the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 26 Aug 2020
| 26 Aug 2020
High-resolution mapping of urban air quality with heterogeneous observations: a new methodology and its application to Amsterdam
In many cities around the world people are exposed to elevated levels of air pollution. Often local air quality is not well known due to the sparseness of official monitoring networks or unrealistic assumptions being made in urban-air-quality models. Low-cost sensor technology, which has become available in recent years, has the potential to provide complementary information. Unfortunately, an integrated interpretation of urban air pollution based on different sources is not straightforward because of the localized nature of air pollution and the large uncertainties associated with measurements of low-cost sensors.
This study presents a practical approach to producing high-spatiotemporal-resolution maps of urban air pollution capable of assimilating air quality data from heterogeneous data streams. It offers a two-step solution: (1) building a versatile air quality model, driven by an open-source atmospheric-dispersion model and emission proxies from open-data sources, and (2) a practical spatial-interpolation scheme, capable of assimilating observations with different accuracies.
The methodology, called Retina, has been applied and evaluated for nitrogen dioxide (NO2) in Amsterdam, the Netherlands, during the summer of 2016. The assimilation of reference measurements results in hourly maps with a typical accuracy (defined as the ratio between the root mean square error and the mean of the observations) of 39 % within 2 km of an observation location and 53 % at larger distances. When low-cost measurements of the Urban AirQ campaign are included, the maps reveal more detailed concentration patterns in areas which are undersampled by the official network. It is shown that during the summer holiday period, NO2 concentrations drop about 10 %. The reduction is less in the historic city centre, while strongest reductions are found around the access ways to the tunnel connecting the northern and the southern part of the city, which was closed for maintenance. The changing concentration patterns indicate how traffic flow is redirected to other main roads.
Overall, it is shown that Retina can be applied for an enhanced understanding of reference measurements and as a framework to integrate low-cost measurements next to reference measurements in order to get better localized information in urban areas.
- Article
(11111 KB) - Full-text XML
-
Supplement
(2265 KB) - BibTeX
- EndNote




Due to growing urbanization in the last decades, more than half of the world's population lives in cities nowadays. Dense traffic and other human activity, in combination with unfavourable meteorological conditions, often cause unhealthy air pollution concentrations. Over 80 % of the urban dwellers are forced to breathe air which does not meet the standards of the World Health Organization (WHO, 2016). In 2015, an estimated 4.5 million people died prematurely from diseases attributed to ambient air pollution (Lelieveld et al., 2018). Good monitoring is important to better understand the local dynamics of air pollution, to identify hot spots, and to improve the ability to anticipate events. This is especially relevant for nitrogen dioxide (NO2) concentrations, which can vary considerably from street to street. NO2 is, apart from being a toxic gas on its own, an important precursor of particulate matter, ozone, and other regional air pollutants. Observations from a single location are not necessarily representative for a larger area. Unfortunately, urban-air-quality reference networks are usually sparse or even absent due to their high installation and maintenance costs. New low-cost sensor technology, available for several years now, has the potential to extend an official monitoring network significantly, even though the current generation of sensors has significant lower accuracy (WMO, 2018).
However, exploiting these measurements (either official or unofficial), apart from publishing the data as dots on a map, is not straightforward. Here, the aim is to make better use of the existing measurement networks to get the best description of hourly urban air quality, and to create value from low-cost measurements towards a Level 4 product, according to the classification proposed by Schneider et al. (2019).
To obtain high-resolution information of air pollutants with sharp concentration gradients, a very sparse observation network needs to be accompanied by a valid high-resolution air quality model, whereas a very dense network can do with simple spatial interpolations. The situation in most large cities is somewhere in between. There is often a reasonably large reference network present (10+ stations), sometimes complemented with an experimental network of low-cost air quality sensors. Assumptions about underlying unresolved structures in the concentration field are still needed, but this can be done with a simplified air quality model, using the available measurements to correct simulation biases where needed.
A popular approach in detailed mapping of air quality is land use regression modelling (LURM; see e.g. Beelen et al., 2013). LURM uses multiple linear regression to couple a broad variety of predictor variables (geospatial information such as traffic, population, altitude, and land use classes) to the observed concentrations. It is typically used in exposure studies, which target long integration intervals by definition. Problems of overfitting might arise when too many predictor variables are used. Alternatively, Denby (2015) advocates the use of less proxy data and a model based on more physical principles. In his approach, the emission proxies are first (quasi) dispersed with a parameterized inverse-distance function, before being coupled to observed concentrations in a regression analysis.
Mapping of air pollution for short timescales is challenging. Only a few scientific studies are published aiming at the assimilation of near-real-time observations in hourly urban-concentration maps. Tilloy et al. (2013) use the 3-hourly output of a well-developed implementation of the AMDS-Urban dispersion model in Clermont-Ferrand, France, to assimilate in situ NO2 measurements at nine reference sites in an optimal-interpolation scheme. With a leave-one-out validation they show a strong reduction in the root mean square error (RMSE) of the time series after assimilation. Schneider et al. (2017) use universal kriging to combine hourly NO2 observations of 24 low-cost sensors in Oslo, Norway, with a time-invariant basemap. The basemap is created from a yearly average concentration field calculated with an Eulerian–Lagrangian dispersion model on a 1 km grid, downscaled to 100 m resolution. Averaged over reference locations, their study shows that hourly values compare well with official values, showing the potential of low-cost sensor data for complementary air quality information at these timescales.
This paper presents a more advanced yet practical approach to map hourly air pollutant concentrations, named Retina. Its main system design considerations are
-
an observation-driven nature
-
an ability to assimilate observations of different accuracy
-
a potential near-real-time application
-
a versatility and portability to other domains
-
an open-data base
-
a reasonable usage of computer resources.
The method is applied to Amsterdam, where, like many cities, NO2 emissions are dominated by transport and residential emissions and where local exceedances of limit values are regularly observed. Amsterdam is the most populous city in the Netherlands, with an estimated population of 863 000. Located at 52∘22′ N 4∘54′ E, it has a maritime climate with cool summers and moderate winters. Concentrations of NO2 within the city vary considerably, being partly produced locally and partly transported from outside the city. Measurements of 2016 show that, compared with regional background values from the Copernicus Atmosphere Monitoring Service (CAMS) ensemble (see Sect. 3.2.3), urban background concentrations are on average around 50 % higher, while at road sides NO2 concentrations are about 100 % higher.
Retina uses a two-stage approach. It runs an urban-air-quality model to account for hourly variability in meteorological conditions (described in Sect. 3), which is dynamically calibrated with recent measurements (Sect. 4). In the second stage it assimilates current measurements using statistical interpolation (Sect. 5). Section 6 presents the validation of the system, while Sect. 7 shows the added value when assimilating additional low-cost sensor measurements. The last section is reserved for discussion, conclusion, and outlook.
The Public Health Service of Amsterdam (GGD) is the responsible authority for air quality measurements in the Amsterdam area. Within the domain used in this study their NO2 network consists of 15 reference stations: 5 stations classify as road stations, 5 as urban-background stations, 2 as industry, 2 as rural, and 1 as undecided (see Fig. 1). Alternatingly, GGD operates a Teledyne API 200E and a Thermo Electron 42i NO∕NOx analyser, both based on chemiluminescence. A catalytic–reactive converter converts NO2 in the sample gas to NO, which, along with the NO present in the sample, is reported as NOx. NO2 is calculated as the difference between NOx and NO. The accuracy of both types of reference instruments is estimated at 3.7 % (GGD, 2014), following the EN 14211 standard which includes all aspects of the measurements method: uncertainties in calibration gas and zero gas, interfering gases, repeatability of the measurement, derivation of NO2 from NOx and NO, and averaging effects.
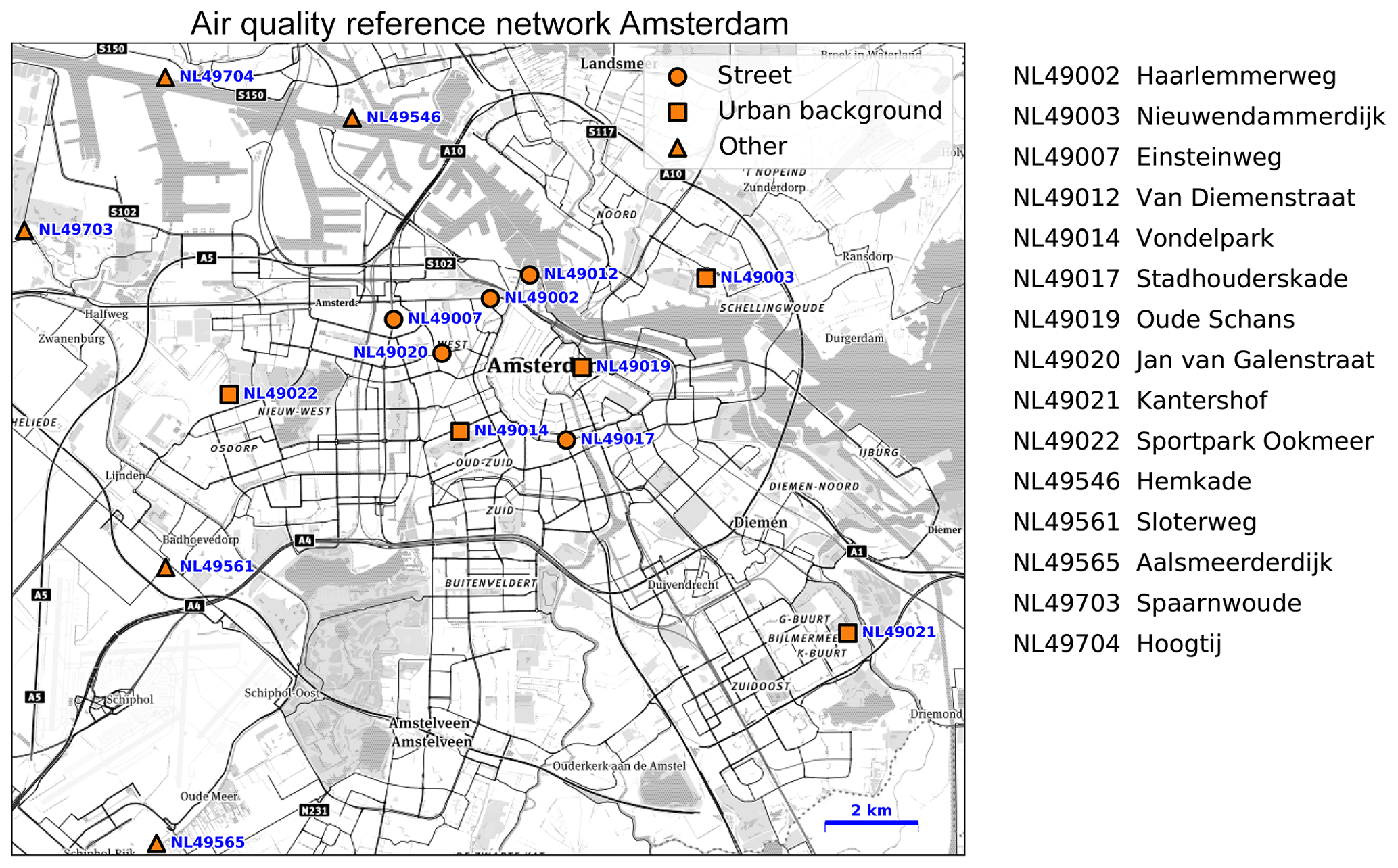
Figure 1Air quality reference network of Amsterdam. (Basemap source: © Mapbox © OpenStreetMap contributors 2019. Distributed under a Creative Commons BY-SA License.)
