the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 08 Jul 2020
| 08 Jul 2020
Exploration of machine learning methods for the classification of infrared limb spectra of polar stratospheric clouds
Lars Hoffmann
Reinhold Spang
Gabriele Cavallaro
Sabine Griessbach
Michael Höpfner
Matthias Book
Morris Riedel
Polar stratospheric clouds (PSCs) play a key role in polar ozone depletion in the stratosphere. Improved observations and continuous monitoring of PSCs can help to validate and improve chemistry–climate models that are used to predict the evolution of the polar ozone hole. In this paper, we explore the potential of applying machine learning (ML) methods to classify PSC observations of infrared limb sounders. Two datasets were considered in this study. The first dataset is a collection of infrared spectra captured in Northern Hemisphere winter 2006/2007 and Southern Hemisphere winter 2009 by the Michelson Interferometer for Passive Atmospheric Sounding (MIPAS) instrument on board the European Space Agency's (ESA) Envisat satellite. The second dataset is the cloud scenario database (CSDB) of simulated MIPAS spectra. We first performed an initial analysis to assess the basic characteristics of the CSDB and to decide which features to extract from it. Here, we focused on an approach using brightness temperature differences (BTDs). From both the measured and the simulated infrared spectra, more than 10 000 BTD features were generated. Next, we assessed the use of ML methods for the reduction of the dimensionality of this large feature space using principal component analysis (PCA) and kernel principal component analysis (KPCA) followed by a classification with the support vector machine (SVM). The random forest (RF) technique, which embeds the feature selection step, has also been used as a classifier. All methods were found to be suitable to retrieve information on the composition of PSCs. Of these, RF seems to be the most promising method, being less prone to overfitting and producing results that agree well with established results based on conventional classification methods.
- Article
(1597 KB) - Full-text XML
- BibTeX
- EndNote





Polar stratospheric clouds (PSCs) typically form in the polar winter stratosphere between 15 and 30 km of altitude. PSCs can be observed only at high latitudes, as they exist only at very low temperatures (T<195 K) found in the polar vortices. PSCs are known to play an important role in ozone depletion caused by heterogeneous reactions under cold conditions, while denitrification of the stratosphere extends the ozone destruction cycles into springtime, as the absence of NOy limits the deactivation process of the reactive ozone-destroying substances (Solomon, 1999; Salawitch et al., 1993). The presence of man-made chlorofluorocarbons (CFCs) in the stratosphere, which have been used for example in industrial compounds present in refrigerants, solvents, blowing agents for plastic foam, affects ozone depletion. CFCs are inert compounds in the troposphere but get transformed under stratospheric conditions to the chlorine reservoir gases HCl and ClONO2. PSC particles are involved in the release of chlorine from the reservoirs.
The main constituents of PSCs are three, i.e., nitric acid trihydrate (NAT), supercooled ternary solution (STS), and ice (Lowe and MacKenzie, 2008). Michelson Interferometer for Passive Atmospheric Sounding (MIPAS) measurements have been used to study PSC processes (Arnone et al., 2012; Khosrawi et al., 2018; Tritscher et al., 2019). The infrared spectra acquired by MIPAS are rather sensitive to optically thin clouds due to the limb observation geometry. This is particularly interesting for NAT and STS PSCs, as ice PSCs are in general optically thicker than NAT and STS (Fromm et al., 2003). As ice clouds form at a lower temperature than NAT and STS, they are mainly present in the Antarctic, while their presence in the Arctic (where the stratospheric temperature minimum in polar winter is higher) is only notable for extremely cold winter conditions (e.g., Campbell and Sassen, 2008; Pawson et al., 1995).
Besides using MIPAS measurements, classification has been carried out with different schemes based on the optical properties of PSCs by lidar measurements. A review of those methods is available in Achtert and Tesche (2014). Classification schemes are based on two features, namely the backscatter ratio and the depolarization ratio. As exposed in Biele et al. (2001), particles with large backscatter ratio and depolarization are likely to be composed of ice (type II). Type I particles are characterized by a low backscatter ratio. The subtype Ia particles show a large depolarization and are composed of NAT, whereas subtype Ib particles have low depolarization and consist of STS. The threshold to classify the PSC types varies among different works such as Browell et al. (1990), Toon et al. (1990), Adriani (2004), Pitts et al. (2009), and Pitts et al. (2011). The nomenclature presented above is a simplification of real case scenarios, since PSCs can occur also with mixtures of particles with different composition (Pitts et al., 2009). Other methods that are used to measure PSCs are in situ optical and nonoptical measurements from balloon or aircraft as well as microwave observations (Buontempo et al., 2009; Molleker et al., 2014; Voigt, 2000; Lambert et al., 2012).
The use of machine learning (ML) algorithms increased dramatically during the last decade. ML can offer valuable tools to deal with a variety of problems. In this paper, we used ML methods for two different tasks: first, for the selection of informative features from the simulated MIPAS spectra; second, to classify the MIPAS spectra depending on the composition of the PSC. In this work we significantly extended the application of ML methods for the analysis of MIPAS PSC observations. Standard methods that exploit infrared limb observation to classify PSCs are based on empirical approaches. Given physical knowledge of the properties of the PSC, some features have been extracted from the spectra, for example the ratio of the radiances between specific spectral windows. These approaches have been proven to be capable of detecting and discriminating between different PSC classes (Spang et al., 2004; Höpfner et al., 2006).
The purpose of this study is to explore the use of ML methods to improve the PSC classification for infrared limb satellite measurements and to potentially gain more knowledge on the impact of the different PSC classes on the spectra. We compare results from the most advanced empirical method, the Bayesian classifier of Spang et al. (2016), with three automatic approaches. The first one relies on principal component analysis (PCA) and kernel principal component analysis (KPCA) for feature extraction, followed by classification with the support vector machine (SVM). The second one is similar to the first, but uses kernel principal component analysis (KPCA) for feature extraction instead of PCA. The third one is based on the random forest (RF), a classifier that directly embeds a feature selection (Cortes and Vapnik, 1995; Breiman, 2001; Jolliffe and Cadima, 2016). A common problem of ML is the lack of annotated data. To overcome this limitation, we used a synthetic dataset for training and testing, the cloud scenario database (CSDB), especially developed for MIPAS cloud and PSC analyses (Spang et al., 2012). As a ground truth for PSC classification is largely missing, we evaluate the ML results by comparing them with results from existing methods and show that they are consistent with established scientific knowledge.
In Sect. 2, we introduce the MIPAS and synthetic CSDB datasets. A brief description of the ML methods used for feature reduction and classification is provided in Sect. 3. In Sect. 4, we compare results of PCA + SVM, KPCA + SVM, and RF for feature selection and classification. We present three case studies and statistical analyses for the 2006/2007 Arctic and 2009 Antarctic winter season. The final discussion and conclusions are given in Sect. 5.
2.1 MIPAS
The MIPAS instrument (Fischer et al., 2008) was an infrared limb emission spectrometer on board the European Space Agency's (ESA) Envisat satellite to study the thermal emission of the Earth's atmosphere constituents. Envisat operated from July 2002 to April 2012 in a polar low Earth orbit with a repeat cycle of 35 d. MIPAS measured up to 87∘ S and 89∘ N latitude and therefore provided nearly global coverage at day- and nighttime. The number of orbits of the satellite per day was equal to 14.3, resulting in a total of about 1000 limb scans per day.
The wavelength range covered by the MIPAS interferometer was about 4 to 15 µm. From the beginning of the mission to spring 2004, the instrument operated in the full resolution (FR) mode (0.025 cm−1 spectral sampling). Later on, this has to be changed to the optimized resolution (OR) mode (0.0625 cm−1) due to a technical problem of the interferometer (Raspollini et al., 2006, 2013). The FR measurements were taken with a constant 3 km vertical and 550 km horizontal spacing, while for the OR measurements the vertical sampling depended on altitude, varying from 1.5 to 4.5 km, and a horizontal spacing of 420 km was achieved. The altitude range of the FR and OR measurements varied from 5–70 km at the poles to 12–77 km at the Equator.
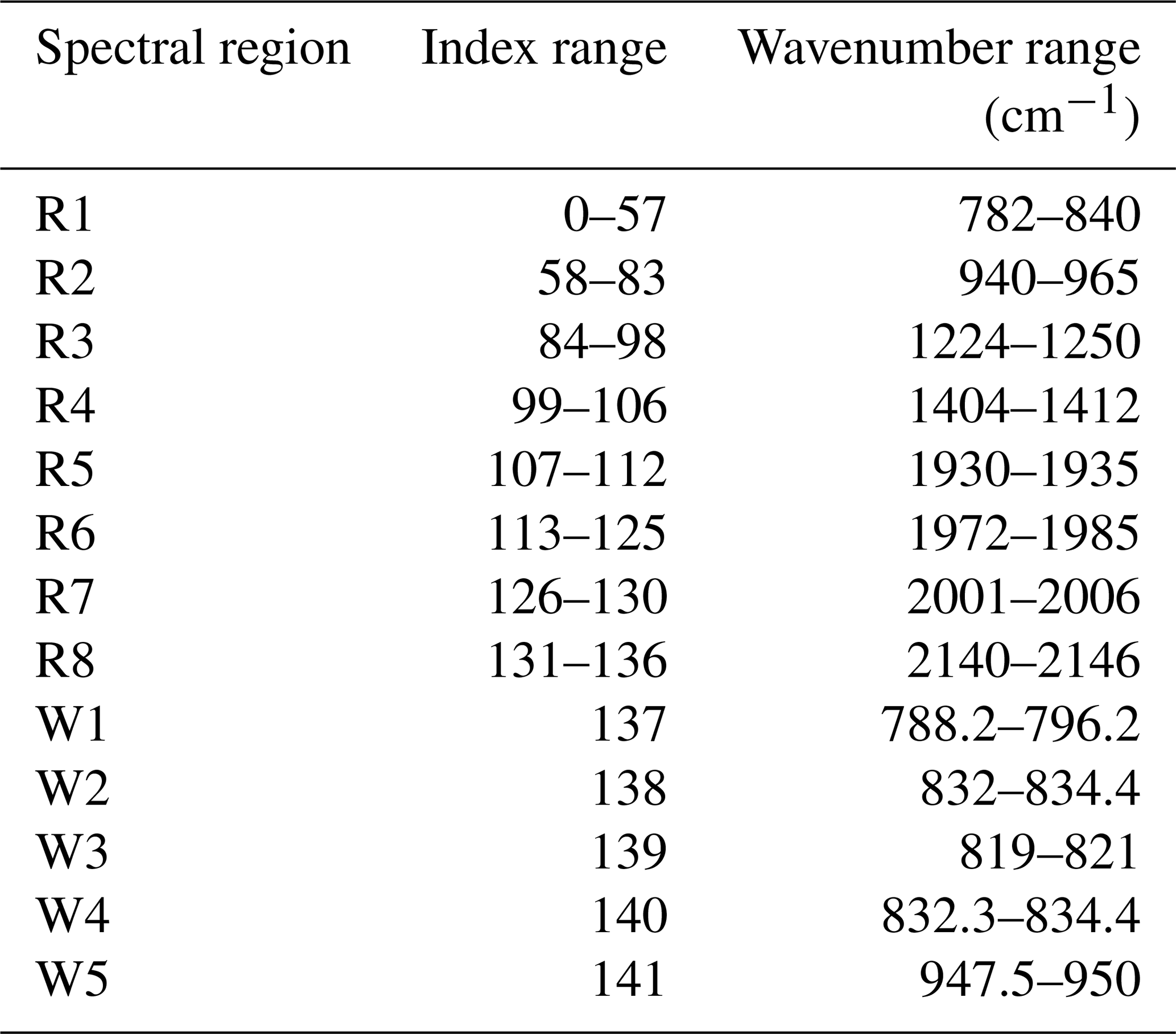
For our analyses, we used MIPAS Level 1B data (version 7.11) acquired at 15–30 km of altitude between May and September 2009 at 60–90∘ S and between November 2006 and February 2007 at 60–90∘ N. The 2009 Southern Hemisphere winter presents a slightly higher than average PSC activity, especially for ice in June and August. The 2006/2007 Northern Hemisphere winter is characterized by a large area covered by NAT, with an exception made for early January, and some ice is present in late December (this analysis was obtained from NASA Ozone Watch from their website at https://ozonewatch.gsfc.nasa.gov, last access: 20 April 2020). The high-resolution MIPAS spectra were averaged to obtain 136 spectral windows of 1 cm−1 width, because PSC particles are expected to typically cause only broader-scale features. The 1 cm−1 window data used in this study comprise the eight spectral regions reported in Table 1. In addition to these, five windows (W1–W5) larger than 1 cm−1 have been considered, as used in the study of Spang et al. (2016).
