the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 11 Jun 2026
| 11 Jun 2026
Accounting for spatiotemporally correlated errors in wind speed for remote surveys of methane emissions
Bradley M. Conrad
Matthew R. Johnson
Spatiotemporally correlated errors in wind speeds estimated via numerical weather prediction (NWP) models – where estimated wind speeds and associated uncertainties at similar times or at nearby sites are likely to be correlated – are an important, but to date neglected, determinant of overall uncertainties in remote surveys of emissions in the oil and gas and other sectors. In this work, we develop a methodology to model such errors using publicly available, anemometer-measured wind speeds at weather stations within a region of interest. The method is parsed into two: (1) creation of a region-averaged wind speed error model to provide the probability of the true wind speed given an NWP model-estimated wind speed while ignoring autocorrelation, and (2) development of a Gaussian copula model for the region of interest (ROI) to capture spatiotemporal autocorrelation. The combined model for total wind uncertainty, including spatiotemporally autocorrelated errors, is demonstrated using the oil and gas-producing region of northeastern British Columbia, Canada as a case study. We also provide additional combined models for the Canadian provinces of Alberta and Saskatchewan, the U.S. state of North Dakota, and Colombia. Finally, we share a simple python code to interface with these models and to simplify application by others. The combined models show varying correlations in wind speed errors, which are attributable to the variability of terrain in the ROIs and the relative accuracy of different NWP models. We observe in our case study region that correlation in wind speed errors can starkly increase overall uncertainties in emissions inventories, especially for large surveys. Results further reveal how temporal correlations and hence uncertainties in aggregated emissions can be minimized through remote survey design, where waiting at least two days before revisiting a site and phase shifting re-surveys by approximately six hours can avoid both near-field and diurnal patterns in temporal autocorrelation.
- Article
(4736 KB) - Full-text XML
- BibTeX
- EndNote




Accurate quantification of methane emissions is critical for directing mitigation, tracking reductions, and informing climate policy. Remote sensing technologies, especially aerial and satellite-based platforms, have emerged as powerful tools for detecting and estimating methane sources. These technologies support development of regional, sector-specific source distributions (Cusworth et al., 2022; Kunkel et al., 2023; Scarpelli et al., 2024; Sherwin et al., 2024; Yu et al., 2022), as well as both measurement-informed (Fosdick et al., 2025; Santos et al., 2025) and measurement-based inventories (Conrad et al., 2023a, 2023c; Johnson et al., 2023). However, the accuracy of remotely sensed methane emission estimates is highly sensitive to atmospheric transport processes, particularly wind speed and direction, which govern the dispersion of methane plumes.
A common challenge for these approaches is the need to estimate a representative wind speed to convert observed methane enhancements into emission rates or fluxes. In the absence of in situ wind speed measurements, wind speeds are commonly estimated from public or commercial numerical weather prediction (NWP) models, such as the High-Resolution Rapid Refresh model (HRRR) and the 12 km analysis from the North American Mesoscale Forecast System (NAM12). These estimates may be spatially interpolated, temporally averaged, and vertically adjusted using assumed wind profiles to match the source height for emission calculations (Johnson et al., 2021; Thorpe et al., 2024). For example, satellite measurements using the Integrated Mass Enhancement or Cross-Sectional Flux methods rely on an “effective wind speed”, which is typically the temporally averaged 10 m wind speed from an NWP model that is further scaled through a calibration function (e.g., Varon et al., 2018). Aerial measurements may follow similar approaches (Duren et al., 2019; Thorpe et al., 2023) or in the case of LiDAR sensors may use measured plume heights and an assumed boundary layer profile to adjust 10 m wind speed estimates from NWP models to obtain wind speed estimates at a characteristic plume height (e.g., Thorpe and Kreitinger, 2024). Regardless of the measurement platform, the performance of NWP models in capturing local wind conditions is a key source of uncertainty in remotely derived methane emission estimates that to date has been difficult to quantify.
In the context of aerial or satellite surveys over multiple sources or sites, there is an added challenge whereby wind speeds (and hence their uncertainties) at nearby locations are likely to be correlated. Neglecting this autocorrelation when aggregating sources to produce an inventory will, through central limit theorem, artificially reduce the contribution of wind speed precision error and hence the overall inventory. More generally, uncertainties in wind speed are expected to be correlated in both space and time, where errors at adjacent locations and similar times would be related, but errors at two far away locations or similar locations at two very different times are more likely to be independent. Region-specific wind speed error models that consider error autocorrelation are thus essential for accurate methane inventories with robustly characterized uncertainties. Unfortunately, such models are conspicuously absent in the literature.
In this manuscript, we detail a methodology to probabilistically model the true wind speed in an arbitrary region and during an arbitrary time period from gridded, discrete-time NWP model estimates and statistically independent weather station data. The developed model explicitly considers spatiotemporal autocorrelation of wind speeds and associated correlation of uncertainties in an easy-to-implement framework. Using the oil and gas-producing region of northeastern British Columbia, Canada as a case study, we then use the presented methodology to develop a comprehensive wind speed error model and subsequently show how this model influences a provincial methane emissions inventory derived from aerial survey data relative to a simpler model (Conrad et al., 2023b) used in our previous work (Conrad et al., 2023a, 2023c; Johnson et al., 2023). Next, we analyze different time periods of case study data to investigate annual variability of wind speed errors and demonstrate the consistency of the modelling method. By creating additional models for the U.S. State of North Dakota, we then illustrate how our modelling approach can be used to compare regional performance of different NWP models, providing a means to choose the best wind speed data for a given region of interest to minimize uncertainties in methane inventories derived from large-scale remote surveys. Finally, referring to Appendix A, we derive six additional models for the remaining oil and gas-producing provinces of Canada (Alberta and Saskatchewan), the U.S. state of North Dakota, and Colombia, and share a simple python code (see Code and data availability) to describe, visualize, and interact with the created models for the purposes of Monte Carlo simulations of wind speed error.
2.1 Case study
2.1.1 Region of interest
We present our wind speed error modelling approach using a case study of the oil and gas-producing region of the Canadian province of British Columbia (BC). BC has been a leader in leveraging sustained provincial-scale measurement campaigns (British Columbia Energy Regulator, 2022) to track emissions, guide regulation, and achieve low methane intensities (e.g., Conrad et al., 2023c; Johnson et al., 2023). Moreover, oil and gas production in BC's Montney and Horn River basins is located immediately downwind of the Rocky Mountains for the prevailing westerlies (Fig. 1), with complex topography and terrain that provides an especially challenging wind modelling example.
The pink polygon in Fig. 1 identifies the approximately 122 000 km2 region of interest (ROI) defined for this case study that bounds upstream oil and gas production in the Northeast of the province. The bounds of the ROI were defined as a convex hull around active and shut-in upstream facilities and wells during early 2023 (dilated with a 25 km radius circular kernel in the NAD83 UTM 10N coordinate system) intersected with provincial boundaries (northern and eastern sides). The ROI contains approximately 1083 oil and gas facilities and 10 441 wells.
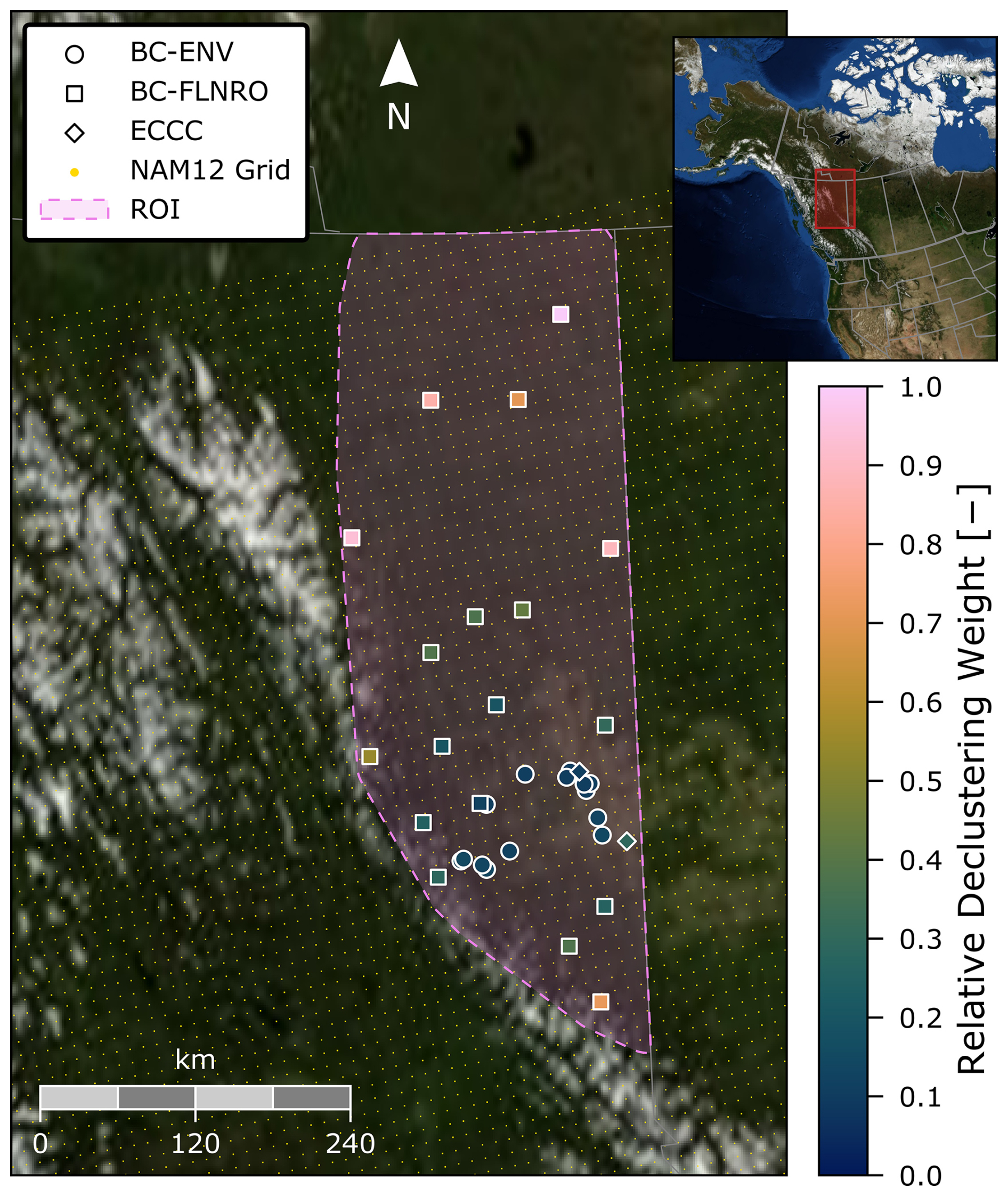
Figure 1Case study region of interest (ROI, pink polygon) spanning upstream oil and gas production sites in northeastern BC. Coloured points locate the 35 weather stations that provided independent ground-truth wind speeds for model development, which are coloured according to their relative declustering weights (see Table 1 and Sect. 2.2.2 and 2.2.3). The grid at which NAM12 data products are reported underlays the figure in yellow. Underlying surface imagery courtesy of NASA Earth Observatory.
2.1.2 “Ground-truth” measurement data
Anemometer-measured, “ground-truth” wind speeds were acquired from 35 active weather stations within the case study ROI that each report a scalar wind speed and direction on an hourly basis (Fig. 1). As summarized in Table 1, these included Environment and Climate Change Canada's (ECCC) surface weather stations (ECCC, 2025), British Columbia's Ministry of Environment and Parks' Air Quality Network stations (BC ENV, 2025; BC Ministry of Environment and Parks, 2015), and British Columbia's Ministry of Forests, Lands, and Natural Resource Operations' Wildfire Management Branch's weather stations (BCWS, 2025). Two additional ECCC weather stations within the ROI were excluded as they are within 10 km of a station (Fort Nelson Airport; World Meteorological Organization ID 71945) that inputs data to the NAM12 NWP model used for the case study demonstration of our methodology (see Sect. 2.1.3). Station-measured wind data were obtained for May to October (i.e., non-snowy months when aerial surveys can reliably be performed in the ROI) during the calendar years of 2021–2024. Critically, these data are not inputs to the evaluated NWP model and thus constitute an independent “ground-truth” data set in the subsequent analysis.