Low-cost NO2 measurements are taken from the 2016 Urban AirQ campaign (Mijling et al., 2018). Sixteen low-cost air quality sensor devices were built and distributed among volunteers living close to roads with high traffic volume for a 2-month measurement period, from 13 June to 16 August. The devices are built around the NO2-B43F electrochemical cell by Alphasense Ltd (Alphasense, 2018). The sensor generates an electrical current when the target gas diffuses through a membrane where it is chemically reduced at the working electrode. Better sensor performance at low-ppb levels is obtained by using low-noise interface electronics. The sensor devices were carefully calibrated using side-by-side measurements next to a reference station, solving issues related to sensor drift and temperature dependence (Mijling et al., 2018). After calibration, they are found to have a typical accuracy of 30 %.
One of the largest unknowns when modelling urban air quality is a detailed, up-to-date emission inventory capable of describing the local contribution. For cities such as Amsterdam the local emissions are dominated by the transport and residential sector. This is confirmed by the EDGAR (Emission Database for Global Atmospheric Research) HTAP (Hemispheric Transport of Air Pollution) v2 emission inventory (Janssens-Maenhout et al., 2013), which estimates the contribution of NOx emissions in a 20 km × 33 km (0.3∘) area around the centre being 62 %, 20 %, 12 %, and 6 % for the transport, residential, energy, and industry sectors respectively. Especially the contribution of road transport is relevant, as its emissions are close to the ground in densely populated areas. Traffic information and population density will be used as proxies for urban emission (see Sects. 3.2.1 and 3.2.2).
In contrast to the regional atmosphere, the urban atmosphere is more dominated by dispersion processes, while many chemical reactions are less important due to a relatively short residence time (Harrison, 2018). For the dispersion of the emission sources, the open-source steady-state plume model AERMOD (Cimorelli et al., 2004) is used, developed by the American Meteorological Society (AMS) and United States Environmental Protection Agency (EPA). Based on the emission inventory and meteorology (see Sect. 3.2.4), AERMOD calculates hourly concentrations of air pollutants. The concentration distribution of emission sources is assumed to be Gaussian both horizontally and vertically when boundary layer conditions are stable. In a convective boundary layer, the vertical distribution is described by a bi-Gaussian probability density function. Note that any other dispersion model can be used in the Retina methodology, as long as it is capable of simulating concentrations from individual emission sectors on an arbitrary receptor mesh.
3.1 AERMOD simulation settings
AERMOD version 16216r is used with simulation settings summarized in Table 1, operating on a rectangular domain of 18 km × 22 km covering the municipality of Amsterdam for the most part. All coordinates are reprojected in a custom oblique stereographic projection (EPSG:9809) around the city centre coordinate such that the coordinate system can be considered equidistant at the urban scale. Instead of using a regular grid, a road-following mesh (Lefebvre et al., 2011) is used. This reduces the number of receptor points, while maintaining an accurate description of strong gradients found close to roads. Receptor locations are chosen at every 75 m along the parallel curves with 25 m distance to the road and at every 125 m along the parallel curves with 50 m distance to the road. The open spaces between these points are filled with a regular grid at 125 m resolution. Roads are modelled as line sources, while residential emissions are described as area sources. The dispersion is calculated for NOx to avoid a detailed analysis of the rapid cycling between its constituents NO and NO2. Afterwards, an NO2∕NOx ratio is applied, depending on the available ozone (O3) (see Sect. 3.1.1).
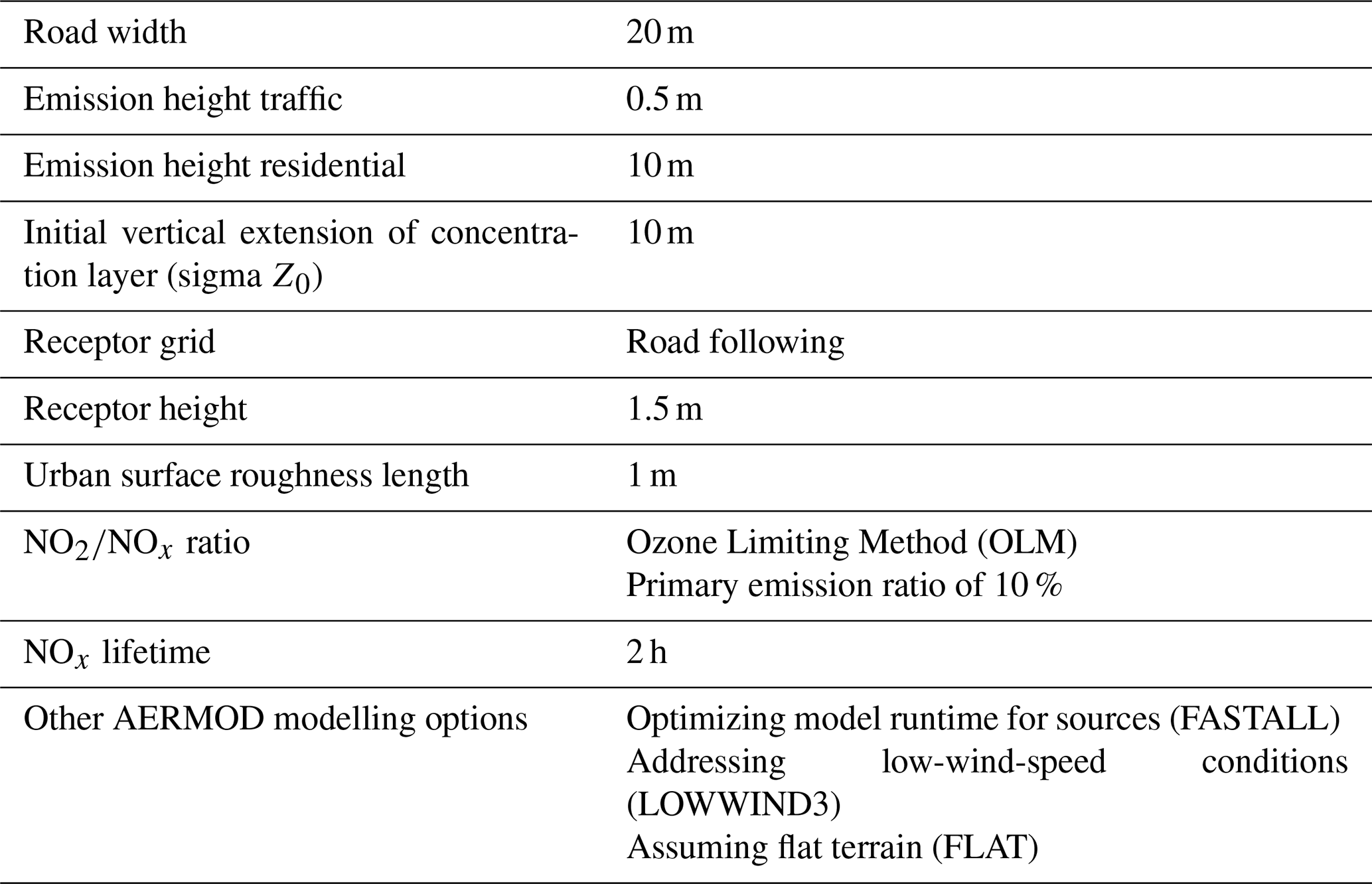
Memory usage of AERMOD for the Amsterdam domain is proportional to the total number of emission source elements (here 17 069 road fragments and 12 182 residential squares) and the number of receptor points in the road-following mesh (here 42 128). The calculation time for a single concentration field is around 10 min but can be reduced to a fraction of this by parallelizing the code.
Ozone chemistry and lifetime
Primary emissions of NO2 (e.g. directly from the tailpipe) are only 5 %–10 % of the total emitted NOx (Sokhi et al., 2007). At short timescales, secondary NO2 is formed by oxidation of NO with O3, while this reaction is counterbalanced by photolysis converting NO2 to NO. The reaction rate of the first reaction is temperature dependent, while the latter depends on the available sunlight. The NO2∕NOx ratio has therefore an intricate dependence on temperature, radiation, and the proximity to the source (i.e. the travel time of the air mass since emission).
A practical approach to estimate this ratio is the Ozone Limiting Method (OLM), as described in EPA (2015). The method uses ambient O3 to determine how much NO is converted to NO2. The dispersed (locally produced) NOx concentration is divided into two components: the primary emitted NO2 (here assumed to be 10 %) and the remaining NOx, which is assumed to be all NO available for reaction with ambient O3: . If the mixing ratio of ozone (O3) is larger than the 90 % of NOx, then all NO is converted to NO2. Otherwise, the amount of NO converted is equal to the available O3, i.e. . The reaction is assumed to be instantaneous and irreversible. The resulting NO2 concentration is added to the NO2 background concentration.
Removal processes of NOx are modelled with an exponential decay. The chemical lifetime is in the order of a few hours. Liu et al. (2016) find NOx lifetimes in a range of 1.8 to 7.5 h using satellite observations over cities in China and the USA. Given the size of the domain and average wind speeds, its exact value is not of great importance here. Based on regression results a practical value of 2 h is chosen.
