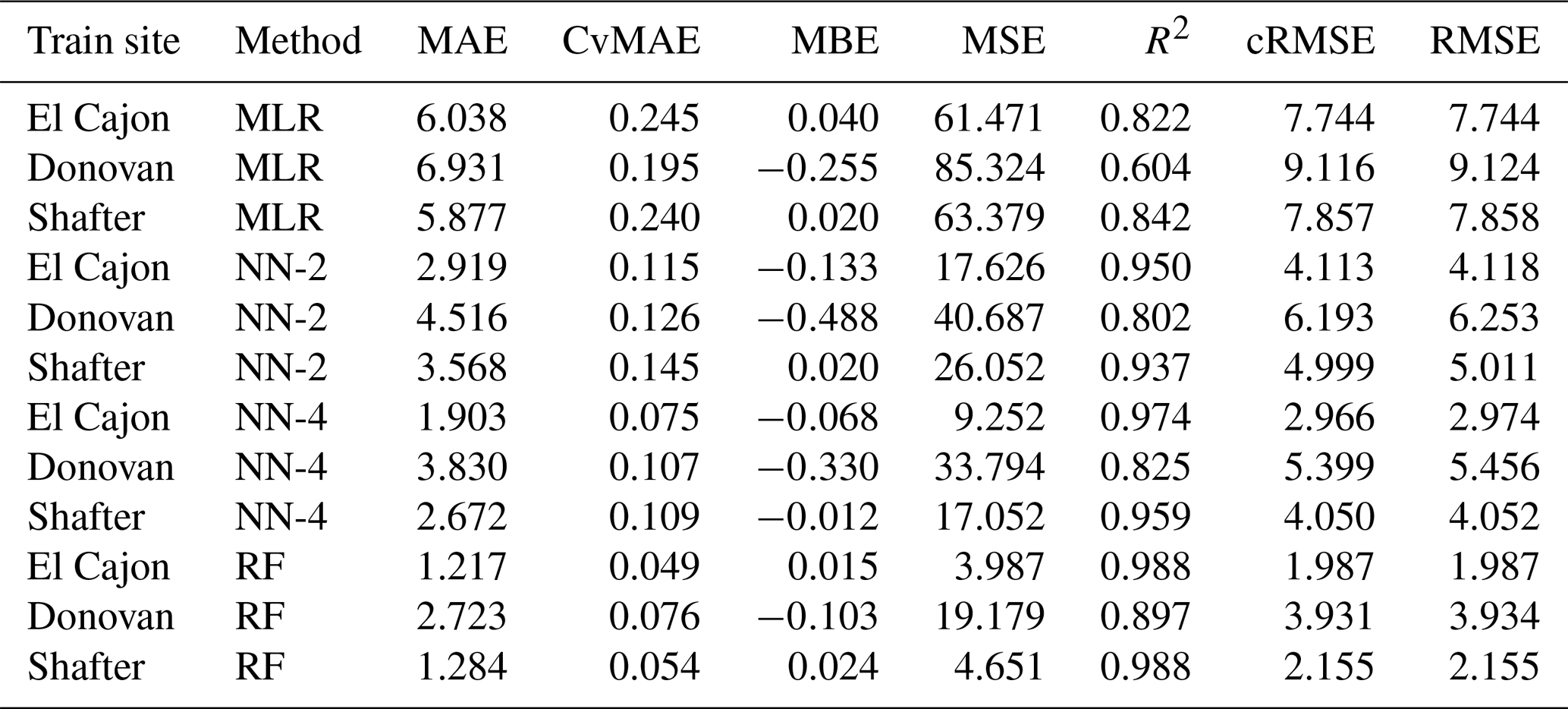
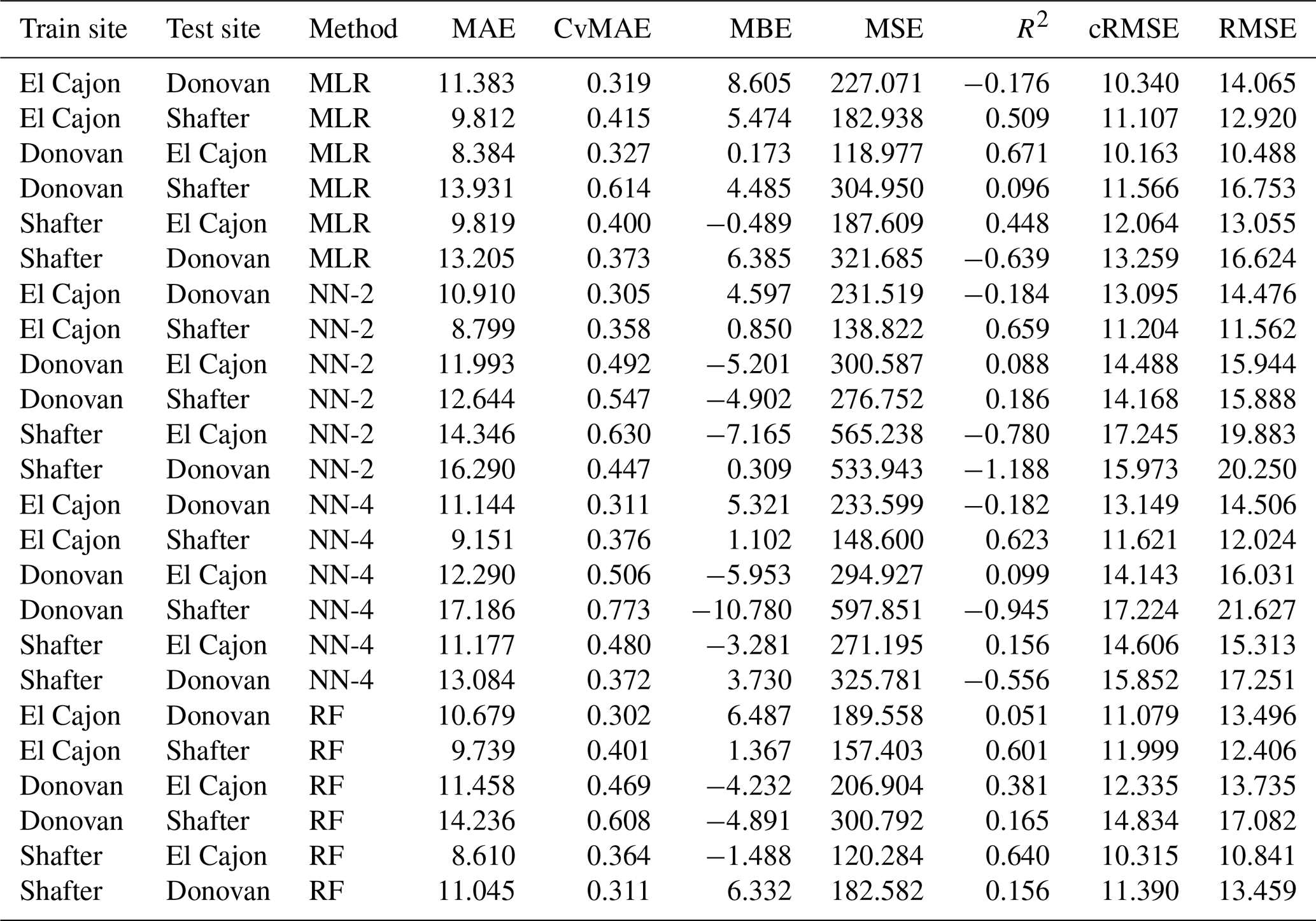
Table C9Level 2 train