the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 12 Aug 2021
| 12 Aug 2021
Reduced-cost construction of Jacobian matrices for high-resolution inversions of satellite observations of atmospheric composition
Daniel J. Jacob
Joannes D. Maasakkers
Tia R. Scarpelli
Melissa P. Sulprizio
Yuzhong Zhang
Chris H. Rycroft
Global high-resolution observations of atmospheric composition from satellites can greatly improve our understanding of surface emissions through inverse analyses. Variational inverse methods can optimize surface emissions at any resolution but do not readily quantify the error and information content of the posterior solution. The information content of satellite data may be much lower than its coverage would suggest because of failed retrievals, instrument noise, and error correlations that propagate through the inversion. Analytical solution of the inverse problem provides closed-form characterization of posterior error statistics and information content but requires the construction of the Jacobian matrix that relates emissions to atmospheric concentrations. Building the Jacobian matrix is computationally expensive at high resolution because it involves perturbing each emission element, typically individual grid cells, in the atmospheric transport model used as the forward model for the inversion. We propose and analyze two methods, reduced dimension and reduced rank, to construct the Jacobian matrix at greatly decreased computational cost while retaining information content. Both methods are two-step iterative procedures that begin from an initial native-resolution estimate of the Jacobian matrix constructed at no computational cost by assuming that atmospheric concentrations are most sensitive to local emissions. The reduced-dimension method uses this estimate to construct a Jacobian matrix on a multiscale grid that maintains a high resolution in areas with high information content and aggregates grid cells elsewhere. The reduced-rank method constructs the Jacobian matrix at native resolution by perturbing the leading patterns of information content given by the initial estimate. We demonstrate both methods in an analytical Bayesian inversion of Greenhouse Gases Observing Satellite (GOSAT) methane data with augmented information content over North America in July 2009. We show that both methods reproduce the results of the native-resolution inversion while achieving a factor of 4 improvement in computational performance. The reduced-dimension method produces an exact solution at a lower spatial resolution, while the reduced-rank method solves the inversion at native resolution in areas of high information content and defaults to the prior estimate elsewhere.
- Article
(3087 KB) - Full-text XML
- BibTeX
- EndNote





Satellite observations of atmospheric composition provide a powerful resource to improve our knowledge of emissions (Streets et al., 2013). However, the inverse analyses used to infer emissions from observed atmospheric concentrations are subject to large errors from the measurements and from the inversion procedure. Conducting inverse analyses of satellite data to quantify emissions at high resolution is of considerable interest but may be limited by data quality in ways that are difficult to quantify and that may compromise the results. Here we present two methods to conduct high-resolution inversions of satellite observations that optimize the information content of the observations while providing full error statistics and minimizing computational cost.
Inverse analyses infer emissions by fitting the observed atmospheric concentrations to a chemical transport model (CTM) that simulates atmospheric concentrations as a function of emissions (Brasseur and Jacob, 2017). The CTM represents the forward model for the inverse problem. The solution is generally obtained in a Bayesian framework by minimizing a cost function regularized by a prior emissions estimate. The optimal (posterior) emissions estimate corresponds to the minimum of the cost function. This minimum is typically found using a numerical (variational) method, often employing the adjoint of the CTM to compute the cost function gradient (e.g., Daescu et al., 2000; Elbern and Schmidt, 2001; Quélo et al., 2005; Henze et al., 2007). However, the numerical solution provides no explicit characterization of the solution's error or information content. Methods of estimating the error exist (e.g., Chevallier et al., 2007; Meirink et al., 2008; Koohkan et al., 2013), but these approaches are computationally expensive, incomplete, and rarely applied in practice.
In the common case where the observed atmospheric concentrations depend linearly on emissions and the error statistics can be assumed to be normally or log-normally distributed, the Bayesian optimization problem has an analytical solution, including closed-form expressions for the posterior emissions estimate, its error statistics, and its information content (Rodgers, 2000; Maasakkers et al., 2019). The analytical solution requires explicit construction of the Jacobian matrix of the forward model, , which represents the sensitivity of the simulated concentrations y∈ℝm to the emission state vector x∈ℝn (Brasseur and Jacob, 2017). The elements of y are individual observations, and the elements of x are the emissions optimized by the inversion, often grid cells in a two-dimensional emissions field. When m≫n, as for inversions of satellite observations, the Jacobian can be constructed column-wise by conducting n+1 CTM simulations to perturb each of the state vector elements xi and obtain the corresponding column . Even on massively parallel computing clusters, the computational cost of conducting these simulations can limit the size of the state vector x and, therefore, the resolution at which inversions are conducted (Turner and Jacob, 2015). However, once the Jacobian matrix is constructed, inversions can be conducted at essentially no additional computational cost, allowing the study of the solution's sensitivity to changes in the specification of inversion parameters, error statistics, prior assumptions, and the number and type of observations.
An illustrative example is the inversion of satellite observations to infer methane emissions. Methane is an important greenhouse gas, but the spatial and temporal distribution of emissions is highly uncertain (Saunois et al., 2020). Satellite observations of atmospheric methane columns can inform emission estimates (Jacob et al., 2016). This was first shown with data from the SCanning Imaging Absorption spectroMeter for Atmospheric CartograpHY (SCIAMACHY) satellite instrument (2003–2012) with a nadir pixel resolution of 30 × 60 km2 (Bergamaschi et al., 2009, 2013; Houweling et al., 2014; Wecht et al., 2014). More recent inversions used observations from the Thermal And Near-infrared Sensor for carbon Observation – Fourier Transform Spectrometer (TANSO-FTS) instrument aboard the Greenhouse Gases Observing Satellite (GOSAT; 2009–present), which has 10 km diameter pixels approximately 250 km apart along-track and cross-track (Monteil et al., 2013; Alexe et al., 2015; Turner et al., 2015; Maasakkers et al., 2019). The TROPOspheric Monitoring Instrument (TROPOMI) aboard the Sentinel-5 precursor satellite, launched in October 2017, now provides daily, global retrievals of atmospheric methane columns at 5.5 × 7 km2 nadir pixel resolution, increasing coverage by orders of magnitude relative to GOSAT (Veefkind et al., 2012). However, TROPOMI's methane retrieval has only a ∼3 % success rate for daytime scenes limited by dark surfaces (water), clouds, high aerosol loadings, and variable surface albedo and topography, resulting in heterogeneously distributed observations (Hu et al., 2018; Hasekamp et al., 2019). Inversions of TROPOMI data must attempt to capture the high resolution and density of observations, where appropriate, while recognizing the limitations in information content resulting from data sparsity and observational errors.
Several methods have been proposed to decrease the computational cost of high-resolution analytical inversions by optimally reducing the dimension or rank of the observation or state vector. Approaches that decrease the dimension of the observation vector (e.g., Xu, 2007) reduce the computational cost of solving the inversion but not of constructing the Jacobian matrix. Approaches that decrease the dimension of the state vector lower the cost of both computations. Reduced-dimension methods solve inversions on a multiscale emission grid of dimension k <n for which the construction of the Jacobian matrix is computationally tractable. Bocquet et al. (2011) and Bocquet and Wu (2011) defined a method to select a multiscale grid from a limited array of allowable grids that preserve resolution where the observations have the highest information content. Turner and Jacob (2015) used prior emissions information to group together similar grid cells using a Gaussian mixture model, but the criteria used to define similarity were subjective and did not consider the information content of the forward model or the observations. Other approaches that decreased the dimension of the state vector assumed knowledge of the Jacobian matrix (e.g., Rigby et al., 2011; Thompson and Stohl, 2014; Ray et al., 2015; Lunt et al., 2016; Liu et al., 2017). Reduced-rank methods generate an approximation of the posterior solution at the original dimension n by solving the inversion in the directions of highest information content. The reduced-rank method proposed by Spantini et al. (2015) assumed knowledge of the Jacobian matrix. Bousserez and Henze (2018) and Miller et al. (2020) avoided explicit construction of the Jacobian matrix by estimating the directions of highest information content, but their approach is effective only if a small number of directions explain most of the information content.
Here we present two methods to construct the Jacobian matrix for a native n-dimensional state vector and maximize the information content of the inverse analysis using k<n forward model simulations. The reduced-dimension method generates a multiscale grid that preserves native resolution where information content is highest and aggregates grid cells elsewhere. The resulting reduced-dimension Jacobian matrix solves the inversion exactly on the multiscale grid. The reduced-rank method constructs a Jacobian matrix along the dominant patterns of information content in the system, allowing the approximation of the inverse solution at native resolution. In both cases, a low-cost initial estimate of the Jacobian matrix is updated using k forward model simulations, where k is selected by the user based on the information content of the observing system and the available computational resources. We demonstrate both methods in a 1-month inversion of satellite data.