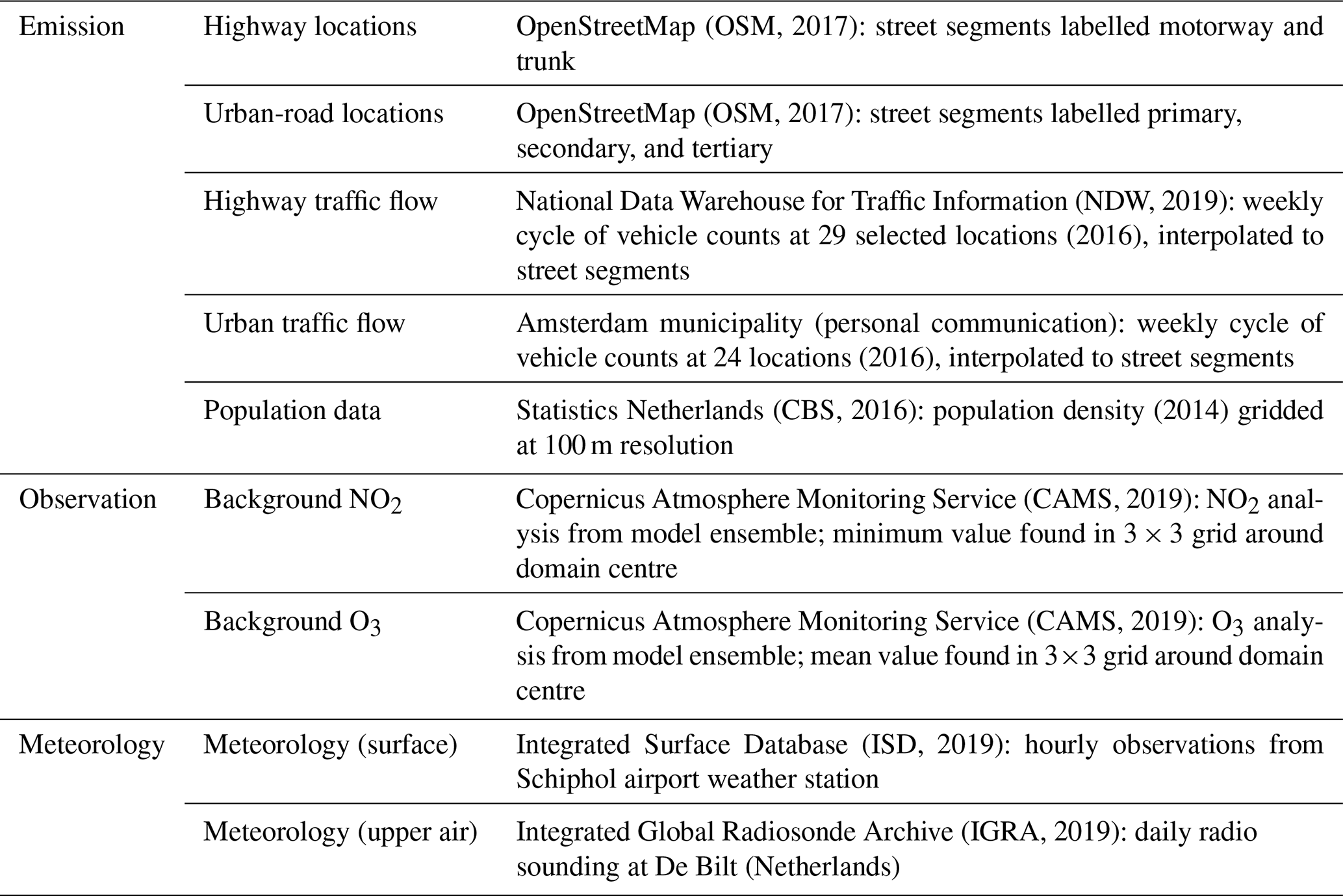
3.2 Simulation input data
The dispersion simulation is driven by input data regarding emissions, background concentrations, and meteorology, as listed in Table 2. All data, except for the traffic counts of inner-city traffic, are taken from open-data portals. The emission proxies are mapped in Fig. 2.
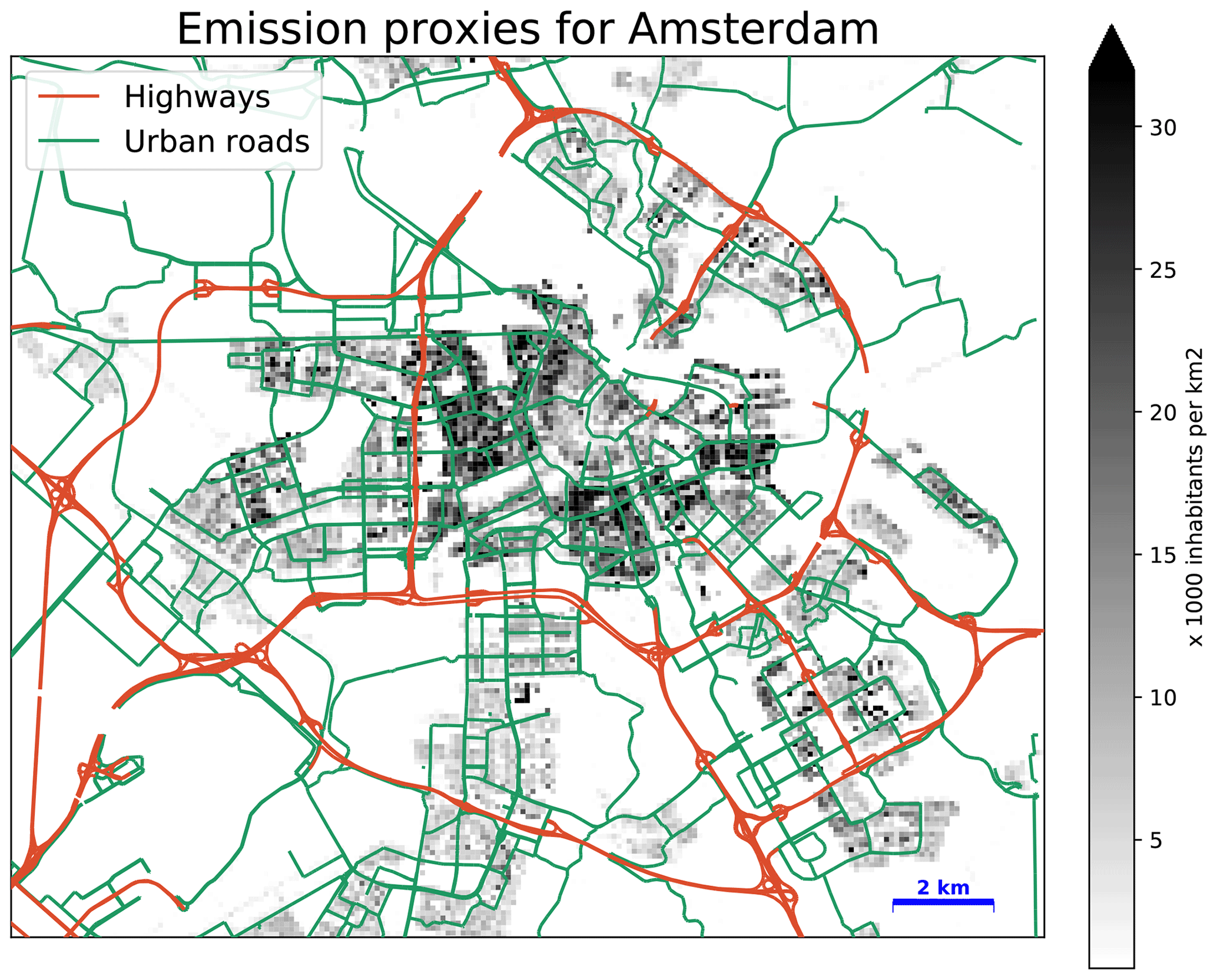
Figure 2Map of the emission proxies used for the dispersion model. Red lines indicate the highways; green lines indicate the urban main roads. Grey colours indicate the population density. (Road location data adopted from © OpenStreetMap contributors 2019. Distributed under a Creative Commons BY-SA License.)
3.2.1 Traffic emissions
A recurrent problem when building urban-air-quality models is finding sufficiently detailed traffic emission information. Traffic emissions depend roughly on traffic flow and fleet composition, including engine technology. For many cities, unfortunately, this information is not available. Here a distinction is made between highways and primary roads, as both have a distinct traffic volume and weekly cycle. Differences in driving conditions and fleet composition are captured by assigning two different emission factors later on.
Road location data and road type definition data are taken from OpenStreetMap (OSM, 2017), which is a crowdsourced project to create a free editable map of the world. A distinction is made between urban roads (labelled in OSM as “primary”, “secondary”, and “tertiary”) and highways (labelled as “motorway” and “trunk”), as they have distinct traffic pulses, fleet compositions, and driving conditions. Road segments labelled as “tunnel” are not taken into account.
When the traffic flow q (in vehicles per hour) is known, the emission rate E for a road segment l can be written as
with emission factor αveh representing the (unknown) NOx emission per unit length per vehicle. Hourly traffic flow data are taken from 29 representative highway locations from the National Data Warehouse for Traffic Information (NDW, 2019), which contains both real-time and historic traffic data. For the urban traffic flow, data from 24 inductive-loop counters provided by the traffic research department of Amsterdam municipality are used. Due to its large numbers, traffic flow is relatively well predictable, especially when lower volumes during holiday periods and occasional road closures are neglected. For each counting site a traffic “climatology” is constructed, parametrized by hour and weekday, based on hourly data of 2016 (see Fig. 3).

Figure 3Weekly cycle of highways and urban roads at counting locations (thin lines), aggregated from hourly data from 2016. The thick lines show the median of traffic flow for both road types. The morning and evening rush hours on working days are clearly visible for highways. Urban traffic has, apart from lower volume, less distinct peaks.
Traffic counts correlate strongly between different highway locations, all showing a strong commuting and weekend effect. Urban traffic typically shows, apart from lower volumes, less reduction between morning and evening rush hours, a less pronounced weekend effect, and higher traffic intensities on Friday and Saturday night.
For locations x between the counting locations xi, the traffic flow q(x) is spatially interpolated by inverse-distance weighting (IDW):
in which the weighting factors wi depend on the distance d between x and the counting location xi:
Validation in the Supplement shows that for this counting network IDW predicts the traffic volume within a 50 % error margin at most locations. Better results are obtained when more counting locations are available or when they are selected strategically around crossings and access roads. Model simulations show that using inferior traffic data is partly compensated by the calibration (Sect. 4), at the expense of less pronounced concentration gradients.
3.2.2 Population data
Population density is considered to be a good proxy for residential emissions, e.g. from cooking and heating. Here, data are taken from the gridded population database of 2014, compiled by the national Central Bureau for Statistics (CBS, 2019) at a 100 m resolution. Each grid cell is offered to the dispersion model as a separate area source. To reflect the observation that residential emissions per capita are less when people are living closer to each other (Makido et al., 2012), the emission fluxes are taken proportional to the square root of the population density p:
3.2.3 Background concentrations
As AERMOD only describes the local contribution to air pollution, background concentrations must be added. These are taken from the Copernicus Atmosphere Monitoring Service (CAMS) European air quality ensemble (Marécal et al., 2015). The CAMS ensemble consists of seven regional models producing hourly air quality and atmospheric-composition forecasts on a 0.1∘ × 0.1∘ resolution. The analysis of the ensemble is based on the assimilation of up-to-date (UTD) air quality observations provided by the European Environment Agency (EEA). Each model has its own data assimilation system.
In the CAMS product the local contributions are already present. To get a better estimate for regional background concentrations avoiding double counts, the lowest concentration found in a 0.3∘ × 0.3∘ area around the city for NO2 is taken, together with the mean concentration found in this area for O3.
3.2.4 Meteorological data
The dispersion of air pollution is strongly governed by local meteorological parameters, especially the winds driving the horizontal advection and the characterization of the boundary layer which defines the vertical mixing. Meteorology also affects the chemical lifetime of pollutants.
AERMET (EPA, 2019) is used as a meteorological preprocessor for organizing available data into a format suitable for use by the AERMOD model. AERMET requires both surface and upper-air meteorological data but is designed to run with a minimum of observed meteorological parameters. Vertical profiles of wind speed, wind direction, turbulence, temperature, and temperature gradient are estimated using all available meteorological observations and extrapolated using similarity (scaling) relationships where needed (EPA, 2018).
