the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 03 Mar 2020
| 03 Mar 2020
Atmospheric condition identification in multivariate data through a metric for total variation
Nicholas Hamilton
Identification of atmospheric conditions within a multivariable atmospheric data set is a necessary step in the validation of emerging and existing high-fidelity models used to simulate wind plant flows and operation. Atmospheric conditions relevant for wind energy research include stationary conditions, given the need for well-converged statistics for model validation, as well as conditions observed less frequently, such as extreme atmospheric events, which are used in wind turbine and wind plant design. Aggregation of observations without regard to covariance between time series discounts the dynamical nature of the atmosphere and is not sufficiently representative of atmospheric conditions. Identification and characterization of continuous time periods with atmospheric conditions that have a high value for analysis or simulation set the stage for more advanced model validation and the development of real-time control and operational strategies. The current work explores a single metric for variation in a multivariate data sample that quantifies variability within each channel as well as covariance between channels. The total variation is used to identify conditions of interest that conform to desired objective functions, such as stationary conditions, ramps or waves of wind speed, and changes in wind direction. Total variation is somewhat sensitive to the presence of outliers in the input data, and the method is best complemented by quality-control procedures to ensure reliable results. The direct detection and classification of events or conditions of interest within atmospheric data sets is vital to developing our understanding of wind plant response and to the formulation of forecasting and control models.
- Article
(3762 KB) - Full-text XML
- BibTeX
- EndNote




Parsing multivariate data sets that are ever growing in size and complexity can be a daunting task for researchers seeking to identify periods or events of interest in time series data (Preston et al., 2009; Shahabi and Yan, 2003). This is especially true for wind energy research seeking to validate high-fidelity numerical models against field observations (Barthelmie et al., 2015; Larsen et al., 2013; Sørensen and Shen, 2002). Wind plants operate continuously over time periods spanning years and across a broad range of atmospheric conditions, each of which implicitly impact the operation of the wind plant, either in terms of power production, operations and maintenance costs, or energy forecasting for grid integration.
Field observations of wind plants are typically collected by instrumentation mounted to wind turbines or meteorological towers, met masts, and by supervisory control and data acquisition (SCADA) systems. Wind plant data sets typically include measurements of wind speed and direction, local temperature and pressure, and wind turbine operational data, such as operational status, power production, and nacelle position. Each of the atmospheric quantities of interest may be classified as non-ergodic stochastic variables that are fundamentally connected (i.e., strongly interdependent).
Wind speed ramps are of particular interest in wind plant power forecasting due to the need to balance energy production against demand curves and in the planning of required reserves and base loads (Sevlian and Rajagopal, 2012; Zhang et al., 2014). Previous work has focused on the forecasting of mesoscale changes in wind speed (Bossavy et al., 2013; Ferreira et al., 2011), generally concentrating on risk and reliability issues for wind turbines. Ramp event detection has been a research focus for more than a decade (Cutler et al., 2007; Ferreira et al., 2013; Hannesdóttir and Kelly, 2019) and has produced some specific recommendations for individual turbine controls and the influence on operations and maintenance costs or activities. Previous research in wind speed ramps is not easily generalized to the identification and characterization of other dynamical events of interest, despite parallels in the detection process and considerations for wind turbine or plant operations and controls.
The detection of events in noisy data is of particular interest in the case of turbulent atmospheric data sets, especially given the need for more sophisticated forecasting systems (Belušić and Mahrt, 2012; Fulcher, 2018; Gamage and Hagelberg, 1993; Kang et al., 2014, 2017; Sun et al., 2015). One of the more common event detection methods leverages the continuous or discrete wavelet transform (Gamage and Hagelberg, 1993; Kumar and Foufoula-Georgiou, 1997; Lilly, 2017). Wavelet transforms leverage time–frequency signals designed to have specific properties that make them easy to use in signal processing applications. However, wavelet transformation remains computationally intensive and requires a fair amount of expertise to implement effectively and avoid the common pitfalls of signal shift sensitivity and the poor representation of phase and directionality (Taswell, 2001). A more direct method simply considers the covariance matrix of the input data, which represents the statistical spread of each data channel as well as cross-correlated variability (Eaton, 1983; Wasserman, 2013). Reducing the variability of a sample of multidimensional observations to a single metric is a necessary step to using numerical methods such as least-squares minimization for event detection and classification. Another method for parsing atmospheric conditions found in the literature leverages the Hilbert transform, which convolves time series signals with a Cauchy kernel and results in a phase-shifted set of Fourier components. This method has been used successfully to relate ocean wave conditions to atmospheric conditions through the use of a reference signal (Hristov et al., 1998) and has successfully been extended to turbulence modeling (Kelly et al., 2009; Sullivan et al., 2000) and to relate turbulent motions of various scales within the atmospheric boundary layer (Mathis et al., 2009).
Simultaneous observation of multiple thermodynamic and kinematic quantities reported by met masts is necessary to characterize the dynamical state of the atmosphere (Barthelmie et al., 2014; Hansen et al., 2012). Directly considering multiple disparate data channels simultaneously represents a challenge in that each quantity has different engineering units and that variation within each channel may occur over a distinct scale. Atmospheric conditions are frequently characterized by considering wind speed, wind direction, and turbulence intensity or thermal stability, each of which have different units, ranges, and statistical properties. Consideration of these variables independently may not provide a complete picture of the state of the atmosphere, as they are inherently correlated (Holtslag and Nieuwstadt, 1986; Kaimal et al., 1976); each variable offers a limited range of insights as to the dynamical state of the atmosphere relevant to the operation of wind energy assets. Direct comparison of the marginal distributions of atmospheric variables aggregates observations without regard to the value of other, potentially correlated variables. Even the use of conditional statistical distributions or measures discounts any dynamic coupling between them and may not fully describe the nature of the atmospheric physics (Hannesdóttir and Kelly, 2019; Preston et al., 2009; Shahabi and Yan, 2003).
The following work explores an application of numerical analysis methods to atmospheric data to identify continuous periods of interest within met mast time series data. The source of the data and their treatment are discussed briefly, although the wind plant and met mast are not in themselves imperative to the demonstration of the method or its utility. A discussion of aggregate statistical measures of the data is followed by a formal definition of the total variability of a block of time series data and applications using the total variation as a metric to identify specific dynamical events of interest. Alternate metrics exist that quantify the variability of multiple samples or multivariate data. The metrics' total variability, overall variability, and summative variance in common use have slightly different definitions and interpretations from the total variation introduced in the current work. Briefly, total variability is defined as the sum-of-squares total of difference between expected or mean value and observed qualities. Overall variability refers generally to the variance or standard deviation of a population (i.e., a group of samples considered together). Summative or pooled variance refers to the inferred variance of a population of observations from the collection of sample variances. In contrast, the total variation used in the current work reduces the covariance between normalized variables to a single value through the determinant of the covariance matrix. A close analog to this method is the generalized variance of a multidimensional random vector. Generalized variance was introduced by Wilks (1932) and Sengupta (2004) as a scalar measure of overall multidimensional scatter. However, in most formulations of generalized variance, the data are regarded as a p−dimensional vector. The current work uses the same mathematical operations but applies them to distinct variables that have been merged into a matrix. Mechanically, the same operations are being applied to the data, but given the distinction in formulation, the current work adopts the jargon of “total variation”. Finally, sensitivity of the method to outliers is analyzed, ending with a discussion of broader applications and extensions to the method.
Data used to demonstrate the current method for detecting conditions of interest issue from met mast signals at the Lillgrund Wind Farm, located 10 km off the coast of southern Sweden in the Kattegat Strait. Lillgrund is comprised of 48 Siemens SWT-2.3-93 wind turbines and has a rated nameplate capacity of 110 MW. The layout of the Lillgrund wind plant is shown in Fig. 1a, where each turbine location is denoted with a marker whose color is representative of the average power produced over the time period analyzed below. Operational data (SCADA, power production, turbine availability) from the wind farm are not discussed further in the following analysis, although a brief summary of future applications of the method is provided in the Conclusions section, including thoughts on wind plant performance and SCADA data. Data used to demonstrate the calculation of total variation and identify periods of interest come from the met mast, located at the southwest corner of the wind plant, indicated in Fig. 1a with an open marker.