Table 1Infrared spectral regions considered for PSC classification.
From the 1 cm−1 windows and the five additional larger windows, more than 10 000 brightness temperature differences (BTDs) were extracted using a two-step preprocessing. At first, the infrared spectra were converted from radiance intensities to brightness temperatures (BTs). This approach is considered helpful, as variations in the signals are more linear in BT compared to radiances. Then, the BTDs were computed by subtracting the BT of each window with respect to the remaining ones. The main motivation for using BTDs rather than BTs for classification is to try to remove background signals from interfering instrument effects such as radiometric offsets.
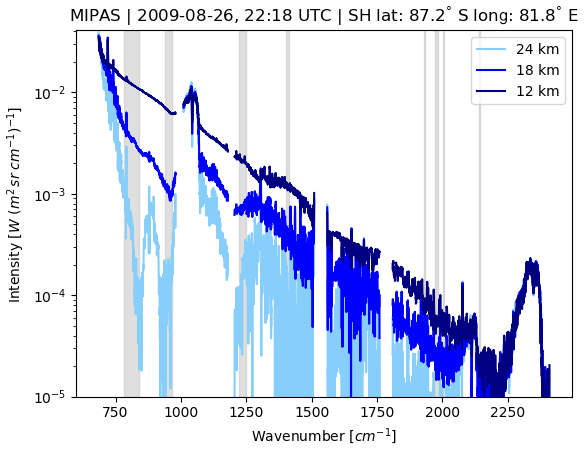
Figure 1MIPAS measurements in Southern Hemisphere polar winter at three tangent altitudes from the same profile showing clear-air (light blue), optically thin (blue), and optically thick (dark blue) conditions. The gray bars indicate the wavenumber regions considered for PSC classification in this study.
Other wavelength ranges covered by MIPAS have been excluded here as they are mainly sensitive to the presence of trace gases. The interference of cloud and trace gas emissions makes it more difficult to analyze the effects of the PSC particles (Spang et al., 2016). As an example, Fig. 1 shows MIPAS spectra of PSC observations acquired in late August 2009 in Southern Hemisphere polar winter conditions, with the spectral regions used for PSC detection and classification being highlighted.
2.2 Cloud scenario database
A synthetic dataset consisting of simulated radiances for the MIPAS instrument provides the training and testing data for this study. The CSDB was generated by considering more than 70 000 different cloud scenarios (Spang et al., 2012). The CSDB spectra were generated using the Karlsruhe Optimized and Precise Radiative Transfer Algorithm (KOPRA) model (Stiller et al., 1998). Limb spectra were simulated from 12 to 30 km tangent height, with 1 km vertical spacing. Cloud top heights were varied between 12.5 and 28.5 km, with 0.5 km vertical spacing. The cloud vertical extent varies between 0.5, 1, 2, 4, and 8 km. The spectral features selected from the CSDB are the same as those for MIPAS (Sect. 2.1, Fig. 1).
Table 2PSC constituents, particle concentrations, and sizes covered by the CSDB.
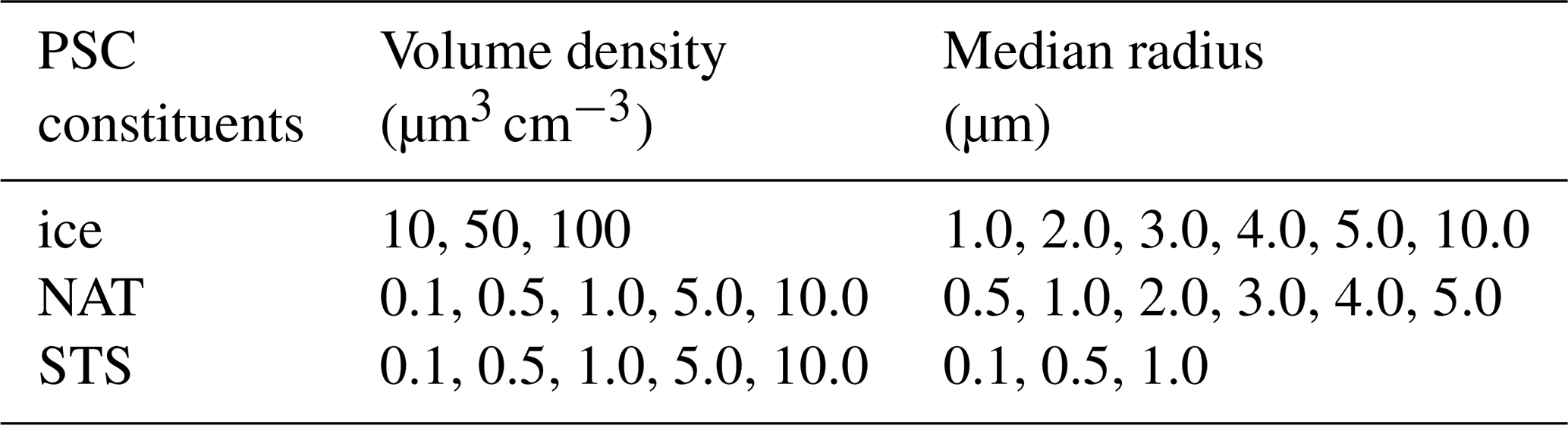

Figure 2Intercomparison of ML and Bayesian classifiers for Southern Hemisphere winter (May to September 2009). Ticks on the x axis represent the classes of the BC. The y axis indicates the fraction of the classes as predicted by the KPCA + SVM (a), PCA + SVM classifier (b), and the RF classifier (c). N is the number of samples belonging to each class of the Bayesian classifier.
As described in Spang et al. (2016), the CSDB was calculated with typical particle radii and volume densities of PSCs (Table 2). Five different PSC compositions have been considered: ice; NAT; STS with 2 % H2SO4, 48 % HNO3, and 50 % H2O (called later on STS 1); STS with 25 % H2SO4, 25 % HNO3, and 50 % H2O (STS 2); and STS with 48 % H2SO4, 2 % HNO3, and 50 % H2O (STS 3). These values are derived from the model by Carslaw et al. (1995) and span over all possible compositions. The CSDB does not give any representative frequency of real occurrences in the atmosphere. For this study, we decided to split the set of NAT spectra into two classes, large NAT (radius>2 µm) and small NAT (). This decision was taken to assess the capability of the classifiers to correctly separate between the two classes. It is well known that small NAT particles () produce a specific spectral signature at 820 cm−1 (Spang and Remedios, 2003; Höpfner et al., 2006). Spectra for large NAT particles are more prone to overlap with those of ice and STS.
To prepare both the real MIPAS and the CSDB data for PSC classification, we applied the cloud index (CI) method of Spang et al. (2004) with a threshold of 4.5 to filter out clear-air spectra. In optimal conditions a CI<6 detects clouds with extinction coefficients down to about in the midinfrared (Sembhi et al., 2012). However, in the polar winter regions these optimal conditions do not persist over an entire winter season. Hence, we selected a threshold of 4.5 that reliably discriminates clear air from cloudy air in the Southern and Northern Hemisphere polar winter regions as it is sensitive to extinctions down to (Griessbach et al., 2020).
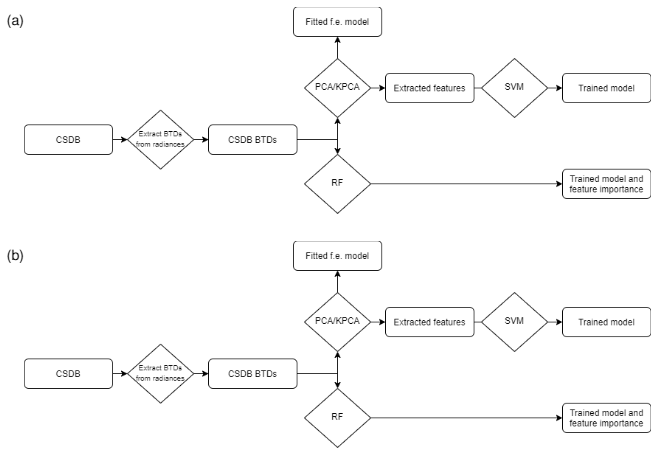
Figure 3(a) Flowchart of the training process and (b) prediction. “F.e.” stands for feature extraction.
3.1 Conventional classification methods
Spang et al. (2016) provide an overview on various conventional methods used to classify Envisat MIPAS PSC observations. Furthermore, a Bayesian approach has been introduced in their study to combine the results of individual classification methods. This approach is used as a benchmark for the new classifiers introduced in the present paper. The Bayesian classifier considers a total of 13 features, including correlations between the cloud index (CI) (Spang et al., 2004), the NAT index (NI) (Spang and Remedios, 2003; Höpfner et al., 2006), and another five additional BTDs. Each feature has been assigned individual probabilities pi,j in order to discriminate between the different PSC composition classes. The output of the Bayesian classifier is calculated according to , where the indices i=1, …, 13 and j=1, 2, 3 refer to the individual feature and the PSC constituent, respectively. The normalized probabilities Pj per PSC constituent are used for final classification applying the maximum a posteriori principle. The BC composition classes are the following: unknown, ice, NAT, STS_mix, ICE_NAT, NAT_STS, and ICE_STS. A stepwise decision criterion is applied to classify each spectrum. If the maximum of Pj (with j=1…3) is greater than 50 %, then the spectrum is assigned a single PSC composition label. If two Pj values are between 40 % and 50 %, then a mixed composition class, for example ICE_STS for j=1 and j=3, is attributed. If the classification results in P1, P2, or P3 <40 %, then the spectrum is labeled as “unknown”. Considering the Southern Hemisphere 2009 case, the NAT_STS mixed composition class is populated with more than 4000 spectra, while ICE_STS and ICE_NAT predictions are negligible (Fig. 2). The analysis of the complete MIPAS period (9 Southern Hemisphere and 10 Northern Hemisphere winters in Spang et al., 2018) showed that ICE_STS and ICE_NAT classes are generally only in the subpercentage range and statistically not relevant. The Bayesian classifier requires a priori information and detailed expert knowledge on the selection of the features to be used as discriminators and in assigning the individual probabilities pi,j for classification. In this work, we aim at investigating automatic ML approaches instead of the manual or empirical methods applied for the Bayesian classifier. Nevertheless, being carefully designed and evaluated, the results of the Bayesian classifier are used for further reference and comparison in this study.
3.2 Feature extraction using PCA and KPCA
In a first step, we calculated BTDs from the 1 cm−1 downsampled radiances of the CSDB. Calculating the BTDs between the 142 spectral windows resulted in 10 011 BTDs for a total of 70 000 spectra. In a second step, in order to reduce the number of data, we applied a variance threshold to exclude BTD features with relatively low variance (σ2<10 K2), as this indicates that the corresponding windows have rather similar information content. In order to further reduce the difficulties and complexity of the classification task, we decided to even further reduce the number of BTD features before training of the classifiers by means of feature extraction.

Figure 4 Variance of normalized BTDs (a) and feature importance as estimated by the RF classifier (b). The BT index numbers on the x and y axis correspond to the spectral regions as listed in Table 1.
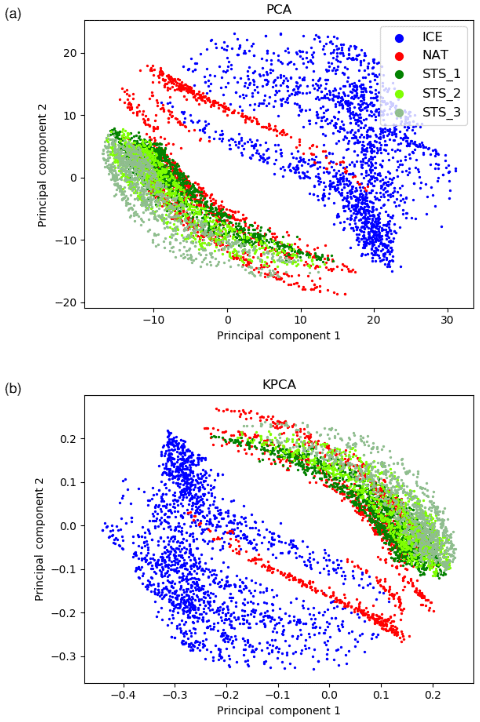
Figure 5Correlations of the first two principal components from the PCA (a) and KPCA (b) analysis applied to the CSDB.