results for NO2 (train and test on the same data set).
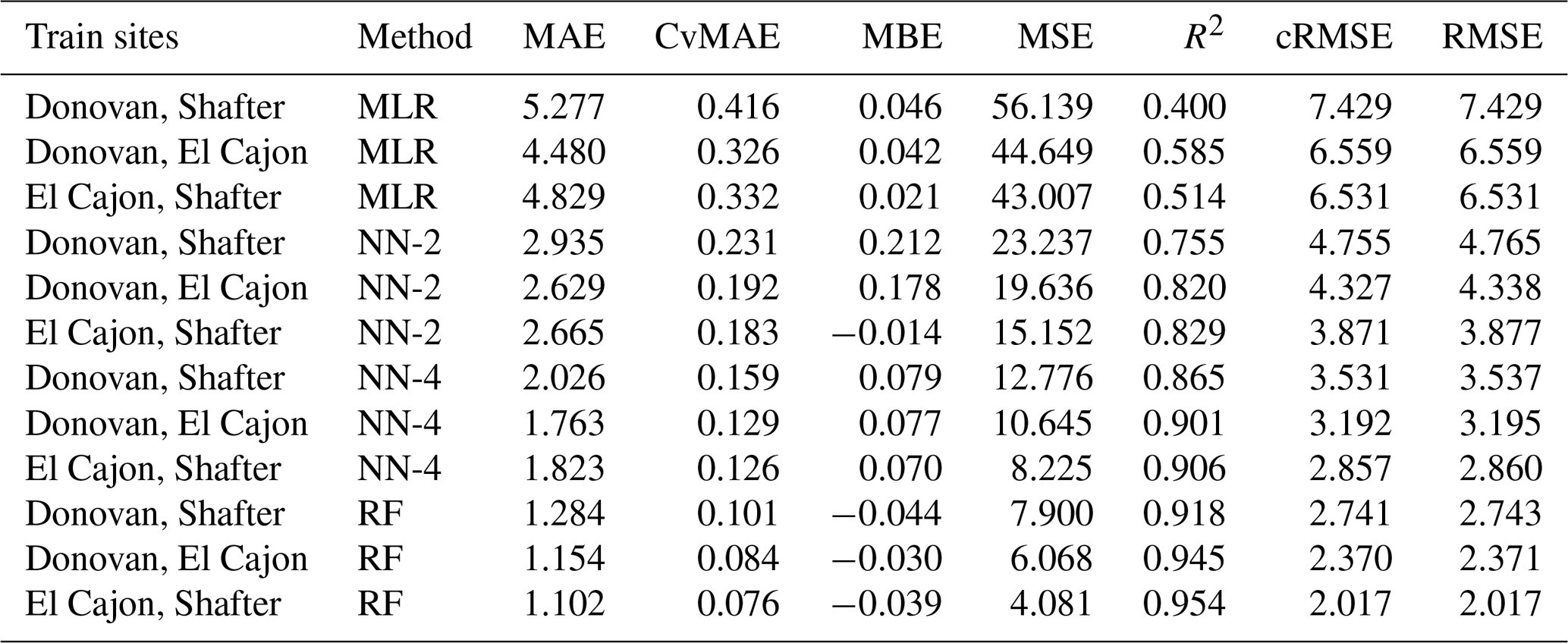
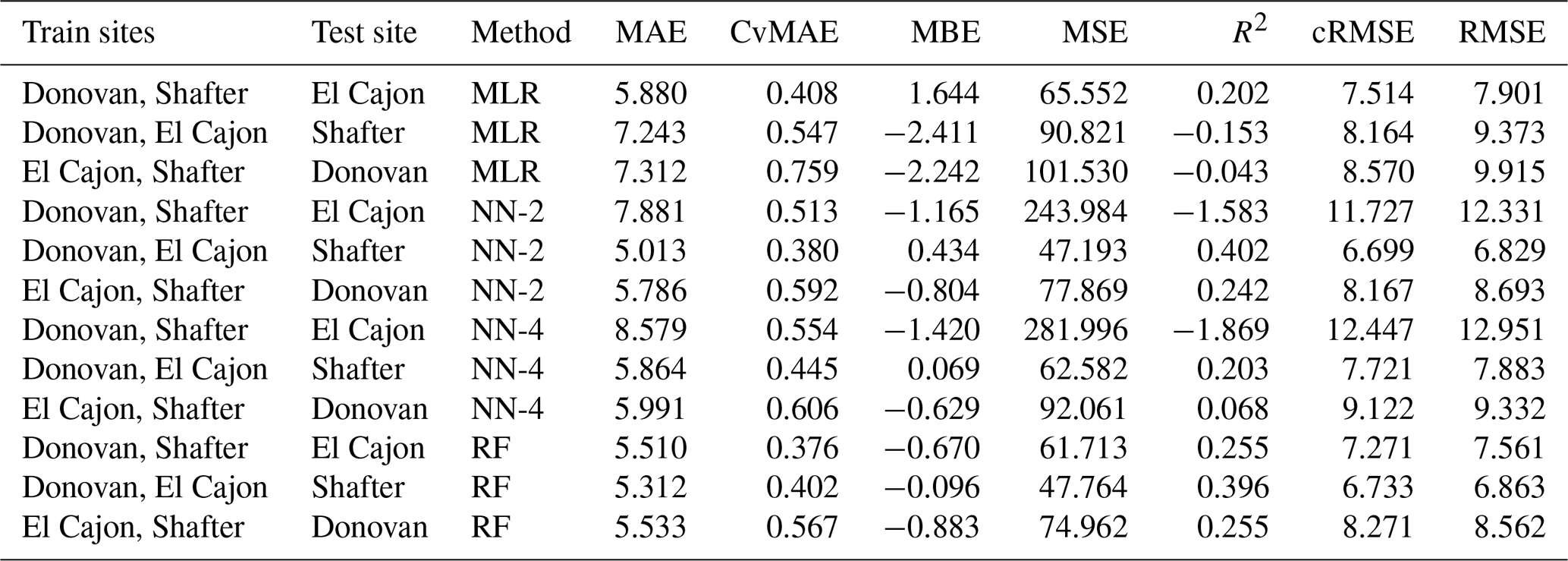
Table C11Level 2 train results for O3 (train and test on the same data set).
