the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 27 Jan 2022
| 27 Jan 2022
Rainfall retrieval algorithm for commercial microwave links: stochastic calibration
Aart Overeem
Hidde Leijnse
Remko Uijlenhoet
During the last decade, rainfall monitoring using signal-level data from commercial microwave links (CMLs) in cellular communication networks has been proposed as a complementary way to estimate rainfall for large areas. Path-averaged rainfall is retrieved between the transmitting and receiving cellular antennas of a CML. One rainfall estimation algorithm for CMLs is RAINLINK, which has been employed in different regions (e.g., Brazil, Italy, the Netherlands, and Pakistan) with satisfactory results. However, the RAINLINK parameters have been calibrated for a unique optimum solution, which is inconsistent with the fact that multiple similar or equivalent solutions may exist due to uncertainties in algorithm structure, input data, and parameters. Here, we show how CML rainfall estimates can be improved by calibrating all parameters of the algorithm systematically and simultaneously with the stochastic particle swarm optimization method, which is used for the numerical maximization of the objective function. An open dataset of approximately 2800 sub-links of minimum and maximum received signal levels over 15 min intervals covering the Netherlands (∼ 35 500 km2) is employed: 12 d are used for calibration and 3 months for validation. A gauge-adjusted radar rainfall dataset is utilized as a reference. Verification of path-average daily rainfall shows a reasonable improvement for the stochastically calibrated parameters with respect to RAINLINK's default parameter settings. Results further improve when averaged over the Netherlands. Moreover, the method provides a better underpinning of the chosen parameter values and is therefore of general interest for calibration of RAINLINK's parameters for other climates and cellular communication networks.
- Article
(4235 KB) - Full-text XML
- BibTeX
- EndNote





Accurate rainfall observations with high temporal and spatial resolution are crucial for, e.g., agriculture, meteorology, flood warnings, and freshwater resource management. However, for many places on the Earth's land surface, accurate rainfall information is lacking, especially from ground-based measurements at sub-daily and daily timescales (Sun et al., 2018). Another issue is the data availability of ground-based measurements. For instance, the largest worldwide rain gauge database, maintained by the Global Precipitation Climatology Centre (GPCC), had 45 000 rain gauges in 1961–2000, down to 10 000 after 2016. This decrease was caused by a delay in data delivery and by post-processing at GPCC (Schneider et al., 2021). Although decreasing in the past due to quality control, the GPCC database has been increasing in recent years as a result of delivery of updates as well as supplements with additional stations and long time series of data (Schneider et al., 2021).
Suggested by Upton et al. (2005) and initially applied by Messer (2006) and Leijnse et al. (2007), the technique to estimate rainfall intensities based on signal-level data from commercial microwave links (CMLs) is slowly but surely becoming a complementary source of rainfall information next to traditional ground-based measurements from rain gauges, weather radars, and disdrometers. A CML is the link along a path between a transmitting antenna on one cell phone tower and a receiving antenna on another cell phone tower, often having two sub-links for communication in both directions. Since rainfall attenuates microwave radiation at frequencies of tens of gigahertz (GHz) (wavelengths of about 1 cm), typically employed by CMLs, the integrated rain-induced attenuation along the link path can be computed from the decrease in signal levels with respect to dry weather and subsequently converted to path-average rainfall. The core of the rainfall retrieval algorithm is the conversion of specific attenuation k (dB km−1) to path-average rainfall intensity R (mm h−1) via the power-law relation R=akb (Atlas and Ulbrich, 1977; Olsen et al., 1978). The coefficient a (mm h−1 dB−b kmb) and exponent b (–) depend mainly on the microwave link's frequency and polarization and on the raindrop size distribution (DSD) (Leijnse et al., 2007). Before applying the power-law relation, the received signal power must be processed to filter out any attenuation unrelated to rain and to compare signals during a rainy interval with those from dry intervals. A typical workflow consists of (i) CML data acquisition and pre-processing, (ii) identification of rain events in noisy raw data (wet–dry classification), (iii) baseline determination representative of dry intervals, (iv) removal of outliers due to malfunctioning links, (v) correction of received signal powers, and (vi) computation of mean path-average rainfall intensities (Overeem et al., 2016a; Chwala and Kunstmann, 2019).
An advantage of CMLs is that they use the existing infrastructure of mobile network operators (MNOs) for network maintenance, data storage, and acquisition. Furthermore, CMLs can be employed as a complement to existing rain gauge and weather radar networks, as well as in areas where instruments for ground observation are poor or non-existent. Thus, rainfall retrieval from CML data and subsequent mapping is a form of “opportunistic” sensing that has gained prominence in recent years (Uijlenhoet et al., 2018; Chwala and Kunstmann, 2019).
A number of studies highlight the successful employment of CMLs for rainfall retrieval, of which the most relevant for this study are discussed here. Zinevich et al. (2009) show that this technique is suitable for measuring near-ground rainfall around the cities of Ramle and Modi'in (area ≈ 900 km2; density ≈ 0.025 CML km−2) in Israel. Incorporating the uncertainty associated with the different sources of rainfall information, Bianchi et al. (2013) obtained reliable rainfall intensity estimates by combining rain gauge, radar, and microwave link observations in the Zürich area, Switzerland (area ≈ 460 km2; density ≈ 0.03 CML km−2). In a dedicated case study in Prague, Czech Republic, Fencl et al. (2015) used 14 CMLs over a small area of 2.5 km2 (i.e., a density of 5.6 CML km−2), concluding that quantitative precipitation estimates from CMLs capture the spatiotemporal rainfall distribution at the microscale very well. Recently, de Vos et al. (2019) reached correlations around 0.60 for daily rainfall accumulations using instantaneously sampled data from a CML network in the Netherlands (density ≈ 0.054 CML km−2). Moreover, comparing those results with earlier studies in the Netherlands, the authors highlight the fact that min–max sampling outperforms instantaneous sampling in terms of rainfall estimates. Long-term studies involving country-wide verification of CML rainfall estimates based on data from a few thousand CMLs are provided by Overeem et al. (2016b) for the Netherlands employing RAINLINK (Overeem et al., 2016a) and by Graf et al. (2020) for Germany employing pycomlink (https://github.com/pycomlink/pycomlink, last access: 16 October 2020), which are both open-source rainfall retrieval packages. Machine learning supervised algorithms have been used for rainfall retrieval via CMLs, improving the performance of this kind of rainfall measurement (Pudashine et al., 2020; Habi and Messer, 2021). These data-driven solutions also hold promise for ungauged areas, but it will not be feasible for places or countries without sufficient reference data to train the machine learning algorithms. That is, data-driven models require a huge number of observations to learn and detect the whole behavior of the phenomenon to be modeled. For other algorithms, such as RAINLINK, it may still be feasible to at least tune a few parameters, for instance, by employing drop size distribution observations (from a region with a similar climate) to obtain more appropriate coefficients of the relationship between specific attenuation and rain rate.
Likewise, research has been conducted to evaluate CML-derived rainfall in hydrological model responses. Brauer et al. (2016) study the effects of differences in rainfall measurement techniques (including CMLs) on discharge and groundwater simulations using a lumped rainfall–runoff model in a small (6.5 km2) catchment. CML-derived rainfall estimates are found to lead to much better results than real-time weather radar data when comparing discharge and groundwater simulations to observations for a full year. Investigating the potential of CML-derived rainfall estimates for streamflow prediction and water balance analyses, Smiatek et al. (2017) observe a significant improvement in the reproduction of observed discharge values for events with local heavy rainfall. The authors find that even rainfall fields provided by gauge-adjusted weather radar do not capture such events, which suggests that an extremely dense monitoring network would be needed to properly capture local heavy rainfall. Likely, this explains why Liberman et al. (2014) achieve better results by merging CML and radar data rather than using just one of these sources to retrieve rainfall intensities.
Despite all these studies showing the potential of CMLs for rainfall monitoring, challenges remain. These are mainly related to dealing with typical sources of error, e.g., wetting of antennas in rain events causing additional attenuation and hence resulting in rainfall overestimation, as well as signal-level decrease during dry periods in CML raw data (Leijnse et al., 2008; Messer and Sendik, 2015; Overeem et al., 2016a). Rainfall retrieval algorithms for CMLs aim to take these phenomena into account, although issues such as wet–dry classification still require improvement. Another challenge concerns the calibration of the parameters of the rainfall retrieval algorithms. Current calibration procedures fall short of addressing the uncertainties associated with CML signal levels (e.g., due to different brands of antennas and varying path lengths), algorithm structure (e.g., attenuation thresholds for classification of rainy and non-rainy periods), model parameters (e.g., for wet antennas and outlier filters), and rainfall itself (e.g., due to DSD spatial variability along the link path). Concretely, the parameters of the algorithms are calibrated empirically in order to obtain a unique optimum solution. In fact, many optimum solutions can occur, corresponding to different parameters sets (a phenomenon known as equifinality).
Here, we partly address this by calibrating the most important parameters of the open-source rainfall retrieval algorithm RAINLINK systematically and simultaneously with the stochastic particle swarm optimization method. This is preceded by a sensitivity analysis selecting the most important parameters. RAINLINK has been used for CML rainfall estimation in various regions, i.e., Australia, Brazil, Italy, the Netherlands, Nigeria, Pakistan, and Sri Lanka (Overeem et al., 2016a, b; Sohail Afzal et al., 2018; Rios Gaona et al., 2018; de Vos et al., 2019; GSMA, 2019; Roversi et al., 2020; Overeem et al., 2021b; Pudashine et al., 2021), and has been calibrated deterministically (Overeem et al., 2011, 2013, 2016a, b; de Vos et al., 2019). With the new optimization method, we provide a better underpinning of parameter values for this CML rainfall retrieval algorithm. Moreover, we optimize for the first time the main RAINLINK processes, i.e., wet–dry classification and rainfall retrieval, separately. These resulting CML rainfall estimates are contrasted with those based on RAINLINK's default parameter values (Overeem et al., 2011, 2013, 2016a). A gauge-adjusted radar rainfall dataset is utilized as a reference for the CML-derived path-average rainfall estimates. We use a large publicly available CML dataset of approximately 2800 sub-links of minimum and maximum received signal levels over 15 min intervals covering the Netherlands (∼ 35 500 km2); 12 d are used for calibration and 3 months for validation.
This study is organized as follows. First, the study area, datasets (Sect. 2.1), and methodology (Sect. 2.2 and 2.3) employed for RAINLINK calibration are presented. Next, the results and discussion (Sect. 3) present our major findings. Finally, the conclusions (Sect. 4) summarize the findings and highlight the recommendations and outlooks for further research.
2.1 Study area and datasets
The study area considered is the Netherlands (∼ 35 500 km2; Fig. 1a), which has a temperate oceanic climate according to the Köppen–Geiger classification (Peel et al., 2007). CML data were obtained from MNO T-Mobile NL: minimum and maximum received power over 15 min intervals based on 10 Hz sampling with a precision of 1 dB. Data from approximately 2800 sub-links (validation) and 2940 (calibration) per time interval were available (after pre-processing with RAINLINK). The 12 d calibration dataset used to optimize RAINLINK's parameters covers the period from June to September 2011. It served as a validation dataset in Overeem et al. (2013). The 3-month validation dataset covers the summer months of June, July, and August 2012. We only use data from summer in the Netherlands to prevent analyzing events with solid precipitation. This has the added advantage of the data bearing greater resemblance to rainfall in (sub)tropical climates, where the use of CMLs for rainfall retrieval has the largest potential.