Feature selection methods are used for picking subsets of an entire set of features while keeping the information content as high as possible. The methods help to reduce the training time of the classifier and to reduce the risk of overfitting. Feature selection methods typically belong to three main families (Bolón-Canedo et al., 2016): (i) filter methods, where the importance of the feature is derived from intrinsic characteristics of it; (ii) wrapper methods, where the features are selected by optimizing the performances of a classifier; and (iii) embedded methods, where classification and selection happen at the same time. Here, we used a more advanced approach to dimensionality reduction, which goes under the name of feature extraction. In this case, instead of simply selecting a subset of the original features, the set of features itself is transformed to another space where the selection takes place.
Principal component analysis (PCA) is among the most popular feature extraction methods (Jolliffe and Cadima, 2016). The main idea of the PCA is to reproject the data to a space where the features are ranked on the variance that they account for. At first a centering of the data through the subtraction of the mean is performed. Then, the covariance matrix is calculated and its eigenvectors and eigenvalues are computed. At this point, selecting the eigenvectors whose eigenvalues are largest, it is possible to pick the components on which most of the variance of the data lays. PCA already found applications in the analysis of atmospheric midinfrared spectra, in particular for the compression of high-resolution spectra and for accelerating radiative transfer calculations (e.g., Huang and Antonelli, 2001; Dudhia et al., 2002; Fauvel et al., 2009; Estornell et al., 2013). PCA has been used in this study for two main purposes, dimensionality reduction and visualization of the data.
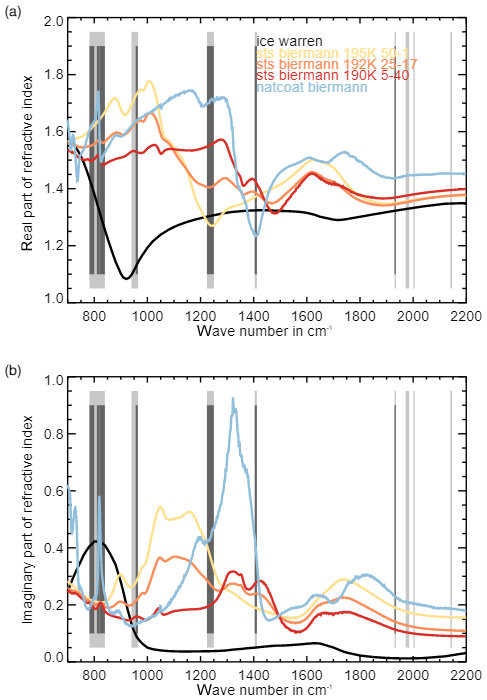
Figure 6Real (a) and imaginary (b) part of PSC particle refractive indices. The gray bars represent the eight spectral regions considered in this study.
Kernel PCA (KPCA) is an extension of the PCA where the original data x are first transformed using a mapping function ϕ(x) to a higher dimensional feature space. The main advantage of using KPCA relies in the fact that it can capture nonlinear patterns, which PCA, being a linear method, may fail to represent well. However the construction of the kernel matrix K for mapping can be expensive in terms of memory. This latter problem undermines severely the possibility of using this algorithm for large datasets. At this point the kernel trick comes into play (Schölkopf et al., 1997). It helps to avoid the inconvenience of having to compute the covariance matrix in a large transformed space. Instead of translating each data point to the transformed feature space using the mapping function ϕ(x), the inner product can be calculated as , resulting in a much less demanding computational task. Among the most common kernels are the radial basis function (RBF) and the polynomial (Genton, 2002), which we also considered in this study.
3.3 Classification using support vector machines and random forests
Supervised classification is a ML task in which the classes or labels of unknown samples are predicted by making use of a large dataset of samples with already known labels. In order to do that, the classification algorithm first has to be trained; i.e., it has to learn a map from the input data to its target values. After a classifier is trained, one can give it as input an unlabeled set of data points with the aim of predicting the labels. The training of a classifier is usually a computationally demanding task. However, the classification of unknown samples using an already trained classifier is computationally cheap.
A large number of classifiers exist based on rather different concepts. Bayesian classifiers follow a statistical approach. Support vector machines (SVMs) are based on geometrical properties. Random forests (RF) are based on the construction of multiple decision trees. Neural networks try to emulate the behavior of the human brain by stacking a number of layers composed of artificial neurons (Zeiler and Fergus, 2014). According to the “no free lunch” theorem, it is not possible to state safely which algorithm is expected to perform best for any problem (Wolpert, 1996). In this study, we selected two well-established methods, RFs and SVMs, to test their performance.
Random forest is an algorithm that learns a classification model by building a set of decision trees. A decision tree is composed of decision nodes, which lead to further branches and leaf nodes, which finally represent classification results. RFs are nonparametric models that do not assume any underlying distribution in the data (Breiman, 2001). RF builds a number of decision trees selecting a random subset of the original features for each tree. In this way the model becomes more robust against overfitting. The classification result of the RF model will be the label of the class that has been voted for by the majority of decision trees (Liu et al., 2012). An interesting characteristic of the RF classifier is that it can give by calculating the Gini index (Ceriani and Verme, 2012) also a measure of the feature importance. In this way, the RF classifier can also be exploited for performing feature selection.
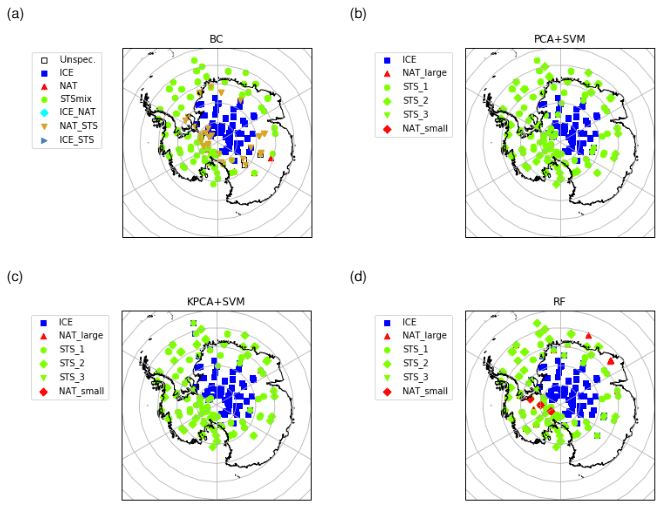
Figure 8MIPAS observations of PSCs on 14 June 2009 in the Southern Hemisphere at tangent altitudes between 18 and 22 km. The classification was performed with (a) the Bayesian classifier, (b) the SVM based on PCA features, (c) the SVM based on KPCA features, and (d) the RF classifier.
The performance of a RF classification model depends on a number of hyperparameters, which must be defined before training. (i) The “number of estimators” or decision trees of the forest needs to be defined. (ii) A random subset of the features is selected by each decision tree to split a node. The dimension of the subset is controlled by the hyperparameter “maximum number of features”. (iii) The “maximum depth”, i.e., the maximum number of levels in each decision tree, controls the complexity of the decision trees. In fact, the deeper a decision tree is, the more splits can take place in it. (iv) The “minimum number of samples before split” that has to be present in a node before it can be split also needs to be defined. (v) A node without a further split has to contain a “minimum number of samples per leaf” to exist. (vi) Finally, we have to decide whether to use “bootstrapping” or not. Bootstrapping is a method used to select a subset of the available data points, introducing further randomness to increase robustness (Probst et al., 2019).
SVMs became popular around the 1990s (Cortes and Vapnik, 1995). The method is based on the idea of identifying hyperplanes, which best separate sets of data points into two classes. In particular, SVM aims at maximizing the margin, which is the distance between few points of the data, referred to as “support vectors”, and the hyperplane that separates the two classes. The “soft margin” optimization technique takes into account the fact that misclassification can occur due to outliers. For that reason a tuning parameter C is included in order to allow for the presence of misclassified samples during the optimization of the margin to a given extent. The choice of the parameter C is a trade-off between minimizing the error on the training data and finding a hyperplane that may generalize better (Brereton and Lloyd, 2010).
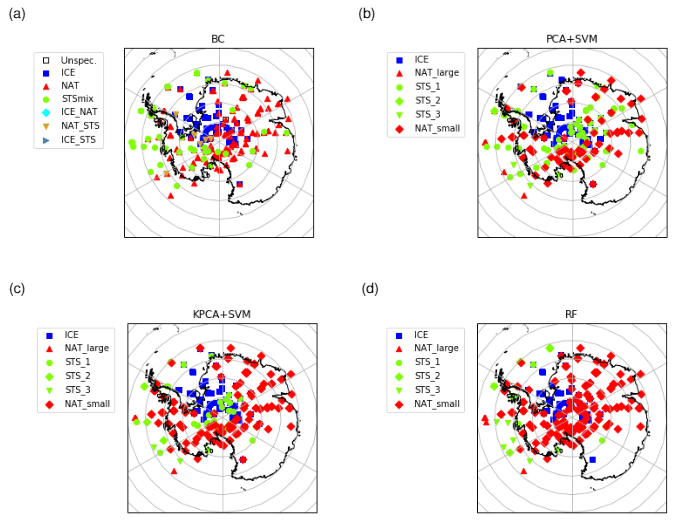
Figure 9Same as Fig. 8 but for 26 August 2009.
SVM had been originally developed to find linear decision boundaries. However, the introduction of the kernel trick (cf., Sect. 3.2) enables the possibility for nonlinear decision boundaries. Kernel functions, e.g., radial basis functions or polynomials, are mapping from the original space to a nonlinearly transformed space, where the linear SVM is applied (Patle and Chouhan, 2013). In the case of a nonlinear kernel, the parameter γ is used to define how much a support vector has influence on deciding the class of a sample. A small value of γ implies that this support vector also has impact on samples far in the feature space, and a large value of γ has an influence only on samples that are close in the feature space.
We recap in Fig. 3 the entire pipeline for training and prediction. The BTDs extracted from the CSDB dataset are given as input to the PCA or KPCA methods, and the extracted features are fed to the SVM classifier for model training (PCA + SVM and KPCA + SVM). On the other hand, the RF classifier is given as input BTDs directly, without prior feature extraction. The input samples (BTDs) are annotated with a label as explained in Sect. 2.2. In prediction (Fig. 3b), the BTDs extracted from the MIPAS measurements are the input to the three methods PCA + SVM, KPCA + SVM, and RF, where the outputs are the predicted label for each sample. The RF classifier provides a feature importance measure as well. During prediction, the sample is assigned to one of the following classes representing the main constituent: ice, small NAT, large NAT, STS 1, STS 2, and STS 3. Compared to the NAT class of the Bayesian classifier, in the proposed ML methods NAT particles are assigned to small and large NAT subclasses. The STS_mix class of the BC overlaps with STS 1, STS 2, and STS 3. There are no directly corresponding classes to the mixed composition ones of the BC. As discussed above in the text, only a few spectra are classified by the BC as ICE_STS or ICE_NAT. Samples belonging to the NAT_STS class of the BC, characterized by a non-negligible population, are labeled by the new ML classes mostly as STS 1 (Fig. 2).
4.1 Feature extraction
In this study, we applied PCA and KPCA for feature extraction from a large set of BTDs. Both PCA and KPCA are reprojecting the original BTD features to a new space, where the eigenvectors are ordered in such a way that they maximize variance contributions of the data. Figure 4a shows a matrix of the normalized variances of the individual BTDs considered here. The matrices in Fig. 4 are symmetric; thus the reader can either focus on the location (i.e., the indices of the BTs from which the BTD feature has been computed) of the maximum values in the upper or lower triangular part. A closer inspection shows that the largest variances originate from BTDs in the range from 820 to 840 cm−1 (indicated as spectral region R1 in Table 1) and 956 to 964 cm−1 (R2). BTDs close to 790 cm−1 (R1, BT index ∼ 10) also show high variance. Another region with high variances originates from BTDs between 820 and 840 cm−1 (part of R1) and between 1404 and 1412 cm−1 (R4) as well as between 1930 and 1935 cm−1 (R5). Around 820, 1408, and 1930 cm−1 the imaginary part (absorption contribution) of the complex refractive index of NAT has pronounced features (Höpfner et al., 2006), whereas around 960 cm−1 the real part (scattering contribution) of the complex refractive index of ice has a pronounced minimum (e.g., Griessbach et al., 2016). Even though in our work the ML classifiers are given BTDs (computed from radiance) as input and refractive indices are not directly used in the classification process, the latter can provide insights on microphysical properties of the different PSC particles and additional information on the features used by the ML methods.