Table 1Ground-truth data sources providing scalar wind speeds for the present case study.
a Excludes two weather stations within 10 km of known NAM data source.
b The anemometer is usually located at 10 m above ground. Measurements represent the 1, 2, or 10 min period preceding the top of the hour (Environment and Climate Change Canada, n.d.).
c Includes verified (quality controlled; to 2022, inclusive) and unverified (not quality controlled, 2023 onward) data.
d Anemometer height varies by site, wind speeds were scaled to 10 m using the logarithmic profile in Johnson et al. (2021).
Data available from the individual networks include hourly reported wind speed magnitudes and directions; however, given the potential for poor resolution and high uncertainties in anemometer-measured wind direction, we ignore direction data and analyze wind speed magnitudes directly. Recommended installation height for anemometers is usually at 10 m above ground level (e.g., Burt, 2012; Manfredi et al., 2008; Oke, 2004), and wind speeds are “most often [averaged over a period of] 10 min” (Burt, 2012). However, installation heights and averaging periods for these weather station networks are either not explicitly stated, ambiguous, or non-standard. For example, documentation for the ECCC weather stations (Environment and Climate Change Canada, n.d.) notes that installed anemometers are usually located at 10 m above ground level and report one, two, or ten minute-averaged wind speeds during the period ending at the top of the hour. While the BC-FLNRO network explicitly states a targeted height range for each installed anemometer, there is no available information regarding averaging periods for the BC-ENV and BC-FLNRO networks nor anemometer height for the BC-ENV network. Thus, anemometers for the BC-ENV network are assumed to be at 10 m above ground level and wind speeds reported by the BC-FLNRO network are scaled to 10 m above ground level from the stated anemometer height using the logarithmic wind profile in Johnson et al. (2021). Finally, throughout this analysis the averaging period is assumed to be 10 min for all weather stations, while noting that this will likely provide a model with larger dispersion relative to measurements over longer averaging periods – refer to the Limitations section (Sect. 4) for further discussion.
2.1.3 NWP model data (NAM12)
For the case study, we assess the North American Mesoscale Forecast System (NAM; National Centers for Environmental Prediction (NCEP) et al., 2025) NWP model, which uses the U.S. National Oceanic and Atmospheric Administration's (NOAA) Non-Hydrostatic Multi-scale Model (NMM). This NWP model is appealing for methane inventory development in Canada as it provides spatiotemporally resolved two-component wind speeds at 10 m above ground level, is freely available from multiple sources online, and provides near-complete coverage of Canada's provinces. Wind speed estimates are available for a forecasted period of 84 h following each data assimilation cycle that occurs every 6 h. These data are provided on NCEP's #218 grid, which has a 12 km resolution at 35° N and is underlaid in yellow in Fig. 1. Wind speed data on this 12 km resolution grid (hereafter called “NAM12” data) were sourced (see “Code and data availability” section) from the U.S. National Centers for Environmental Information's https server (up to 15 September 2021) and NOAA's Open Data Dissemination program on Amazon Web Services (from 16 September 2021, onwards). Two-component wind speeds were acquired for each hour during the calendar years of 2021–2024 using the latest data assimilation cycle at each time point to minimize forecast lag; data at 00:00, 06:00, 12:00, and 18:00 UTC therefore represent analyses rather than forecasts. Component wind speeds were summed in quadrature to provide wind speed magnitudes on the 12 km grid for further processing and comparison with ground-truth, weather station-measured, 10 m wind speeds.
2.1.4 Data pre-processing
Prior to model fitting, alignment of the measured and NAM12 wind speed datasets was required. Fortunately, all datasets for the case study ROI reported at identical timepoints, the top of each hour. Wind speeds at the specific coordinates of the weather stations were assigned using a simple nearest-neighbour interpolation of the NAM12 grid points within the NAD83 UTM 10N projected coordinate system. Missing data in the measurement datasets were stricken. Similarly, recognizing that wind speeds over a finite averaging period cannot be exactly zero but may be below the detection limit of an anemometer, we also struck zero-valued wind speeds in the measurement dataset. Following pre-processing, we have five m×1 vectors containing case study data from all of the 35 weather stations (m = 470 014); these are the ground-truth (u [m s−1]) and NWP model-estimated ( [m s−1]) 10 m wind speeds across all weather stations, the corresponding eastings (sx) and northings (sy) of each measurement in projected coordinates [km], and the corresponding time of each measurement in Coordinated Universal Time (t [d]).
2.2 Modelling approach
To characterize the true wind speed at the arbitrary locations and measurement times of sources in a remote measurement survey, we require a probabilistic error model. This model is the probability of the true wind speed (u) given the NWP model-estimated wind speed () at each location (defined by sx and sy) and time (t) of interest for the survey. Critically, this model must consider the spatiotemporal dependence (i.e., autocorrelation) of the true wind speed.
Consider n remote measurement locations/timepoints for which we wish to model the true 10 m wind speed; here, u, , sx, sy, and t are n×1 real-valued vectors. The spatial vectors may contain duplicate values representing multiple temporal measurements at one location in space, while the temporal vectors may contain duplicate values representing simultaneous measurements at different locations. With these definitions, our objective is to derive a probability distribution for the true wind speed with probability density function (PDF)
and cumulative distribution function (CDF)
Given known values for sx, sy, and t, and estimated wind speeds from an NWP model, this distribution permits random sampling of the true wind speed vector u, enabling emissions quantification across an entire survey while specifically considering autocorrelation of NWP model error in space and time.
Beyond the potentially high dimensionality of the problem, deriving a model following Eq. (1) is challenging for two reasons. Firstly, the univariate conditional probability density at the ith location and timepoint is a non-negative distribution of sufficient complexity that the multivariate density in Eq. (1) is unlikely to be well-represented by standard analytical multivariate distributions. Secondly, correlation between the ui is likely to be strongly dependent on the spatial and temporal lags between the locations and timepoints of interest.
2.2.1 Copula approach
One logical and easily implemented approach to circumvent these challenges leverages a statistical tool known as a copula. Copulas were first presented by Sklar (1959) and are discussed in abundant detail in the literature (see, for example, Nelsen, 2006). In this section, we simply present the formal definition and relate it to the present challenge. Sklar's theorem states that the joint CDF of n arbitrary random variates can be represented exactly as a function of each xi's univariate marginal CDF (Fi(xi)) through an n-dimensional function called a “copula” (C) (e.g., Nelsen, 2006), that is
or in terms of PDFs (e.g., Arrieta-Prieto and Schell, 2022)
where c(…) is the copula density. This formulation is useful as it separates independent information about each xi (defined by their marginal distributions) and the dependence structure of the xi (defined by the copula). Stated differently, the copula maps the marginal CDFs to the joint CDF (Nelsen, 2003, 2006; Sadegh et al., 2017).
In the present context, introducing our variables of interest, the desired CDF (Eq. 2) has the form
Here, we have noted that the marginal distributions for the true wind speeds are conditional on the NWP model-estimated wind speeds and locations and timepoints of the remote survey and that the copula (i.e., the dependence structure or autocorrelation) is similarly functional on the locations and timepoints. The key advantage of this approach is that the copula-based model of the desired joint probability can be parsed into two tractable problems. This two-step modelling process requires: (i) a wind speed error model for the marginal distributions at each location and timepoint, and (ii) the copula that joins them to give the joint CDF. However, we can further simplify the modelling process by deriving a univariate region-averaged wind speed error model with CDF that is representative of the average error in NWP-estimated wind speeds over the ROI (i.e., dropping the location and timepoint dependence of the marginal distributions). Since this error model would be assumed applicable within the ROI regardless of location/timepoint, the marginal distributions (Fi) in Eq. (5) are all equivalent . This gives the format of the joint CDF that we ultimately seek to model
Numerous types of copulas exist for modelling complex dependence structures (see, for example, Nelsen, 2006). In this work, we employ the Gaussian copula, which has the form
where Φ−1(x) is the inverse CDF (quantile function) of the standard univariate normal distribution and is the joint CDF for the multivariate normal of arbitrary dimension n with n×1 mean vector (μ, defined here to be the zero vector, 0) and n×n covariance matrix (Σ), which is parameterized by locations and timepoints (sx, sy, and t, all n×1). We choose the Gaussian copula for this work because it reduces the modelling to that of a covariance function or covariogram for a Gaussian field, , and algorithms to generate random numbers from a multivariate normal distribution are readily available in mathematical software applications.
2.2.2 Region-averaged wind speed error Model
In a previous work, we described a simple method to probabilistically model true wind speeds from NWP model-estimated wind speeds (i.e., a wind speed error model, based on controlled release experiments assessing a provider of remote methane detection (Conrad et al., 2023b). This model fit the ratio , which we denoted as the relative error ratio (RER), to candidate probability distributions such that the wind speed error model had the form
where πcand(x;θ) is a candidate probability distribution with non-negative support. This previous model, which assumes the RER follows the same distribution regardless of the NWP model-estimated wind speed, fit the limited experimental data well but is overly simplistic here where we have years of hourly wind speed data across 35 unique sites and need not constrain the RER in this way.
In the present study, we use a more-general model for region-averaged wind speed error that uses the true wind speed (u) as the random variate (i.e., not the RER) and allows the distribution parameters to be functional on the NWP model-estimated wind speed (i.e., such that
We considered nine candidate distributions with non-negative support – Burr Type XII, Gamma, Inverse Gaussian, Log-Logistic/Fisk, Lognormal, Nakagami, Rayleigh, Rician, and Weibull – all of which have two parameters except the Rayleigh distribution, which has just one. Moreover, we permitted each parameter to be a constant (a), linear function , or offset power-law giving a total of 75 candidate models for . For each candidate model, we calculated a weighted maximum likelihood estimate using MATLAB's fmincon (constrained minimization) function and chose the model that minimized the Akaike Information Criterion (Akaike, 1974; essentially a parameter count-adjusted negative log-likelihood) as optimal. Data were weighted to account for biased spatial clustering of weather stations using a custom implementation of Deutsch and Journel's (1997) “DECLUS” cell declustering algorithm, which weights station data by the inverse of station count on a regular but randomly perturbed two-dimensional grid. Following recommended practices (e.g., Deutsch, 1989), this algorithm was implemented with a cell size of 147 km, which minimized the declustered mean of ground-truth wind speeds. Declustering weights, normalized to the unit interval, for the 35 weather stations of the BC case study are shown by colour in Fig. 1.
2.2.3 Spatiotemporal autocorrelation model
To model the covariogram within the ROI for use in the Gaussian copula, we employ geostatistical variography techniques on the m case study data. There is myriad literature regarding the evaluation, characterization, and simulation of autocorrelated geostatistical data including the seminal work of Cressie (1993). Here, we outline our approach to modelling following published techniques within this field. We begin by transforming our case study data to follow a normal distribution via a normal score transform, which gives an m×1 vector z corresponding to the random variate in the multivariate CDF in Eq. (7) (here, of length m). We employ a transformation that leverages our optimized region-averaged wind speed error model – each element of z is
and can be interpreted as a function of location and timepoint via . The vector z represents a random sample from a multivariate normal distribution with zero-mean and some covariance structure, the latter of which we can now simulate using the corresponding location and timepoint vectors. However, to avoid bias in the empirical estimation of covariance (e.g., Isaaks and Srivastava, 1988), we characterize the covariance of z by instead modelling its semivariogram.
Like covariance, the semivariogram (γ) is a means to characterize how similar and different zi are in the near- and far-fields, respectively – i.e., the spatiotemporal autocorrelation of z. In the most general sense, the semivariogram is functional on two specific positions in space and time and is one-half of the variance of the difference of the zi at these positions. Letting the vector , the semivariogram is
This formulation can be simplified greatly. Referring to Cressie (1993) for further detail, if the random field Z is intrinsically stationary, such that it has a constant mean over all values of r and the variance var(Z(r1)−Z(r2)) depends only the spacing (lag) between the positions , then the semivariogram can be restated as
where E[⋅] is the expectation operator. Furthermore, if the random field Z is second-order stationary such that the autocovariance cov(Z(r1),Z(r2)) depends only on the spacing between the positions, then the covariance of two positions separated by h is easily derived from the semivariogram via
where cov(0) is the variance over the entire field, which is equivalent to the sill of the semivariogram (see below). Thus, with a semivariogram model, the elements of a covariance matrix can be easily calculated as a function of spatiotemporal lag.