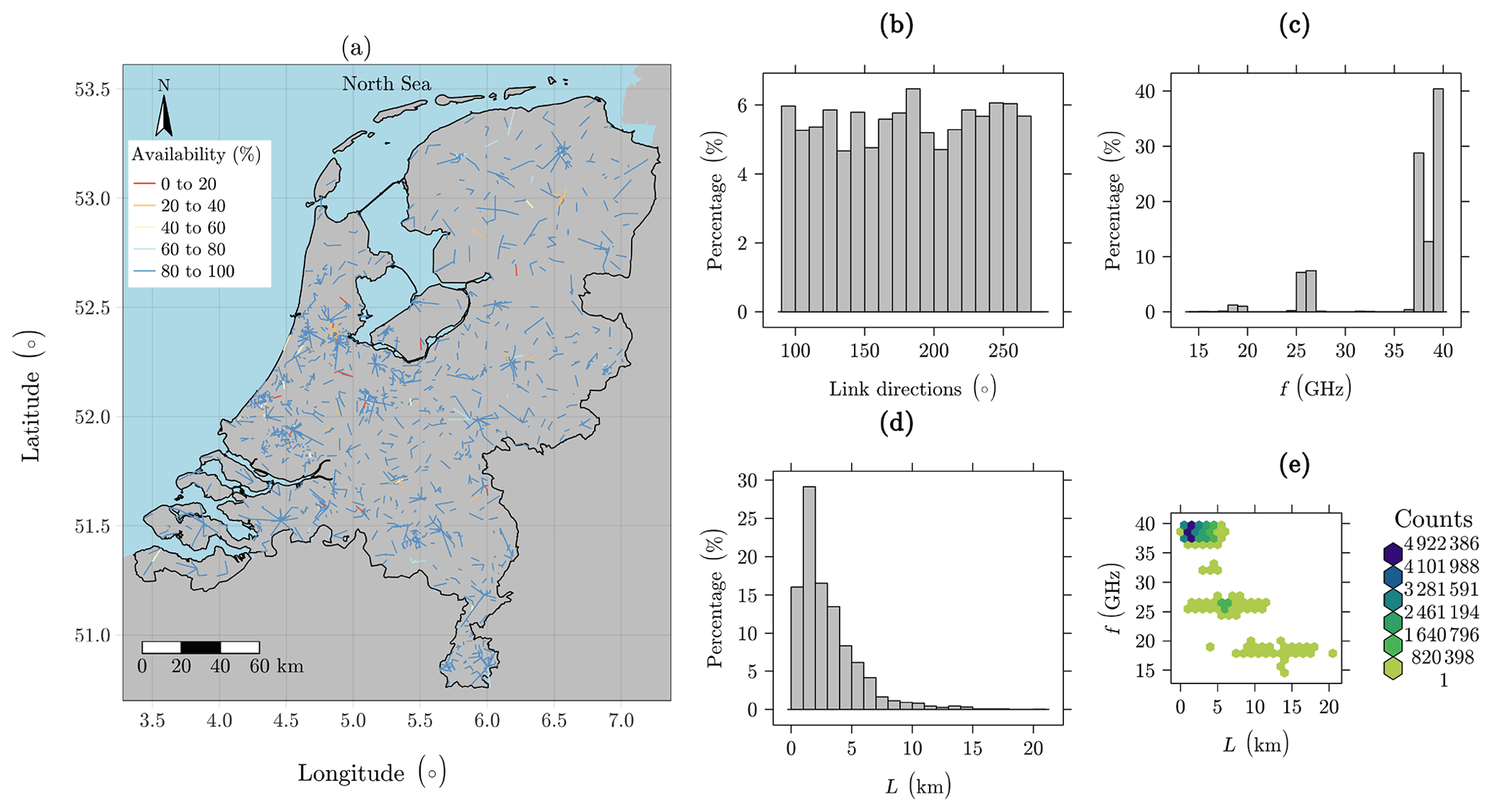
Figure 1Map of the Netherlands and sub-link characteristics for the validation dataset: (a) CML locations and availability, (b) distribution of link directions, (c) distribution of microwave link frequencies, (d) distribution of link lengths, and (e) density of link length and frequency combinations.
Figure 1 illustrates the main characteristics of the CML dataset used for validation. Being distributed over the entire country (Fig. 1a), the CMLs have a high temporal and spatial data availability; i.e., 92 % of sub-links have observations for more than 80 % of the period. In spite of not having a perfectly uniform distribution in terms of their directions, all direction classes are well-represented (Fig. 1b). Microwave frequencies range from ∼ 13 to 40 GHz (the majority from 37 to 40 GHz, Fig. 1c). Lengths vary from 0.1 to 20 km (the majority less than 5 km, Fig. 1d), with shorter lengths typically corresponding to higher microwave frequencies (Fig. 1d).
A climatological gauge-adjusted radar rainfall dataset of 5 min rainfall depths, aggregated over 15 min, was used as a reference for calibration of the rainfall retrieval algorithm (RAINLINK) and validation of rainfall estimates. The radar dataset is maintained by the Royal Netherlands Meteorological Institute (KNMI) and has a 1 km spatial resolution. For more details, see Overeem et al. (2009a, b, 2011).
2.2 Rainfall retrieval algorithm
Overeem et al. (2016a) describe the CML rainfall retrieval algorithm RAINLINK. Made available as an R package (R Core Team, 2018), the current version of RAINLINK is 1.21 (Overeem et al., 2021a), and version 1.2 was used in this study, which is hosted at https://doi.org/10.5281/zenodo.5907524 (Overeem et al., 2022). The code has been published together with Overeem et al. (2016a). RAINLINK's default parameter values are derived or selected (Overeem et al., 2011, 2013, 2016a). The algorithm begins with a quality control by pre-processing the CML data. Links with frequencies lower than 12.5 GHz and higher than 40.5 GHz are discarded. Moreover, the attributes frequency, link coordinates, path length, and identifier are checked for either duplicated or mismatched information. Next, RAINLINK is divided into two main sub-processes, one for defining wet and dry periods and the other one for the actual rainfall retrieval.
2.2.1 Wet–dry classification
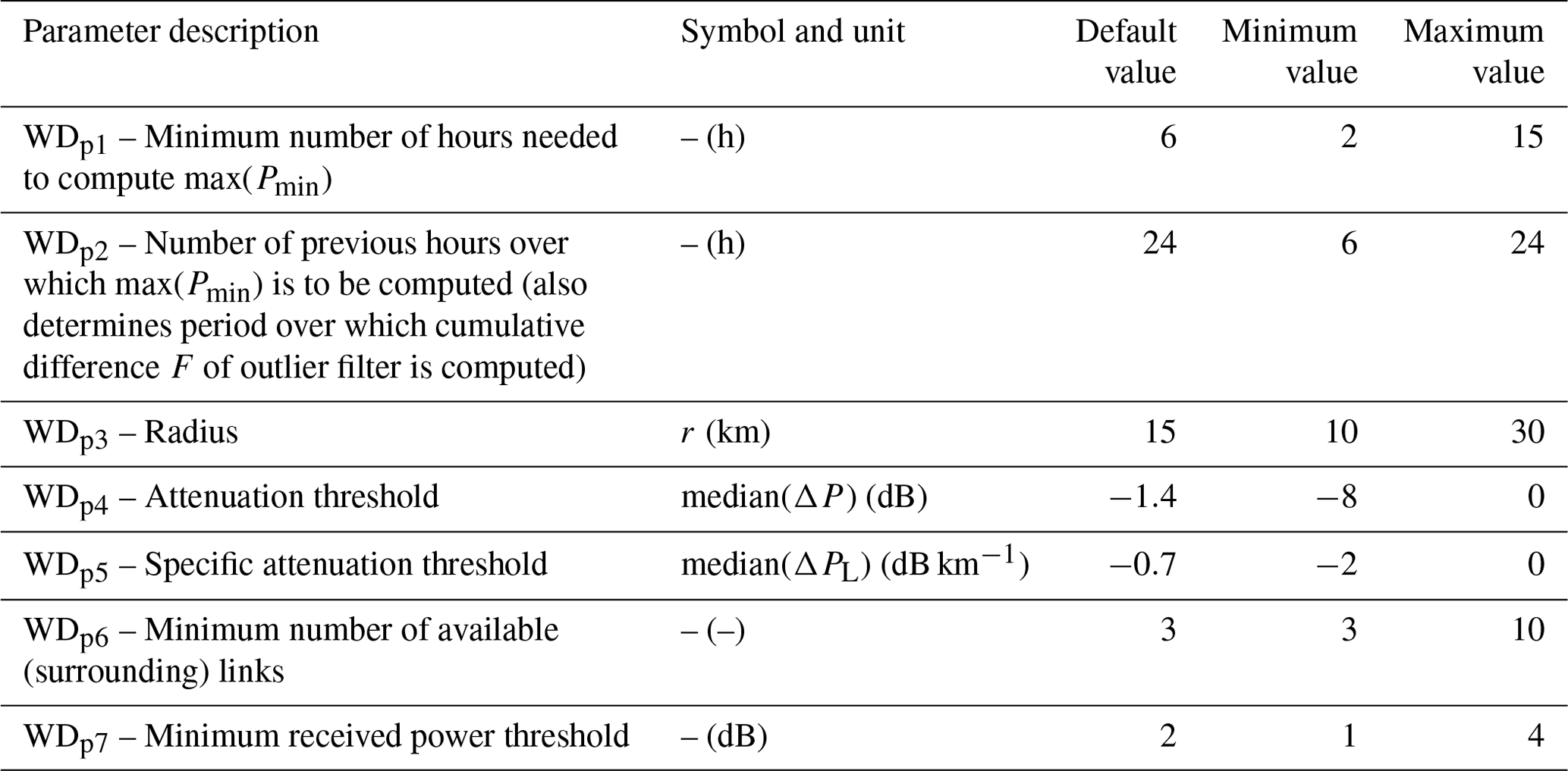
The process to define wet and dry periods assumes that rainfall is spatially correlated. Therefore, during a rainy time interval, a substantial decrease in received signal levels should be detected by nearby links within a specific radius (Overeem et al., 2011, 2016a). This approach is called the “nearby link approach”. The output is a binary response to indicate wet and dry periods. Table 1 highlights all employed parameters.
Table 1Wet–dry classification parameters (WDpn): default values from RAINLINK and calibration search space (minimum and maximum values). Modified from Overeem et al. (2016a).
2.2.2 Rainfall retrieval
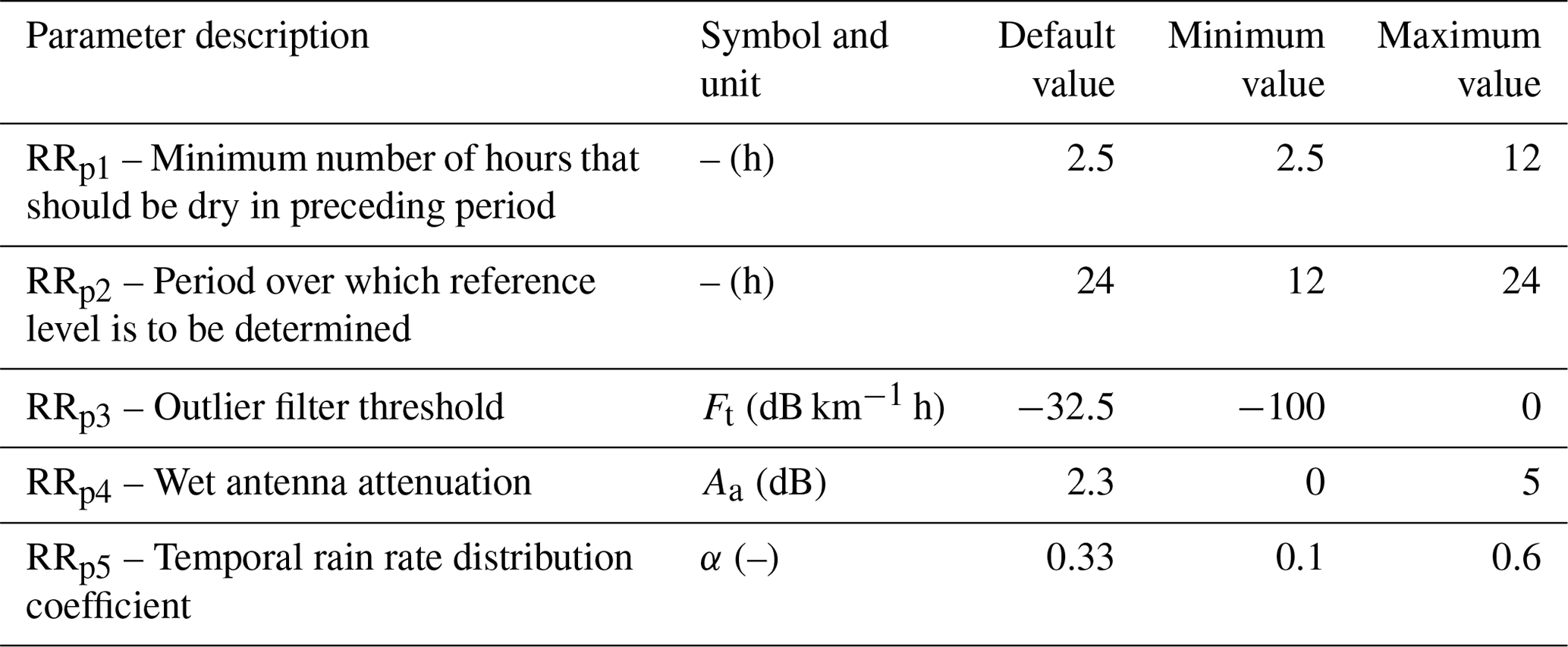
Once the rainy and non-rainy time intervals have been identified, a reference signal level (Pref) is computed, which represents the median received power during dry intervals. Next, outliers are removed by applying a filter which uses specific attenuation derived from the uncorrected minimum received power. It assumes that rainfall is correlated in space. The filter removes a time interval of a link for which the time-integrated difference between its specific attenuation and that of the surrounding links over the previous period (Table 2, parameter RRp2) is lower (i.e., more negative) than a certain threshold (Table 2, parameter RRp3).