The first and second principal components, which capture most of the variance in the data, are shown in Fig. 5. Comparing PCA and KPCA, we note that they mostly differ in terms of order and amplitude. This means that the eigenvalues change, but the eigenvectors are rather similar in the linear and nonlinear case. For this dataset, the nonlinear KPCA method (using a polynomial kernel) does not seem to be very sensitive to nonlinear patterns that are hidden to the linear PCA method. However, it should be noted that the SVM classifier is sensitive to differences in scaling of the input features as they result from the use of PCA and KPCA for feature selection. Therefore, classification results of PCA + SVM and KPCA + SVM can still be expected to differ and are tested separately.
As discussed in Sect. 3.3, RF itself is considered to be an effective tool not only for classification but also for feature selection. It is capable of finding nonlinear decision boundaries to separate between the classes. However, the method does not group the features together in components like PCA or KPCA. It is rather delivering a measure of importance of all of the individual features. Figure 4b shows the feature importance matrix provided by the RF. Note that the values are normalized; i.e., the feature importance values of the upper triangular matrix sum up to 1. We can observe that this approach highlights clusters similar to Fig. 4a.
Table 3Top ten list of BTDs providing maximum feature importance as estimated by the RF classifier.
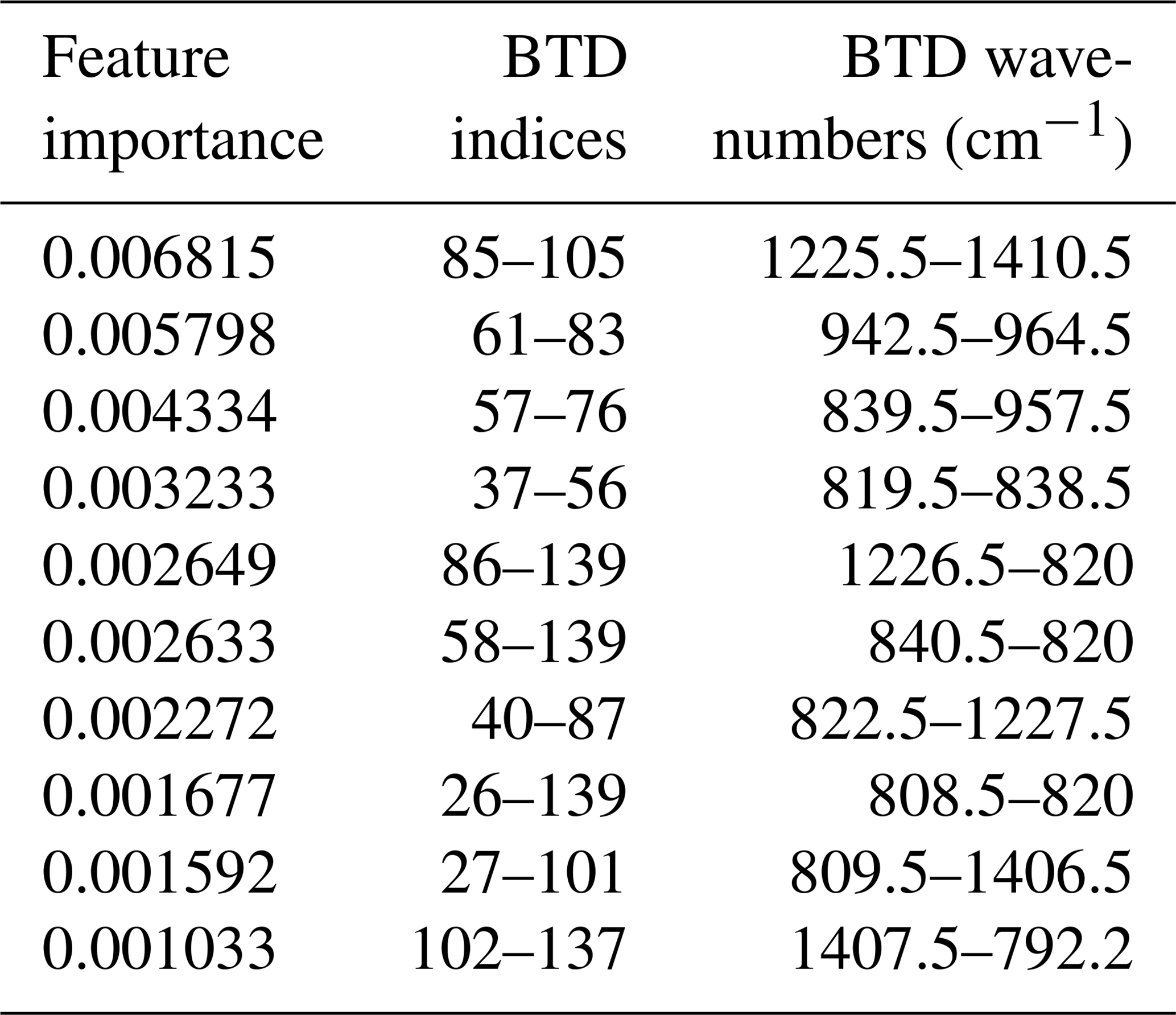
Similarly to PCA and KPCA, BTDs between windows in the range from 820 to 840 cm−1 (R1) and from 956 to 964 cm−1 (R2) are considered to be important by the RF algorithm. BTDs between 1224 and 1250 cm−1 (R3) and between 1404 and 1412 cm−1 (R4) are also regarded as important. The importance of the RF features located in this cluster is in contrast with the relatively low BTD variance in the same area. A similar observation can be done regarding BTDs between 782 and 800 cm−1 and between 810 and 820 cm−1 (both belonging to R1). This region is in the range of values of the NAT feature, providing a possible explanation of the capability of the RF to detect the characteristic peak of small NAT as well as its shift with the increase in the radius. BTDs between 960 cm−1 (R2) and 1404 to 1412 cm−1 (R4) are also quite important. Table 3 specifically provides the most important BTDs between the different regions. Actually, Fig. 6 shows that all the windows or BTDs found here by the RF are associated with physical features of the PSC spectra, namely a peak in the real and imaginary part of the complex refractive index of NAT around 820 cm−1 or a minimum in the real part of the complex refractive index of ice around 960 cm−1. STS can be identified based on the absence of these features. Considering the larger windows W, the matrices of the variance and of the RF feature importance seem to agree, with the exception of W3 (∼820 cm−1) that is regarded as important by the RF scheme but is not characterized by high variance, confirming the capability of the RF for detecting the NAT feature.
A closer inspection reveals an interesting difference between PCA and KPCA on the one hand and RF on the other hand. Two additionally identified windows around ∼790 (BT index ∼10) and ∼1235 cm−1 (BT index ∼90) are located at features in the imaginary part of the refractive index of ice and NAT, respectively (Höpfner et al., 2006). This latter set of BTDs is considered to have a large feature importance by the RF method but does not show a particularly large variance. This suggests that a supervised method like RF can capture important features where unsupervised methods like PCA and KPCA may fail.
4.2 Hyperparameter tuning and cross-validation accuracy
Concerning classification, we compared two SVM-based classifiers that take as input the features from PCA and KPCA and the RF that uses the BTD features without prior feature selection. The first step in applying the classifiers is training and tuning of the hyperparameters. Cross validation is a standard method to find optimal hyperparameters and to validate a ML model (Kohavi, 1995). For cross validation the dataset is split into a number of subsets, called folds. The model is trained on all the folds, except for one, which is used for testing. This procedure is repeated until the model has been tested on all the folds. The cross-validation accuracy refers to the mean error of the classification results for the testing datasets. Cross validation is considered essential to avoid overfitting while training a ML model. Selecting the best hyperparameters that maximize the cross-validation accuracy of a ML model is of great importance to exploit the models' capabilities at a maximum.
Table 4Hyperparameter choices considered for the SVM classifier.

Table 5Hyperparameter choices considered for the RF classifier.

In this study, we applied 5-fold cross validation on the CSDB dataset. For the SVM models we decided to utilize a grid-search approach to find the hyperparameters. As the parameter space of the RF model is much larger, a random-search approach was adopted (Bergstra and Bengio, 2012). The test values and optimum values of the hyperparameters for the SVM and RF classifiers are reported in Tables 4 and 5, respectively. For the optimum hyperparameter values, all classification methods provided an overall prediction accuracy close to 99 %. Also, our tests showed that the ML methods considered here for the PSC classification problem are rather robust against changes in the hyperparameters.
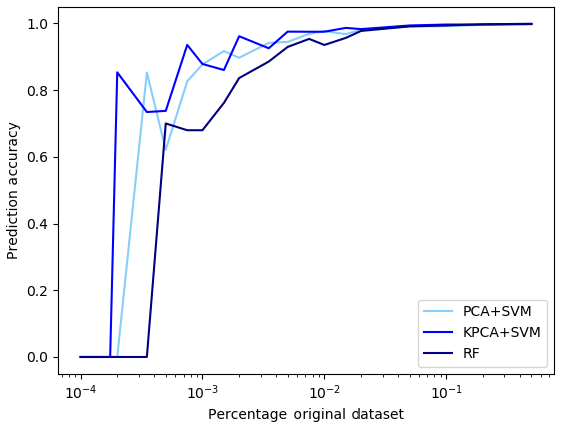
During the training of the classifiers, we conducted two experiments. In the first experiment, we checked how large the amount of synthetic samples from the CSDB needs to be in order to obtain good cross-validation accuracy. For this experiment, we performed the training with subsets of the original CSDB data, using randomly sampled fractions of 50 %, 20 %, 10 %, 5 %, 2 %, 1 %, 0.05 %, 0.02 %, 0.01 %, 0.005 %, 0.002 %, and 0.001 % of the full dataset. This experiment was run for all three ML models (PCA + SVM, KPCA + SVM, and RF) using the optimal hyperparameters found during the cross-validation step. The results in Fig. 7 show that using even substantially smaller datasets (>0.02 % of the original data or about 1200 samples) would still result in acceptable prediction accuracy (>80 %). This result is surprising and points to a potential limitation of the CSDB for the purpose of training ML models that will be discussed in more detail in Sect. 5.
Table 6Scores of the RF classifier on a small subset of CSDB samples.