Hourly surface data from the nearby Schiphol airport weather station can be obtained from the Integrated Surface Database (ISD; see Smith et al., 2011). Observations of temperature, winds, cloud cover, relative humidity, pressure, and precipitation are retrofitted to match the SAMSON (Solar and Meteorological Surface Observation Network) data format (WebMet, 2019a), which is supported by AERMET. Upper-air observations are taken from daily radiosonde observations in De Bilt (35 km from Amsterdam), archived in the Integrated Global Radiosonde Archive (IGRA) (Durre et al., 2006). Pressure, geopotential height, temperature, relative humidity, dew point temperature, and wind speed and direction are converted to the TD6201 data format (WebMet, 2019b) for each reported level up to 300 hPa.
Using proxy data instead of real emission introduces the problem of finding the emission factors which best relate the activity data to their corresponding emissions. Instead of using theoretical values or values found in literature, effective values are derived which best fit the hourly averaged NO2 observations of a network of N stations.
For a certain hour t, the emission of a source element i belonging to source sector k can be written as
in which Pik represents the corresponding emission proxy. The contribution of this source to the concentration at a receptor location j is
with fij describing the dispersion of a unit emission from i to j, including the conversion from NOx to NO2 from the OLM. Equation (6) is assumed to describe a linear relation between emission and concentration, although strictly speaking the variable NO2∕NOx ratio introduces a weak nonlinearity. A regression analysis is applied for a certain period, assuming that for each t the total NO2 concentration cj at station j can be described as a background field b and a local contribution consisting of a linear combination of the dispersed fields of K emission sectors:
where Sk represents the number of source elements for an emission sector k. The second sum in this equation is calculated for every hour with the Gaussian dispersion model taking the meteorological conditions during t into account. Note that both background concentrations b(t) and local concentrations cj(t) are taken from external data (see Sects. 3.2.3 and 2). Considering a period of T hours, Eq. (7) can be interpreted as a matrix equation from which the emission factors ak can be solved using ordinary least squares. Given the physical meaning of ak, only positive regression results are allowed.
In this setup, the emissions are approximated by the three sectors of highway traffic, urban traffic, and population density (K=3). The resulting ak values do not necessarily represent real emission factors. Their values partly compensate for unaccounted emission sectors and unrealistic modelling (e.g. based on wrong traffic data or an incorrect chemical lifetime). In Retina ak is recalculated every 24 h, based on observations of the preceding week (T=168). Doing so, the periodic calibration adjusts itself to seasonal cycles and episodes not captured by the climatologies (e.g. cold spells or holiday periods). To avoid reducing the predictability of the regression model too much (ak dropping to zero), not all reference stations are used for calibration but rather only stations classified as roadside or urban background. For the Amsterdam network, N=11. The residential emissions are represented by the population density, which is a time-invariant proxy. To allow for a diurnal cycle, the residential emission factor is evaluated for 2 h bins. This brings the total number of fitted emission factors to 14: 1 for highway traffic, 1 for urban traffic, and 12 describing the daily residential emission cycle.
Figure 4 shows an example of the air quality simulation after the emission factors have been determined. The stacked colours in the time series of Fig. 4b show that the contribution from different emission sectors to local air pollution can strongly vary from site to site.

Figure 4(a) Dispersion maps of NO2 concentrations for each emission sector on 8 July 2016 at 09:00. The lower-right panel shows the linear combination which best fits the time series at the calibration sites. Wind is blowing from the southwest at 16 km h−1. The grey dots indicate an urban-background location, a street location, and a highway location. (b) Comparison of observed and simulated NO2 time series (date format of day-month-year) for the urban-background location, the street location, and the highway location. The colours indicate the simulated contribution of the three source sectors and the background.
Diurnal and seasonal analysis of calibration results
It is important to realize that the numerous modelling assumptions prevent the calibration from realistically solving the underdetermined inverse problem of finding the underlying NOx emissions based on the observed NO2 concentrations. Instead, it evaluates how much NOx must be injected into the model to explain the observed spatial NO2 patterns (unbiased with respect to the calibration locations). To study the results of the regression analysis, a comparison was made between a summer month (July 2016, mean temperature of 18.4 ∘C) and a winter month (January 2017, mean temperature of 1.6 ∘C). Figure 5 shows the diurnal emissions for a 0.2∘ × 0.1∘ area, corresponding to the two grid cells of the EDGAR inventory covering the city centre.

Ideally, the emissions would be around the values found in the EDGAR inventory (6.23 and kg NOx m−2 s−1 for summer and winter respectively) and a corresponding ratio between residential and transport emissions (8 % and 48 % for summer and winter respectively). Unlike traffic, however, the diurnal cycle for the residential contribution is not prescribed but is shaped in the regression analysis. The seasonal analysis shows that its fitted diurnal cycle not only describes changing residential emissions but also compensates for changing NO2∕NOx ratios over the day (not included in the OLM) due to changing photochemistry and temperature. In daylight, the destruction of NO2 by photolysis () is strong, reducing the NO2∕NOx ratio. At low temperatures, the formation of NO2 from NO () is slow, also reducing the NO2∕NOx ratio. Also, due to collinearity, part of the traffic emissions will be explained by population density. Therefore, the found emission factors (and the corresponding sectoral emissions) should be considered as “effective” rather than real, i.e. as factors which best describe the observations under the given model assumptions.
As the air quality network is spatially undersampling the urban area, the observations need to be combined with additional model information to preserve the fine local structures in air pollutant concentrations. The interpolation technique of choice here is optimal interpolation (OI) (Daley, 1991), having the desired property that the Bayesian approach allows for assimilation of heterogeneous measurements with different error bars. At an observation location the model value is corrected towards the observation, with the innovation depending on the balance between the observation error and the simulation error. The error covariances determine how the simulation in the surroundings of this location is adjusted. Note that OI is essentially the same assimilation scheme as kriging-based approaches. The main advantage here is that one has detailed manual control over the error covariance matrix, which allows for a more comprehensive specification of the area of influence for each contributing observation. Outside the representativity range (i.e. the correlation length) of the observations, the analysis relaxes to the model values.
Consider a state vector x representing air pollutant concentrations on the (road-following) receptor mesh (n≈40 000). Define xb as the background, i.e. the model simulation. Observation vector z contains m measurements, typically 10–100. Following the convention by Ide et al. (1997), the OI algorithm can now be written as:
Matrix R is the m×m observation error covariance matrix. As all observations are independent (the measurement errors are uncorrelated), R is a diagonal matrix with the measurement variances on its diagonal.
Pb is the n×n model error covariance matrix, describing how model errors are spatially correlated. The calculation of Pb is not straightforward; in Sect. 5.1 an approximation is derived.
Operator H is the forward model, which maps the model state to the observed variables and locations. The matrix calculations can be simplified by reserving the first m elements of the state vector for the observation locations and the other n−m elements for the road-following mesh. The Gaussian dispersion model is evaluated “in situ” at the observation locations. Avoiding reprojection or interpolation means that there are no representation errors associated with H. The simulations at the observation locations zb can then be written as a matrix multiplication
in which H is an m×n matrix for which its first m columns form a unity matrix, while its remaining elements are 0.
Equation (8) describes the analysis xa, i.e. how the observations z are combined (assimilated) with the model xb. It is a balance between the model covariance and the observation covariances, described by the gain matrix K in Eq. (9). K determines how strong the analysis must incline towards the observations or remain at the simulated values to obtain the lowest analysis error variance, Pa in Eq. (10).
Note that Eqs. (8)–(10) are analogous to the first step in Kalman filtering. The second step of the filter, propagating the analysis to the next time step, cannot be made here as the plume model solves a stationary state which is independent of the initial air pollutant concentration field. Also note that since an approximated model error covariance matrix will be used, generally these equations do not lead to an optimal analysis; hence this approach is more correctly referred to as statistical interpolation.
Let vector c represent the observed NO2 mass concentrations, as described in Sect. 2. The distribution of the air pollutant concentrations resembles better the lognormal distribution than the Gaussian distribution, as can be seen from the Q–Q plots in Fig. 6. The analysis is done in log space (zj=ln cj), stabilizing the results by reducing the impact of less frequent measurements of high concentrations. Once returning from the log domain, Eq. (8) can be rewritten as
By doing the analysis in the log domain the assimilation updates correspond to multiplication instead of addition: exp(KΔz) represents the local multiplication factor with which the simulated concentration cb is corrected. This means that the shape of the model field (e.g. strong gradients found close to busy roads) is locally preserved. Note that the error in zj corresponds to the relative error in cj: . The observation error covariance matrix is therefore ), with σj being the relative error corresponding to observation j.
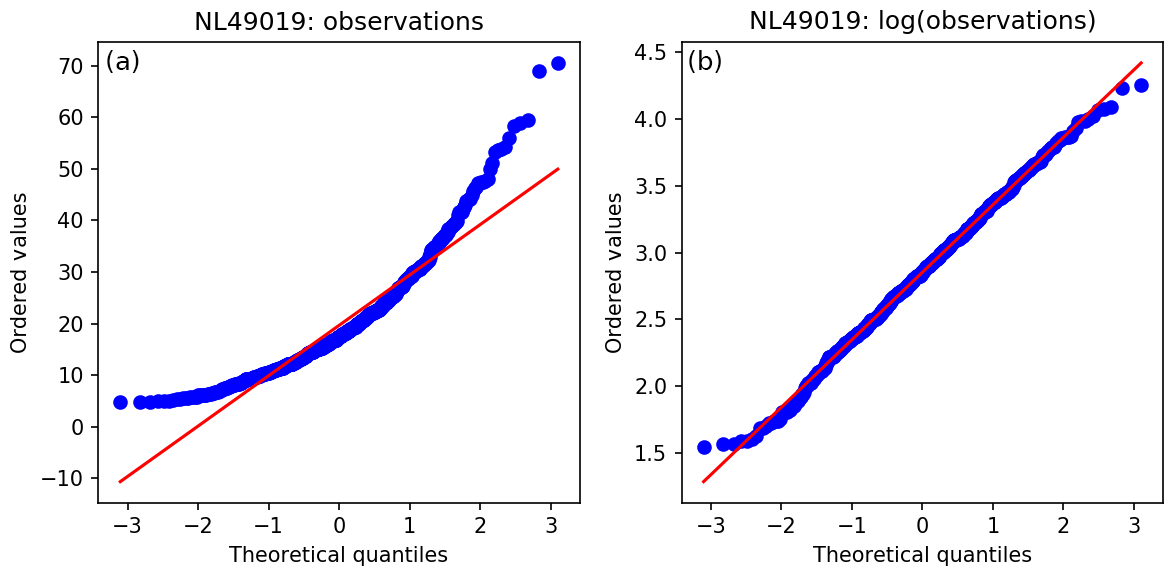
Figure 6(a) Distribution of the NO2 observations at reference station Oude Schans in July 2016 compared to a standard normal distribution. (b) The logarithm of the observed values correspond better to a Gaussian distribution, shown by the quantile value pairs being almost on a straight line.
Modelling the model error covariance matrix
For an optimal result in the data assimilation a realistic representation of the model covariance matrix Pb is essential. The model covariances influence the spatial representativity of the observations: when model errors correlate over larger distances, the assimilated observation will change the analysis over a longer range.
Tilloy et al. (2013) choose to model the covariances depending on the road network. Error correlations are assumed to be high on the same road or on connected roads. For background locations, the correlation decreases fast in the vicinity of a road, while the error correlation between two background locations remains significant across a larger distance. The error covariances are kept constant in time and taken independent of traffic conditions.