Table 2Rainfall retrieval parameters (RRpn): default values from RAINLINK and calibration search space (minimum and maximum values). Modified from Overeem et al. (2016a).
To prevent nonzero rainfall estimates during non-rainy intervals, corrected minimum () and maximum () received power is calculated by adjusting the signals to the base level for non-rainy intervals. Subsequently, the minimum and maximum rain-induced attenuation, Amin (dB) and Amax (dB), respectively, are calculated for each link and time interval using
Next, the minimum and maximum path-averaged rainfall intensities, (mm h−1) and (mm h−1), respectively, are computed according to
where H is the Heaviside function (if the argument of H is smaller than zero, H=0; else H=1). Aa (dB) is a fixed wet antenna attenuation correction term, and a (mm h−1 dB−b kmb) and b (–) are the coefficient and exponent of the employed power-law R−k relation, respectively. The values of a and b, which depend mainly on link frequency, have been derived from measured raindrop size distributions and computations of electromagnetic scattering by raindrops for vertically polarized signals (Leijnse et al., 2008). The polarization for individual links was unknown, but the majority of links used vertically polarized signals.
Finally, the mean path-averaged rainfall intensity, (mm h−1), is computed by means of
where α is a coefficient which determines the contribution of the minimum and maximum path-averaged rainfall intensity during a time interval. Table 2 gives an overview of all parameters used in the rainfall retrieval process.
2.3 RAINLINK sensitivity analysis and calibration
Using the mean 15 min path-averaged rainfall intensities retrieved from RAINLINK, the parameters with the highest importance in the algorithm are identified by means of a sensitivity analysis called Latin hypercube one factor at a time (LH-OAT) (Van Griensven et al., 2006). This method ensures that the full range of parameters is sampled according to an LH design and within each sample the parameters are tested one at a time. Initially, it takes N LH sample points for N intervals while varying each LH sample point p times by changing each of the n parameters one at a time, according to the OAT design (Van Griensven et al., 2006). Around each Latin hypercube point a relative partial effect for each parameter is calculated. A final effect is calculated by averaging the partial effects over all N LH points. Thus, local sensitivities (i.e., partial effects) get integrated into a global sensitivity measure. Having the same feature as the Monte Carlo sampling, i.e., a global screening method, LH sampling reduces the computational cost significantly (n−1 times), therefore being more efficient (Van Griensven et al., 2006).
The method is very efficient, as the N intervals in the LH method require a total of N(p+1) evaluations. The relative importance of the parameters is determined by ranking the final effects from large to small (Van Griensven et al., 2006). Each relative importance can be divided by the sum of all relative importances to yield a normalized measure of relative importance. We choose a step size that represents a fraction of 0.1 of the parameter search space. The 12 parameters selected for the sensitivity analysis are listed in Tables 1 and 2. The most sensitive parameters are selected such that the sum of their normalized relative importances reaches at least 95 %.
After having selected the most important parameters by sensitivity analysis, the RAINLINK parameters are optimized with the standard particle swarm optimization (SPSO-2011) method (Clerc, 2012). As a major improvement over previous PSO versions with an adaptive random topology and rotational invariance, SPSO-2011 is a stochastic, effective, and efficient calibration method, as highlighted in recent studies with other hydrological and environmental models (Abdelaziz and Zambrano-Bigiarini, 2014; Bisselink et al., 2016; Pijl et al., 2018). The optimization is performed for the two RAINLINK sub-processes separately. First, the wet–dry classification parameters are calibrated to make sure RAINLINK is able to correctly identify dry and rainy periods. Next, using the optimum parameters for the wet–dry classification, the rainfall retrieval parameters are calibrated. We have included all zero rainfall observations in the entire calibration process for both the gauge-adjusted radar reference and the RAINLINK estimates. Note that data from individual sub-links were used in the calibration process, so data from two links (in opposite directions) having the same link path were not averaged.
The goodness-of-fit measures chosen to drive the optimization and performance for the wet–dry classification and the rainfall retrieval processes are the Matthews correlation coefficient (MCC) (Matthews, 1975) and the modified Kling–Gupta efficiency (KGE) (Kling et al., 2012), respectively. Both are maximized towards an optimum value of 1. A 15 min time interval from a given sub-link is considered dry if the reference is below 0.25 mm.
Due to the higher frequency of non-rainy 15 min intervals (data points), the process of wet–dry classification is considered an imbalanced classification problem. Employing recurrent metrics for binary classification, such as F1 score and accuracy, may lead to inflated results. The Matthews correlation coefficient is less subjective and preferred since it informs how correlated the predictions and observations are, reaching a high score only if the prediction obtained good results in all four confusion matrix categories (true positives – TPs, false negatives – FNs, true negatives – TNs, and false positives – FPs) (Chicco and Jurman, 2020). The Matthews correlation coefficient is defined as
The denominator is arbitrarily set to 1 when any of the four sums in the denominator is zero. Kling–Gupta efficiency is defined as
with ρ the Pearson correlation coefficient, β the bias ratio
and γ the variability ratio,
where μ and σ are the mean and standard deviation of path-averaged rainfall intensity (mm h−1) for CML estimates (e) and gauge-adjusted radar observations (o). CV is the coefficient of variation, defined as the ratio of the standard deviation and the mean.
2.4 RAINLINK validation
The validation was performed for both wet–dry and rainfall retrieval RAINLINK processes by using the newly calibrated parameters against its default parameters as given by Overeem et al. (2016a). In addition to MCC and following the confusion matrix, the assessment binary metrics, accuracy, sensitivity, and specificity were computed as follows:
As for the RAINLINK rainfall retrieval process, besides KGE and its components ρ, β, and γ, the CV of the residuals (CVres), the percent bias (PBIAS), and root mean square error (RMSE) were employed:
Finally, the level of agreement of daily rainfall is analyzed graphically. RAINLINK's ability to estimate 15 min path-average rainfall rates is also evaluated. Moreover, both agreement of accumulated rainfall for all individual CMLs and agreement of daily mean rainfall over the Netherlands estimated from the CML values (as time series) are considered, taking those links with over 75 % of data availability into account.
3.1 Calibration
3.1.1 Wet–dry classification parameter optimization
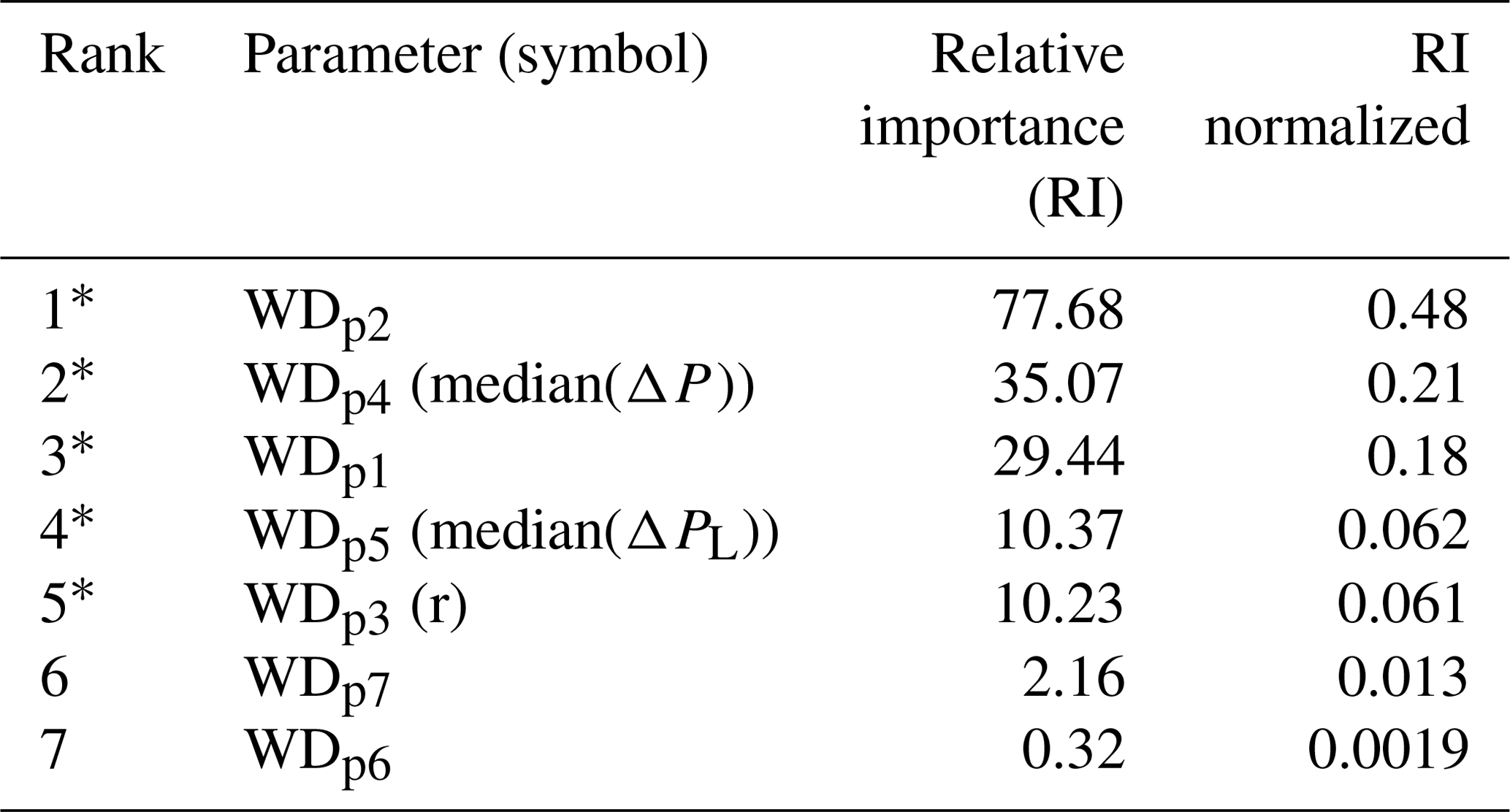
The sensitivity analysis for the wet–dry classification process is performed at a 15 min time interval. Table 3 provides the parameter ranking obtained considering the search space illustrated in Table 1. The most important parameters are WDp2, WDp4 (median(ΔP)), WDp1, WDp5 (median(ΔPL)), and WDp3 (r). The accumulated relative importance of these parameters is 98 %. The importance of the two thresholds (WDp4 and WDp5) was expected because these parameters define the values for which an individual microwave link will be classified as rainy or not. However, the analysis performed here, which systematically evaluates all parameters together by maximizing a goodness-of-fit measure, reveals that the parameters WDp2, WDp1, and WDp5 are important as well. The highest importance reached by the WDp2 parameter highlights the rain-induced attenuation temporal correlation. Since this parameter represents the number of previous hours over which the maximum value of the minimum received power (max(Pmin)) is computed, it governs the wet–dry classification process by influencing the attenuation (median(ΔP)) and specific attenuation (median(ΔPL)) computation. It is important to highlight that the max(Pmin) is only computed if at least a minimum number of hours (defined by WDp1) of data are available; otherwise it is not computed and no rainfall intensities are retrieved. The low ranking of the WDp7 threshold is consistent with the findings of Overeem et al. (2016a), who report that including this step hardly changes results for a 12 d dataset when validating rainfall depths (i.e., the total effect on the amounts, not the occurrence of wet and dry periods as such).
Table 3Wet–dry classification sensitivity analysis: WDpn (symbol) – wet–dry classification parameters; see description in Table 1.
Note: ∗ most sensitive parameters obtained from the Latin hypercube one-factor-at-a-time analysis.