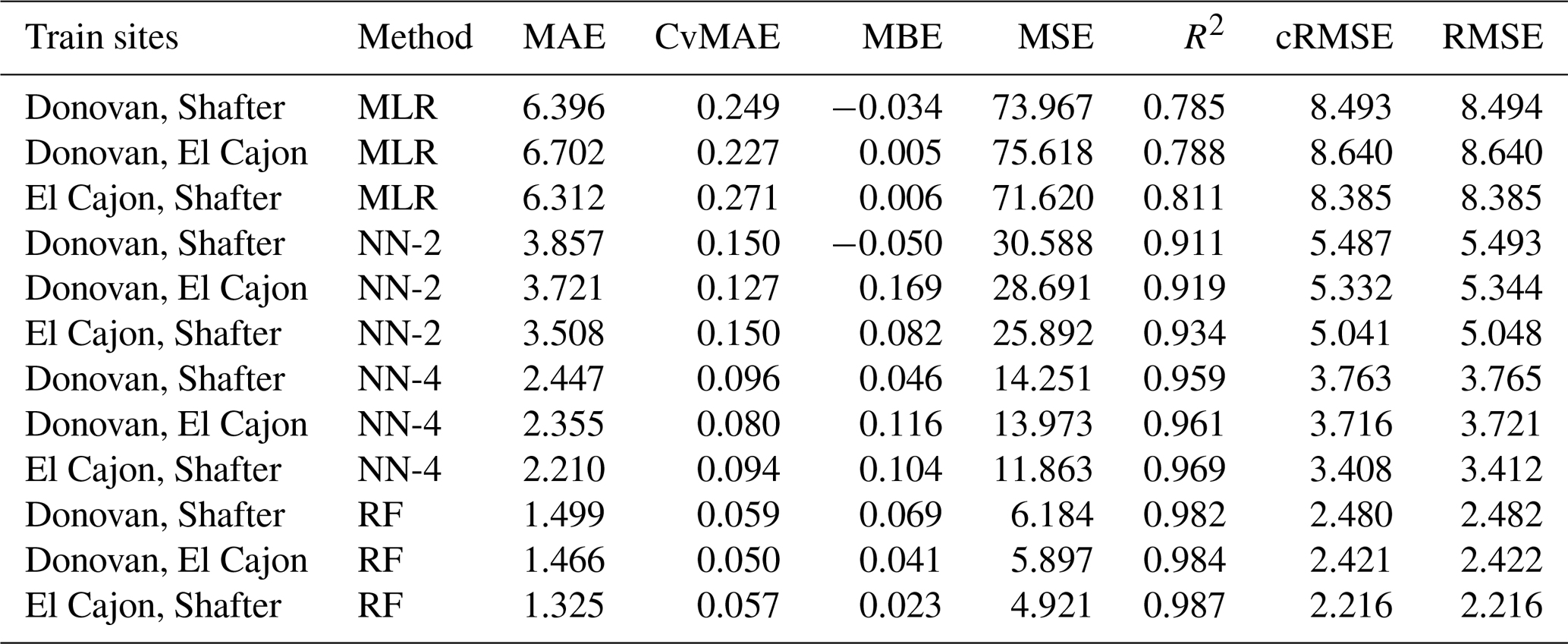
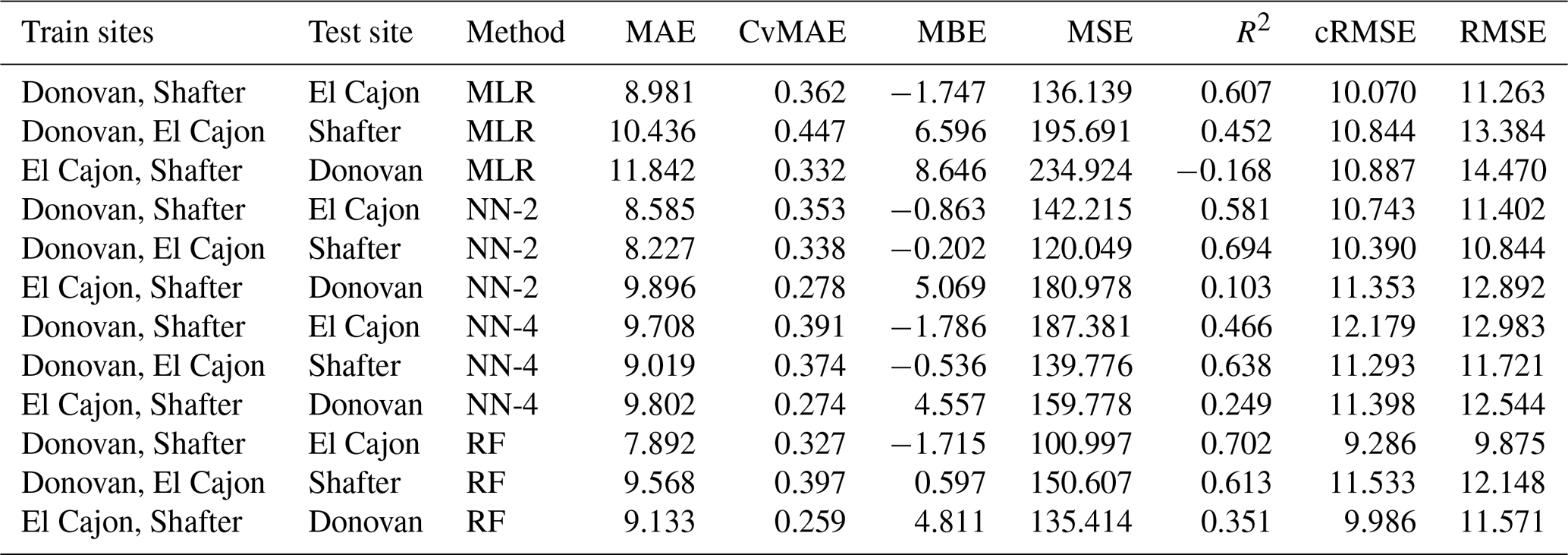
Table C13Level 3 train results for NO2 (train and test on the same data set).