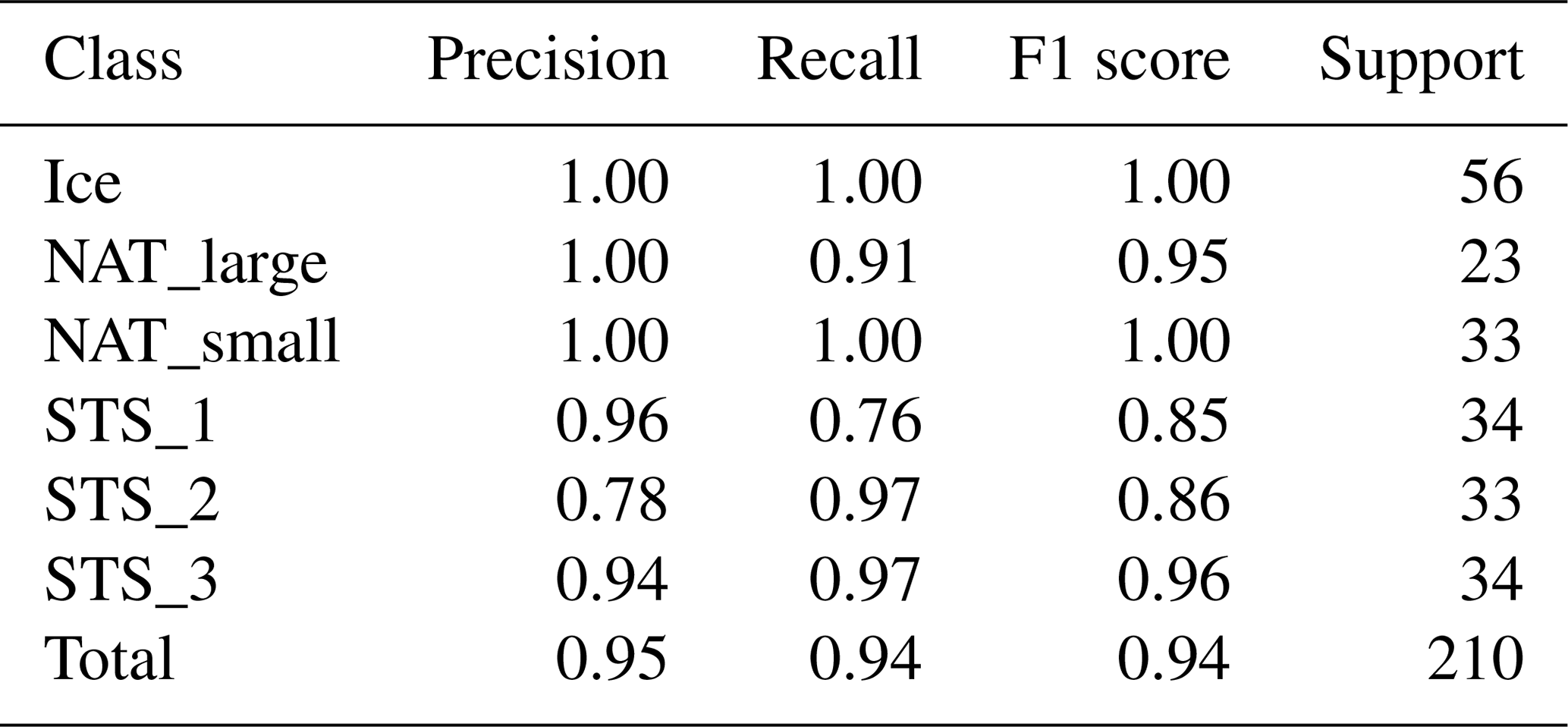
In the second experiment, we intentionally performed and analyzed the training and testing of the RF method with a rather small subset of data. Although the results from this procedure are less robust, they can help pinpoint potential issues that cannot be detected using the full dataset. We computed different scores to assess the quality of the prediction for the RF classifier in the case of 600 randomly selected samples used for training and around 200 samples used for testing. As shown in Table 6, also using a limited number of samples for training leads to very high classification accuracy. The metrics used in Table 6 are precision , recall , and F1 score , where TP is the number of true positives, FP the number of false positives, FN the number of false negatives, and support is the number of samples (Tharwat, 2018). As reported in Table 6, it is found that ice and small NAT accuracies are higher than the ones of STS. This is a hint to the fact that distinguishing small NAT and ice from the other classes is an easier task than separating spectra of PSCs containing larger NAT particles from those populated with STS, which is consistent with previous studies (Höpfner et al., 2009).
Table 7Predicted labels vs. CSDB classes, with analysis restricted to NAT large (radius >2 µm).

An additional experiment was performed on the CSDB spectra labeled as large NAT. The BC misclassifies a large amount of those spectra (99 % of them classified as STS_mix), whereas the proposed ML methods correctly classify them as large NAT (Table 7). This experiment suggests that the new classification schemes can help in overcoming the inability of the BC in discriminating between large NAT and STS.
4.3 Classification using real MIPAS data
4.3.1 Case studies
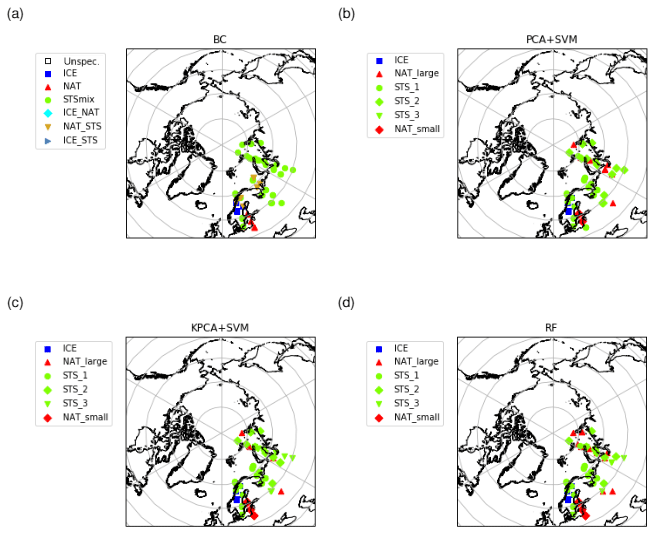
Figure 10Same as Fig. 8 but for 25 January 2007 and the Northern Hemisphere.
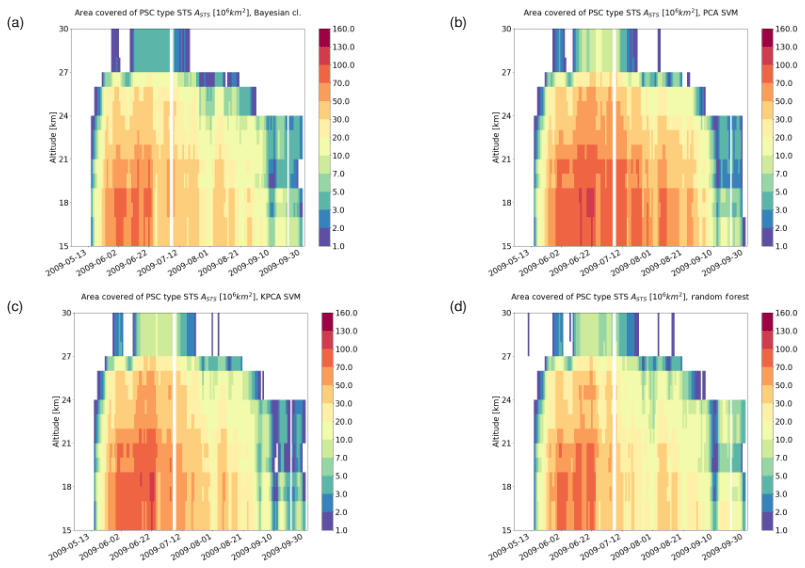
Figure 11Area covered by STS clouds from May to September 2009 in the Southern Hemisphere based on results of (a) the Bayesian classifier, (b) the PCA + SVM classifier, (c) the KPCA + SVM classifier, and (d) the RF classifier. The bins span a length of 1 d in time and 1 km in altitude. A horizontal (3 d) and vertical (3 km) moving average has been applied for the sake of a smoother representation.
For three case studies looking at individual days of MIPAS observations, two in the Southern Hemisphere and one in the Northern Hemisphere winter season, we compared the results of the different classification methods (Figs. 8 to 10). Early in the Southern Hemisphere PSC season, on 14 June 2009 (Fig. 8), we found that the classification results are mostly coherent among all the classifiers, not only from a quantitative point of view but also geographically, especially concerning the separation of ice and STS PSCs. Further, we found that most of the PSCs, which were labeled as NAT by the Bayesian classifier, were classified as STS by the ML classification methods. While both SVM classification schemes did not indicate the presence of NAT, the RF found some NAT, but mostly at different places than the Bayesian classifier. Note that from a climatological point of view, NAT PSCs are not expected to be the dominant PSC type until the middle to end of June for the Southern Hemisphere (Pitts et al., 2018).
Later in the Southern Hemisphere PSC season, on 26 August 2009 (Fig. 9), it is again found that the separation between ice and nonice PSCs is largely consistent for all the classifiers. The NAT predictions by the RF classifier tend to agree better with the Bayesian classifier than the NAT classifications by the SVM method. Overall, the Southern Hemisphere case studies seem to suggest that the SVM classifiers (using PCA or KPCA) underestimate the presence of NAT PSCs compared to the BC and the RF classifiers. We note that separating the NAT and STS classes from limb infrared spectra presents some difficulties.
As a third case study, we analyzed classification results for 25 January 2007 for the Northern Hemisphere (Fig. 10). This case was already analyzed to some extent by Hoffmann et al. (2017). It is considered to be particularly interesting, as ice PSCs have been detected over Scandinavia at synoptic-scale temperatures well above the frost point. Hoffmann et al. (2017) provided evidence that the PSC formation in this case was triggered by orographic gravity waves over the Scandinavian Mountains. Also in this case study the classification of ice PSCs over Scandinavia shows a good agreement for the new ML methods with the Bayesian classifier. Further, we see that the two SVM and the RF methods identified small NAT where the Bayesian classifier also found NAT. However, at the locations where the Bayesian classifier indicates a mixture of NAT and STS, the ML methods indicate STS, and the ML methods indicate large NAT at locations where the Bayesian classifier found STS.
4.3.2 Seasonal analyses
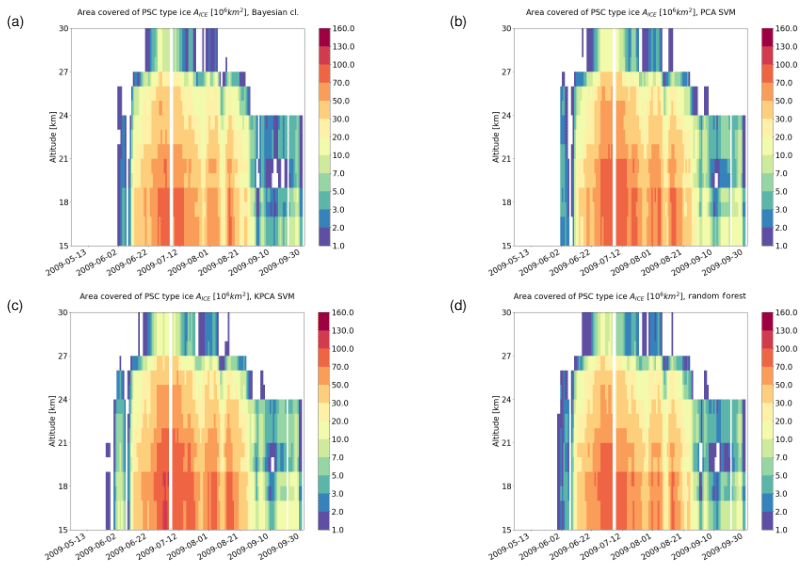
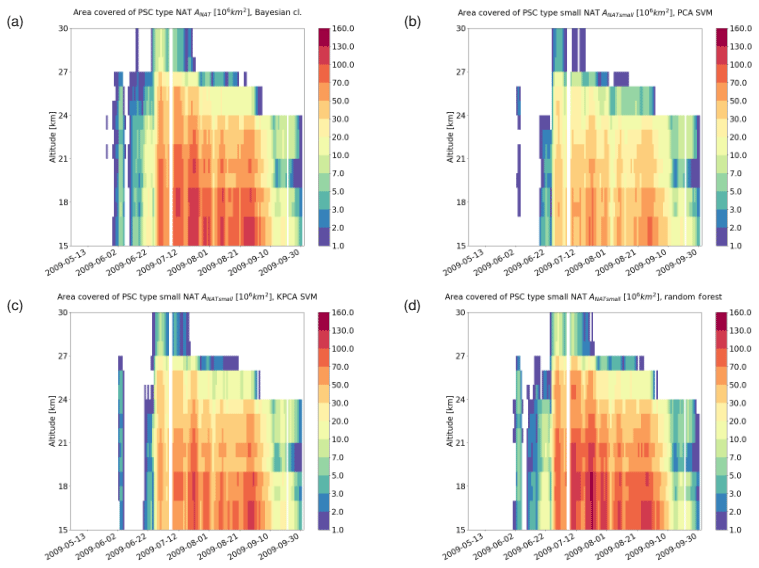
For a seasonal analysis, we first considered MIPAS observations during the months from May to September 2009. Figures 11 to 13 show the area coverage for each class of PSC along time and altitude. Comparing the time series of the classification results, we can assess the agreement quantitatively. The mixed composition classes of the Bayesian classifier (NAT_STS, ICE_STS, and ICE_NAT) are not considered in this analysis. Taking a look at STS (Fig. 11), all the classifiers predict an early season appearance. While the RF predicts a time series that resembles quite closely the one predicted by the Bayesian classifier, the other two ML methods (PCA + SVM and KPCA + SVM) predict a significantly larger coverage of STS clouds over the winter. Regarding the ice PSCs (Fig. 12), the patterns in the time series are similar between all classifiers. However, we can observe that, even if the spatiotemporal characteristics are similar, both SVM methods predict a notably larger area covered by ice clouds. Moreover, the KPCA + SVM classifier predicts an earlier emergence of ice with respect to the other classifiers. Considering the NAT time series (Fig. 13), all the classifiers predict a late appearance during the season. The classification schemes based on SVM predict a much lower presence of NAT with respect to the RF and the Bayesian classifier. Furthermore, most of the bins with a high value of NAT coverage in the Bayesian classification scheme are predicted as small NAT particles. This result confirms that the spectral features of small NAT are strong enough to find a good decision boundary, as explained in Sect. 2.2.