However, Pb changes from hour to hour, mainly because varying meteorology changes the atmospheric-dispersion properties. Here, the model error covariance is estimated for each hour based on the spatial coherence of the simulated concentration field. The covariance between two grid locations xi and xj can be expressed as their correlation ρ and their standard deviations σ:
The model error σ can only be evaluated at locations of the reference network using time series analysis. These model errors are spatially interpolated to other grid locations using IDW, analogous to Eqs. (2)–(3). The correlation of model errors between different locations is parametrized with a downwind correlation length Ldw and a crosswind correlation length Lcw. The extent of the correlation lengths reflects the turbulent diffusion and transport of the Gaussian-dispersed plumes for a specific hour.
From spatial analysis of the simulation data a heuristic model is derived which describes the dependence of the correlation on distance:
with d being the scaled distance between xi and xj (expressed as xdw and xcw along the downwind and crosswind axes),
such that all points on an ellipse with semi-major axis Ldw and semi-minor axis Lcw have the same correlations.
To fit the parameters Ldw and Lcw for a certain hour, 1000 sample locations are selected from the road-following mesh. To represent both polluted and less polluted areas, the locations are selected such that their concentrations are homogeneously distributed over the value range, excluding the first and last five percentiles. For this sample, correlation lengths Ldw and Lcw are fitted using Eqs. (14) and (15).
Figure 7 shows the results of this analysis for two different hours. For fields with low gradients (e.g. when traffic contribution is low at night), large values of L can occur. To prevent assimilation instabilities, the fitted values of L are limited to a maximum of 10 km. During the 2016 summer months, the longest correlation lengths are found for fields with low gradients. Average midnight values, when traffic contribution is low, are about 8 km. Correlation lengths are shortest during the morning rush hour (∼1 km), increasing to 3 km during the late morning and afternoon. There is a wind dependency, as stronger winds stretch the pollution plumes, increasing correlation lengths. From the fit results the average ratio between Lcw and Ldw is found to be 68 %.
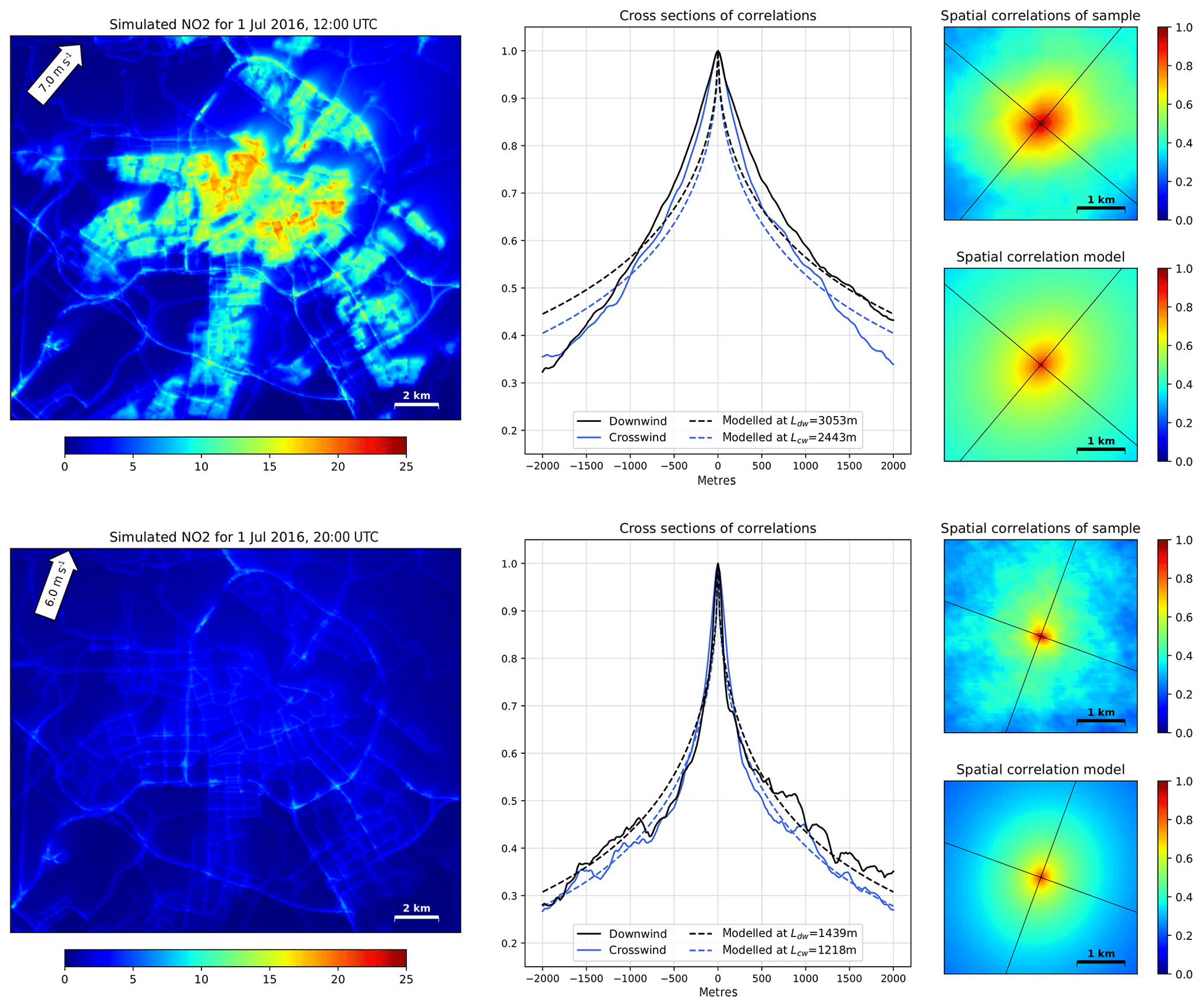
Figure 7Left panels show simulated NO2 concentration fields at 2 different hours. The middle panels show the spatial correlations along the downwind and crosswind axes based on a sample of n=1000. The right panels show the spatial correlations of the sample and the resulting modelled spatial correlation model.
Once the covariance parameters are known, the covariance matrix elements are calculated with Eq. (13). Note that for the calculation of the gain matrix K there is no need to calculate the full Pb matrix. Instead, PbHT is calculated, which due to the structure of H this matrix product corresponds to the first m columns of the n×n matrix Pb.
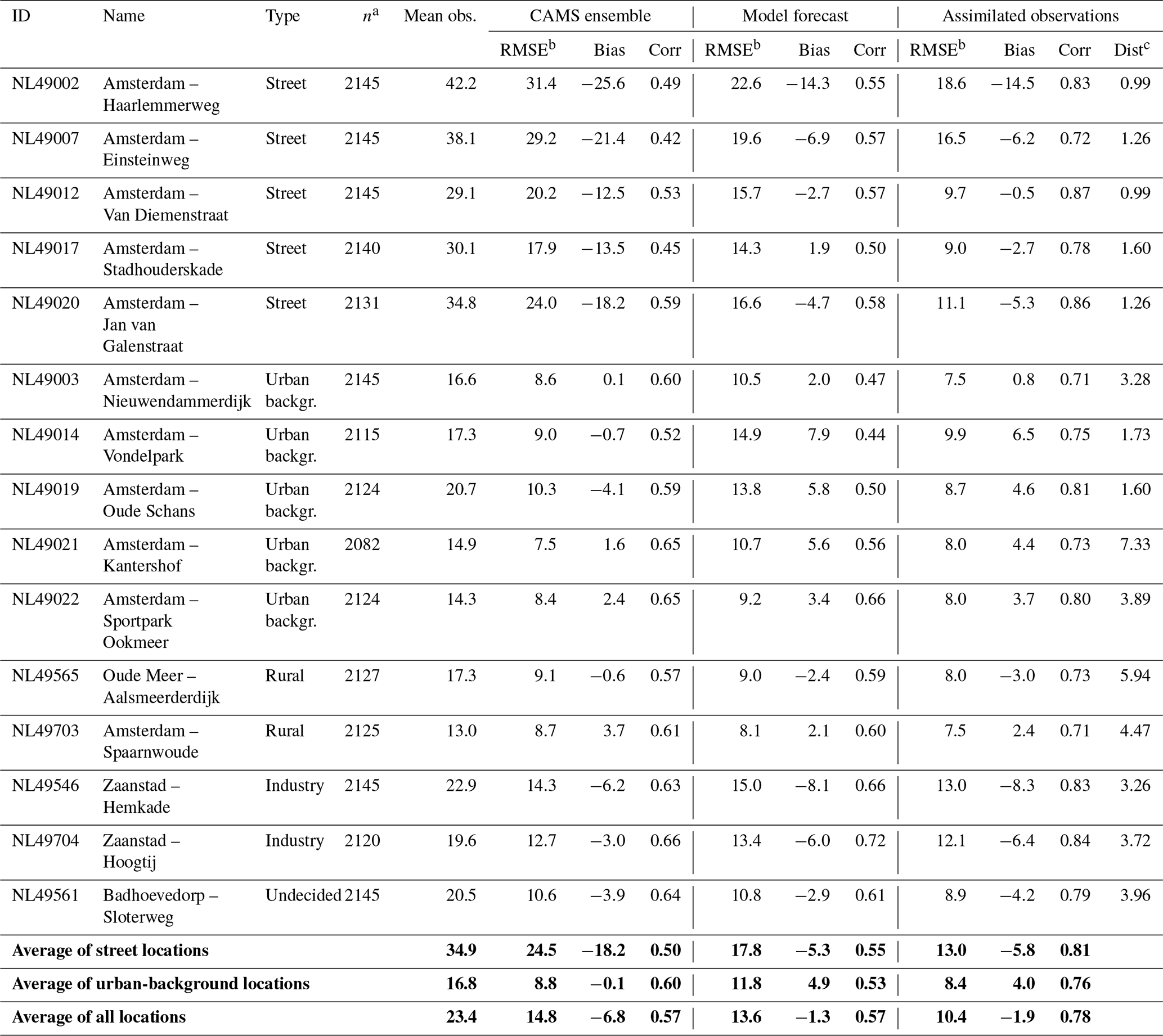
To assess the data quality across the domain, a leave-one-out analysis is performed at all locations of the reference network for the period 1 June–31 August 2016. The results are summarized in Table 3. Figure 8 illustrates two examples; plots for all validation locations can be found in the Supplement. For the observation-free simulation (i.e. the model forecast) an average RMSE is found of 13.6 µg m−3 with a correlation of 0.57. When assimilating observations, the average RMSE drops to 10.4 µg m−3, while the correlation increases to 0.78. Strong systematic underestimations of the simulation (characterized by a large negative bias) are observed at street locations NL49002 and NL49007 and industrial locations NL49546 and NL49704. These are most likely caused by unrealistic assumptions of local emissions of either traffic or industry. The strong positive bias found at NL49014, located in a city park separated from the nearby main road by a block of four-storey buildings, might be explained by an incorrect simulation of air pollutants in the direct vicinity of these buildings.