Within any wind plant data, conditions of value for validation are typically identified by way of aggregate statistical metrics or by identifying “well-behaved” time periods exhibiting a dynamical event or atmospheric condition of interest. Kinematic and thermodynamic atmospheric quantities that are expected to have the greatest impact on the performance of a wind plant are the wind speed u, wind direction θ, and the atmospheric stability, considered either in an instantaneous or time-averaged sense. The stability of the atmosphere (typically quantified by the Monin–Obukhov stability parameter or the Richardson number) indicates the magnitude of buoyant production or destruction of turbulent kinetic energy (TKE) relative to shear production of TKE and whether it represents either a source or sink of (vertical) momentum (Kumar et al., 2006; Wyngaard, 2010). Forcing in the momentum equations as indicated by the presence and sign of a buoyancy term is manifested in atmospheric flow as vertical turbulent mixing and is an important overall factor in the energy balance relevant to wind plant operation. Thermal stability has a significant effect on atmospheric turbulence and the structure of wind turbine wakes, wake interaction, and thus the overall energy balance within the wind plant (Ali et al., 2019).
Data used in the current work do not contain any observations of the temperature or heat flux between the atmosphere and the ocean surface, and thus no estimate for the traditional stability metrics is available. Turbulence intensity (TI), although an imperfect proxy of atmospheric stability from a fluid mechanical or atmospheric perspective, provides some sense of the energy contained in the fluctuating flow field and is well-suited for presenting the utility of the total variation method below. Additionally, TI is a quantity frequently used in the wind energy community to characterize wind plant operating conditions and structural loading of wind turbines (Dimitrov et al., 2018; Kelly et al., 2014) and is often accessible through instrumentation on met masts or wind turbine nacelles making it an appropriate choice for the current demonstration.
Raw data used to demonstrate the current methods include high-frequency (20 Hz) observations of u and θ reported by the met mast between March and December 2009. Wind speed and direction data were binned to a temporal resolution of 1 min, from which mean and standard deviations were calculated. Turbulence intensity in each bin is estimated as the ratio of the retained 1 min statistics for wind speed as TI . As with most field observations, data availability from each channel is less than 100 %, as instruments require maintenance, lose connectivity to data acquisition systems, or shut down to prevent damage under certain conditions. Binning the data into 1 min periods smooths the observed time series of wind speed and direction and reduces the noise reported by the cup anemometer and wind vane.
Additional quality-control steps for the data include omitting from further consideration any 1 min period during which any of the data channels are not correctly reported. Any time stamp associated with wind speeds less than 1 m s−1, when wind speed observations reported by cup anemometers and wind vanes are not considered to be reliable (IEC, 2005a), are also removed from the data set. Figure 1b shows data availability of the record as a percent of the total number of data possible per day. The final quality-control step implemented for the current study is to exclude data that are not part of any continuous set of observations of at least 60 min. The current method searches continuous data samples to identify atmospheric conditions and events of interest. Rather than infill or interpolate data, periods with missing values are simply excluded from consideration.

Characterization of atmospheric conditions is most often pursued through aggregate statistics, that is without explicitly considering their evolution in time. Statistical quantities (arithmetic mean values, variances, and higher-order moments) may reflect the occurrence of infrequent events but do not convey the dynamical evolution of variables or their correlation in time. Considering atmospheric variables in terms of either their marginal distributions (as in Fig. 2) or their conditional distributions (as in Fig. 3) falls short of saying anything about the dynamics embedded in those observations. For example, many steady-state and analytical wake models are defined to represent the time-averaged flow behind a wind turbine and many uses of high-fidelity models assume that the bulk flow speed and direction do not change in time. Effective validation of numerical modeling tools for wind energy requires that observations conform to stationary atmospheric flow (Chenge and Brutsaert, 2005; Metzger et al., 2007; Vincent et al., 2010, 2011; Guala et al., 2011) or represent a dynamic event of interest. Histograms of each of the data channels are provided in Fig. 2, showing characteristic behavior for the wind speed and turbulence intensity distributions.
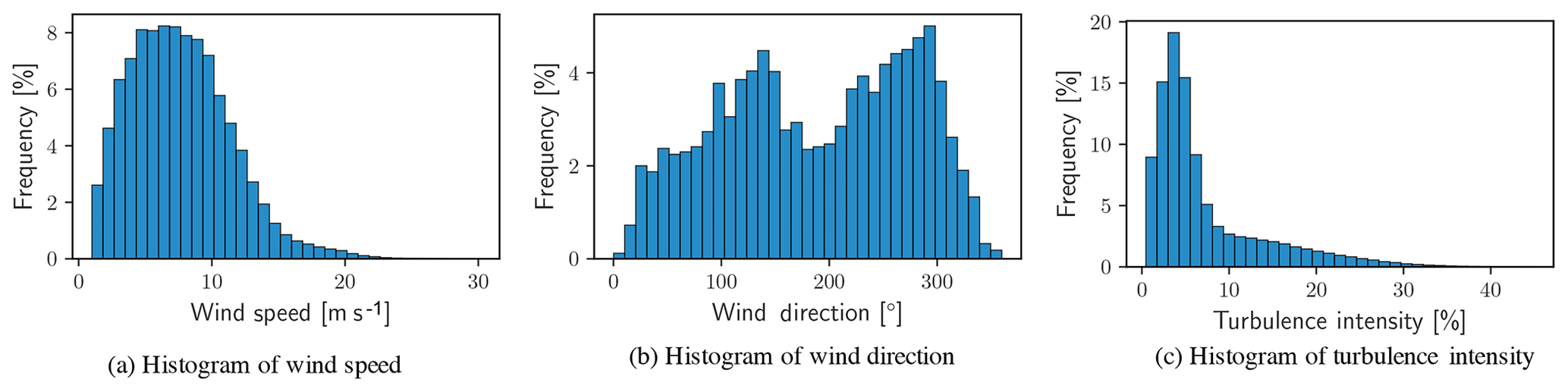
The wind direction (Fig. 2b) shows several key features typical of atmospheric records; first, it identifies the prevailing wind directions as per the number of observations within each direction sector (10∘), and, second, it shows that virtually no observations correspond with wind directly from the north. According to the IEC (2005b) Standard for Power Performance Measurements of Electricity Producing Wind Turbines, met masts should be placed sufficiently far from the nearest upstream obstacle or risk introducing bias and increased uncertainty into the record. This limitation can be difficult or prohibitively expensive to accommodate due to logistical constraints, especially in offshore settings where placement is often strictly limited.