Following Eq. (12), the semivariogram can be empirically estimated from the case study data by
where positive real-valued scalars hx, hy, ht are the lags in two-dimensional cartesian space and time and is the number of pairs of data in z that are separated by these lags. The (empirical) semivariogram can be simplified by assuming that the semivariogram is isotropic in space. Letting be the spatial lag vector and be its positive, real-valued magnitude, the empirical semivariogram simplifies to
where , and are the cartesian unit vectors, and we introduce the subscript “st” to identify that the semivariogram describes space and time. Practically, for a finite dataset, there are limited realizations of the continuous positive variables hs and ht. Consequently, empirical estimation of semivariograms requires discretization of the data by lags with a defined tolerance – see, for example, Deutsch and Journel (1997) for further discussion.
In theory, one could interpolate the empirical semivariogram to estimate our desired covariance matrix, for arbitrary locations in space and timepoints. However, careful modelling of the semivariogram is required to ensure that it is valid for the simulation of covariance. We must develop a semivariogram model using appropriate functions (or a superposition of appropriate functions) that are conditionally negative semidefinite, which in turn ensures a positive definite covariance matrix (e.g., Curriero, 2006; Pyrcz and Deutsch, 2006). For spatiotemporal applications with an isotropic correlation in space, one useful approach to make modelling of the semivariogram more tractable is to separate it into space and time components. We adopt the product-sum model of De Iaco et al. (2001) in this work
where is the optimal model of the semivariogram, is a marginal spatial semivariogram model at zero temporal lag, and is a marginal temporal semivariogram model at zero spatial lag, which are linked by an optimized parameter k∗.
We first model the spatial semivariogram. For each available timepoint of the case study data, we calculate an empirical semivariogram for lags at every 25 km, with a bin tolerance of ± 25 km (e.g., the first bin is 0–50 km, the second is 25–75 km, and so forth). Rather than taking the arithmetic mean of the data within each bin (as indicated by Eq. 15), here we calculate a weighted mean for each bin using weights via Richmond's (2002) two-point declustering method. Like the cell declustering described in Sect. 2.2.2, this method weights the kth data pair based on the inverse of the number of pairs that originate and terminate in the same cell as the kth pair; our implementation of this method uses the same cell size for the earlier cell declustering, 147 km. As in the region-averaged wind speed error model, this space-informed weighting was executed to provide what we believe is a better average empirical semivariogram across the ROI. We then fit candidate semivariogram models to this empirical semivariogram using a weighted least squares algorithm where the weights are proportional to the number of valid data informing each lag bin of the empirical semivariogram.
We consider 21 unique monotonic semivariogram models as candidate fits. Firstly, as a baseline, the constant model which assumes zero spatial correlation. We also consider semivariograms of the form
where is one of four monotonic semivariogram models standardized between zero and one and parameterized by a fitted parameter b>0 (the range of the model):
-
Exponential:
-
Gaussian:
-
Spherical:
-
Pentaspherical:
with R being the Heaviside step function and ak fixed constants such that the value of each is exactly 0.95 by convention. Fitted parameters bi are constrained such that the overall semivariogram is monotonically increasing and the ranges of the are positive and rank-ordered . We consider each of the four models independently (not requiring b3) and all 16 ordered pairs. Finally, we discard any model that is not statistically better than the constant model (via an F-test) and choose the remaining model that maximizes the parameter-adjusted coefficient of determination for the weighted least squares approach.
Next, we model the temporal semivariogram. For each weather station, we calculate the empirical semivariogram for integer-valued hours up to two weeks (336 h). Due to the large amount of temporal data in the case study, we derive these empirical semivariograms iteratively by pulling a subset of random pairs of data and terminating when more than 104 data pairs with temporal lags less than or equal to two weeks have been obtained. We then estimate an ROI-averaged empirical semivariogram by taking the weighted average across the weather stations for each bin, weighted by the product of the cell declustering weights shown in Fig. 1 and the amount of data at each lag. We continue by fitting candidate semivariogram models using weighted least squares with weights corresponding to the those used in the empirical semivariogram calculation, summed over all weather stations.
In contrast to the spatial semivariogram, the temporal empirical semivariogram has a clear periodic nature that aligns with the 24 h diurnal cycle (see further discussion and results in Sect. 3.2). Specifically, we observe that wind speed errors are maximally correlated at lags that are multiples of 12 hours, with peak positive correlations at lags that are multiples of 24 hours. Given the observed diurnal variation, we adopt candidate models that capture this “hole effect” of the empirical temporal semivariogram. These models include monotonic semivariograms ( as in the spatial semivariogram modelling above superimposed with a periodic semivariogram. The candidate periodic semivariograms are linear combinations of zeroth-order Bessel functions of the first kind (J0(x)) as in Ecker and Gelfand (1997) and Ye et al. (2015) and a cosine function. For temporal lag ht in days, the fitted models have the form
Here, we scale the Bessel functions' arguments by 2π and introduce phase shifts ϕj to force the (j+1)th peak to occur at a lag of exactly one day; similarly, the cosine's argument has a scaling factor of 2π to capture the diurnal cycle. Fitted parameters bi are constrained such that each component semivariogram causes a net nonnegative effect ; the ranges of the are positive and rank-ordered ; the coefficients of the Bessel basis functions are decreasing ; the coefficient on the cosine is nonnegative (d>0); and, like , the periodic component is standardized to start from zero and oscillate around one at large lags. The former requires that
Two-hundred and eleven candidate semivariogram models are considered with up to ten (J=10) Bessel basis functions: a constant model ; a constant plus oscillating model (10 total, with ; one monotonic semivariogram plus oscillating models (40 total, with b3=0); and two monotonic semivariograms plus oscillating models (160 total, with all bi>0). We select the optimal model in the same manner as for the spatial semivariogram.
The final step in characterizing the spatiotemporal semivariogram is to optimize for the constant k∗ in Eq. (16). We follow the procedure of De Iaco et al. (2001). First, we calculate a two-dimensional empirical spatiotemporal semivariogram (Eq. 15) using the same lag bins as the independent spatial and temporal semivariograms. Like the spatial and temporal semivariograms, we use a weighted mean in place of the arithmetic mean for Eq. (15) to obtain an ROI-average semivariogram. As in the temporal semivariogram, the weights here are the product of the declustering weights and count of data in each lag bin; however, we use the two-dimensional declustering algorithm here for the declustering weights consistent with the spatial semivariogram. We then take the sum of the weights within each lag bin and perform a relative weighted least squares fit to Eq. (16) to optimize for k∗.
With a full spatiotemporal semivariogram model, we can now define the desired covariance matrix for arbitrary locations and timepoints. First though, we must calculate the sill of the fitted spatiotemporal semivariogram model, which is the value that a semivariogram approaches or oscillates around as the lag(s) go to infinity. For the spatial semivariogram in Eq. (17), the sill is b2 or b3 depending on the form of the optimized model, while for the temporal semivariogram in Eq. (18), the sill is b4. Denoting the sills of the optimized spatial and temporal semivariograms as and , respectively, De Iaco et al. (2001) show that the sill of the spatiotemporal semivariogram is
and, under the aforementioned conditions of second-order stationarity, the covariance can be easily computed from the semivariogram as
Re-introducing the vectors sx, sy, and t, the covariance matrix required for the Gaussian copula is therefore
where , , and the diagonal of the covariance matrix is fixed at unity to ensure that the marginal distributions of each ui follow the region-averaged wind speed error model.
2.3 Model implementation
Recalling Sect. 2.2, consider again a remote measurement survey with n observations for which we desire the true 10 m wind speed (n×1 vector u). Further assume that emissions have been reported using NAM12 wind speeds (n×1 vector ) and let emission rates scale with some effective wind speed that is a function, f, of the 10 m wind speed. We seek true emission rates (n×1 vector q) that update the reported emission rates (n×1 vector ) with bias, uncertainty, and correlation in the wind speeds by
This analysis could theoretically be executed in a Bayesian framework, but such an analysis would quickly become intractable as the number of observations (n), and thus the dimensions of the joint distribution , increases. Instead, a Monte Carlo framework can efficiently draw random samples of the vector u and use them in Eq. (23) to update the emission rates and quantify uncertainties.
Steps to generate random samples of the true 10 m wind speed vector to perturb estimated emission rates within a Monte Carlo analysis are as follows (please also see code provided with supplemental information):
-
Calculate the covariance matrix (Σ) from vectors sx, sy, and t using Eq. (22);
-
For each Monte Carlo iteration, calculate an n×1 vector of random variates (z) from the multivariate normal distribution with zero mean and the calculated covariance matrix;
-
Apply the standard univariate normal cumulative distribution function to each element of z independently, which gives gi=Φ(zi);
-
Invert the normal score transform of Eq. (10) (i.e., “back-transform”) to obtain an n×1 vector of random ground-truth 10 m wind speeds (u) with
-
Obtain an n×1 vector of random updated emission rates (q) with
-
Go to step 2 and repeat for desired number of Monte Carlo iterations.
3.1 Region-averaged wind speed error model for case study
Using the BC case study region of Fig. 1 as an illustrative example, Fig. 2a compares the measured 10 m wind speeds during May to October (typically non-snowy months in this region) of 2021–2024 from the 35 weather stations (i.e., ground-truth data on the vertical axis) versus NAM12-estimated 10 m wind speeds (horizontal axis), both in units of m s−1. The colour scale indicates the mode-normalized, empirical joint density of the underlying data computed via a Gaussian kernel density estimator (KDE; see, for example, Scott (2015) for further details). The difference between the overlaid 1:1 correspondence line and the plotted expected value of the ground-truth wind speed conditional on the NWP model-estimated wind speed (i.e., the empirically estimated conditional mean/expectation, ) reveals significant bias error in the NWP model's estimates. This is perhaps unsurprising for this region of BC that is heavily forested, immediately downwind of the Rocky Mountains for the prevailing westerlies, and largely in their foothills (complex topography). Spatially coarse, time-averaged/smoothed NWP models can be expected to miss potentially significant microscale variations in wind, which here tend to bias NWP model-estimated wind speeds high.
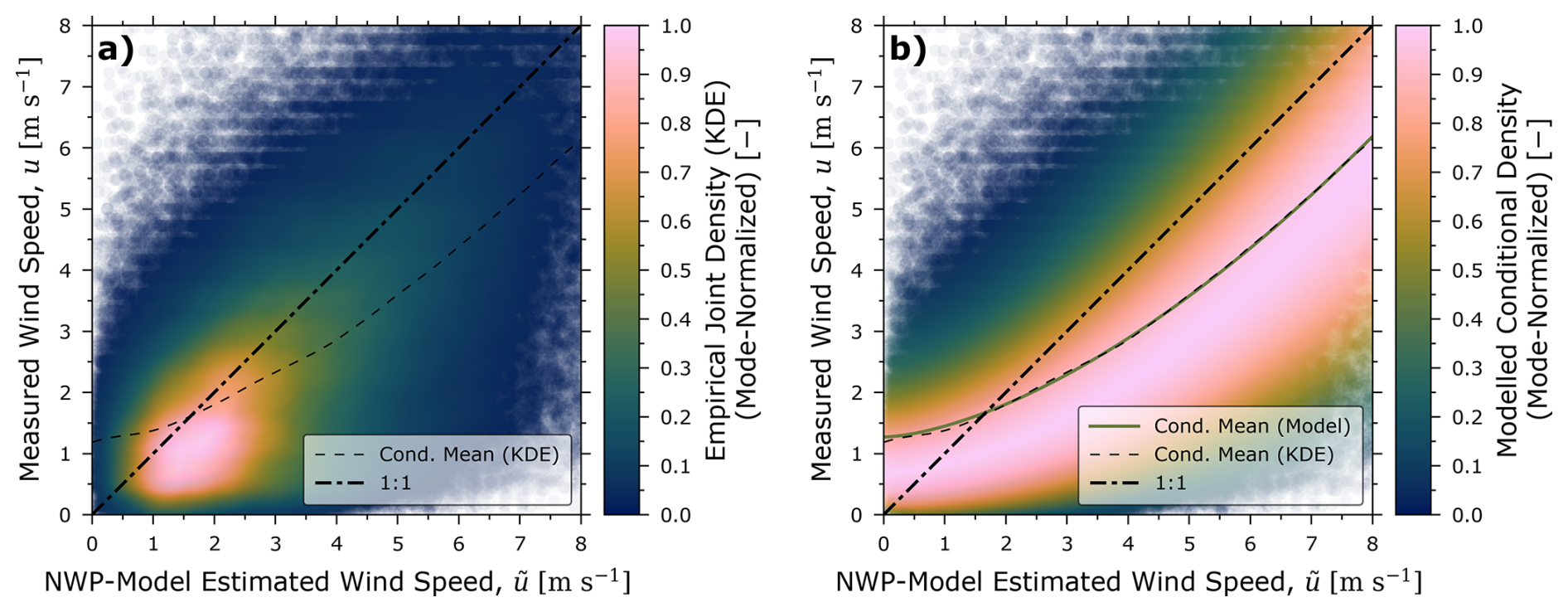
Figure 2Summary plot of derived region-averaged wind speed error model for the present case study showing available data points with forecasted and measured wind speeds below 8 m s−1. (a) plots the mode-normalized, empirical joint density using Gaussian kernel density estimation (KDE) and the conditional mean and (b) plots the modelled conditional density and conditional mean. Good agreement between the central tendencies can be seen in subplot (b) where the modelled and empirical conditional densities closely match.