This section presents the reduced-dimension and reduced-rank methods of constructing the Jacobian matrix. Following a review of the standard analytical inverse framework (Sect. 2.1), we describe optimal reductions in both dimension and rank for an inverse system with a known native-resolution Jacobian matrix (Sect. 2.2). We then present a two-step approach to approximate an initially unknown Jacobian matrix using reductions in dimension and rank (Sect. 2.3 through 2.5). For the purposes of illustration, we take the state vector to be a gridded field of static emissions, but the methods apply to temporally variable emissions and, more generally, to any state vector.
2.1 Analytical solution to the inverse problem
The optimal estimate of a state vector x, given a prior estimate xA, observation vector y, and normal error statistics given by prior and observational error covariance matrices SA and SO, respectively, is obtained by the minimization of the Bayesian scalar cost function 𝒥(x) given by the following (Brasseur and Jacob, 2017):
Here F(x) represents the forward model that simulates the observations y given x. In our application, the forward model is a CTM. The observational error covariance matrix SO includes errors from both the measurement and the forward model, which collectively form the observing system. If the forward model is linear so that , where is the Jacobian matrix calculated by finite difference (see the Introduction) and c is a constant, then an analytical solution to the cost function minimum exists that yields both the posterior estimate and its error covariance matrix as follows:
Comparison of and SA defines the information content of the observing system, quantified by the averaging kernel matrix that represents the sensitivity of the posterior emissions estimate to the true state x. A can be calculated as or equivalently as follows:
Equation (4) expresses the dependence of the averaging kernel matrix on the forward model and both error covariance matrices. The diagonal elements of A are commonly referred to as the averaging kernel sensitivities. They are highest in highly observed locations with uncertain, high emissions and lowest in poorly observed areas or in regions known to have low emissions. The sum of the sensitivities, or the trace of A, measures the number of pieces of information that can be independently quantified by the observing system, known as the degrees of freedom for signal or DOFS (Rodgers, 2000).
2.2 Optimal reductions in dimension and rank of inverse systems
We first consider the problem of optimally reducing the dimension and rank of an inverse system, as described in Sect. 2.1, with a known Jacobian matrix . Figure 1 illustrates dimension and rank reductions for an emission grid over North America. The top left panel represents the original n-dimensional state space, i.e., the native-resolution grid. A linear transformation reduces the dimension of the state space from n to k. This transformation may reduce dimension discretely, as in the case of grid cell aggregation (top right panel), or non-discretely, in which case the k state vector components are themselves n-dimensional vectors (bottom right panel). A second linear transformation restores the dimension of the state space from k back to the original n. The resulting space, depicted in the bottom left, is a low-rank approximation of the original state space. The matrix transforms the original state space to the low-rank subspace. The inverse problem can be solved in any of these four spaces, although the eigenvector corrections generated in the non-discrete reduced-dimension space (bottom right panel) would be difficult to interpret.
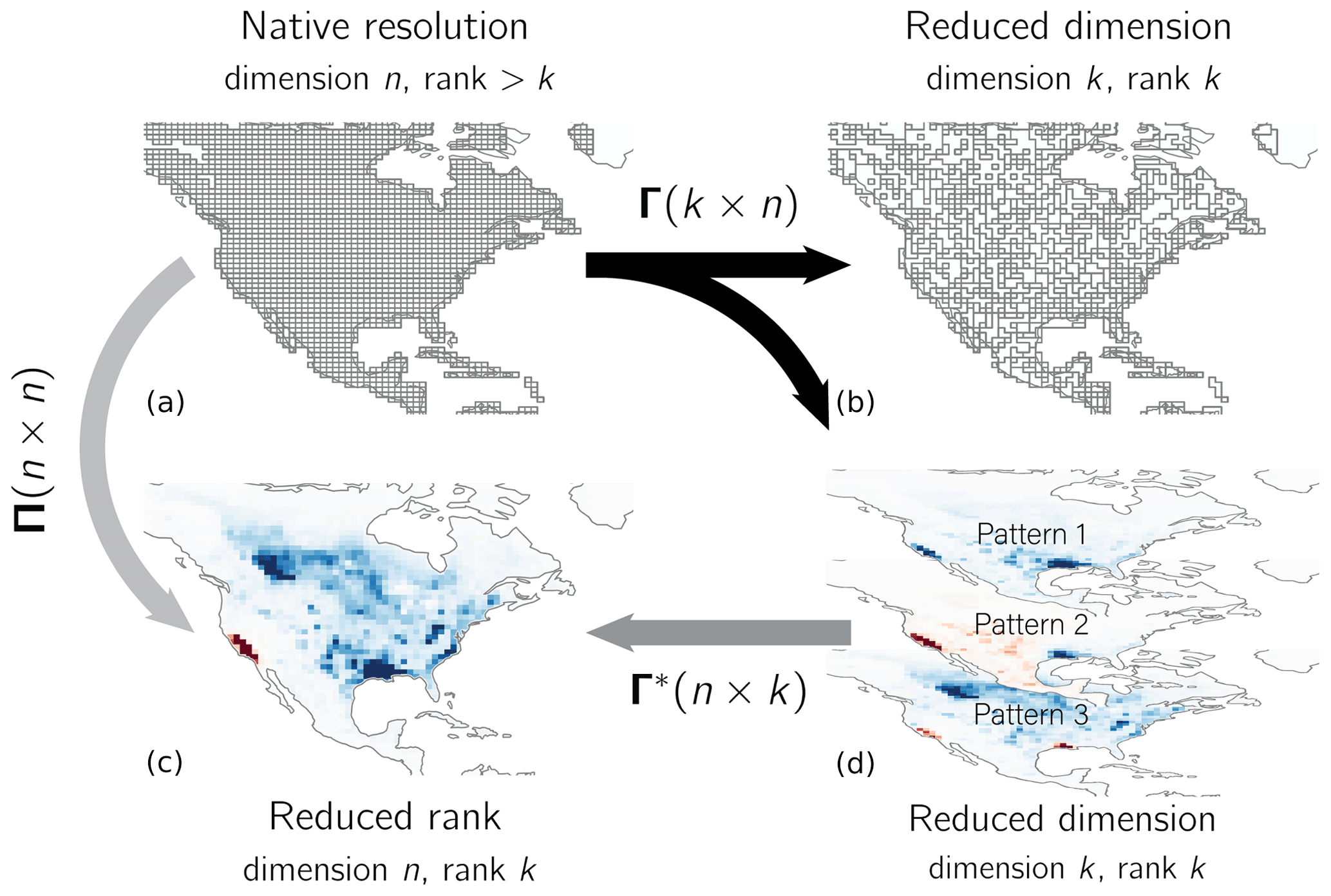
Figure 1Dimension and rank reductions of a gridded emissions field. The linear transformation matrix Γ reduces the dimension of the original state space (a), either discretely by aggregating grid cells to generate a multiscale grid (b) or non-discretely by projecting along the patterns given by the rows of Γ (c, with positive values in red and negative in blue). The reverse transformation Γ∗ restores the dimension but not the rank, producing a low-rank subspace of the original state space (d). The projection reduces the rank but not the dimension.
We wish to define matrices Γ and Γ∗ that minimize the information loss associated with reducing the dimension or rank of the state vector. Bousserez and Henze (2018) show that the projection Π that maximizes the probability of restoring the original full dimension state vector x, given the reduced dimension state vector Γx, is given by , where . For a projection of this form, they show that information loss is minimized by maximizing , where AΠ and A are the reduced-rank and native-resolution averaging kernel matrices, respectively. They define as follows:
where the columns of W are the eigenvectors of Q, and Σ is a diagonal matrix of the corresponding eigenvalues ranked in descending order. The quantity Tr(AΠ) is maximized for a rank-k subspace when U=Wk, where Wk is the matrix of the first k columns of W. The corresponding optimal projection is then as follows:
This projection applies a dimension-reducing transformation Γ followed by a dimension-restoring transformation Γ∗ as follows:
The columns of Γ∗ give an eigenvector basis for the averaging kernel matrix, and the diagonal of Σ gives its eigenvalues, together defining the dominant patterns of information content. The fraction of information content explained by the first i columns of Γ∗ is the sum of the i largest eigenvalues divided by the total DOFS (Bousserez and Henze, 2018). The eigenvalues can also be related to other measures of information content, including the Shannon and relative entropy differences (Rodgers, 2000; Xu, 2007). We will refer to the ordered list of the eigenvalues as the information content spectrum. On the basis of this spectrum, we can select k so that most of the information content is explained by the first k eigenvectors. Alternatively, we can select k so that all eigenvectors have a sufficiently large signal-to-noise ratio. The signal-to-noise ratio SNR of the ith eigenvector is given by the ith singular value of the pre-whitened Jacobian matrix and is calculated as follows:
where σi is the ith ordered eigenvalue of Q (Rodgers, 2000).