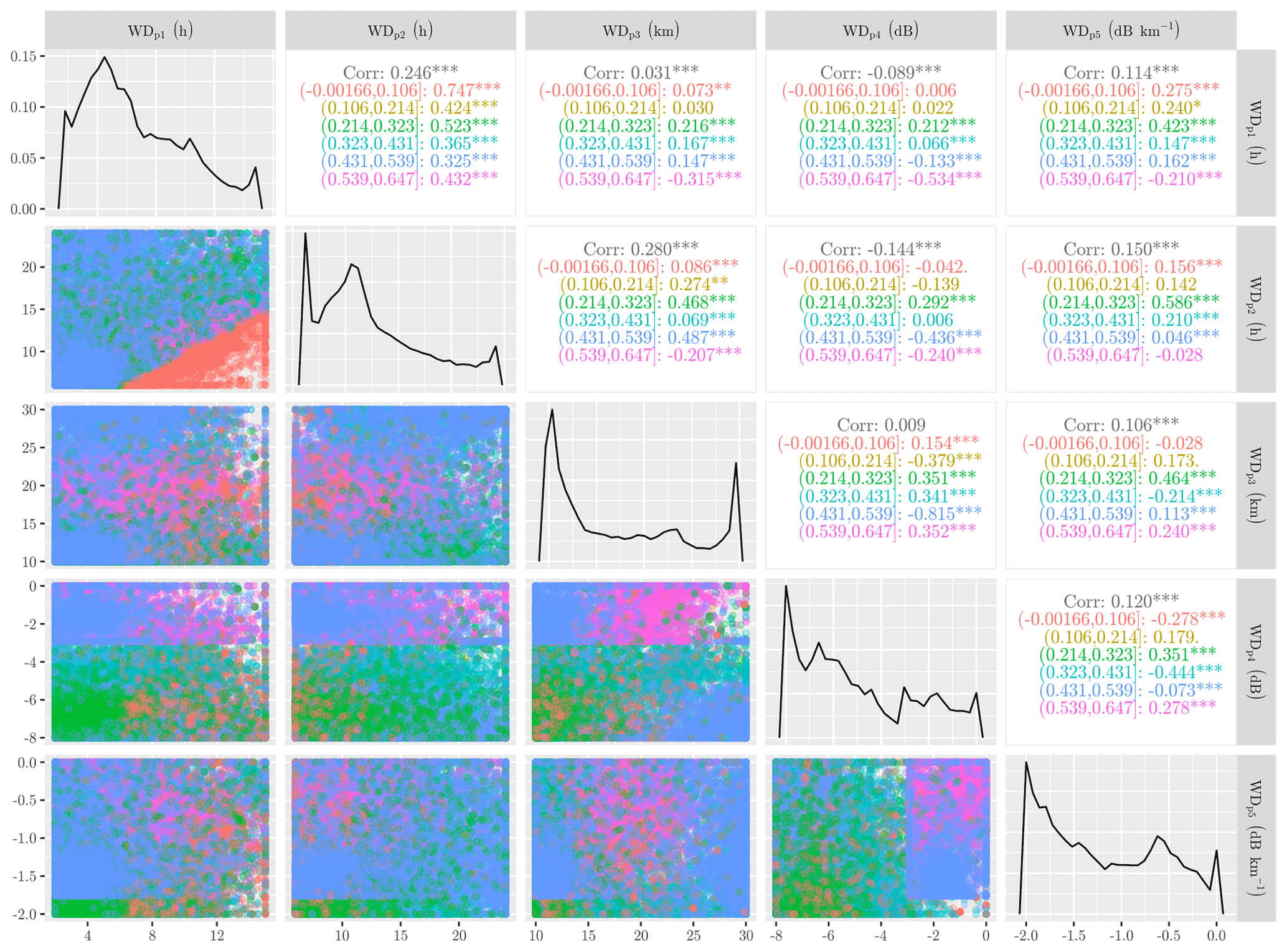
Figure 2Calibration of the wet–dry classification parameters: panel showing the interaction between calibration parameters at different Matthews correlation coefficient (MCC) values. Note: the upper-right diagonal represents the correlation among the parameters for both the total samples (black values) and the grouped samples (color values) by MCC intervals. Significance levels: p<0.001, ∗ p<0.05, “.” p<0.1, and no symbol p<1.
The five highest-ranked parameters are now employed in the calibration, taking the ranges reported in Table 1 into account. Using particle swarm optimization (PSO), the parameters' dispersion and distributions across the search space have been computed for the 12 d calibration dataset (Fig. 2). The distributions are obtained for all solutions, and the frequency histograms of the parameters are multi-modal and skewed, reflecting the uncertainties in the optimum values.
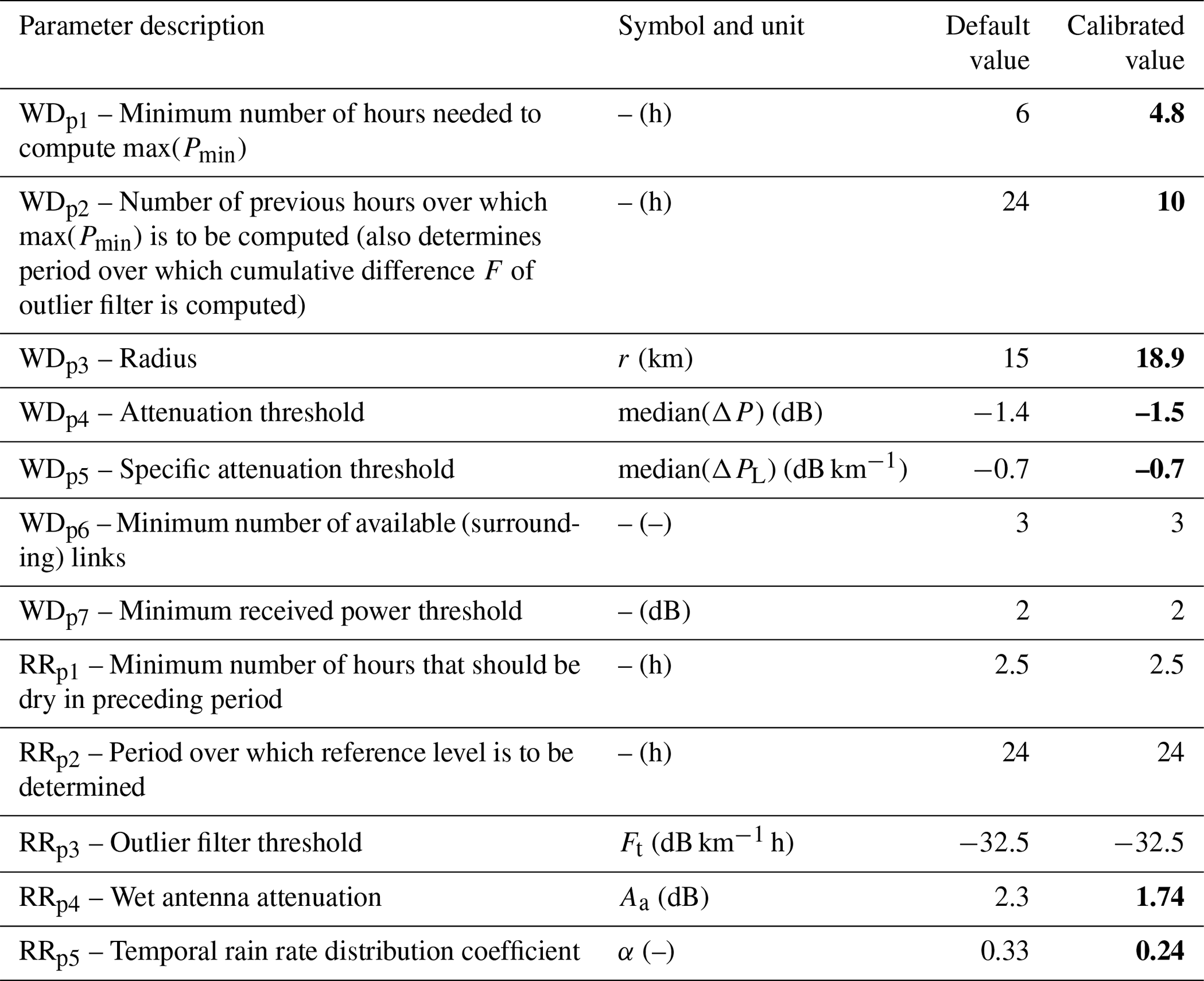
The parameters WDp1, WDp2, WDp3, WDp4, and WDp5 reach optimum values equal to 7.5 h, 14.1 h, 19.7 km, −2.7 dB, and −0.9 db km−1, respectively. Compared with the default values of these parameters, namely 6 h, 24 h, 15 km, −1.4 dB, and −0.7 dB km−1, the difference is considered small for the parameters WDp1, WDp3, and WDp5. However, the parameters WDp2 and WDp4 presented a reasonable difference compared to the default values. For solutions with an MCC value greater than 0.53, which are classified as “behavioral” solutions (Zambrano-Bigiarini and Rojas, 2013), the median values of the parameters were 4.8 h, 10 h, 18.9 km, −1.5 dB, and −0.7 dB km−1 for WDp1, WDp2, WDp3, WDp4, and WDp5, respectively. The values obtained for the calibrated parameters are based on the median of the behavioral solutions and are in line with the default parameters, except for WDp2, which indicates a shorter period for computing the maximum of the minimum received power. A possible explanation for the optimized value of 10 h in contrast to the default value of 24 h is that this 10 h period is more representative for the wet–dry classification. For instance, signal fluctuations due to, e.g., changes in atmospheric moisture in the period 24 to 10 h before the current interval may result in wet–dry classification parameter values being less representative, which may lead to less accurate wet–dry classification.
It should be noted that, in spite of being gauge-adjusted, the radar product used here is not a perfect reference. Differences between radar sampling (indirect measurements aloft) and ground-based sensors can lead to significant errors (de Vos et al., 2019). Thus, accounting for this sampling difference could even further increase the value of the MCC metric. In particular for small rainfall events, these errors can lead to false positive and false negative classifications.
The value of the WDp1 parameter results in exclusion of 12 % of the data points during the algorithm processing for both default and calibrated parameters sets (which have a similar value). This parameter has a direct relation with data availability, since it determines the minimum number of hours needed to compute max(Pmin). Note that max(Pmin) is only computed if at least a minimum number of hours of data are available; otherwise it is not computed and no rainfall intensities will be retrieved (Overeem et al., 2016b). Although the calibration dataset has been selected considering rainy days, the number of non-rainy data points is much higher than the number of rainy data points, representing 93 %, which is comparable to the average occurrence of dry spells in the Netherlands according to automatic weather stations. Thus, this calibration period can be considered representative for other periods within the same weather season.
3.1.2 Rainfall retrieval parameter optimization
The same sensitivity analysis and calibration are employed for the rainfall retrieval at the 15 min time interval (Table 4); zeroes in the CML and/or reference are also included. The sensitivity analysis presented here underlines the uncertainty associated with the microwave link measurements. The most sensitive parameters are RRp5 (α) and RRp4 (Aa). The summed relative importance of these parameters is 95 %.
Table 4Rainfall retrieval sensitivity analysis: RRpn – rainfall retrieval parameters; see Table 2.

The parameter RRp4 is related to the correction of the attenuation due to wet antennas. This phenomenon is considered an important source of extra attenuation and may cause significant rainfall overestimation if not sufficiently accounted for (Leijnse et al., 2008; Messer and Sendik, 2015; Overeem et al., 2016a).
Since the parameter RRp5 represents a coefficient that determines the relative contributions of the minimum and maximum path-averaged rainfall intensities ( and , Eq. 3) to the 15 min average rainfall intensity estimates, it is directly related to the temporal sampling strategy of the received signal power and has an important weight in the rainfall retrieval. In a comparative study, de Vos et al. (2019) found that min–max sampling at a 15 min time interval (as employed by RAINLINK) outperforms instantaneous sampling in the Dutch climate. This underlines the importance of properly estimating RRp5 (α) for accurate rainfall retrievals.
The parameter RRp3 (Ft) represents an outlier filter. Therefore, it seems reasonable to assume a threshold value based on expert judgment because strict filtering would result in a high performance, but with a severe decline in the remaining number of links. Using the default values of the parameters RRp4 (Aa) and RRp5 (α) obtained in Overeem et al. (2013), Overeem et al. (2016a) applied a sensitivity analysis varying only the parameter RRp3 (Ft), confirming that the default value equal to −32.5 dB km−1 h−1 (Overeem et al., 2013) is a reasonable trade-off between performance and retaining a significant number of links. Although considered unimportant by the sensitivity analysis in the range from −100 to 0 dB km−1 h, a proper calibration procedure is deemed important, and the default value of RRp3 (Ft) fixed at −32.5 dB km−1 h−1 is kept to prevent an excessive loss of data. One way forward to calibrate RRp3 (Ft) would be to include the number of available links in the optimization or perform an optimization based on rainfall maps, which can be influenced by the underlying CML network density.