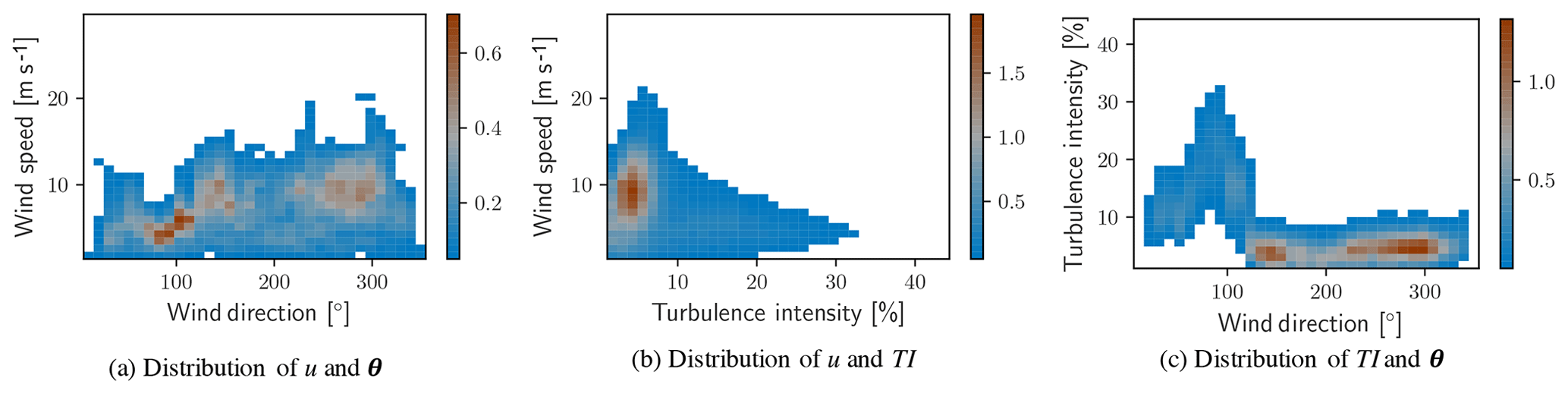
Figure 3Two-dimensional histograms of met mast data. Color information conveys percent of total observations for each pair of variable values.
Each of the histograms in Fig. 2 categorizes a single quantity without regard to the variation in the others; each single-variable histogram effectively integrates the observations over the other two variables. More complex treatment of the data is required to take into account the simultaneous variability of more than one channel. Figure 3 shows two-dimensional histograms with two-way permutations of the data channels. In each of the histograms, a threshold has been applied to the frequency of observations. Any bin representing less than 0.5 % of the total observations has been filtered out to highlight more common conditions. Two-dimensional histograms demonstrate that the atmospheric conditions are more complex than is possible to estimate from pairwise consideration of any two of the one-dimensional histograms in Fig. 2. An observation from the two-dimensional histograms that is not immediately evident in one-dimensional histograms is that the greatest turbulence intensity comes from a single, distinct sector of wind directions. Placement of the met mast with respect to the wind turbines contributes to a sharp increase in TI in the range of 15 %–45 % and is not typical of unobstructed measurements. Reports of high TI likely result from the introduction of turbulence to the flow by the wind turbines or wind plant from directions between 70 and 110∘.

Wind speed and TI roses contain the same information as the two-dimensional histograms from Fig. 4 but convey it on a polar projection representative of the compass, thus making them more intuitive to read for many users. Figure 4 shows wind and TI roses for the considered data. The rose diagrams highlight directional dependence of the mapped variable. For example, Fig. 4b demonstrates that the greatest turbulence intensity is highly correlated with winds from the sector of 70∘–110∘. This is the range of directions in which the met mast is waked by the wind turbine located to the west.
Aggregate statistical representation accounts for interdependence of the three variables considered in the current example but cannot account for the dynamic nature of the atmosphere. A histogram, as a consequence of its composition, only denotes how frequently a given condition is observed without regard to what condition may precede or follow. The actual weather conditions could well be undergoing a dramatic change, but within any 1 min observation, the variables of interest fall within the stated bounds of a single bin within the full condition space.
An alternate path toward identifying conditions of interest for model validation or benchmarking studies comes through seeking continuous periods from the time series of observations that has properties of interest for a given study. An obvious choice would be a continuous period in which the atmospheric conditions remain statistically stationary. Statistical stationarity (i.e., time independence of statistical quantities) is a common consideration in turbulence and atmospheric science (Chenge and Brutsaert, 2005; Metzger et al., 2007; Vincent et al., 2010, 2011; Guala et al., 2011). Stationarity is not often assumed for wind energy research and modeling applications, although it is rarely quantified or even considered in validation data. Additionally, retaining a time series allows users to leverage the interdependence of the channels within a data set by way of correlation or covariance metrics.
Quantifying the variability of a set of data must include the correlation between data channels or risk discounting any information regarding the relationship between variables. Stated otherwise, any metric that combines the variability of each channel independently without accounting for covariance between the channels is incomplete and will not be sufficient to fully characterize the state of a given system. Therefore, a method that accounts for variation within each channel and the covariance between variables is necessary to quantify the distribution of data across multiple channels into a single metric.
Below, each data block, D, is a selected time period and corresponds to an array of size of [m,n], where m is the length of the time period – either 60 or 120 min – and n is 3, corresponding to the number of variables u, θ, and TI.
In order for the variability of each channel in D and their respective covariances to be given equal weight, the data must be normalized to a single common range. Each variable has been normalized by its standard deviation and mapped to an interval determined by the range of each channel in standard deviations according to the formulation
In Eq. (2), the arithmetic mean and standard deviation (denoted by the overline and σ, respectively) are calculated separately for each column of D. Normalizing data before calculating the total variation ensures that each data stream is weighted equally in the characterization of a given condition or state.
In addition to the definition of D, a block, f, containing objective functions of interest to apply to each of the variables in D is defined as
The difference between objective functions and their respective data will be referred to as a regularized data block and is noted with a caret:
The purpose of defining an objective function block is to tune the data to show covariance specifically with respect to a desired form about which the data are regularized. Seeking stationary conditions in which minimal variation occurs in all data channels without regularization amounts to the special case of setting the function block to f=0 (or, more generally, when the objective function is any constant value; f=c). The objective function block is discussed in greater detail in the following sections.
The total variation, 𝒱, of a system is a unitless metric to quantify spread of a set of interdependent variables that accounts for autocorrelation within each channel and for covariance between channels. A covariance matrix is calculated for a subset of the data, representing a continuous period of a specified duration:
In Eq. (5), C is a square matrix of size n×n representing the covariance between any pair of data channels. The total variation, 𝒱, of a given regularized data block, , is expressed as the determinant of the respective correlation matrix:
Larger values of 𝒱 indicate that the data points are more dispersed in the condition space. In the observational data of the atmosphere discussed here, 𝒱>0. The case of 𝒱=0 would indicate that the full n-dimensional condition space is not occupied and some of the variables are perfectly correlated with, i.e., linearly dependent on, some of the others. Metrics of the variation in a multivariate data set have some history in the literature. Notable past contributions include the pooled variance method to estimate population variance from those of distinct samples (Ruxton, 2006) and the “total” or “overall” variability (Anderson, 1962; Goodman, 1968) which combines variances of individual variables either linearly or in a sum-of-squares sense. The generalized variance (Wilks, 1932; Sengupta, 2004) shares a common formulation with 𝒱 but has historically been applied to a p-dimensional random vector. In contrast, the total variation merges n distinct variables, whose relationship need not be known a priori, and seeks the determinant of the associated correlation matrix.