2.3 Approximating the Jacobian matrix
Section 2.2 described optimal reductions in the dimension and rank of a state vector assuming knowledge of the native-resolution Jacobian matrix K. However, the n+1 forward model simulations needed to construct K may be prohibitively expensive. Here we present a two-step approach to construct a reduced-dimension or reduced-rank Jacobian matrix at much lower computational cost. We start from a low-cost, native-resolution estimate K(0) (see below) and calculate the corresponding averaging kernel matrix A(0). In the reduced-dimension method, we use A(0) to construct a multiscale grid that maintains resolution in the areas of highest information content (top right panel of Fig. 1). We generate the updated, reduced-dimension Jacobian matrix on the resulting grid using the forward model. In the reduced-rank method, we construct on the basis of the k dominant eigenvectors of A(0) by perturbing those patterns in the forward model, generating an approximation of the Jacobian matrix in a reduced-rank state space (bottom left panel of Fig. 1). In both methods, the updated Jacobian matrix improves the estimate of the averaging kernel matrix and its eigenvectors by incorporating information content from the forward model. We use either or to conduct a second update and construct the final Jacobian matrix.
In our demonstration case, we generate an initial estimate of the native-resolution Jacobian matrix K(0) at no cost by assuming that a local perturbation of methane emissions Δx (kilograms per square meter per second; hereafter kg m−2 s−1) produces local dry column mixing ratio enhancements Δy (moles per mole; hereafter mol mol−1), as determined by a simple column mass balance dependent on local wind speed and parameterized turbulent diffusion. We construct K(0) column-wise by assuming that observation i responds to emissions in grid cell j as follows:
so that the elements of K(0) are given by
where is a dimensionless coefficient providing a crude parameterization of turbulent diffusion, Mair and are the molecular weights of dry air and methane, respectively, L is a ventilation length scale taken as the square root of the grid cell area, g is gravitational acceleration, U is the local wind speed taken here as 5 km h−1, and p is the surface pressure. We assume αij=0.4 for observations in grid cell j and distribute the remaining mass over the three concentric rings surrounding that cell with αij=0.3/8, 0.2/16, and 0.1/24 from the inner to outer ring. Including a representation of turbulent diffusion increases the spatial coverage of the dominant patterns of information content. The exact form of the parameterization (e.g., the number of rings used or the values of αij) is unimportant.
The reduced-dimension and reduced-rank methods rely on characterizing the dominant patterns of information content of the observing system using the initial estimate of the averaging kernel matrix A(0) corresponding to K(0). A(0) can provide a good approximation of A, even if the initial estimate of the Jacobian matrix K(0) is crude, because the averaging kernel matrix depends strongly on the specified prior and observational error covariance matrices SA and SO (Eq. 4) and because, by assuming that observed concentrations are most sensitive to local emissions, K(0) generates the highest information content where the observations are densest. This information content structure can then be refined by a two-step update.
2.4 Constructing the reduced-dimension Jacobian matrix
In an inverse system with a known native-resolution Jacobian matrix K, a reduced-dimension Jacobian matrix KRD can be constructed on a multiscale grid that maintains the native resolution where the information content is highest and aggregates grid cells elsewhere (top right panel of Fig. 1). We refer to the state vector elements of this multiscale grid as clusters. An optimal multiscale grid maximizes the total DOFS and the averaging kernel sensitivities of each state vector element, referred to here as the DOFS per cluster. To construct this grid, we first define the state vector as a single element encompassing the inversion domain. We then add the native-resolution grid cells with the highest averaging kernel sensitivities to the state vector one by one, removing them from the original state vector element. For each new element xi, we calculate the corresponding Jacobian matrix column and the resulting increase in DOFS. When the DOFS stabilize, we add instead clusters of two or more native-resolution grid cells and repeat this procedure. Clusters can be generated by, for example, K-means clustering, which aggregates spatially proximate grid cells. We repeat this process, increasing cluster size, until all native-resolution grid cells are allocated to the multiscale grid and the corresponding reduced-dimension Jacobian matrix KRD is constructed. The DOFS convergence criteria and the sequence of cluster sizes can be selected to achieve the desired state vector dimension.
We apply this approach, beginning with our initial estimate K(0) (Sect. 2.3), in a two-step update that iteratively improves the multiscale grid. Algorithm 1 describes this process in detail. Briefly, the information content for the initial multiscale grid is given by A(0), which we use to identify the grid cells with the highest information content and construct a multiscale grid as described above. We compute the corresponding reduced-dimension Jacobian matrix , introducing information content from the forward model. We identify the state vector elements where the forward model contributes the most information content by comparing the sensitivities given by the updated reduced-dimension averaging kernel matrix to the sensitivities given by A(0). We disaggregate the clusters with the largest differences and update the reduced-dimension Jacobian, generating . Convergence is rapid, and we find no need for further iteration. The analytical inversion can then be solved exactly on the multiscale grid with .

2.5 Constructing the reduced-rank Jacobian matrix
In an inverse system with a known native-resolution Jacobian matrix K, a reduced-rank approximation of the Jacobian matrix KΠ can be constructed by calculating the linear relationship between emissions and observations for the most important patterns of information content rather than for individual or aggregate grid cells. A low-rank Jacobian corresponds to the state space shown in the bottom left panel of Fig. 1. We showed that the leading patterns of information content are given by the columns of the dimension-restoring transformation Γ∗ (Eq. 8). For any selected value of k, the k leading patterns span a rank-k, dimension-n subspace of the original information content space. A Jacobian matrix can be constructed within this space by calculating the model response to perturbations of these patterns. The response of the forward model F to the jth normalized eigenvector , given by the jth column of Γ∗, is as follows:
where β is any scalar sufficiently large to ensure numerical stability. The model responses , form the columns of the matrix , which is the Jacobian matrix for an inverse system with a reduced-dimension state space spanned by the first k eigenvectors of the information content, illustrated by the bottom right panel of Fig. 1. This reduced-dimension Jacobian must be transformed to the original state dimension to enable physical interpretation of the posterior results. Bousserez and Henze (2018), following Bocquet et al. (2011), show that the reduced-dimension Jacobian matrix Kω is given by and the reduced-rank Jacobian matrix KΠ by . Thus, the reduced-rank Jacobian can be calculated from the reduced-dimension Jacobian by KΠ=KωΓ. The resulting Jacobian has dimension m×n and rank k.
In an inverse system without a known Jacobian matrix, the reduced-rank Jacobian matrix approximation can be constructed in a two-step update that iteratively improves the patterns of information content used as perturbations. Algorithm 2 describes this process in detail. Briefly, we use the initial estimate of the Jacobian matrix K(0) (Sect. 2.3) to calculate the corresponding averaging kernel matrix A(0) and the matrix of its eigenvectors . When calculating , we select the k(0) eigenvectors that have a signal-to-noise ratio greater than some threshold. We use the signal-to-noise criterion, which is stricter than the information content criterion, to account for the errors in the initial estimate of the information content. We compute the forward model response to each of the eigenvectors using Eq. (12) and transform the resulting reduced-dimension Jacobian to the full-dimension state space with . We calculate the associated averaging kernel matrix and the matrix of its eigenvectors . Because is a reduced-rank approximation, its spectrum of information content is discontinuous at k(0). We, therefore, use the spectrum of information content associated with the initial, full-rank estimate A(0) to select the rank k(1) of the second update and calculate . We use the k(1) eigenvectors that span most of the information content from the initial estimate and construct an updated reduced-rank Jacobian matrix approximation as above. The resulting Jacobian matrix is a rank ≈k(1) approximation that accurately quantifies the forward model where the observing system has high information content, and loses accuracy in areas with lower information content, where the observations are least able to constrain emissions. The resulting posterior solution is accurate in areas with high information content and defaults to the prior estimate elsewhere.

We demonstrate the reduced-dimension and reduced-rank Jacobian matrix construction methods in an analytical Bayesian inversion of atmospheric methane columns observed by the GOSAT satellite over North America in July 2009. Although TROPOMI now provides higher density observations, using GOSAT allows us to use the inversion framework of Maasakkers et al. (2021). We construct a “native-resolution” inverse system at 1∘ × 1.25∘ grid cell resolution (n=2098; top left panel of Fig. 1) against which we compare our reduced-dimension and reduced-rank methods. To demonstrate the applicability of the methods to higher-information observing systems such as TROPOMI, we artificially increase the information content of the GOSAT data by introducing an amplification factor λ>1 to the cost function that increases the weight of the observational terms as follows:
The amplification factor functionally decreases the observational error covariance, increasing the DOFS. We set λ=5, which increases the native-resolution DOFS from 82 to 198. Because of noise in the GOSAT data, this results in an overfit solution, which is irrelevant in our demonstration.
We use the nested North American GEOS-Chem CTM (version 11-01) as the forward model to simulate atmospheric methane column concentrations at 1∘ × 1.25∘ resolution for July 2009. The 2098 1∘ × 1.25∘ grid cells constitute our native-resolution state vector. The model is driven with MERRA-2 (Modern-Era Retrospective analysis for Research and Applications, Version 2) meteorological fields (Bosilovich et al., 2016) from the NASA Global Modeling and Assimilation Office. We use boundary conditions and initial conditions from a global posterior GEOS-Chem 4∘ × 5∘ simulation from Maasakkers et al. (2019). The GOSAT observations are from the University of Leicester version 7 CH4 proxy retrieval over land (Parker et al., 2011; Parker et al., 2015; ESA CCI GHG project team, 2018) for July 2009. Prior emissions and observational error covariances are as described in Maasakkers et al. (2021). We assume uniform relative prior errors of 50 %. The demonstration has a sufficiently coarse resolution and is short enough that the native-resolution Jacobian matrix K can be explicitly computed with 2099 model runs. After constructing K, we use it as the forward model in lieu of additional GEOS-Chem simulations.
Figure 2 (top left panel) shows the native-resolution averaging kernel sensitivities, i.e., the diagonal elements of the native-resolution averaging kernel matrix A. As discussed in Sect. 2.3, the structure of the averaging kernel matrix is largely determined by the prior error covariance matrix SA and by the observation density, as reflected in both the observational covariance matrix SO and the Jacobian matrix K. This is apparent in the bottom panels of Fig. 2, which show the distribution of the prior error standard deviations (left) and observation density (right). The absolute errors on the prior emissions estimate are largest for wetlands along the southeastern coast of the USA (Bloom et al., 2017). The variability in the observation density is driven by sampling frequency and retrieval success (Parker et al., 2015).
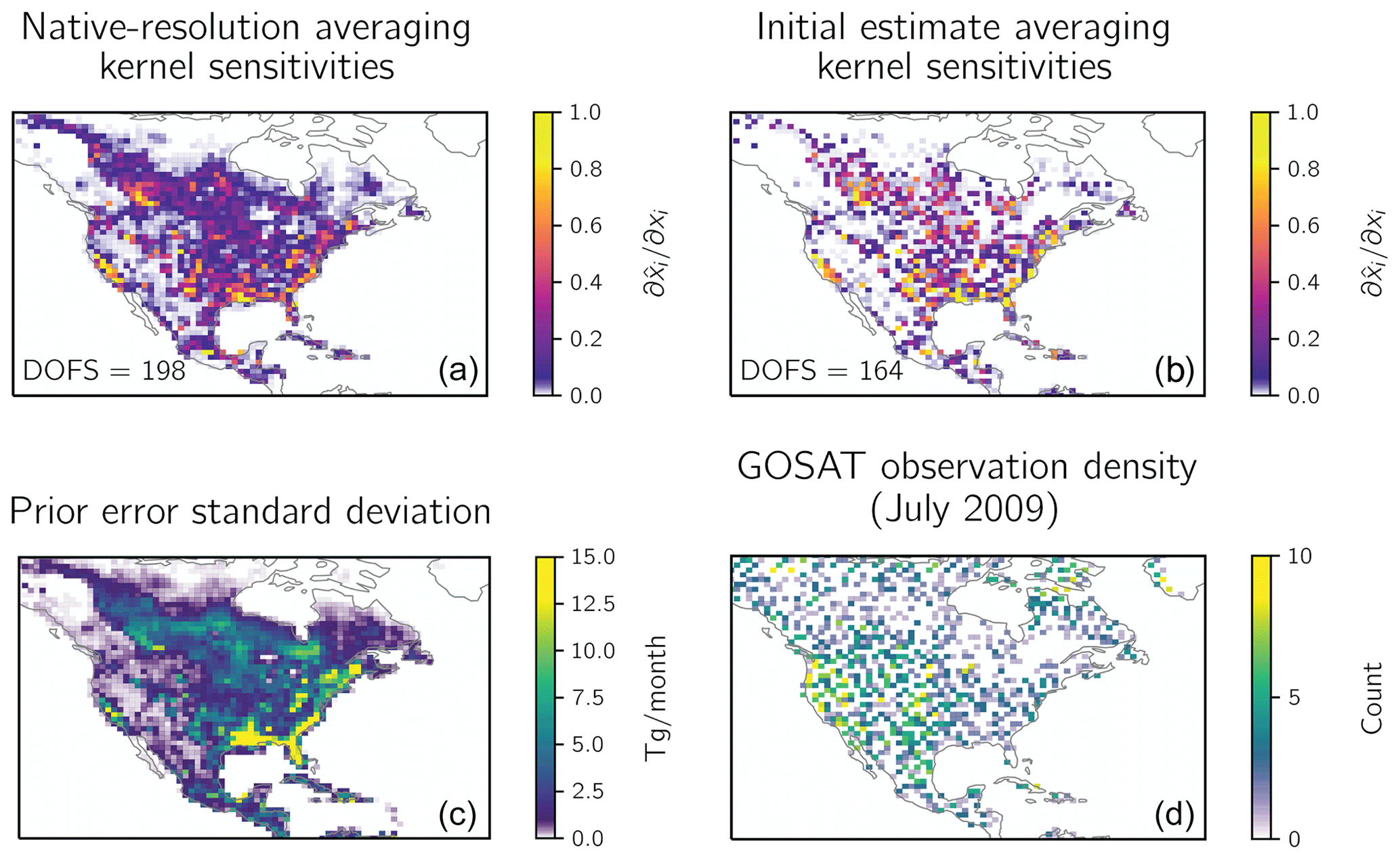
Figure 2Averaging kernel sensitivities for the demonstration inversion of GOSAT observations with enhanced information content for July 2009. The top panels show the sensitivities given by the diagonal elements of the averaging kernel matrix A of the native-resolution inversion (a) and of the initial estimate of the averaging kernel matrix A(0) (b). The DOFS for each averaging kernel matrix are inset in the corresponding panel. Panel (c) shows the error standard deviations on the prior emissions estimate given by the square roots of the diagonal elements of SA. Panel (d) shows the GOSAT observation density.
Figure 2 (top right panel) also shows the initial estimate of averaging kernel sensitivities of A(0) derived from the initial estimate of the Jacobian matrix K(0), constructed as described in Sect. 2.3. No forward model simulations were conducted to construct this initial estimate, yet the patterns of information content reproduce those given by the native-resolution averaging kernel matrix A because of the strong dependence on the prior error standard deviations and the observation density. A has a smoother structure than A(0) because of the effect of long-range transport in the CTM, but this has little effect on the leading patterns of information content.
For this demonstration, we aim to reduce the number of forward model runs needed to construct the Jacobian matrix by at least a factor of 4 relative to the native-resolution inversion, from 2099 to ≈525 simulations. We first apply the reduced-dimension method to construct a Jacobian matrix on a multiscale grid generated with K-means clustering, following Sect. 2.4. The resulting initial multiscale grid and reduced-dimension Jacobian matrix constrain 380 clusters and required 381 model simulations. We disaggregate 11 clusters with a sensitivity increase greater than 0.6, adding 65 native-resolution grid cells and model simulations. The resulting multiscale grid is shown in the top right panel of Fig. 1. It has a dimension of 434, and the corresponding reduced-dimension Jacobian matrix required 446 forward model simulations across 17 parallelized batches, representing a factor of 5 decrease in computational cost relative to the native-resolution solution. The grid has 137 native-resolution grid cells and clusters of between 2 and 55 grid cells.
Figure 3 shows the posterior emission scaling factors relative to the prior estimate (top) and averaging kernel sensitivities (bottom) for the reduced-dimension solution (center column) compared to the native-resolution solution (left column). Both solutions are exact on the grids used. The reduced-dimension solution generates fewer DOFS (95) than the native-resolution solution (198) because the DOFS depend on the dimension of the state vector. When comparing the DOFS per cluster, a dimension-independent measure, the reduced-dimension solution produces more than twice the value of the native-resolution solution (0.22 compared to 0.09), reflecting the consolidation of information content. This is reflected in the reduced-dimension averaging kernel sensitivities, which are more uniform than the native-resolution values. The reduced-dimension posterior scaling factors exhibit less variability than the native-resolution solution, which exhibits checkerboard patterns resulting, in part, from the overfit of the posterior solution to observational noise. The posterior scaling factors agree on regional scales.