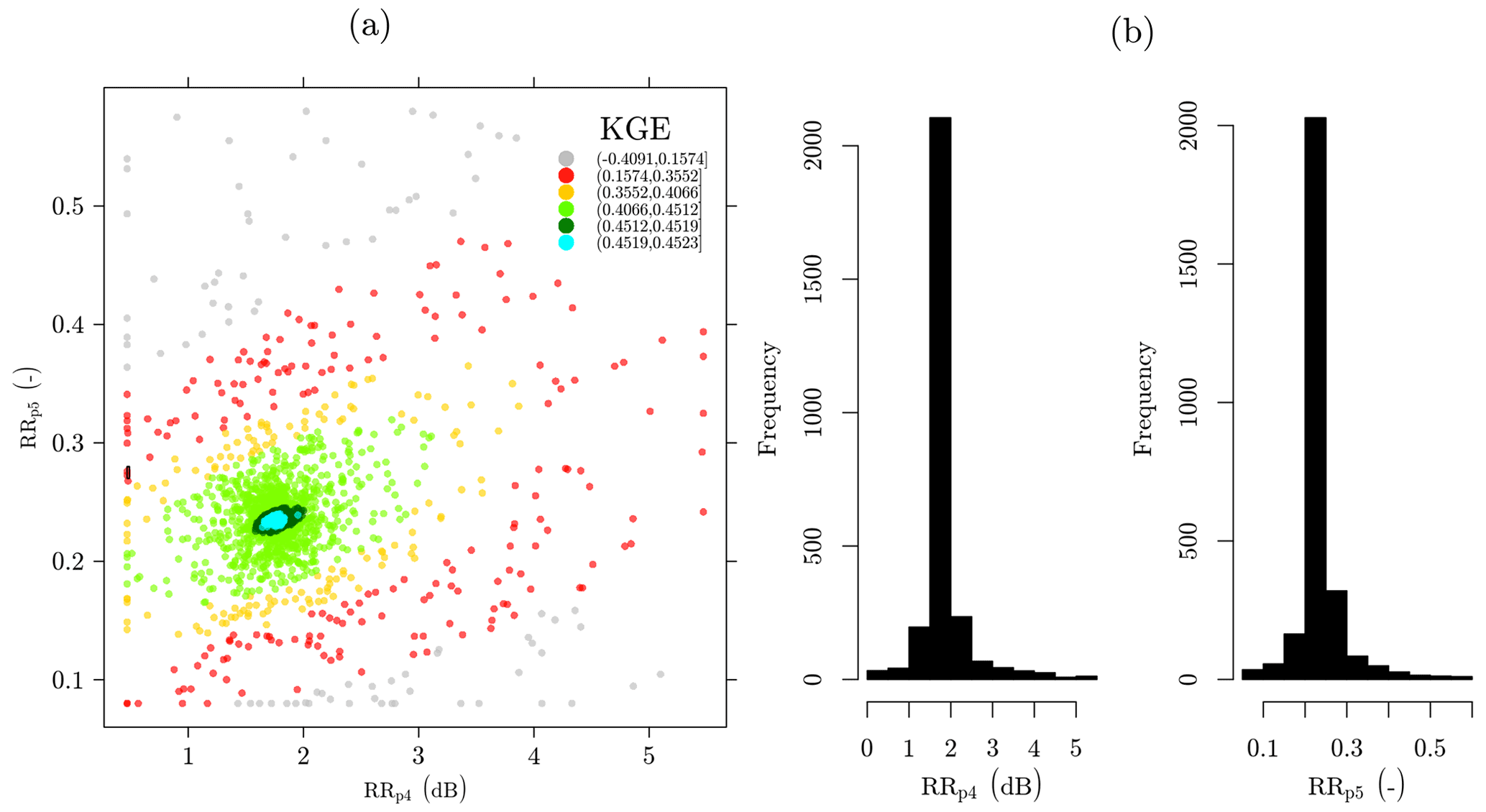
Figure 3Rainfall retrieval performance projected onto the parameter space: dotty plot showing the interaction between calibration parameters at different Kling–Gupta efficiency (KGE) values.
Figure 3 illustrates the interaction between parameters in the calibration procedure for the rainfall retrieval at different KGE values. This figure shows that the regions with the highest KGE values (green and blue points) correspond mainly to values ranging from 1 to 2.5 dB for RRp4 and from 0.17 to 0.30 for RRp5. We classified the solutions greater than 0.45 as behavioral solutions (dark green and blue points in Fig. 3a). Different from the calibration of the wet–dry classification process, we observe a distribution of the parameters that is less skewed and with a well-defined mode (Fig. 3b). Thus, for the respective parameters RRp4 and RRp5, the optimum values of 1.7 dB and 0.23 are almost identical to the median values for the behavioral solutions of 1.74 dB and 0.24.
The parameter RRp4 shows a more pronounced dispersion than the parameter RRp5. RRp4 is related to wet antenna attenuation and varies depending on the ambient conditions, e.g., while there is dew, rainwater, or melting precipitation (the latter unlikely in this study) present on the antenna covers (Leijnse et al., 2008; Overeem et al., 2016b; Uijlenhoet et al., 2018). It may also vary depending on the type of antenna cover. Finally, in the rainfall retrieval algorithm it is always assumed that, whenever it rains, RRp4 is constant, whereas in reality neither antenna, only one antenna, or both antennas may be wet. Hence, it is unlikely that all CMLs across the considered study area will share the same excess signal attenuation in terms of magnitude, timing, and spatial occurrence. In principle, each single CML is expected to have its own time-varying set of values of the parameter RRp4. This implies great uncertainty in the overall optimum value for the time period and region of interest. These parameters are expected to be positively correlated. Likely, higher RRp5 values lead to higher rain intensities, increasing the weight of the maximum attenuation, and consequently a higher value of RRp4 would become necessary to compensate for the extra attenuation, decreasing the rain intensity estimates.
It is apparent from Fig. 3 that the parameter RRp5 reaches its optimum value at 0.23, which is much lower than RAINLINK's default value of 0.33. This implies that the maximum and minimum path-averaged rainfall intensities (, ) have respective weights of 0.23 and 0.77 in the computation of the best estimate of the 15 min mean path-averaged rainfall intensity. However, a smaller spread around the optimum value compared to the other parameters can be observed, indicating a moderate uncertainty around the optimum. Note that the value of α is related to the temporal distribution of path-average rainfall intensities within 15 min intervals, which is influenced by the lengths of the links as well as by the rainfall space–time variability. This suggests that the optimum parameter value will depend on both link network topology and rainfall climatology.
Its important to highlight that we did not calibrate the power-law coefficients. Since they are physically based, we used values obtained in dedicated experiments representative for the Dutch climate (Leijnse, 2007). For other countries, the International Telecommunication Union (ITU) presents recommendations (International Telecommunication Union, 2005). However, these are not representative for all climates. A physically based approach which derives these coefficients from drop size distribution observations and scattering computations is preferred compared to optimizing these coefficients in a statistical manner, especially for frequencies higher than 35 GHz. The drop size distribution dependence of the k−R relation in the frequency range of approximately 20–35 GHz is considered small compared to errors from wet antenna attenuation or erroneous wet–dry classification. Although a physically based approach is considered better, a calibration of power-law coefficients may be a way forward for regions which lack disdrometer data (Ostrometzky and Messer, 2020).
3.2 Validation
After the parameter optimization using the 12 d calibration dataset from 2011, the optimized and default parameter sets are applied to a 3-month validation dataset from July, August, and September 2012. The 15 min path-average rainfall estimates were aggregated to hourly and daily path-average rainfall estimates if CML availability was at least 75 %, resulting in data from on average 2783 sub-links for both the default and optimized parameters. Thus, given that after the RAINLINK pre-processing on average 2800 sub-links are left, data availability is reduced by approximately 0.7 % for both default and optimized parameters due to the pre-processing.
3.2.1 Wet–dry classification validation
Figure 4 highlights that the wet–dry classification process by using calibrated parameters performs better in terms of MCC and accuracy metrics, with values of 0.40 and 0.96 against 0.37 and 0.95 for the default parameters, respectively. However, the sensitivity metric shows that the calibrated parameters are worse for classifying the true positive rate; the default parameter set reaches a value of 0.51 against 0.49 for the calibrated parameter set. We find an MCC value of 0.4 for the validation dataset, which is smaller than the MCC threshold for behavioral solutions, i.e., 0.53. This occurred because the optimization might not have generalized the wet–dry classification process well enough. It was focused on the calibration dataset, capturing many details and noise, and subsequently failed to capture a different trend from another dataset, i.e., became an overfitted model. Thus, the performance for the validation dataset was worse because the calibration dataset will not be entirely representative for other periods. A solution could be to increase the size of the calibration dataset, encompassing more characteristics and trends about the phenomenon.

Figure 4Confusion matrices and binary classification metrics for the wet–dry classification process: (a) results of the wet–dry classification using calibrated parameters and (b) results of the wet–dry classification using default parameters. Note: Matthews correlation coefficient (MCC), accuracy (Acc.), sensitivity (Sen.), and specificity (Spe.) metrics.
In spite of having the same specificity value, we can observe in confusion matrices (Fig. 4, green cells for line and column 1) that the calibrated parameter set classified more dry periods correctly than the default parameter set. Thus, considering the MCC feature, which aims to evaluate all elements of the confusion matrix (false positive, false negative, true positive, and true negative), the calibrated parameters outperform the default ones. Approximately 50 % of the rainy events are classified as dry (i.e., false negatives) for both the calibrated and default parameter sets. Using a convolutional neural network for classifying wet–dry periods, Polz et al. (2020) found a proportion of approximately 25 % for false negatives.
According to the wet–dry observations of the reference during the validation period, we observed that 97 % of the data points represent non-rainy intervals. Being just 4 percentage points higher than the calibration period (93 %), the fraction of dry periods can be considered comparable to each other. However, the fraction of rainy periods for the calibration period (7 %) is more than twice as high as for the validation period (3 %). This implies that the calibration dataset is at least different with respect to the validation dataset concerning the percentage of rainy periods, which may have resulted in a lower MCC value for validation.
3.2.2 Rainfall retrieval validation
Figure 5 illustrates the performance in terms of daily path-average rainfall estimates for the two tested parameter sets, i.e., calibrated and default. In general, the metrics for the calibrated parameters are slightly better than those for the default parameters. The values improve from 0.37 to 0.45 for KGE, from 6.37 to 5.75 mm for RMSE, from 2.5 to 2.27 for CVres, and from 0.42 to 0.46 for ρ.

Figure 5Daily path-averaged rainfall depth comparison of CML rainfall estimates against gauge-adjusted radar data: (a) rainfall retrieved using calibrated parameters; (b) rainfall retrieved using default parameters.
The main improvement is observed for the percent bias (PBIAS). Even if both parameter sets lead to overestimates compared to the reference, the rainfall depth retrieved when using the calibrated parameters shows 10.6 percentage points less overestimation compared to using the default parameters. In addition to ρ, the bias ratio (β) and the variability ratio (γ) are incorporated into the KGE metric (Eqs. 5–7). The default parameters β and γ are 1.24 and 0.99, respectively. For the calibrated parameters the values of β and γ are 1.13 and 0.99, respectively. All three KGE components have their ideal value at unity, and the higher value of KGE when using the calibrated parameters is due to a better bias performance. Overall, the calibrated parameters outperform the default parameters.
Table 5The 15 min path-averaged rainfall depth performance for different thresholds. Note: reference is provided by the gauge-adjusted radar data.