Table 3Validation results at reference locations on 1 June–31 August 2016.
a Number of samples.
b In units of µg m−3.
c The distance to the nearest observation site (in km).

Figure 8Validation of hourly time series for the period 1 June to 31 August 2016, for a well-performing street location (above) and a less performing urban-background location (below). Statistics of the n data pairs are given in correlation (ρ), coefficient of determination (R2), and RMSE. The right-hand panels compare the error distributions: the observation minus forecast (OmF) against the observation minus analysis (OmA).
The CAMS regional ensemble analysis compares well with the average of the urban-background stations; the very low bias (−0.1 µg m−3) corresponds with the fact that data of these stations are used in its analysis. (Note that the CAMS values used here correspond to the Amsterdam grid cell, not the 3×3 minimum values used as background for the modelling.) On the other hand, it shows strong underestimations at street locations, as expected. It is here where the Retina simulation outperforms the low-resolution results of CAMS.
From Table 3 it can be seen that the relative error in the model forecast (defined as the ratio between the RMSE and the mean of the observations) is around 58 % on average. When assimilating, the error becomes dependent on the distance to the nearest observation locations. For sites having the nearest assimilated observation within 2 km distance, the average RMSE drops from 16.8 to 11.9 µg m−3, corresponding to an average relative error of 39 %. For sites where the nearest assimilated observation is further away than 2 km, the average RMSE drops from 10.8 to 9.1 µg m−3, corresponding to an average relative error of 53 %.
The previous analysis is purely based on high-quality reference measurements. In this section it is explored whether the statistical-interpolation scheme can be used to derive useful information from low-cost measurements, despite their lower accuracy.
This is done by testing different assimilation configurations during the Urban AirQ campaign, from 15 June to 15 August 2016 (see Sect. 2). The campaign targeted a central area with 4 reference stations and 14 low-cost sensors (see Fig. 10a). Validation is done for five different assimilation scenarios (ASs):
-
AS1 – assimilation of all reference measurements (leave-one-out)
-
AS2 – assimilation of measurements from three central reference sites (leave-one-out)
-
AS3 – assimilation of low-cost data only
-
AS4 – assimilation of measurements from three central reference sites (leave-one-out) and all low-cost data
-
AS5 – assimilation of all reference measurements (leave-one-out) and all low-cost data.
The results are summarized in Fig. 9. As expected, results deteriorate when the number of reference locations in the assimilation is reduced from 14 (AS1) to 3 (AS2). The correlation decreases at all four validation locations. At NL49012, the RMSE increases significantly due to a positive jump in the bias. The lower analysis with respect to the observations is due to the absence of assimilation of high values at nearby street location NL49002, which enlarges the influence of lower observations found at urban-background location NL49019. At NL49019, located in the middle of three assimilation locations, the RMSE does not change significantly. Apparently, the effect of assimilation of observations farther than the surrounding locations is small.
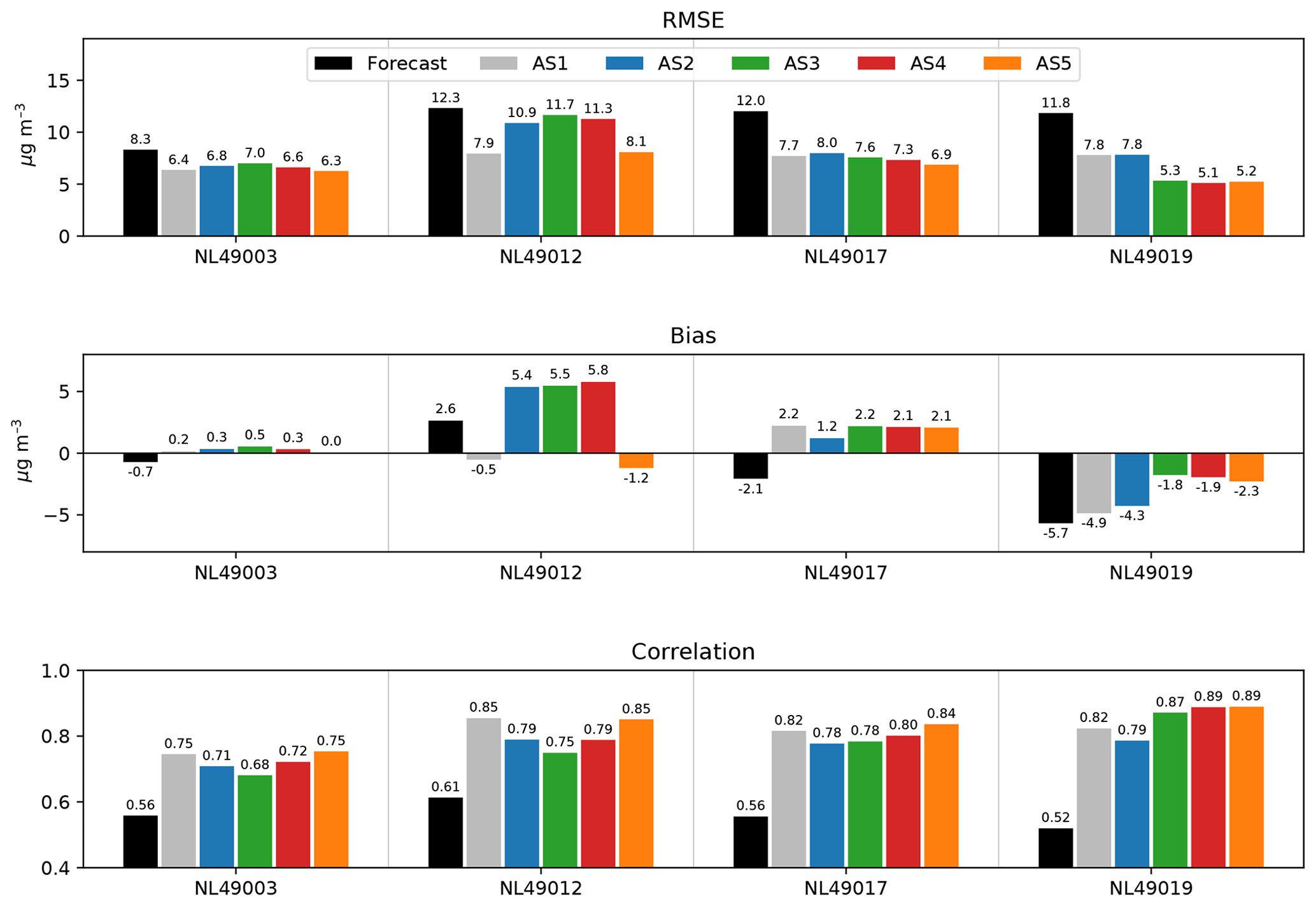
Figure 9Validation of the model forecast and five different assimilation scenarios at four central reference sites, for the period 15 June to 15 August 2016.
When only observations of 14 low-cost sensors are assimilated (AS3), instead of observations at 3 reference sites (AS2), there is a notable improvement visible in bias and RMSE at location NL49019. Here, the low-cost sensors are relatively nearby, the closest being sensor SD04 at 120 m distance. At the other validation locations, the low-cost sensor assimilation results in a similar RMSE (i.e. within 1 µg m−3) and a comparable bias but a slightly lower correlation.
The results can be further improved if both reference and low-cost sensor data are included (AS4 and AS5). At NL49019, the RMSE drops to 5.1 µg m−3 (compared to 7.8 µg m−3 when no low-cost data are included) while the correlation increases to 0.89. Again, there is no significant difference between including the three surrounding reference locations and including all reference locations. Also at street location NL49017 and urban-background location NL49003, the inclusion of low-cost sensor data improves RMSE and correlation compared to assimilations with reference data only (AS4 vs. AS2 and AS5 vs. AS1). At location NL49012, the bias reduces considerably only when all reference data are included in the assimilation (AS1 and AS5).
The different assimilation scenarios show that low-cost sensor data assimilation improve the results locally, even in absence of reference data. Generally, the best results are obtained when both reference data and low-cost data are included. Assimilation can reduce local model biases. However, unrealistically modelled covariances can lead locally to the introduction of an additional bias.
Next, a monthly averaged concentration map of Amsterdam is constructed with all reference data and all low-cost sensor data from the first half of the Urban AirQ (see Fig. 10b). The addition of the low-cost data lowers the assimilation results by several micrograms per cubic metre in the undersampled area west of Oude Schans (NL49019), while the NO2 increases by several micrograms per cubic metre around the traffic arteries found south and east of this location (Fig. 10c). A large fraction of traffic on these roads uses the IJtunnel to cross the river. On a monthly basis, this tunnel is used by approximately 1 million vehicles.
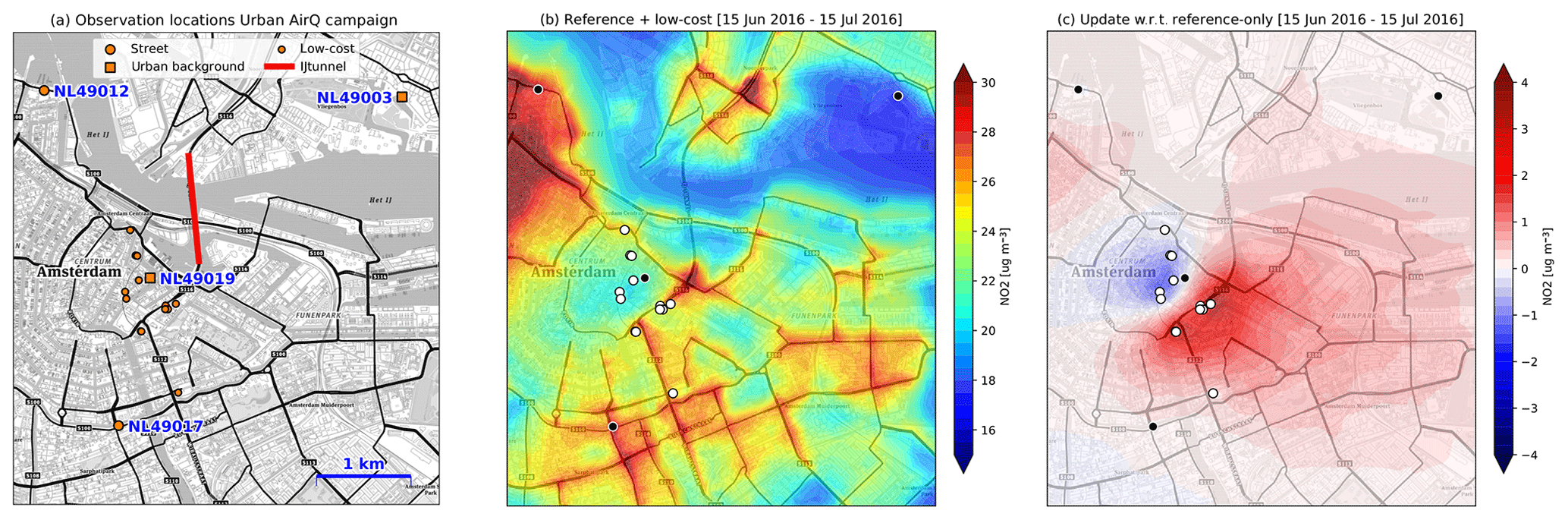
Figure 10(a) Observation sites during the Urban AirQ campaign. (b) The 30 d average of NO2 concentrations in the centre of Amsterdam, after assimilation of both reference measurements (black dots) and low-cost measurements (white dots). (c) Changes in spatial pattern when low-cost measurements are included in the analysis. (Basemap source: © Mapbox © OpenStreetMap contributors 2019. Distributed under a Creative Commons BY-SA License.)