A region-averaged wind speed error model was fit to these data following the procedure in Sect. 2.2.2. The optimal region-averaged wind speed error model followed a Weibull distribution, as is typical for the modelling of site-level wind speed data (e.g., Elliott et al., 2004). The optimized parameters of the distribution both followed the offset power-law candidate such that the PDF and CDF of the optimized model (indicated with a superscript asterisk) are
with shape and scale parameters fitted to (showing coefficients to three decimal points)
Figure 2b plots the same data as Fig. 2a but colours the points by their modelled conditional probability , which is normalized by the conditional mode for visibility. The conditional mean of the model is plotted alongside the empirically calculated conditional mean, showing near overlapping agreement between the model's and the underlying data's central tendency. Indeed, the modelled and empirical conditional means only deviate notably at forecasted wind speeds exceeding 8.5 m s−1, where less than 1.2 % of the case study data reside.
The goodness-of-fit of the region-averaged wind speed error model is also illustrated in Fig. 3, which compares the ground-truth 10 m wind speed for sub-domains of the NWP model-estimated 10 m wind speed. Subplots (a)–(t) in the figure plot the empirical CDFs for discrete bins of the forecasted wind in increments of 0.4 m s−1 (up to 8 m s−1, representing 98.1 % of the data) in addition to the modelled CDF evaluated at the centre of each bin (i.e., ). Overlaid in text is the number of valid datapoints within each bin as well as two additional statistics: the root mean squared deviation (ΔRMS) and mean deviation/bias (Δbias) between the modelled and empirical CDFs. These statistics are calculated using the empirical conditional distribution and the region-averaged wind speed error model from Eq. (26). ΔRMS is equivalent to the root of the Cramer-von-Mises distance
where the integration is performed numerically using the trapezoidal rule. Analogously, the bias is
These statistics vary as a function of and trend only slightly with the quantity of data in each bin. The RMS deviation of the empirical and modelled CDFs is generally less than 0.02 and bias is typically near-zero; indeed, over all of the case study data, ΔRMS and Δbias are approximately 0.017 and , respectively.
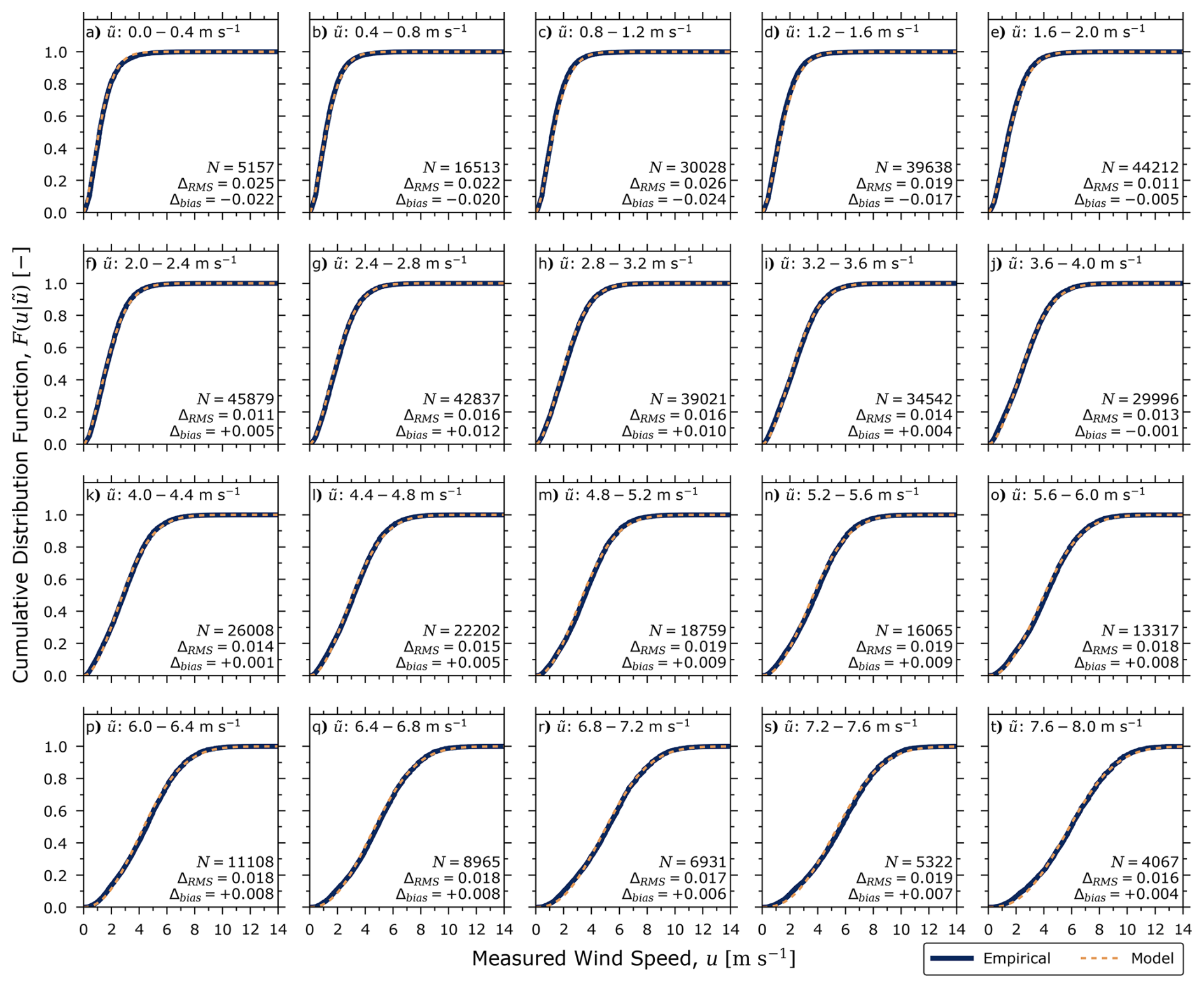
Figure 3Assessment of the region-averaged wind speed error model's goodness-of-fit comparing the empirical and modelled cumulative distribution functions (CDFs) for subsets of the training data, parsed into forecasted wind speed bins of 0.4 m s−1 in width. Each subplot shows the number of training data in the bin, the root-mean-squared deviation of the empirical and model CDFs (ΔRMS) and the absolute bias of the model's CDF (Δbias). A good model fit is observed across all forecasted wind speeds with overall ΔRMS and Δbias of approximately 0.016 and , respectively.
3.2 Spatiotemporal autocorrelation of wind speed errors for case study region
With an optimized region-averaged wind speed error model, we proceed by modelling the spatiotemporal autocorrelation within the case study ROI following Sect. 2.2.3. Figure 4a plots the empirical and modelled spatial semivariograms in lag units of km while Fig. 4b plots the temporal semivariograms in lag units of days. To clearly illustrate the sign of spatiotemporal correlation, we plot results both in terms of their semivariogram (left axis) and their correlogram (right axis) – i.e., correlation as a function of spatial and/or temporal lag. With the previously noted conditions of second-order stationarity, the spatial correlogram is calculated by
with analogous equations for the temporal (with subscript t and and spatiotemporal (with subscript st and correlograms.
Data points in Fig. 4a illustrate the empirical data at 25 km intervals, coloured by the employed fitting weight (see Sect. 2.2.3), and the line plots the modelled semivariogram. The best-fitting semivariogram model for the BC case study was the spherical model yielding a positive correlation approaching 0.55 in the near-field and monotonically decreasing towards zero with 95 % decorrelation (i.e., the range of occurring at a spatial lag of approximately 95 km. This illustrates how wind errors at locations within ∼ 100 km tend to be correlated. Although, with just 35 data points, the empirical semivariogram data are quite scattered and the quality of the fit is questionable (one can envision alternative models fitting nearly as well), this is an ROI-specific limitation. For example, the supplemental figure for the additional analysis of North Dakota shows a much-improved goodness-of-fit for the spatial semivariogram attributable to North Dakota's relatively flatter topography.
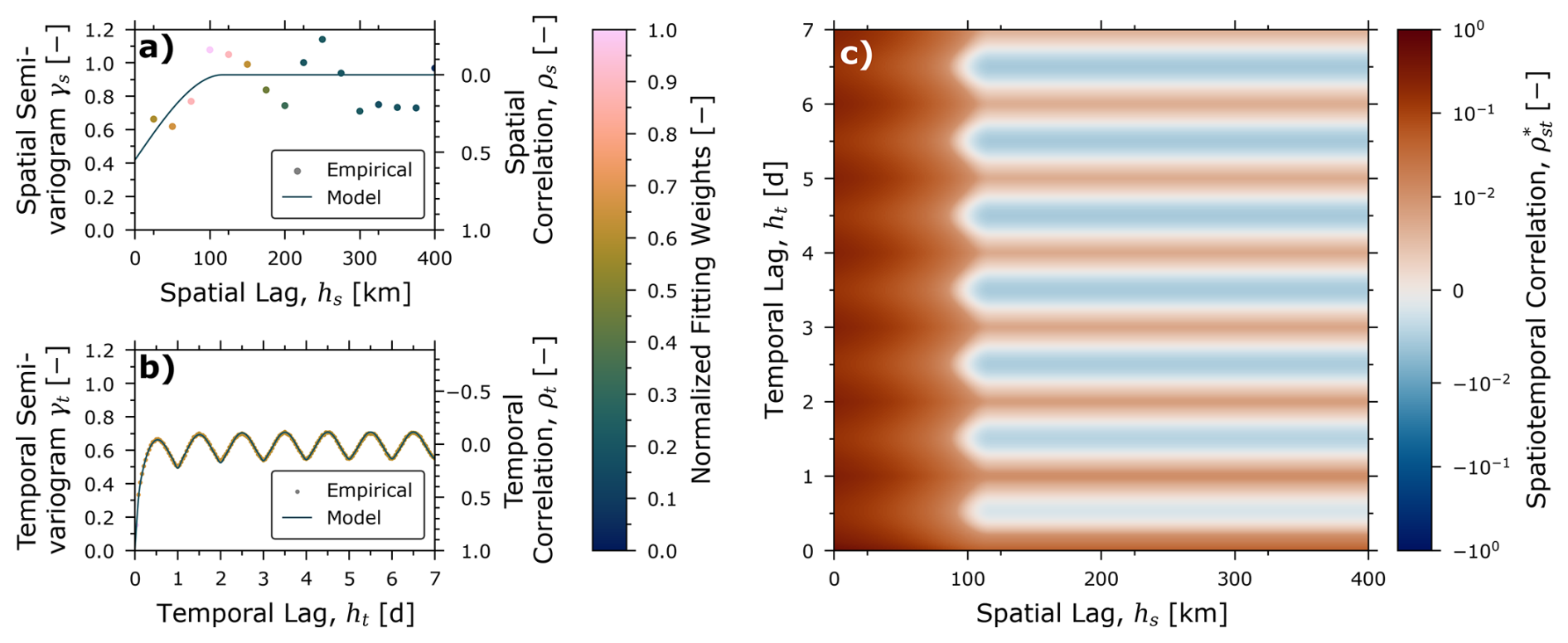
Figure 4Summary of empirical and modelled spatiotemporal autocorrelation. (a) and (b) plot the empirical and modelled spatial and temporal semivariograms/correlograms, respectively, and (c) plots the modelled two-dimensional correlogram. A poor goodness-of-fit to the spatial semivariogram (a) is expected for this case study due to the low number of unique spatial data (35 weather stations) and corresponding scatter in the empirical semivariogram; see text for additional discussion. The empirical temporal semivariogram (b) is captured remarkably well by the present model with a parameter-adjusted coefficient of variation exceeding 0.9999. The global sill of the spatiotemporal semivariogram is approximately 0.976, close to the ideal value of 1.0 expected following normal score transformation, indicating the quality of the region-averaged wind speed error model.