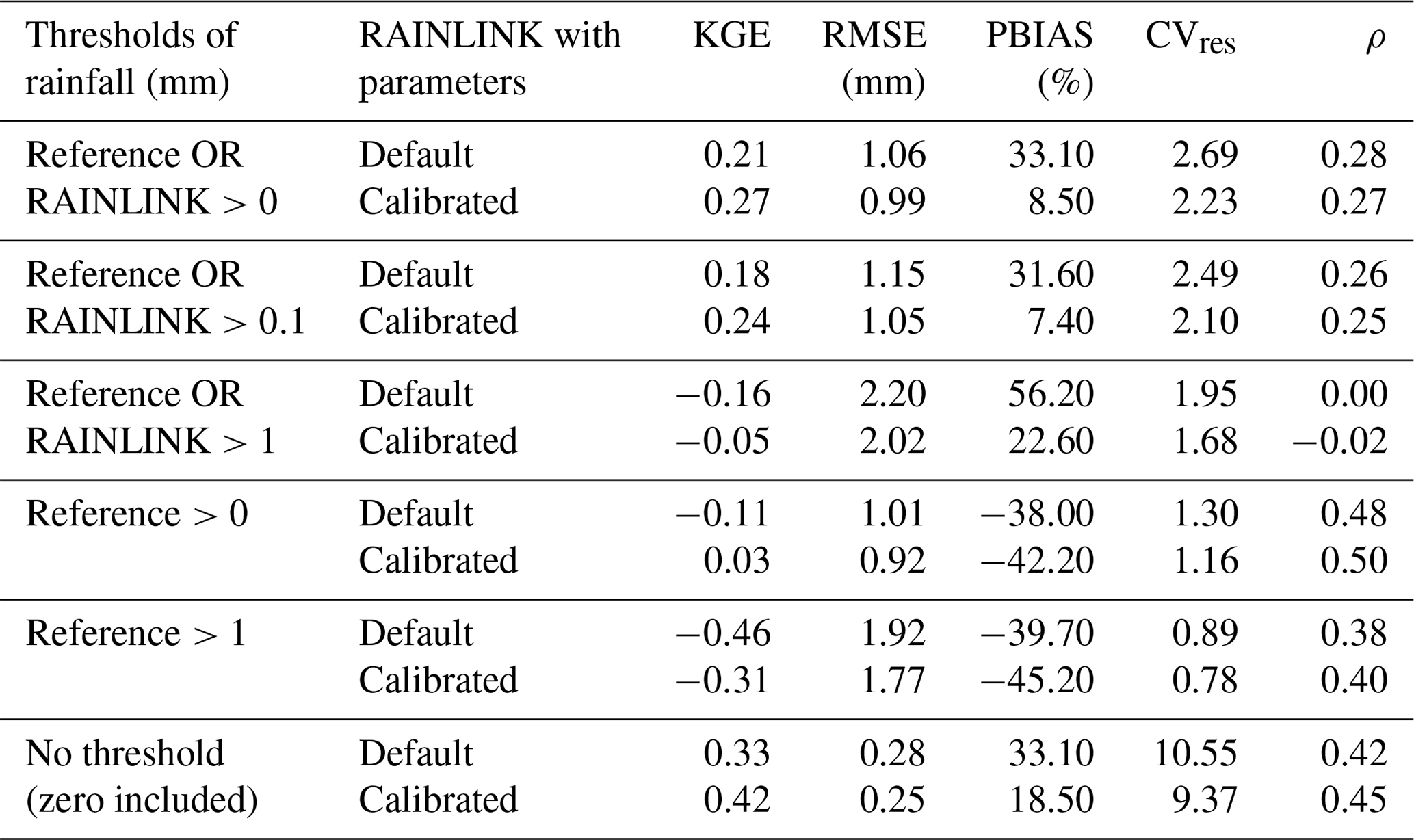
Next, the performance of 15 min path-averaged rainfall estimates is investigated. Table 5 summarizes RAINLINK's performance when the default and calibrated parameters are applied for different rainfall thresholds. The calibrated parameter set yields a better performance of RAINLINK in terms of KGE, RMSE, and CVres for all thresholds. As for PBIAS, the default parameters outperform the calibrated ones for the thresholds “reference >0” and “reference >1”, whereas the calibrated parameters show better performance for the remaining thresholds. One can also observe that, if a threshold is only applied to the reference and consequently the false positives are removed, RAINLINK shows a large underestimation with respect to the reference. This underestimation is not observed if either RAINLINK or the reference is above the threshold. This indicates that the observed underestimation is due to RAINLINK estimating zero rain when the reference suggests that it is raining. This may be related to differences in spatial and temporal sampling, although we are not able to provide a conclusive explanation. Indeed, the false positives presented a strong effect on PBIAS because when they were removed (i.e., reference >0), PBIAS changed significantly. As for Polz et al. (2020) a different behavior was observed, maybe due to a lower number of false positives or due to a different distribution of false positives.
The ρ goodness-of-fit metric results in a better performance for the default parameters with the CML rainfall estimates used in the thresholds. On the other hand, when just the radar reference is considered in the thresholds, the calibrated parameter set achieves better ρ performance.
When no thresholding is applied the calibrated parameters clearly perform better than the default ones in terms of KGE and PBIAS values. With respect to data availability, the calibrated and default parameter sets contain 15.6 % and 12.3 % fewer observations after running all of RAINLINK's processing steps than the entire dataset, respectively.
Reevaluating the Overeem et al. (2016b) study employing default parameter values, de Vos et al. (2019) find 5.75 %, 2.84, and 0.27 for PBIAS, CVres, and ρ, respectively, for path-average 15 min rainfall depths and for links or radars larger than 0 mm. Differences with respect to the performance obtained here for the default parameter values (33.10 %, 2.69, and 0.28 for PBIAS, CVres, and ρ, respectively) can be explained by the fact that the underlying data for both studies are from different periods with different durations (∼20 months for the months of February–October in de Vos et al., 2019, and 3 months for the months of June–August here). Possibly, the wet–dry classification using default parameters applied by de Vos et al. (2019) results in fewer false positives, or due to the longer period the false negatives compensate for the false positives, resulting in a lower PBIAS value. The summer of 2012 was rainy, with 286 mm of rain compared to the climatological average of 225 mm averaged over the Netherlands. For the central weather station in the Netherlands, a long precipitation duration of 153 h was observed compared to the climatological average of 121 h over the summer months June, July, and August. This could be a reason for differences in PBIAS, although this summer is also part of the 613 d dataset evaluated in de Vos et al. (2019).
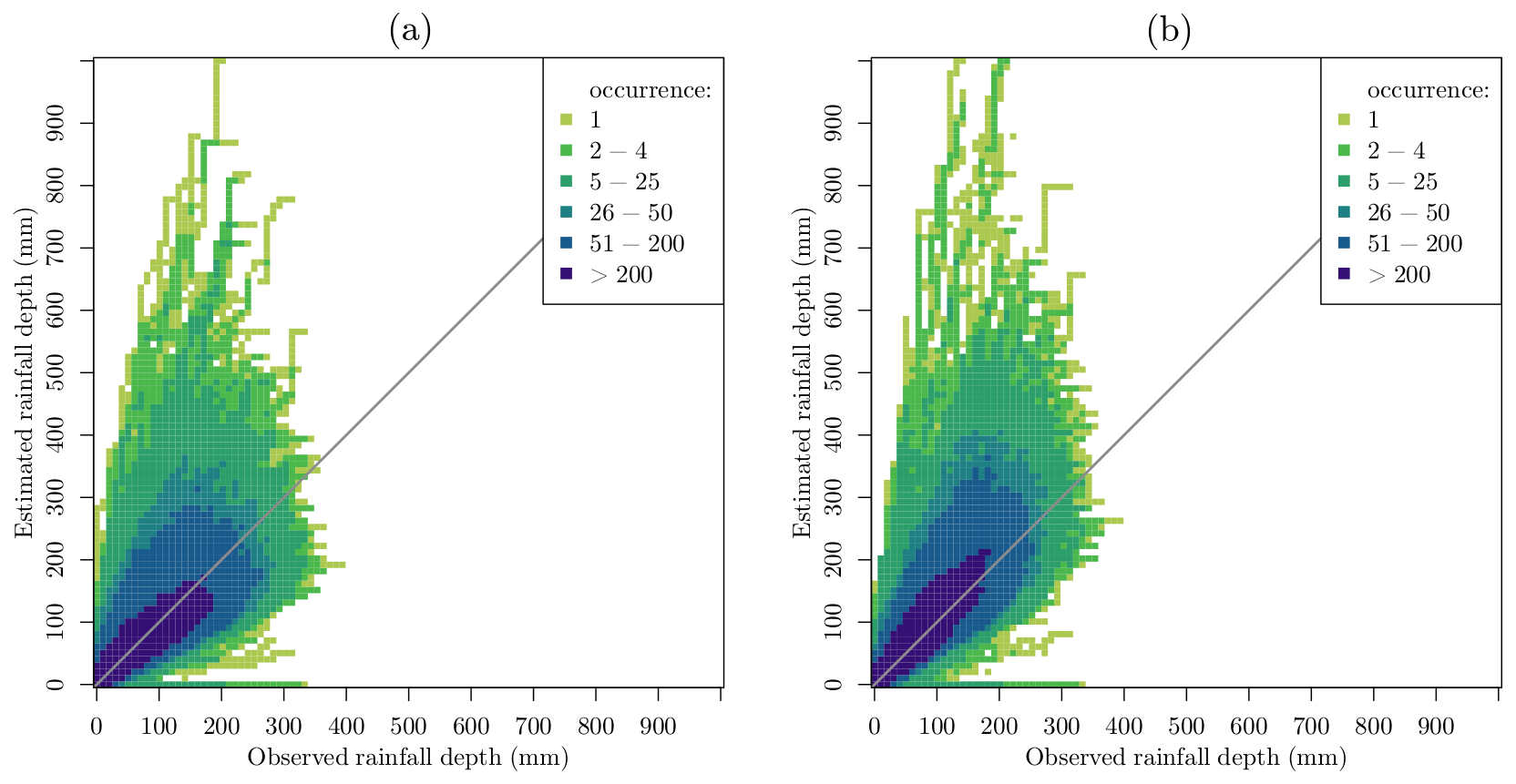
Figure 6Density plots of the double-mass curves of all individual CMLs with respect to the gauge-adjusted radar reference at 15 min time intervals: (a) rainfall accumulation retrieved by RAINLINK with calibrated parameters; (b) rainfall accumulation retrieved by RAINLINK with default parameters.
Figure 6 shows density plots for all CML double-mass curves, i.e., the relation between the accumulation of rainfall retrieved by RAINLINK and that obtained from the gauge-adjusted radar reference. This figure shows that the class with the highest occurrence coincides with the diagonal, indicating reasonable agreement between the estimates and the observations. A considerable dispersion above the diagonal is found for both the calibrated and the default parameters. However, it is clear that with the calibrated parameters, this dispersion is less severe. This overestimation observed in the double-mass curves is in line with the PBIAS values reported earlier (Table 5), being caused by the higher presence of false positive observations. Identifying the extra attenuation as the main source of error, de Vos et al. (2019) report a similar behavior of the double-mass curves for instantaneous signal power sampling, although the considered period and hence the meteorological circumstances are partly different.