The second half of the Urban AirQ campaign coincides with the start of the summer holiday period and the closure of the IJtunnel for maintenance. Comparison of the NO2 concentration maps of both periods reveal interesting features (Fig. 11). Based on averaged NO2 measurements at rural stations NL49565 and NL49703, the NO2 reduction due to meteorological variability is estimated to be 7 %. The overall drop in NO2 concentrations in the central area, however, is around 10 % due to reduced traffic during the summer break. A notable exception is the historic city centre, where the NO2 reduction is only a few percent, probably related to the steady economic activity driven by tourism. The strongest NO2 reductions, around 15 %, are found around the access ways of the IJtunnel. A few main roads (e.g. De Ruijterkade/Piet Heinkade and Ceintuurbaan) show less NO2 reduction than average, apparently due to redirected traffic avoiding the tunnel.
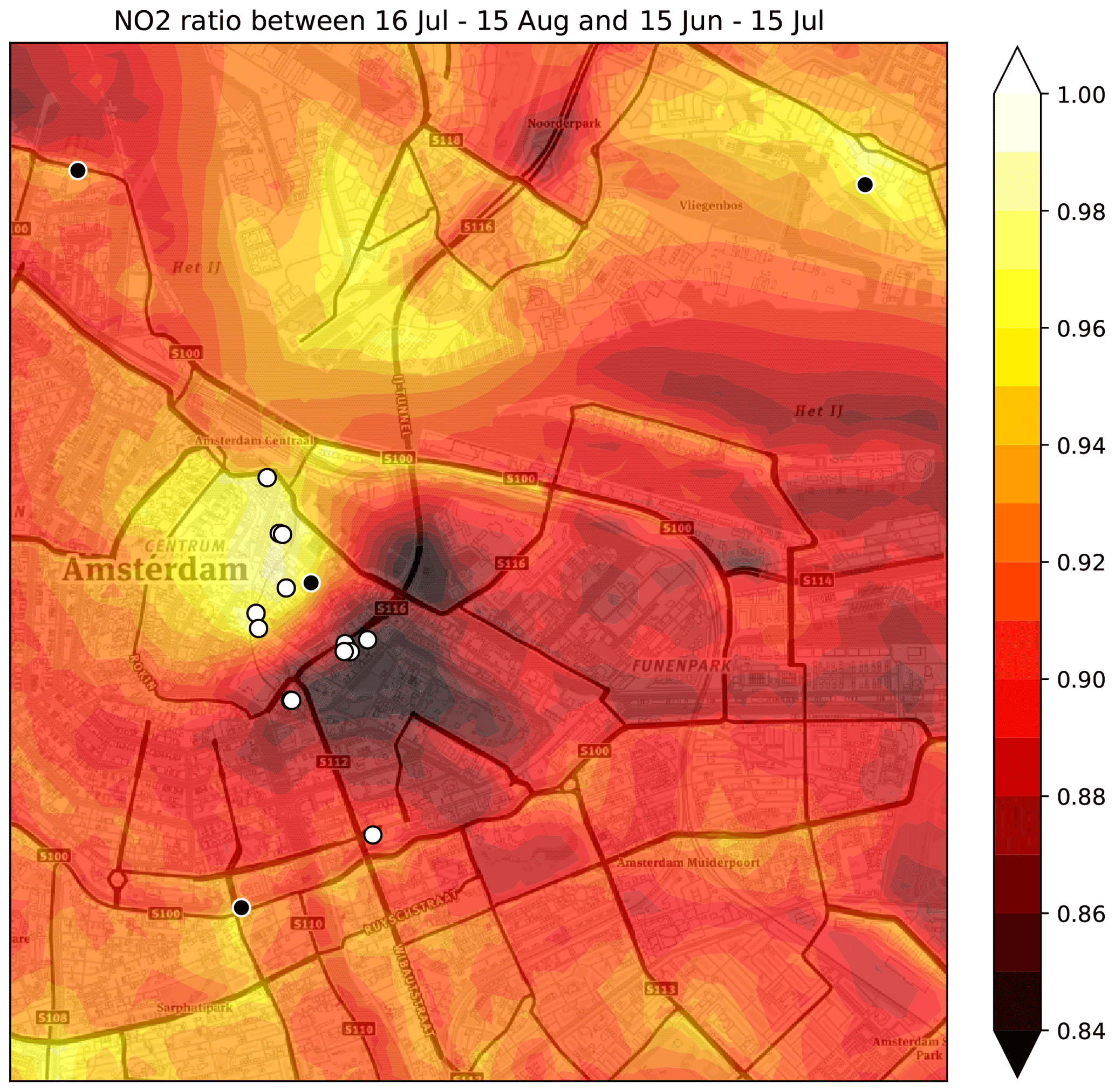
Figure 11Reduction of NO2 during the holiday period. Largest reduction of concentrations is found in the vicinity of access ways to the IJtunnel, which was closed for maintenance. Concentrations in the historic centre remain unchanged. (Basemap source: © Mapbox © OpenStreetMap contributors 2019. Distributed under a Creative Commons BY-SA License.)
As air pollution gradients can be strong in the urban environment, it is essential to combine (sparse) measurements with an air quality model when aiming at street-level resolution. Retina is a practical approach to interpolating hourly urban-air-quality measurements. The first step consists of a simulation by a dispersion model which is driven by meteorological data and proxies for traffic and residential emissions. The model is daily calibrated with historic measurements. In the second step, observations of different accuracy are assimilated using a statistical-interpolation scheme.
Validation analysis confirms that the European CAMS ensemble is a good predictor for hourly NO2 concentrations found in the urban background. However, the CAMS data for NO2 can be misleading when interpreted at the local scale, as the predicted diurnal cycle often deviates substantially from that observed at urban-air-quality stations. Local effects can be better resolved when CAMS data are used for background concentrations in a dispersion model which is driven by proxies for traffic and residential emissions.
The Retina simulation setup shows that such a system can be built from open software and open data. Applied to summer 2016 in Amsterdam, it reduces the relative error at street locations from 70 % to 51 %, mainly by reducing the negative bias from 18.2 to 5.3 µg m−3. At urban-background locations the dispersion model often introduces a positive bias, especially when traffic sources are nearby.
The mapping results improve considerably with the second Retina step when available observations are assimilated by the statistical-interpolation scheme. When assimilating measurements of the reference network, the relative error in NO2 concentrations drops to 44 % on average. The local error depends on the distance to the nearest observations: approximately 39 % within 2 km of an observation site, increasing to 53 % for larger distances. The typical correlation increases from 0.6 to 0.8.
The Bayesian assimilation scheme also allows us to improve the results by including low-cost sensor data, in order to get improved localized information. However, biases must be removed beforehand with careful calibration, as most low-cost air quality sensors suffer from issues like cross-sensitivity or signal drift (see e.g. Mijling et al., 2018). The assimilation of low-cost sensor data from the Urban AirQ campaign reveals a more detailed structure in concentration patterns in an area which is undersampled by the official network. The additional measurements correct for wrong assumptions in traffic emissions used in the a priori interpolation and give better insight into how traffic rerouting (for instance due to closure of an arterial road) affects local air quality.
Retina has been built on open data to facilitate a flexible application to other cities. The meteorology needed for AERMOD is taken from global data sets of ISD and IGRA. Road network information can also be obtained globally from OpenStreetMap. Traffic data tend to be hard to obtain. When no local data are available on diurnal and weekly traffic flow its patterns should be estimated. In the absence of local census data, population density data can be taken from the Global Human Settlement database (Schiavina et al., 2019), which has global coverage on a 250 m resolution. For application within Europe, the necessary background pollutant concentrations can be obtained from CAMS. For applications outside Europe other data sets have to be found.
In general, degraded input data and imperfections in the dispersion modelling will deteriorate the system's capability to resolve local structures; it will lower the effective spatial resolution of the simulations. In its extreme it will only describe the blurry urban-background pollution contribution added to the rural background. Oppositely, with improved input data and atmospheric modelling, the effective resolution will improve, reducing local biases. This is the focus of future research.
Significant inaccuracies due to local emissions which are not described adequately by the proxies (e.g. from industry, port, and airport activity) can be reduced by including these sources explicitly in the dispersion modelling. Small-scale structures provoked by the local built-up area will be better described by introducing the street canyon effect. The model will also benefit from a more detailed traffic emission model, based on more counting locations and aggregated from shorter time intervals. Ideally, such an emission model takes local differences in fleet composition also into account. Finally, simulations will gain accuracy with a more realistic NOx chemistry, concerning the NOx chemical lifetime (influencing the plume length) and the NO2∕NOx ratio.
Overall, the error of the assimilation results depends on the accuracy of the air quality model, the number of assimilated observations, the quality of observations, and the distance to the observation location. A reasonable approximation of the model covariance matrix is found by assuming the model covariance to be isotropic and by fitting correlation lengths along the downwind and crosswind axes for every hour. Finding a more realistic description of the model covariance matrix will better suppress the introduction of bias by the assimilation and will be subject to future research.
For near-real-time monitoring and forecasting of air quality the CAMS ensemble analysis must be changed for the ensemble forecast. Instead of observation-based meteorology one should use data from local or global numerical weather prediction models, e.g. from the National Centers for Environmental Prediction (the Global Forecast System, GFS; open data) or the European Centre for Medium-Range Weather Forecasts (ECMWF; not open data).
Apart from assessment of historic data such as in this study, Retina has been applied successfully for near-real-time monitoring and forecasting of NO2 in the cities of Amsterdam, Barcelona, and Madrid. Future work includes the implementation of other cities inside and outside of Europe and the application of Retina to other pollutants such as particulate matter.
The data sets used and produced in this study can be accessed by the digital object identifier (DOI) https://doi.org/10.21944/retina-amsterdam-2016 (Mijling, 2020).
The supplement related to this article is available online at: https://doi.org/10.5194/amt-13-4601-2020-supplement.
The author declares that there is no conflict of interest.
The author wishes to acknowledge the people behind the data sources used in this study, most notably GGD Amsterdam (reference measurements), volunteers of the Urban AirQ campaign (low-cost measurements), NDW and Amsterdam Traffic Research Department (traffic data), contributors to OpenStreetMap (road location and classification), CAMS (background concentrations), IGRA and ISD (meteorology), and CBS (population data).
This research has been supported by the European Commission through the Horizon 2020 programme (AirQast; grant no. 776361).
This paper was edited by Dominik Brunner and reviewed by two anonymous referees.
Alphasense: Alphasense Data Sheet for NO2-B43F, April 2016, available at: http://www.alphasense.com/index.php/products/nitrogen-dioxide-2/ (last access: 21 August 2020), 2018.