The empirical and modelled temporal semivariograms of Fig. 4b, almost perfectly overlap (parameter-adjusted coefficient of determination exceeding 0.99996), while revealing high correlation over short intervals and smaller diurnal correlations that persist over longer time intervals. The optimized semivariogram from Eq. (18) combines two exponential semivariograms for and with ranges of 0.35 and 3.0 d, with an effective range (i.e., 95 % decorrelation excluding the oscillating component of the semivariogram) of approximately 1.5 d, and includes seven Bessel basis functions (J=7). The data demonstrate that temporal correlation at small lags can be quite significant, yielding positive correlations greater than 0.63 for lags less than the hourly resolution of the NAM12 data. At large lags, temporal correlations, representing bias over the diurnal cycle, presumably due to temporally dependent physical process(es) not captured by the NWP model, oscillate with an amplitude of approximately 0.13.
Figure 4c shows the two-dimensional spatiotemporal correlogram, created by combining the modelled spatial and temporal semivariograms into a two-dimensional model by optimizing for k∗ in Eq. (16). The optimized k∗ value of 0.996 corresponds to a global sill for the spatiotemporal semivariogram of 0.976, which is encouragingly close to the idealized global sill of 1.0 expected following a normal score transform. This is a testament to the quality of the fitted region-averaged wind speed error model.
Figure 4a and b identify that the modelled sills of the spatial and temporal variograms are non-identical. This suggests an anisotropy in the spatiotemporal data where the overall variance in the ROI is more-strongly affected by variability in space (sill of 0.928) than variability in time (sill of 0.636). However, the nuggets of the semivariograms (i.e., their values at zero-lags) imply that the converse is true for near-field correlation, where we observe stronger correlations in time than we do in space. This has important implications for the timing of remote surveys of methane emissions. The stronger temporal correlation suggest that repeat measurements (i.e., re-visits) should ideally be spaced by more than approximately two days (the effective range of the temporal semivariogram) to reduce correlated errors in inferred emissions. Moreover, due to the diurnal variation in temporal correlations, phase shifting repeat measurements by approximately 6 hours (a quarter day) could theoretically minimize the correlated errors in inferred emission rates. Of course, this is not possible for observations by sun-synchronous satellites, which includes most methane-detecting satellite instruments (Jacob et al., 2022), but could be accommodated by careful planning of aerial surveys.
3.3 Effect of correlated wind speed errors on basin-scale methane inventory
To illustrate the effect of correlated wind speed errors on a jurisdiction-level methane inventory, we recalculate the inventory of Johnson et al. (2023) for BC in 2021. In this analysis, to demonstrate how in the limit of infinite measurement data uncorrelated wind speed errors cause uncertainties to diminish towards zero, we replicate the aerial survey data 2, 5, 10, 50, and 100 times with each replication being shifted in time to simulate additional measurements on additional days. We then compute the measured source portion of the inventory three different ways: first, using the RER scaling model of Conrad et al. (2023b) applied to the present training data; second, using the present region-averaged wind speed model (i.e., without autocorrelation), and third, using the present combined model (i.e., with autocorrelation). Referring to Johnson et al. (2023) for further details, the provincial inventory for BC in 2021 is based on 527 quantified sources at 508 sites comprising 601 active facilities and 904 active wells, which are perturbed within a Monte Carlo framework and scaled to the population of facilities/wells in the province. For the present comparison, minor methodological differences to simplify and accelerate this analysis are employed including: (1) all flight passes with unquantified detections are discarded, (2) missed passes are not perturbed using the Bayesian analyses described by Johnson et al. (2023), and (3) sample size uncertainty quantified via bootstrap is ignored. For these reasons, the absolute magnitude of the calculated inventory is not directly comparable to Johnson et al.'s (2023) result and results are instead normalized by the recalculated measured source inventory using the combined model. Results are summarized in Fig. 5.
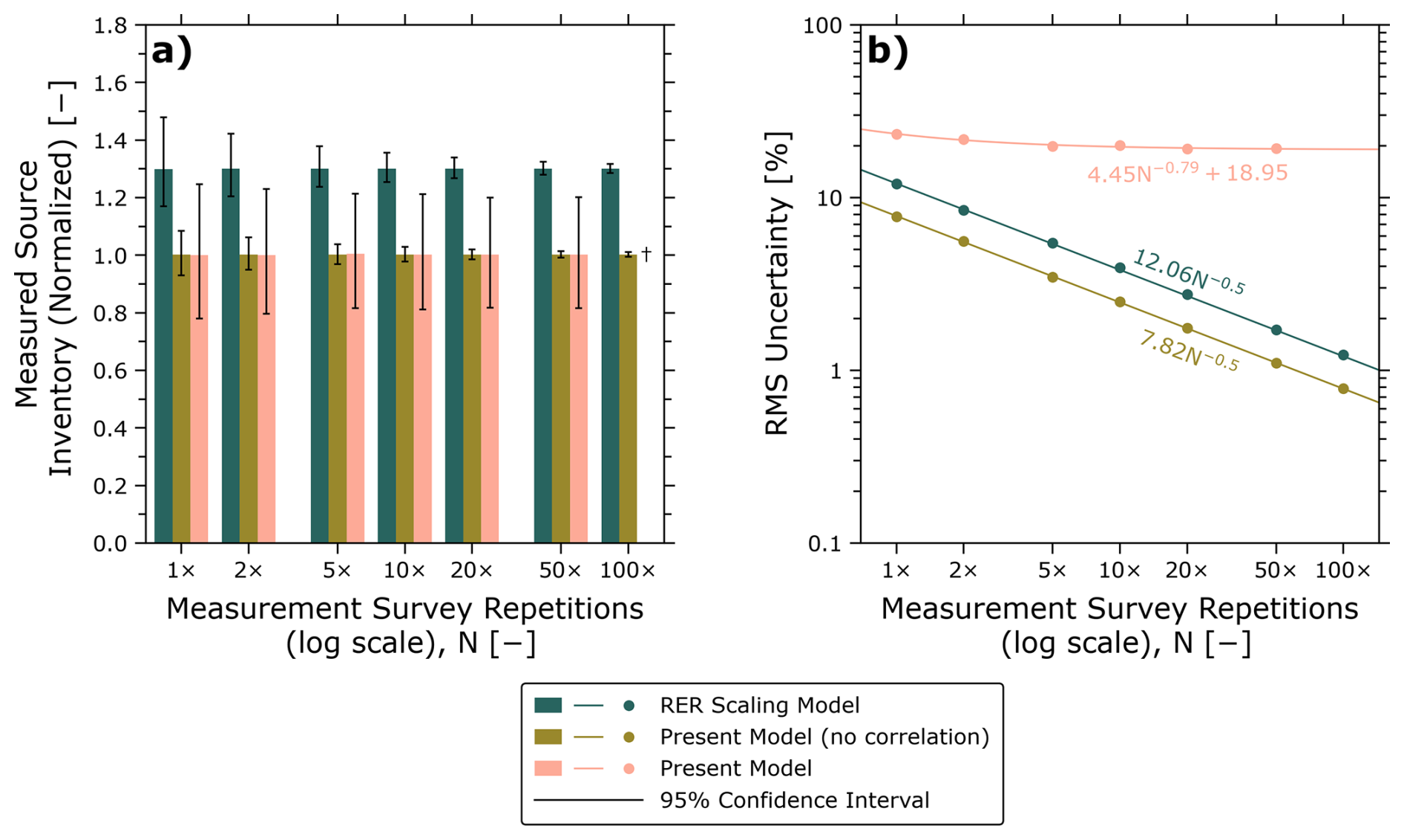
Figure 5Effect of the present wind modelling methodology on the measured source inventory for BC in 2021 (Johnson et al., 2023) for remote survey data replicated up to 100× to illustrate the effect of wind speed error correlation. (a) Bar chart with 95 % equal tail confidence intervals when using the simple RER scaling model (Conrad et al., 2023b) applied to the present wind speed datasets, the region-averaged wind speed error model (i.e., without autocorrelation), and the full combined model (with autocorrelation). (b) Representative one-sided error (root-mean-square of the upper and lower error bars) for each scenario showing the typical N−0.5 decrease in error when correlated errors are not considered and the bounded decrease in error when correlated errors are included via the combined model. † Inventory could not be computed due to computer memory limitations (see Sect. 4.1).
Figure 5a shows the three recalculated measured source inventories with 95 % confidence intervals, plotted as a function of survey size. There are two key observations. Firstly, we observe that the inventory calculated using the RER scaling model is approximately 30 % larger than when using the combined wind error model. This is a consequence of the former's simplicity, in which the expected value of the ground-truth wind speed is a constant factor multiplied by the NWP model-estimated wind speed. The non-linear conditional means of Fig. 2 show that this is a gross over-simplification and, for the present case study at least, results in a sizeable upward bias in wind speed and therefore methane inventory. By contrast, and as expected, the nominal inventory using the combined model with or without correlation are equivalent (since, for a well-fitting model, correlation has no effect on the conditional mean of the ground-truth wind speed). However, as the measurement survey is artificially repeated, inventory uncertainties when using the RER scaling model or when using the region-averaged wind speed error model alone (i.e., without autocorrelation) both unrealistically shrink to zero. This is best summarized by Fig. 5b which plots the RMS uncertainty (i.e., RMS of the upper and lower error bars) as a function of survey repetitions. The figure shows that when correlated errors are ignored, uncertainties decrease per the standard error of the mean (N−0.5) as is expected for the inventory calculation, which is essentially a linear function of mean emission factors for various facility/well types. We also observe that the RER scaling model provides larger uncertainties than the region-averaged wind speed error model when autocorrelation is ignored; this is due to the complexity of the latter that captures non-linearity in the relation between ground-truth and NWP model-estimated winds.
Most importantly, Fig. 5b shows the dramatic effect of wind speed error correlation. For the nominal inventory without repetition, uncertainties increase by a factor of approximately three when correlation in the wind speed data is accurately modelled. Perhaps more importantly, correlations in wind speed impose a lower bound on uncertainties – more measurements do not bring uncertainties to zero. This is a desired characteristic of the combined model. While, in general, additional measurements tend to improve accuracy in the nominal inventory, because wind speed errors measurements are not generally statistically independent (i.e., they are correlated), central limit theorem does not apply, and the uncertainties should not be expected to decrease to zero ad infinitum with additional measurements.
3.4 Temporal variability of the case-study wind speed error model
To assess the robustness of the combined model to variations across different years, we have derived combined models using the same methodology for data during each May–October period of 2021 through 2024 independently. Figure 6a plots the bias (mean error with a positive value indicating overestimation by the NWP model) and standard deviation of the region-averaged wind speed error models (i.e., as a function of NWP model-estimated 10 m wind speed for these periods of time and for the aggregated data from 2021–2024. Encouragingly, there is little variation in both the central tendency and variability across years, with the aggregate result representing a good temporal average. This is true also for the spatial and temporal correlograms in Figs. 6b and c with perhaps the largest deviations being apparent in the spatial near-field which may be related to the limited number of weather stations and the scattered empirical spatial semivariogram (see Sect. 3.2 and Fig. 4). Overall, the minimal observed deviations in Figs. 6b and c suggest that the aggregated model provides a robust representation of spatiotemporal correlation for the case study ROI across different years. Leveraging this insight, Appendix A provides six additional combined models derived using the present methodology for the Canadian province of Alberta, the U.S. state of North Dakota, the combined oil and gas region of Saskatchewan and North Dakota (as a surrogate for the Canadian Province of Saskatchewan, which has limited public wind speed measurement data), and the country of Colombia.
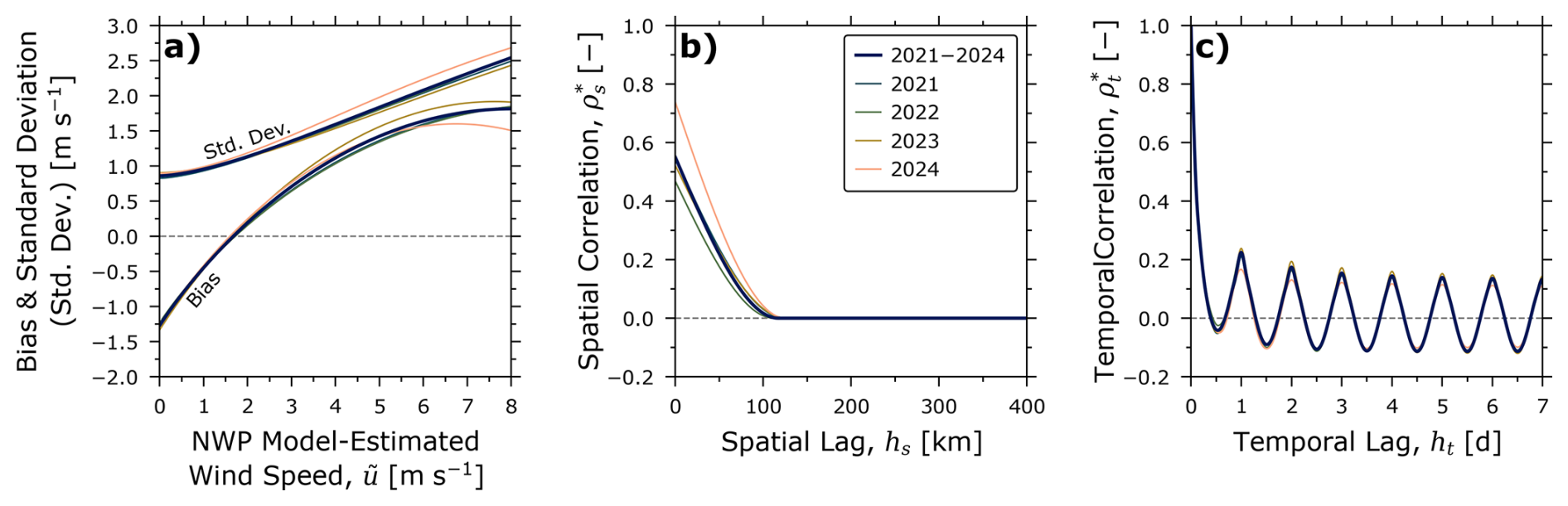
Figure 6Comparisons of optimized models using data across four years independently and in aggregate: (a) bias and standard deviation of the region-averaged wind speed error model, (b) spatial correlogram, and (c) temporal correlogram. Results identify modest variability from year-to-year, with the aggregate model representing a good time-average of wind speed error and spatial autocorrelation.
3.5 Comparing performance of NWP models
The derived methodology can be used to assess and compare the performance of different NWP models within a fixed ROI. As a proof-of-concept, two of the six additional analyses described in Appendix A compare the performance of NAM12 and the High-Resolution Rapid Refresh model (HRRR; Dowell et al., 2022; James et al., 2022) in the U.S. state of North Dakota. Figure 7 compares these combined models against the BC case study in the same manner as Fig. 6. Firstly, comparing the NAM12 results in BC and ND, we see markedly different results with less overall bias, slower spatial decorrelation, and less pronounced temporal correlation in ND. We suspect that these observations are a result of the very different topographies in BC and ND, with BC being much more rugged and treed and generally exhibiting a lower albedo/surface reflectivity. A higher albedo in ND theoretically reduces surface heating resulting in less diurnal variation in wind speeds; we also observe low temporal correlation in the oil and gas-producing region of the Canadian province of Saskatchewan (see Supplement), which has a similar topography and land cover as ND.
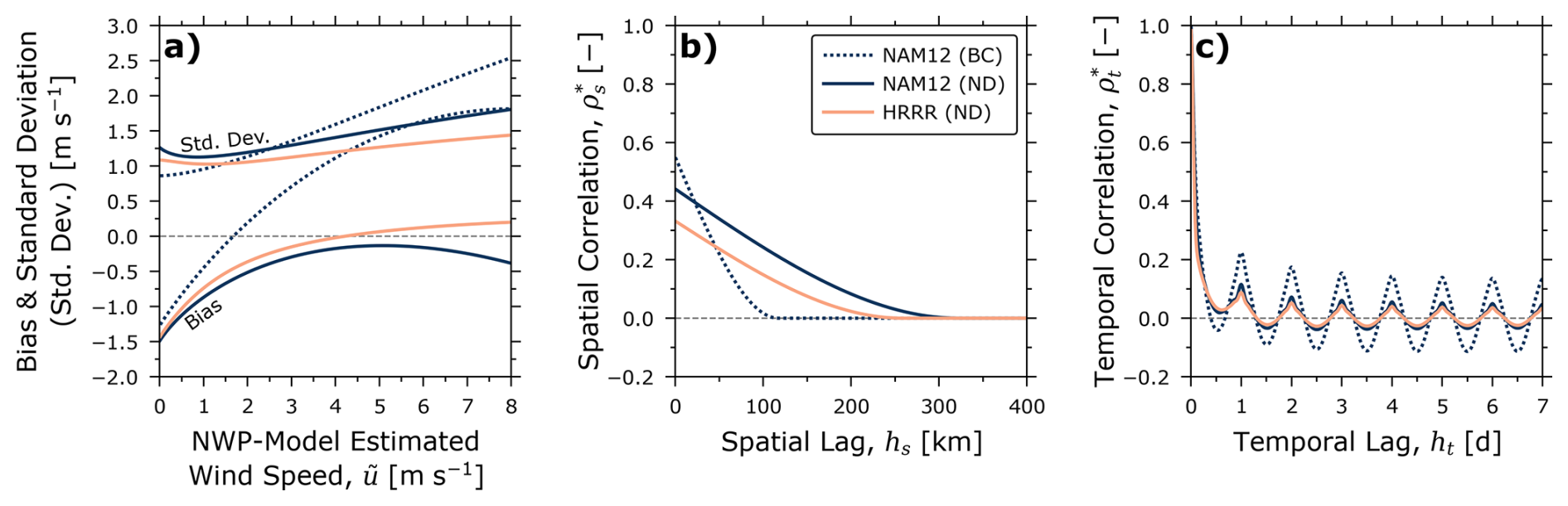
Figure 7Comparisons of optimized models for two regions (British Columbia (BC) and North Dakota (ND)) and NWP models (NAM12 and HRRR): (a) bias and standard deviation of the region-averaged wind speed error model, (b) spatial correlogram, and (c) temporal correlogram. Unsurprisingly, performance of the same NWP can be markedly different in different regions. Moreover, the higher-spatial resolution HRRR model provides less bias, variance, and correlation than NAM12 suggesting its usage is preferred for North Dakota.
The present methodology effectively calibrates NWP model-estimated wind speeds using the available measurement data. However, NWP models do indeed perform differently with respect to bias and dispersion of the region-averaged wind speed error model and spatiotemporal autocorrelation. In ND, surely due to its improved (3 km) resolution and hourly data assimilation, the HRRR model delivers less bias and dispersion in the region-averaged wind speed error model, faster decorrelation in space, and less overall autocorrelation in both space and time. This demonstrates that when using NWP model-estimated data for large-scale remote surveys and the development of methane inventories – and despite calibration using the same ground-truth dataset – reductions in inventory uncertainties can be achieved by quantifying emission rates using the NWP model that minimizes dispersion in wind speed error and spatiotemporal autocorrelation.
As noted in Sect. 2.1.2, there is some ambiguity regarding the averaging time of ground-truth measurement wind speeds for the present case study; while averaging time is generally recommended to be ten minutes, we cannot be certain that this standard is applied for all ground-truth data. As different averaging times may be desired for different remote measurement techniques, the applicability of the derived case-study model might reasonably be questioned. However, on the scale of a measurement, the averaging time would only affect the dispersion in the derived region-averaged wind speed error model, the bias would likely be negligibly affected. If the averaging time of the modelled data were smaller than required by the measurement technique, then dispersion of the region-averaged wind speed error model would be overestimated and vice versa. Ideally, higher resolution ground-truth wind speed data could enable investigation into the significance of this limitation, but these data are not available to our knowledge.
One drawback of the combined models is that, relative to simpler models that do not consider spatiotemporal autocorrelation of wind speed errors, computation time and memory usage for random sampling within a Monte Carlo framework (see Sect. 2.3) may be prohibitively large. Random sampling of the multivariate normal distribution requires a decomposition of the n×n covariance matrix (e.g., Gentle, 2009); the fastest method to do this using the NumPy software package (Harris et al., 2020), the Cholesky decomposition, is of order n3 (e.g., Watkins, 2002). Thus, as n increases, computational time might become prohibitively large. Moreover, even when the Cholesky decomposition is performed “in-place”, memory usage scales quadratically, which may cause out-of-memory conditions on desktop computers. This occurred as part of the analysis in Sect. 3.3 (see rightmost data point in Fig. 5a), where the simulated survey with 162 600 measurements caused memory overflow. Practically, however, memory overflow issues like this can be solved by leveraging modern high-performance scientific computing resources.
To model spatiotemporal autocorrelation with the Gaussian copula through the semivariogram, we assumed second-order stationarity of the transformed data, z (refer to Sect. 2.3). In general, we do not expect wind speed errors for any one weather station and time period to be stationary since, for example, microscale variations in topography would likely cause bias and precision error in the NWP model-estimated wind speed that change with space and time. The same can be said when considering data across regions and time periods in general, owing to numerous factors including the finite availability of measurement data and, more importantly, errors in NWP model-estimated wind speeds that change in time and space. While the region-averaged wind speed error model considers the average bias and precision errors, it does not remove the spatiotemporal trend of these from z. As such, the assumption of secondary stationarity is overly optimistic and there is likely some error in the combined models because of non-stationarity in the data. We also (see Eq. 15) model spatial autocorrelation as isotropic. Given the non-uniformity of terrain in general but especially in the case study ROI, we would expect spatial autocorrelation to be anisotropic; however, to maintain the tractability of our modelling approach, we ignore this and accept the corresponding inaccuracy in the model.
Our case study and additional analyses derive models for wind speeds at 10 m above ground level. The modelling approach, however, is agnostic to the specific height above ground level and model fitting could be performed using any height for ground-truth and NWP model-estimated winds; they could indeed even be different. The caveat is that additional bias and precisions errors will be engendered if scaling any wind speeds using an assumed wind speed profile.
Our case study analysis was performed during the typical non-snowy period in Northeastern British Columbia, May to October, since the presence of snow may preclude remote measurements from air and space. The presented methodology is agnostic to the time period of interest and can be applied to data from any time period as long as there are sufficient data available. Indeed, as indicated in Table A1, we have applied our method to evaluate the ERA5-Land reanalysis product over the entire calendar year in the primary oil and gas-producing region of Colombia.
The methodology we have outlined requires ground-truth wind speed measurement data in the specific region of interest. We expect that such data do not exist or are not publicly available in some regions. In such a case, we would recommend that representative wind data be sought from a nearby region with similar topography and prevailing winds, if possible, while recognizing that there would be some unquantifiable bias in the model of wind speed error and its autocorrelation.
One opportunity to improve our methodology is to expand the candidate models for the marginal wind speed error distributions (see Sect. 2.2.2). Referring to Fig. 3, the performance of the case study model reduces as the NWP model-estimated wind speeds go to zero. This is partly due to the reduction of available data in this domain – i.e., model fitting is naturally biased by the amount of available data – but may also be a consequence of the candidate functions for (constant, linear, or offset power-law). Theoretically, the model might be improved by considering additional candidate functions of different forms.
In this article, we have presented a new method to probabilistically model the errors of NWP model-estimated wind speeds and their autocorrelations in both space and time. The combined model (superimposing the region-averaged wind speed error model and the spatial autocorrelation model) enables random sampling of true wind speeds that are spatiotemporally correlated, which is necessary to properly characterize uncertainties when aggregating remote measurements from large aerial and satellite surveys into methane inventories. We illustrate the importance of considering spatiotemporal correlation for remote measurement surveys via our case study for the oil and gas-producing region in the northeast of British Columbia, Canada, which demonstrates how bias and precision errors in NWP model-estimated wind speeds can be easily characterized while considering error correlation. The case study model shows notable spatial autocorrelation within a range of approximately 100 km and oscillatory temporal autocorrelation following the diurnal cycle. This former observation provides guidance for repeated remote measurements in an aerial survey, where, for the case study region, spacing between re-measurements would ideally be greater than two days and phase-shifted by 6 hours to minimize temporal correlation in the inferred emission rates. We also provide guidance in using the case study models and six additional models for other regions and NWP models (see Appendix A) using the provided code (see Code and data availability).
To test the robustness of the present methodology for different regions of interest (ROIs), glean insight into the spatial variability of wind speed error and autocorrelation, and provide combined models for methane inventory development in various oil and gas-producing regions, we have developed six additional combined models. These include combined models for NAM12 in three additional ROIs using weather station data for the oil and gas-producing regions of the Canadian provinces of Alberta (AB) and Saskatchewan (SK) and the U.S. state of North Dakota (ND). We also develop an additional combined model for Saskatchewan with ground-truth data augmented by measurement data in North Dakota, which has a similar topography and oil and gas sector; we denote this analysis as “SK + ND”. To support parallel work of the authors' in developing methane emissions inventories, we also present a combined model for the primary oil and gas-producing region of Colombia (COLO) using the ERA5-Land reanalysis (Muñoz Sabater, 2019) from the European Centre for Medium-Range Weather Forecasts (ECMWF). Finally, to illustrate the effectiveness of the present method for comparing NWP model performance, we also develop a combined model for ND using the high-resolution rapid refresh (HRRR) forecast system. Additional figures corresponding to Figs. 2, 3, and 4 for each of the additional analyses are available in the supplement.
Ground-truth measurement data supporting the additional analyses were sourced from the ECCC network noted in the manuscript augmented by data from three weather station networks: the Ambient Air Quality network of the Government of Alberta (AB-AAQ), the North Dakota Agricultural Weather Network (NDAWN), and Colombia's Instituto de Hidrología, Meteorología y Estudios Ambientales (IDEAM). Table A1 summarizes the ground-truth data for these analyses in the same manner as Table 1.
Table A1Ground-truth data sources providing scalar wind speeds for comparison with NWP model-estimated forecasted wind speeds and development of combined models for additional jurisdictions.
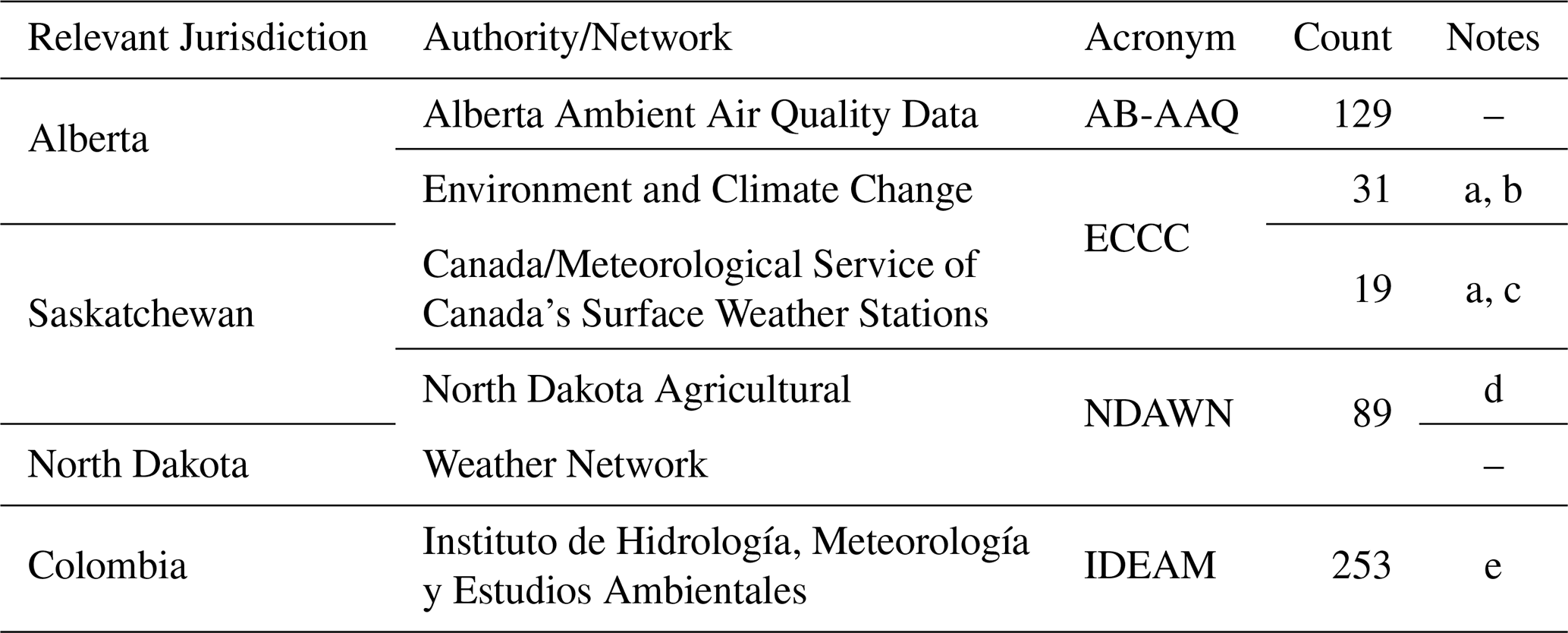
a The anemometer is usually located at 10 m above ground. Measurements represent the 1, 2, or 10 min period preceding the top of the hour (Environment and Climate Change Canada, n.d.).
b Excludes six weather stations within 10 km of known NAM data source(s).
c Excludes eight weather stations within 10 km of known NAM data source(s).
d One additional analysis of Saskatchewan (SK+ND) augments ECCC data in Saskatchewan with NDAWN data.
e Model developed using data over the entire year for 2021–2024 for Colombia, where snow does not preclude aerial survey.
A python code summarizing model equations and enabling visualization and Monte Carlo sampling (per Sect. 2.3) of the developed models is provided as part of this article's Supplement located at https://doi.org/10.5683/SP3/PMLX4X (Conrad and Johnson, 2025). A MATLAB code to implement wind speed error modelling from NWP and measurement data can be made available upon request.
NAM12 data are publicly available via https server at https://www.ncei.noaa.gov/data/north-american-mesoscale-model/access/forecast/ (last access: 7 March 2026) and on Amazon Web Services (16 September 2021 and later) at https://registry.opendata.aws/noaa-nam/ (last access: 7 March 2026). HRRR data are publicly available on Amazon Web Services (30 July 2014 and later) at https://registry.opendata.aws/noaa-hrrr-pds/ (last access: 7 March 2026). ERA5-Land data are publicly available through ECMWF's Climate Data Store at https://cds.climate.copernicus.eu/datasets/reanalysis-era5-land (last access: 7 March 2026). Climate/weather station data published by Environment and Climate Change Canada, the Government of British Columbia, the Government of Alberta, the North Dakota Agricultural Weather Network, and Colombia's Instituto de Hidrología, Meteorología y Estudios Ambientales are publicly available through online portals, anonymous FTP access, and/or https server:
-
ECCC: https://dd.weather.gc.ca/today/climate/observations/hourly/csv/BC/ (last access: 7 March 2026)
-
BC-ENV (Contains information licensed under the Open Government Licence – British Columbia): ftp://ftp.env.gov.bc.ca/pub/outgoing/AIR/AnnualSummary/ (last access: 7 March 2026) (verified) and ftp://ftp.env.gov.bc.ca/pub/outgoing/AIR/Hourly_Raw_Air_Data/Year_to_Date/ (last access: 7 March 2026) (unverified)
-
BC-FLNRO (©2025, Province of British Columbia): ftp://ftp.for.gov.bc.ca/HPR/external/!publish/BCWS_DATA_MART (last access: 7 March 2026) and https://www.for.gov.bc.ca/ftp/HPR/external/!publish/BCWS_DATA_MART/ (last access: 7 March 2026)
-
AB-AAQ: https://datamanagementplatform.alberta.ca/Ambient (last access: 7 March 2026)
-
NDAWN: https://ndawn.ndsu.nodak.edu (last access: 7 March 2026)
-
IDEAM: https://www.datos.gov.co/Ambiente-y-Desarrollo-Sostenible/Velocidad-del-Viento/sgfv-3yp8 (last access: 7 March 2026)
BMC conceptualized the research and developed the methodology. MRJ was responsible for funding acquisition, project administration, provision of resources, and supervision. BMC curated the data, performed the formal analysis and investigation, and developed the software. Both authors produced the original manuscript and reviewed and edited the manuscript throughout the publication process.
The contact author has declared that neither of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
This work was supported by the United Nations Environment Programme (UNEP) under the framework of UNEP's International Methane Emissions Observatory (IMEO, grant no. DTIE22-EN4582), the British Columbia Government through the Ministry of Environment and Climate Change Strategy (grant no. TP23CASG0011MY), the Natural Sciences and Engineering Research Council of Canada (NSERC, grant nos. ALLRP 590391-23 and RGPIN-2024-06485), and Natural Resources Canada (NRCan, grant no. EIP-22-002).
This paper was edited by Steffen Beirle and reviewed by three anonymous referees.
Akaike, H.: A new look at the statistical model identification, IEEE Trans. Automat. Contr., 19, 716–723, https://doi.org/10.1109/TAC.1974.1100705, 1974.
Arrieta-Prieto, M. and Schell, K. R.: Spatio-temporal probabilistic forecasting of wind power for multiple farms: A copula-based hybrid model, Int. J. Forecast., 38, 300–320, https://doi.org/10.1016/j.ijforecast.2021.05.013, 2022.
BC ENV: Air Quality and Climate Monitoring: Unverified Hourly Air Quality and Meteorological Data, https://catalogue.data.gov.bc.ca/dataset, last access: 16 June 2025.
BC Ministry of Environment and Parks: Air Quality and Climate Monitoring: Verified Hourly Air Quality and Meteorological Data, https://catalogue.data.gov.bc.ca/dataset (last access: 16 June 2025), 24 February 2015.
BCWS: BC Wildfire Active Weather Stations and Data, https://catalogue.data.gov.bc.ca/dataset/bc-wildfire-active-weather-stations, last access: 16 June 2025.
British Columbia Energy Regulator: Multi-Year Study to Look at Methane Emissions (IB 2022-02), https://www.bc-er.ca/news/multi-year-study-to-look-at-methane-emissions/ (last access: 16 June 2025), 2022.
Burt, S.: The Weather Observer's Handbook, Cambridge University Press, New York, NY, https://doi.org/10.1017/CBO9781139152167, 2012.
Conrad, B. M. and Johnson, M. R.: Supplemental Code and Derived Models for “Accounting for spatiotemporally correlated errors in wind speed for remote surveys of methane emissions”, Borealis, V1 [data set], https://doi.org/10.5683/SP3/PMLX4X, 2025.
Conrad, B. M., Tyner, D. R., Li, H. Z., Xie, D., and Johnson, M. R.: A measurement-based upstream oil and gas methane inventory for Alberta, Canada reveals higher emissions and different sources than official estimates, Commun. Earth Environ., 4, 1–10, https://doi.org/10.1038/s43247-023-01081-0, 2023a.
Conrad, B. M., Tyner, D. R., and Johnson, M. R.: Robust probabilities of detection and quantification uncertainty for aerial methane detection: Examples for three airborne technologies, Remote Sens. Environ., 288, 113499, https://doi.org/10.1016/j.rse.2023.113499, 2023b.
Conrad, B. M., Tyner, D. R., and Johnson, M. R.: The Futility of Relative Methane Reduction Targets in the Absence of Measurement-Based Inventories, Environ. Sci. Technol., 57, 21092–21103, https://doi.org/10.1021/acs.est.3c07722, 2023c.
Cressie, N. A. C.: Statistics for Spatial Data, Revised, John Wiley & Sons, Inc., New York, NY, https://doi.org/10.1002/9781119115151, 1993.
Curriero, F. C.: On the Use of Non-Euclidean Distance Measures in Geostatistics, Math. Geol., 38, 907–926, https://doi.org/10.1007/s11004-006-9055-7, 2006.
Cusworth, D. H., Thorpe, A. K., Ayasse, A. K., Stepp, D., Heckler, J., Asner, G. P., Miller, C. E., Yadav, V., Chapman, J. W., Eastwood, M. L., Green, R. O., Hmiel, B., Lyon, D. R., and Duren, R. M.: Strong methane point sources contribute a disproportionate fraction of total emissions across multiple basins in the United States, Proc. Natl. Acad. Sci., 119, 1–7, https://doi.org/10.1073/pnas.2202338119, 2022.
De Iaco, S., Myers, D. E., and Posa, D.: Space–time analysis using a general product–sum model, Stat. Probab. Lett., 52, 21–28, https://doi.org/10.1016/S0167-7152(00)00200-5, 2001.
Deutsch, C.: DECLUS: a fortran 77 program for determining optimum spatial declustering weights, Comput. Geosci., 15, 325–332, https://doi.org/10.1016/0098-3004(89)90043-5, 1989.
Deutsch, C. V. and Journel, A. G.: GSLIB: Geostatistical Software Library and User's Guide, 2nd ed., Oxford University Press, New York, NY, https://claytonvdeutsch.com/wp-content/uploads/2019/03/GSLIB-Book-Second-Edition.pdf (last access: 7 March 2026), 1997.
Dowell, D. C., Alexander, C. R., James, E. P., Weygandt, S. S., Benjamin, S. G., Manikin, G. S., Blake, B. T., Brown, J. M., Olson, J. B., Hu, M., Smirnova, T. G., Ladwig, T., Kenyon, J. S., Ahmadov, R., Turner, D. D., Duda, J. D., and Alcott, T. I.: The High-Resolution Rapid Refresh (HRRR): An Hourly Updating Convection-Allowing Forecast Model, Part I: Motivation and System Description, Weather Forecast., 37, 1371–1395, https://doi.org/10.1175/WAF-D-21-0151.1, 2022.
Duren, R. M., Thorpe, A. K., Foster, K. T., Rafiq, T., Hopkins, F. M., Yadav, V., Bue, B. D., Thompson, D. R., Conley, S., Colombi, N. K., Frankenberg, C., McCubbin, I. B., Eastwood, M. L., Falk, M., Herner, J. D., Croes, B. E., Green, R. O., and Miller, C. E.: California's methane super-emitters, Nature, 575, 180–184, https://doi.org/10.1038/s41586-019-1720-3, 2019.
ECCC: Historical Climate Data, https://climate.weather.gc.ca/, last access: 16 June 2025.
Ecker, M. D. and Gelfand, A. E.: Bayesian Variogram Modeling for an Isotropic Spatial Process, J. Agric. Biol. Environ. Stat., 2, 347, https://doi.org/10.2307/1400508, 1997.
Elliott, D., Schwartz, M., and Scott, G.: Wind Resource Base, in: Encyclopedia of Energy, Elsevier, 465–479, ISBN 9780121764807, 2004.
Environment and Climate Change Canada: Technical Documentation: Historical Hourly Climate Station Data, https://www.canada.ca/en/environment-climate-change/services/climate-change/canadian-centre-climate-services/display-download/technical-documentation-hourly-data.html (last access: 16 June 2025), n.d.
Fosdick, B., Weller, Z., Wong, H., Corbett, A., Roell, Y., Martinez, E., Berry, A., Gielczowski, N., Hajny, K., and Moore, C.: Extrapolation Approaches for Creating Comprehensive Measurement-Based Methane Emissions Inventories, ACS EST Air, https://doi.org/10.1021/acsestair.5c00455, 2025.
Gentle, J. E.: Computational Statistics, Springer New York, New York, NY, ISBN 9780387981437, 2009.
Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M. H., Brett, M., Haldane, A., del Río, J. F., Wiebe, M., Peterson, P., Gérard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohlke, C., and Oliphant, T. E.: Array programming with NumPy, Nature, 585, 357–362, https://doi.org/10.1038/s41586-020-2649-2, 2020.
Isaaks, E. H. and Srivastava, R. M.: Spatial continuity measures for probabilistic and deterministic geostatistics, Math. Geol., 20, 313–341, https://doi.org/10.1007/BF00892982, 1988.
Jacob, D. J., Varon, D. J., Cusworth, D. H., Dennison, P. E., Frankenberg, C., Gautam, R., Guanter, L., Kelley, J., McKeever, J., Ott, L. E., Poulter, B., Qu, Z., Thorpe, A. K., Worden, J. R., and Duren, R. M.: Quantifying methane emissions from the global scale down to point sources using satellite observations of atmospheric methane, Atmos. Chem. Phys., 22, 9617–9646, https://doi.org/10.5194/acp-22-9617-2022, 2022.
James, E. P., Alexander, C. R., Dowell, D. C., Weygandt, S. S., Benjamin, S. G., Manikin, G. S., Brown, J. M., Olson, J. B., Hu, M., Smirnova, T. G., Ladwig, T., Kenyon, J. S., and Turner, D. D.: The High-Resolution Rapid Refresh (HRRR): An Hourly Updating Convection-Allowing Forecast Model, Part II: Forecast Performance, Weather Forecast., 37, 1397–1417, https://doi.org/10.1175/WAF-D-21-0130.1, 2022.
Johnson, M. R., Tyner, D. R., and Szekeres, A. J.: Blinded evaluation of airborne methane source detection using Bridger Photonics LiDAR, Remote Sens. Environ., 259, 112418, https://doi.org/10.1016/j.rse.2021.112418, 2021.
Johnson, M. R., Conrad, B. M., and Tyner, D. R.: Creating measurement-based oil and gas sector methane inventories using source-resolved aerial surveys, Commun. Earth Environ., 4, 139, https://doi.org/10.1038/s43247-023-00769-7, 2023.
Kunkel, W. M., Carre-Burritt, A. E., Aivazian, G. S., Snow, N. C., Harris, J. T., Mueller, T. S., Roos, P. A., and Thorpe, M. J.: Extension of Methane Emission Rate Distribution for Permian Basin Oil and Gas Production Infrastructure by Aerial LiDAR, Environ. Sci. Technol., 57, 12234–12241, https://doi.org/10.1021/acs.est.3c00229, 2023.
Manfredi, J., Walters, T., Wilke, G., Osborne, L., Hart, R., Incrocci, T., Schmitt, T., Garrett, V. K., Boyce, B., and Krechmer, D.: Road Weather Information System Environmental Sensor Station Siting Guidelines, Version 2.0, United States Department of Transportation, https://rosap.ntl.bts.gov/view/dot/3290 (last access: 7 March 2026), 2008.
Muñoz Sabater, J.: ERA5-Land Hourly Data from 1950 to Present, Copernicus Climate Change Service (C3S) Climate Data Store (CDS) [data set], https://doi.org/10.24381/cds.e2161bac, 2019.
National Centers for Environmental Prediction, National Weather Service, National Oceanic and Atmospheric Administration, and U.S. Department of Commerce: NCEP North American Mesoscale (NAM) 12 km Analysis, https://doi.org/10.5065/G4RC-1N91, last access: 16 June 2025.
Nelsen, R. B.: Properties and Applications of Copulas: A brief survey, in: Proceedings of the First Brazilian Conference on Statistical Modelling in Insurance and Finance, edited by: Dhaene, J., Kolev, N., and Morettin, P., São Paulo, Brazil, 10–28, CorpusID: 2508363, 2003.
Nelsen, R. B.: An Introduction to Copulas, Springer Science+Business Media, Inc., New York, NY, https://doi.org/10.1007/0-387-28678-0, 2006.
Oke, T. R.: Initial Guidance to Obtain Representative Meteorological Observations at Urban Sites, Instruments and Observing Methods, Report 81, WMO, https://urban-climate.org/wp-content/uploads/2023/10/Oke_2006_IOM-81-UrbanMetObs.pdf (last access: 21 May 2026), 2004.
Pyrcz, M. J. and Deutsch, C. V.: Semivariogram Models Based on Geometric Offsets, Math. Geol., 38, 475–488, https://doi.org/10.1007/s11004-005-9025-5, 2006.
Richmond, A.: Two-point declustering for weighting data pairs in experimental variogram calculations, Comput. Geosci., 28, 231–241, https://doi.org/10.1016/S0098-3004(01)00070-X, 2002.
Sadegh, M., Ragno, E., and AghaKouchak, A.: Multivariate Copula Analysis Toolbox (MvCAT): Describing dependence and underlying uncertainty using a Bayesian framework, Water Resour. Res., 53, 5166–5183, https://doi.org/10.1002/2016WR020242, 2017.
Santos, A., Mollel, W., Duggan, G. P., Hodshire, A., Vora, P., and Zimmerle, D.: Using Measurement-Informed Inventory to Assess Emissions in the Denver-Julesburg Basin, ACS EST Air, 2, 1598–1611, https://doi.org/10.1021/acsestair.5c00089, 2025.
Scarpelli, T. R., Cusworth, D. H., Duren, R. M., Kim, J., Heckler, J., Asner, G. P., Thoma, E., Krause, M. J., Heins, D., and Thorneloe, S.: Investigating Major Sources of Methane Emissions at US Landfills, Environ. Sci. Technol., 58, 21545–21556, https://doi.org/10.1021/acs.est.4c07572, 2024.
Scott, D. W.: Multivariate Density Estimation: Theory, Practice, and Visualization, 2nd edn., John Wiley & Sons, Inc., Hoboken, NJ, https://doi.org/10.1002/9780470316849, 2015.
Sherwin, E. D., Rutherford, J. S., Zhang, Z., Chen, Y., Wetherley, E. B., Yakovlev, P. V., Berman, E. S. F., Jones, B. B., Cusworth, D. H., Thorpe, A. K., Ayasse, A. K., Duren, R. M., and Brandt, A. R.: US oil and gas system emissions from nearly one million aerial site measurements, Nature, 627, 328–334, https://doi.org/10.1038/s41586-024-07117-5, 2024.
Sklar, A.: Fonctions de répartition à N dimensions et leurs marges, Publ. l'Institut Stat., l'Université Paris, 8, 229–231, https://hal.science/hal-04094463/document (last access: 7 March 2026), 1959.
Thorpe, A. K., Kort, E. A., Cusworth, D. H., Ayasse, A. K., Bue, B. D., Yadav, V., Thompson, D. R., Frankenberg, C., Herner, J., Falk, M., Green, R. O., Miller, C. E., and Duren, R. M.: Methane emissions decline from reduced oil, natural gas, and refinery production during COVID-19, Environ. Res. Commun., 5, 021006, https://doi.org/10.1088/2515-7620/acb5e5, 2023.
Thorpe, M. J. and Kreitinger, A. T.: Apparatuses and Methods for Gas Flux Measurements, U.S. Patent No: 20240361200, 2024.
Thorpe, M. J., Kreitinger, A., Altamura, D. T., Dudiak, C. D., Conrad, B. M., Tyner, D. R., Johnson, M. R., Brasseur, J. K., Roos, P. A., Kunkel, W. M., Carre-Burritt, A., Abate, J., Price, T., Yaralian, D., Kennedy, B., Newton, E., Rodriguez, E., Elfar, O. I., and Zimmerle, D. J.: Deployment-invariant probability of detection characterization for aerial LiDAR methane detection, Remote Sens. Environ., 315, 114435, https://doi.org/10.1016/j.rse.2024.114435, 2024.
Varon, D. J., Jacob, D. J., McKeever, J., Jervis, D., Durak, B. O. A., Xia, Y., and Huang, Y.: Quantifying methane point sources from fine-scale satellite observations of atmospheric methane plumes, Atmos. Meas. Tech., 11, 5673–5686, https://doi.org/10.5194/amt-11-5673-2018, 2018.
Watkins, D. S.: Fundamentals of Matrix Computations, 2nd edn., John Wiley & Sons, Inc., New York, NY, https://doi.org/10.1002/0471249718, 2002.
Ye, J., Lazar, N. A., and Li, Y.: Nonparametric variogram modeling with hole effect structure in analyzing the spatial characteristics of fMRI data, J. Neurosci. Methods, 240, 101–115, https://doi.org/10.1016/j.jneumeth.2014.11.008, 2015.
Yu, J., Hmiel, B., Lyon, D. R., Warren, J., Cusworth, D. H., Duren, R. M., Chen, Y., Murphy, E. C., and Brandt, A. R.: Methane Emissions from Natural Gas Gathering Pipelines in the Permian Basin, Environ. Sci. Technol. Lett., 9, 969–974, https://doi.org/10.1021/acs.estlett.2c00380, 2022.