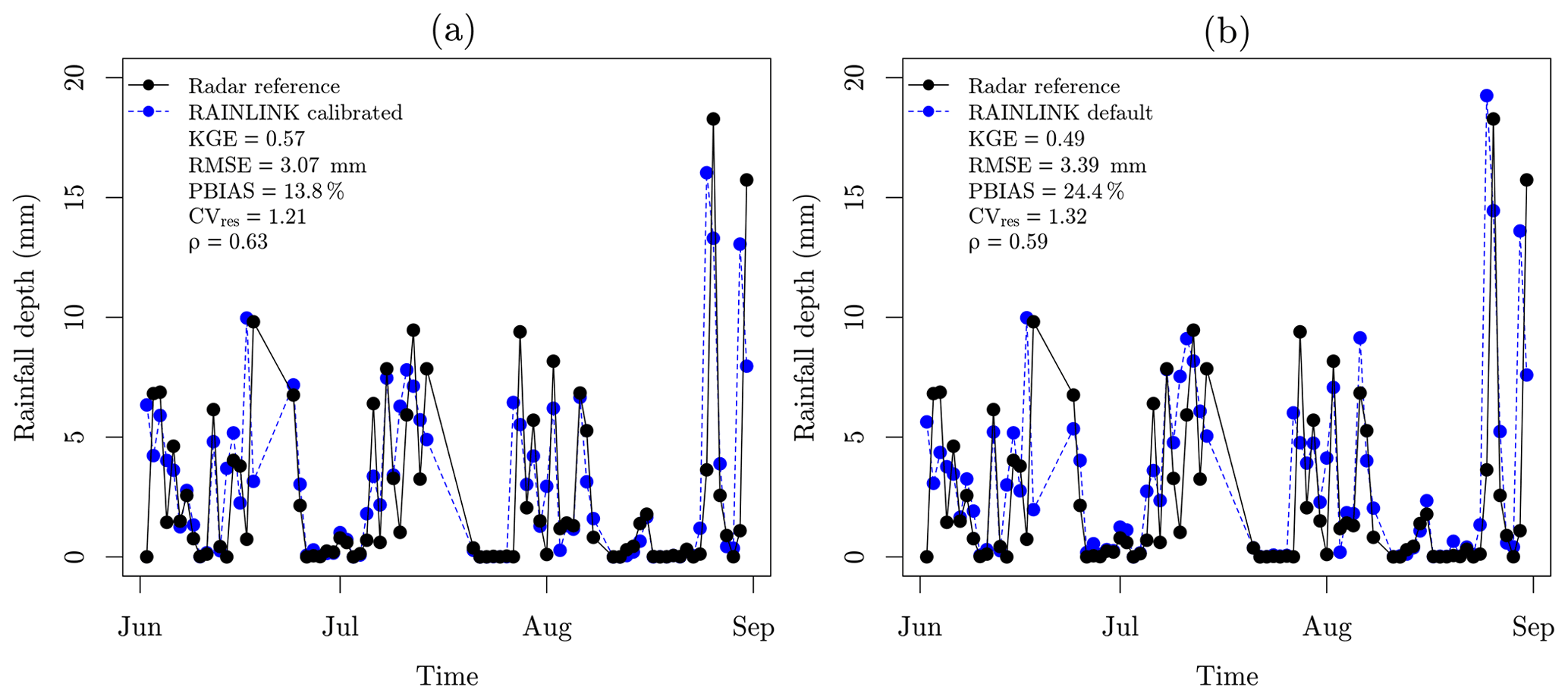
Figure 7Comparison of the daily mean rainfall depth time series for all of the Netherlands during the summer months of June, July, and August 2012: (a) rainfall time series retrieved by RAINLINK with calibrated parameters; (b) rainfall time series retrieved by RAINLINK with default parameters.
So far small improvements in the rainfall retrievals are obtained when employing the calibrated parameters through the stochastic method of particle swarm optimization (PSO). However, analyzing the average over an area, in this case the Netherlands, more substantial improvements are found. Figure 7 shows time series of the daily mean rainfall depth over the Netherlands; i.e., for each day the mean of all CML rainfall estimates is computed.
By employing the calibrated parameters, all metrics improve with respect to the default parameters. The values of KGE, RMSE, PBIAS, CVres, and ρ improve from 0.49, 3.39 mm, 24.4 %, 1.32, and 0.59 to 0.57, 3.07 mm, 13.8 %, 1.21, and 0.63, respectively. Since the CML rainfall estimates are averaged over a ∼ 35 500 km2 area not taking into account how they are distributed, the PBIAS and β values stay the same (Fig. 5). On the other hand, the variability and similarity (correlation), expressed by KGE components γ and ρ, respectively, are slightly better. In spite of not being a homogeneous network, the CMLs observe the entirety of the Netherlands with a high enough spatial representativity for computing a spatial average rainfall. Thus, for the areal time series obtained by employing calibrated parameters, γ and ρ are equal to 0.83 (0.81 for default) and 0.63 (0.59 for default), respectively. The γ value closer to unity confirms that the estimated rainfall time series vary to the same extent as the observed rainfall time series. Hence, as concluded from the path-averaged rainfall evaluation, the main improvement provided by the calibrated parameters compared to the default parameters is a lower relative bias.
For both sets of parameters, calibrated and default, CML-derived rainfall estimates correspond reasonably well to the gauge-adjusted radar rainfall estimates. For path-averaged daily rainfall an improvement is found when calibrated parameter values are employed, especially in terms of relative bias. Results further improve when rainfall estimates are averaged over all of the Netherlands. Differences in calibrated parameter values with respect to the default ones may be caused by the calibration being performed over different events in June and July 2009 and in 2011 for the default parameters (Overeem et al., 2011, 2013). Moreover, the calibration here is done with a state-of-the-art and efficient method.
3.3 Search space of parameters
For some parameters in Tables 1 and 2 a wider search space could have been chosen. For WDp2 and RRp2 a maximum value of 24 h was chosen, implying that data from the previous day are needed. Because the calibration dataset is not continuous, it was not feasible to use a larger value for WDp2. In both cases 24 h seems reasonably long for a reliable computation. The maximum allowed value of 24 h for RRp2 may even be beneficial for the reference-level determination. If this value became longer than 24 h, varying meteorological conditions (e.g., related to changes in relative humidity) may affect the accuracy of the reference-level determination, rendering it less representative of the reference level just before a rainfall event. For the radius WDp3 the minimum value is 15 km. A lower value could be tested, but given the network density (Fig. 1), this is expected to lead to a (severe) reduction of available sub-links. This is because the wet–dry classification needs a minimum number of nearby links, which is more difficult to achieve in the case of a smaller radius. The employed minimum value for WDp6 is already quite low. The wet–dry classification is expected to become more reliable when more sub-links are involved. Hence, it does not seem sensible to choose an even lower minimum value.
A novel and reliable method for the objective estimation of optimum parameter sets for RAINLINK and potentially for other CML-based rainfall retrieval algorithms has been presented and tested. Using a 12 d dataset, the calibration was performed by means of a stochastic approach, particle swarm optimization (PSO), preceded by a sensitivity analysis selecting the parameters to be optimized. The optimized parameters were determined according to optimum goodness-of-fit values and for the median of “behavioral” solutions, i.e., those solutions performing better than a threshold. Table 6 summarizes the values of RAINLINK's optimized parameters and the default ones.
Table 6RAINLINK parameters: default and calibrated values (median of “behavioral” solutions). Note: calibrated parameter values are in bold font.
The validation of daily path-averaged CML rainfall estimates over 3 summer months reveals a reasonable improvement for the calibrated parameters compared to the default values. When daily path-averaged values are averaged over the entire surface area of the Netherlands, the improvement becomes much stronger. The aggregation over an area tends to limit the effects of representativeness errors in the rainfall estimates and yields information with an acceptable performance for hydrological and meteorological applications. This result is important because from a general perspective, hydrological and meteorological scales of application are defined over areas, e.g., watersheds, climate zones, and political and administrative regions. Compelling improvements were achieved not only in terms of the performance of CML rainfall estimates as such, but also with respect to the choice of parameter values, which are now underpinned in a more objective way.
In fact, we now have a way to analyze the sensitivity and stochastically optimize all parameters used in a rainfall retrieval algorithm. The proposed methodology is applicable for different CML networks, climates, and algorithms, for which either rain gauge or (gauge-adjusted) radar data can be used as a reference. In the case of sampling strategies other than min–max the algorithm can be easily adapted. Ideally, optimized parameters would be obtained for different seasons. Hence, for each processing period a dedicated parameter set would be obtained.
Fencl et al. (2019) underline the importance of considering the rainfall properties in the quantification of wet antenna attenuation, for which a fixed value may lead to overestimation of heavy rainfalls. This can lead to an increase in the computational cost, however, especially in the case of extensive CML datasets. We also recommend extending our algorithm by adding an extra goodness-of-fit criterion to the optimization regarding the sub-link data availability after running RAINLINK's processing steps (de Vos et al., 2019). This could lead to improved coverage of CML rainfall estimates. In general, quantifying the effect of processing steps on data availability is important. Moreover, due to the large impact of false positives on PBIAS, a calibration of the rainfall retrieval process taking into account the wet–dry classification from the reference should be considered for further research. Thus, an overestimation of wet antenna attenuation that has to compensate for the long-term rainfall overestimation from false positives would be avoided.
As a recommendation, studies could be conducted by testing the convergence and performance of different goodness-of-fit measures in addition to the Kling–Gupta efficiency (Kling et al., 2012). Moreover, one could optimize the parameters using rain gauges near the CMLs as a reference in order to exclude deviations that are sometimes found in radar rainfall observations. Representativeness errors between radars measuring aloft and CMLs measuring near the Earth's surface can affect comparisons between the two. This especially holds for short time intervals, which are as short as 15 min in this study.
In spite of having stochastic properties and aiming to explore the uncertainties affecting rainfall retrievals from CMLs, the approach proposed here is not a panacea. In regions without reliable rainfall ground truth, the calibration of rainfall retrieval algorithm parameters can be a challenge (Chwala and Kunstmann, 2019). Hence, we recommend the setup of experiments in regions with little ground-based rainfall information in order to optimize parameters for specific networks and climates, or even to improve rainfall retrieval algorithms themselves such as RAINLINK. As an alternative, parameters could be optimized in a well-gauged region having a similar climate and CML network as the ungauged region for which CML rainfall estimates are desired.
Further research can be conducted to test how the parameter range affects the importance of parameters in this approach. Specifically, even wider parameter ranges could be tested. Moreover, a longer calibration period could be analyzed to make the optimized parameters more generally applicable to other data from other periods. This especially holds for the wet–dry classification process.
Comparing CML-derived rainfall maps and gauge-adjusted radar observations, Overeem et al. (2016b) found a better performance for the summer season than for the winter season in the Netherlands, likely related to the absence of snow and melting precipitation, among other factors. The rainfall type during the Dutch summer is largely of a convective nature, bearing some resemblance to that in regions characterized by (sub)tropical climates, which often lack surface rainfall observations. As a consequence, we believe CML rainfall monitoring is especially promising for low- to middle-income countries typically having (sub)tropical climates.
The RAINLINK code is available at https://doi.org/10.5281/zenodo.5907524 (Overeem et al., 2022). The CML data are available via https://doi.org/10.4121/uuid:323587ea-82b7-4cff-b123-c660424345e5 (Overeem, 2019). The gauge-adjusted radar data can be obtained at https://dataplatform.knmi.nl/dataset/rad-nl25-rac-mfbs-5min-2-0 (Overeem, 2017).
WW was responsible for the conceptualization, formal analysis, visualization, code, and writing of the original draft. AO and RU were responsible for the conceptualization and dataset and also reviewed and edited the paper together with HL.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We gratefully acknowledge Ronald Kloeg and Ralph Koppelaar from T-Mobile NL for providing the commercial microwave link data. We thank the two anonymous reviewers for their constructive comments.
This research has been supported by the Fundação de Amparo à Pesquisa do Estado de São Paulo (grant nos. 2017/09708-7 and 2016/15342-2).
This paper was edited by Alexis Berne and reviewed by two anonymous referees.