Beelen, R., Hoek, G., Vienneau, D., Eeftens, M., Dimakopoulou, K., Pedeli, X., Tsai, M.-Y., Künzli, V, Schikowski, T., Marcon, A., Eriksen, K. T., Raaschou-Nielsen, O., Stephanou, Eu., Patelarou, E., Lanki, T., Yli-Tuomi, T., Declercq, Ch., Falq, G, Stempfelet, M., Birk, M., Cyrys, J., von Klot, S., Nádor, G., Varró, M. J., Dėdelė, A., Gražulevičienė, R., Mölter, A., Lindley, S., Madsen, Ch., Cesaroni, G., Ranzi, A., Badaloni, Ch., Hoffmann, B., Nonnemacher, M., Krämer, U., Kuhlbusch, T., Cirach, M., de Nazelle, A., Nieuwenhuijsen, M., Bellander, T., Korek, M., Olsson, D., Strömgren, M., Dons, E., Jerrett, M., Fischer, P., Wang, M., Brunekreef, B., and de Hoogh, K.: Development of NO2 and NOx land use regression models for estimating air pollution exposure in 36 study areas in Europe – The ESCAPE project, Atmo. Environ., 72, 10–23, https://doi.org/10.1016/j.atmosenv.2013.02.037, 2013.
CAMS: Copernicus Atmosphere Monitoring System, European-scale air quality analysis from model ensemble, available at: https://atmosphere.copernicus.eu/data (last access: 25 October 2019), 2019.
CBS: Statistics Netherlands, Statistische gegevens per vierkant 2000–2014, available at: https://www.cbs.nl/nl-nl/dossier/nederland-regionaal/gemeente/ruimtelijke-statistieken (last access: 25 October 2019), 2019.
Cimorelli, A. J., Perry, S. G., Venkatram, A., Weil, J. C., Paine, R. J., Wilson, R. B., Lee, R. F., Peters, W. D., and Brode, R. W.: AERMOD: A dispersion model for industrial source applications Part I: General model formulation and boundary layer characterization, J. Appl. Meteor., 44, 682–693, 2004.
Daley, R.: Atmospheric data analysis, Cambridge Atmospheric and Space Science Series, Cambridge University Press, Cambridge, https://doi.org/10.1002/joc.3370120708, 2019.
Denby, B. R.: Mapping of NO2 concentrations in Bergen (2012–2014), METreport No. 12/15, Norwegian Meteorological Institute, ISSN 2387-4201, 2015.
Durre, I., Vose, R. S., and Wuertz, D. B.: Overview of the Integrated Global Radiosonde Archive, J. Clim., 19, 53–68, 2006.
EPA: Technical support document (TSD) for NO2-related AERMOD modifications, U.S. Environmental Protection Agency, EPA-454/B-15-004, July 2015, 2015.
EPA: AERMOD Model Formulation and Evaluation, EPA-454/R-18-003, April 2018, available at: https://www3.epa.gov/ttn/scram/models/aermod/aermod_mfed.pdf (last access: 21 August 2020), 2018.
EPA: User's Guide for the AERMOD Meteorological Preprocessor (AERMET), EPA-454/B-19-028, August 2019, available at: https://www3.epa.gov/ttn/scram/7thconf/aermod/aermet_userguide.pdf (last access: 21 August 2020), 2019.
GGD: Foutenbeschouwing (revisie) kalibratie van eerstelijns standaard, Public Health Service of Amsterdam (GGD), GGD/LO 14-1134, July 2014, 2014 (in Dutch).
Harrison, R. M.: Urban atmospheric chemistry: a very special case for study, Nature, npj Clim. Atmos. Sci., 20175, 2397–3722, https://doi.org/10.1038/s41612-017-0010-8, 2018.
Ide, K., Courtier, P., Ghil, M., and Lorenc, A. C.: Unified notation for data assimilation: Operational, sequential and variational, J. Met. Soc. Japan, 75, 181–189, 1997.
IGRA: National Oceanic and Atmospheric Administration, Integrated Global Radiosonde Archive, version 2, available at: https://www.ncdc.noaa.gov/data-access/weather-balloon/integrated-global-radiosonde-archive (last access: 25 October 2019), 2019.
ISD: National Oceanic and Atmospheric Administration, Integrated Surface Database, available at: https://www.ncdc.noaa.gov/isd/data-access (last access: 25 October 2019), 2019.
Janssens-Maenhout, G., Pagliari, V., Guizzardi, D., and Muntean, M.: Global emission inventories in the Emission Database for Global Atmospheric Research (EDGAR) – Manual (I): Gridding: EDGAR emissions distribution on global gridmaps, JRC Technical Reports, 33 pp., https://doi.org/10.2788/81454, 2013.
Lefebvre, W., Fierens, F., Trimpeneers, E., Janssen, S., Van de Vel, K., Deutsch, F., Viaene, P., Vankerkom, J., Dumont, G., Vanpoucke, C., Mensink, C., Peelaerts, W., and Vliegen, J.: Modeling the effects of a speed limit reduction on traffic-related elemental carbon (EC) concentrations and population exposure to EC, Atmos. Environ., 45, 197–207, https://doi.org/10.1016/j.atmosenv.2010.09.026, 2011.
Lelieveld, J., Haines, A., and Pozzer, A.: Age-dependent health risk from ambient air pollution: a modelling and data analysis of childhood mortality in middle-income and low-income countries, Lancet Planet Health, 2, e292–e300, 2018.
Liu, F., Beirle, S., Zhang, Q., Dörner, S., He, K., and Wagner, T.: NOx lifetimes and emissions of cities and power plants in polluted background estimated by satellite observations, Atmos. Chem. Phys., 16, 5283–5298, https://doi.org/10.5194/acp-16-5283-2016, 2016.
Makido, Y., Dhakal, S., and Yamagata, Y.: Relationship between urban form and CO2 emissions: Evidence from fifty Japanese cities, Urban Climate, 2, 55–67, https://doi.org/10.1016/j.uclim.2012.10.006, 2012.
Marécal, V., Peuch, V.-H., Andersson, C., Andersson, S., Arteta, J., Beekmann, M., Benedictow, A., Bergström, R., Bessagnet, B., Cansado, A., Chéroux, F., Colette, A., Coman, A., Curier, R. L., Denier van der Gon, H. A. C., Drouin, A., Elbern, H., Emili, E., Engelen, R. J., Eskes, H. J., Foret, G., Friese, E., Gauss, M., Giannaros, C., Guth, J., Joly, M., Jaumouillé, E., Josse, B., Kadygrov, N., Kaiser, J. W., Krajsek, K., Kuenen, J., Kumar, U., Liora, N., Lopez, E., Malherbe, L., Martinez, I., Melas, D., Meleux, F., Menut, L., Moinat, P., Morales, T., Parmentier, J., Piacentini, A., Plu, M., Poupkou, A., Queguiner, S., Robertson, L., Rouïl, L., Schaap, M., Segers, A., Sofiev, M., Tarasson, L., Thomas, M., Timmermans, R., Valdebenito, Á., van Velthoven, P., van Versendaal, R., Vira, J., and Ung, A.: A regional air quality forecasting system over Europe: the MACC-II daily ensemble production, Geosci. Model Dev., 8, 2777–2813, https://doi.org/10.5194/gmd-8-2777-2015, 2015.
Mijling, B.: Data sets used in the manuscript “High-resolution mapping of urban air quality with heterogeneous observations: a new methodology and its application to Amsterdam”, Royal Netherlands Meteorological Institute (KNMI), https://doi.org/10.21944/retina-amsterdam-2016, 2020.
Mijling, B., Jiang, Q., de Jonge, D., and Bocconi, S.: Field calibration of electrochemical NO2 sensors in a citizen science context, Atmos. Meas. Tech., 11, 1297–1312, https://doi.org/10.5194/amt-11-1297-2018, 2018.
NDW: National Data Warehouse for Traffic Information, Historical data, available at: https://www.ndw.nu/pagina/en/78/database (last access: 25 October 2019), 2019.
OSM: OpenStreetMap contributors, Planet dump, available at: https://planet.osm.org (last access: 21 August 2020), https://www.openstreetmap.org (last access: 21 August 2020), 2017.
Schiavina, M., Freire, S., and MacManus, K.: GHS population grid multitemporal (1975, 1990, 2000, 2015) R2019A. European Commission, Joint Research Centre (JRC), https://doi.org/10.2905/42E8BE89-54FF-464E-BE7B-BF9E64DA5218, 2019.
Schneider, P., Castell, N., Vogt, M., Dauge, F. R., Lahoz,, W. A., and Bartonova, A.: Mapping urban air quality in near real-time using observations from low-cost sensors and model information, Environ. Int., 106, 234–247, https://doi.org/10.1016/j.envint.2017.05.005, 2017.
Schneider, P., Bartonova, A., Castell, N., Dauge, F. R., Gerboles, M., Hagler, G. S. W., Hüglin, Ch., Jones, R. L., Khan, S., Lewis, A. C., Mijling, B., Müller, M., Penza, M., Spinelle, L., Stacey, B., Vogt, M., Wesseling, J., and Williams, R. W.: Toward a Unified Terminology of Processing Levels for Low-Cost Air-Quality Sensors, Environ. Sci. Technol., 53, 8485–8487, https://doi.org/10.1021/acs.est.9b03950, 2019.
Smith, A., Lott, N., and Vose, R.: The Integrated Surface Database: Recent Developments and Partnerships, B. Am. Meteorol. Soc., 92, 704–708, https://doi.org/10.1175/2011BAMS3015.1, 2011.
Sokhi, R. S., Middleton, D. R., and Luhana, L.: Review of methods for NO to NO2 conversion in plumes at short ranges, Science Report: SC030171/SR2, Environment Agency, Bristol, United Kingdom, 2007.
Tilloy, A., Mallet, V., Poulet, D., Pesin, C., and Brocheton, F.: BLUE-based NO2 data assimilation at urban scale, J. Geophys. Res.-Atmos., 118, 2031–2040, https://doi.org/10.1002/jgrd.50233, 2013.
WebMET: SAMSON Surface Met Data, available at: http://www.webmet.com/MetGuide/Samson.html (last access: 25 October 2019), 2019a.
WebMET: TD6201 – Upper Air Data for AERMOD, available at: http://www.webmet.com/MetGuide/TD6200.html (last access: 25 October 2019), 2019b.
WHO: Global Urban Ambient Air Pollution Database (update 2016), World Health Organization, available at: https://www.who.int/airpollution/data/cities-2016/en/ (last access: 25 October 2019), 2016.
WMO: Low-cost sensors for the measurement of atmospheric composition: overview of topic and future applications, WMO-No. 1215, edited by: Lewis, A. C., Schneidemesser, E., and Peltier, R. E., World Meteorological Organization, 2018.
- Abstract
- Introduction
- Air quality measurements
- Setting up a versatile urban-air-quality model
- Calibrating the model
- Assimilation of observations
- Validation of simulation and assimilation
- Added value of low-cost sensors
- Discussion and conclusions
- Data availability
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Introduction
- Air quality measurements
- Setting up a versatile urban-air-quality model
- Calibrating the model
- Assimilation of observations
- Validation of simulation and assimilation
- Added value of low-cost sensors
- Discussion and conclusions
- Data availability
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement