the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 25 Mar 2022
| 25 Mar 2022
Identification of tropical cyclones via deep convolutional neural network based on satellite cloud images
Biao Tong
Xiangfei Sun
Jiyang Fu
Pakwai Chan
Tropical cyclones (TCs) are one of the most destructive natural disasters. For the prevention and mitigation of TC-induced disasters, real-time monitoring and prediction of TCs is essential. At present, satellite cloud images (SCIs) are utilized widely as a basic data source for such studies. Although great achievements have been made in this field, there is a lack of concern about on the identification of TC fingerprints from SCIs, which is usually involved as a prerequisite step for follow-up analyses. This paper presents a methodology which identifies TC fingerprints via deep convolutional neural network (DCNN) techniques based on SCIs of more than 200 TCs over the northwestern Pacific basin. In total, two DCNN models have been proposed and validated, which are able to identify the TCs from not only single TC-featured SCIs but also multiple TC-featured SCIs. Results show that both models can reach 96 % of identification accuracy. As the TC intensity strengthens, the accuracy becomes better. To explore how these models work, heat maps are further extracted and analyzed. Results show that all the fingerprint features are focused on clouds during the testing process. For the majority of the TC images, the cloud features in TC's main parts, i.e., eye, eyewall, and primary rainbands, are most emphasized, reflecting a consistent pattern with the subjective method.
- Article
(16991 KB) - Full-text XML
-
Supplement
(49 KB) - BibTeX
- EndNote





As one of the most destructive natural disasters, tropical cyclones (TCs) can cause severe casualties and economic losses in TC-prone areas. The southeastern coast of China is adjacent to the most active TC ocean basin. Statistics show that an average of 30 TCs develop over the northwestern Pacific Ocean every year, about one-third of which make landfall in China, resulting in an annual economic loss of USD 5.6 billion. With the rapid development of urbanization in the coastal region of China, TC-induced disasters are expected to become even more severe.
To mitigate TC-induced disasters, real-time monitoring and forecasting of TCs activity are essential. To this end, various kinds of devices and techniques have been developed and utilized, such as radiosonde balloons, weather radar, wind profilers, airborne GPS dropsonde, aircraft-based remote sensing equipment, and ever-updating numerical models for weather prediction. Since the 20th century, satellites have been used in meteorology. Since then, satellite cloud images (SCIs), which contain rich atmospheric information for investigating synoptic scale systems, have been more and more utilized as a basic data source for TC studies. An overwhelming advantage of SCIs against their counterparts is that they can be obtained effectively over each ocean basin in almost every desired period, making it possible to persistently and synchronously observe TCs from a global perspective.
With the assistance of SCIs, fruitful achievements have been gained. As one of the representatives, the Dvorak technique is proposed for the systematic analysis of TCs, especially for identifying TC intensity (Dvorak, 1984). The Dvorak technique is still under development (see Velden et al., 1998, 2006; Olander and Velden, 2019). To date, most meteorological bureaus use the Dvorak technique to identify TC intensity. Another representative achievement is the Automated Tropical Cyclone Forecasting System (ATCF), which is developed to predict track and intensity of TCs based on a comprehensive usage of SCIs, detecting results from radiosonde, aircraft reconnaissance and other devices, as well as numerical weather forecasting models (Miller et al., 1990; Sampson and Schrader, 2000; Goerss, 2000).
For SCI-aided studies on TCs, it is a prerequisite to identify the TC fingerprint from the SCIs. Generally, the complex morphological characteristics of TCs and the coexistence of many interference factors, such as multiple cumulus clouds and continental background in the SCIs, make the task extremely challenging.
The most widely adopted method for TC identification from a SCI is the manual method. A series of fingerprint patterns are stratified in the Dvorak technique (Dvorak, 1984), which can be used empirically for TC identification. These patterns are summarized solely based on experiences of TC cloud shapes and their evolutionary characteristics. Apparently, the application of the Dvorak technique relies greatly on the users' experience, and it also involves many manual manipulations, which makes it nonobjective and less efficient.
In this regard, increased efforts have been made to identify TCs objectively, and several such methods have been developed, including the mathematical morphology method which exploits geometric transformations to extract morphological features on satellite images (Liao et al., 2011; Lopez-Ornelas et al., 2004; Han et al., 2009; Hayatbini et al., 2019; Wang et al., 2014), the threshold method in which threshold filtering or segmentation processing is implemented (Di Vittorio and Emery, 2002; Wang, 2002; Sun et al., 2016; Lu et al., 2010), and the rotation coefficient method, which applies vector moments to represent the morphological characteristics of TC clouds (Geng et al., 2014). Despite the merit of objectivity, as these methods usually contain complex operations, they tend to be less user-friendly and more computationally expensive, especially for issues with a huge number of SCIs.
In recent years, deep learning (LeCun et al., 2015; Schmidhuber, 2015; Zou et al., 2019) techniques, such as the generative adversarial network (GAN), recurrent neural network (RNN), and convolutional neural network (CNN; Chen et al., 2020; Lee et al., 2020; Sun et al., 2021; Pang et al., 2021), have developed fast. These techniques show overwhelming superiority against traditional approaches when dealing with data-intense prediction, recursive, and/or classification problems. Thus, they provide a new way to study TCs objectively and efficiently, based on SCIs.
This paper presents a study on the identification of TC fingerprint via deep convolutional neural network (DCNN) techniques. As an abstract–feature–extraction-oriented technique (Krizhevsky et al., 2019; Simonyan and Zisserman, 2015; Liu et al., 2019), DCNN is able to identify and classify various complex features involved in images in a highly generalized manner. Therefore, it turns out to be more objective and convenient to identify TCs using this technique than using traditional methods. The reminder of this article is organized as follows. Section 2 states the methodology, where both the details of two specific DCNN models and the datasets are introduced. Section 3 presents typical results for the identification of the TC fingerprint. The main results and conclusions are summarized in Sect. 4.
A flowchart of the methodology adopted in this study is shown in Fig. 1. There are two types of SCIs are available from open-source databases. For the first type, which is most readily available, each SCI covers the entire northwestern Pacific Ocean basin (hereafter called the NWPO image). Thus, it is not unusual that multiple TCs coexist in an NWPO image. In contrast, for the other type, each SCI covers a much smaller region over the northwestern Pacific Ocean, where there exists, at most, one TC (hereafter called L image). Although the NWPO images are more basic and more frequently utilized in practice, the L images are still employed in this study. The reason is twofold. First, it is necessary to preliminarily judge whether the DCNN technique is able to identify a specific TC effectively. For such feasibility testing, the L images are more appropriate. Second, it is much more difficult to identify TCs from an NWPO image than from an L image. Thus, the identification results associated with the L images can provide a useful reference to deal with the issues on the NWPO images.
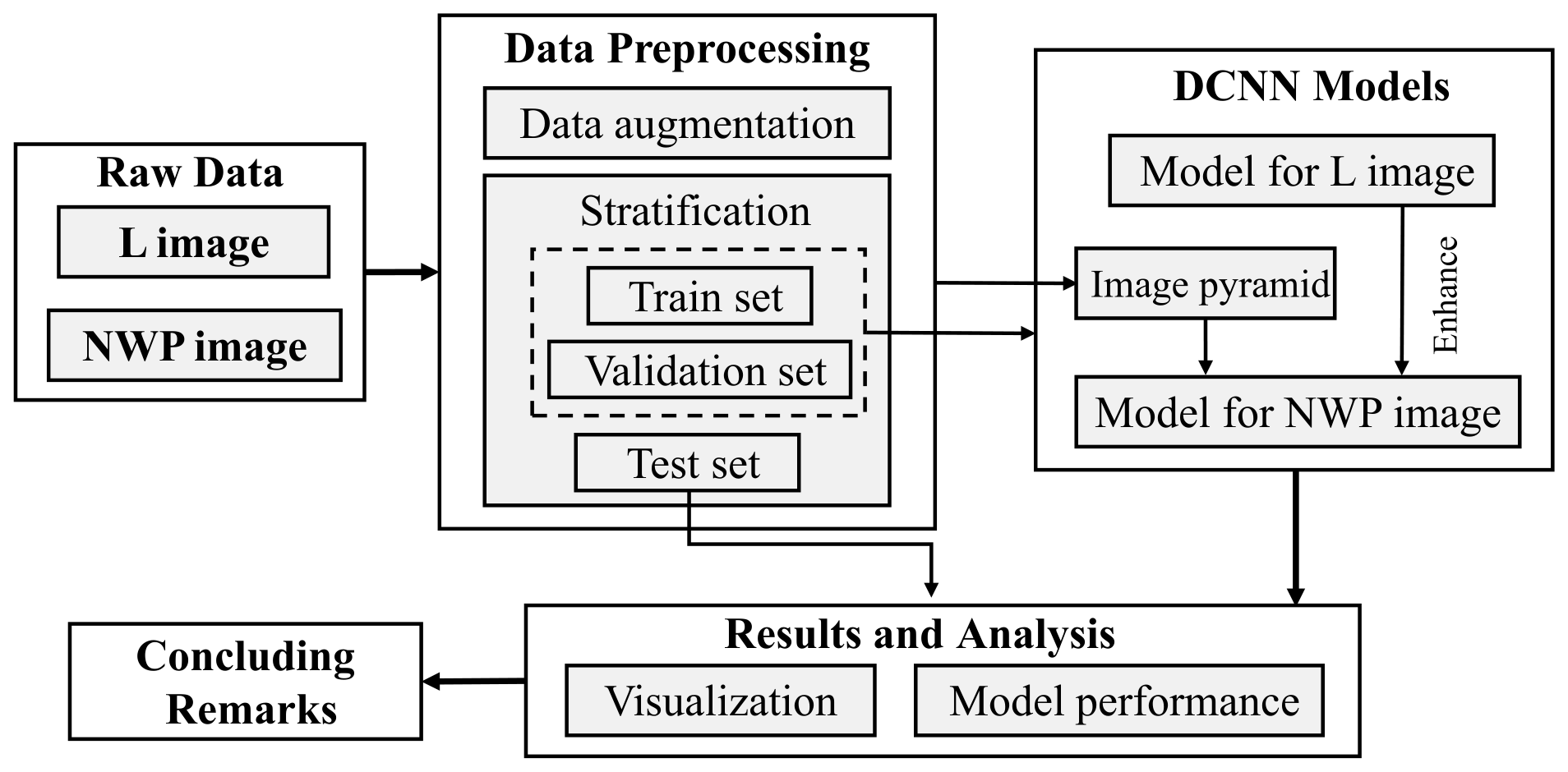
In accordance to the features of the two types of SCIs, two DCNN models are proposed, respectively. To improve model performance, all SCIs are pre-processed initially (i.e., data augmentation and stratification of datasets). Then, the models are trained and validated via SCI data. Visualization techniques (i.e., heat map) are further utilized to explore how the models work. Each link involved in the flowchart is detailed below.
2.1 Data source
The L images refer to the high-resolution infrared SCIs that are captured by Himawari-8, MSSAT-1R, and other Japanese satellites over the northwestern Pacific Ocean. Each image contains 512 pixel × 512 pixel in a plane which covers a geographic area of about 20∘ × 20∘. These images corresponded to the snapshots at 1 h intervals during the periods from 1–2 d ahead of the formation of a TC to a couple of days after its dissipation in 2010–2019. In total, 252 TCs were sampled during their whole life cycle. Both the image data and corresponding label information, i.e., TC track and intensity, are available from the website of the National Institute of Informatics (NII) of Japan (http://agora.ex.nii.ac.jp/digital-typhoon/, last access: 29 November 2021). Note that the intensity information of a TC is provided in a form of an integral multiple of 5 kn for this data source, and all intensity records are labeled as zero if they are below 35 kn. Owing to the poor quality of some SCIs and the absence of some TC label information, a limited number of the L images are discarded in this study, leaving about 47 000 valid images (the proportion between TC images and non-TC images is about 7:3) for the following analysis.
The NWPO images refer to the high-resolution infrared SCIs that were captured over the northwestern Pacific Ocean basin by geostationary satellites. Most of the images contain 1080 pixel × 680 pixel in a plane which covers a geographic area of 91–188∘ E and 3–55∘ N. These images corresponded to the snapshots at 3 h intervals throughout the TC seasons in 2014–2019. In total, about 160 TCs were sampled during their life cycle. Each of the NWPO images has two formats, namely one with a colorful background of the Earth's surface and the other without it. The image data are available from the website of the Meteorological Satellite Research Cooperation Institute/University of Wisconsin–Madison (CIMSS; http://tropic.ssec.wisc.edu/, last access: 29 November 2021). As no corresponding label information is provided on the website, the one archived in the typhoon yearbooks, as issued by the China Meteorological Administration (CMA), is adopted (https://tcdata.typhoon.org.cn/, last access: 29 November 2021). In this study, ∼ 15 000 valid images of this type are used, and the proportion between TC images and non-TC images is about 3:7.