Abdelaziz, R. and Zambrano-Bigiarini, M.: Particle Swarm Optimization for inverse modeling of solute transport in fractured gneiss aquifer, J. Contam. Hydrol., 164, 285–298, https://doi.org/10.1016/j.jconhyd.2014.06.003, 2014. a
Atlas, D. and Ulbrich, C. W.: Path- and area-integrated rainfall measurement by microwave attenuation in the 1–3 cm band, J. Appl. Meteorol., 16, 1322–1331, https://doi.org/10.1175/1520-0450(1977)016<1322:PAAIRM>2.0.CO;2, 1977. a
Bianchi, B., van Leeuwen, P. J., Hogan, R. J., and Berne, A.: A variational approach to retrieve rain rate by combining information from rain gauges, radars, and microwave links, J. Hydrometeorol., 14, 1897–1909, https://doi.org/10.1175/JHM-D-12-094.1, 2013. a
Bisselink, B., Zambrano-Bigiarini, M., Burek, P., and de Roo, A.: Assessing the role of uncertain precipitation estimates on the robustness of hydrological model parameters under highly variable climate conditions, Journal of Hydrology: Regional Studies, 8, 112–129, https://doi.org/10.1016/j.ejrh.2016.09.003, 2016. a
Brauer, C. C., Overeem, A., Leijnse, H., and Uijlenhoet, R.: The effect of differences between rainfall measurement techniques on groundwater and discharge simulations in a lowland catchment, Hydrol. Process., 30, 3885–3900, https://doi.org/10.1002/hyp.10898, 2016. a
Chicco, D. and Jurman, G.: The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation, BMC Genomics, 21, 6, https://doi.org/10.1186/s12864-019-6413-7, 2020. a
Chwala, C. and Kunstmann, H.: Commercial microwave link networks for rainfall observation: Assessment of the current status and future challenges, WIREs Water, 6, e1337, https://doi.org/10.1002/wat2.1337, 2019. a, b, c
Clerc, M.: Standard Particle Swarm Optimisation, Hal Open Sci., 15 pp., available at: https://hal.archives-ouvertes.fr/hal-00764996 (last access: 21 September 2020), 2012. a
de Vos, L., Overeem, A., Leijnse, H., and Uijlenhoet, R.: Rainfall estimation accuracy of a nation-wide instantaneously sampling commercial microwave link network: error-dependency on known characteristics, J. Atmos. Ocean. Tech., 36, 1267–1283, https://doi.org/10.1175/JTECH-D-18-0197.1, 2019. a, b, c, d, e, f, g, h, i, j, k
Fencl, M., Rieckermann, J., Sýkora, P., Stránský, D., and Bareš, V.: Commercial microwave links instead of rain gauges: fiction or reality?, Water Sci. Technol., 71, 31, https://doi.org/10.2166/wst.2014.466, 2015. a
Fencl, M., Valtr, P., Kvicera, M., and Bares, V.: Quantifying wet antenna attenuation in 38-GHz commercial microwave links of cellular backhaul, IEEE Geosci. Remote S., 16, 514–518, https://doi.org/10.1109/LGRS.2018.2876696, 2019. a
Graf, M., Chwala, C., Polz, J., and Kunstmann, H.: Rainfall estimation from a German-wide commercial microwave link network: optimized processing and validation for 1 year of data, Hydrol. Earth Syst. Sci., 24, 2931–2950, https://doi.org/10.5194/hess-24-2931-2020, 2020. a
GSMA: Mobile technology for rural climate resilience: The role of mobile operators in bridging the data gap, tech. Rep., London, UK, available at: https://www.gsma.com/mobilefordevelopment/wp-content/uploads/2019/10/GSMA_AgriTech_Climate_Report.pdf (last access: 13 August 2020), 2019. a
Habi, H. V. and Messer, H.: Recurrent neural network for rain estimation using commercial microwave links, IEEE T. Geosci. Remote, 59, 3672–3681, https://doi.org/10.1109/TGRS.2020.3010305, 2021. a
International Telecommunication Union: Specific attenuation model for rain for use in prediction methods, Tech. rep., International Telecommunication Union, available at: https://www.itu.int/dms_pubrec/itu-r/rec/p/R-REC-P.838-3-200503-I!!PDF-E.pdf (last access: 8 August 2021), 2005. a
Kling, H., Fuchs, M., and Paulin, M.: Runoff conditions in the upper Danube basin under an ensemble of climate change scenarios, J. Hydrol., 424–425, 264–277, https://doi.org/10.1016/j.jhydrol.2012.01.011, 2012. a, b
Leijnse, H.: Hydrometeorological application of microwave links: measurement of evaporation and precipitation, PhD thesis, Wageningen University, ISBN 978-90-8504-775-9, 2007. a
Leijnse, H., Uijlenhoet, R., and Stricker, J. N. M.: Rainfall measurement using radio links from cellular communication networks, Water Resour. Res., 43, W03201, https://doi.org/10.1029/2006WR005631, 2007. a, b
Leijnse, H., Uijlenhoet, R., and Stricker, J.: Microwave link rainfall estimation: effects of link length and frequency, temporal sampling, power resolution, and wet antenna attenuation, Adv. Water Resour., 31, 1481–1493, https://doi.org/10.1016/j.advwatres.2008.03.004, 2008. a, b, c, d
Liberman, Y., Samuels, R., Alpert, P., and Messer, H.: New algorithm for integration between wireless microwave sensor network and radar for improved rainfall measurement and mapping, Atmos. Meas. Tech., 7, 3549–3563, https://doi.org/10.5194/amt-7-3549-2014, 2014. a
Matthews, B.: Comparison of the predicted and observed secondary structure of T4 phage lysozyme, BBA-Protein Struct., 405, 442–451, https://doi.org/10.1016/0005-2795(75)90109-9, 1975. a
Messer, H.: Environmental monitoring by wireless communication networks, Science, 312, 713–713, https://doi.org/10.1126/science.1120034, 2006. a
Messer, H. and Sendik, O.: A new approach to precipitation monitoring: a critical survey of existing technologies and challenges, IEEE Signal Proc. Mag., 32, 110–122, https://doi.org/10.1109/MSP.2014.2309705, 2015. a, b
Olsen, R., Rogers, D., and Hodge, D.: The aRb relation in the calculation of rain attenuation, IEEE T. Antenn. Propag., 26, 318–329, https://doi.org/10.1109/TAP.1978.1141845, 1978. a
Ostrometzky, J. and Messer, H.: Statistical signal processing approach for rain estimation based on measurements from network management systems, in: ICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 4 May 2020, Barcelona, Spain, IEEE, 9026–9030, https://doi.org/10.1109/ICASSP40776.2020.9054652, 2020. a
Overeem, A.: Precipitation – 5 minute precipitation accumulations from climatological gauge-adjusted radar dataset for The Netherlands (1 km) in KNMI HDF5 format, KNMI Data Services [data set], available at: https://dataplatform.knmi.nl/dataset/rad-nl25-rac-mfbs-5min-2-0 (last access: 7 May 2020), 2017. a
Overeem, A.: Commercial microwave link data for rainfall monitoring, 4TU.ResearchData [data set], https://doi.org/10.4121/uuid:323587ea-82b7-4cff-b123-c660424345e5, 2019. a
Overeem, A., Buishand, T. A., and Holleman, I.: Extreme rainfall analysis and estimation of depth-duration-frequency curves using weather radar, Water Resour. Res., 45, 1–15, https://doi.org/10.1029/2009WR007869, 2009a. a
Overeem, A., Holleman, I., and Buishand, A.: Derivation of a 10-year radar-based climatology of rainfall, J. Appl. Meteorol. Clim., 48, 1448–1463, https://doi.org/10.1175/2009JAMC1954.1, 2009b. a
Overeem, A., Leijnse, H., and Uijlenhoet, R.: Measuring urban rainfall using microwave links from commercial cellular communication networks, Water Resour. Res., 47, W12505, https://doi.org/10.1029/2010WR010350, 2011. a, b, c, d, e, f
Overeem, A., Leijnse, H., and Uijlenhoet, R.: Country-wide rainfall maps from cellular communication networks, P. Natl. Acad. Sci. USA, 110, 2741–2745, https://doi.org/10.1073/pnas.1217961110, 2013. a, b, c, d, e, f, g
Overeem, A., Leijnse, H., and Uijlenhoet, R.: Retrieval algorithm for rainfall mapping from microwave links in a cellular communication network, Atmos. Meas. Tech., 9, 2425–2444, https://doi.org/10.5194/amt-9-2425-2016, 2016a. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p
Overeem, A., Leijnse, H., and Uijlenhoet, R.: Two and a half years of country-wide rainfall maps using radio links from commercial cellular telecommunication networks, Water Resour. Res., 52, 8039–8065, https://doi.org/10.1002/2016WR019412, 2016b. a, b, c, d, e, f, g
Overeem, A., Leijnse, H., and de Vos Lotte: RAINLINK: Retrieval algorithm for rainfall mapping from microwave links in a cellular communication network, R package version 1.21, GitHub [code], available at: https://github.com/overeem11/RAINLINK, last access: 14 July 2021a. a
Overeem, A., Leijnse, H., van Leth, T. C., Bogerd, L., Priebe, J., Tricarico, D., Droste, A., and Uijlenhoet, R.: Tropical rainfall monitoring with commercial microwave links in Sri Lanka, Environ. Res. Lett., 16, 074058, https://doi.org/10.1088/1748-9326/ac0fa6, 2021b. a
Overeem, A., Leijnse, H., and de Vos, L.: RAINLINK: Retrieval algorithm for rainfall mapping from microwave links in a cellular communication network, R package version 1.21, Zenodo [code], https://doi.org/10.5281/zenodo.5907524, 2022. a, b
Peel, M. C., Finlayson, B. L., and McMahon, T. A.: Updated world map of the Köppen-Geiger climate classification, Hydrol. Earth Syst. Sci., 11, 1633–1644, https://doi.org/10.5194/hess-11-1633-2007, 2007. a
Pijl, A., Brauer, C. C., Sofia, G., Teuling, A. J., and Tarolli, P.: Hydrologic impacts of changing land use and climate in the Veneto lowlands of Italy, Anthropocene, 22, 20–30, https://doi.org/10.1016/j.ancene.2018.04.001, 2018. a
Polz, J., Chwala, C., Graf, M., and Kunstmann, H.: Rain event detection in commercial microwave link attenuation data using convolutional neural networks, Atmos. Meas. Tech., 13, 3835–3853, https://doi.org/10.5194/amt-13-3835-2020, 2020. a, b
Pudashine, J., Guyot, A., Petitjean, F., Pauwels, V. R. N., Uijlenhoet, R., Seed, A., Prakash, M., and Walker, J. P.: Deep learning for an improved prediction of rainfall retrievals from commercial microwave links, Water Resour. Res., 56, 1–10, https://doi.org/10.1029/2019WR026255, 2020. a
Pudashine, J., Guyot, A., Overeem, A., Pauwels, V. R., Seed, A., Uijlenhoet, R., Prakash, M., and Walker, J. P.: Rainfall retrieval using commercial microwave links: Effect of sampling strategy on retrieval accuracy, J. Hydrol., 603, 126909, https://doi.org/10.1016/j.jhydrol.2021.126909, 2021. a
R Core Team: R: A Language and Environment for Statistical Computing, Version 3.4.4, available at: http://www.R-project.org/ (last access: 7 July 2019), 2018. a
Rios Gaona, M. F., Overeem, A., Raupach, T. H., Leijnse, H., and Uijlenhoet, R.: Rainfall retrieval with commercial microwave links in São Paulo, Brazil, Atmos. Meas. Tech., 11, 4465–4476, https://doi.org/10.5194/amt-11-4465-2018, 2018. a
Roversi, G., Alberoni, P. P., Fornasiero, A., and Porcù, F.: Commercial microwave links as a tool for operational rainfall monitoring in Northern Italy, Atmos. Meas. Tech., 13, 5779–5797, https://doi.org/10.5194/amt-13-5779-2020, 2020. a
Schneider, U., Finger, P., Meyer-Christoffer, A., Ziese, M., and Becker, A.: Global Precipitation Analysis Products of the GPCC, Tech. Rep. 9, National Meteorological Service of Germany, Offenbach am Main, available at: https://opendata.dwd.de/climate_environment/GPCC/PDF/GPCC_intro_products_v2020.pdf, last access: 7 September 2021. a, b
Smiatek, G., Keis, F., Chwala, C., Fersch, B., and Kunstmann, H.: Potential of commercial microwave link network derived rainfall for river runoff simulations, Environ. Res. Lett., 12, 034026, https://doi.org/10.1088/1748-9326/aa5f46, 2017. a
Sohail Afzal, M., Shah, S. H. H., Cheema, M. J. M., and Ahmad, R.: Real time rainfall estimation using microwave signals of cellular communication networks: a case study of Faisalabad, Pakistan, Hydrol. Earth Syst. Sci. Discuss. [preprint], https://doi.org/10.5194/hess-2017-740, 2018. a
Sun, Q., Miao, C., Duan, Q., Ashouri, H., Sorooshian, S., and Hsu, K.-L.: A review of global precipitation data sets: data sources, estimation, and intercomparisons, Rev. Geophys., 56, 79–107, https://doi.org/10.1002/2017RG000574, 2018. a
Uijlenhoet, R., Overeem, A., and Leijnse, H.: Opportunistic remote sensing of rainfall using microwave links from cellular communication networks, WIREs Water, 5, 1–15, https://doi.org/10.1002/wat2.1289, 2018. a, b
Upton, G., Holt, A., Cummings, R., Rahimi, A., and Goddard, J.: Microwave links: The future for urban rainfall measurement?, Atmos. Res., 77, 300–312, https://doi.org/10.1016/j.atmosres.2004.10.009, 2005. a
Van Griensven, A., Meixner, T., Grunwald, S., Bishop, T., Diluzio, M., and Srinivasan, R.: A global sensitivity analysis tool for the parameters of multi-variable catchment models, J. Hydrol., 324, 10–23, https://doi.org/10.1016/j.jhydrol.2005.09.008, 2006. a, b, c, d
Zambrano-Bigiarini, M. and Rojas, R.: A model-independent Particle Swarm Optimisation software for model calibration, Environ. Model. Softw., 43, 5–25, https://doi.org/10.1016/j.envsoft.2013.01.004, 2013. a
Zinevich, A., Messer, H., and Alpert, P.: Frontal rainfall observation by a commercial microwave communication network, Jo. Appl. Meteorol. Clim., 48, 1317–1334, https://doi.org/10.1175/2008JAMC2014.1, 2009. a