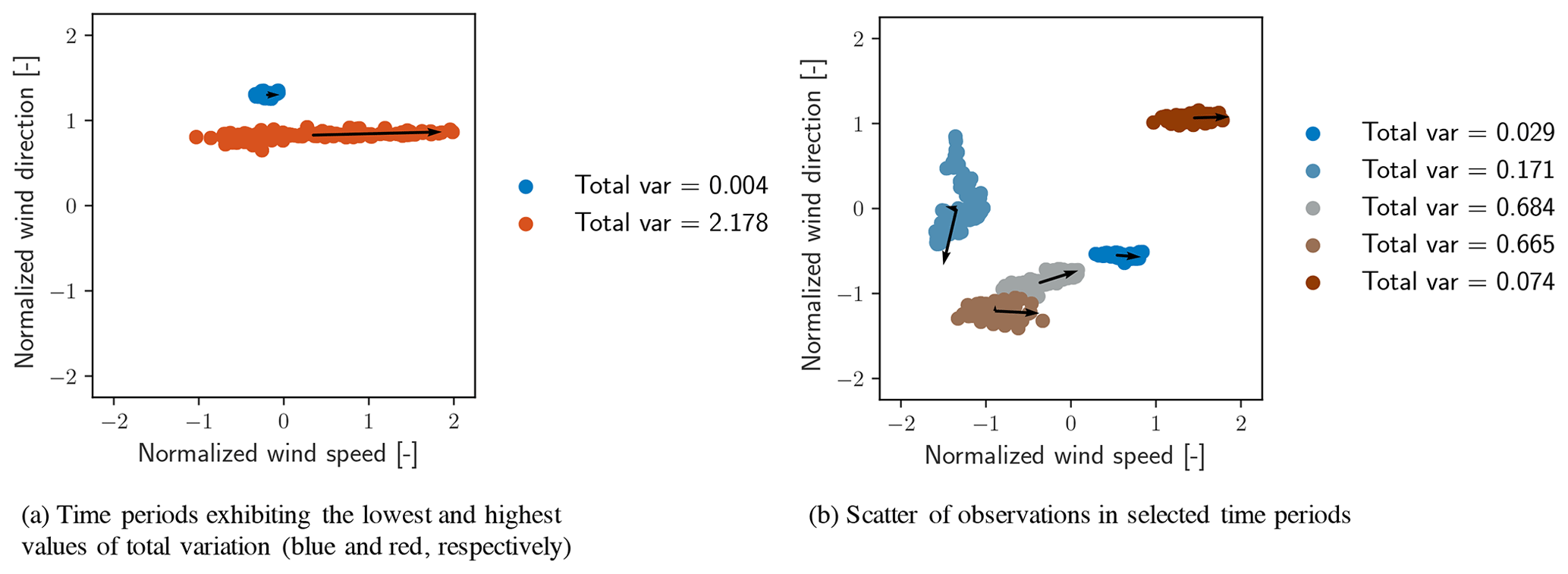
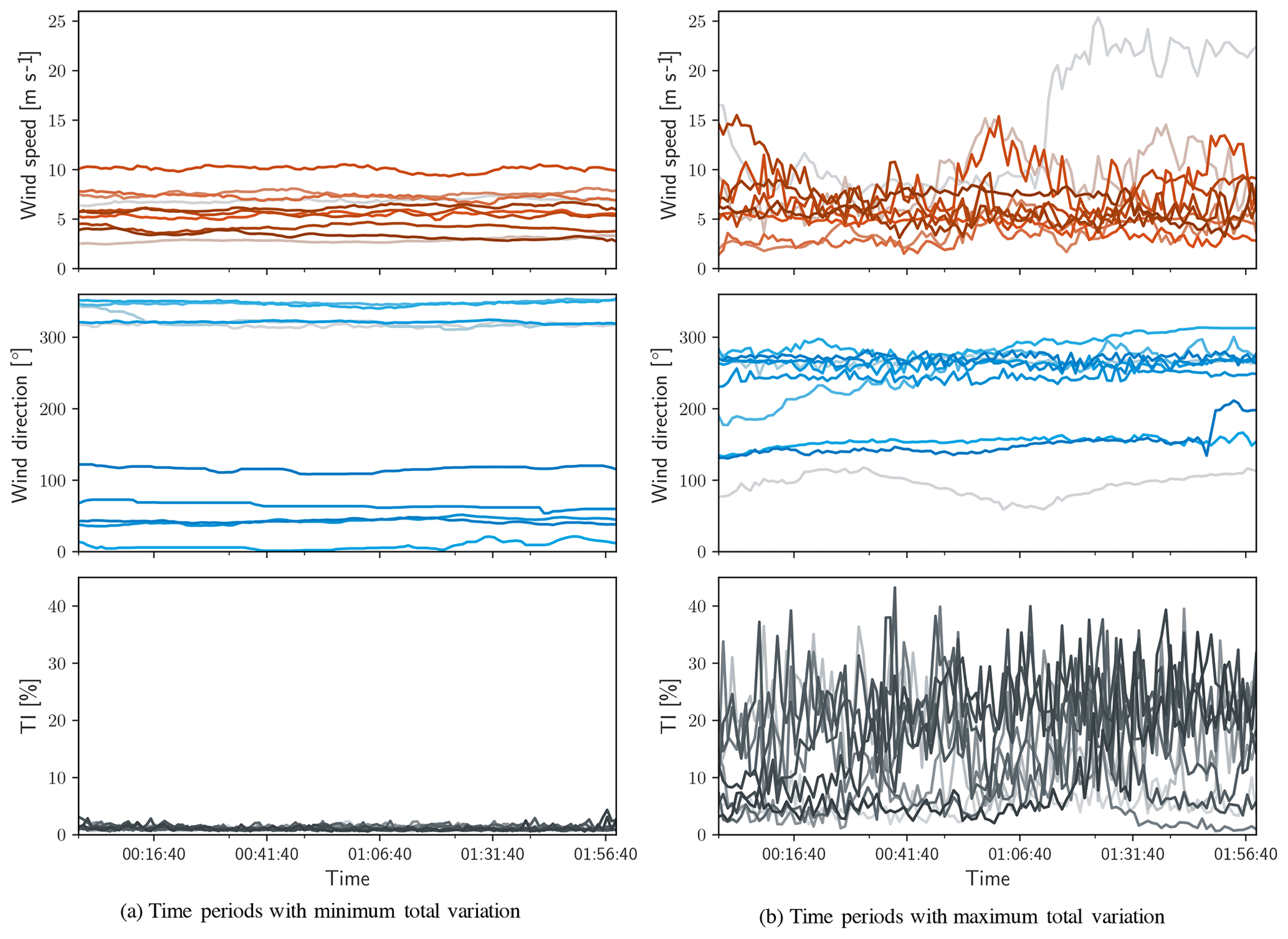
Figure 7Time series of the 10 blocks with minimum and maximum values of 𝒱 – (a) and (b), respectively.
4.1 Quiescent conditions: f=c
Figure 5 shows the distribution of 𝒱 dividing the data record into continuous periods of either 60 (blue) or 120 min (red). Both distributions in Fig. 5 have been limited to 𝒱≤0.30 to emphasize differences between the two data block lengths. In either case, the distribution is positively skewed, and high values of 𝒱 exist with very low frequency. Immediately visible in the histograms of 𝒱 is that there is a range of values exhibited most commonly by the blocks of data. For data broken into 60 min periods, 35.9 % of blocks have a total variation of less than 0.05, whereas for data broken into 120 min periods, only 25.0 % of blocks have a total variation in the same range. Although 𝒱 is a unitless metric, its relative value does convey the degree of variation represented by all data within a respective time period. The values of 𝒱 with the greatest frequency of occurrence are larger for periods of 120 min than for periods of 60 min. This is an expected trend because of the greater changes in atmospheric conditions that are possible within a larger window. There remains an inherent trade-off between the length of a data block and the degree of variation; longer blocks provide greater statistical convergence of C but risk including more dynamical variation, which contributes to higher values of 𝒱.
Periods of time corresponding to the minimum values of 𝒱 are those in which the total atmospheric conditions vary the least. In these periods, small values of standard deviation within each data channel as well as minimal covariance between the channels is expected. Minimal covariance between channels is equivalent to observing only stochastic, uncorrelated fluctuations in each channel. In contrast, periods corresponding to the maximum values of 𝒱 are those in which the subset of data experiences the greatest variability, to which individual channel noise and correlated events between channels both contribute. Time periods of 120 min corresponding to the maximum (red) and minimum (blue) total variation are shown in Fig. 6a. To provide a broader sense of how other time periods are characterized in terms of 𝒱, five randomly selected periods of 120 min are shown in Fig. 6b. The principal components of each data block are shown with black vectors and the total variation is listed in the legend. The figure represents each block of data as a scatter of only normalized wind speed and direction, although TI is also in the calculation of 𝒱.
Figure 7 shows the wind speed, direction, and turbulence intensity corresponding to the 10 periods of minimum and maximum total variation. Each variable is shown in its original (non-normalized) engineering units to provide insight into the atmospheric conditions, although they were identified using normalized data. Figure 7a shows that the periods with minimal values of 𝒱 have time series that appear constant and experience only small stochastic variations within each channel and that periods with large values of 𝒱 exhibit more spread. For each set of time series, the extreme values are shown in the boldest color (red, blue, and gray for the wind speed, direction, and turbulence intensity, respectively) and fade to lighter colors for more moderate values of 𝒱. Starting and ending times are not included, as Fig. 7 is intended only to demonstrate the sorting capability of the method.
4.2 Objective conditions: f≠0
Regularizing the data with respect to a set of nonzero objective functions centers 𝒱 around specific conditions of interest. For example, in the case of wind plant analysis, it may be of interest to assess array performance during a wind speed ramp event or change in wind direction. Such events may be readily formulated according to accepted mathematical definitions and supplied to the total variation algorithm from Sect. 4. Defining specific objective functions will quantify the total variation around those conditions, which can then be used to identify the time periods that match the event of interest most closely.
An additional step is considered to sort the full data set for a more general formulation. In such a case, events of interest are defined in a suitably general formulation, and a least-squares minimization is applied to seek the relevant parameter values. In the current demonstration, function types of interest are wind speed ramps, wind speed waves, and wind direction changes, shown in the function blocks Eqs. (7), (8), and (9), respectively, distinguished with the subscripts A, B, and C.
In each of the equations for fA, fB, or fC, objective function parameters, ci, are sought through least-squares minimization of the following expressions:
where ρ is the least-squares fit residual. Least-squares fit parameters and the respective fit residual from each time period are retained, enabling an additional layer of filtering for conditions of interest. After objective function coefficients are determined, the total variation method is continued, yielding a value of 𝒱 for regularized data in each time period. Regularizing the data block by subtracting away objective functions amounts to “detrending” the data such that the covariance matrix reflects correlation among the remaining data.
Figure 8a compares distributions of 𝒱 given the objective function definitions in Eqs. (7), (8), and (9). The distributions indicate that the total variation can be reduced by regularizing data around generalized sinusoidal (red), linear (blue), and inverse tangent (black) functions as compared to the case where f=0 (gray). However, the reduction in 𝒱 for the full data set is caused by the general definitions of the objective functions. Defining the coefficient values ahead of time would likely increase the average value and spread of 𝒱; for example, it is not expected that a wind speed ramp with specific slope and vertical offset would fit every time period well and thus would not necessarily reduce the total variation for that period.
Noted earlier, the additional step of least-squares minimization provides a fit residual for each time period under consideration, shown in Fig. 8b. Fit residuals indicate the goodness of fit of a given time period to the specified objective function forms. The distributions in Fig. 8b suggest that inverse tangent and sinusoidal functions fit the data with less residual error, ρ, than a linear objective function. This is likely caused by the additional objective function parameters (degrees of freedom) available for tuning the minimization.
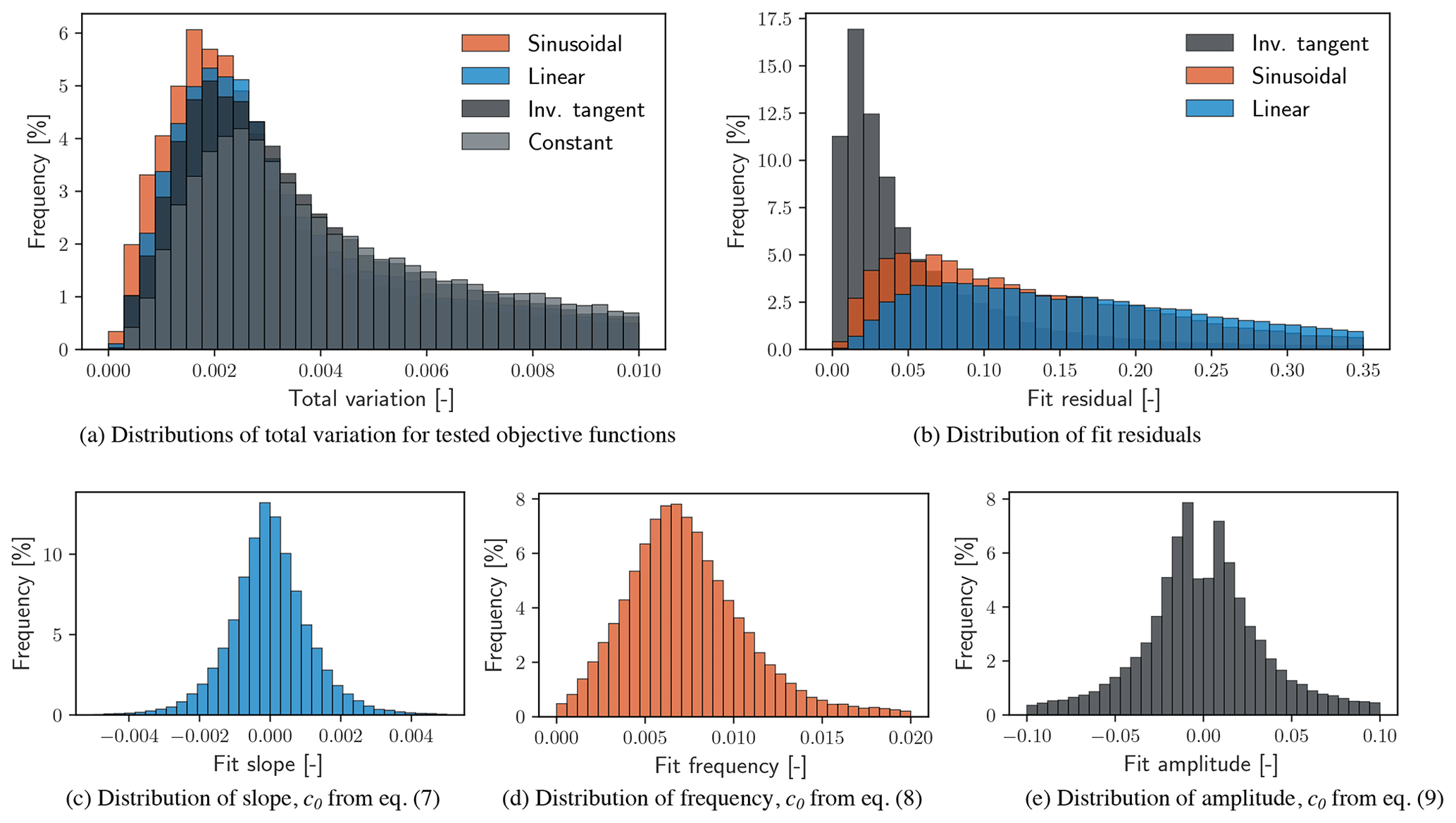
Adding an auxiliary step to the search process of least-squares minimization to a given objective function quantifies the goodness of fit of each data block and can return the parameter values necessary for the desired fit. For example, a least-squares fit to a linear relationship for any data channel will provide values of slope and offset as well as a residual value indicating the quality of the fit. In this way, the data provide alternative values for which sorting may be applied in addition to the total variation.
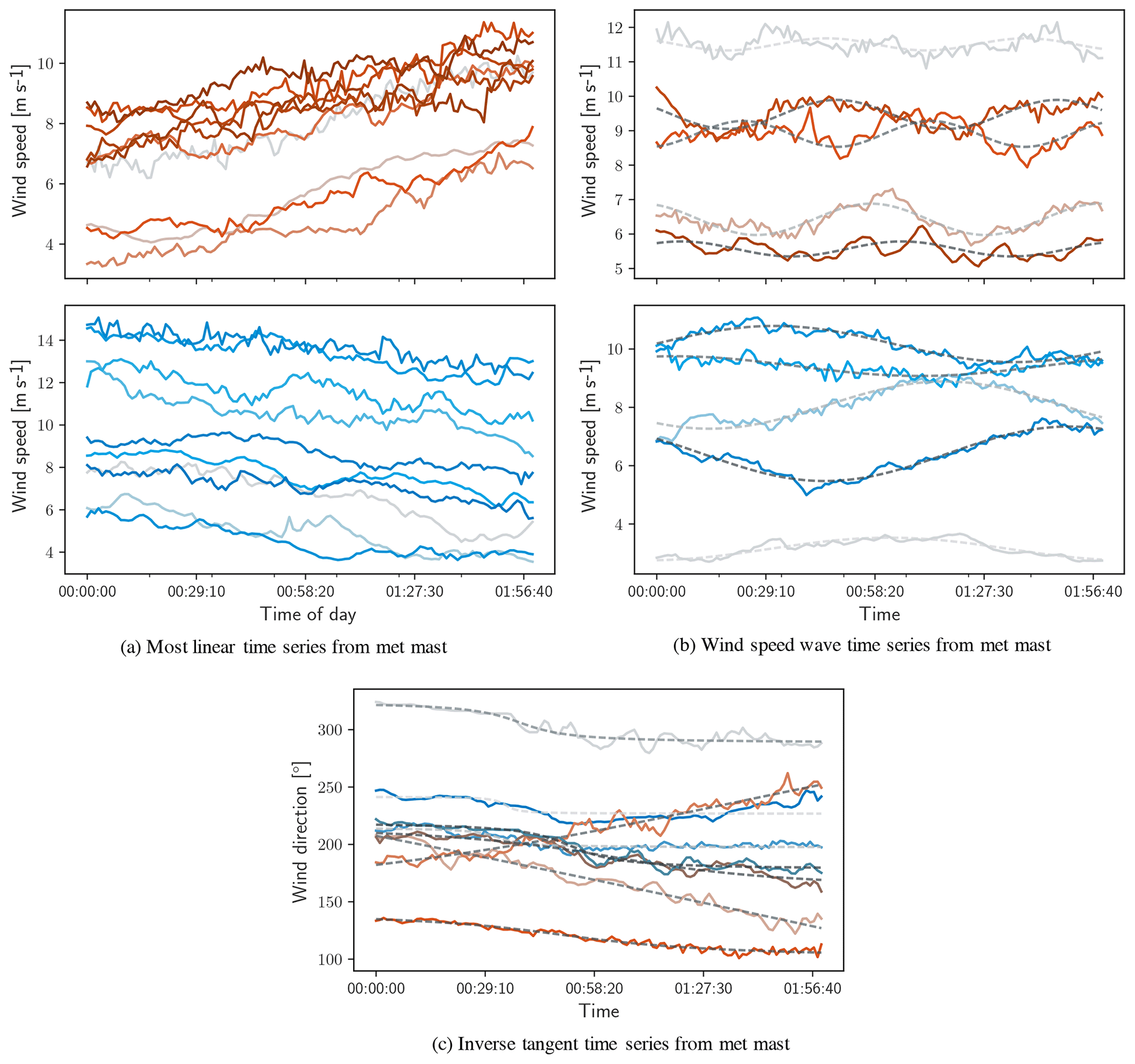
Figure 9Examples of time series identified by calculating covariance matrix around linear, sinusoidal, and inverse tangent objective functions.
Figure 9a and b show a selection of periods with minimal total variation around linear and sinusoidal objective functions of wind speed, corresponding to wind speed ramps and waves, respectively. The selection of the wind speed ramps in Fig. 9a is conditioned to have the minimal total variation, minimal fit residual, and maximum absolute values of slope. These are the time periods in which the wind speed ramps are simultaneously the most well-behaved (i.e., minimal fit residual) and most intense (i.e., greatest absolute value of slope). Similarly, the wind speed waves shown in Fig. 9b were selected by seeking the minimal total variation and then selecting time periods in which the fit frequency fell between desired limits. In Fig. 9b, the top subpanel shows 120 min time periods in which the fit frequency is in the range of [0.015,0.02] rad s−1 (in red), and the bottom subpanel shows time periods in which the fit frequency is in the range of [0.0075,0.008] rad s−1 (in blue). Frequency limits were selected arbitrarily and are meant only as a demonstration of the method's independence of fit frequency. Figure 9c applies an inverse tangent objective function to the wind direction channel while seeking constant conditions in wind speed and turbulence intensity, identifying the periods of wind direction change with minimal total variation. Direction changes were considered in an absolute sense, and Fig. 9c shows time periods with minimal 𝒱 in which the absolute direction change falls in the range . Again, the particular magnitude of direction change selected here is arbitrary, and was selected only to demonstrate the fit to an inverse tangent objective function.
A word of caution on using the total variation to identify periods of interest: because principal component analysis is sensitive to outliers contained in the data, the method may falsely classify a time period as having a large value of total variation due to a few spurious data points. Consideration of outliers in multivariate space requires a similar treatment as for the consideration of total variation. Seeking outlying points in each data channel individually discounts the possibility that the other data channels may be within acceptable statistical limits for the same point. Determining outliers from individual data channels further discounts any correlation that may exist between the channels. An effective means of considering outliers in multivariate data is the Mahalanobis distance, χ, which quantifies the Euclidean distance of a point from the center of a data set in terms of standard deviations (De Maesschalck et al., 2000; Hadi, 1992; Rousseeuw and Van Zomeren, 1990; Xiang et al., 2008):
The Mahalanobis distance is sought through the covariance matrix of the data, and thus accounts for interdependence of the data channels, as emphasized earlier. Setting a threshold value for the Mahalanobis distance effectively draws an n-dimensional ellipsoidal boundary around the data set in nondimensional space, outside of which data are considered invalid.
To quantify the sensitivity of 𝒱 to the presence of outliers, 10 000 synthetic data sets are generated and outliers are detected and eliminated. Total variation is compared for each data set before and after outlier detection or elimination. Synthetic data sets (n=2 dimensions, 1000 points each) are normally distributed about a zero mean value with a standard deviation that is randomly assigned in the range of [0, 10]. Each data set is normalized, given a random shape parameter to stretch the data, and rotated to simulate covariance between data channels. The covariance matrix is calculated using Eq. (5), and 𝒱 is calculated as in Eq. (6). Any point with χ>3 is flagged as an outlier and eliminated. With 2 degrees of freedom (variables in the data block), values of χ>3 are expected to be observed with a probability of approximately 1.1 % (Penny, 1996; Ben-Gal, 2005; Gellert et al., 2012). The total variation is then calculated for the cleaned data without outliers, for comparison.

Figure 10a shows a single example set of synthetic data. Accepted data are shown in blue, outliers in red, and the principal components of the data are shown as the black vectors. Figure 10b shows distributions of 𝒱 before and after the exclusion of outlying data identified with a threshold of χ in blue and red, respectively. As expected, the total variation in data sets without outliers is smaller than data sets before cleaning. Because of the large number of synthetic data sets considered, statistics regarding sensitivity to outliers are also within reach.
Figure 10c shows the distribution of the number of detected outliers within each synthetic data set. Figure 10d shows the mean relative error according to the number of detected outliers according to
where the subscripts denote the presence and absence of outliers (raw and clean, respectively). Uncertainty of the error is shown as the shaded bands around the mean relative error. The red band indicates the standard deviation of the relative error (σε), and the blue band denotes the standard error (σε∕Noutliers). The roughly linear relationship shown in Fig. 10d indicates that one could expect an increase in error of approximately 4 % for each additional percent outlier content of a given data set.
It should be noted that the present error analysis is not expected to yield identical results for atmospheric data. Observations of wind speed, direction, and turbulence intensity can vary considerably during any given period as part of the normal development of weather patterns. Mentioned briefly in the Introduction, quality control of met mast and SCADA data is an active research topic and is beyond the scope of the current method development. However, it should be clear from the sensitivity analysis undertaken here that a careful quality-control process should be applied before calculation of the total variation.
The definition of high-value conditions for wind plant analysis is ultimately up to the user but may not conform to the most frequently observed state. For example, it may be of greater concern to wind plant developers, owners, or operators to be able to validate models where wake losses are greatest or during ramps of wind speed. These conditions may be more relevant to control or curtailment actions of wind plants and may have a greater impact on the return on investment of wind energy assets.
The identification of continuous time periods that conform to conditions of interest is not intuitive through aggregate statistics, such as measures of central tendency or joint probability distributions. The method to quantify the total variation in a multivariate data set described earlier provides a computationally economical means of parsing large and complex data sets and includes a mathematically robust approach to sorting with respect to a desired condition or objective function. In addition, the method should be equally applicable to any data, regardless of which variables are part of the data block and for data of any length and resolution, provided that enough observations are present to ensure reasonably converged statistics. Normalizing the data makes combining disparate types of data into a single metric possible and meaningful.
The total variation method for seeking conditions of interest has applications far beyond the demonstration undertaken in the current work. Once properly classified, any number of detection and forecasting models may be trained and validated. Collecting time periods containing similar dynamical events opens a path forward for more advanced analyses, such as modal decomposition methods and reduced-order modeling. Extreme atmospheric events, as from the International Electrotechnical Commission (IEC) Standard for Wind Turbine Design (IEC, 2005a), have well-defined characteristic functions that could readily be incorporated into the method explored in this article. Extreme atmospheric event definitions can be included in the definition of the function block and used to regularize the data, providing an algorithmic means of identifying extreme events in historical data records for subsequent analysis.
The total variation method explored here details identification and characterization of time series data from met masts only. Validation of high-fidelity wind plant models frequently relies on some form of operational data, most often power production or some integrated statistic of wind plant performance. SCADA signals and power production or fault events could readily be identified with the total variation method. A further extension of the method would be to add functionality that accounts for spatial variation in operational data within a wind plant. A spatial aspect of the total variation method would augment the process to be able to detect and characterize the movement of weather fronts through a wind plant or cases in which wake losses are particularly significant and heterogeneous.
An example Python library has been uploaded to a public repository at https://github.com/nhamilto/total-variation (Hamilton, 2020a, b) (https://doi.org/10.5281/zenodo.3630875). In the repository, there can also be found a synthetic data generator used for the analysis of outlier sensitivity and met mast data similar to that used in the work above. Data in the example are derived from a meteorological mast located at the National Renewable Energy Laboratory’s Flatirons campus. Additional data from the met mast are available at https://nwtc.nrel.gov/MetData (NREL, 2020) and the atmospheric conditions at NREL are summarized in Hamilton and Debnath (2019).
The author declares that there is no conflict of interest.
This work was authored by the National Renewable Energy Laboratory, operated by Alliance for Sustainable Energy, LLC, for the U.S. Department of Energy (DOE) under Contract No. DE-AC36-08GO28308. Funding provided by the U.S. Department of Energy Office of Energy Efficiency and Renewable Energy Wind Energy Technologies Office. The views expressed in the article do not necessarily represent the views of the DOE or the U.S. Government. The U.S. Government retains and the publisher, by accepting the article for publication, acknowledges that the U.S. Government retains a nonexclusive, paid-up, irrevocable, worldwide license to publish or reproduce the published form of this work, or allow others to do so, for U.S. Government purposes. Data were furnished to the authors under an agreement between the National Renewable Energy Laboratory, Siemens Gamesa Renewable Energy A/S, and Vattenfall. Data and results used herein do not reflect findings by Siemens Gamesa Renewable Energy A/S and Vattenfall. Additional thanks to the National Renewable Energy Laboratory Wake Squad for the musings and dialogue that ultimately led to this work getting started (and finished). Special thanks to Tony Martinez for countless discussions on everything from numerical methods to physical interpretations, editing, and computational assistance with volume rendering. Bridging the gap between my own turbulence experience and Mike Optis' atmospheric perspective essentially framed the discussion and motivation of the work.
This research has been supported by the U.S. Department of Energy Office of Energy Efficiency and Renewable Energy Wind Energy Technologies Office (Contract No. DE-AC36-08GO28308).
This paper was edited by Laura Bianco and reviewed by Ásta Hannesdóttir and Mark Kelly.
Ali, N., Hamilton, N., Calaf, M., and Cal, R. B.: Turbulence kinetic energy budget and conditional sampling of momentum, scalar, and intermittency fluxes in thermally stratified wind farms, J. Turbul., 1, 32–63, https://doi.org/10.1080/14685248.2018.1564831, 2019. a
Anderson, T. W.: An introduction to multivariate statistical analysis, Tech. rep., Wiley New York, 1962. a
Barthelmie, R., Crippa, P., Wang, H., Smith, C., Krishnamurthy, R., Choukulkar, A., Calhoun, R., Valyou, D., Marzocca, P., Matthiesen, D., et al.: 3D wind and turbulence characteristics of the atmospheric boundary layer, B. Am. Meteorol. Soc., 95, 743–756, 2014. a
Barthelmie, R., Churchfield, M. J., Moriarty, P. J., Lundquist, J. K., Oxley, G., Hahn, S., and Pryor, S.: The role of atmospheric stability/turbulence on wakes at the Egmond aan Zee offshore wind farm, in: Journal of Physics: Conference Series, 625, p. 012002, IOP Publishing, 2015. a
Belušić, D. and Mahrt, L.: Is geometry more universal than physics in atmospheric boundary layer flow?, J. Geophys. Res.-Atmos., 117, https://doi.org/10.1029/2011JD016987, 2012. a
Ben-Gal, I.: Outlier detection, in: Data mining and knowledge discovery handbook, 131–146, Springer, 2005. a
Bossavy, A., Girard, R., and Kariniotakis, G.: Forecasting ramps of wind power production with numerical weather prediction ensembles, Wind Energy, 16, 51–63, 2013. a
Chenge, Y. and Brutsaert, W.: Flux-profile relationships for wind speed and temperature in the stable atmospheric boundary layer, Bound.-Lay. Meteorol., 114, 519–538, 2005. a, b
Cutler, N., Kay, M., Jacka, K., and Nielsen, T. S.: Detecting, categorizing and forecasting large ramps in wind farm power output using meteorological observations and WPPT, Wind Energy: An International Journal for Progress and Applications in Wind Power Conversion Technology, 10, 453–470, 2007. a
De Maesschalck, R., Jouan-Rimbaud, D., and Massart, D. L.: The mahalanobis distance, Chemometr. Intell. Lab., 50, 1–18, 2000. a
Dimitrov, N. K., Kelly, M. C., Vignaroli, A., and Berg, J.: From wind to loads: wind turbine site-specific load estimation with surrogate models trained on high-fidelity load databases, Wind Energy Science, 3, 767–790, 2018. a
Eaton, M. L.: Multivariate statistics: a vector space approach, John Wiley & Sons, Inc., 605 third ave., New York, NY 10158, USA, 1983, 512 pp., 1983. a
Ferreira, C., Gama, J., Matias, L., Botterud, A., and Wang, J.: A survey on wind power ramp forecasting, Tech. rep., Argonne National Lab. (ANL), Argonne, IL (United States), 2011. a
Ferreira, C., Gama, J., Miranda, V., and Botterud, A.: Probabilistic ramp detection and forecasting for wind power prediction, in: Reliability and risk evaluation of wind integrated power systems, 29–44, Springer, 2013. a
Fulcher, B. D.: Feature-based time-series analysis, in: Feature Engineering for Machine Learning and Data Analytics, 87–116, CRC Press, 2018. a
Gamage, N. and Hagelberg, C.: Detection and analysis of microfronts and associated coherent events using localized transforms, J. Atmos. Sci., 50, 750–756, 1993. a, b
Gellert, W., Hellwich, M., Kästner, H., and Küstner, H.: The VNR concise encyclopedia of mathematics, Springer Science & Business Media, 2012. a
Goodman, M.: 242. Note: A Measure of'Overall Variability'in Populations, Biometrics, 189–192, 1968. a
Guala, M., Metzger, M., and McKeon, B. J.: Interactions within the turbulent boundary layer at high Reynolds number, J. Fluid Mech., 666, 573–604, 2011. a, b
Hadi, A. S.: Identifying multiple outliers in multivariate data, J. Roy. Stat. Soc. B, 54, 761–771, 1992. a
Hamilton, N.: total-variation, available at: https://github.com/nhamilto/total-variation (last access: 30 January 2020), 2020a. a
Hamilton, N.: total-var, Zenodo, https://doi.org/10.5281/zenodo.3630875, 2020b. a
Hamilton, N. and Debnath, M. C.: National Wind Technology Center-Characterization of Atmospheric Conditions, Tech. rep., National Renewable Energy Lab. (NREL), Golden, CO (United States), 2019. a
Hannesdóttir, Á. and Kelly, M. C.: Detection and characterization of extreme wind speed ramps, Wind Energy Science, 4, 385–396, 2019. a, b
Hansen, K. S., Barthelmie, R. J., Jensen, L. E., and Sommer, A.: The impact of turbulence intensity and atmospheric stability on power deficits due to wind turbine wakes at Horns Rev wind farm, Wind Energy, 15, 183–196, 2012. a
Holtslag, A. A. and Nieuwstadt, F. T.: Scaling the atmospheric boundary layer, Bound.-Lay. Meteorol., 36, 201–209, 1986. a
Hristov, T., Friehe, C., and Miller, S.: Wave-coherent fields in air flow over ocean waves: Identification of cooperative behavior buried in turbulence, Phys. Rev. Lett., 81, 5245–5248, https://doi.org/10.1103/PhysRevLett.81.5245, 1998. a
IEC: 61400-1: Wind turbines part 1: Design requirements, International Electrotechnical Commission, p. 177, 2005a. a, b
IEC, I.: 61400-12-1: Wind turbines Part 12-1: Power performance measurements of electricity producing wind turbines, International Electrotechnical Commission, 14–16, Annexes A and B, 2005b. a
Kaimal, J., Wyngaard, J., Haugen, D., Coté, O., Izumi, Y., Caughey, S., and Readings, C.: Turbulence structure in the convective boundary layer, J. Atmos. Sci., 33, 2152–2169, 1976. a
Kang, Y., Belušić, D., and Smith-Miles, K.: Detecting and classifying events in noisy time series, J. Atmos. Sci., 71, 1090–1104, 2014. a
Kang, Y., Hyndman, R. J., and Smith-Miles, K.: Visualising forecasting algorithm performance using time series instance spaces, Int. J. Forecast., 33, 345–358, 2017. a
Kelly, M., Wyngaard, J. C., and Sullivan, P. P.: Application of a subfilter-scale flux model over the ocean using OHATS field data, J. Atmos. Sci., 66, 3217–3225, 2009. a
Kelly, M., Larsen, G., Dimitrov, N. K., and Natarajan, A.: Probabilistic meteorological characterization for turbine loads, in: Journal of Physics: Conference Series, vol. 524, p. 012076, IOP Publishing, 2014. a
Kumar, P. and Foufoula-Georgiou, E.: Wavelet analysis for geophysical applications, Rev. Geophys., 35, 385–412, 1997. a
Kumar, V., Kleissl, J., Meneveau, C., and Parlange, M. B.: Large-eddy simulation of a diurnal cycle of the atmospheric boundary layer: Atmospheric stability and scaling issues, Water Resour. Res., 42, https://doi.org/10.1029/2005WR004651, 2006. a
Larsen, T. J., Madsen, H. A., Larsen, G. C., and Hansen, K. S.: Validation of the dynamic wake meander model for loads and power production in the Egmond aan Zee wind farm, Wind Energy, 16, 605–624, 2013. a
Lilly, J. M.: Element analysis: a wavelet-based method for analysing time-localized events in noisy time series, P. Roy. Soc. A, 473, 20160776, https://doi.org/10.1098/rspa.2016.0776, 2017. a
Mathis, R., Hutchins, N., and Marusic, I.: Large-scale amplitude modulation of the small-scale structures in turbulent boundary layers, J. Fluid Mech., 628, 311–337, 2009. a
Metzger, M., McKeon, B., and Holmes, H.: The near-neutral atmospheric surface layer: turbulence and non-stationarity, Philos. T. Roy. Soc. A, 365, 859–876, 2007. a, b
NREL: NWTC Information Portal (NWTC 135-m Tower Data), available at: https://nwtc.nrel.gov/MetData (last access: 30 January 2020), 2020. a
Penny, K. I.: Appropriate critical values when testing for a single multivariate outlier by using the Mahalanobis distance, J. R. Stat. Soc. C, 45, 73–81, 1996. a
Preston, D., Protopapas, P., and Brodley, C.: Discovering arbitrary event types in time series, Stat. Anal. Data Min., 2, 396–411, 2009. a, b
Rousseeuw, P. J. and Van Zomeren, B. C.: Unmasking multivariate outliers and leverage points, J. Am. Stat. Assoc., 85, 633–639, 1990. a
Ruxton, G. D.: The unequal variance t-test is an underused alternative to Student's t-test and the Mann–Whitney U test, Behav. Ecol., 17, 688–690, 2006. a
Sengupta, A.: Generalized variance, Encyclopedia of statistical sciences, 2004. a, b
Sevlian, R. and Rajagopal, R.: Wind power ramps: Detection and statistics, in: 2012 IEEE Power and Energy Society General Meeting, 1–8, IEEE, 2012. a
Shahabi, C. and Yan, D.: Real-time Pattern Isolation and Recognition Over Immersive Sensor Data Streams, in: MMM, 93–113, 2003. a, b
Sørensen, J. N. and Shen, W. Z.: Numerical modeling of wind turbine wakes, J. Fluid. Eng., 124, 393–399, 2002. a
Sullivan, P. P., McWilliams, J. C., and Moeng, C.-H.: Simulation of turbulent flow over idealized water waves, J. Fluid Mech., 404, 47–85, 2000. a
Sun, J., Nappo, C. J., Mahrt, L., Belušić, D., Grisogono, B., Stauffer, D. R., Pulido, M., Staquet, C., Jiang, Q., Pouquet, A., et al.: Review of wave-turbulence interactions in the stable atmospheric boundary layer, Rev. Geophys., 53, 956–993, 2015. a
Taswell, C.: Handbook of wavelet transform algorithms, Birkhauser, 1st edition, ISBN 081763925X, 2001. a
Vincent, C., Giebel, G., Pinson, P., and Madsen, H.: Resolving nonstationary spectral information in wind speed time series using the Hilbert–Huang transform, J. Appl. Meteorol. Clim., 49, 253–267, 2010. a, b
Vincent, C. L., Pinson, P., and Giebela, G.: Wind fluctuations over the North Sea, Int. J. Climatol., 31, 1584–1595, 2011. a, b
Wasserman, L.: All of statistics: a concise course in statistical inference, Springer Science & Business Media, 2013. a
Wilks, S. S.: Certain generalizations in the analysis of variance, Biometrika, 471–494, 1932. a, b
Wyngaard, J. C.: Turbulence in the Atmosphere, Cambridge University Press, 2010. a
Xiang, S., Nie, F., and Zhang, C.: Learning a Mahalanobis distance metric for data clustering and classification, Pattern Recogn., 41, 3600–3612, 2008. a
Zhang, J., Florita, A., Hodge, B.-M., and Freedman, J.: Ramp forecasting performance from improved short-term wind power forecasting, in: ASME 2014 international design engineering technical conferences and computers and information in engineering conference, V02AT03A022–V02AT03A022, American Society of Mechanical Engineers, 2014. a