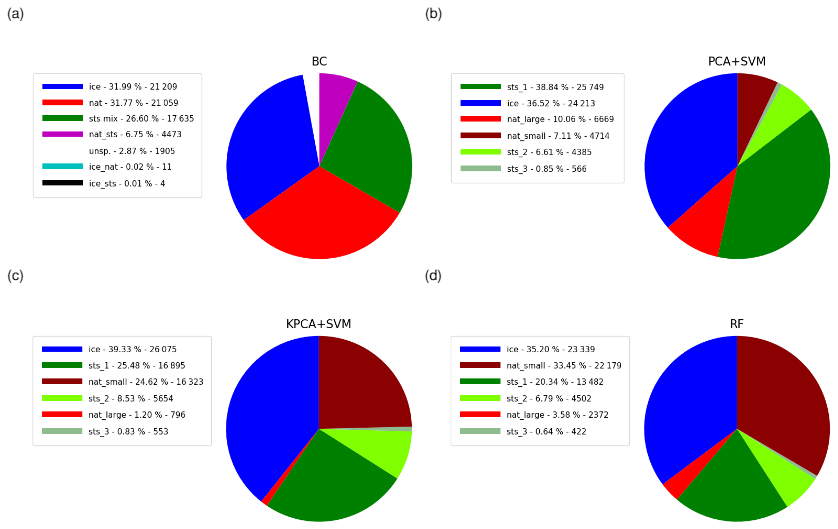
Figure 14Partitioning of the PSC composition classes for the Southern Hemisphere winter (May to September 2009) derived by (a) the Bayesian classifier, (b) the PCA + SVM classifier, (c) the KPCA + SVM classifier, and (d) the RF classifier. Percentage values and number of events are reported in the legends.
Figure 14 shows the overall percentages of the PSC classes for May to September 2009 for the Southern Hemisphere. The occurrence frequencies of ice PSCs are quite consistent, ranging from 32 % for the Bayesian classifier to 39 % for KPCA + SVM. It is found that the approaches based on SVM slightly overestimate the presence of ice with respect to the RF (35 %) and the Bayesian classifier. However, the main differences that were encountered are in the separation between STS and NAT. The two classification schemes using SVM predict a much smaller amount of NAT PSCs (17 and 26 % taking small and large NAT together) compared to the RF (33 % considering only small NAT, 37 % taking small and large NAT together) and the Bayesian classifier (32 % NAT). The RF and the Bayesian classifier are more coherent between themselves. Other interesting findings are related to the classification between small and large NAT. Indeed, the vast majority of the NAT predictions in the KPCA + SVM and RF methods belong to the small NAT class. PCA + SVM diverges significantly from the other methods, largely underestimating small NAT and overestimating large NAT. This suggests once more that the discrimination between small NAT and STS PSCs is more easily possible using midinfrared spectra for classification, while larger NAT PSCs are harder to separate.
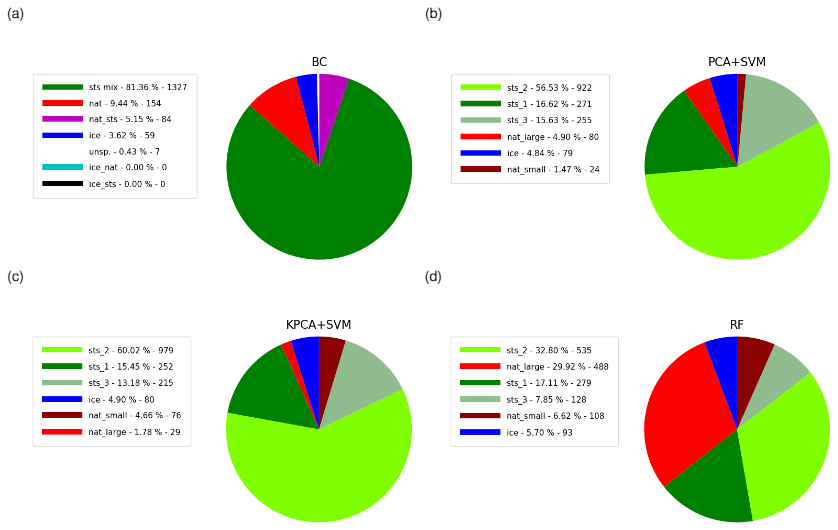
Figure 15Same as Fig. 14 but for November 2006 to February 2007 for the Northern Hemisphere.
In addition to the results presented above, we conducted the seasonal analyses also for MIPAS observations acquired in the months from November 2006 to February 2007 in the Northern Hemisphere (Fig. 15). As expected, a much smaller fraction of ice PSCs (4–6 %) was found compared to the Southern Hemisphere. As in the Southern Hemisphere winter, the SVM classifiers taking as input the PCA and KPCA features found significantly less NAT (both 6 %) than the Bayesian classifier (15 %), whereas the RF classifier identified a significantly larger fraction of large NAT spectra (30 %) that resulted in a significantly higher NAT detection rate (37 %). This finding may point to a potential improvement of the RF classifier compared to the Bayesian classifier. In fact, it had been already reported by Spang et al. (2016) that the Bayesian classifier for MIPAS underestimated the fraction of NAT clouds compared to Cloud-Aerosol Lidar with Orthogonal Polarization (CALIOP) observations. Further, the STS partitioning between the three STS subclasses is different between the Southern and Northern Hemisphere winters. While in the Southern Hemisphere STS 1 is dominant, in the Northern Hemisphere STS 2 is dominant and the fraction of STS 3 is significantly increased. This result is plausible, because the Northern Hemisphere winters are warmer than the Southern Hemisphere winters, and STS 1 forms at lower temperatures (e.g., ∼189 K) than STS 2 (∼192 K) and STS 3 (∼195 K at 50 hPa, Carslaw et al., 1995).
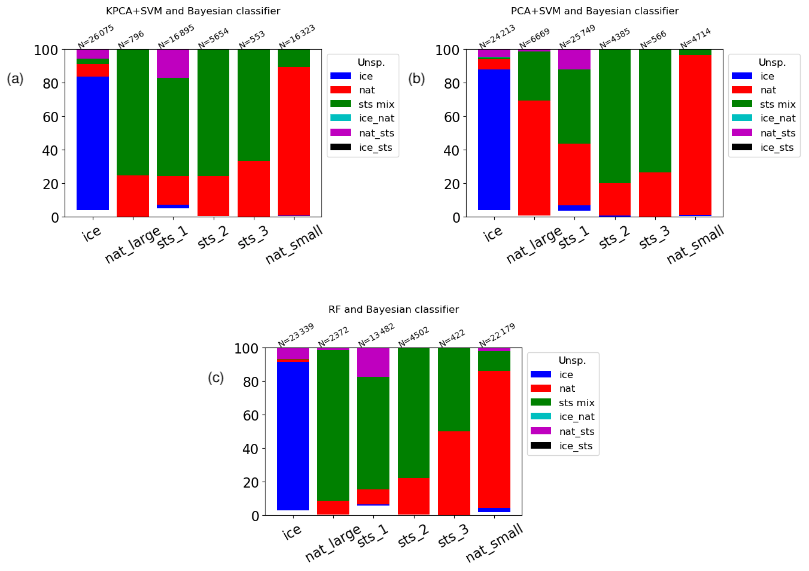
Figure 16Intercomparison of ML and Bayesian classifiers for Southern Hemisphere winter (May to September 2009). Ticks on the x axis represent the classes of the KPCA + SVM classifier (a), the PCA + SVM classifier (b), and the RF classifier (c). The y axis indicates the fraction of the classes as predicted by the Bayesian classifier. N is the number of samples belonging to each class of the ML classifiers.
Figures 16 and 2 show cross tabulations between the classification results of the Bayesian classifier and the three ML methods. They allow us to directly assess how much the different classification schemes agree in terms of their predictions for the different classes. For instance, considering the ice class of the PCA + SVM and KPCA + SVM classifiers, it can be seen that around 80 % of the samples were classified consistently with the Bayesian method, while this percentage is above 90 % for the RF (Fig. 16). Concerning NAT, the RF classifier predicts as small NAT more than 80 % of what had been classified as NAT class by the Bayesian classifier (Fig. 2). The PCA + SVM and KPCA + SVM methods predict a smaller fraction of small NAT for the NAT class of the Bayesian classifier, around 30 % and 70 %, respectively. The PCA + SVM in particular predicts a significantly smaller amount of samples belonging to the small NAT class than the other methods (Fig. 16), while it predicts a larger number of samples of the STS subclasses. This result may suggest that PCA + SVM and KPCA + SVM are not as sensitive as BC for small NAT detection, while RF is. Considering the STS subclasses of the RF and KPCA + SVM classifiers altogether, they seem to mostly agree with the STS_mix predictions of the Bayesian classifier. On the other hand, the total number of samples predicted by the PCA + SVM scheme as belonging to the STS subclasses is notably larger than the predictions of the Bayesian classifier (Fig. 16). This finding is in line with what has been discussed a few lines above and in Sect. 4.3.2. There is a large percentage of spectra predicted as large NAT by the proposed ML methods that are instead classified as STS by the BC, especially in the results of the RF scheme. This is probably caused by the fact that the BC misclassifies spectra of large NAT, as discussed in Sect. 4.2 for the CSDB.
In this study, we investigated whether ML methods can be applied for the PSC classification of infrared limb spectra. We compared the classification results obtained by three different ML methods – PCA + SVM, KPCA + SVM, and RF – with those of the Bayesian classifier introduced by Spang et al. (2016). First, we discussed PCA, KPCA, and RF as methods for feature extraction from midinfrared spectral regions and showed that the selected features correspond with distinct features in the complex refractive indices of NAT and ice PSCs. Then we compared classification results obtained by the ML methods with respect to previous work using conventional classification methods combined with a Bayesian approach.
We presented three case studies as well as seasonal analyses for the validation and comparison of the classification results. Based on the case studies, we showed that there is spatial agreement of the ML method predictions between ice and nonice PSCs. However, there is some disagreement between NAT and STS. We evaluated time series and pie charts of cloud coverage for the Southern Hemisphere polar winter 2009 and the Northern Hemisphere polar winter 2006/2007, showing that all methods are highly consistent with respect to the classification of ice. For the NAT and STS predictions, RF and the Bayesian classifier tend to agree best, whereas the SVM methods yielded larger differences. The agreement between the different classification schemes was further quantified by means of cross tabulation. While the SVM methods found significantly less NAT than the Bayesian classifier, the RF classifier found slightly more NAT than the Bayesian classifier. The RF results might be more realistic, because the Bayesian classifier is known to find less NAT for MIPAS compared to CALIOP satellite observations, especially for Northern Hemisphere winter conditions (Spang et al., 2016). A practical advantage of RF, presented in Sect. 3.3 and further discussed in Sect. 4.1, is that it enables a better control on the importance of the features it selects to train the model. Moreover, RF is a fully supervised method, from feature selection to training, whereas the feature extraction methods PCA and KPCA are unsupervised methods and may fail to capture important features if they do not show high variance. From the user point of view, RF is also simpler to deploy since it embeds feature selection and does not require a two-step process of feature extraction and training (unlike PCA + SVM and KPCA + SVM). Parallel implementations of the ML methods presented in this paper are also available, enabling significant acceleration of model training and prediction with a large number of data (Cavallaro et al., 2015; Genuer et al., 2017).
The Bayesian method developed by Spang et al. (2016) requires a priori knowledge of a domain expert to select the decision boundaries and to tune the probabilities used for classification for different areas in the feature space. The ML schemes proposed in this work are more objective in the premises and rely only on the available training data without additional assumptions. Models have been trained on the CSDB, a simulation dataset that has been created systematically sampling the parameter space, not reflecting the natural occurrence frequencies of parameters. This point is in our opinion of great importance, as we demonstrated that ML methods are capable of predicting PSC composition classes without the need of substantial prior knowledge, providing a means for consistency checking of subjective assessments. Although the lack of ground truth narrows the assessment down to comparison with other classification schemes, we found that the classification results of the ML methods are consistent with spectral features of the PSC particles, in particular, the features found in the real and imaginary part of their refractive indices. Another important benefit of the proposed ML methods is that they have shown the potential of extending the prediction to NAT particles with large radius, which was not possible with the BC scheme. This aspect has been successfully tested on the synthetic CSDB dataset and might be a promising path for future research.
