the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 12 Nov 2021
| 12 Nov 2021
Global ensemble of temperatures over 1850–2018: quantification of uncertainties in observations, coverage, and spatial modeling (GETQUOCS)
Maryam Ilyas
Douglas Nychka
Chris Brierley
Serge Guillas
Instrumental global temperature records are derived from the network of in situ measurements of land and sea surface temperatures. This observational evidence is seen as being fundamental to climate science. Therefore, the accuracy of these measurements is of prime importance for the analysis of temperature variability. There are spatial gaps in the distribution of instrumental temperature measurements across the globe. This lack of spatial coverage introduces coverage error. An approximate Bayesian computation based multi-resolution lattice kriging is developed and used to quantify the coverage errors through the variance of the spatial process at multiple spatial scales. It critically accounts for the uncertainties in the parameters of this advanced spatial statistics model itself, thereby providing, for the first time, a full description of both the spatial coverage uncertainties along with the uncertainties in the modeling of these spatial gaps. These coverage errors are combined with the existing estimates of uncertainties due to observational issues at each station location. It results in an ensemble of 100 000 monthly temperatures fields over the entire globe that samples the combination of coverage, parametric and observational uncertainties from 1850 to 2018 over a grid.
- Article
(13161 KB) - Full-text XML
- BibTeX
- EndNote





Instrumental surface temperature data sets are frequently used to determine the variability in changing surface temperatures on Earth (e.g., Hansen et al., 2010; Morice et al., 2012; Menne et al., 2018). Climate models also use instrumental observations for accurate assessment of various climate phenomena (e.g., Glanemann et al., 2020). Temperature databases are generally created by blending the land and sea surface temperature records. The land component of the data sets is mostly collected from the global historical network of meteorological stations (e.g., Jones et al., 2012). Much of these data are derived from the World Meteorological Organization (WMO) and Global Climate Observing System (GCOS) initiatives. On the other hand, sea surface temperatures are largely compiled by the International Comprehensive Ocean-Atmosphere Data Set (ICOADS; Woodruff et al., 2011). These are collected from ships and drifting buoys (e.g., Kennedy et al., 2011b).
These raw temperature estimates are post-processed by removing biases from them (Dunn et al., 2014). In a first step of quality control, noise originating from instrumental or observer error is removed (Dunn et al., 2016). After this, systematic biases that arise from station movements or incorrect station merges, changes in instruments and observing practices and land use changes around stations (more commonly known as urbanization impacts) are removed (Dunn et al., 2016). Such a homogenization process (Domonkos and Coll, 2017) aims to remove or at least reduce the non-climatic signals that will likely affect the genuine data characteristics (e.g., Hausfather et al., 2016; Cao et al., 2017).
Blended land and sea surface temperature data are generated by a variety of organizations. These include the following: the National Oceanic and Atmospheric Administration (NOAA) Global Surface Temperature (NOAAGlobalTemp) data set (Smith et al., 2008; Vose et al., 2012; Zhang et al., 2019; Vose et al., 2021), the Goddard Institute for Space Studies (GISS) surface temperature anomalies by the National Aeronautics and Space Administration (NASA; Hansen et al., 2010; Lenssen et al., 2019), temperature anomalies provided by the Japanese Meteorological Agency (JMA; Ishihara, 2006), the HadCRUT5 temperature anomalies by the Met Office Hadley Centre and the University of East Anglia Climatic Research Unit (Morice et al., 2012, 2021) and the Berkeley Earth Surface Temperature (BEST) project by Rohde and Hausfather (2020). Each group compiles these monthly temperature products using somewhat different input data and extensively different quality control and homogenization procedures (e.g., Rohde, 2013; Jones, 2016).
The GISS temperatures make substantial use of satellite nightlight data (Hansen et al., 2010; Lenssen et al., 2019) for bias adjustment of urban areas. However, NOAAGlobalTemp, HadCRUT5 and BEST use no satellite data at all (Rohde and Hausfather, 2020; Vose et al., 2021; Morice et al., 2021). These data sets are also different in terms of their starting years, namely 1850–present for HadCRUT and BEST, 1880–present for GISS and NOAA, and 1891–present for JMA. The spatial resolution is different as well. Each group also employs different methods of averaging to derive gridded temperature products from in situ measurements (Jones, 2016; McKinnon et al., 2017).
In addition to these methodological differences, spatial coverage is also being treated differently by these groups (Huang et al., 2020). The HadCRUT4 data set does not interpolate over grid boxes having missing observations. The sea component of JMA grid estimates are based on optimally interpolated (i.e., kriging) sea surface temperature anomalies (Ishii et al., 2005; Kennedy, 2014). On the other hand, no spatial interpolation is performed on HadSST3 (Rayner et al., 2006) and CRUTEM4 (Jones et al., 2012), which are the land and sea components of HadCRUT4 data set. The NOAAGlobalTemp (Vose et al., 2021) data set is based on a nonparametric smoothing process and empirical orthogonal teleconnections. The reconstruction combines a low-frequency spatial running average and a high-frequency reduced space analysis. For broader spatial coverage, the GISS uses a linear distance weighting with data from all the stations up to 1200 km of the prediction location (Hansen et al., 2010). The weight of each sample point decreases linearly from unity to zero. This interpolation scheme computes estimates by weighting the sample points closer to the prediction location greater than those farther away without considering the degree of autocorrelation for those distances. On the other hand, the JMA (Ishii et al., 2005) ocean records use covariance structure of spatial data and are based on traditional kriging. Formal Gaussian process regression is used by the BEST to produce spatially complete temperature estimates (Rohde et al., 2013). Cowtan and Way (2014) also handle the issue of missing observations and provide a data product that is based on HadCRUT4 temperature estimates (Morice et al., 2012). This data set (Cowtan and Way, 2014) consists of spatially dense fields. The unobserved grid cells of HadCRUT4 spatial fields are estimated using a spatial interpolation approach, i.e., ordinary kriging. A newer and more refined version (HadCRUT5) of this data set has recently been created (Morice et al., 2021). HadCRUT4 is not interpolated, but the recently published HadCRUT5 is interpolated (Morice et al., 2012, 2021). Additionally, the compilation of the new HadCRUT5 data set involves a conditional simulation step that incorporates analysis uncertainties into an ensemble. It is important to note that simulation is not involved in the other data sets discussed before for calculating the uncertainty estimates in their interpolation.
Recently, a new monthly temperature data set was created (Ilyas et al., 2017). It employs the multi-resolution lattice kriging approach (Nychka et al., 2015) that captures variation at multiple scales of the spatial process. This multi-resolution model quantifies gridded uncertainties in global temperatures due to the gaps in spatial coverage. It results in a 10 000 member ensemble of monthly temperatures over the entire globe. These are spatially dense, equally plausible fields that sample the combination of observational and coverage uncertainties. The data are open access and freely available at https://oasishub.co/dataset/global-monthly-temperature-ensemble-1850-to-2016 (last access: 7 November 2021).
This paper provides a substantial update on the Ilyas et al. (2017) data set. Here, a new version of this data set is produced that incorporates the uncertainties in the statistical modeling itself (i.e., parametric uncertainties) in addition to the observational and coverage errors. To account for the model parametric uncertainties, an approximate Bayesian inference methodology is proposed that extends the multi-resolution lattice kriging (Nychka et al., 2015). It is based on the variogram, which is a measure of spatial variability between spatial observations as a function of spatial distance.
2.1 Multi-resolution lattice kriging using ABC
The multi-resolution lattice kriging (MRLK) model was introduced by Nychka et al. (2015). It models spatial observations as a sum of a Gaussian process, a linear trend and a measurement error term. The MRLK can flexibly adjust to complicated shapes of the spatial domain and has the property of approximating standard covariance functions. This methodology extends spatial methods to very large data sets accounting for all the scales and for the goals of spatial inference and prediction. Indeed, it is computationally efficient for large data sets by exploiting sparsity in precision matrices. The underlying spatial process is a sum of independent processes, each of which is a linear combination of the chosen basis functions. The basis functions are fixed and coefficients of the basis functions are random.
Consider observations y(x) at n spatial locations in the spatial domain D. The aim is to predict the underlying process at an arbitrary location x∈D and to estimate the uncertainty in the prediction. For x∈D, in the following:
where d is the mean, and ϵ is the error term. The unknown spatial process g(x) is assumed to be the sum of L independent processes having different scales of spatial dependence. Each process is a linear combination of m basis functions, where m(l) is the number of basis functions at level l, as follows:
The basis functions (ϕj,l) are fixed. These are constructed at each level using the unimodal and symmetric radial basis functions. Radial basis functions are functions that depend only on the distance from the center.
The inference methodology (Nychka et al., 2015) is the direct consequence of maximizing the likelihood function. This inference framework does not account for the uncertainty in the model parameters within the MRLK (Nychka et al., 2015). Here, we estimate the MRLK parameters and quantify uncertainty in these parameters. For this purpose, a Bayesian framework is created in which the posterior densities of the multi-resolution lattice kriging parameters are estimated using the approximate Bayesian computation (ABC). Our new technique allows for the spatial predictions to be accompanied by a quantification of uncertainties in these predictions that reflect not only the coverage gaps but also the uncertainties in the MRLK parameters.
2.1.1 ABC posterior density estimation
Consider a n-dimensional spatial random variable y(x). The multi-resolution lattice kriging model depends on the unknown p-dimensional parameter θ. The probability distribution of the data, given a specific parameter value θ, is denoted by f(y|θ). If the prior distribution of θ is denoted as π(θ), then the posterior density is given by the following:
Here, , where λ and a.wght are, respectively, the smoothing parameter and autoregressive weights (Nychka et al., 2019). These are the two main parameters of the MRLK. The autoregressive weight (a.wght) is the key covariance parameter. More precisely, it is the spatial autoregressive (SAR) parameter that controls the spatial dependence among lattice points. It is essential for specifying and fitting the spatial model. The smoothness parameter , λ, represents the signal-to-noise ratio; an inappropriate estimate can lead to over- or underfitting a spatial model and can result in imprecise interpolated values and prediction uncertainties (Nychka et al., 2015). The posterior distribution of these parameters, given data, f(θ|y), is approximated using ABC. The ABC acceptance–rejection technique, based on a variogram as a summary statistic, is developed in the next section that is used to approximate the posterior densities.
2.1.2 Variogram-based ABC algorithm
The approximate Bayesian computation (e.g., Busetto and Buhmann, 2009; Beaumont, 2010; Dutta et al., 2017; Beaumont, 2019) is a family of algorithms that deals with the situations where the likelihood of a statistical model is intractable, whereas it is possible to simulate data from the model for a given parameter value. ABC bypasses the evaluation of the likelihood function by comparing observed and simulated data. Additionally, it offers algorithms that are very easy to parallelize. There are several forms of ABC algorithms. The standard rejection algorithm is the classical ABC sampler (e.g., Pritchard et al., 1999; Beaumont et al., 2002). It is widely used, e.g., for model calibration by Gosling et al. (2018). The algorithm is based on drawing values of the parameters from the prior distribution. The data sets are simulated for each draw of parameters, each resulting in a chosen summary statistic. A distance metric is computed between the summary statistic of the observed and simulated data. The parameters that produce distances less than a tolerance threshold are retained. These accepted parameters form a sample from the approximate posterior distribution.
The basic idea of ABC is to simulate from the multi-resolution lattice kriging model for a given set of parameters θ. Simulations are run for a large number of parameters to be able to produce meaningful posterior distributions. The parameter values are retained for simulated data y∗ that match the observed data y up to a tolerance threshold. For the similarity metric, we choose the sum of the squared differences between the semivariance at various lag distances of observed (γ(h)) and simulated (γ∗(h)) data. Indeed, these semivariances are traditional descriptors of the correlations across space.

Figure 1ABC acceptance–rejection algorithm using a variogram as a summary statistic for multi-resolution lattice kriging.
The empirical semivariogram is typically computed by aggregating spatial pairs with similar distances. For this, the distances are partitioned into intervals called bins. The average distance between each bin is referred as lag distance h. The semivariance is half of the average squared differences between the observations for the point pairs falling in each bin. The standard rules are observed while computing the semivariogram. For example, the number of point pairs at each lag distance is at least 30. The semivariogram is computed up to half of the maximum distance between the points over the whole spatial domain. The retained , a.wght∗]T are such that .
2.2 Spatial estimate based on ABC posteriors
The existing MRLK inference methodology (Nychka et al., 2015) uses maximum likelihood estimators of smoothing parameter , λ, and autoregressive weights, a.wght. The ABC-based inference methodology proposed here accounts for the posterior densities (not joint pointwise estimates) while making spatial predictions. For the full spatial estimate, the ABC posterior distributions of the MRLK model parameters () are used to determine the conditional distribution of the coefficient c in Eq. (2). For the kth posterior sample, in the following:
Here, the mean (d) and process variance (ρ) are estimated using the maximum likelihood approach. The ABC posteriors of these parameters (ρ and d) are not considered in this paper. Hence, the spatial predictions in ABC-based multi-resolution lattice kriging are carried out using Eq. (5) and the associated uncertainties are evaluated based on Eq. (6) below, as follows:
The primary data used in this paper are the well-known HadCRUT4 (version 4.5.0.0) temperature anomalies (Morice et al., 2012). It is a combination of global land surface air temperature (CRUTEM4; Jones et al., 2012) and sea surface monthly temperatures (HadSST3; Kennedy et al., 2011a, b; Kennedy, 2014). The HadCRUT4 database consists of temperature anomalies with respect to the baseline (1961–1990). Monthly temperatures are provided, beginning from 1850, over a grid. The average temperature anomalies of the stations falling within each grid are provided (Morice et al., 2012). The data set is updated on monthly basis to provide the updated climatic state. The gridded temperature estimates and time series can be downloaded from the Met Office website (https://www.metoffice.gov.uk/hadobs/hadcrut4/; last access: 7 November 2021).
3.1 Ensemble members
Errors in weather observations can either be random or systematic. They can lead to a complex spatial and temporal correlation structures in the gridded data. An ensemble approach is used by Morice et al. (2012) to represent the observational uncertainties in HadCRUT4 data. The ensemble methodology characterizes the uncertainties that are spatially and temporally correlated. The realizations of an ensemble are typically formed by combining the observed data with multiple realizations drawn from the uncertainty model. This uncertainty model describes spatial and temporal interdependencies. This allows one-to-one blending of 100 realizations of HadSST3 and 100 realizations of CRUTEM4, resulting in 100 realizations of the HadCRUT ensemble data. Together, these HadCRUT ensemble members represent the distribution of observational uncertainties that arise due to the non-climatic factors.
3.2 Observational uncertainties
Systematic observational errors emerge from the non-climatic factors. The HadCRUT ensemble data are created by blending the sea surface temperature anomalies from HadSST3 (Kennedy et al., 2011b, a; Kennedy, 2014) and land temperature anomalies from CRUTEM4 (Jones et al., 2012). This approach follows the use of ensemble methodology to represent a range of observational uncertainties. HadSST3 is an ensemble data that is based on the Rayner et al. (2006) uncertainty model. CRUTEM4 is not available as an ensemble data set (Jones et al., 2012). Therefore, it was converted to an ensemble data set by Morice et al. (2012) using the Brohan et al. (2006) uncertainty model.
The sea surface temperature anomalies are typically being measured using engine room intake measurements, bucket measurements and drifting buoys. The HadSST3 ensemble is used as the sea component of HadCRUT data. This ensemble is generated by drawing the bias adjustment realizations for three measurement types. Therefore, the ensemble samples the systematic observational errors in sea surface temperature anomalies (Rayner et al., 2006; Kennedy et al., 2011a; Kennedy, 2014). Below are the components of the error model used to characterize the observational uncertainties in the land measurements of HadCRUT. This error model also generates an ensemble version of CRUTEM4 (Morice et al., 2012).
-
Homogenization adjustment error. Systematic biases occur due to changing station locations, measurement time, equipment and methods to calculate monthly averages. Homogenization adjustments are applied to the data to remove these non-climatic signals. These adjustments typically do not fully capture the systematic biases. This residual error is referred to as the homogenization adjustment error. It is modeled using a Gaussian distribution (Brohan et al., 2006; Morice et al., 2012).
-
Climatological error. For each station, temperature anomalies are computed with respect to the base period 1961–1990. Typically, data are not available for all the months in the 30-year climatological period. These missing observations introduce climatological error in the estimates of the base period. The climatological error is modeled using a Gaussian distribution (Morice et al., 2012).
-
Urbanization bias. The urban areas absorb and store more heat than the rural areas (as evidenced during the last few decades). This creates a heating effect that is known as the urban heat effect. The urbanization effect induces a warming bias in the temperature records. The error model represents the effects of potential residual biases when using station records that have been screened for urbanization. This bias is referred to as urbanization bias. In HadCRUT, the effects of urbanization are modeled on a global scale instead of considering these effects on measurement stations. For this, a truncated Gaussian distribution is used. The large-scale urbanization bias in temperatures is adjusted for all the years beyond 1900 (Morice et al., 2012).
-
Exposure bias. It has been observed that bias in temperatures can be introduced due to the station site and exposure. Changes in instrumentation can broadly be grouped into two broad classes. There were few standards for thermometer exposure or instrument shelters before the 19th century. By the early 20th century, these thatched (or covered) enclosures were largely replaced by free-standing louvered shelters or Stevenson-type screens (Trewin, 2010). A Stevenson-type screen is a shelter or enclosure that protects meteorological instruments from precipitation and direct heat radiation. However, it allows free circulation of the air. Changes in the thermometers, exposure to the atmosphere and shelters from direct or indirect solar radiation introduces exposure bias in temperatures (Parker, 1994; Moberg et al., 2003). This error in temperatures is modeled on a regional scale in HadCRUT using a Gaussian distribution (Morice et al., 2012).
In addition to the large-scale bias terms that are discussed above, Morice et al. (2012) provide the measurement and grid sampling uncertainty components. These are particularly important for marine regions, as ship/buoy movement leads to spatially correlated errors. HadCRUT4 does not include these in the ensemble. These are provided as additional spatial error covariance matrices. The data set (Sect. 4) created in this paper uses HadCRUT4 ensembles only. Stated differently, all the components of the HadCRUT4 uncertainty model are not used in this study, and only the uncertainties encoded in the HadCRUT4 ensemble members are used.
The ensemble temperature data set created by Ilyas et al. (2017) presumed perfect knowledge of multi-resolution lattice kriging covariance parameters. The approximate Bayesian computation based on multi-resolution lattice kriging developed in Sect. 2.1 is applied to the sparse HadCRUT4 ensemble data (Sect. 3; Morice et al., 2012). As a result of this, a new 100 000 member ensemble data set is created. It is an update to the data set discussed in Ilyas et al. (2017).
The key difference between the two data sets is the inference methodology. The updated data set is produced by using the ABC-based posterior densities of the multi-resolution lattice kriging covariance parameters, whereas the first data set used pointwise estimates obtained via a likelihood approach. The use of the posterior distribution of the model parameters creates a data set that accounts for the multi-resolution lattice kriging parametric uncertainties.
4.1 ABC posteriors and model parameters
The HadCRUT ensemble data set samples observational uncertainties in the instrumental temperature records (Morice et al., 2012). Similar to the first version of Ilyas et al. (2017), the updated data set is based on HadCRUT4 ensemble members. For the updated version, the ABC posterior densities of the smoothing parameter and autoregressive weights are determined. These are identified for each of the 2028 months from January 1850 to December 2018. The ABC algorithm (Fig. 1) based on the variogram is used to compute the posterior distributions. Uniform priors are considered, i.e., U(0.001,4) and U(1,4) for the smoothing parameter and autoregressive weight, respectively. In particular, priors put on autoregressive weight assume that ω (Nychka et al., 2019) follows a uniform distribution over the interval [−4.5, 0.55]. This choice covers a useful span of spatial correlations when ω is translated back into the a.wght (i.e., a.wght ) parameter and, subsequently, into the dependence of the field at the lattice points. The tolerance threshold t is chosen to correspond to the 4 % acceptance rate with 250 iterations. It results in 10 hyperparameter sample draws from the posterior densities.
Fitting the multi-resolution lattice kriging model requires a choice of the basis functions and marginal spatial variance. The multi-resolution basis is the same as the one that was chosen for the earlier version of the ensemble (Ilyas et al., 2017). So, a three-level model is chosen such that the number of basis function is greater than the number of spatial locations. The value of α, i.e., the marginal spatial variance (Nychka et al., 2015), is estimated as . This is computed over the field with the maximum available information, i.e., February 1988. This varies slightly across time. The values of the α parameter for February 1988 are the relative variances between different resolution levels. The decay of these for a finer resolution fix the smoothness of the field, and because these are difficult to estimate, they were not emphasized in the analysis, and the correlation range parameter, a.wght, was given more attention. February 1988 has the most complete data field. Therefore, it was assumed that the smoothness reflected in the α parameters are consistent across different times. It results from the maximum likelihood estimation as the algorithm in Fig. 1 is not yet extended to obtain posteriors of α, as this parameter has little influence on the uncertainties compared to the others. Other parameters are estimated for each monthly field since the spatial characteristics can vary considerably. The geodesic grid and the great circle distance is used to handle the spherical domain. To implement multi-resolution lattice kriging, the LatticeKrig R package version 6.4 is used. As an example, the posterior densities of smoothing parameter , λ, and autoregressive weight , a.wght, are shown in Fig. 2 for one spatial field. There are two other examples that are presented in the appendix (Figs. A1 and A2). These posterior distributions result from the HadCRUT4 median spatial field with the minimum spatial coverage, i.e., May 1861. The month with the poorest spatial coverage was chosen to illustrate the advantages (Figs. 3 and 4) of using a more refined spatial approach (Sect. 2.1). It is important to note that hyperparameter estimates are global. These are estimated independently for each field without using any regional estimates. Additionally, temperature anomaly variability is assumed identical at all locations over land and sea. Also, it is a space-only model (not space–time). There is no accounting for the persistence of temperatures used to aid reconstruction or accounted for in uncertainty estimates.
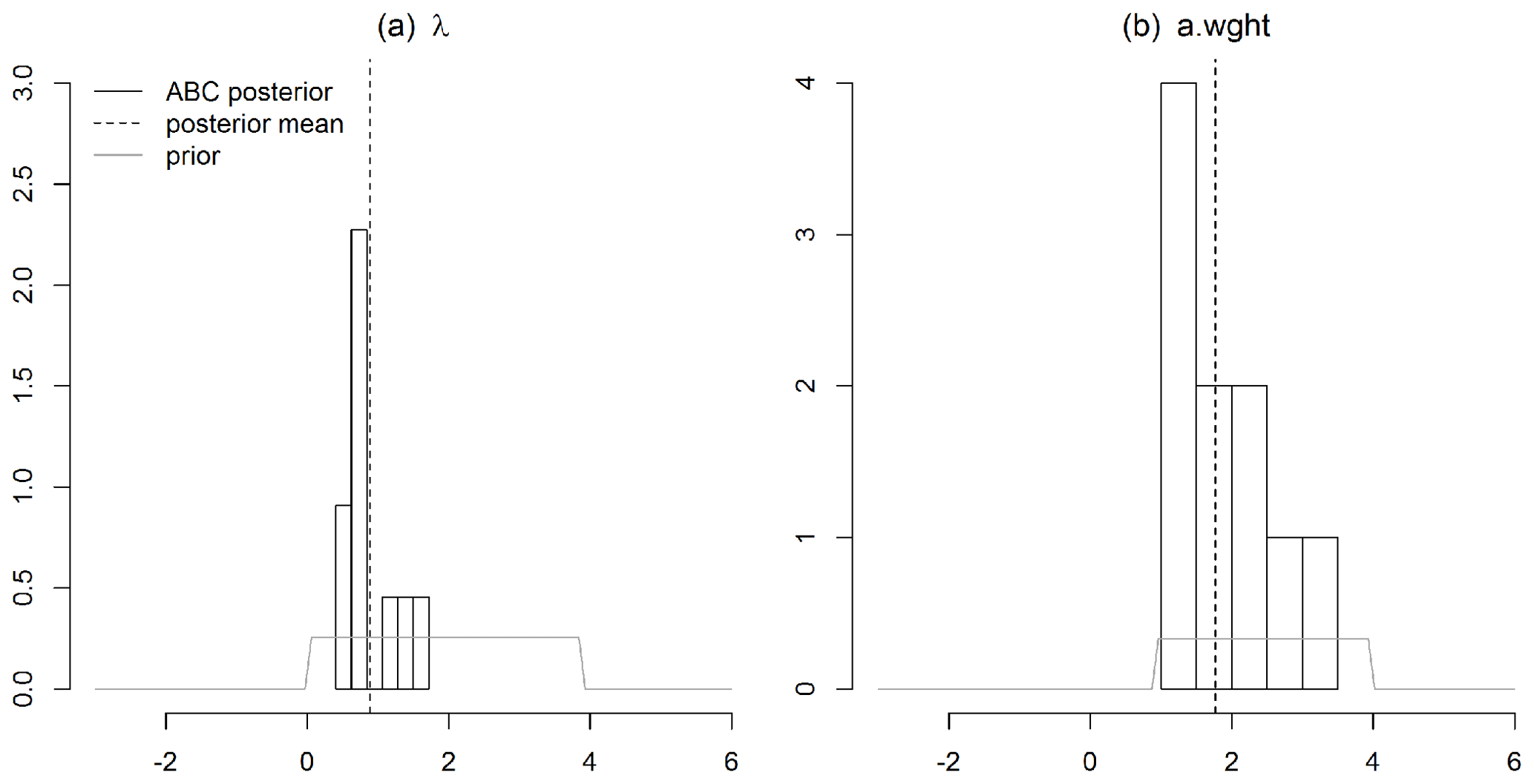
Figure 2Posterior densities of (a) the smoothing parameter, λ, and (b) the autoregressive weight, a.wght, for a HadCRUT4 spatial field with the minimum spatial coverage, i.e., May 1861.
4.2 Spatial field with minimum coverage
ABC-based multi-resolution lattice kriging (Fig. 1) is used to predict this sparse spatial field. The spatial predictions and associated uncertainties are shown in Figs. 3a and 4a, respectively. The spatial predictions (Fig. 3a) are computed using the available spatial observations, multi-resolution basis functions (Sect. 4.1) and ABC posterior distributions of autoregressive weights, a.wght, and smoothing parameter , λ, (Fig. 2). Equation (5) is used for the calculation of the spatial predictor. For comparison with the previous reconstruction (Ilyas et al., 2017) of this spatial field, the spatial predictions based on the profile maximum likelihood approach are presented in Fig. 3b.
The value of autoregressive weight, a.wght, used in the old ensemble is 8.95. This value is much greater than the range of the posterior distribution of a.wght (Fig. 2). This is due to the fact that the versions of the LatticeKrig package used here and in old ensemble (Ilyas et al., 2017) are 6.4 and 6.2, respectively. LatticeKrig version 6.4 is mainly an update on the LKrig function for spherical spatial domains. The minimum value of autoregressive weights in version 6.2 is restricted to be greater than 6 to avoid artifacts in the covariance. This restriction is removed in version 6.4, and the weights are updated for improved specification of covariance over the sphere (Nychka et al., 2019).
The differences in these reconstructions (Fig. 3c) indicate that the spatial predictions using ABC-based multi-resolution lattice kriging (Fig. 3a) generally show anomalies in temperature from the baseline climate that are smaller in magnitude compared to the likelihood-based reconstruction (Fig. 3b). The uncertainties in predictions are shown in Fig. 4a that result from ABC-based multi-resolution lattice kriging. These uncertainties in the predictions are computed using Eq. (6). Figure 4c compares these uncertainties with those resulting from the previous reconstruction (Fig. 4b). It can be observed that ABC-based multi-resolution lattice kriging is producing higher uncertainty estimates close to the observed spatial sites. This was expected since there is now account of more sources of uncertainty. However, the unobserved grid locations are showing less uncertainties that are resulting from ABC-based multi-resolution lattice kriging.
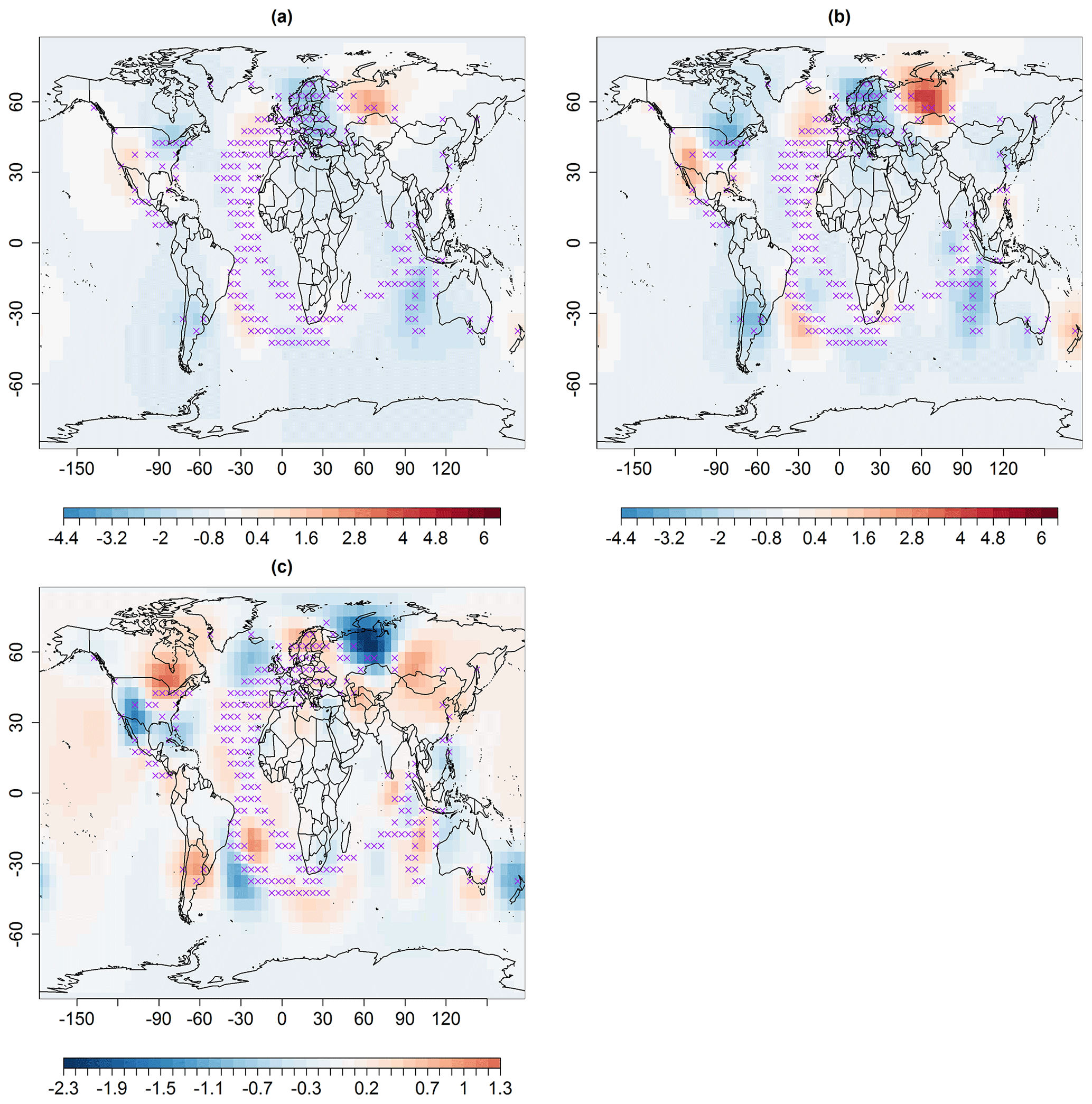
Figure 3Median spatial predictions (in degrees Celsius) for May 1861 using multi-resolution lattice kriging based on (a) ABC, using a variogram (Sect. 2.1), and (b) the profile maximum likelihood approach (Nychka et al., 2015) used to create data in Ilyas et al. (2017). (c) The difference in panels (a) and (b), i.e., panels (a)–(b). The × signs show observed spatial sites (purple).
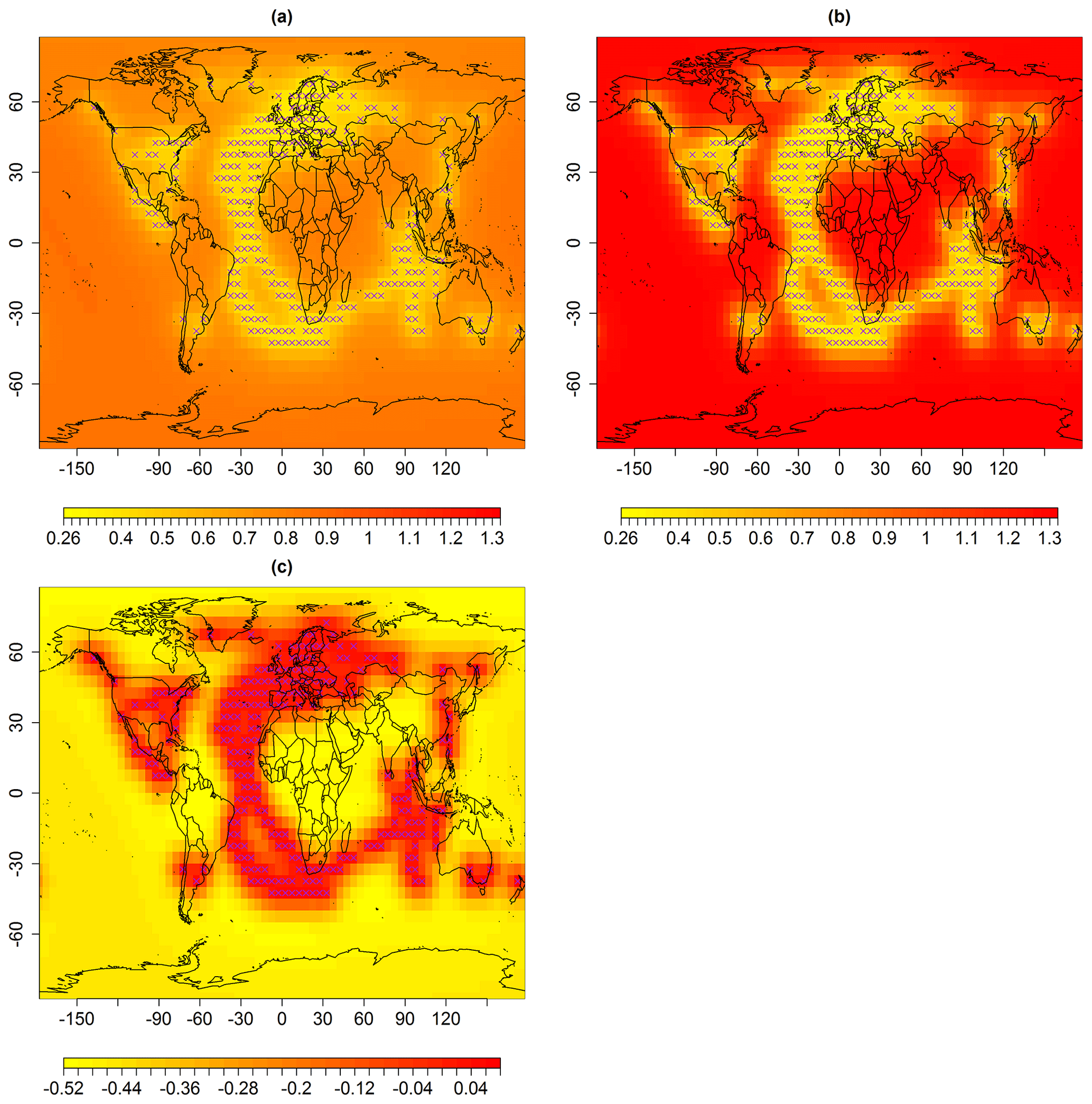
Figure 4Standard error (uncertainties) in degrees Celsius associated with spatial predictions for median May 1861, using multi-resolution lattice kriging based on (a) ABC, using a variogram (Sect. 2.1), and (b) the profile maximum likelihood approach (Nychka et al., 2015) used to create data in Ilyas et al. (2017). (c) The difference in panels (a) and (b), i.e., panels (a)–(b). The × signs show observed spatial sites (purple).
It seems like the ABC-based multi-resolution lattice kriging is leaning towards more of the observational noise variance and less process variance. Additionally, it is possibly due to the fact that LKrig function of LatticeKrig R package has undergone substantial modifications. The spatial estimates and uncertainties of two more fields are presented in Figs. B1 to B4. These fields generally show a similar story, as seen in May 1861. The ABC-based predictions have collapsed to be more certain about a weaker temperature anomaly than seen in the Ilyas et al. (2017) data set. Additionally, the model parameters change with time (Figs. 2, A1, A2). Therefore, the corresponding uncertainty estimates (Figs. 4, B2, B4) for these temperature fields also vary with time, particularly for unobserved spatial sites.
4.3 The 100 000 member hyperparameter ensemble
The ABC posterior distributions and model parameters of the multi-resolution lattice kriging model (Sect. 4.1) are used to generate an ensemble. These ensemble data are based on HadCRUT4 temperature data. The HadCRUT4 monthly data set consists of 100 sparse ensemble members. For each of 100 monthly spatial fields of HadCRUT4, a spatially complete 1000 member ensemble is created that samples the coverage and parametric uncertainties of multi-resolution lattice kriging. The resulting 100 000 ensemble members are referred to as a hyperparameter temperature ensemble data set. The 1000 members of the ensemble generated from each of the 100 HadCRUT4 ensemble members (thus eventually creating fields) are the random fields drawn from the multivariate conditional normal distribution. These are drawn by conditioning on the available HadCRUT4 field measurements, and sampling the multi-resolution lattice kriging covariance model, namely the variogram-based ABC posteriors of autoregressive weights and smoothing parameter. In other words, 100 fields are drawn from the multivariate conditional normal distribution. These are sampled corresponding to each of the 10 draws from the ABC posterior distributions of smoothing parameter and autoregressive weights.
This ensemble data set is generated using high-performance computing due to the computational expense. The HadCRUT4 sparse monthly data set spans from 1850 to 2018, which is 2028 months in total. For each month, the posterior of autoregressive weight, a.wght, and smoothing parameter, λ, are computed using the median ensemble member. Given these posteriors, 1000 coverage samples are drawn for each of 100 HadCRUT4 ensemble members. To achieve sufficiently fast computation, different parts of the data are handled in parallel on different nodes. For this, 100 HadCRUT4 ensemble members are divided into sets of five. It results in 20 sets, each consisting of five members. For one time point, the sampling for 100 HadCRUT4 ensemble members is performed in parallel by submitting 20 shared memory parallel jobs with five threads. Therefore, a single job that performs computations over five ensemble members of a month runs in parallel and takes approximately 66 min. The total number of parallel jobs are . Therefore, the time required to run these jobs is . Typically, six or seven parallel jobs run simultaneously, so it took approximately 8 months of wall clock time to perform these computations.
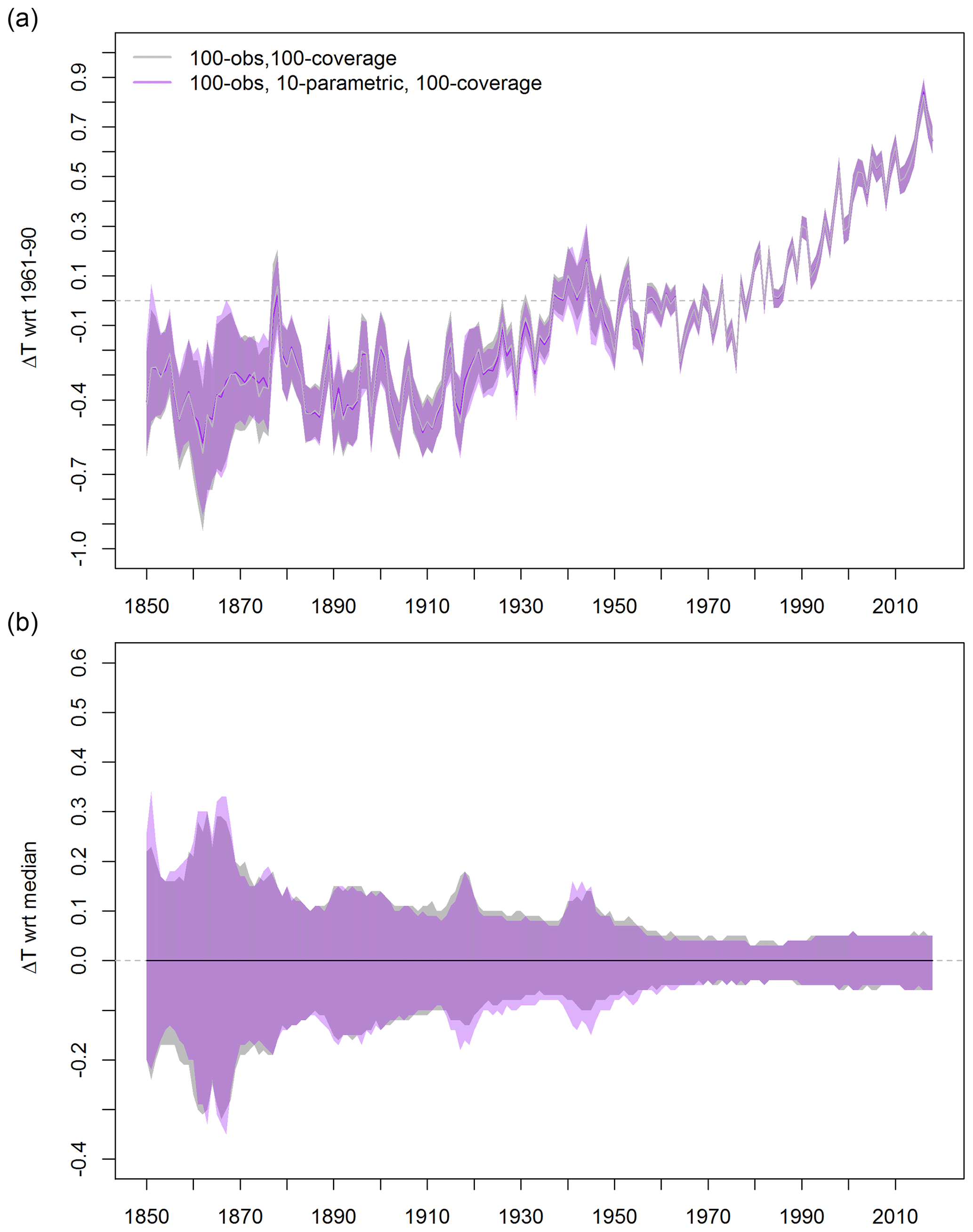
Figure 5Global mean and annual average temperature anomalies in degrees Celsius with respect to the (a) 1961–1990 baseline and (b) median. The 95 % credible (purple) and confidence (gray) interval estimates are based on the data set created in Ilyas et al. (2017) and the hyperparameter ensemble and the data set created in Sect. 4.3.
The global mean temperature time series is computed for the 100 000 member hyperparameter ensemble data described in Sect. 4.3. For each ensemble member, the global mean time series is calculated. Figure 5 represents the annual median time series along with the 95 % credible interval. For comparison, Fig. 5a also presents the median time series and the uncertainties resulting from an earlier version of the ensemble data (Ilyas et al., 2017) which sampled only the combination of observational and coverage uncertainties without uncertainty in the MRLK model. The impact of including parametric uncertainties can be observed from Fig. 5 at a global scale. The overall features of the time series resulting from the hyperparameter ensemble and the first version of the data (Sect. 4.3) are mostly similar (Fig. 5b). Uncertainty ranges appear to be roughly comparable, and of similar magnitude to the quantization in the plot of roughly 0.01 ∘C, but slightly skewed one way or another. The smoothing parameter, λ, is processed to the noise ratio (Nychka et al., 2015). Sampling into high values of the smoothing parameter can give a process with low variance and large measurement noise, which can lead to smaller uncertainties arising from sampling limitations. The lower variance in the ABC analysis field (Fig. 3) suggests that this might be the case.
For easy handling of this large data, a subsample of this hyperparameter ensemble is created using conditioned Latin hypercube sampling (cLHS; Minasny and McBratney, 2006). In practice, Monte Carlo and Latin hypercube sampling approaches are used to draw samples that approximate the underlying distribution. Usually, a large number of samples are required to achieve good accuracy in traditional Monte Carlo (e.g., Pebesma and Heuvelink, 1999; Olsson and Sandberg, 2002; Olsson et al., 2003; Diermanse et al., 2016). Additionally, the Monte Carlo samples can contain some points clustered closely, while other intervals within the space obtain no sample. On the other hand, the Latin hypercube sampling provides a stratified sampling framework for improved coverage of the k-dimensional input space (e.g., McKay et al., 2000; Helton and Davis, 2003; Iman, 2008; Clifford et al., 2014; Shields and Zhang, 2016; Shang et al., 2020). Conditioned Latin hypercube sampling is an attempt to draw a sample that captures the variation in multiple environmental variables. This sample accurately represents the distribution of the environmental variables over the full range.
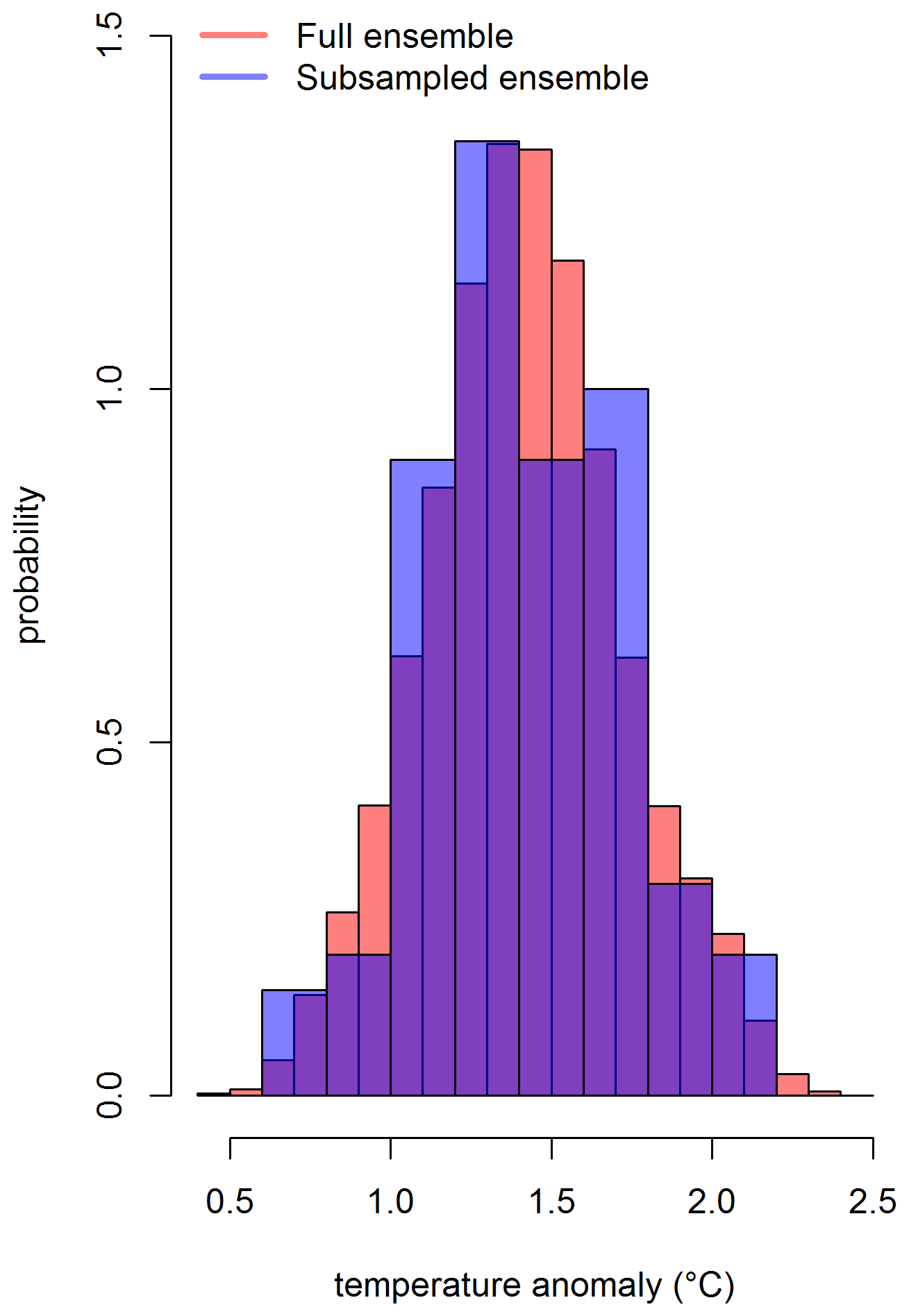
To draw a subsample from 100 000 ensemble members, we considered a set of prominent environmental variables, i.e., monthly area averages and the Intergovernmental Panel on Climate Change (IPCC) AR5 regional means. The conditional Latin hypercube sample is being drawn from the distribution of these environmental variables. The subsample accurately approximates the variation in the set of environmental variables over the full range of these variables. Stated differently, the distributions of the set of environmental variables in the conditioned Latin hypercube sample of size 100 is approximately similar to the distributions of these variables over the full range based on 100 000 ensemble members. It can be observed from the distribution of a grid box that is shown in Figs. 6, C1, and C2 for three different time points. The full ensemble distribution is based on 100 000 grid boxes (Sect. 4.3). The subsample distribution results from the conditioned Latin hypercube subsample of 100 grid boxes. Both the distributions overlap mostly. However, the extreme values at the tails are not being captured by the subsample. Also, it is important to note that the subsample ensemble only captures the variation in the specified environmental variables discussed above (i.e., AR5 regional means and monthly area averages). This subsample may not be suitable for exploring any other locations outside of those regions. In those situations, it might be wise to perform a check using the full hyperparameter ensemble.
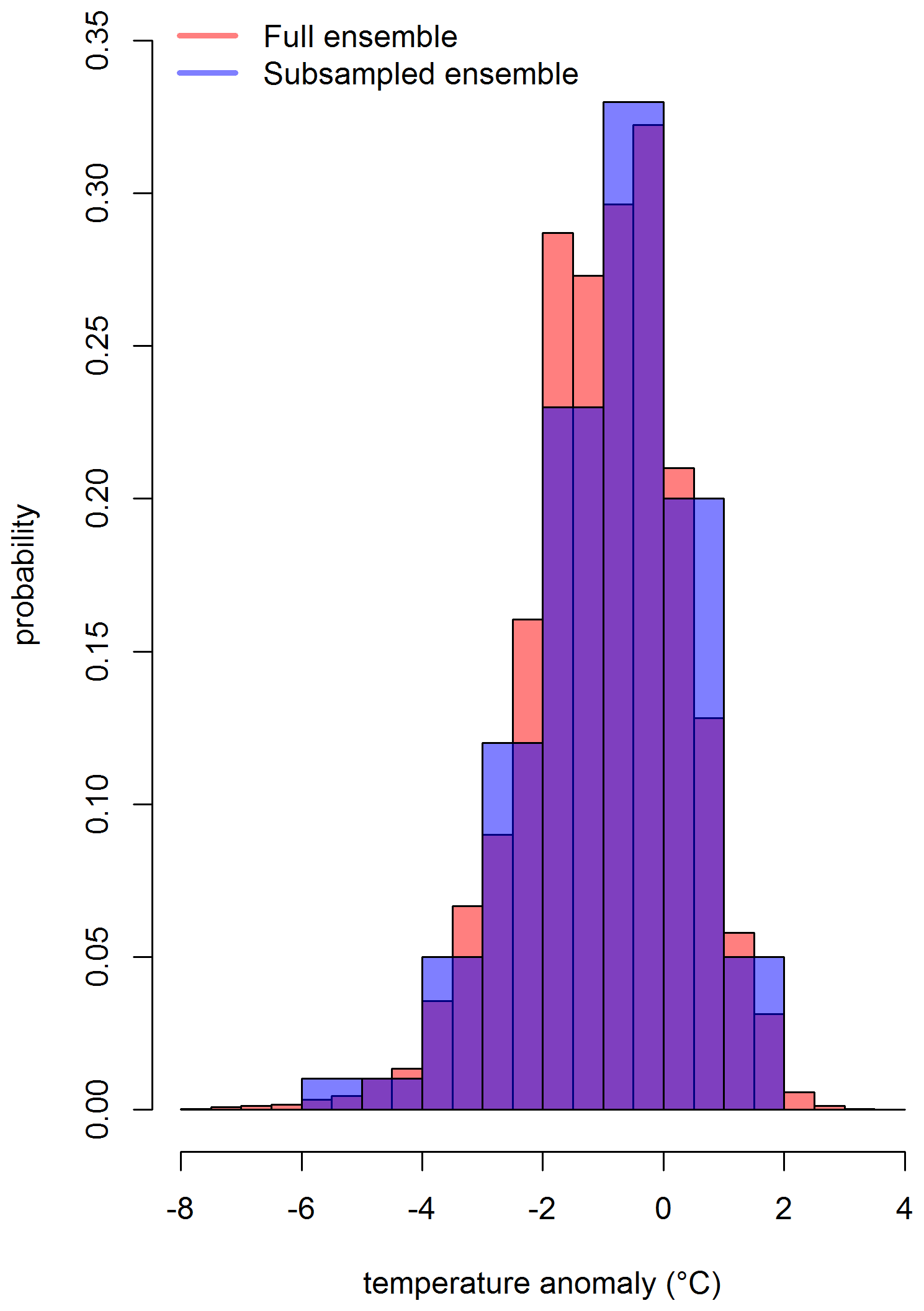
Uncertainty in gridded temperature comes from a variety of sources, of which instrumental error is only one. Uncertainties associated with the lack of spatial coverage are understandably more important in the early portion of the record, i.e., when observations were sparse. Many approaches can be used to fill in the grid boxes with missing observations, some of which also quantify the associated coverage uncertainties. There is a debate as to which model is the most appropriate. For the first time, this research considers the uncertainty in that model itself. We demonstrate that this is achievable through Monte Carlo sampling of perturbations in the hyperparameters in the model. The method described is computationally intensive and results in a data set that is somewhat unwieldy, i.e., the large ensemble. We have demonstrated that this latter point can be overcome by conditional sampling under some circumstances.
The hyperparameter ensemble (i.e., an update on Ilyas et al., 2017) has provided an improved version of the global temperature anomalies since 1850. Instead of the classical or frequentist approach, a Bayesian methodology for the quantification of uncertainties in large data settings is developed for characterization of uncertainties. The impact of including parametric uncertainties is evident at a regional (Fig. 4) and global scale (Fig. 5). However, the overall impact of parametric uncertainties makes little substantive advance in our general understanding of global average temperature estimates since 1850. The hyperparameter sampling approach described here results in an ensemble that is an order of magnitude larger than that of Ilyas et al. (2017) and 3 orders of magnitude larger than the original HadCRUT4 ensemble of Morice et al. (2012). Our analysis here has focused on changes in the mean climate, and perhaps this hyperparameter ensemble may be better suited for studies that aim to explore changing climate variability (Beguería et al., 2016).
The inclusion of parametric uncertainties does not have a substantial impact on the uncertainties in global average temperature estimates. However, parameter uncertainty estimates may be important at regional scales. We strongly recommend that, before embarking on future efforts, people explore this data set to see if there will be any tangible benefit. It may be possible that alternate methodologies could be devised that do not require such an outlay of resources during creation and analysis. For example, there may be approaches to sample hyperparameters and uncertainty mappings simultaneously, without running the risk of undersampling key elements of parameter space. Or, a few example fields could be created using the approach here, and then conditional Latin hypercube sampling could be used to determine the hyperparameter settings for a reduced ensemble.
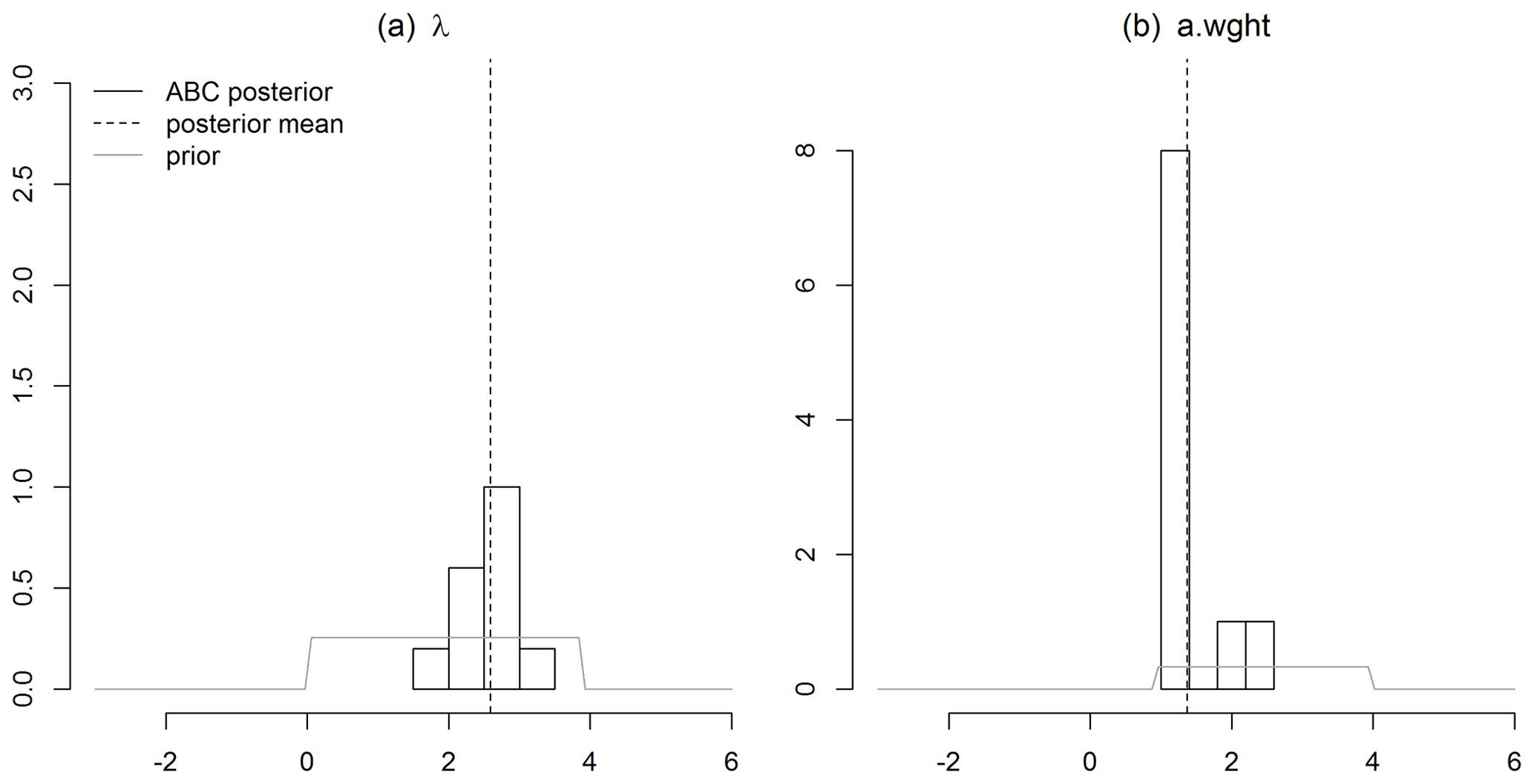
Figure A1Posterior densities of the smoothing parameter, λ, (a) and autoregressive weight, a.wght (b), for a HadCRUT4 spatial field with a 50 % spatial coverage, i.e., February 1932.

Figure A2Posterior densities of the smoothing parameter, λ, (a) and autoregressive weight, a.wght (b), for a HadCRUT4 spatial field with a maximum (78 %) spatial coverage, i.e., February 1988.
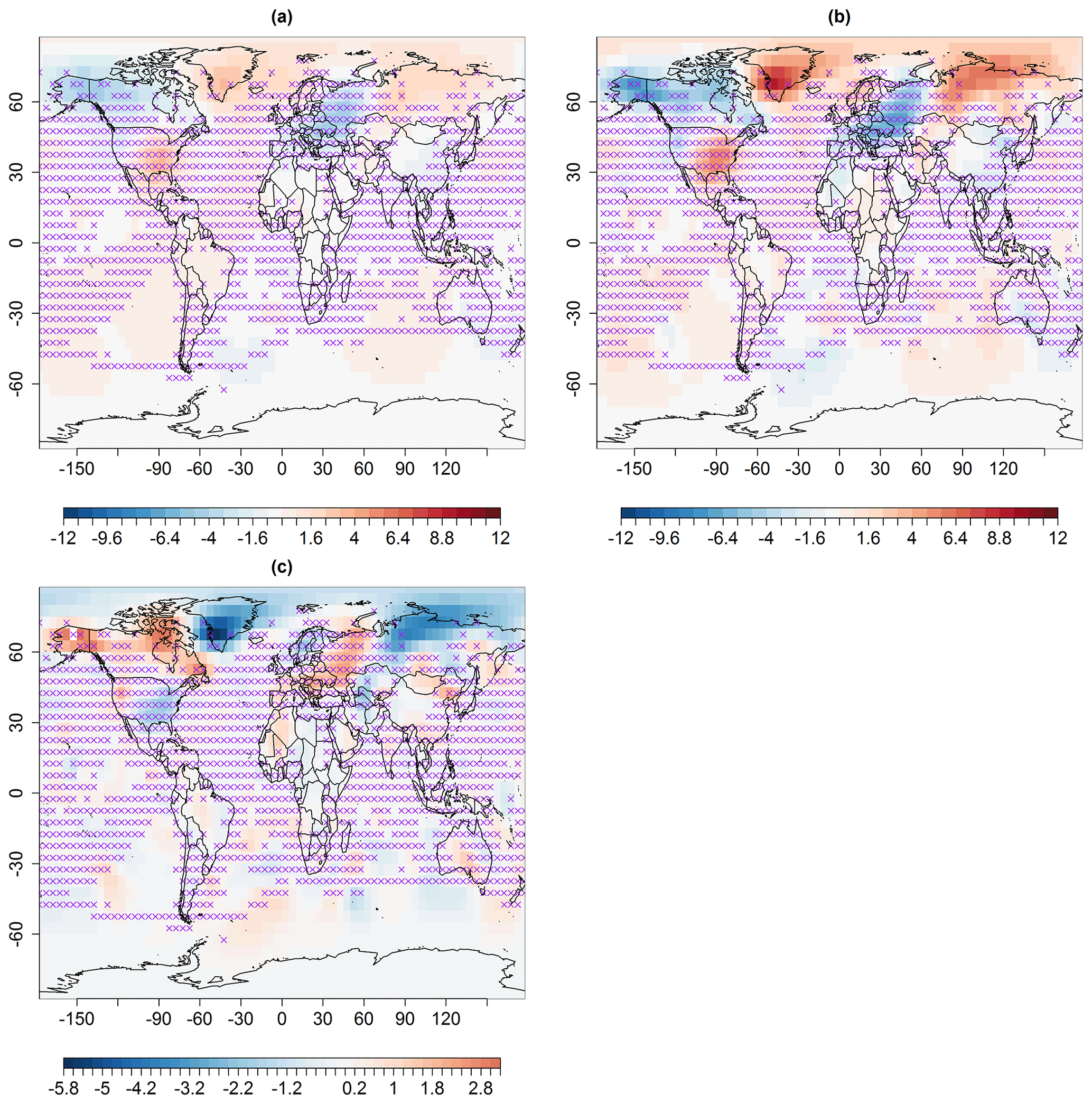
Figure B1Spatial predictions (in degrees Celsius) for February 1932, using multi-resolution lattice kriging based on (a) ABC, using a variogram (Sect. 2.1), and (b) the profile maximum likelihood approach (Nychka et al., 2015) used to create data in Ilyas et al. (2017). (c) The difference in panels (a) and (b), i.e., (a)–(b). The × signs show observed spatial sites (purple).
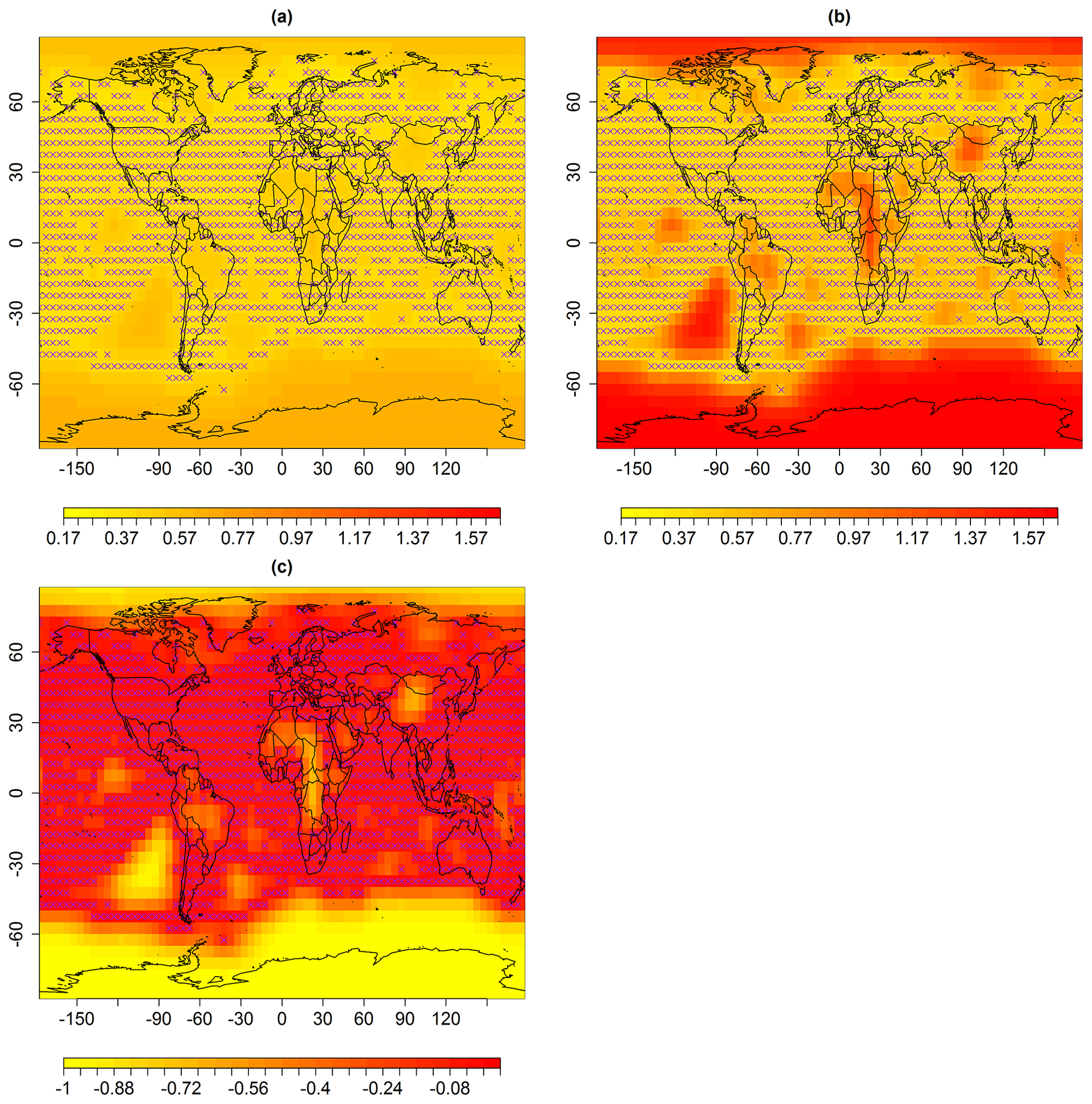
Figure B2Standard error (uncertainties) in degrees Celsius associated with spatial predictions for the median in February 1932, using multi-resolution lattice kriging based on (a) ABC, using a variogram (Sect. 2.1), and (b) the profile maximum likelihood approach (Nychka et al., 2015) used to create data in Ilyas et al. (2017). (c) The difference in panels (a) and (b), i.e., (a)–(b). The × signs show observed spatial sites (purple).

Figure B3Spatial predictions (in degrees Celsius) for February 1988, using multi-resolution lattice kriging, based on (a) ABC, using a variogram (Sect. 2.1), and (b) the profile maximum likelihood approach (Nychka et al., 2015) used to create data in Ilyas et al. (2017). (c) The difference in panels (a) and (b), i.e., (a)–(b). The × signs show observed spatial sites (purple).

Figure B4Standard error (uncertainties) in degrees Celsius associated with spatial predictions for the median in February 1988, using multi-resolution lattice kriging, based on (a) ABC, using a variogram (Sect. 2.1), and (b) the profile maximum likelihood approach (Nychka et al., 2015) used to create data in Ilyas et al. (2017). (c) The difference in panels (a) and (b), i.e., (a)–(b). The × signs show observed spatial sites (purple).
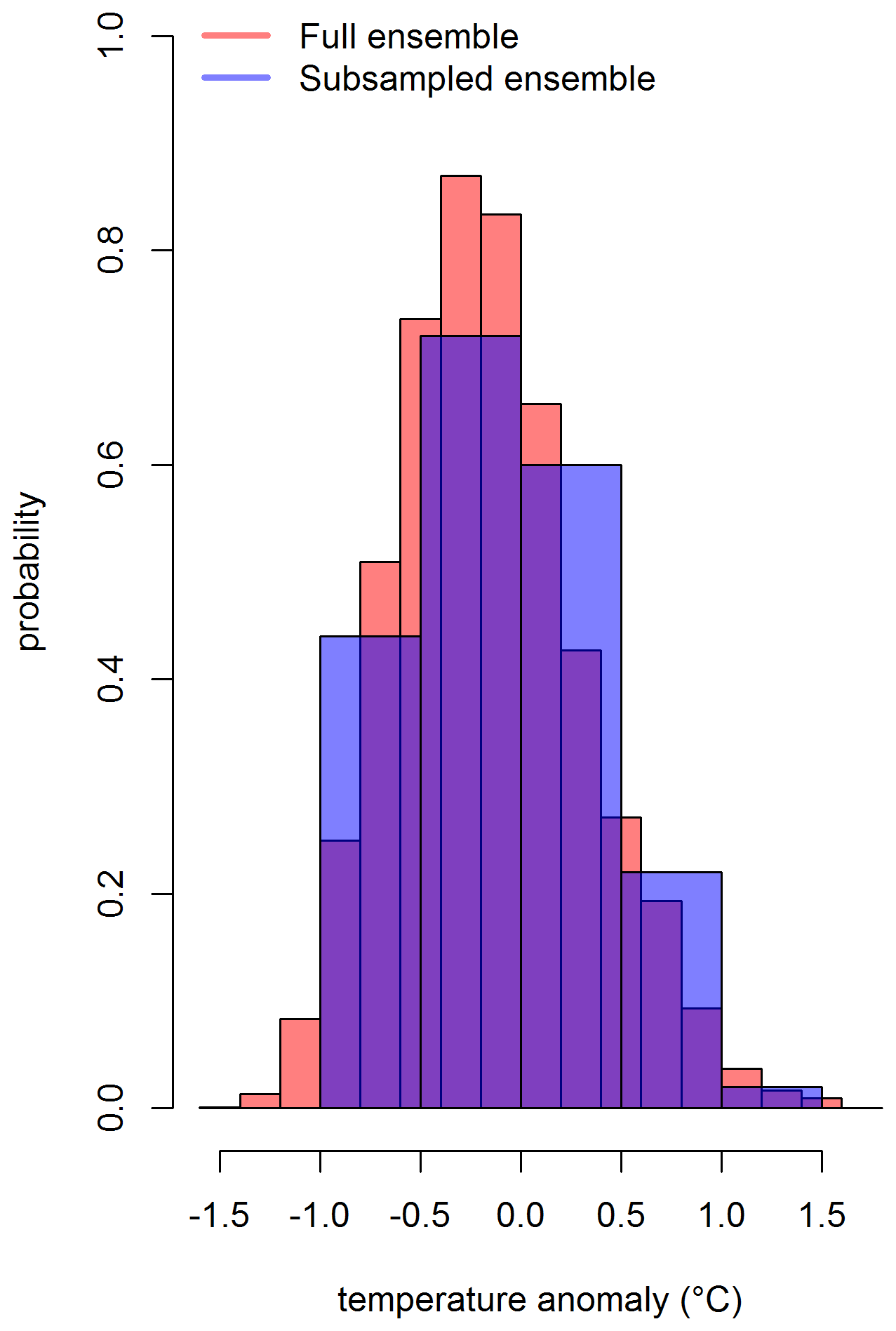
Figure C1Distribution of the grid box (long and lat are 72.5∘ and 32.5∘, respectively) that includes Lahore for February 1932. The full ensemble consists of 100 000 grid boxes (Sect. 4.3), and the subsampled ensemble consists of 100 grid boxes based on Latin hypercube sampling.
The codes used for processing follow the methodologies and equations described herein. These are available upon request.
The data sets are available upon request.
SG and CB conceived the project. MI performed the analysis and wrote the paper with CB, SG and DN. DN devised the idea of multi-resolution lattice kriging using ABC.
The authors declare that they have no conflict of interest.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research was supported by a UCL Overseas Research Scholarship, a University of the Punjab Overseas Scholarship and Research Grant, and National Center for Atmospheric Research (NCAR; all for Maryam Ilyas). Maryam Ilyas acknowledges the support from the REsearch on Changes of Variability and Environmental Risk. This research would not have been possible without the assistance and generosity of the Met Office's Hadley Centre and the University of East Anglia's Climate Research Unit. The authors acknowledge the use of the UCL Legion High Performance Computing Facility (Legion@UCL), and associated support services, in the completion of this work. We also acknowledge the helpful comments from the reviewers.
This research has been supported by the REsearch on Changes of Variability and Environmental Risk (RECoVER; grant no. EPSRC 15 EP/M008495/1).
This paper was edited by Francis Pope and reviewed by three anonymous referees.
Beaumont, M.: Approximate Bayesian computation in evolution and ecology, Annu. Rev. Ecol. Evol. S., 41, 379–406, 2010. a
Beaumont, M.: Approximate bayesian computation, Annu. Rev. Stat. Appl., 6, 379–403, 2019. a
Beaumont, M., Zhang, W., and Balding, D.: Approximate Bayesian computation in population genetics, Genetics, 162, 2025–2035, 2002. a
Beguería, S., Vicente-Serrano, S. M., Tomás-Burguera, M., and Maneta, M.: Bias in the variance of gridded data sets leads to misleading conclusions about changes in climate variability, Int. J. Climatol., 36, 3413–3422, https://doi.org/10.1002/joc.4561, 2016. a
Brohan, P., Kennedy, J., Harris, I., Tett, S., and Jones, P.: Uncertainty estimates in regional and global observed temperature changes: A new data set from 1850, J. Geophys. Res.-Atmos., 111, 1–21, 2006. a, b
Busetto, A. and Buhmann, J.: Stable Bayesian parameter estimation for biological dynamical systems, in: Computational Science and Engineering, CSE'09, IEEE International Conference on, Vol. 1, 148–157, 2009. a
Cao, L., Yan, Z., Zhao, P., Zhu, Y., Yu, Y., Tang, G., and Jones, P.: Climatic warming in China during 1901–2015 based on an extended dataset of instrumental temperature records, Environ. Res. Lett., 12, 064005, https://doi.org/10.1088/1748-9326/aa68e8, 2017. a
Clifford, D., Payne, J., Pringle, M., Searle, R., and Butler, N.: Pragmatic soil survey design using flexible Latin hypercube sampling, Comput. Geosci., 67, 62–68, 2014. a
Cowtan, K. and Way, R.: Coverage bias in the HadCRUT4 temperature series and its impact on recent temperature trends, Q. J. Roy. Meteorol. Soc., 140, 1935–1944, 2014. a, b
Diermanse, F., Carroll, D., Beckers, J., and Ayre, R.: An efficient sampling method for fast and accurate Monte Carlo Simulations, Austral. J. Water Resour., 20, 160–168, 2016. a
Domonkos, P. and Coll, J.: Homogenisation of temperature and precipitation time series with ACMANT3: Method description and efficiency tests, Int. J. Climatol., 37, 1910–1921, 2017. a
Dunn, R. J. H., Willett, K. M., Morice, C. P., and Parker, D. E.: Pairwise homogeneity assessment of HadISD, Clim. Past, 10, 1501–1522, https://doi.org/10.5194/cp-10-1501-2014, 2014. a
Dunn, R., Willett, K., Parker, D., and Mitchell, L.: Expanding HadISD: Quality-controlled, sub-daily station data from 1931, Geoscientific Instrumentation, Method. Data Syst., 5, 473–491, 2016. a, b
Dutta, R., Chopard, B., Lätt, J., Dubois, F., Boudjeltia, K., and Mira, A.: Parameter estimation of platelets deposition: Approximate Bayesian computation with high performance computing, Front. Physiol., 9, 1–11, 2018. a
Glanemann, N., Willner, S., and Levermann, A.: Paris Climate Agreement passes the cost-benefit test, Nat. Commun., 11, 1–11, 2020. a
Gosling, J., Krishnan, S., Lythe, G., Chain, B., MacKay, C., and Molina-París, C.: A mathematical study of CD8+ T cell responses calibrated with human data, arXiv preprint arXiv:1802.05094, 2018. a
Hansen, J., Ruedy, R., Sato, M., and Lo, K.: Global surface temperature change, Rev. Geophys., 48, 1–29, 2010. a, b, c, d
Hausfather, Z., Cowtan, K., Menne, M., and Williams, C.: Evaluating the impact of US Historical Climatology Network homogenization using the US Climate Reference Network, Geophys. Res. Lett., 43, 1695–1701, 2016. a
Helton, J. and Davis, F.: Latin hypercube sampling and the propagation of uncertainty in analyses of complex systems, Reliab. Eng. Syst. Safe., 81, 23–69, 2003. a
Huang, B., Menne, M. J., Boyer, T., Freeman, E., Gleason, B. E., Lawrimore, J. H., Liu, C., Rennie, J. J., Schreck III, C. J., Sun, F., Vose, R., Wiliams, C. N., Yin, X., and Zhang, H.-M.: Uncertainty estimates for sea surface temperature and land surface air temperature in NOAAGlobalTemp version 5, J. Clim., 33, 1351–1379, 2020. a
Ilyas, M., Brierley, C., and Guillas, S.: Uncertainty in regional temperatures inferred from sparse global observations: Application to a probabilistic classification of El Niño, Geophys. Res. Lett., 44, 9068–9074, 2017. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s
Iman, R.: Latin hypercube sampling, Encyclopedia of quantitative risk analysis and assessment, Wiley Online Library, https://doi.org/10.1002/9780470061596.risk0299, 2008. a
Ishihara, K.: Calculation of global surface temperature anomalies with COBE-SST, Weather Serv. Bull., 73, S19–S25, 2006. a
Ishii, M., Shouji, A., Sugimoto, S., and Matsumoto, T.: Objective analyses of sea-surface temperature and marine meteorological variables for the 20th century using ICOADS and the Kobe collection, Int. J. Climatol., 25, 865–879, 2005. a, b
Jones, P.: The reliability of global and hemispheric surface temperature records, Adv. Atmos. Sci., 33, 269–282, 2016. a, b
Jones, P., Lister, D., Osborn, T., Harpham, C., Salmon, M., and Morice, C.: Hemispheric and large-scale land-surface air temperature variations: An extensive revision and an update to 2010, J. Geophys. Res.-Atmos., 117, 1–29, 2012. a, b, c, d, e
Kennedy, J.: A review of uncertainty in in situ measurements and data sets of sea surface temperature, Rev. Geophys., 52, 1–32, 2014. a, b, c, d
Kennedy, J., Rayner, N., Smith, R., Parker, D., and Saunby, M.: Reassessing biases and other uncertainties in sea surface temperature observations measured in situ since 1850: 2. Biases and homogenization, J. Geophys. Res.-Atmos., 116, 1–22, 2011a. a, b, c
Kennedy, J., Rayner, N., Smith, R., Parker, D., and Saunby, M.: Reassessing biases and other uncertainties in sea surface temperature observations measured in situ since 1850: 1. Measurement and sampling uncertainties, J. Geophys. Res.-Atmos., 116, 1–13, 2011b. a, b, c
Lenssen, N., Schmidt, G., Hansen, J., Menne, M., Persin, A., Ruedy, R., and Zyss, D.: Improvements in the GISTEMP uncertainty model, J. Geophys. Res.-Atmos., 124, 6307–6326, https://doi.org/10.1029/2018JD029522, 2019. a, b
McKay, M., Beckman, R., and Conover, W.: A comparison of three methods for selecting values of input variables in the analysis of output from a computer code, Technometrics, 42, 55–61, 2000. a
McKinnon, K., Poppick, A., Dunn-Sigouin, E., and Deser, C.: An “Observational Large Ensemble” to compare observed and modeled temperature trend uncertainty due to internal variability, J. Clim., 30, 7585–7598, 2017. a
Menne, M., Williams, C., Gleason, B., Rennie, J., and Lawrimore, J.: The global historical climatology network monthly temperature dataset, version 4, J. Clim., 31, 9835–9854, 2018. a
Minasny, B. and McBratney, A. B.: A conditioned Latin hypercube method for sampling in the presence of ancillary information, Comput. Geosci., 32, 1378–1388, 2006. a
Moberg, A., Alexandersson, H., Bergström, H., and Jones, P.: Were southern Swedish summer temperatures before 1860 as warm as measured?, Int. J. Climatol., 23, 1495–1521, 2003. a
Morice, C., Kennedy, J., Rayner, N., and Jones, P.: Quantifying uncertainties in global and regional temperature change using an ensemble of observational estimates: The HadCRUT4 data set, J. Geophys. Res.-Atmos. (1984–2012), 117, 1–22, 2012. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q
Morice, C., Kennedy, J., Rayner, N., Winn, J., Hogan, E., Killick, R., Dunn, R., Osborn, T., Jones, P., and Simpson, I.: An updated assessment of near-surface temperature change from 1850: the HadCRUT5 dataset, J. Geophys. Res.-Atmos., 126, 1–28, 2021. a, b, c, d
Nychka, D., Bandyopadhyay, S., Hammerling, D., Lindgren, F., and Sain, S.: A multi-resolution Gaussian process model for the analysis of large spatial data sets, J. Comput. Graph. Stat., 24, 579–599, 2015. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o
Nychka, D., Hammerling, D., Sain, S., Lenssen, N., Smirniotis, C., and Iverson, M.: Package “LatticeKrig”, available at: http://rsync5.jp.gentoo.org/pub/CRAN/web/packages/LatticeKrig/LatticeKrig.pdf (last access: 10 November 2021), 2019. a, b, c
Olsson, A. and Sandberg, G.: Latin hypercube sampling for stochastic finite element analysis, J. Eng. Mech., 128, 121–125, 2002. a
Olsson, A., Sandberg, G., and Dahlblom, O.: On Latin hypercube sampling for structural reliability analysis, Struct. Saf., 25, 47–68, 2003. a
Parker, D.: Effects of changing exposure of thermometers at land stations, Int. J. Climatol., 14, 1–31, 1994. a
Pebesma, E. and Heuvelink, G.: Latin hypercube sampling of Gaussian random fields, Technometrics, 41, 303–312, 1999. a
Pritchard, J. K., Seielstad, M. T., Perez-Lezaun, A., and Feldman, M. W.: Population growth of human Y chromosomes: a study of Y chromosome microsatellites, Mol. Biol. Evol., 16, 1791–1798, 1999. a
Rayner, N., Brohan, P., Parker, D., Folland, C., Kennedy, J., Vanicek, M., Ansell, T., and Tett, S.: Improved analyses of changes and uncertainties in sea surface temperature measured in situ since the mid-nineteenth century: The HadSST2 dataset, J. Clim., 19, 446–469, 2006. a, b, c
Rohde, R.: Comparison of Berkeley Earth, NASA GISS, and Hadley CRU averaging techniques on ideal synthetic data, Berkeley Earth Memo, available at: https://static.berkeleyearth.org/memos/robert-rohde-memo.pdf (last access: 8 November 2021), 2013. a
Rohde, R. A. and Hausfather, Z.: The Berkeley Earth Land/Ocean Temperature Record, Earth Syst. Sci. Data, 12, 3469–3479, https://doi.org/10.5194/essd-12-3469-2020, 2020. a, b
Rohde, R., Muller, R., Jacobsen, R., Muller, E., Perlmutter, S., Rosenfeld, A., Wurtele, J., Groom, D., and Wickham, C.: A new estimate of the average earth surface land temperature spanning 1753 to 2011, Geoinformatics and Geostatistics: An Overview, 1, 1–7, 2013. a
Shang, X., Chao, T., Ma, P., and Yang, M.: An efficient local search-based genetic algorithm for constructing optimal Latin hypercube design, Eng. Optimiz., 52, 271–287, 2020. a
Shields, M. and Zhang, J.: The generalization of Latin hypercube sampling, Reliab. Eng. Syst. Safe., 148, 96–108, 2016. a
Smith, T., Reynolds, R., Peterson, T., and Lawrimore, J.: Improvements to NOAA's historical merged land-ocean surface temperature analysis (1880–2006), J. Clim., 21, 2283–2296, 2008. a
Trewin, B.: Exposure, instrumentation, and observing practice effects on land temperature measurements, Wiley Interdisciplinary Reviews, Climate Change, 1, 490–506, 2010. a
Vose, R., Arndt, D., Banzon, V., Easterling, D., Gleason, B., Huang, B., Kearns, E., Lawrimore, J. H., Menne, M. J., Peterson, T. C., Reynolds, R. W., Smith, T. M., Williams, C. N., and Wuertz, D. L.: NOAA's merged land–ocean surface temperature analysis, Bull. Am. Meteorol. Soc., 93, 1677–1685, 2012. a
Vose, R., Huang, B., Yin, X., Arndt, D., Easterling, D., Lawrimore, J., Menne, M., Sánchez-Lugo, A., and Zhang, H.: Implementing full spatial coverage in NOAA’s global temperature analysis, Geophys. Res. Lett., 48, 1–9, 2021. a, b, c
Woodruff, S., Worley, S., Lubker, S., Ji, Z., Eric F., J., Berry, D., Brohan, P., Kent, E., Reynolds, R., Smith, S., et al.: ICOADS Release 2.5: extensions and enhancements to the surface marine meteorological archive, Int. J. Climatol., 31, 951–967, 2011. a
Zhang, H., Lawrimore, J., Huang, B., Menne, M., Yin, X., SánchezLugo, A., Gleason, B., Vose, R., Arndt, D., Rennie, J., and Williams, C. N.: Updated temperature data give a sharper view of climate trends, Eos, 100, 1961–2018, 2019. a
- Abstract
- Introduction
- Methods
- HadCRUT4 data
- Hyperparameter temperature ensemble data
- Uncertainties in global mean temperature
- Subsample of hyperparameter ensemble data
- Discussion and conclusion
- Appendix A
- Appendix B
- Appendix C
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methods
- HadCRUT4 data
- Hyperparameter temperature ensemble data
- Uncertainties in global mean temperature
- Subsample of hyperparameter ensemble data
- Discussion and conclusion
- Appendix A
- Appendix B
- Appendix C
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References