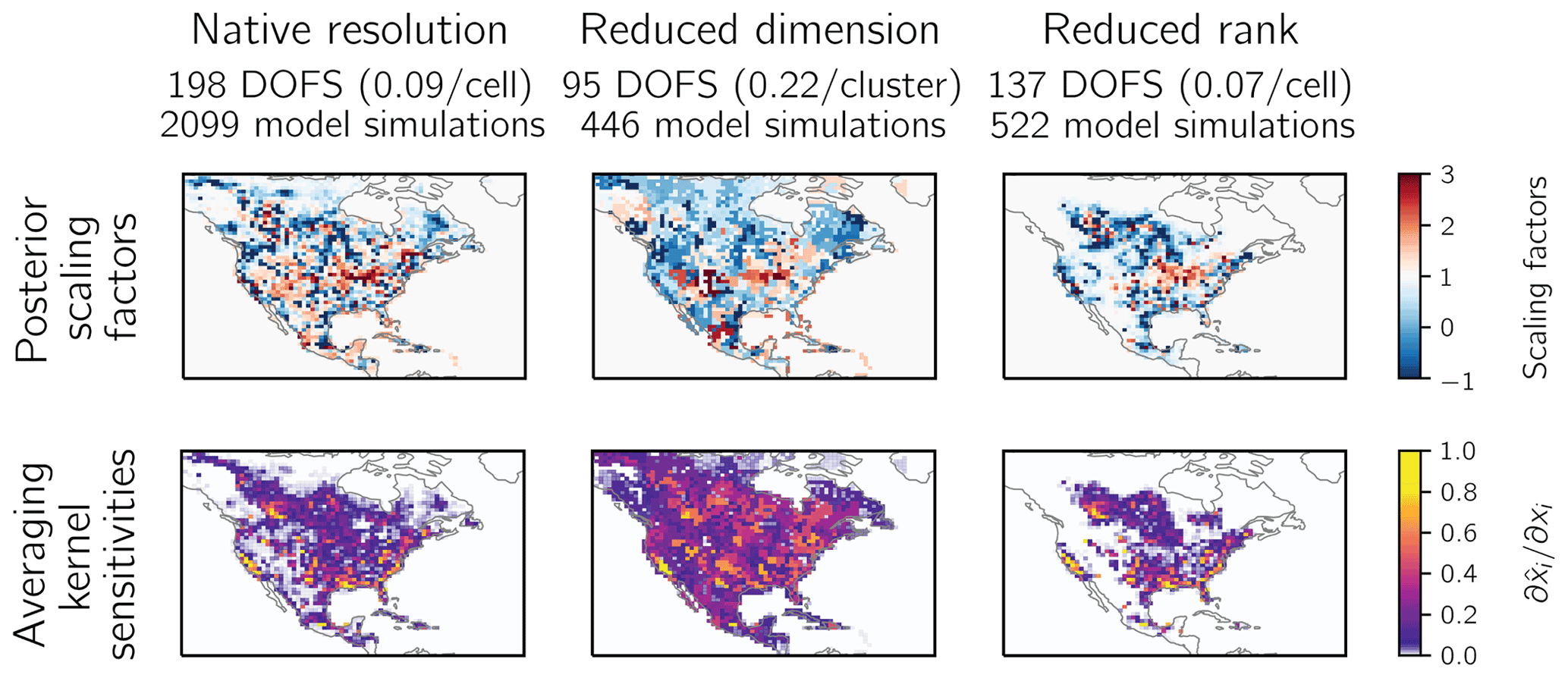
Figure 3Results from the demonstration inversion at native resolution compared to the reduced-dimension and reduced-rank methods. The figure shows the posterior scaling factors with respect to the prior emissions estimate and the averaging kernel sensitivities for each inversion. The degrees of freedom for signal (DOFS) give the number of pieces of information that the inversion can independently constrain.
We next apply the reduced-rank method (Sect. 2.5) to construct a reduced-rank approximation of the Jacobian matrix. We calculate the dominant eigenvectors of the initial averaging kernel matrix estimate A(0), requiring that the signal-to-noise ratio of all eigenvectors be greater than 1.25. This yields k(0)=90 eigenvectors, which account for 43 % of the initial-estimate DOFS. We perturb these eigenvectors in the forward model and construct the reduced-rank Jacobian matrix . We then calculate the averaging kernel matrix and its dominant eigenvectors, defining k(1)=431 by requiring that the improved eigenvectors capture 97 % of the information content defined by . The resulting Jacobian matrix has a rank of ≈431 and required 522 forward model simulations across two parallelized batches. We solve the inversion with and find 137 DOFS, compared to the 198 DOFS generated in the native-resolution inversion, achieving 69 % of the DOFS at a quarter of the computational cost.
The DOFS of the reduced-rank inversion are only moderately sensitive to the first- and second-update thresholds, with a stronger dependence on the number of model runs conducted in the second update. Figure 4 shows the reduced-rank DOFS as a function of the number of first- and second-update forward model runs. Among all possible partitions of 522 total model runs (dashed line), our update scheme (starred) nearly maximizes the DOFS, but the DOFS has only moderate sensitivity to the choice of partition. Using a signal-to-noise ratio threshold of 0.75 or 1.75 instead of 1.25 (dots) decreases the reduced-rank DOFS by 7 %. Lowering the signal-to-noise ratio threshold increases the number of eigenvectors drawn from A(0), which increases the effect of errors in the initial Jacobian matrix estimate K(0). Increasing the threshold fails to exploit the information content of A(0). More generally, applying a signal-to-noise ratio threshold of 1.25 in the first update maximizes the DOFS, regardless of the number of model runs conducted in the second update. We show the DOFS generated by these optimal configurations as a function of the total number of forward model runs in the top panel of Fig. 4. After only 300 simulations, the optimal reduced-rank inversion generates 101 DOFS, achieving half of the native-resolution DOFS at 14 % of the computational cost.
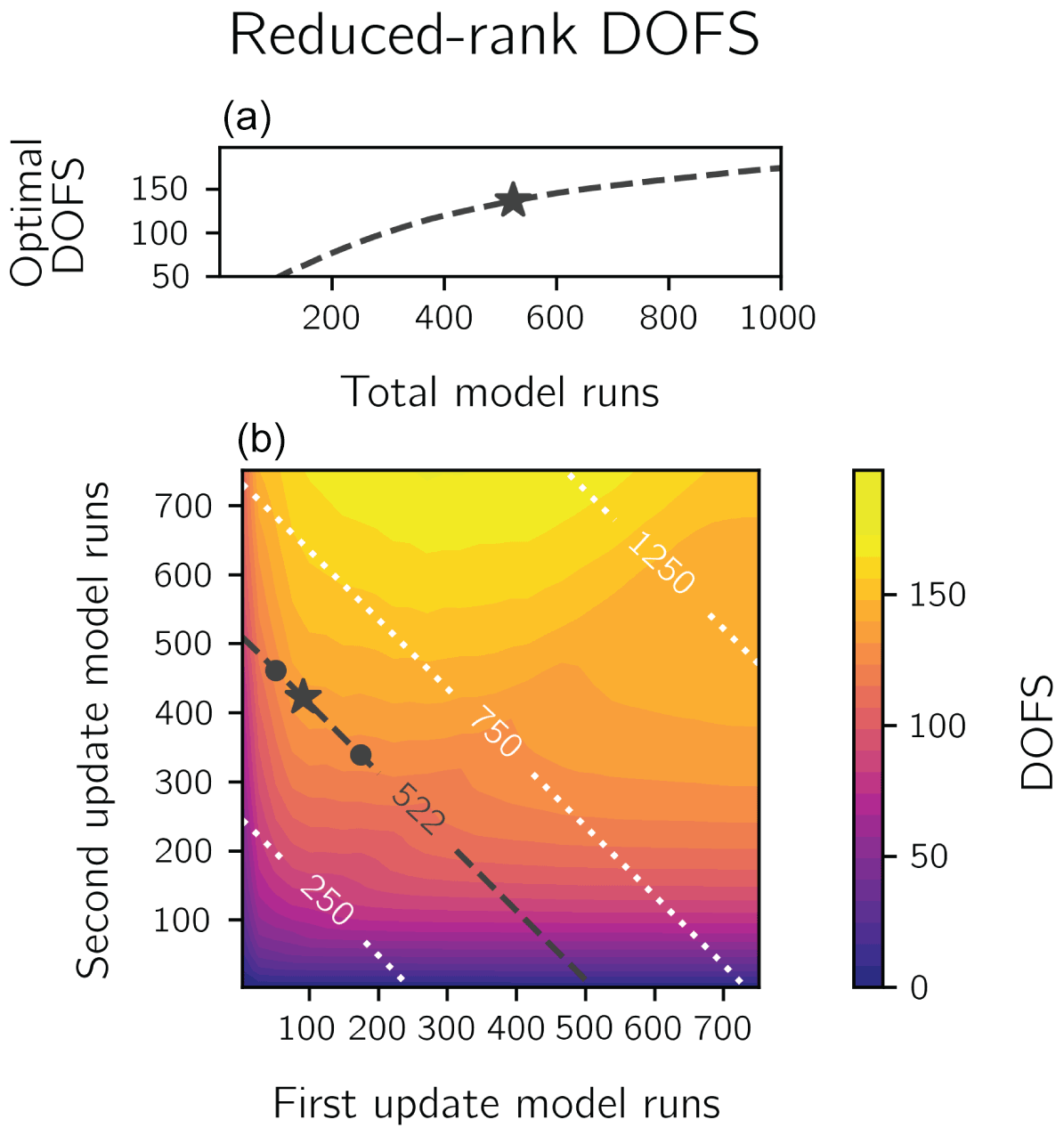
Figure 4The sensitivity of the reduced-rank inversion DOFS to the number of forward model runs. Panel (b) shows the sensitivity of the DOFS to the partitioning of model runs between the first (x axis) and second (y axis) update. The lines represent the total number of simulations. Our inversion uses a signal-to-noise ratio of 1.25 for the first update and an information content threshold of 97 % for the second update (star), requiring 522 forward model runs and generating 137 DOFS, accounting for 69 % of the native-resolution DOFS at a quarter of the computational expense. Using a signal-to-noise ratio of 0.75 or 1.75 with the same total number of model simulations (dots) does not substantially decrease the DOFS. Panel (a) shows the DOFS as a function of the total number of model runs for all optimal first- and second-update partitions.