2.2 Data preprocessing
2.2.1 Data augmentation
Although this study aims to identify a TC image from non-TC images, the identification performance of the proposed DCNN models potentially depends upon the TC intensity for TC images and the way a TC is defined. Meteorologically, the intensity of a TC can be classified into several levels according to the maximum sustained wind speed at the near-ground level in the TC's inner region, i.e., tropical depression (22–33 kn), tropical storm (34–47 kn), severe tropical storm (48–63 kn), typhoon (64–80 kn), severe typhoon (81–99 kn), and super typhoon (≥ 100 kn). Because the intensity of a tropical depression is labeled as 0 kn for the L images in the data source, a SCI is regarded as a TC image throughout this study if it contains a TC storm whose intensity is labeled to reach or exceed the tropical storm level; otherwise, it is regarded as a non-TC condition.
To improve the model performance, it is expected that (i) there are sufficient samples for each of the typical categories (e.g., TC image or non-TC image) involved in the classification problem and that (ii) the numbers of samples are evenly distributed among different categories. However, both the L image and NWPO image datasets suffer from an imbalanced distribution. Meanwhile, there are insufficient samples to cover each of the typical categories of TC images (e.g., with different TC intensity or TC numbers). For the L images, there are much fewer images for TCs with a higher intensity level, while for the NWPO images, there are many more non-TC images than those for TCs. To solve the above problems, two pre-processing techniques are adopted herein, i.e., down-sampling, which is exploited when there are relatively more images involved in a data type, and image transformation, which is exploited for a data type with insufficient SCIs. As shown in Fig. 2, five image transformation modes are utilized, i.e., rotating 90, 180, and 270∘ counterclockwise and flipping horizontally and vertically, respectively. Through such a transformation, the original image is able to generate six variations. On the one hand, down-sampling can be achieved by randomly selecting a certain portion of SCIs for a data type (i.e., TC images for L dataset and non-TC images for NWPO dataset). It is worth noting that using the image transformation technique is also beneficial for improving the generalization ability of the DCNN models. However, owing to the rotating/flipping manipulations, some information involved in the image tends to be lost, e.g., rainbands spiraling counterclockwise in the Northern Hemisphere.

Figure 2Image transformation showing the (a) original image followed by images that are (b) rotating 90∘ counterclockwise, (c) rotating 180∘ counterclockwise, (d) rotating 270∘ counterclockwise, and have a (e) horizontal flip and (f) vertical flip.
2.2.2 Stratification and standardization
After data augmentation processing, about 32 000 L images and 45 000 NWPO images are obtained. The datasets are divided into three sets, i.e., training set, validation set, and test set. While the training set and validation set are, respectively, used to train and validate the DCNN models, the test set is used for overall model performance. In this study, both the L image and NWPO image datasets are stratified in such a way that the ratio of SCI numbers among training set, validation set, and test set is about .
All SCIs are then standardized in terms of pixel size and pixel value to meet the requirements of the models for input information and to promote convergence during the training process. Each SCI is compressed to contain 100 pixel × 100 pixel in a plane for L images and 300 pt × 300 pt in a plane for NWPO images. Meanwhile, all pixel values are normalized so that they are changed to be in a range of .
2.3 DCNN model
A convolutional neural network (CNN) is essentially a multi-layer perceptron. It can be used for classification and regression of images, as well as the automatic extraction of graphic features. In recent years, with the development of deep learning theory, DCNN has been further proposed based on the CNN techniques, which is usually regarded to possess a better performance than the CNN in terms of universality and accuracy.
Structurally, a DCNN model consists of several functional modules which can be combined in certain ways according to both internal logic and external requirements. Typical modules include the convolutional layer, pooling layer, dropout layer, and dense layer. The convolutional layer contains a number of digital scanners, i.e., the convolutional kernels, whose sizes (called the kernel size) are fixed uniformly within the layer. This layer is used to read the input information of the model and obtain various potential features of the targets through convolution computation (filtering). Many convolutional layers may be involved in a DCNN model. In principle, using more convolutional layers is beneficial for the model to generate more potential features of the targets. However, if there are too many convolutional layers, the model tends to suffer from gradient vanishing or explosion problems. Typically, a DCNN model consists of more convolutional layers than a CNN model. The pooling layer is mainly used to reduce the matrix information through a number of pooling operations, such as maximum pooling and average pooling. It is apparent that the appropriate usage of the pooling layers can improve the computational efficiency of the model effectively. The dropout layer (Srivastava et al., 2014) is used to maximize the efficiency of the neural nodes through eliminating unimportant features. During training, the dropout layer can randomly drop neural units from the neural network. Meanwhile, it also plays a role in avoiding over-fitting problems. Note that there are no dropout layers in a CNN model. At the end of the DCNN model is the dense layer (Jégou et al., 2017), which is used to flatten the information from previous layers and to estimate classification similarities through calculating a nonlinear function.
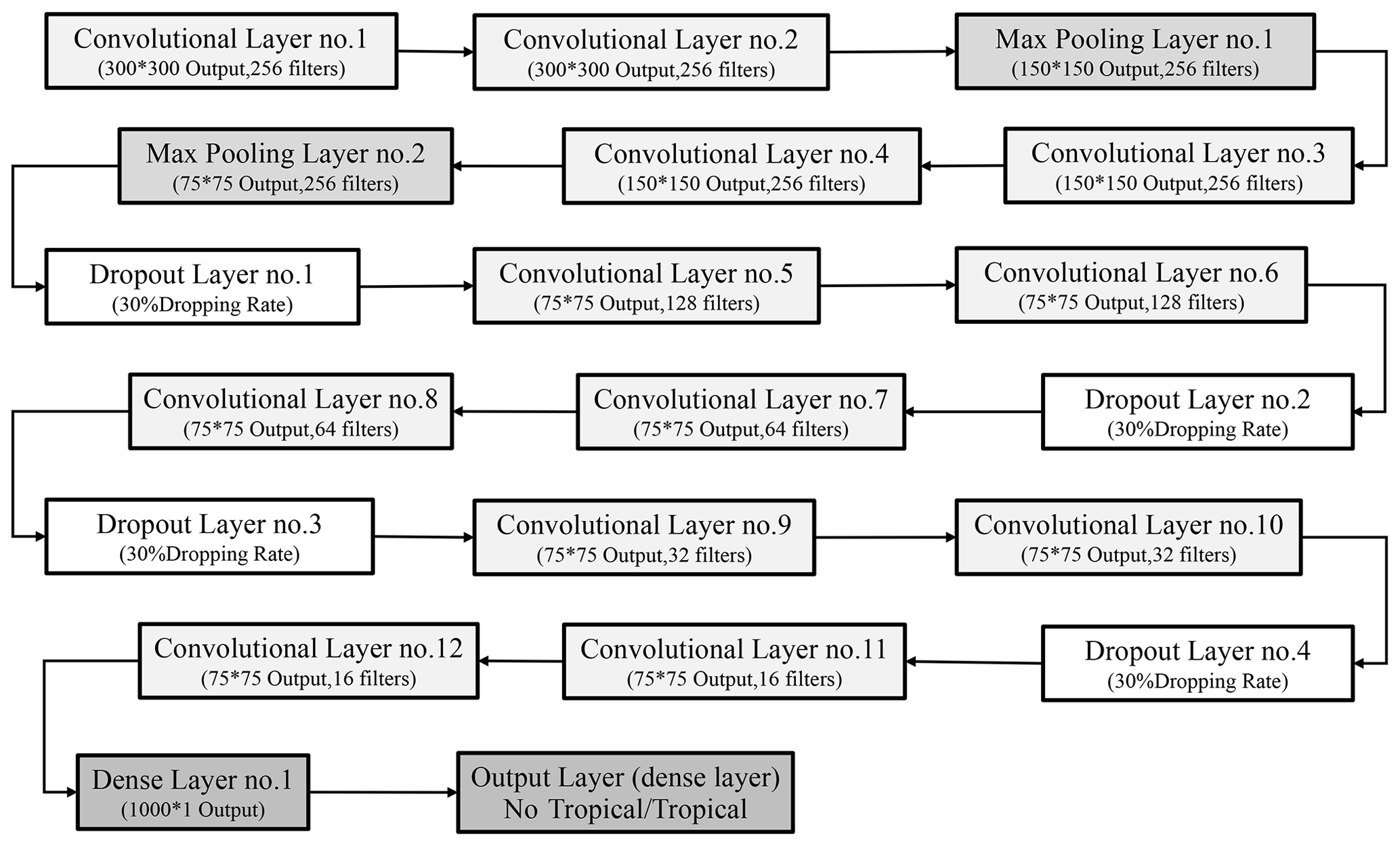
Figure 3 depicts the internal structure of the DCNN model for the NWPO images. The one for the L images is similar but somewhat simplified. Both models adopt a supervised learning strategy. The model for L images consists of five convolutional layers, three max-pooling layers, two dropout layers, and two dense layers, while the one for NWPO images consists of 12 convolutional layers, four dropout layers, two max-pooling layers, and two dense layers. For both models, the first convolutional layer serves as the input layer of the model, and the last dense layer serves as the output layer.
Functionally, the input layer and the hidden layers cooperate to extract any potential features from SCIs for TC identification, while the output layer plays a role in judging and making decisions based on the extracted results. It is clear that judging whether a SCI contains a TC essentially belongs to a binary classification problem. In this regard, the output layer herein utilizes the binary cross-entropy loss function L to quantify the inconsistence of the judgment (or training/prediction results) against the truth (i.e., data records) as follows:
where is the label of the c classification (1 for positive judgments and 0 for negative judgments) for the ith SCI, N is the number of SCI samples, M is the number of categories, and denotes the probability of the prediction associated with , which can be expressed via the softmax function as follows:
where is the original score of the model for prediction , which is calculated by the output layer on the basis of the output vector x (or the characteristic vector) from previous layers as follows:
in which W represents the coefficient matrix which quantifies the weight for each element in x during the judging/prediction process, and b is the bias vector.
Both W and b should be determined through training. In this study, the stochastic gradient descent (SGD) method is utilized to provide an efficient estimation of the model parameters. Besides W and b, there are also some hyper-parameters in the DCNN model, including the number of neural network nodes, the learning rate and epoch, etc. These parameters are usually preset and adjusted empirically, based on training results. Based on previous tests, the model for L images in this study uses a learning rate of 0.01, with a batch size of 64 and a training epoch number of 80. The settings of the model for NWPO images are similar, but the batch size is changed to eight, and the number of the training epoch becomes 100.
The model finally outputs a prediction value for each SCI, which is in the range of 0 %–100 %. If the value exceeds 50 %, it is judged that the SCI belongs to a TC image; otherwise, the SCI is classified as a non-TC image.
2.4 Model performance
The parameters of accuracy, precision rate, recall rate, and F measure are conventionally adopted to indicate the performance of a DCNN model. In this study, a SCI is classified as a positive sample if it contains a TC; otherwise, it is marked as negative. Accordingly, the accuracy is defined to represent the percentage of correctly classified (both positive and negative) samples in the dataset; the precision rate indicates the proportion of correctly identified positive samples in all positive predictions, while the recall rate represents the percentage of correctly identified positive samples in all positive samples. The latter two parameters differ with each other in that the precision rate highlights the performance in terms of not making misjudgments, while recall rate focuses on the ability to avoid the omission of positive predictions. During the training and validating processes, the training accuracy and validation accuracy are usually compared in real time to determine whether an over-fitting problem occurs.
where NTP represents the number of true positive predictions, NTN is the number of true negative predictions, NFP is the number of false positive predictions, and NFN is the number of false negative predictions.
F1 score is another indicator for the performance of models associated with classification problems. For binary classification problems, F1 can be expressed as the harmonic mean of precision and recall as follows:
In reference to classification problems, it is not unusual that the numbers of samples associated with different categories vary significantly. Under such conditions, it becomes inappropriate to evaluate the model performance via a single value of the above parameters. For binary classification problems, the so-called receiver operating characteristic (ROC) curve and precision–recall curve (PRC) are often adopted to provide more intuitive evaluation results (Powers, 2011; Hanley and McNeil, 2006; Molodianovitch et al., 2006; Saito and Rehmsmeier, 2015).
A ROC curve compares the true positive rate (TPR; ) against the false positive rate (FPR; =NFP/(NFP+NTN)), usually with FPR as the abscissa and TPR as the vertical coordinate. As the classification results depend upon how the prediction criterion (i.e., probability threshold of positive predictions) is defined, one can obtain a series of TPR and FPR values by selecting different threshold levels during the prediction process. In general, the smoother the ROC curve is, the better the classifier becomes. One can further use the so-called area under curve (AUC), which expresses the area demarcated by the ROC curve in the coordinate system, to quantify the accuracy of prediction results.
PRC is similar to the ROC curve in form, but it compares the recall rate (as the abscissa) and precision (vertical coordinate). A preferred classifier should correspond to a smooth PRC located toward the top right corner of the coordinate system. Usually, PRC works better than ROC for the cases with severe imbalance of samples between the positive and negative categories.