However, there are still some limitations to the proposed ML approach. First, the feature selection methods found the highest variance and feature importance at spectral windows where ice and NAT have pronounced features in the complex refractive indices, whereas the main features of STS are located at wavenumbers not covered by the CSDB. Since the classification of STS is therefore based on the absence of features in the optical properties and for the large NAT particles the features in the optical properties vanish as well, the discrimination between STS and large NAT is more complicated than the identification of ice. Hence, we suppose that the inclusion of more spectral windows, especially regions where the optical properties of STS have features, may bear the potential to improve the separation between STS and NAT. Second, we showed that using a much smaller subset of the original CSDB for training of the ML methods would have been sufficient to achieve similar classification results. This suggests that the information provided by the CSDB is largely redundant, at least in terms of training of the ML methods. Despite the fact that the CSDB contains many training spectra, it was calculated only for a limited number of PSC volume densities, particle sizes, and cloud layer heights and depths as well as fixed atmospheric background conditions. It could be helpful to test the ML methods using a training dataset providing better coverage of the micro- and macrophysical parameter space and more variability in the atmospheric background conditions. Third, in the CSDB and the ML classification schemes we assumed only pure constituent (ice, NAT, STS 1, STS 2, and STS 3) PSCs, whereas in the atmosphere mixed clouds are frequently observed (e.g., Deshler et al., 2003; Pitts et al., 2018). In future work, mixed PSCs should be included, as an investigation of mixed PSCs could be beneficial to assess how far the ML methods applied to limb infrared spectra agree with predictions from CALIOP measurements that already comprise mixed-type scenarios.
In general, the presented classification methods are straightforward to adopt on spectrally resolved measurements of other infrared limb sensors like the Cryogenic Infrared Spectrometers and Telescopes for the Atmosphere (CRISTA) (Offermann et al., 1999) or the GLObal limb Radiance Imager for the Atmosphere (GLORIA) (Riese et al., 2005, 2014; Ungermann et al., 2010) space- or airborne instruments. It could be of interest to extend the methods to combine different observational datasets, even with different types of sensors providing different spectral and geometrical properties of their acquisitions. This study has assessed the potential of ML methods in predicting PSC composition classes, which may be a starting point for new classification schemes for different aerosol types in the upper troposphere and lower stratosphere region (Sembhi et al., 2012; Griessbach et al., 2014, 2016), helping to answer open questions about the role of these particles in the atmospheric radiation budget.
The MIPAS Level 1B IPF version 7.11 data can be accessed via ESA's Earth Online portal at https://earth.esa.int/web/guest/-/mipas-localized-calibrated-emission-spectra-1541 (ESA, 2019). The CSDB database can be obtained by contacting Michael Höpfner, Karlsruhe. The software repository containing the ML codes developed for this study is available at https://gitlab.com/rocco.sedona/psc_mipas_classification (Sedona, 2020).
GC, LH, and ReS developed the concept for this study. RoS developed the software and conducted the formal analysis of the results. SG, MH, and ReS provided expertise on the MIPAS measurements. MH prepared and provided the CSDB. GC and MR provided expertise on the ML methods. RoS wrote the manuscript with contributions from all coauthors.
The authors declare that they have no conflict of interest.
We thank the European Space Agency (ESA) for making the Envisat MIPAS data available. We found the scikit-learn software package (https://scikit-learn.org/, last access: 10 December 2019) of great importance for the development of the code for this study.
The article processing charges for this open-access publication were covered by a Research Centre of the Helmholtz Association.
This paper was edited by Christian von Savigny and reviewed by two anonymous referees.
Achtert, P. and Tesche, M.: Assessing lidar-based classification schemes for polar stratospheric clouds based on 16 years of measurements at Esrange, Sweden, J. Geophys. Res.-Atmos., 119, 1386–1405, https://doi.org/10.1002/2013jd020355, 2014. a
Adriani, A.: Climatology of polar stratospheric clouds based on lidar observations from 1993 to 2001 over McMurdo Station, Antarctica, J. Geophys. Res., 109, D24, https://doi.org/10.1029/2004jd004800, 2004. a
Arnone, E., Castelli, E., Papandrea, E., Carlotti, M., and Dinelli, B. M.: Extreme ozone depletion in the 2010–2011 Arctic winter stratosphere as observed by MIPAS/ENVISAT using a 2-D tomographic approach, Atmos. Chem. Phys., 12, 9149–9165, https://doi.org/10.5194/acp-12-9149-2012, 2012. a
Bergstra, J. and Bengio, Y.: Random search for hyper-parameter optimization, J. Mach. Learn. Res., 13, 281–305, 2012. a
Biele, J., Tsias, A., Luo, B. P., Carslaw, K. S., Neuber, R., Beyerle, G., and Peter, T.: Nonequilibrium coexistence of solid and liquid particles in Arctic stratospheric clouds, J. Geophys. Res.-Atmos., 106, 22991–23007, https://doi.org/10.1029/2001jd900188, 2001. a
Bolón-Canedo, V., Sánchez-Maroño, N., and Alonso-Betanzos, A.: Feature selection for high-dimensional data, Progress in Artificial Intelligence, Springer-Verlag, Berlin, Heidelberg, https://doi.org/10.1007/s13748-015-0080-y, 2016. a
Breiman, L.: Machine Learning, 45, 5–32, https://doi.org/10.1023/a:1010933404324, 2001. a, b
Brereton, R. G. and Lloyd, G. R.: Support Vector Machines for classification and regression, The Analyst, 135, 230–267, https://doi.org/10.1039/b918972f, 2010. a
Browell, E. V., Butler, C. F., Ismail, S., Robinette, P. A., Carter, A. F., Higdon, N. S., Toon, O. B., Schoeberl, M. R., and Tuck, A. F.: Airborne lidar observations in the wintertime Arctic stratosphere: Polar stratospheric clouds, Geophys. Res. Lett., 17, 385–388, https://doi.org/10.1029/gl017i004p00385, 1990. a
Buontempo, C., Cairo, F., Di Donfrancesco, G., Morbidini, R., Viterbini, M., and Adriani, A.: Optical measurements of atmospheric particles from airborne platforms: In situ and remote sensing instruments for balloons and aircrafts, Ann. Geophys., 49, 57–64, https://doi.org/10.4401/ag-3149, 2009. a
Campbell, J. R. and Sassen, K.: Polar stratospheric clouds at the South Pole from 5 years of continuous lidar data: Macrophysical, optical, and thermodynamic properties, J. Geophys. Res., 113, D20204, https://doi.org/10.1029/2007jd009680, 2008. a
Carslaw, K. S., Luo, B., and Peter, T.: An analytic expression for the composition of aqueous HNO3-H2SO4 stratospheric aerosols including gas phase removal of HNO3, Geophys. Res. Lett., 22, 1877–1880, https://doi.org/10.1029/95gl01668, 1995. a, b
Cavallaro, G., Riedel, M., Richerzhagen, M., Benediktsson, J. A., and Plaza, A.: On Understanding Big Data Impacts in Remotely Sensed Image Classification Using Support Vector Machine Methods, IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens., 8, 4634–4646, 2015. a
Ceriani, L. and Verme, P.: The origins of the Gini index: extracts from Variabilità e Mutabilità (1912) by Corrado Gini, J. Econ. Inequal., 10, 421–443, https://doi.org/10.1007/s10888-011-9188-x, 2012. a
Cortes, C. and Vapnik, V.: Support-Vector Networks, Mach. Learn., 20, 273–297, https://doi.org/10.1023/A:1022627411411, 1995. a, b
Deshler, T., Larsen, N., Weissner, C., Schreiner, J., Mauersberger, K., Cairo, F., Adriani, A., Di Donfrancesco, G., Ovarlez, J., Ovarlez, H., Blum, U., Fricke, K. H., and Dornbrack, A.: Large nitric acid particles at the top of an Arctic stratospheric cloud, J. Geophys. Res., 108, 4517, https://doi.org/10.1029/2003JD003479, 2003. a
Dudhia, A., Morris, P. E., and Wells, R. J.: Fast monochromatic radiative transfer calculations for limb sounding, J. Quant. Spectrosc. Ra. T., 74, 745–756, 2002. a
ESA: MIPAS geo-located and calibrated atmospheric spectra (ENVISAT.MIP.NL_1P), available at: https://earth.esa.int/web/guest/-/mipas-localized-calibrated-emission-spectra-1541 last access: 10 December 2019. a
Estornell, J., Martí-Gavliá, J. M., Sebastiá, M. T., and Mengual, J.: Principal component analysis applied to remote sensing, Model. Sci. Educ. Learn., 6, 83–89, https://doi.org/10.4995/msel.2013.1905, 2013. a
Fauvel, M., Chanussot, J., and Benediktsson, J. A.: Kernel principal component analysis for the classification of hyperspectral remote sensing data over urban areas, Eurasip J. Adv. Sign. Process., 2009, 783194, https://doi.org/10.1155/2009/783194, 2009. a
Fischer, H., Birk, M., Blom, C., Carli, B., Carlotti, M., von Clarmann, T., Delbouille, L., Dudhia, A., Ehhalt, D., Endemann, M., Flaud, J. M., Gessner, R., Kleinert, A., Koopman, R., Langen, J., López-Puertas, M., Mosner, P., Nett, H., Oelhaf, H., Perron, G., Remedios, J., Ridolfi, M., Stiller, G., and Zander, R.: MIPAS: an instrument for atmospheric and climate research, Atmos. Chem. Phys., 8, 2151–2188, https://doi.org/10.5194/acp-8-2151-2008, 2008. a
Fromm, M., Alfred, J., and Pitts, M.: A unified, long-term, high-latitude stratospheric aerosol and cloud database using SAM II, SAGE II, and POAM II/III data: Algorithm description, database definition, and climatology, J. Geophys. Res., 108, 4366, https://doi.org/10.1029/2002jd002772, 2003. a
Genton, M.: Classes of kernels for machine learning: a statistics perspective, J. Mach. Learn. Res., 2, 299–312, 2002. a
Genuer, R., Poggi, J.-M., Tuleau-Malot, C., and Villa-Vialaneix, N.: Random Forests for Big Data, Big Data Res., 9, 28–46, https://doi.org/10.1016/j.bdr.2017.07.003, 2017. a
Griessbach, S., Hoffmann, L., Spang, R., and Riese, M.: Volcanic ash detection with infrared limb sounding: MIPAS observations and radiative transfer simulations, Atmos. Meas. Tech., 7, 1487–1507, https://doi.org/10.5194/amt-7-1487-2014, 2014. a
Griessbach, S., Hoffmann, L., Spang, R., von Hobe, M., Müller, R., and Riese, M.: Infrared limb emission measurements of aerosol in the troposphere and stratosphere, Atmos. Meas. Tech., 9, 4399–4423, https://doi.org/10.5194/amt-9-4399-2016, 2016. a, b
Griessbach, S., Hoffmann, L., Spang, R., Achtert, P., von Hobe, M., Mateshvili, N., Müller, R., Riese, M., Rolf, C., Seifert, P., and Vernier, J.-P.: Aerosol and cloud top height information of Envisat MIPAS measurements, Atmos. Meas. Tech., 13, 1243–1271, https://doi.org/10.5194/amt-13-1243-2020, 2020. a
Hoffmann, L., Spang, R., Orr, A., Alexander, M. J., Holt, L. A., and Stein, O.: A decadal satellite record of gravity wave activity in the lower stratosphere to study polar stratospheric cloud formation, Atmos. Chem. Phys., 17, 2901–2920, https://doi.org/10.5194/acp-17-2901-2017, 2017. a, b
Höpfner, M., Larsen, N., Spang, R., Luo, B. P., Ma, J., Svendsen, S. H., Eckermann, S. D., Knudsen, B., Massoli, P., Cairo, F., Stiller, G., v. Clarmann, T., and Fischer, H.: MIPAS detects Antarctic stratospheric belt of NAT PSCs caused by mountain waves, Atmos. Chem. Phys., 6, 1221–1230, https://doi.org/10.5194/acp-6-1221-2006, 2006. a
Höpfner, M., Luo, B. P., Massoli, P., Cairo, F., Spang, R., Snels, M., Di Donfrancesco, G., Stiller, G., von Clarmann, T., Fischer, H., and Biermann, U.: Spectroscopic evidence for NAT, STS, and ice in MIPAS infrared limb emission measurements of polar stratospheric clouds, Atmos. Chem. Phys., 6, 1201–1219, https://doi.org/10.5194/acp-6-1201-2006, 2006. a, b, c, d
Höpfner, M., Pitts, M. C., and Poole, L. R.: Comparison between CALIPSO and MIPAS observations of polar stratospheric clouds, J. Geophys. Res., 114, D00H05, https://doi.org/10.1029/2009JD012114, 2009. a
Huang, H.-L. and Antonelli, P.: Application of Principal Component Analysis to High-Resolution Infrared Measurement Compression and Retrieval, J. Appl. Meteorol., 40, 365–388, https://doi.org/10.1175/1520-0450(2001)040<0365:AOPCAT>2.0.CO;2, 2001. a
Jolliffe, I. T. and Cadima, J.: Principal component analysis: a review and recent developments, Philos. Trans. Roy. Soc. A-Math., 374, 20150 202, https://doi.org/10.1098/rsta.2015.0202, 2016. a, b
Khosrawi, F., Kirner, O., Stiller, G., Höpfner, M., Santee, M. L., Kellmann, S., and Braesicke, P.: Comparison of ECHAM5/MESSy Atmospheric Chemistry (EMAC) simulations of the Arctic winter 2009/2010 and 2010/2011 with Envisat/MIPAS and Aura/MLS observations, Atmos. Chem. Phys., 18, 8873–8892, https://doi.org/10.5194/acp-18-8873-2018, 2018. a
Kohavi, R.: A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection, International Joint Conference of Artificial Intelligence, 14, 1137–1145, 1995. a
Lambert, A., Santee, M. L., Wu, D. L., and Chae, J. H.: A-train CALIOP and MLS observations of early winter Antarctic polar stratospheric clouds and nitric acid in 2008, Atmos. Chem. Phys., 12, 2899–2931, https://doi.org/10.5194/acp-12-2899-2012, 2012. a
Liu, Y., Wang, Y., and Zhang, J.: New Machine Learning Algorithm: Random Forest, in: Information Computing and Applications, pp. 246–252, Springer, Berlin, Heidelberg, https://doi.org/10.1007/978-3-642-34062-8_32, 2012. a
Lowe, D. and MacKenzie, A. R.: Polar stratospheric cloud microphysics and chemistry, J. Atm. Sol.-Terr. Phys., 70, 13–40, https://doi.org/10.1016/j.jastp.2007.09.011, 2008. a
Molleker, S., Borrmann, S., Schlager, H., Luo, B., Frey, W., Klingebiel, M., Weigel, R., Ebert, M., Mitev, V., Matthey, R., Woiwode, W., Oelhaf, H., Dörnbrack, A., Stratmann, G., Grooß, J.-U., Günther, G., Vogel, B., Müller, R., Krämer, M., Meyer, J., and Cairo, F.: Microphysical properties of synoptic-scale polar stratospheric clouds: in situ measurements of unexpectedly large HNO3-containing particles in the Arctic vortex, Atmos. Chem. Phys., 14, 10785–10801, https://doi.org/10.5194/acp-14-10785-2014, 2014. a
Offermann, D., Grossmann, K.-U., Barthol, P., Knieling, P., Riese, M., and Trant, R.: Cryogenic Infrared Spectrometers and Telescopes for the Atmosphere (CRISTA) experiment and middle atmosphere variability, J. Geophys. Res., 104, 16311–16325, 1999. a
Patle, A. and Chouhan, D. S.: SVM kernel functions for classification, in: 2013 International Conference on Advances in Technology and Engineering (ICATE), Mumbai, pp. 1–9, IEEE, https://doi.org/10.1109/icadte.2013.6524743, 2013. a
Pawson, S., Naujokat, B., and Labitzke, K.: On the polar stratospheric cloud formation potential of the northern stratosphere, J. Geophys. Res., 100, 23215, https://doi.org/10.1029/95jd01918, 1995. a
Pitts, M. C., Poole, L. R., and Thomason, L. W.: CALIPSO polar stratospheric cloud observations: second-generation detection algorithm and composition discrimination, Atmos. Chem. Phys., 9, 7577–7589, https://doi.org/10.5194/acp-9-7577-2009, 2009. a, b
Pitts, M. C., Poole, L. R., Dörnbrack, A., and Thomason, L. W.: The 2009–2010 Arctic polar stratospheric cloud season: a CALIPSO perspective, Atmos. Chem. Phys., 11, 2161–2177, https://doi.org/10.5194/acp-11-2161-2011, 2011. a
Pitts, M. C., Poole, L. R., and Gonzalez, R.: Polar stratospheric cloud climatology based on CALIPSO spaceborne lidar measurements from 2006 to 2017, Atmos. Chem. Phys., 18, 10881–10913, https://doi.org/10.5194/acp-18-10881-2018, 2018. a, b
Probst, P., Wright, M. N., and Boulesteix, A.-L.: Hyperparameters and tuning strategies for random forest, WIRES Data Mining Knowledge Discovery, 9, e1301, https://doi.org/10.1002/widm.1301, 2019. a
Raspollini, P., Belotti, C., Burgess, A., Carli, B., Carlotti, M., Ceccherini, S., Dinelli, B. M., Dudhia, A., Flaud, J.-M., Funke, B., Höpfner, M., López-Puertas, M., Payne, V., Piccolo, C., Remedios, J. J., Ridolfi, M., and Spang, R.: MIPAS level 2 operational analysis, Atmos. Chem. Phys., 6, 5605–5630, https://doi.org/10.5194/acp-6-5605-2006, 2006. a
Raspollini, P., Carli, B., Carlotti, M., Ceccherini, S., Dehn, A., Dinelli, B. M., Dudhia, A., Flaud, J.-M., López-Puertas, M., Niro, F., Remedios, J. J., Ridolfi, M., Sembhi, H., Sgheri, L., and von Clarmann, T.: Ten years of MIPAS measurements with ESA Level 2 processor V6 – Part 1: Retrieval algorithm and diagnostics of the products, Atmos. Meas. Tech., 6, 2419–2439, https://doi.org/10.5194/amt-6-2419-2013, 2013. a
Riese, M., Friedl-Vallon, F., Spang, R., Preusse, P., Schiller, C., Hoffmann, L., Konopka, P., Oelhaf, H., von Clarmann, T., and Höpfner, M.: GLObal limb Radiance Imager for the Atmosphere (GLORIA): Scientific objectives, Adv. Space Res., 36, 989–995, 2005. a
Riese, M., Oelhaf, H., Preusse, P., Blank, J., Ern, M., Friedl-Vallon, F., Fischer, H., Guggenmoser, T., Höpfner, M., Hoor, P., Kaufmann, M., Orphal, J., Plöger, F., Spang, R., Suminska-Ebersoldt, O., Ungermann, J., Vogel, B., and Woiwode, W.: Gimballed Limb Observer for Radiance Imaging of the Atmosphere (GLORIA) scientific objectives, Atmos. Meas. Tech., 7, 1915–1928, https://doi.org/10.5194/amt-7-1915-2014, 2014. a
Salawitch, R., Wofsy, S., Gottlieb, E., Lait, L., Newman, P., Schoeberl, M., Loewenstein, M., Podolske, J., Strahan, S., Proffitt, M., Webster, C., May, R., Fahey, D., Baumgardner, D., Dye, J., Wilson, J., Kelly, K., Elkins, J., Chan, K., and Anderson, J.: Chemical Loss of Ozone in the Arctic Polar Vortex in the Winter of 1991–1992, Science, 261, 1146–1149, https://doi.org/10.1126/science.261.5125.1146, 1993. a
Schölkopf, B., Smola, A., and Müller, K. R.: Kernel principal component analysis, in: Artificial Neural Networks – ICANN'97, edited by: Gerstner, W., Germond, A., Hasler, M., Nicoud, J. D., ICANN 1997, Lecture Notes in Computer Science, vol. 1327, Springer, Berlin, Heidelberg, pp. 583–588, https://doi.org/10.1007/BFb0020217, 1997. a
Sedona, R.: PSC MIPAS classification, available at: https://gitlab.com/rocco.sedona/psc_mipas_classification, last access: 19 May 2020. a
Sembhi, H., Remedios, J., Trent, T., Moore, D. P., Spang, R., Massie, S., and Vernier, J.-P.: MIPAS detection of cloud and aerosol particle occurrence in the UTLS with comparison to HIRDLS and CALIOP, Atmos. Meas. Tech., 5, 2537–2553, https://doi.org/10.5194/amt-5-2537-2012, 2012. a, b
Solomon, S.: Stratospheric ozone depletion: A review of concepts and history, Rev. Geophys., 37, 275–316, https://doi.org/10.1029/1999RG900008, 1999. a
Spang, R. and Remedios, J. J.: Observations of a distinctive infra-red spectral feature in the atmospheric spectra of polar stratospheric clouds measured by the CRISTA instrument, Geophys. Res. Lett., 30, 1875, https://doi.org/10.1029/2003GL017231, 2003. a, b
Spang, R., Remedios, J. J., and Barkley, M. P.: Colour indices for the detection and differentiation of cloud type in infra-red limb emission spectra, Adv. Space Res., 33, 1041–1047, 2004. a, b, c
Spang, R., Arndt, K., Dudhia, A., Höpfner, M., Hoffmann, L., Hurley, J., Grainger, R. G., Griessbach, S., Poulsen, C., Remedios, J. J., Riese, M., Sembhi, H., Siddans, R., Waterfall, A., and Zehner, C.: Fast cloud parameter retrievals of MIPAS/Envisat, Atmos. Chem. Phys., 12, 7135–7164, https://doi.org/10.5194/acp-12-7135-2012, 2012. a, b
Spang, R., Hoffmann, L., Höpfner, M., Griessbach, S., Müller, R., Pitts, M. C., Orr, A. M. W., and Riese, M.: A multi-wavelength classification method for polar stratospheric cloud types using infrared limb spectra, Atmos. Meas. Tech., 9, 3619–3639, https://doi.org/10.5194/amt-9-3619-2016, 2016. a, b, c, d, e, f, g, h, i
Spang, R., Hoffmann, L., Müller, R., Grooß, J.-U., Tritscher, I., Höpfner, M., Pitts, M., Orr, A., and Riese, M.: A climatology of polar stratospheric cloud composition between 2002 and 2012 based on MIPAS/Envisat observations, Atmos. Chem. Phys., 18, 5089–5113, https://doi.org/10.5194/acp-18-5089-2018, 2018. a
Stiller, G. P., Hoepfner, M., Kuntz, M., von Clarmann, T., Echle, G., Fischer, H., Funke, B., Glatthor, N., Hase, F., Kemnitzer, H., and Zorn, S.: Karlsruhe optimized and precise radiative transfer algorithm. Part I: requirements, justification, and model error estimation, in: Optical Remote Sensing of the Atmosphere and Clouds, Proc. SPIE, 3501, https://doi.org/10.1117/12.317754, 1998. a
Tharwat, A.: Classification assessment methods, Appl. Comput. Inf., in press, https://doi.org/10.1016/j.aci.2018.08.003, 2018. a
Toon, O. B., Browell, E. V., Kinne, S., and Jordan, J.: An analysis of lidar observations of polar stratospheric clouds, Geophys. Res. Lett., 17, 393–396, https://doi.org/10.1029/gl017i004p00393, 1990. a
Tritscher, I., Grooß, J.-U., Spang, R., Pitts, M. C., Poole, L. R., Müller, R., and Riese, M.: Lagrangian simulation of ice particles and resulting dehydration in the polar winter stratosphere, Atmos. Chem. Phys., 19, 543–563, https://doi.org/10.5194/acp-19-543-2019, 2019. a
Ungermann, J., Kaufmann, M., Hoffmann, L., Preusse, P., Oelhaf, H., Friedl-Vallon, F., and Riese, M.: Towards a 3-D tomographic retrieval for the air-borne limb-imager GLORIA, Atmos. Meas. Tech., 3, 1647–1665, https://doi.org/10.5194/amt-3-1647-2010, 2010. a
Voigt, C.: Nitric Acid Trihydrate (NAT) in Polar Stratospheric Clouds, Science, 290, 1756–1758, https://doi.org/10.1126/science.290.5497.1756, 2000. a
Wolpert, D. H.: The Lack of A Priori Distinctions Between Learning Algorithms, Neural Comput., 8, 1341–1390, https://doi.org/10.1162/neco.1996.8.7.1341, 1996. a
Zeiler, M. D. and Fergus, R.: Visualizing and understanding convolutional networks, in: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), available at: https://doi.org/10.1007/978-3-319-10590-1_53, 2014. a