We solve the inversion (Eqs. 2–4) using the reduced-rank Jacobian matrix and compare the posterior to the native-resolution solution. Figure 3 (right column) shows the distribution of the reduced-rank posterior scaling factors (top) and averaging kernel sensitivities (bottom) compared to the native-resolution inversion (left column). Because was constructed on the basis of the dominant patterns of information content, it solves for the posterior scaling factors accurately in the areas of the highest information content and defaults to the prior value (a scaling factor of 1) elsewhere. As a result of the exclusion of grid cells with low native-resolution information content, the reduced-rank DOFS (137) are lower than native-resolution DOFS (198). However, in grid cells with large averaging kernel sensitivities, the reduced-rank inversion preserves most of the information content: 755 grid cells have reduced-rank averaging kernel sensitivities greater than 0.01 and generate 136 DOFS, amounting to 83 % of the 163 DOFS generated by the same grid cells in the native-resolution inversion.
Figure 5 shows a statistical comparison of the reduced-rank and native-resolution inversion results for grid cells with a reduced-rank averaging kernel sensitivity above 0.01. None of the reduced-rank quantities exhibit significant bias, as shown by comparison to the 1:1 line. The elements of the reduced-rank Jacobian matrix correspond closely with those of the native-resolution Jacobian matrix K (correlation coefficient R=0.97). The strong correlation of the averaging kernel sensitivities (R=0.93) confirms that the reduced-rank inversion accurately identifies the native-resolution grid cells with the highest information content. The posterior errors and scaling factors agree well in these grid cells. The posterior error standard deviations correlate strongly (R=0.94), due, in part, to the common contribution of the prior and observational error covariance matrices (Eq. 3). The outlier reduced-rank standard deviations tend to be larger than the native-resolution values, reflecting the error introduced by discarding information content. The posterior scaling factors also agree well, but the correlation coefficient is smaller (R=0.84) because of the smaller dynamical range and the propagation of errors from the posterior error covariance and Jacobian matrices (Eq. 2). Negative scaling factors reflect the overfit from artificially increasing the information content but are of no consequence for our demonstration.

Figure 5Comparison statistics between the reduced-rank and native-resolution inversions for the grid cells with reduced-rank averaging kernel sensitivity greater than 0.01. Individual panels compare binned counts for Jacobian matrix elements (parts per billion), posterior scaling factors (dimensionless), posterior error standard deviations (dimensionless), and averaging kernel sensitivities (dimensionless). Correlation coefficients are inset, and the 1:1 line (dotted) is shown.
The reduced-dimension and reduced-rank methods reproduce the native-resolution inversion with a factor of at least 4 reduction in total computational cost. The reduced-dimension method generates lower DOFS but higher DOFS per state vector element due to the clustering of grid cells. The resulting posterior solution is exact on the multiscale grid and provides better spatial coverage than the reduced-rank method at lower resolution. The reduced-rank method generates a higher-DOFS, higher-resolution approximation where the averaging kernel sensitivities are large. While the calculation of large Jacobian matrices can take advantage of parallel computing environments (Maasakkers et al., 2019), the iterative nature of both methods proposed here puts some limit on the parallelization. The limit is greater for the reduced-dimension method, which requires an iteration for each cluster size added to the state vector. The reduced-rank method requires only two iterations. In both cases, these limitations may not be meaningful because the native-resolution Jacobian matrix is rarely generated in a fully parallel environment in practice.
We proposed two methods to conduct analytical high-resolution inversions of satellite observations of atmospheric composition to infer emissions while maximizing information content and minimizing computational cost. The computational cost of analytical inversions is driven by the construction of the Jacobian matrix, which expresses the sensitivity of the observed concentrations to emissions. The Jacobian matrix is constructed numerically by conducting perturbation simulations with a chemical transport model (CTM) that serves as the forward model for the inversion. Our methods exploit the dominant patterns of information content in the observing system to build the Jacobian matrix. The reduced-dimension method constructs the Jacobian matrix on a multiscale grid that aggregates grid cells where information content is lowest. The reduced-rank method approximates the Jacobian matrix using the dominant patterns of information content, discarding the weaker patterns. Beyond the atmospheric application presented here, both methods can be applied more generally to the problem of efficient numerical approximation of high-dimension Jacobian matrices.
Both methods use a two-step update to improve an initial, no-cost estimate of the Jacobian matrix and the corresponding averaging kernel matrix. The initial estimate of the Jacobian matrix is constructed here by assuming that observed atmospheric concentrations are most sensitive to local emissions. Because the averaging kernel matrix has a strong dependence on the prior error covariance matrix and observation density, this initial estimate can accurately quantify the fine structure of information content. The reduced-dimension method uses the initial estimate of the averaging kernel matrix to generate a multiscale grid that maintains the native resolution where information content is the highest and consolidates grid cells elsewhere. The forward model is used to build the Jacobian matrix on this grid, and the resulting reduced-dimension averaging kernel matrix is compared to the initial estimate to identify the state vector elements where the forward model contributed the most information content. These elements are disaggregated to generate a second and final update. The reduced-rank method uses the initial estimate of the averaging kernel matrix to identify the dominant patterns of information content. These patterns are perturbed in the forward model, generating a first update of the Jacobian matrix. This update serves as the basis for a second and final update. In both methods, rapid convergence occurs after two updates.
We applied both methods in a demonstration inversion of GOSAT column methane observations over North America for July 2009 with artificially enhanced information content. We compared the results to a native-resolution inversion that optimized emissions on a 1∘ × 1.25∘ grid. Both methods successfully approximated the native-resolution results and decreased the total computational cost by a factor of at least 4. The reduced-dimension method produced only 50 % of the native-resolution information content, as measured by the degrees of freedom for signal (DOFS), due to spatial averaging, but it generated twice the DOFS per state vector element and avoided the correlated errors found in the native-resolution inversion. The reduced-rank method retained 70 % of the native-resolution DOFS by solving the inversion accurately in the grid cells with the highest information content and defaulting to the prior emissions estimate elsewhere. In sensitivity tests, the reduced-rank method retained 50 % of the native-resolution DOFS while decreasing computational cost by a factor of 7.
All code and data are available at https://github.com/hannahnesser/reduced_rank_jacobian (last access: 5 August 2021), https://doi.org/10.5281/zenodo.5165262, Nesser, 2021).
HN and DJJ designed the study. HN performed the analysis. JDM provided all demonstration inversion data and supporting guidance. HN and MPS performed the simulations. HN, DJJ, JDM, TRS, MPS, YZ, and CHR discussed the methods and results. HN and DJJ prepared the paper, with contributions from all co-authors.
The authors declare that they have no conflict of interest.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work has been funded by the NASA Carbon Monitoring System and by a National Science Foundation (NSF) Graduate Fellowship to Hannah Nesser. We thank Daven Henze, Kevin Bowman, Michael Brenner, Cynthia Randles, Jeremy Brandman, and Laurent White, for the helpful discussions, and Marc Bocquet, for an insightful review.
This research has been supported by the National Science Foundation (grant no. 2017239632) and the NASA Earth Sciences Division (grant no. 80NSSC18K0178).
This paper was edited by Helen Worden and reviewed by Marc Bocquet and one anonymous referee.