On the other hand, to improve the robustness of the model performance, the cross-validation strategy (Ron, 1995) is often exploited. As introduced previously, the original data in this study are stratified into 10 parts, with nine parts used as the training/validation set and one part as the test set. By using the cross-validation strategy, the data can be trained and tested at most 10 times.
2.5 Model visualization
Basically, a DCNN model can be regarded as a black box, since it is very difficult to explore the working mechanism of the model in a way that can be understood by human beings. In recent years, great efforts have been made to better understand how a DCNN model works internally.
As introduced previously, convolutional layers are able to extract various features from SCIs, which actually can be visualized by the so-called feature maps. As an example, Fig. 4 shows the visualization results of the outputs from all convolution kernels involved in the first four convolutional layers (i.e., Conv1, Conv2, Conv3, and Conv4) of a DCNN model. There are 256 convolution kernels in the Conv1 layer. Accordingly, they correspond to 256 feature maps. It is seen that some of the feature maps (e.g., feature map 3) are very similar to the input image, except that many marginal details in the input image are filtered in the feature map. For deeper convolutional layers, the feature maps become more abstract (e.g., feature map 34), and some convolution kernels may fail to generate valid feature maps (e.g., the black squares in Conv2 and Conv3).
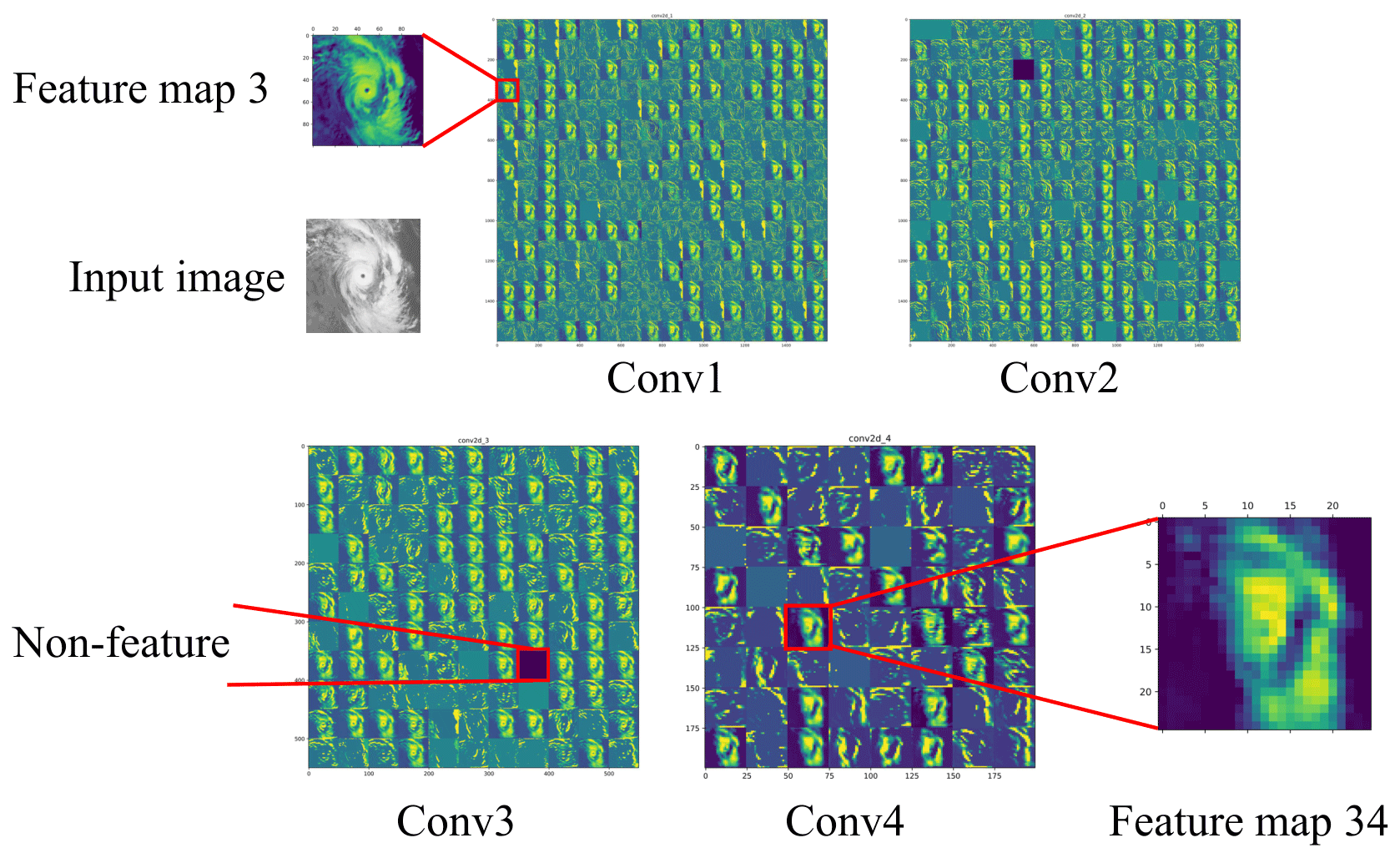
Figure 4Visualization of outputs from the convolution kernels involved in the first four convolutional layers of a DCNN model.
To clarify how the extracted features from convolutional layers influence the prediction results of a DCNN model, the class activation map (CAM) technique is proposed (Zeiler and Fergus, 2014; Selvaraju et al., 2020; Chattopadhay et al., 2018), which essentially aims to generate a heat map through computing the weighted sum of all the activation maps associated with the convolution kernels in a convolutional layer. Since a heat map expresses the extracted fingerprint features in a colorful form in the original image, one can then distinguish the emphasized features by the model from others. Then, the CAM technique has been developed into more advanced versions, e.g., Grad CAM and Grad CAM. Because the Grad CAM technique is able to focus on fingerprint patches more accurately and, simultaneously, cover multiple targets, this study adopts this technique in the following analysis.
2.6 Computational platform
The DCNN models and supervised learning algorithms were coded using Python 3.7 in conjunction with the Keras 2.2.4 and TensorFlow 1.11.0/2.0.0 packages. The training process was executed by a combined usage of NVIDIA GeForce RTX 2080Ti × 4 GPU, with parallel computing management software CUDA (v10.0) and acceleration library cuDNN (v7.3.1.20 and v7.6.0.64).
3.1 Results for L images
3.1.1 Overall performance
The 10-fold cross-validation strategy is employed to examine the robustness of the model performance. Figure 5 depicts the 10 evolutional curves of prediction accuracy during both training (TG) and validation (VG) processes for L images. As demonstrated, the training accuracy increased rapidly within the first 40 epochs (from 61 % to 97 %), and then leveled off at a considerably high level (∼ 100 %), which demonstrates the good convergence of the model during the training process. Results for the validation process were similar. Most of the 10 accuracy curves varied insignificantly and were stabilized at a high accuracy (> 90 % after 40 epochs). These results reflect the robustness of the model performance among different groups of samples. The high accuracy during both training and validation processes also reveals that the proposed model does not suffer from over-fitting problems. This should be partially attributed to the usage of dropout layers in DCNN models. Note that using dropout layers tends to slow down the convergence rate of the model slightly at the beginning of the training process, as reflected by the results within the first several epochs in Fig. 5 (dropout layers do not participate in work during the validation process). However, it does not influence the overall convergence rate (and, therefore, the training efficiency) of the model noticeably.
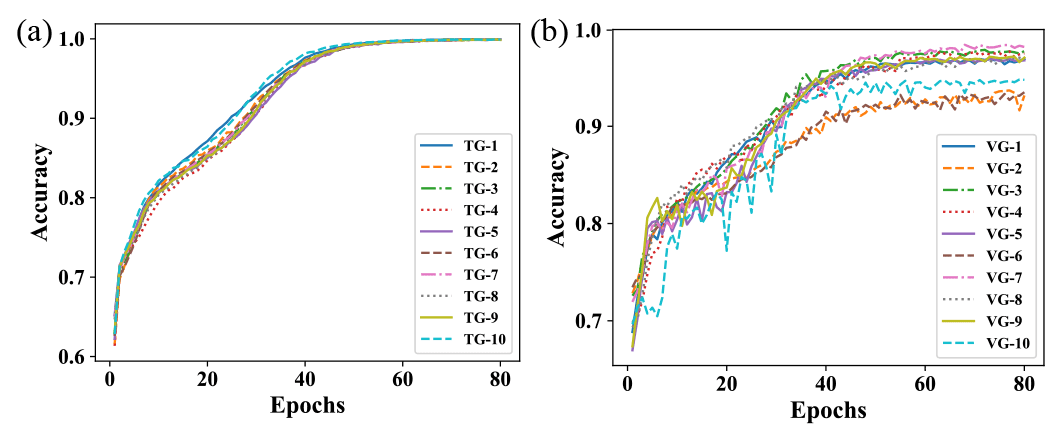
Figure 5Evolutional curves of the prediction accuracy of the proposed DCNN model for L images, with the (a) training process and (b) validation process.
Results from the training and validation processes show that the prediction performance of the model driven by dataset TG-1 (hereafter referred to as the TG-1 model) agreed best with the average performance obtained via the 10-fold cross-validation strategy. As a result, this specific model is expected to be able to generate more representative predictions than others. Therefore, it was adopted for the analysis during the testing process.
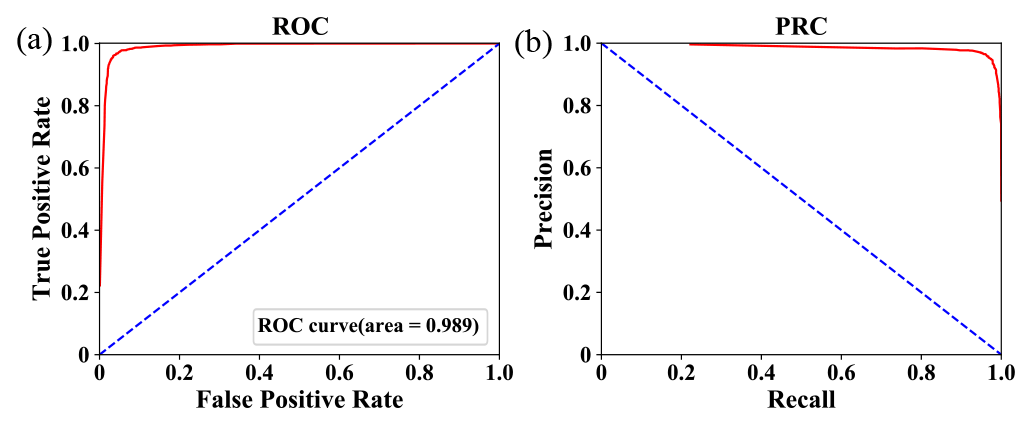
Table 1 summarizes the prediction performance of the TG-1 model during the testing process. The values of prediction accuracy, precision, recall ratio, and F1 are 96.43 %, 96.72 %, 94.49 %, and 95.59 %, respectively. Figure 6 depicts the associated ROC curve and PRC. Based on the ROC curve, the AUC is calculated to be 99.10 %. The high values of these parameters, especially the one of AUC, and the favorable features of the ROC curve (smooth) and PRC (located toward the upper right) suggest the overall good performance of the proposed model for L images during the testing process.
Table 1Prediction performance of TG-1 model during the testing process.

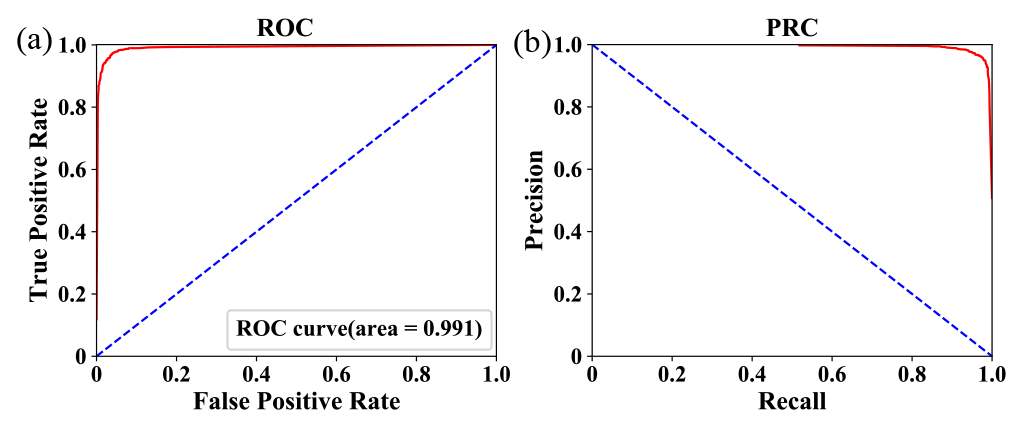
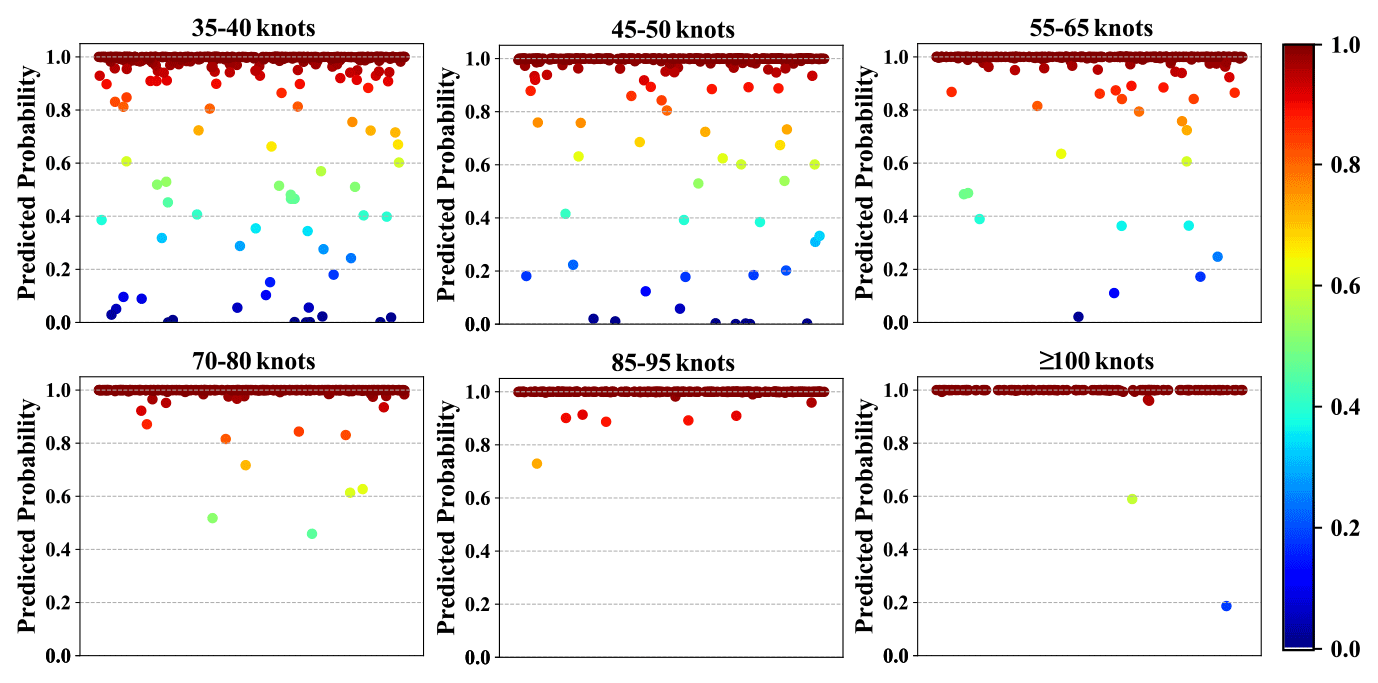
Figure 7Predicted probability for each of TC images with varied intensity levels in the testing L image dataset via the TG-1 model.
To examine the potential influence of TC intensity on the prediction performance of the proposed model, Fig. 7 exhibits the predicted probability for each of the TC images with varied intensity levels in the testing dataset. As demonstrated, although there were a limited number of misjudged samples for the cases with low intensity levels, very few (only two) samples were misjudged for the cases with higher intensity levels (i.e., > 70 kn), which reflects that the proposed model has a much better ability to identify stronger TCs from SCIs. This is understandable, since more intense TCs tend to possess more typical fingerprint features that can be better detected and recognized by the classifier.

Figure 8L images of TCs with varied intensity misjudged as non-TC images during testing process (main TC structures are demarcated by red dash squares).
Figure 8 depicts some typical SCIs of TCs with varied intensity levels that were misjudged as non-TC images via the TG-1 model during the testing process. Main TC structures are demarcated by the red dashed squares in the figure. By contrast, Fig. 9 depicts some non-TC images but is misjudged as TC images. Noted that some information (e.g., rainbands spiraling counterclockwise in the Northern Hemisphere) for these images has been lost due to the rotating/flipping manipulations involved in the data pre-processing stage.

It is a bit strange that the SCI with a super typhoon (Fig. 8f) was misjudged as a non-TC image. Scrutinizing the TC images shows that the number of SCIs for super typhoons is very limited, and almost all the super typhoons contain a calm eye at the center of the storm. However, there is no such distinct TC eye in Fig. 8f. Instead, the image looks much similar to some of the non-TC cases, e.g., Fig. 9a and c. It is most likely that the model failed to identify this case due to the lack of appropriate training samples. Figure 8c corresponds to another kind of misjudged TC image. Although this TC was labeled as a severe tropical storm (55 kn), it stayed at a rapidly decaying stage around and after landfall. The other cases in Fig. 8 may be regarded as the third kind. For these TCs, the morphological structures of TC cloud become too multifarious (thus, the training samples turn out to be insufficient) and irregular to be distinguished accurately by the model from those for non-TC cases, as shown in Fig. 9.
In reference to the results shown in Fig. 9, the failure of the model may be attributed to two main reasons. First, as tropical depression storms are not regarded as TCs in this study (refer to Sect. 2.2.1), some misjudged non-TC images actually contain a tropical depression. As one can imagine, there should be no evident differences between tropical depressions and TCs with a slightly higher intensity level (e.g., tropical storm). Second, for some true non-TC images, the morphological characteristics of clouds are so similar to those for TCs that it is difficult to distinguish them effectively. Whatever the reason, more training samples that cover each type of the misjudged SCIs are needed so that the model can be trained to perform more accurately.
3.2 Model visualization
Figure 10 depicts the heat maps (color pictures) of the TG-1 model for some successfully identified TC images. Corresponding SCIs (gray pictures) are also depicted for reference. In principle, during the identification process, the DCNN model would pay more attention to the graphic features that correspond to the areas depicted in a warmer color in the heat map. Thus, one can find out what the model most concerns with in a SCI intuitively. Results in the figure suggest that all the highlighted features are focused on clouds, especially on large masses of clouds, which is consistent with the way adopted by humankind. However, compared to the conditions for other identification issues (e.g., with a cat or dog), where usually only a few detailed features (e.g., mouth, nose/whiskers, or ears) within a small portion of the picture are emphasized, there were many more highlighted features that were scattered throughout the image in this study. The above difference reflects the complexity of identifying TCs from SCIs.
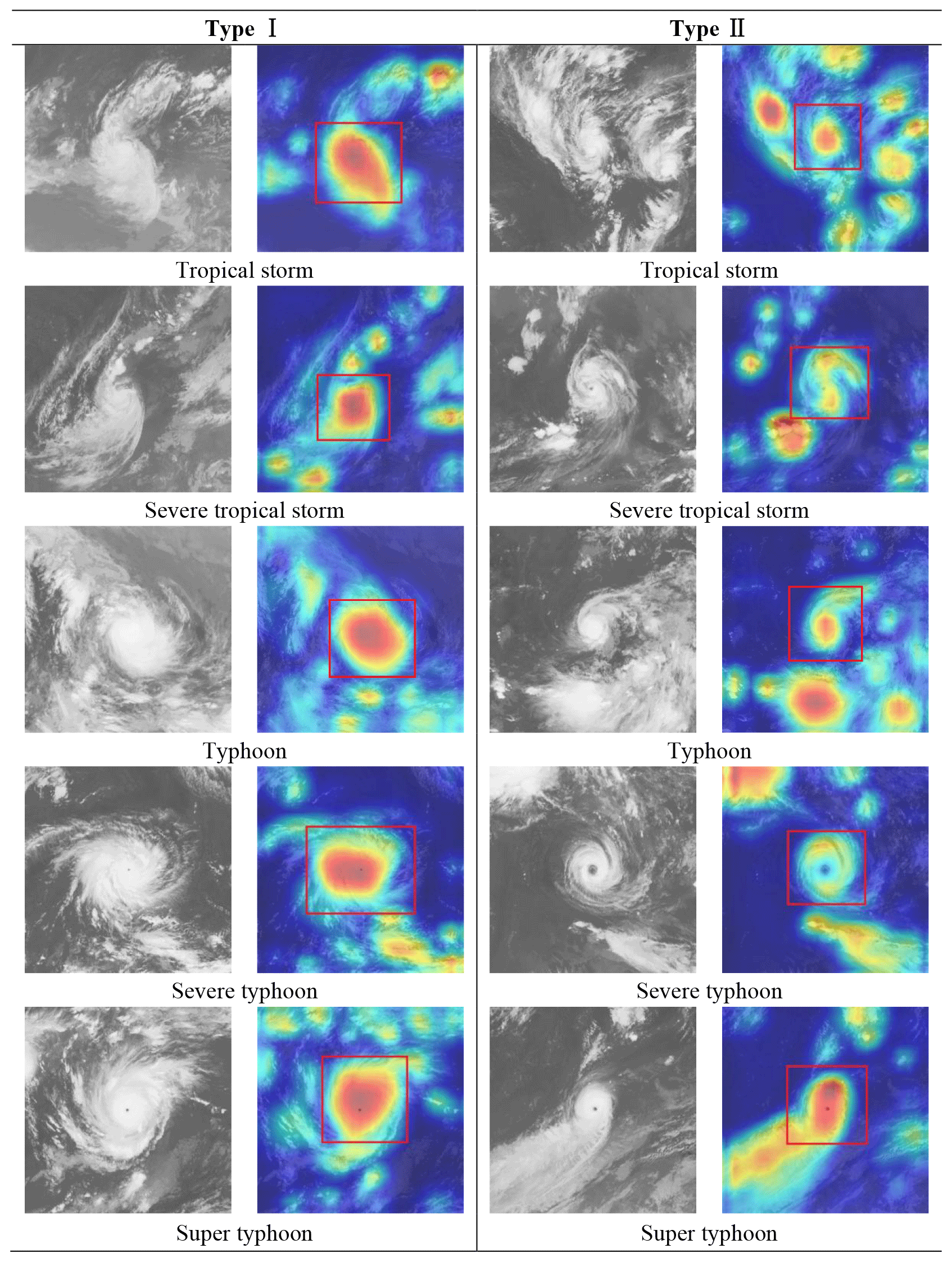
Figure 10Heat maps (color pictures; TC is demarcated by a red rectangle hereafter) of some successfully identified TC images compared with the associated L images (gray pictures hereafter).
Basically, the heat maps can be categorized into two types, i.e., Type I and Type II, as shown in Fig. 10. For Type I, which accounts for over 80 % of the total results, the main body of TC cloud (corresponding to TC eye, eyewall, and primary rainbands) was identified as the most typical features. Within the TC body, the inner portions (i.e., eye and eyewall) received even more concerns than the outer region. These findings are consistent with the traditional knowledge about the inner structures of a TC and their storm-relative distributions. By contrast, the results in Type II demonstrate a different pattern. The main body of the TC cloud was no longer highlighted most significantly, although it was still regarded as being one of the main fingerprint features. For this type, it is still unclear whether the model is able to identify the TC successfully with an unknown but correct method or if it only happened to make a right prediction but in a wrong way. Thus, more advanced visualization techniques are required to further explore how a DCNN model works internally.
Figure 11 examines the heat maps for some non-TC images but which are misjudged as TC images (i.e., false positive predictions). Basically, these results show a high degree of similarity to those for TCs with a weak intensity level in Fig. 10. In fact, a large number of such false positive predictions correspond to the dissipative process of a TC during or after landfall, when the intensity of the storm was decreased to a level below 35 kn and the formerly huge TC cloud was fragmented. It is possible that the DCNN model is able to correlate the patches of clouds with a decaying TC.
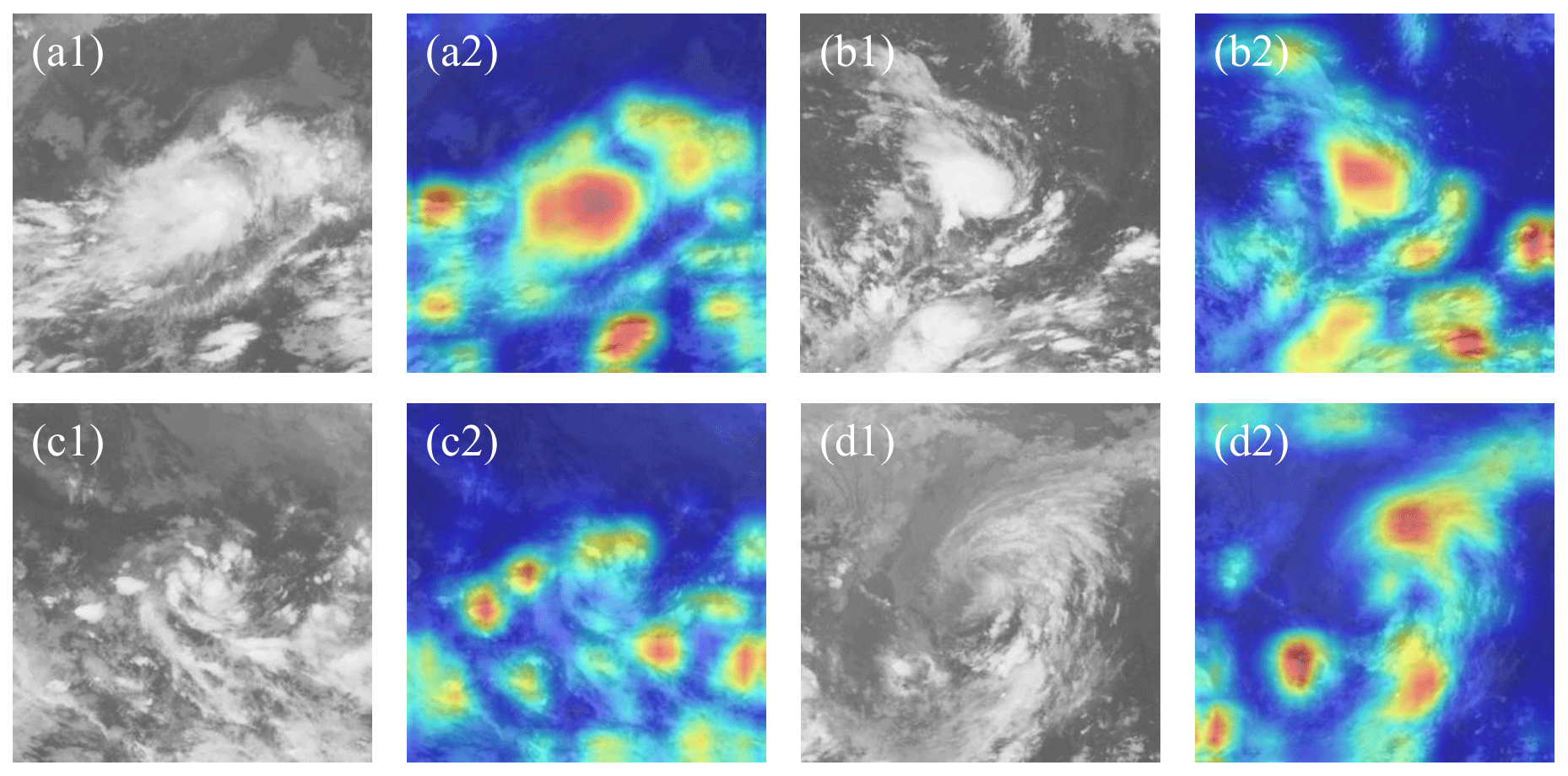
Figure 11Heat maps of some non-TC images misjudged as TC images compared with associated L images.
3.3 Results for NWPO images
3.3.1 Method improvement via image pyramid technique
The NWPO images can be analyzed in a similar way to the one for L images. However, results from previous attempts show that the fingerprint features highlighted in the heat maps of the DCNN model (Fig. 3) could not be focused on TC clouds, although the prediction accuracy of the model was pretty high. This should be attributed to the fact that the TC structure is too small compared to many other graphic features involved in an NWPO image (e.g., coastal lines and continent/peninsulas), and the model is able to correlate the label of the image with such unexpected features rather than the TC clouds.
To impel the model to focus on cloud features during the identification process, the model was trained by the NWPO images in conjunction with the L images. However, the obtained results of heat maps were still abnormal. What is worse is that the problem of decreased prediction accuracy occurs. Attempts were also made to train the model by NWPO images in conjunction with the magnified views of TCs that were extracted from the NWPO images, but the results were similar to those in the former case. The unacceptable performance of the model may be explained as follows. As mentioned previously, the NWPO image covers a much larger region (97∘ × 52∘) than the L image (20∘ × 20∘). As a result, the scale of TC structures in NWPO images turns to be considerably smaller than that in L images, which makes it difficult for the model to correlate the TC features in NWPO images with those in L images effectively.
Finally, the image pyramid (IP) technique was adopted, and the results turned to be satisfactory. The IP technique was firstly proposed to solve classification problems for targets with varied scales in the classifier, such as face detection and recognition (Zhang et al., 2016). With the development of feature pyramid networks (FPNs), it was then used to deal with problems with small targets (Lin et al., 2017). Due to the great convenience in operation and high efficiency in performance, this technique has been increasingly exploited in the field of computer vision.
Table 2 and Fig. 12 summarize the changes before and after using IP technology. It can be clearly seen from Table 2 that all parameters are only slightly improved after IP technology is used. However, it can be obvious from Fig. 12b and c that the weight range of the model after using IP technology basically covers TC clouds or TC-like clouds, while heat maps without IP technology show relatively strange attention.
Table 2Comparison of indicators before and after using IP technology.

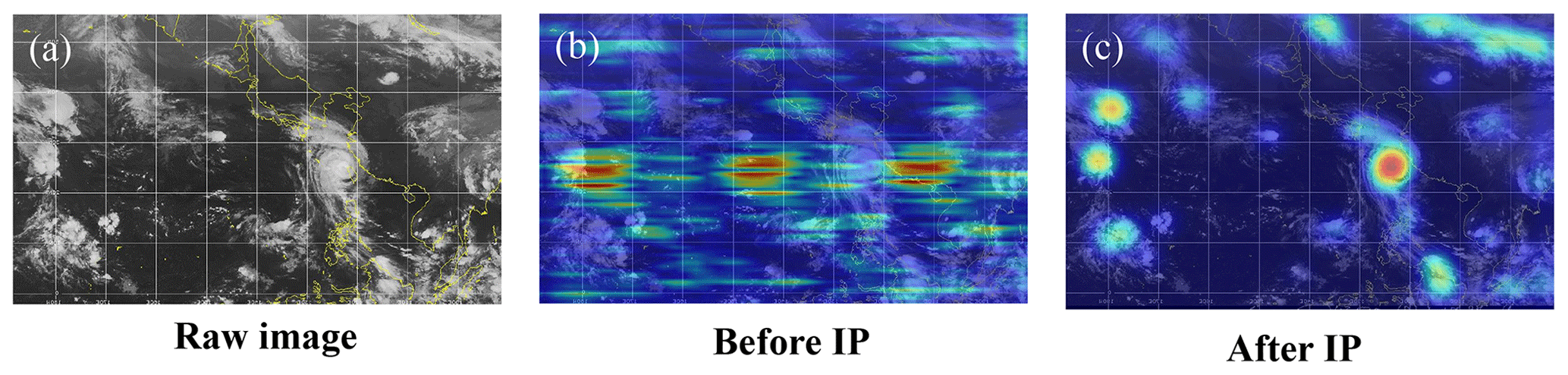
Figure 12Heat map before and after using IP.
The image pyramid is actually a cascade structure for multi-scale representations of an image. It consists of a series of pictures that are derived from the same original image but with varied characteristic scales for highlighted targets. As an example, Fig. 13 illustrates the realization process for the image pyramid of a TC image. The original image (herein called the large picture) consists of . One can extract a portion (containing , , etc.) of the image to generate a magnified view of the TC (herein called medium picture). In this study, a random extraction stratify was adopted. Similarly, a second stage magnified view (containing , , etc.) can be derived from the original picture (herein called the small picture). The large, medium, and small pictures are then normalized in terms of size (i.e., to have same the number of pixels). A combination of the several normalized pictures forms a multi-level image pyramid of the original picture. As can be seen, the TC in these pictures is expressed in varied scales and resolutions.
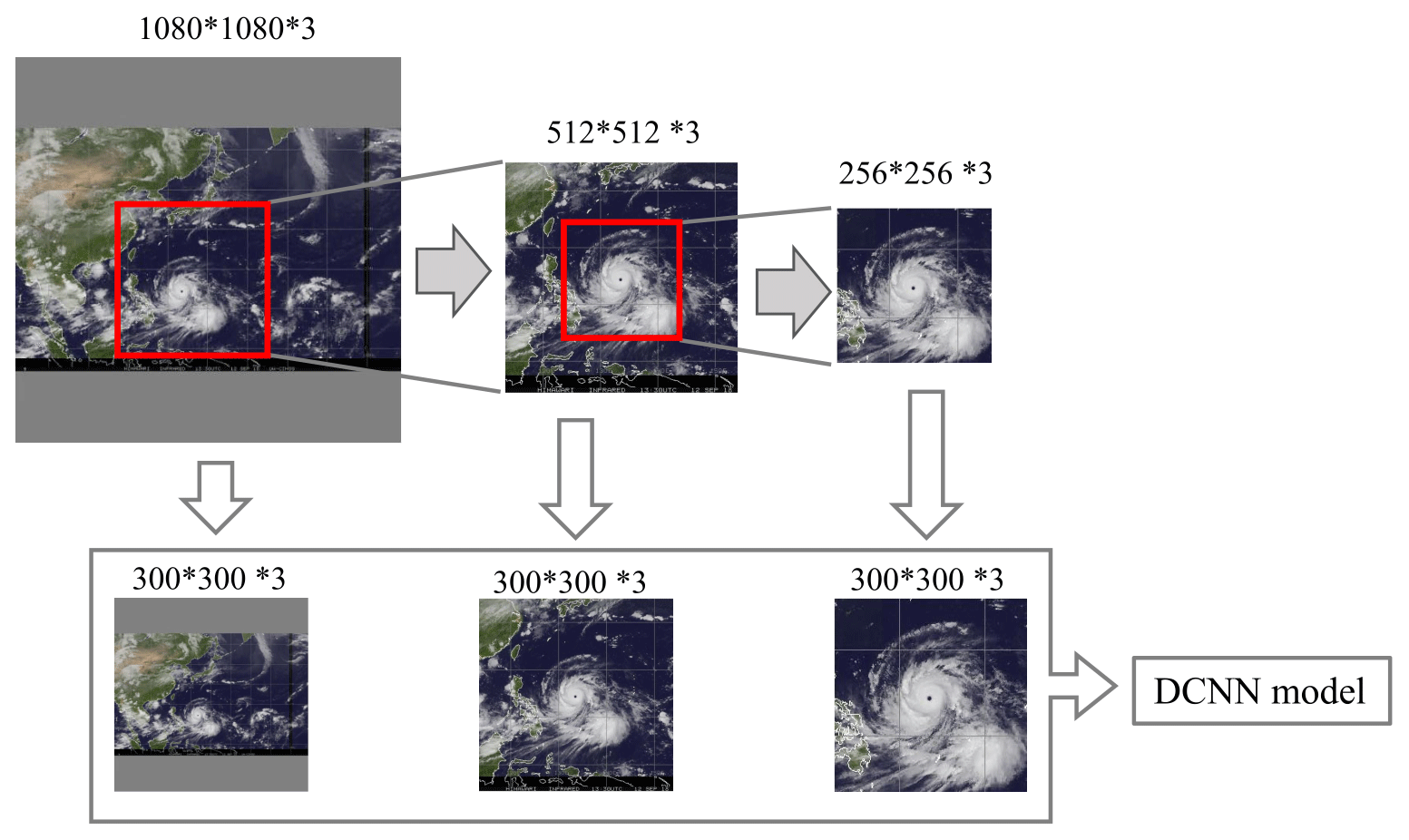
Figure 13Flowchart for the realization of image pyramid of a TC image.
Using the IP technique, the input samples of NWPO images for the DCNN model turned to be ∼ 135 000, and the proportion among the numbers of small, medium, and large images approached . The model was then trained and validated based on the samples following the method introduced previously. Note that only the large images (∼ 4600 samples) were tested and analyzed during the testing process.
3.3.2 Overall performance
Because there are many more NWPO images than L images, the prediction performance of the proposed model for NWPO images tends to be more robust. Thus, when using the 10-fold cross-validation strategy to train and validate the model, it was only conducted three times. Figure 14 shows the evolutional curves of the prediction accuracy during both the training and validation processes. Following the analytical method adopted for related results of L images, it is found that the performance of the model for NWPO images is satisfactory in terms of convergence, robustness, and anti-overfitting. The training accuracy within 100 epochs reached 99.99 %, compared to 95.37 % for the validation accuracy. These results demonstrate the effectiveness of using the IP technique to deal with identification problems with small targets. Although the performances for the three training/validation processes were similar, the one associated with TG-1 dataset was comparatively more consistent with the ensemble mean performance. Thus, the model trained by this dataset, i.e., TG-1 model, was adopted during the testing process.
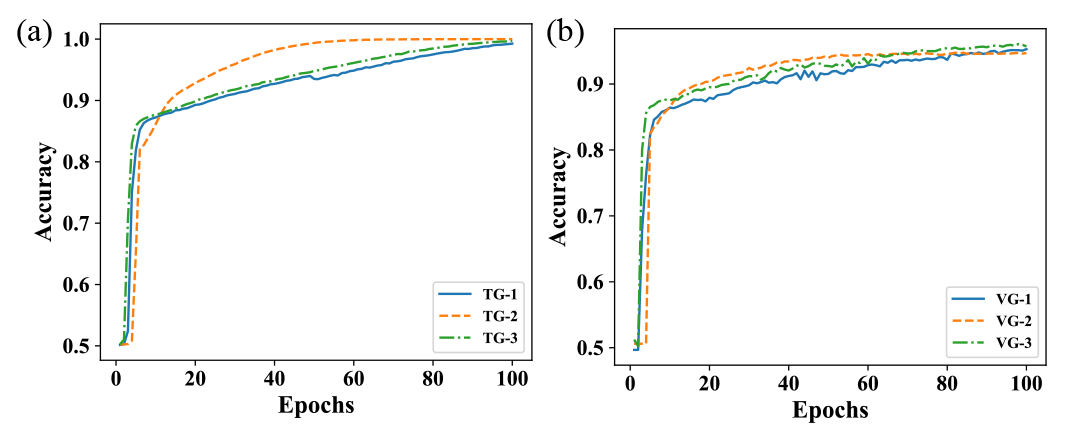
Figure 14Evolutional curves of the prediction accuracy of the proposed DCNN model for NWPO images, with the (a) training process and (b) validation process.
The prediction performance of the TG-1 model during the testing process is detailed in Table 3 and Fig. 15. The results for all studied indexes, except for precision and AUC, are found to be better than their counterparts for L images (refer to Table 1 and Fig. 6), although there exist many unfavorable factors in NWPO images for the performance of the model. The reason is twofold. First, using the IP technique makes it effective to train the model with NWPO images. Second, training the DCNN model with more samples helps to promote prediction accuracy.
Table 3Prediction performance of the TG-1 model during testing process.

Given the better performance of the model for NWPO images in terms of accuracy and recall ratio than that for L images, the relatively lower precision herein reveals that there were relatively more false positive predictions than those for L images. To better understand this issue, Fig. 16 depicts some selected non-TC images that were misjudged as TC images and associated heat maps. It is found that the majority of such false positive predictions corresponded to images whose cloud characteristics were similar to those of SCIs with a TC at a low intensity level (refer to Figs. 8 and 9). As discussed previously, there are two possibilities. First, the image indeed involves a TC, but the storm stayed at the ending or beginning stage of the life cycle, and its intensity was too low to be classified as a TC level. Second, there are no TCs involved in the image, but the cloud features are too similar to those for TC images that the model failed to distinguish the two types correctly. Because the NWPO image covers a much larger area than the L image, an NWPO image tends to contain more such TC-like features than an L image, which results in relatively more false positive predictions for the NWPO images.
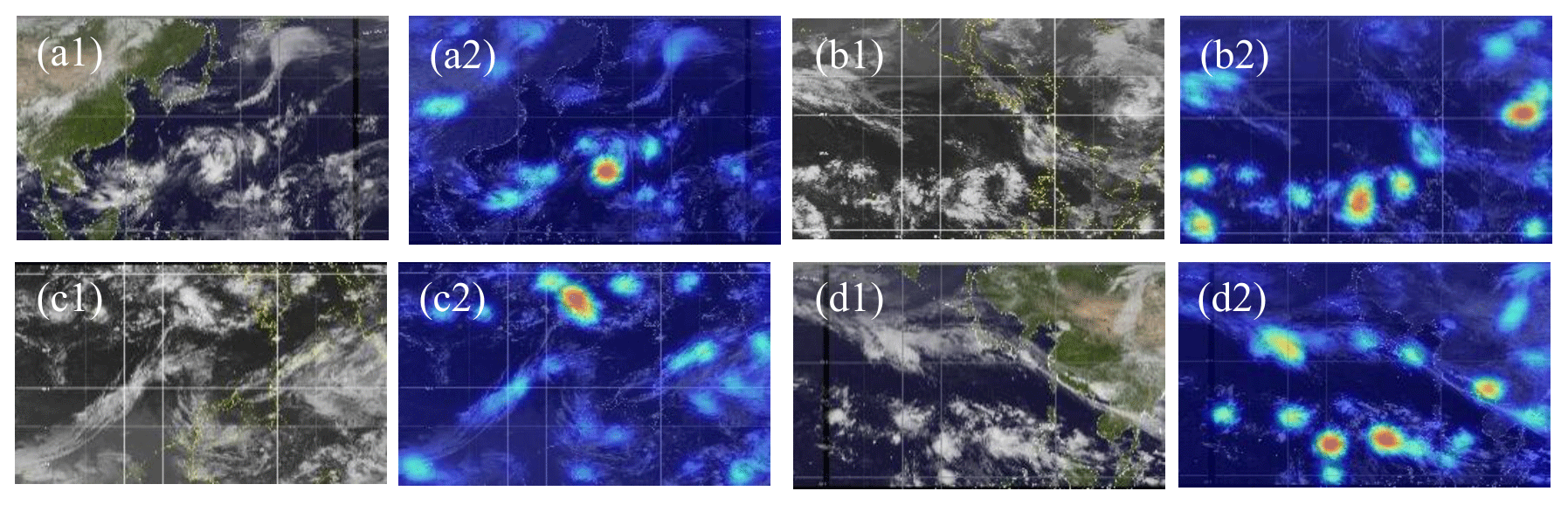
Figure 16Non-TC images misjudged as TC images and associated heat maps.
3.3.3 Dependence on TC intensity for SCIs with a single TC
To examine the dependence of prediction performance of the model on TC intensity, the testing samples of NWPO images involving a single TC were stratified into different groups according to the TC intensity. Figure 17 shows the prediction probability for each of the intensity groups. Overall, the false positive predictions (or the recall ratio) become fewer (larger) as the TC intensity increases. Comparing the results to those shown in Fig. 7, it is further found that there are fewer false negative predictions for NWPO images with TCs at low-to-moderate intensity levels (< 70–80 kn), despite the fact that the number of testing samples for NWPO images is much larger than that for L images. The above findings suggest the proposed model herein has a good performance in terms of avoiding the omission of identifying TCs.
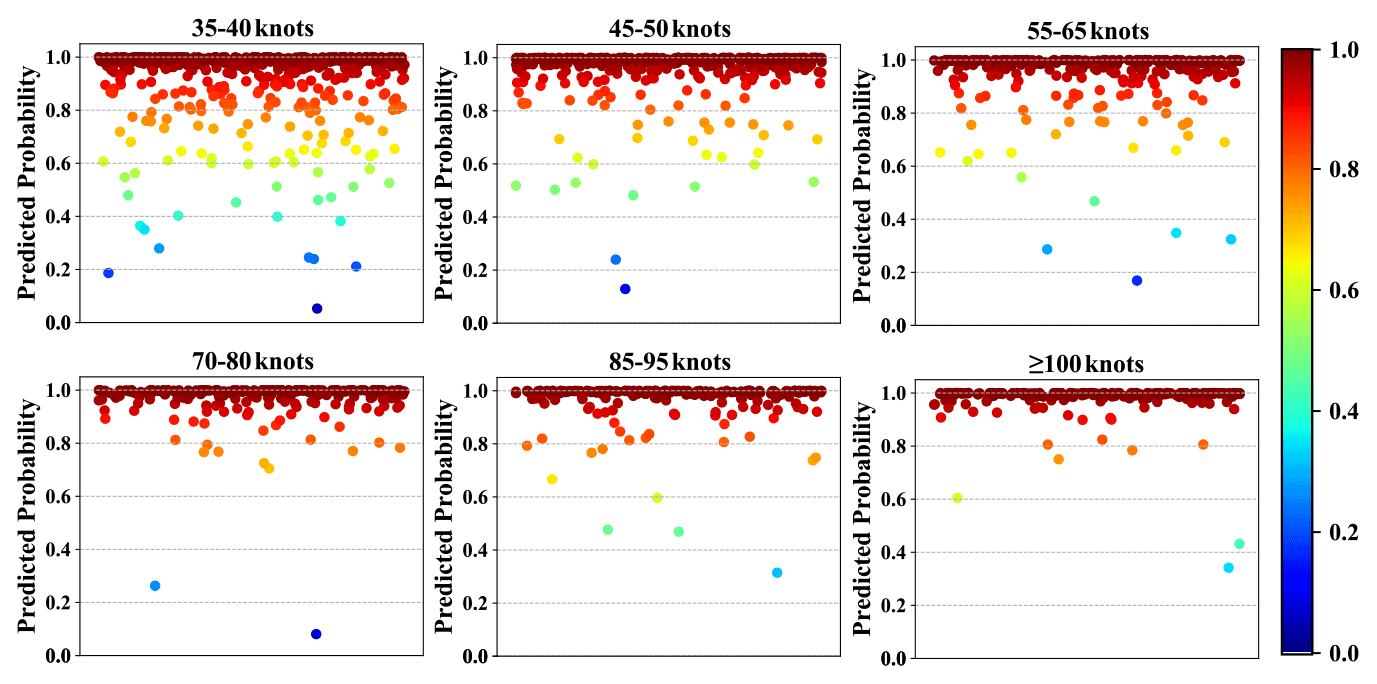
Figure 17Prediction probability for NWPO images involving a single TC stratified by TC intensity.
Figure 18 exhibits two types of successfully identified TC images and associated heat maps. As can be seen, the fingerprint features from both types can be reasonably focused on clouds. It seems that the model is able to distinguish clouds from other background factors, such as coastal lines, continent/peninsulas, ocean surface, and deserts, which are depicted in varied colors in the image. The difference between the two types of results lies in the fact that the main body of the TC cloud in Type I is identified as the primary fingerprint feature, while there are multiple fingerprint features highlighted in the heat maps from Type II. The above difference may be explained by the varied characteristics of color gradation of the clouds between the two types of images. Results suggest that all fingerprint features with more concerns in the heat maps correspond to brighter clouds in the image. In Type I, the TC clouds are brightest among various kinds of clouds. By contrast, there are several cloud clusters in an image from Type II whose color gradations are comparable to that of the TC cloud.
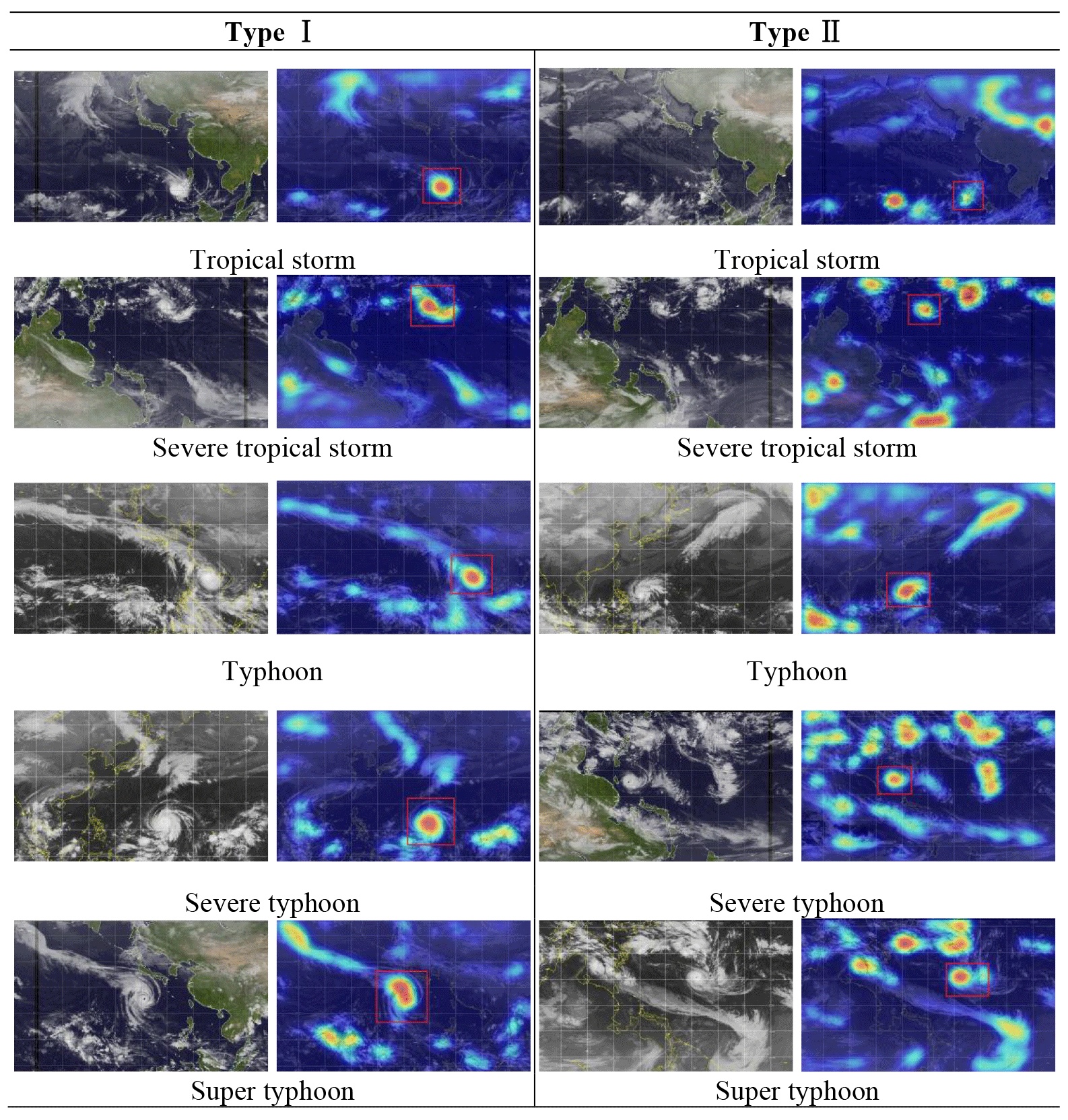
Figure 18Heat maps of some successfully identified TC images compared with associated NWPO images that contain a single TC.
Figure 19 depicts some typical TC images that were misjudged as non-TC images. In reference to the images with a weak to moderately strong TC, the reasons to account for such false negative predictions are similar to those discussed in Fig. 8. For images with a strong TC (≥ 80 kn), the TC clouds are found to be distinctly smaller than their counterparts in Fig. 18. It is expected that the IP structure of this paper fails to connect such tiny features with those on a normal scale. Thus, an IP structure with a few more levels may be more appropriate for such cases.
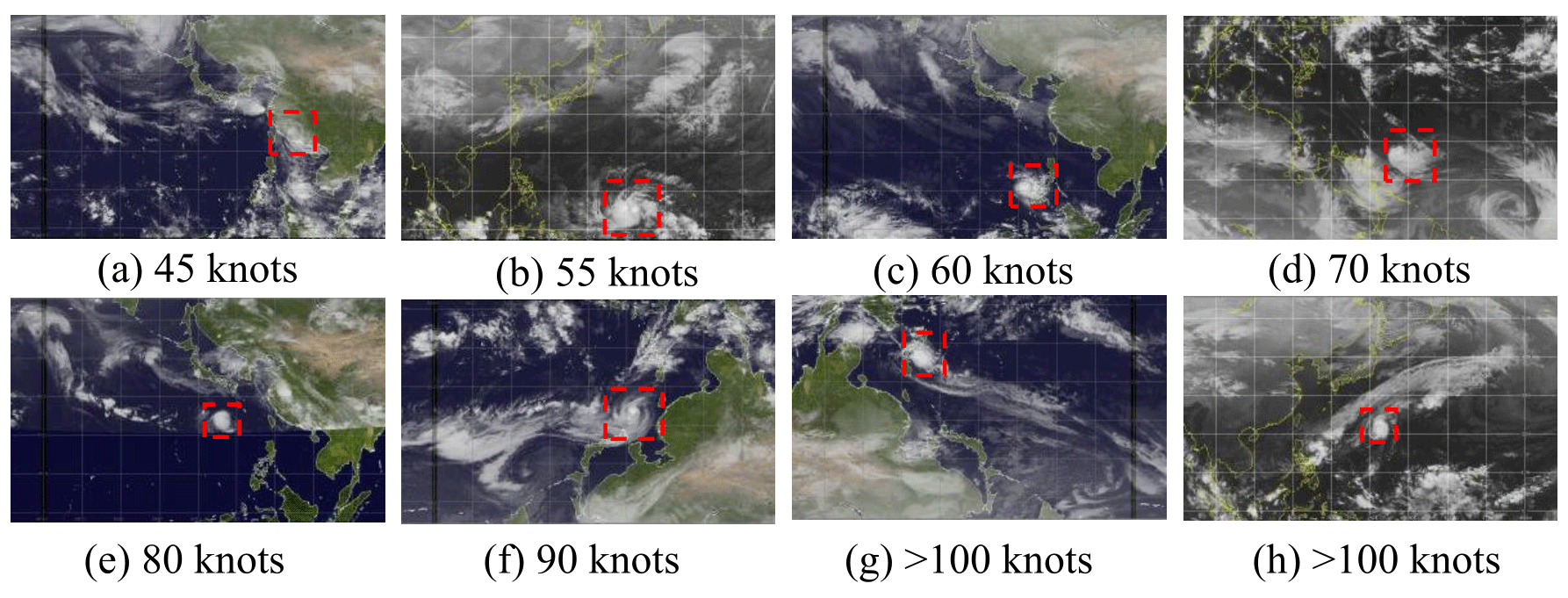
Figure 19TC (demarcated by a red rectangle) images misjudged as non-TC images.
3.3.4 Dependence on the number of TCs within a TC image
One of the largest differences between L images and NWPO images is that there may be multiple TCs involved in an NWPO image, while there is no more than one TC in an L image. To examine the dependence of the prediction performance of the model on the number of TCs within a TC image, the testing samples of NWPO images involving multiple TCs were stratified into different groups according to the TC number. Figure 20 shows the prediction probability for each of the groups. The recall ratios for the groups with an image involving one TC, two TC, and three or more TCs are 98.38 %, 99.75 %, and 100 %, respectively. It is clear that, as the increase in TC numbers for associated NWPO images occurs, it becomes more and more unlikely for the model to misjudge a TC image as a non-TC image. The above observation is consistent with one's expectation, as an image involving more TCs usually contains more distinguishable fingerprint features that facilitate the model to predict more correctly.
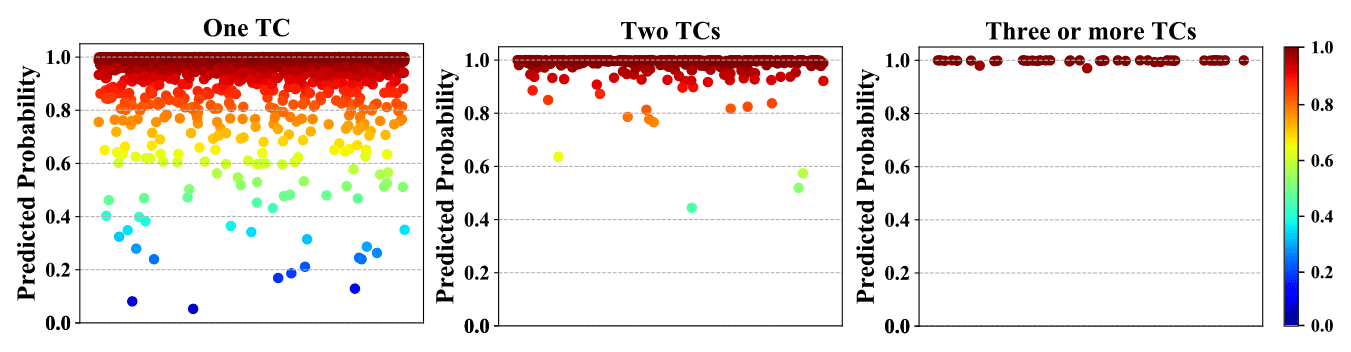
Figure 21 examines the heap maps of some successfully identified images with multiple TCs. As demonstrated, all the TCs involved in the images are highlighted in the heat maps from the two categorized types. For the results in Type I, the TCs are recognized exclusively as the primary fingerprint features. However, for the results in Type II, there may be some additional false targets identified; meanwhile, some of the TCs may receive even fewer concerns than the highlighted false targets in the heat maps. From the perspective of TC identification, an NWPO image involving multi-TCs may be regarded as a composite of multiple NWPO images, with each of them containing only a single TC. Consequently, the findings in Fig. 21 can be comprehended in a similar way to the one for Fig. 18.
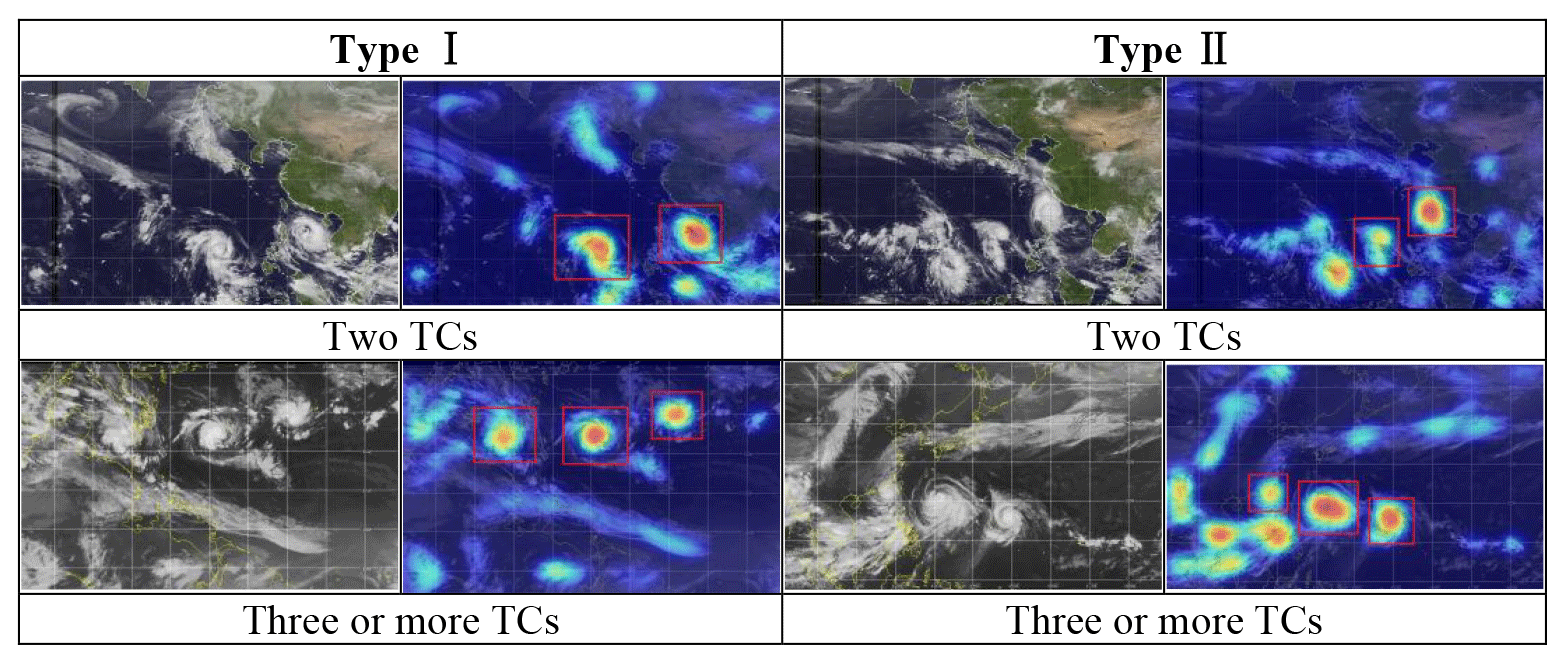
Figure 21Heat maps of some successfully identified TC images compared with associated NWPO images that involve multiple TCs.
This article presents a study on the identification of TC images from SCIs via DCNN techniques. There were two DCNN models proposed to, respectively deal with the issues associated with L images and NWPO images which covered different geographical areas and varied numbers of TCs. Results suggested that the performances of the two models were satisfactory, with both of the prediction accuracies exceeding 96 %. Through analysis via heat map techniques, it was demonstrated that the DCNN models are able to focus on TC fingerprint features successfully during the testing process. Thus, it provides an automatic and objective method to distinguish TC images from non-TC images by using deep learning techniques. This is pretty useful for many SCI-based studies, e.g., SCI-aided identification of TC intensity, in which it is prerequisite to select TC images usually out from hundreds of thousands of SCI samples that correspond to both TC and non-TC conditions.
The two proposed models differ from each other by both the internal structures and the realization of training and validation processes. The NWPO model consisted of more convolutional layers and dropout layers, so it would be more efficient to extract useful information from a more complex image. More importantly, the IP techniques were specially adopted for the NWPO model to generate more appropriate training and validation datasets. Results show that the NWPO model failed to focus on correct targets if they were trained by conventionally pre-processed image samples in which the TC structures became considerably small with respect to the coverage area of the image. By contrast, when training the model with image samples pre-processed via the IP techniques, all TC fingerprint features could be identified correctly, which reflects the effectiveness of using the IP technique to deal with identification problems with small targets.
Despite the overall good performance, the DCNN models failed to provide correct predictions for some cases. Basically, there are three reasons to account for the failures. First, there are essentially no differences between an image involving a TC at a low intensity level and the one that should be regarded as a non-TC image but actually contains a tropical depression. Second, the morphological characteristics of TC clouds involved in some TC images, especially those corresponded to TCs staying at the very beginning and ending stages of their life cycle, are too similar to those associated with non-TC conditions, which makes it to be challenge to identify such TC images correctly. Third, there were insufficient training samples for some special types of TC images (e.g., Fig. 8f). Whatever the reason, more training samples that cover each type of the misjudged SCIs are needed so that the model can be trained to perform more accurately.
This study has only considered the identification problem, i.e., to judge whether a SCI belongs to a TC image or a non-TC image, but has no concerns with the problem where the TC is located in a TC image. Although all the main potential TC fingerprint features have been identified in the heap maps, further efforts are needed to distinguish the true targets from the false.
The DCNN models are available as Python *.py files in the Supplement, where the corresponding examples of implementing the two models are also available.
The data used in this study are openly available at the National Institute of Informatics (NII) at http://agora.ex.nii.ac.jp/digital-typhoon/ (last access: 29 November 2021; NII, 2021), Meteorological Satellite Research Cooperation Institute, University of Wisconsin-Madison (CIMSS) at http://tropic.ssec.wisc.edu/ (last access: 29 November 2021; CIMSS, 2021), and China Meteorological Administration tropical cyclone database (Ying et al., 2014, https://doi.org/10.1175/JTECH-D-12-00119.1; Lu et al., 2021, https://doi.org/10.1007/s00376-020-0211-7) at http://tcdata.typhoon.org.cn/ (last access: 29 November 2021).
The supplement related to this article is available online at: https://doi.org/10.5194/amt-15-1829-2022-supplement.
BT drafted the paper, developed the methodology, and performed the data analysis. XFS helped with the methodology development. JYF conceptualized the paper, with the help of YCH, organized the funding, with the help of YCH, and assisted with the editing and revision of the paper, with the help of PWC. YCH also assisted with drafting and revising the paper.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors would like to thank our colleagues, who made suggestions for our paper, and the developers, who selflessly provided the source code to the research.
This research has been funded by the National Science Fund for Distinguished Young Scholars, China (grant no. 51925802), the National Natural Science Foundation of China (grant nos. 51878194 and 52178465), the 111 Project (grant no. D21021), and the Guangzhou Municipal Science and Technology Project (grant no. 20212200004).
This paper was edited by Lars Hoffmann and reviewed by three anonymous referees.
Chattopadhay, A., Sarkar, A., Howlader, P., and Balasubramanian, V. N.: Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks, in: 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018, IEEE WACV, 839–847, https://doi.org/10.1109/WACV.2018.00097, 2018.
Chen, R., Zhang, W., and Wang, X.: Machine learning in tropical cyclone forecast modeling: A review, Atmosphere-Basel, 11, 676, https://doi.org/10.3390/atmos11070676, 2020.
Di Vittorio, A. V. and Emery, W. J.: An automated, dynamic threshold cloud-masking algorithm for daytime AVHRR images over land, IEEE T. Geosci. Remote., 40, 1682–1694, https://doi.org/10.1109/TGRS.2002.802455, 2002.
Dvorak, V. F.: Tropical cyclone intensity analysis using satellite data, in: NOAA Technical Report NESDIS, 11, US Department of Commerce, National Oceanic and Atmospheric Administration, National Environmental Satellite, Data, and Information Service, Washington, DC, USA, pp. 1–47, 1984.
Geng, X. Q., Li, Z. W., and Yang, X. F.: Tropical cyclone auto-identification from stationary satellite imagery, Journal of Image and Graphics, 19, 964–970, https://doi.org/10.11834/jig.20140618, 2014.
Goerss, J. S.: Tropical cyclone track forecasts using an ensemble of dynamical models, Mon. Weather Rev., 128, 1187–1193, https://doi.org/10.1175/1520-0493(2000)128<1187:TCTFUA>2.0.CO;2, 2000.
Han, L., Fu, S., Zhao, L., Zheng, Y., Wang, H., and Lin, Y.: 3D convective storm identification, tracking, and forecasting—An en-hanced TITAN algorithm, J. Atmos. Ocean. Tech., 26, 719–732, https://doi.org/10.1175/2008JTECHA1084.1, 2009.
Hanley, J. A. and McNeil, B. J.: The meaning and use of the area under a receiver operating characteristic (ROC) curve, Radiology, 143, 29–36, https://doi.org/10.1148/radiology.143.1.7063747, 2006.
Hayatbini, N., Hsu, K., Sorooshian, S., Zhang, Y., and Zhang, F.: Effective cloud detection and segmentation using a gradient-based algorithm for satellite imagery: Application to improve PERSIANN-CCS, J. Hydrometeorol., 20, 901–913, https://doi.org/10.1175/JHM-D-18-0197.1, 2019.
Jégou, S., Drozdzal, M., Vazquez, D., Romero, A., and Bengio, Y.: The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation, in: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017, IEEE CVPRW, 1175–1183, https://doi.org/10.1109/CVPRW.2017.156, 2017.
Krizhevsky, A., Sutskever, I., and Hinton, G. E.: Imagenet classification with deep convolutional neural networks, Adv Neur. Inf., 60, 84–90, https://doi.org/10.1145/3065386, 2019.
LeCun, Y., Bengio, Y., and Hinton, G.: Deep learning, Nature, 521, 436–444, https://doi.org/10.1038/nature14539, 2015.
Lee, J., Im, J., Cha, D., Park, H., and Sim, S.: Tropical cyclone intensity estimation using multi-dimensional convolutional neural networks from geostationary satellite data, Remote Sens.-Basel, 12, 108, https://doi.org/10.3390/rs12010108, 2020.
Liao, X. L., Tian, Y. G., and Liu, J.: Research on the TC Segmentation Method with Priori Features, Remote Sensing for Land and Resources, 23, 37–42, http://en.cgsjournals.com/zgdzdcqkw-data/gtzyyg/2011/3/PDF/gtzyyg201103007.pdf (last access: 15 March 2022), 2011.
Lin, T., Dollár, P., Girshick, R., He, K., Hariharan, B., and Belongie, S.: Feature pyramid networks for object detection, in: 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017, IEEE CVPR, 936–944, https://doi.org/10.1109/CVPR.2017.106, 2017.
Liu, C., Zhang, Y., Chen, P., Lai, C., Chen, Y., Cheng, J., and Ko, M.: Clouds classification from Sentinel-2 imagery with deep residual learning and semantic image segmentation, Remote Sens.-Basel, 11, 119, https://doi.org/10.3390/rs11020119, 2019.
Lopez-Ornelas, E., Laporterie-Dejean, F., and Flouzat, G.: Satellite image segmentation using graph representation and morpho-logical processing, Proc. SPIE, 5238, 104–113, https://doi.org/10.1117/12.511221, 2004.
Lu, J., Zhang, C. J., Zhang, X., Yang, B., and Duanmu, C.J.: Auto-recognition of typhoon cloud based on boundary features, J. Remote Sens., 14, 990–1003, http://www.gissky.net/paper/UploadFiles_4495/201208/2012080521453763.pdf (last access: 15 March 2022), 2010.
Lu, X., Yu, H., Ying, M., Zhao, B., Zhang, S., Lin, L., Bai, L., and Wan, R.: Western north pacific tropical cyclone database created by the China meteorological administration, Adv. Atmos. Sci., 38, 690–699, https://doi.org/10.1007/s00376-020-0211-7, 2021 (data available at: http://tcdata.typhoon.org.cn/, last access: 29 November 2021).
Meteorological Satellite Research Cooperation Institute, University of Wisconsin-Madison (CIMSS): Tropical Cyclones ... A Satellite Perspective, CIMSS, http://tropic.ssec.wisc.edu/, last access: 29 November 2021.
Miller, R. J., Schrader, A. J., Sampson, C. R., and Tsui, T. L.: The Automated Tropical Cyclone Forecasting System (ATCF), Weather Forecast., 5, 653–660, https://doi.org/10.1175/1520-0434(1990)005<0653:TATCFS>2.0.CO;2, 1990.
Molodianovitch, K., Faraggi, D., and Reiser, B.: Comparing the areas under two correlated ROC curves: parametric and nonparametric approaches, Biometrical J., 48, 745–757, https://doi.org/10.1002/bimj.200610223, 2006.
National Institute of Informatics (NII): Digital Typhoon: Typhoon Images and Information, NII, http://agora.ex.nii.ac.jp/digital-typhoon/, last access: 29 November 2021.
Olander, T. L. and Velden, C. S.: The Advanced Dvorak Technique (ADT) for estimating tropical cyclone intensity: Update and new capabilities, Weather Forecast., 34, 905–922, https://doi.org/10.1175/WAF-D-19-0007.1, 2019.
Pang, S., Xie, P., Xu, D., Meng, F., Tao, X., Li, B., Li, Y., and Song, T.: NDFTC: A New Detection Framework of Tropical Cyclones from Meteorological Satellite Images with Deep Transfer Learning, Remote Sens.-Basel, 13, 1860, https://doi.org/10.3390/rs13091860, 2021.
Powers, D.: Evaluation: From Predcision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation, J. Mach. Learn. Technol., 2, 37–63, https://doi.org/10.9735/2229-3981, 2011.
Ron, K.: A study of cross-validation and bootstrap for accuracy estimation and model selection, in: Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence, Montreal, Quebec, Canada, 20–25 August 1995, IJCAI, 1137–1143, 1995.
Saito, T. and Rehmsmeier, M.: The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets, PLoS One, 10, e118432, https://doi.org/10.1371/journal.pone.0118432, 2015.
Sampson, C. R. and Schrader, A. J.: The automated tropical cyclone forecasting system (version 3.2), B. Am. Meteorol. Soc., 81, 1231–1240, https://doi.org/10.1175/1520-0477(2000)081<1231:TATCFS>2.3.CO;2, 2000.
Schmidhuber, J.: Deep learning in neural networks: An overview, Neural Networks, 61, 85–117, https://doi.org/10.1016/j.neunet.2014.09.003, 2015.
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D.: Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization, Int. J. Comput. Vision, 128, 336–359, https://doi.org/10.1007/s11263-019-01228-7, 2020.
Simonyan, K. and Zisserman, A.: Very deep convolutional networks for large-scale image identification, arXiv [preprint], arXiv:1409.1556, 10 April 2015.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R.: Dropout: A Simple Way to Prevent Neural Networks from Overfitting, J. Mach. Learn. Res., 15, 1929–1958, http://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf (last access: 2 July 2020), 2014.
Sun, L., Wei, J., Wang, J., Mi, X., Guo, Y., Lv, Y., Yang, Y., Gan, P., Zhou, X., and Jia, C.: A universal dynamic threshold cloud de-tection algorithm (UDTCDA) supported by a prior surface reflectance database, J. Geophys. Res.-Atmos., 121, 7172–7196, https://doi.org/10.1002/2015JD024722, 2016.
Sun, X., Xie, L., Shah, S. U., and Shen, X.: A Machine Learning Based Ensemble Forecasting Optimization Algorithm for Preseason Prediction of Atlantic Hurricane Activity, Atmosphere-Basel, 12, 522, https://doi.org/10.3390/atmos12040522, 2021.
Velden, C., Harper, B., Wells, F., Beven, J. L., Zehr, R., Olander, T., Mayfield, M., Guard, C. C., Lander, M., and Edson, R.: The Dvorak tropical cyclone intensity estimation technique: A satellite-based method that has endured for over 30 years, B. Am. Meteorol. Soc., 87, 1195–1210, https://doi.org/10.1175/BAMS-87-9-1195, 2006.
Velden, C. S., Olander, T. L., and Zehr, R. M.: Development of an objective scheme to estimate tropical cyclone intensity from digital geostationary satellite infrared imagery, Weather Forecast., 13, 172–186, https://doi.org/10.1175/1520-0434(1998)013<0172:DOAOST>2.0.CO;2, 1998.
Wang, K., Li, X., and Trinder, J. C.: Mathematical morphological analysis of typical cyclone eyes on ocean SAR, in: 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014, 4393–4396, https://doi.org/10.1109/IGARSS.2014.6947464, 2014.
Wang, Y.: Vortex Rossby waves in a numerically simulated tropical cyclone. Part II: The role in tropical cyclone structure and intensity changes, J. Atmos. Sci., 59, 1239–1262, https://doi.org/10.1175/1520-0469(2002)059<1239:VRWIAN>2.0.CO;2, 2002.
Ying, M., Zhang, W., Yu, H., Lu, X., Feng, J., Fan, Y., Zhu, Y., and Chen, D.: An overview of the China Meteorological Administration tropical cyclone database, J. Atmos. Ocean. Tech., 31, 287–301, https://doi.org/10.1175/JTECH-D-12-00119.1, 2014 (data available at: http://tcdata.typhoon.org.cn/, last access: 29 November 2021).
Zeiler, M. D. and Fergus, R.: Visualizing and Understanding Convolutional Networks, in: Computer Vision – ECCV 2014, Lecture Notes in Computer Science, chapter 53, Springer, Cham, Switzerland, 818–833, https://doi.org/10.1007/978-3-319-10590-1_53, 2014.
Zhang, K., Zhang, Z., Li, Z., and Qiao, Y.: Joint face detection and alignment using multitask cascaded convolutional networks, IEEE Signal Proc. Let., 23, 1499–1503, https://doi.org/10.1109/LSP.2016.2603342 2016.
Zou, Z., Shi, Z., Guo, Y., and Ye, J.: Object detection in 20 years: A survey, arXiv [preprint], arXiv:1905.05055, 16 May 2019.