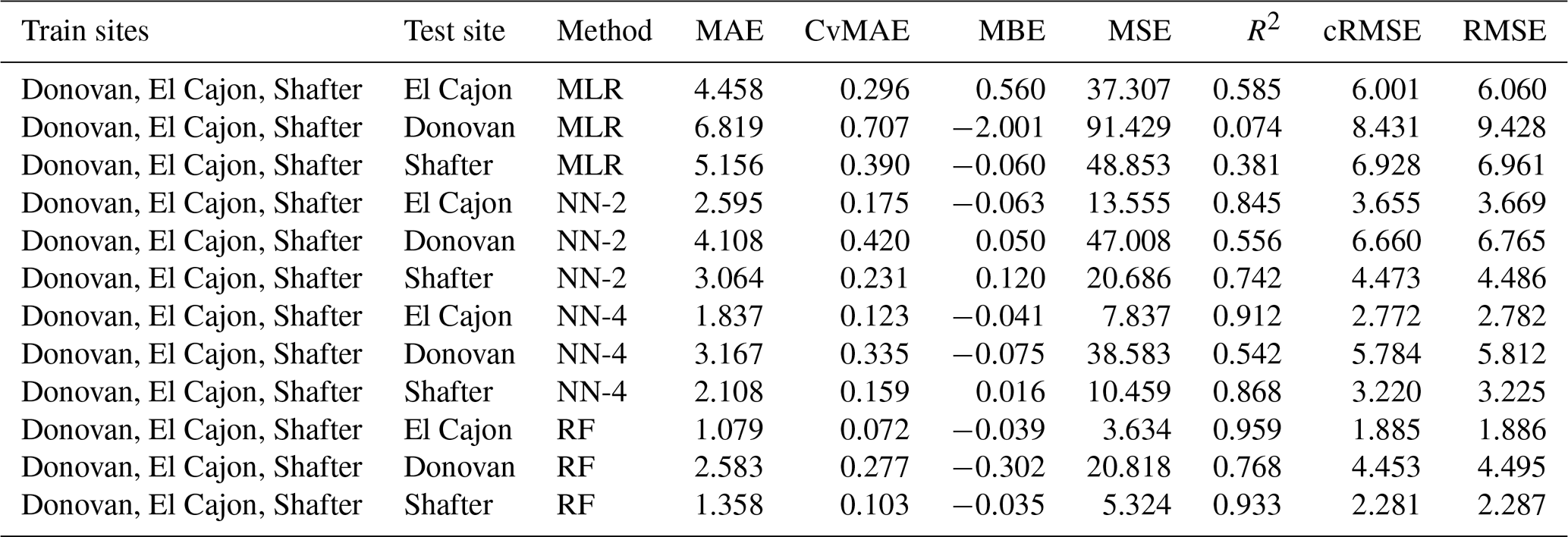
Table C15Level 3 train results for O3 (train and test on the same data set).

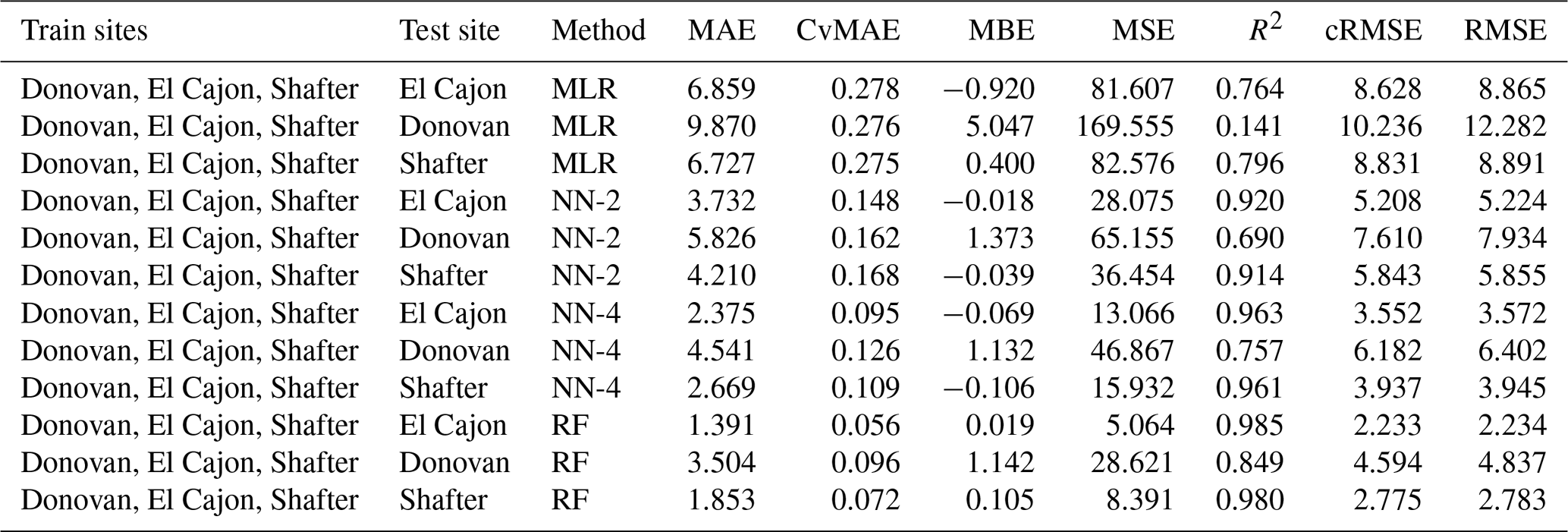
The following tables are error results for the split-NN models of size 3 and size 9. The error measures are labeled as MAE for mean absolute error, CvMAE for coefficient of variation of the mean absolute error, MBE for mean bias error, MSE for mean standard error, R2 for the coefficient of determination, cRMSE for centered root mean square error, and RMSE for root mean squared error. The results are disaggregated by train and test sites and averaged across the sensor packages. However, because these are split models, both the global model and the board-specific models are trained on all the sites. However, the trained board was not placed at the test site during training.
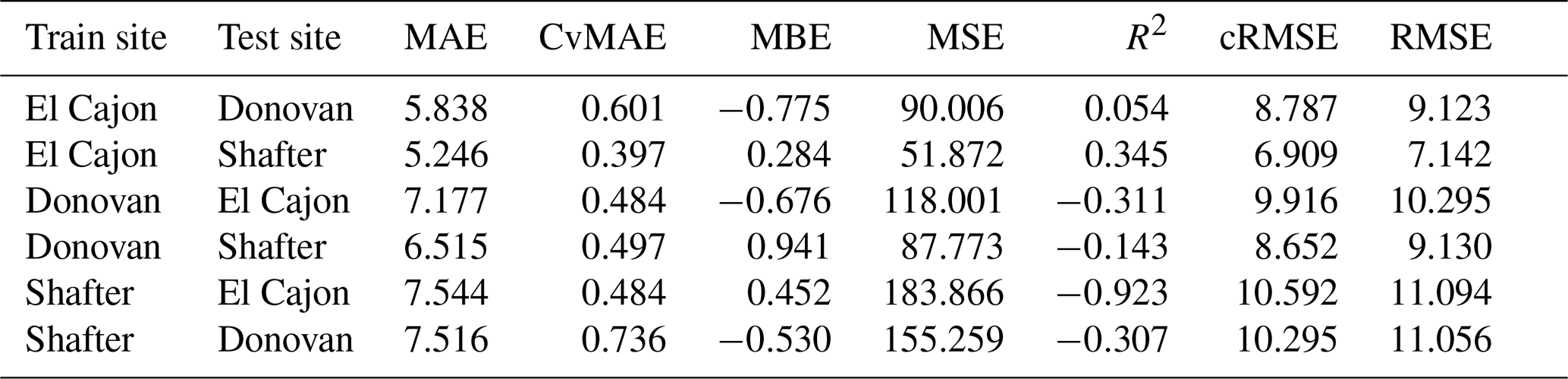




Our hardware designs, software, and raw collected data are archived on GitHub at https://github.com/metasenseorg/MetaSense (last access: 6 June 2019). The reference data used for analysis were provided courtesy of the San Diego Air Pollution Control District and the San Joaquin Valley Air Pollution Control District. These data have not passed through the normal review process and are therefore not quality-assured, and they are thus unofficial data.
SV, ACO, MHO, and MM contributed to the research design, experiments, analysis, and writing of the paper. CC helped with the experiments and analysis. SD, TR, and MH helped with the research design and analysis. WGG contributed to the research design, analysis, and writing of the paper.
The authors declare that they have no conflict of interest.
This material is based upon work supported by the National Science Foundation under grant nos. CNS-1446912 and CNS-1446899. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. We would also like to thank partners at the San Diego Air Pollution Control District as well as San Joaquin Valley Air Pollution Control District for their support throughout this deployment.
This research has been supported by the National Science Foundation, Division of Computer and Network Systems (grant no. 1446912), and the National Science Foundation (grant no. CNS-1446899) and King Abdulaziz City for Science and Technology (KACST).
This paper was edited by Francis Pope and reviewed by Christine Braban and one anonymous referee.
AQI: Uniform Air Quality Index (AQI) and Daily Reporting, 40 C.F.R. Appendix G to Part 58, 2015. a
Arfire, A., Marjovi, A., and Martinoli, A.: Mitigating Slow Dynamics of Low-Cost Chemical Sensors for Mobile Air Quality Monitoring Sensor Networks, in: Proceedings of the 2016 International Conference on Embedded Wireless Systems and Networks, pp. 159–167, Junction Publishing, Graz, 2016. a
Bigi, A., Mueller, M., Grange, S. K., Ghermandi, G., and Hueglin, C.: Performance of NO, NO2 low cost sensors and three calibration approaches within a real world application, Atmos. Meas. Tech., 11, 3717–3735, https://doi.org/10.5194/amt-11-3717-2018, 2018. a, b, c, d
Brunekreef, B. and Holgate, S. T.: Air pollution and health, Lancet, 360, 1233–1242, 2002. a
Casey, J., Collier-Oxandale, A., and Hannigan, M.: Performance of artificial neural networks and linear models to quantify 4 trace gas species in an oil and gas production region with low-cost sensors, Sens. Actuators B, submitted, 2018. a
Casey, J. G. and Hannigan, M. P.: Testing the performance of field calibration techniques for low-cost gas sensors in new deployment locations: across a county line and across Colorado, Atmos. Meas. Tech., 11, 6351–6378, https://doi.org/10.5194/amt-11-6351-2018, 2018. a, b, c, d
Castell, N., Dauge, F. R., Schneider, P., Vogt, M., Lerner, U., Fishbain, B., Broday, D., and Bartonova, A.: Can commercial low-cost sensor platforms contribute to air quality monitoring and exposure estimates?, Environ. Int., 99, 293–302, https://doi.org/10.1016/j.envint.2016.12.007, 2017. a, b, c
Chan, C. S., Ostertag, M. H., Akyürek, A. S., and Rosing, T. Š.: Context-aware system design, in: Micro-and Nanotechnology Sensors, Systems, and Applications IX, 10194, 101940B, International Society for Optics and Photonics, Anaheim, 2017. a
Clements, A. L., Griswold, W. G., RS, A., Johnston, J. E., Herting, M. M., Thorson, J., Collier-Oxandale, A., and Hannigan, M.: Low-Cost Air Quality Monitoring Tools: From Research to Practice (A Workshop Summary), Sensors, 17, 11, https://doi.org/10.3390/s17112478, 2017. a
Cross, E. S., Williams, L. R., Lewis, D. K., Magoon, G. R., Onasch, T. B., Kaminsky, M. L., Worsnop, D. R., and Jayne, J. T.: Use of electrochemical sensors for measurement of air pollution: correcting interference response and validating measurements, Atmos. Meas. Tech., 10, 3575–3588, https://doi.org/10.5194/amt-10-3575-2017, 2017. a, b, c
De Vito, S., Piga, M., Martinotto, L., and Di Francia, G.: CO, NO2, and NOx urban pollution monitoring with on-field calibrated electronic nose by automatic bayesian regularization, Sensor. Actuat. B-Chem., 143, 182–191, https://doi.org/10.1016/j.snb.2009.08.041, 2009. a
English, P. B., Olmedo, L., Bejarano, E., Lugo, H., Murillo, E., Seto, E., Wong, M., King, G., Wilkie, A., Meltzer, D., Carvlin, G., Jerrett, M., and Northcross, A.: The Imperial County Community Air Monitoring Network: a model for community-based environmental monitoring for public health action, Environ. Health Perspect., 125, 7, 2017. a, b
Fonollosa, J., Fernandez, L., Gutiérrez-Gálvez, A., Huerta, R., and Marco, S.: Calibration transfer and drift counteraction in chemical sensor arrays using Direct Standardization, Sensor. Actuat. B-Chem., 236, 1044–1053, 2016. a
Goodfellow, I., Bengio, Y., and Courville, A.: Deep Learning, MIT Press, available at: http://www.deeplearningbook.org (last access: 6 June 2019), 2016. a, b
Hagan, D. H., Isaacman-VanWertz, G., Franklin, J. P., Wallace, L. M. M., Kocar, B. D., Heald, C. L., and Kroll, J. H.: Calibration and assessment of electrochemical air quality sensors by co-location with regulatory-grade instruments, Atmos. Meas. Tech., 11, 315–328, https://doi.org/10.5194/amt-11-315-2018, 2018. a, b, c
Jerrett, M., Donaire-Gonzalez, D., Popoola, O., Jones, R., Cohen, R. C., Almanza, E., Nazelle, A. D., Mead, I., Carrasco-Turigas, G., Cole-Hunter, T., Trigueromas, M., Seto, E., and Nieuwenhuijsen, M.: Validating novel air pollution sensors to improve exposure estimates for epidemiological analyses and citizen science, Environ. Res., 158, 286–294, https://doi.org/10.1016/j.envres.2017.04.023, 2017. a
Malings, C., Tanzer, R., Hauryliuk, A., Kumar, S. P. N., Zimmerman, N., Kara, L. B., Presto, A. A., and R. Subramanian: Development of a general calibration model and long-term performance evaluation of low-cost sensors for air pollutant gas monitoring, Atmos. Meas. Tech., 12, 903–920, https://doi.org/10.5194/amt-12-903-2019, 2019. a, b, c
Monn, C., Carabias, V., Junker, M., Waeber, R., Karrer, M., and Wanner, H.-U.: Small-scale spatial variability of particulate matter <10 µm (PM10) and nitrogen dioxide, Atmos. Environ., 31, 2243–2247, 1997. a
Piedrahita, R., Xiang, Y., Masson, N., Ortega, J., Collier, A., Jiang, Y., Li, K., Dick, R. P., Lv, Q., Hannigan, M., and Shang, L.: The next generation of low-cost personal air quality sensors for quantitative exposure monitoring, Atmos. Meas. Tech., 7, 3325–3336, https://doi.org/10.5194/amt-7-3325-2014, 2014. a, b