Alexe, M., Bergamaschi, P., Segers, A., Detmers, R., Butz, A., Hasekamp, O., Guerlet, S., Parker, R., Boesch, H., Frankenberg, C., Scheepmaker, R. A., Dlugokencky, E., Sweeney, C., Wofsy, S. C., and Kort, E. A.: Inverse modelling of CH4 emissions for 2010–2011 using different satellite retrieval products from GOSAT and SCIAMACHY, Atmos. Chem. Phys., 15, 113–133, https://doi.org/10.5194/acp-15-113-2015, 2015.
Bergamaschi, P., Frankenberg, C., Meirink, J. F., Krol, M., Villani, M. G., Houweling, S., Dentener, F., Dlugokencky, E. J., Miller, J. B., Gatti, L. V., Engel, A., and Levin, I.: Inverse modeling of global and regional CH4 emissions using SCIAMACHY satellite retrievals, J. Geophys. Res.-Atmos., 114, D22301, https://doi.org/10.1029/2009JD012287, 2009.
Bergamaschi, P., Houweling, S., Segers, A., Krol, M., Frankenberg, C., Scheepmaker, R. A., Dlugokencky, E., Wofsy, S. C., Kort, E. A., Sweeney, C., Schuck, T., Brenninkmeijer, C., Chen, H., Beck, V., and Gerbig, C.: Atmospheric CH4 in the first decade of the 21st century: Inverse modeling analysis using SCIAMACHY satellite retrievals and NOAA surface measurements, J. Geophys. Res.-Atmos., 118, 7350–7369, https://doi.org/10.1002/jgrd.50480, 2013.
Bloom, A. A., Bowman, K. W., Lee, M., Turner, A. J., Schroeder, R., Worden, J. R., Weidner, R., McDonald, K. C., and Jacob, D. J.: A global wetland methane emissions and uncertainty dataset for atmospheric chemical transport models (WetCHARTs version 1.0), Geosci. Model Dev., 10, 2141–2156, https://doi.org/10.5194/gmd-10-2141-2017, 2017.
Bocquet, M. and Wu, L.: Bayesian design of control space for optimal assimilation of observations. Part II: Asymptotic solutions, Q. J. Roy. Meteor. Soc., 137, 1357–1368, https://doi.org/10.1002/qj.841, 2011.
Bocquet, M., Wu, L., and Chevallier, F.: Bayesian design of control space for optimal assimilation of observations. Part I: Consistent multiscale formalism, Q. J. Roy. Meteor. Soc., 137, 1340–1356, https://doi.org/10.1002/qj.837, 2011.
Bosilovich, M. G., Lucchesi, R., and Suarez, M.: File Specification for MERRA-2, GMAO Office Note No. 9 (Version 1.1), 73 pp., available at: http://gmao.gsfc.nasa.gov/pubs/docs/Bosilovich785.pdf (last access: 1 December 2018), 2016.
Bousserez, N. and Henze, D. K.: Optimal and scalable methods to approximate the solutions of large-scale Bayesian problems: theory and application to atmospheric inversion and data assimilation, Q. J. Roy. Meteor. Soc., 144, 365–390, https://doi.org/10.1002/qj.3209, 2018.
Brasseur, G. P. and Jacob, D. J.: Inverse Modeling for Atmospheric Chemistry, in Modeling of Atmospheric Chemistry, Cambridge University Press, Cambridge, UK, pp. 487–537, 2017.
Chevallier, F., Bréon, F. M., and Rayner, P. J.: Contribution of the Orbiting Carbon Observatory to the estimation of CO2 sources and sinks: Theoretical study in a variational data assimilation framework, J. Geophys. Res.-Atmos., 112, D09307, https://doi.org/10.1029/2006JD007375, 2007.
Daescu, D., Carmichael, G. R., and Sandu, A.: Adjoint Implementation of Rosenbrock Methods Applied to Variational Data Assimilation Problems, J. Comput. Phys., 165, 496–510, https://doi.org/10.1006/jcph.2000.6622, 2000.
Elbern, H. and Schmidt, H.: Ozone episode analysis by four-dimensional variational chemistry data assimilation, J. Geophys. Res.-Atmos., 106, 3569–3590, https://doi.org/10.1029/2000JD900448, 2001.
ESA CCI GHG project team: ESA Greenhouse Gases Climate Change Initiative (GHG_cci): Column-averaged CH4 from GOSAT generated with the OCPR (UoL-PR) Proxy algorithm (CH4_GOS_OCPR), v7.0, Centre for Environmental Data Analysis (CEDA) Archive, available at: https://catalogue.ceda.ac.uk/uuid/f9154243fd8744bdaf2a59c39033e659 (last access: October 2018), 2018.
Hasekamp, O., Lorente, A., Hu, H., Butz, A., Aan de Brugh, J., and Landgraf, J.: Algorithm Theoretical Baseline Document for Sentinel-5 Precursor Methane Retrieval, SRON, 1.10, SRON-S5P-LEV2-RP-001, 63 pp., available at: https://sentinels.copernicus.eu/documents/247904/2476257/Sentinel-5P-TROPOMI-ATBD-Methane-retrieval (last access: 9 July 2021), 2019.
Henze, D. K., Hakami, A., and Seinfeld, J. H.: Development of the adjoint of GEOS-Chem, Atmos. Chem. Phys., 7, 2413–2433, https://doi.org/10.5194/acp-7-2413-2007, 2007.
Houweling, S., Krol, M., Bergamaschi, P., Frankenberg, C., Dlugokencky, E. J., Morino, I., Notholt, J., Sherlock, V., Wunch, D., Beck, V., Gerbig, C., Chen, H., Kort, E. A., Röckmann, T., and Aben, I.: A multi-year methane inversion using SCIAMACHY, accounting for systematic errors using TCCON measurements, Atmos. Chem. Phys., 14, 3991–4012, https://doi.org/10.5194/acp-14-3991-2014, 2014.
Hu, H., Landgraf, J., Detmers, R., Borsdorff, T., Aan de Brugh, J., Aben, I., Butz, A., and Hasekamp, O.: Toward Global Mapping of Methane With TROPOMI: First Results and Intersatellite Comparison to GOSAT, Geophys. Res. Lett., 45, 3682–3689, https://doi.org/10.1002/2018gl077259, 2018.
Jacob, D. J., Turner, A. J., Maasakkers, J. D., Sheng, J., Sun, K., Liu, X., Chance, K., Aben, I., McKeever, J., and Frankenberg, C.: Satellite observations of atmospheric methane and their value for quantifying methane emissions, Atmos. Chem. Phys., 16, 14371–14396, https://doi.org/10.5194/acp-16-14371-2016, 2016.
Koohkan, M. R., Bocquet, M., Roustan, Y., Kim, Y., and Seigneur, C.: Estimation of volatile organic compound emissions for Europe using data assimilation, Atmos. Chem. Phys., 13, 5887–5905, https://doi.org/10.5194/acp-13-5887-2013, 2013.
Liu, Y., Haussaire, J. M., Bocquet, M., Roustan, Y., Saunier, O., and Mathieu, A.: Uncertainty quantification of pollutant source retrieval: comparison of Bayesian methods with application to the Chernobyl and Fukushima Daiichi accidental releases of radionuclides, Q. J. Roy. Meteor. Soc., 143, 2886–2901, https://doi.org/10.1002/qj.3138, 2017.
Lunt, M. F., Rigby, M., Ganesan, A. L., and Manning, A. J.: Estimation of trace gas fluxes with objectively determined basis functions using reversible-jump Markov chain Monte Carlo, Geosci. Model Dev., 9, 3213–3229, https://doi.org/10.5194/gmd-9-3213-2016, 2016.
Maasakkers, J. D., Jacob, D. J., Sulprizio, M. P., Scarpelli, T. R., Nesser, H., Sheng, J.-X., Zhang, Y., Hersher, M., Bloom, A. A., Bowman, K. W., Worden, J. R., Janssens-Maenhout, G., and Parker, R. J.: Global distribution of methane emissions, emission trends, and OH concentrations and trends inferred from an inversion of GOSAT satellite data for 2010–2015, Atmos. Chem. Phys., 19, 7859–7881, https://doi.org/10.5194/acp-19-7859-2019, 2019.
Maasakkers, J. D., Jacob, D. J., Sulprizio, M. P., Scarpelli, T. R., Nesser, H., Sheng, J., Zhang, Y., Lu, X., Bloom, A. A., Bowman, K. W., Worden, J. R., and Parker, R. J.: 2010–2015 North American methane emissions, sectoral contributions, and trends: a high-resolution inversion of GOSAT observations of atmospheric methane, Atmos. Chem. Phys., 21, 4339–4356, https://doi.org/10.5194/acp-21-4339-2021, 2021.
Meirink, J. F., Bergamaschi, P., and Krol, M. C.: Four-dimensional variational data assimilation for inverse modelling of atmospheric methane emissions: method and comparison with synthesis inversion, Atmos. Chem. Phys., 8, 6341–6353, https://doi.org/10.5194/acp-8-6341-2008, 2008.
Miller, S. M., Saibaba, A. K., Trudeau, M. E., Mountain, M. E., and Andrews, A. E.: Geostatistical inverse modeling with very large datasets: an example from the Orbiting Carbon Observatory 2 (OCO-2) satellite, Geosci. Model Dev., 13, 1771–1785, https://doi.org/10.5194/gmd-13-1771-2020, 2020.
Monteil, G., Houweling, S., Butz, A., Guerlet, S., Schepers, D., Hasekamp, O., Frankenberg, C., Scheepmaker, R., Aben, I., and Röckmann, T.: Comparison of CH4 inversions based on 15 months of GOSAT and SCIAMACHY observations, J. Geophys. Res.-Atmos., 118, 11807–11823, https://doi.org/10.1002/2013JD019760, 2013.
Nesser, H.: hannahnesser/reduced_rank_jacobian: Reduced-cost construction of Jacobian matrices (AMT 2021) (1.0), Zenodo [data set], https://doi.org/10.5281/zenodo.5165262, 2021.
Parker, R., Boesch, H., Cogan, A., Fraser, A., Feng, L., Palmer, P. I., Messerschmidt, J., Deutscher, N., Griffith, D. W. T., Notholt, J., Wennberg, P. O., and Wunch, D.: Methane observations from the Greenhouse Gases Observing SATellite: Comparison to ground-based TCCON data and model calculations, Geophys. Res. Lett., 38, L15807, https://doi.org/10.1029/2011GL047871, 2011.
Parker, R. J., Boesch, H., Byckling, K., Webb, A. J., Palmer, P. I., Feng, L., Bergamaschi, P., Chevallier, F., Notholt, J., Deutscher, N., Warneke, T., Hase, F., Sussmann, R., Kawakami, S., Kivi, R., Griffith, D. W. T., and Velazco, V.: Assessing 5 years of GOSAT Proxy XCH4 data and associated uncertainties, Atmos. Meas. Tech., 8, 4785–4801, https://doi.org/10.5194/amt-8-4785-2015, 2015.
Quélo, D., Mallet, V., and Sportisse, B.: Inverse modeling of NOx emissions at regional scale over northern France: Preliminary investigation of the second-order sensitivity, J. Geophys. Res.-Atmos., 110, D24310, https://doi.org/10.1029/2005JD006151, 2005.
Ray, J., Lee, J., Yadav, V., Lefantzi, S., Michalak, A. M., and van Bloemen Waanders, B.: A sparse reconstruction method for the estimation of multi-resolution emission fields via atmospheric inversion, Geosci. Model Dev., 8, 1259–1273, https://doi.org/10.5194/gmd-8-1259-2015, 2015.
Rigby, M., Manning, A. J., and Prinn, R. G.: Inversion of long-lived trace gas emissions using combined Eulerian and Lagrangian chemical transport models, Atmos. Chem. Phys., 11, 9887–9898, https://doi.org/10.5194/acp-11-9887-2011, 2011.
Rodgers, C. D.: Inverse Methods for Atmospheric Sounding: Theory and Practice, Series on Atmospheric, Oceanic and Planetary Physics – Vol. 2, World Scientific Publishing Co. Pte. Ltd., Singapore, https://doi.org/10.1142/3171, 2000.
Saunois, M., Stavert, A. R., Poulter, B., Bousquet, P., Canadell, J. G., Jackson, R. B., Raymond, P. A., Dlugokencky, E. J., Houweling, S., Patra, P. K., Ciais, P., Arora, V. K., Bastviken, D., Bergamaschi, P., Blake, D. R., Brailsford, G., Bruhwiler, L., Carlson, K. M., Carrol, M., Castaldi, S., Chandra, N., Crevoisier, C., Crill, P. M., Covey, K., Curry, C. L., Etiope, G., Frankenberg, C., Gedney, N., Hegglin, M. I., Höglund-Isaksson, L., Hugelius, G., Ishizawa, M., Ito, A., Janssens-Maenhout, G., Jensen, K. M., Joos, F., Kleinen, T., Krummel, P. B., Langenfelds, R. L., Laruelle, G. G., Liu, L., Machida, T., Maksyutov, S., McDonald, K. C., McNorton, J., Miller, P. A., Melton, J. R., Morino, I., Müller, J., Murguia-Flores, F., Naik, V., Niwa, Y., Noce, S., O'Doherty, S., Parker, R. J., Peng, C., Peng, S., Peters, G. P., Prigent, C., Prinn, R., Ramonet, M., Regnier, P., Riley, W. J., Rosentreter, J. A., Segers, A., Simpson, I. J., Shi, H., Smith, S. J., Steele, L. P., Thornton, B. F., Tian, H., Tohjima, Y., Tubiello, F. N., Tsuruta, A., Viovy, N., Voulgarakis, A., Weber, T. S., van Weele, M., van der Werf, G. R., Weiss, R. F., Worthy, D., Wunch, D., Yin, Y., Yoshida, Y., Zhang, W., Zhang, Z., Zhao, Y., Zheng, B., Zhu, Q., Zhu, Q., and Zhuang, Q.: The Global Methane Budget 2000–2017, Earth Syst. Sci. Data, 12, 1561–1623, https://doi.org/10.5194/essd-12-1561-2020, 2020.
Spantini, A., Solonen, A., Cui, T., Martin, J., Tenorio, L., and Marzouk, Y.: Optimal Low-Rank Approximations of Bayesian Linear Inverse Problems, SIAM J. Sci. Comput., 37, 2451–2487, 2015.
Streets, D. G., Canty, T., Carmichael, G. R., De Foy, B., Dickerson, R. R., Duncan, B. N., Edwards, D. P., Haynes, J. A., Henze, D. K., Houyoux, M. R., Jacob, D. J., Krotkov, N. A., Lamsal, L. N., Liu, Y., Lu, Z., Martin, R. V., Pfister, G. G., Pinder, R. W., Salawitch, R. J., and Wecht, K. J.: Emissions estimation from satellite retrievals: A review of current capability, Atmos. Environ., 77, 1011–1042, https://doi.org/10.1016/j.atmosenv.2013.05.051, 2013.
Thompson, R. L. and Stohl, A.: FLEXINVERT: an atmospheric Bayesian inversion framework for determining surface fluxes of trace species using an optimized grid, Geosci. Model Dev., 7, 2223–2242, https://doi.org/10.5194/gmd-7-2223-2014, 2014.
Turner, A. J. and Jacob, D. J.: Balancing aggregation and smoothing errors in inverse models, Atmos. Chem. Phys., 15, 7039–7048, https://doi.org/10.5194/acp-15-7039-2015, 2015.
Turner, A. J., Jacob, D. J., Wecht, K. J., Maasakkers, J. D., Lundgren, E., Andrews, A. E., Biraud, S. C., Boesch, H., Bowman, K. W., Deutscher, N. M., Dubey, M. K., Griffith, D. W. T., Hase, F., Kuze, A., Notholt, J., Ohyama, H., Parker, R., Payne, V. H., Sussmann, R., Sweeney, C., Velazco, V. A., Warneke, T., Wennberg, P. O., and Wunch, D.: Estimating global and North American methane emissions with high spatial resolution using GOSAT satellite data, Atmos. Chem. Phys., 15, 7049–7069, https://doi.org/10.5194/acp-15-7049-2015, 2015.
Veefkind, J. P., Aben, I., McMullan, K., Förster, H., de Vries, J., Otter, G., Claas, J., Eskes, H. J., de Haan, J. F., Kleipool, Q., van Weele, M., Hasekamp, O., Hoogeveen, R., Landgraf, J., Snel, R., Tol, P., Ingmann, P., Voors, R., Kruizinga, B., Vink, R., Visser, H., and Levelt, P. F.: TROPOMI on the ESA Sentinel-5 Precursor: A GMES mission for global observations of the atmospheric composition for climate, air quality and ozone layer applications, Remote Sens. Environ., 120, 70–83, https://doi.org/10.1016/j.rse.2011.09.027, 2012.
Wecht, K. J., Jacob, D. J., Frankenberg, C., Jiang, Z., and Blake, D. R.: Mapping of North American methane emissions with high spatial resolution by inversion of SCIAMACHY satellite data, J. Geophys. Res.-Atmos., 119, 7741–7756, https://doi.org/10.1002/2014JD021551, 2014.
Xu, Q.: Measuring information content from observations for data assimilation: Relative entropy versus shannon entropy difference, Tellus A, 59, 198–209, https://doi.org/10.1111/j.1600-0870.2006.00222.x, 2007.