Sadighi, K., Coffey, E., Polidori, A., Feenstra, B., Lv, Q., Henze, D. K., and Hannigan, M.: Intra-urban spatial variability of surface ozone in Riverside, CA: viability and validation of low-cost sensors, Atmos. Meas. Tech., 11, 1777–1792, https://doi.org/10.5194/amt-11-1777-2018, 2018. a, b, c
San Joaquin Valley Air Pollution Control District: 2016 Plan for the 2008 8-Hour Ozone Standard, Appendix A, available at: http://valleyair.org/Air_Quality_Plans/Ozone-Plan-2016/a.pdf (last access: 6 June 2019), 2016. a
Shina, D. N. and Canter, A.: Annual Air Quality Monitoring Network Plan 2016, available at: https://www.sdapcd.org/content/dam/sdc/apcd/monitoring/2016_Network_Plan.pdf (last access: 6 June 2019), 2016. a, b, c, d
SJVAPCD Website: Shafter | Valley Air District, available at: http://community.valleyair.org/selected-communities/shafter/, last access: 5 June 2019. a
Smith, K. R., Edwards, P. M., Evans, M. J., Lee, J. D., Shaw, M. D., Squires, F., Wilde, S., and Lewis, A. C.: Clustering approaches to improve the performance of low cost air pollution sensors, Faraday Discuss.s, 200, 621–637, 2017. a
Snyder, E. G., Watkins, T. H., Solomon, P. A., Thoma, E. D., Williams, R. W., Hagler, G. S., Shelow, D., Hindin, D. A., Kilaru, V. J., and Preuss, P. W.: The changing paradigm of air pollution monitoring, Environ. Sci. Technol., 47, 11369, 2013. a
Solórzano, A., Rodriguez-Perez, R., Padilla, M., Graunke, T., Fernandez, L., Marco, S., and Fonollosa, J.: Multi-unit calibration rejects inherent device variability of chemical sensor arrays, Sensor. Actuat. B-Chem., 265, 142–154, 2018. a
Spinelle, L., Gerboles, M., Villani, M. G., Aleixandre, M., and Bonavitacola, F.: Calibration of a cluster of low-cost sensors for the measurement of air pollution in ambient air, Sensors, 21–24, 2014. a, b
Spinelle, L., Gerboles, M., and Aleixandre, M.: Performance Evaluation of Amperometric Sensors for the Monitoring of O3 and NO2 in Ambient Air at ppb Level, Procedia Engineer., 120, 480–483, https://doi.org/10.1016/j.proeng.2015.08.676, 2015a. a
Spinelle, L., Gerboles, M., Villani, M. G., Aleixandre, M., and Bonavitacola, F.: Field calibration of a cluster of low-cost available sensors for air quality monitoring, Part A: Ozone and nitrogen dioxide, Sensor. Actuat. B-Chem., 215, 249–257, 2015b. a, b, c, d
Spinelle, L., Gerboles, M., Villani, M. G., Aleixandre, M., and Bonavitacola, F.: Field calibration of a cluster of low-cost commercially available sensors for air quality monitoring, Part B: NO, CO and CO2, Sensor. Actuat. B-Chem., 238, 706–715, https://doi.org/10.1016/j.snb.2016.07.036, 2017. a, b, c, d
Wheeler, A. J., Smith-Doiron, M., Xu, X., Gilbert, N. L., and Brook, J. R.: Intra-urban variability of air pollution in Windsor, Ontario—measurement and modeling for human exposure assessment, Environ. Res., 106, 7–16, 2008. a
Wilson, J. G., Kingham, S., Pearce, J., and Sturman, A. P.: A review of intraurban variations in particulate air pollution: Implications for epidemiological research, Atmos. Environ., 39, 6444–6462, 2005. a
Wu, X., Fan, Z., Zhu, X., Jung, K., Ohman-Strickland, P., Weisel, C., and Lioy, P.: Exposures to volatile organic compounds (VOCs) and associated health risks of socio-economically disadvantaged population in a “hot spot” in Camden, New Jersey, Atmos. Environ., 57, 72–79, 2012. a
Yan, K. and Zhang, D.: Improving the transfer ability of prediction models for electronic noses, Sensor. Actuat. B-Chem., 220, 115–124, 2015. a
Zhang, L., Tian, F., Kadri, C., Xiao, B., Li, H., Pan, L., and Zhou, H.: On-line sensor calibration transfer among electronic nose instruments for monitoring volatile organic chemicals in indoor air quality, Sensor. Actuat. B-Chem., 160, 899–909, 2011. a
Zimmerman, N., Presto, A. A., Kumar, S. P. N., Gu, J., Hauryliuk, A., Robinson, E. S., Robinson, A. L., and R. Subramanian: A machine learning calibration model using random forests to improve sensor performance for lower-cost air quality monitoring, Atmos. Meas. Tech., 11, 291–313, https://doi.org/10.5194/amt-11-291-2018, 2018. a, b, c, d, e, f, g
- Abstract
- Introduction
- Methods
- Results and discussion
- Conclusions
- Appendix A: Environment and pollutant distributions (based on reference data)
- Appendix B: Summaries of data for each location and round
- Appendix C: Raw results for the baseline calibration models
- Appendix D: Raw results for the split neural network models
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methods
- Results and discussion
- Conclusions
- Appendix A: Environment and pollutant distributions (based on reference data)
- Appendix B: Summaries of data for each location and round
- Appendix C: Raw results for the baseline calibration models
- Appendix D: Raw results for the split neural network models
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References